2PC 3PC TCC等多种分布式事务解决方案分析对比
前言
本文分析多种分布式事务的解决方案2PC、3PC TCC、可靠消息服务、最大努力通知,事务消息等。讲述其执行流程、优缺点、适用场景以及引文具体实战例子。
名词解释
- TM(transaction manager) 事务协调者
- RM(resource manager) 资源管理者/事务参与者/业务服务
2PC(Two Phase Commit)
原理
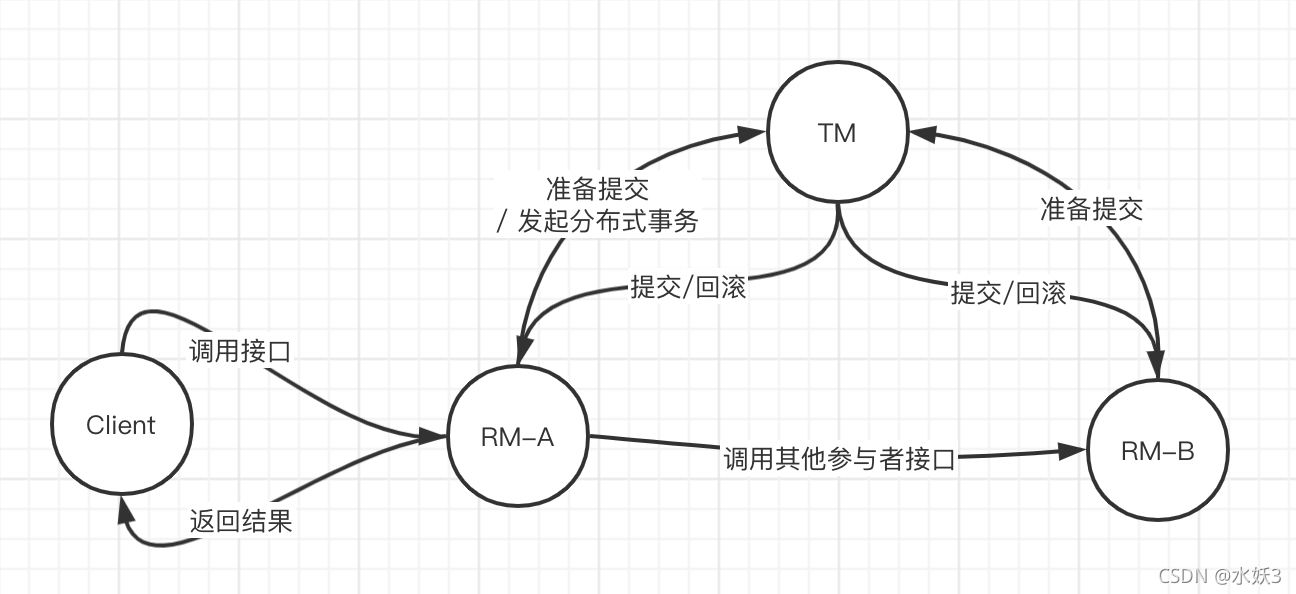
- 未加入分布式事务时,正常流程是 Client 调用 RM-A 接口开始事务,RM-A 调用 RM-B 后返回结果给 Client。如果 RM-B 异常自己本地事务可以回滚,RM-A 也可以回滚,因为它是调用方,可以捕获到远程调用的异常。
- 问题在于 RM-A 里在调用 RM-B 之后如果出错了,RM-A 本地事务可以回滚,但是 RM-B 回滚不了,因为对方已经提交。
