
《特征工程三部曲》之三:维度压缩
当特征选择完成之后,就可以直接训练模型了,但是可能由于特征矩阵过大导致计算量大,训练时间长的问题;因此,降低特征矩阵维度,也是必不可少的,主成分分析就是最常用的降维方法,在减少数据集的维度的同时,保持对方差贡献最大的特征,在sklearn中,我们使用PCA类进行主成分分析。
主成分分析(Principal Components Analysis)
PCA API
- 有一个参数用于设置主成分的个数:pca_3=PCA(n_components=3),设置好参数后,就可以生成PCA的对象了
- 接着我们可以调用fit_transform方法对高维数据进行压缩:data_pca_3=pca3.fit_transform(data)
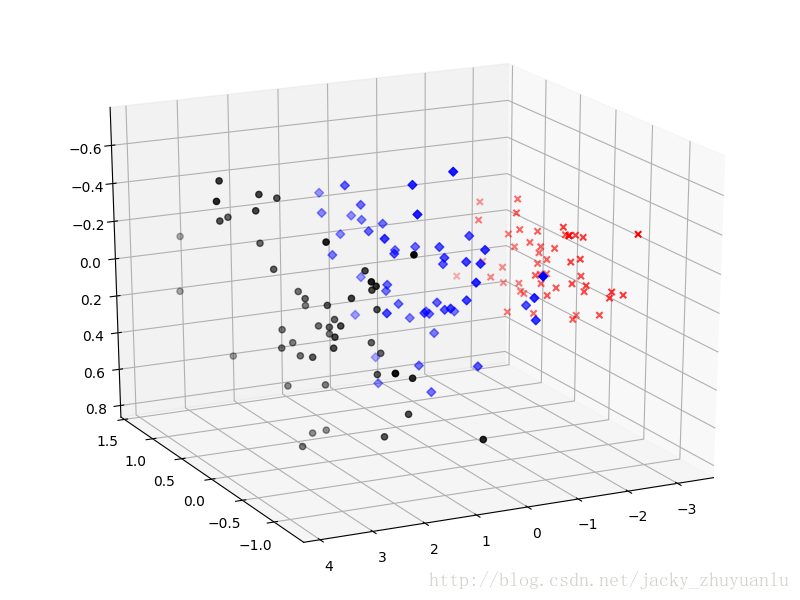
我们人类能看到的数据是三维数据,那么怎样把四维数据压缩到三维数据呢?
#导入iris特征数据到data变量中
import pandas
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from mpl_toolkits.mplot3d import Axes3D
iris =datasets.load_iris()
data = iris.data
#分类变量到target变量中
target = iris.target
#使用主成分分析,将四维数据压缩为三维
pca_3 = PCA(n_components=3)
data_pca_3 = pca_3.fit_transform(data)
#绘图
colors={0:'r',1:'b',2:'k'}
markers={0:'x',1:'D',2:'o'}
#弹出图形
#%matplotlib qt
#三维数据
fig = plt.figure(1,figsize=(8,6))
ax = Axes3D(fig,elev=-150,azim=110)
data_pca_gb = pandas.DataFrame(
data_pca_3
).groupby(target)
for g in data_pca_gb.groups:
ax.scatter(
data_pca_gb.get_group(g)[0],
data_pca_gb.get_group(g)[1],
data_pca_gb.get_group(g)[2],
c=colors[g],
marker=markers[g],
cmap=plt.cm.Paired
)
plt.show()生成的效果图如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号