
Python数据抓取(3) —抓取标题、时间及链接
本次分享,jacky将跟大家分享如何将第一财经文章中的标题、时间以及链接抓取出来
(一)观察元素抓取位置
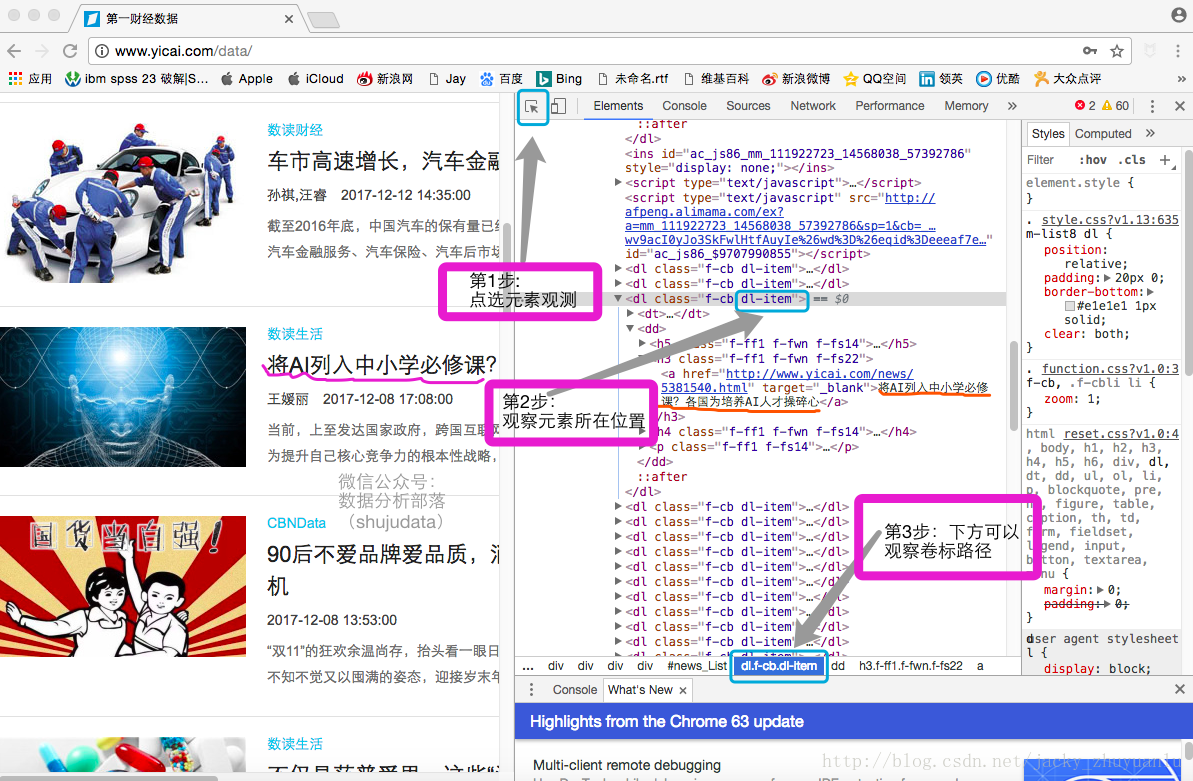
- 网页的原始码很复杂,我们必须找到特殊的元素做抽取,怎么找到特殊的元素呢?使用开发者工具检视每篇文章的分隔发现都以dl-item做区隔,我们可以知道可以透过dl-item提取一个一个的列表,既然知道我们要存储的位置在 dl-item下,我们就可以把dl-item下的结构拓展出来,我们接下来就可以根据不同的标签取得不同的内容,我们把一个个的dl-item列出来
(二)爬虫撰写
import requests
from bs4 import BeautifulSoup
response = requests.get('http://www.yicai.com/data/')
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text,'html.parser')
for news in soup.select('.dl-item'):