- 2PC 加入了事务协调者服务 TM,参与者 RM 先执行本地事务但不提交,并通知 TM。如果都成功,再通知所有参与者提交,否则通知它们回滚。
特点
- 需要参与者本身支持事务操作,具有 ACID 特性,通过事务回滚操作,比如数据库。
- 准备提交阶段一般 RM 通过劫持与数据库的连接,先执行事务不提交,待 TM 通知后在执行提交操作。
- 缺点:
在准备提交阶段,正式提交前,RM 一直占用了资源比如线程,数据库连接。
在 TM 等待 RM 准备提交的反馈时,有 RM 宕机会一直等待。
如果 TM 在通知 RM 前宕机,则所有 RM 会一直等待。
实现
- Txlcn 框架的 lcn 方式就是参考这一方案实现的,实现见 分布式事务-TX-LCN。
- Seata 框架则进行了改进,参与者直接先提交,在 undo_log 记录回滚信息,如果都成功则删掉记录,否则根据 undo_log 记录回滚。这种方式解决了准备提交占用资源问题。实现见 分布式事务-Seata
3PC(Three Phase Commit)
原理
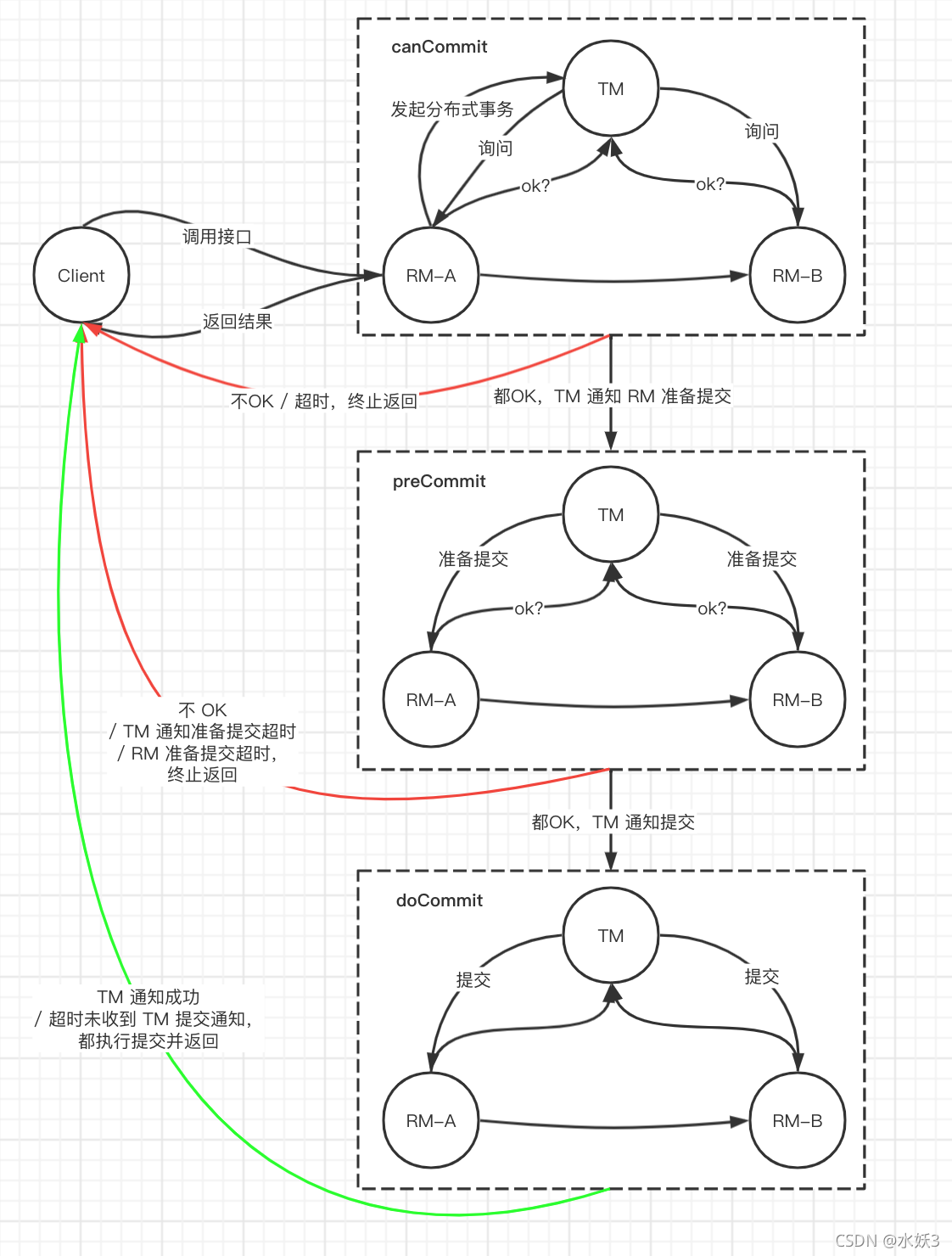
- 3PC 在 2PC 的基础上加入了询问(canCommit) 和超时机制,降低锁定资源概率,解决 TM/RM 宕机超时不响应导致等待问题。
- canCommit:TM 先询问参与者 RM 是否可以开始事务,RM 自我检测,判断、反馈是否具有开始事务条件。
- preCommit:TM 通知 RM 准备提交,RM 执行本地事务但不提交,并反馈给 TM。
- doCommit:TM 通知 RM 提交,RM 提交本地事务完成整个事务流程。到了这一阶段,TM 通知超时也提交事务。
特点
- 3PC 是在 2PC 基础上进行改进,同样要求事务参与者本身支持事务操作。准备提交阶段也会占用资源。
- 通过 canCommit 确认 RM 具备事务条件,提高事务成功率从而降低资源占用概率。
- 通过超时机制解决 TM / RM 宕机导致的等待问题。
