01、Pandas基础
Pandas基础
概述:
Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
神器一DataFrame:
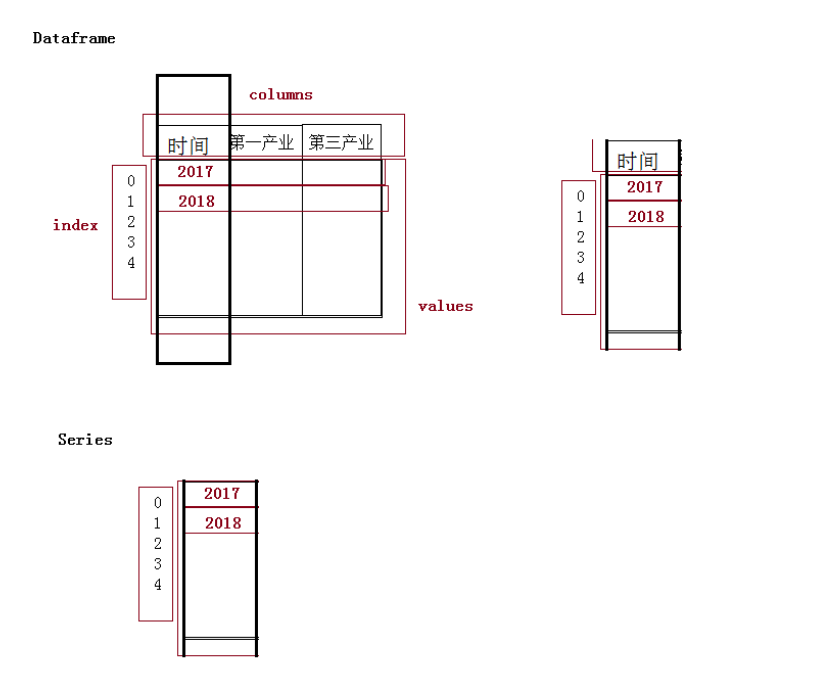
DataFrame是Pandas中的一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。
神器二Series:
Series它是一种类似于一维数组的对象,是由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象。
图示:
1.创建dataframe 第一种方法
# 构建dataframe
columns = ['时间', '第一产业', '第三产业']
values = [[2017, 1089, 890], [2018, 2131, 4321], [2019, 2133, 3421]]
index = [0, 1, 2]
# 创建dataframe
df = pd.DataFrame(columns=columns, data=values, index=index)
print(df)
# 执行结果
时间 第一产业 第三产业
0 2017 1089 890
1 2018 2131 4321
2 2019 2133 3421
2.创建dataframe 第二种方法
data = {'时间': [2017, 2018, 2019], '第二产业': [3211, 4123, 4121], '第三产业': [4321, 2313, 1232]}
index = ['a', 'b', 'c']
df2 = pd.DataFrame(data=data,index=index)
print(df2)
# 执行结果
时间 第二产业 第三产业
a 2017 3211 4321
b 2018 4123 2313
c 2019 4121 1232
3.创建series:没有列索引,一维
data = [1000, 1001, 1200, 1300]
index = ['a', 'b', 'c', 'd']
ser1 = pd.Series(data, index=index)
print(ser1)
dataframe属性:
| 属性 | 概述 |
|---|---|
| df.columns | 获取列属性 |
| df.index | 行属性 |
| values | 元素 |
| dtypes | 元素类型 |
| shape | 表的结构 |
| size | 元素个数 |
| ndim | 维度 |