print(news.select('h3'))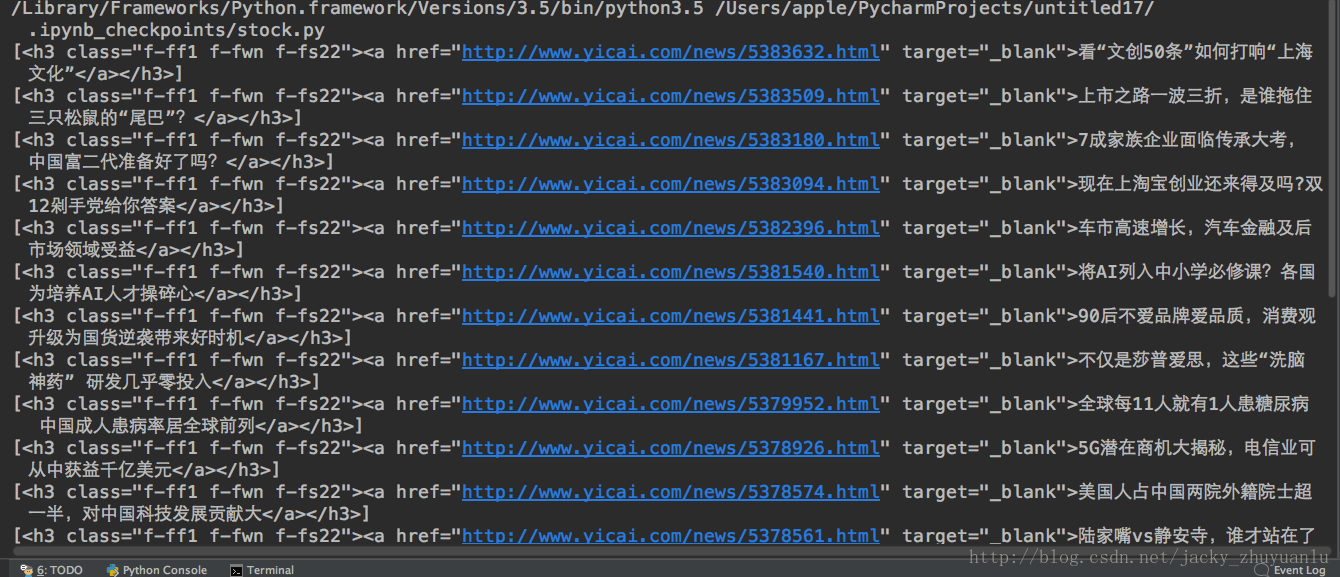
- 去掉要抓取内容中的中括号[0]
for news in soup.select('.dl-item'):
print(news.select('h3')[0])- 取得里面的文字内容
for news in soup.select('.dl-item'):
print(news.select('h3')[0].text)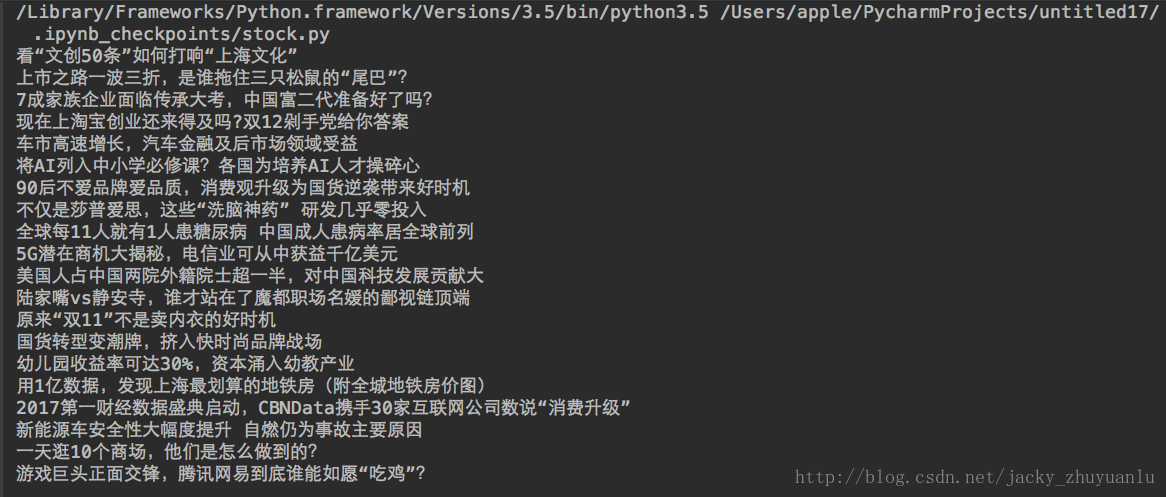
- 抓取a 下的链接,发布来源及发布时间
for news in soup.select('.dl-item'):
h3 = news.select('h3')[0].text
a = news.select('a')[0]['href']
h4 =news.select('h4')[0].text
print(h4,h3,a)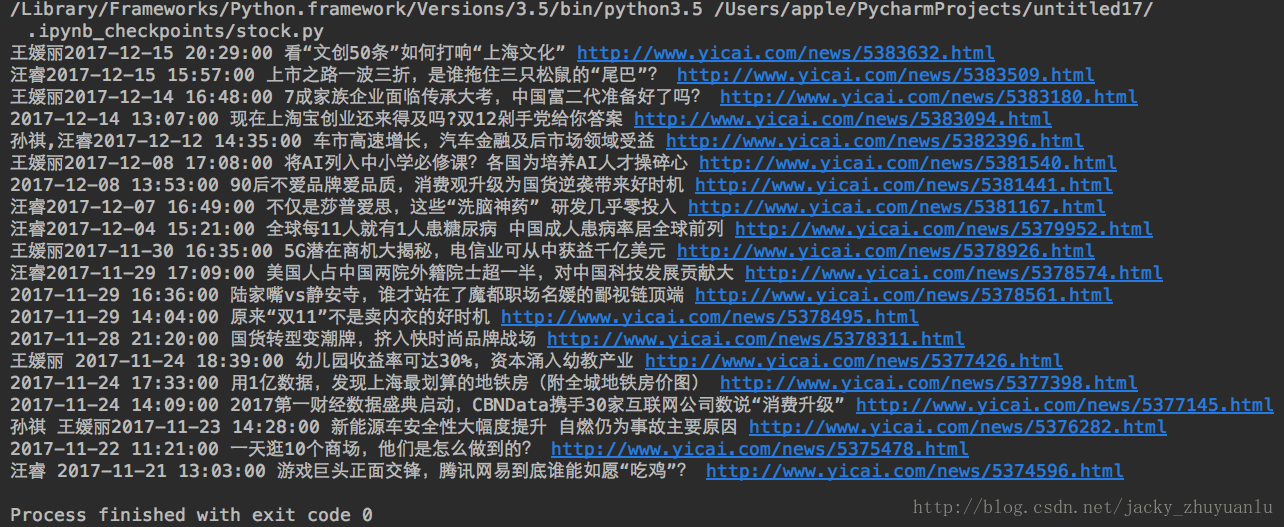

 浙公网安备 33010602011771号
浙公网安备 33010602011771号