TCC(Try Confirm Cancel)
原理
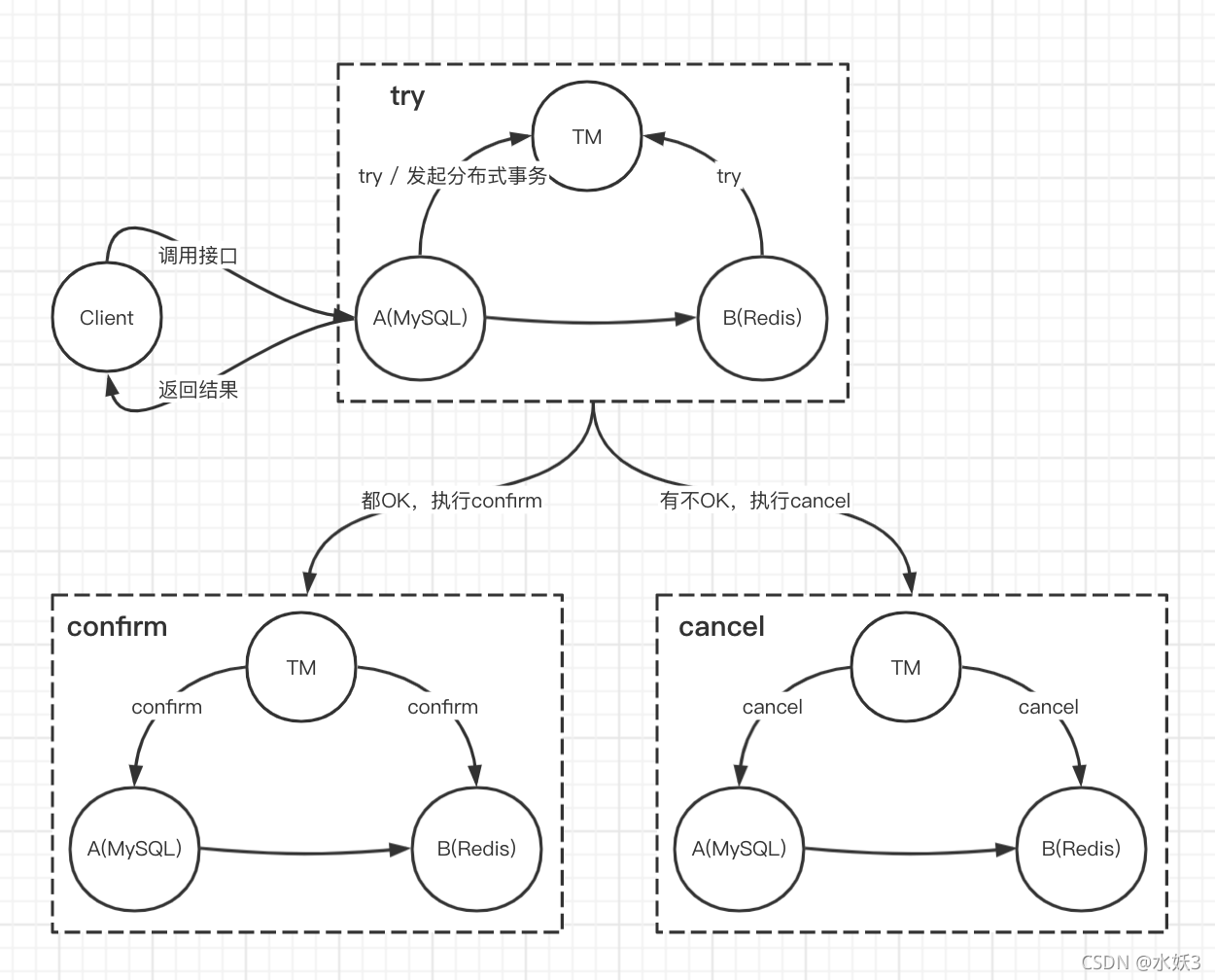
- 将整个事务分为 try confirm cancel 三部操作,都执行 try 成功则执行 confirm 返回,否则执行 cancel 逆操作回滚 try 的执行结果后返回。各个步骤本地事务直接提交。
- try 和 confirm 具体操作,可以根据情况而定,看后面扣款例子。
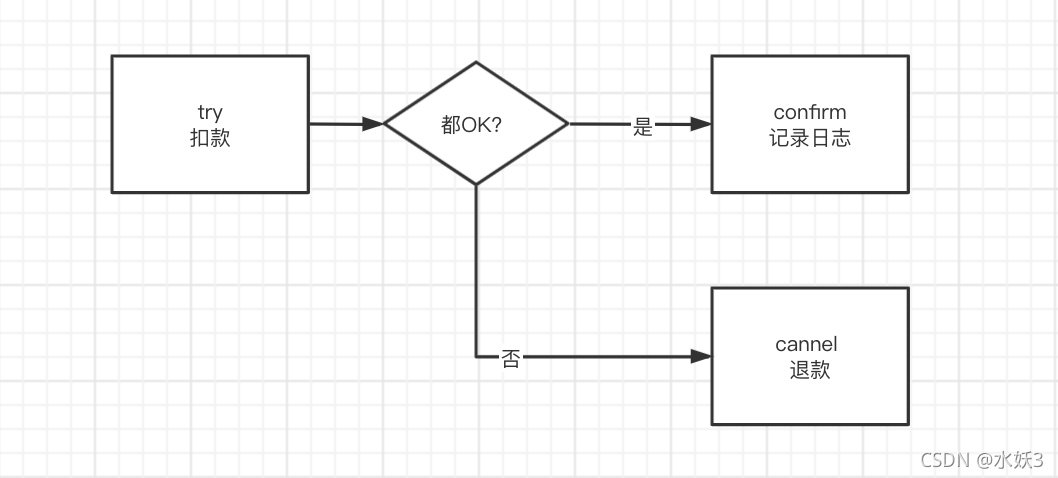
- 在 try 中执行扣款完整逻辑,如果整体失败 concel 将金额返还。一般的业务这样做可以,但是在事务失败的情况下,用户会看到金额先扣掉了,然后又退回来了,感觉会有点疑惑。后面另一种处理方式会更好一点。
- 在 try 中将金额扣除,写入到冻结资金中,这样展示给用户是冻结状态,成功则在 confirm 中真正扣除金额,而失败则在 cancel 中解冻金额。事务失败在 try cancel 之间展示给用户冻结状态,更为友好。
特点
- 对比 2PC 和 3PC 这种方式直接提交事务不需要一直占用资源。
- 通过 cancel 逆操作回滚,不要求参与者本身支持事务,适用混合了本身不支持事务的服务,比如 Redis
- 缺点是有中间状态,每个事务操作都必须写 3 个处理方法。
实现
见 分布式事务-TX-LCN 和 分布式事务-Seata。
可靠消息服务
原理
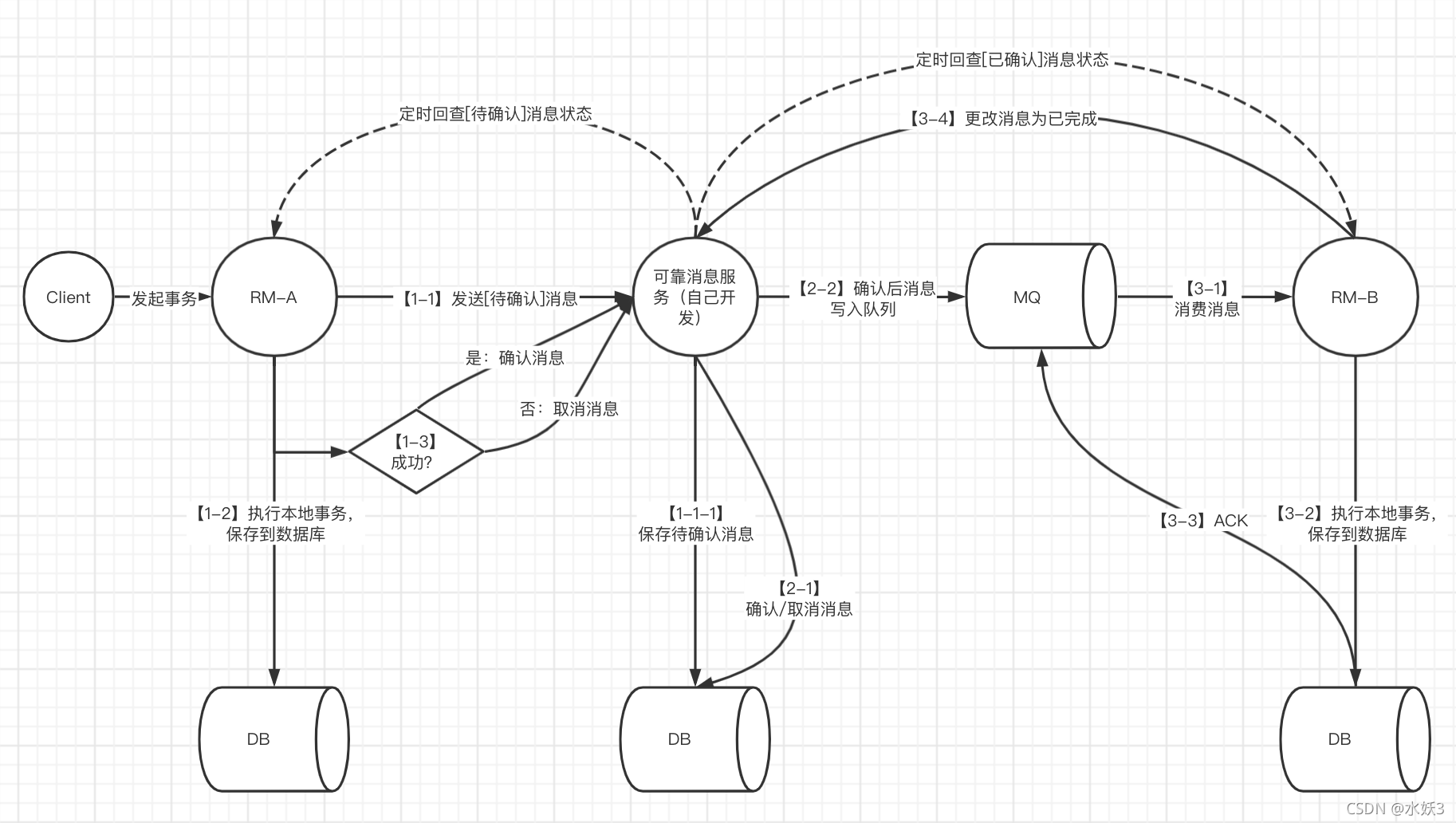
- 这种方式需要自己开发一个管理分布式事务状态的可靠消息服务,将事务分为待确认、已确认、已取消、已完成状态。
- 上游服务先发起事务,向可靠消息服务写入【待确认】事务消息;本地事务执行成功或者失败后请求可靠消息服务将事务消息更改成【已确认】或者【已取消】。
- 如果是【已确认】则可靠消息服务发送消息到消息队列,让下游服务消费。如果上游服务一直未修改【待确认】的消息状态,则定时向上游服务回查并修改。
- 下游服务则消费消息队列中的消息,成功则最终发送【已完成】给可靠消息服务,如果下游服务不反馈消息消费状态,可靠消息服务同样会向下游服务定时回查状态。
特点
- 各个事务参与者之间通过消息服务来保证消息最终一致性,达到了解耦的效果。
- 从单个事务参与者角度看,事务变简单了;整体看分布式事务更复杂,需要开发单独可靠消息服务
- 自己逻辑处理完就返回,比较适合高并发的场景。
- 下游服务更新不一定立即处理,需要业务能容忍这点,比如购买商品后增加积分这种就可以。
最大努力通知
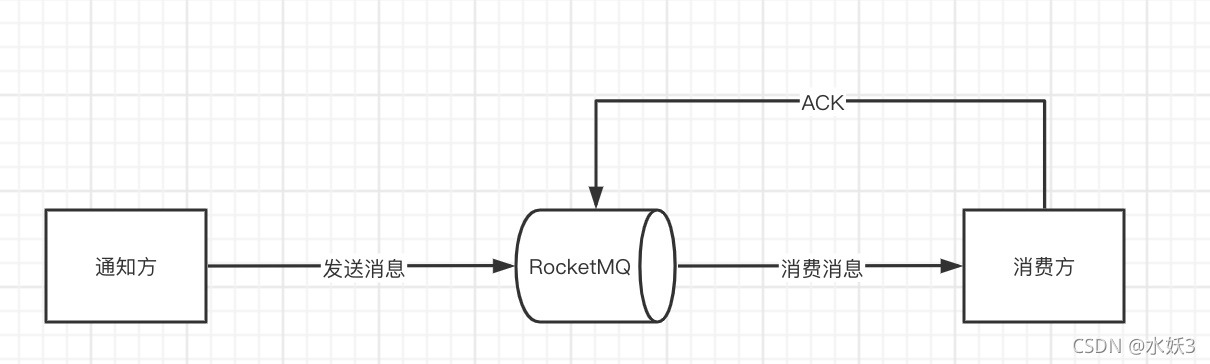
- 这种适合向下游推送消息的场景,比如支付服务通知其他服务支付状态。下游服务需要给上游服务确认消费反馈,否则上游服务会尽可能的重复推送,尽量确保下游服务收到。
- 比如 RocketMQ 可以配置未收到 ACK 逐步拉大重复推送的消息间隔 1min、5min、10min、30min、1h、2h、5h、10h,直到达到通知要求的时间窗口上限。
事务消息
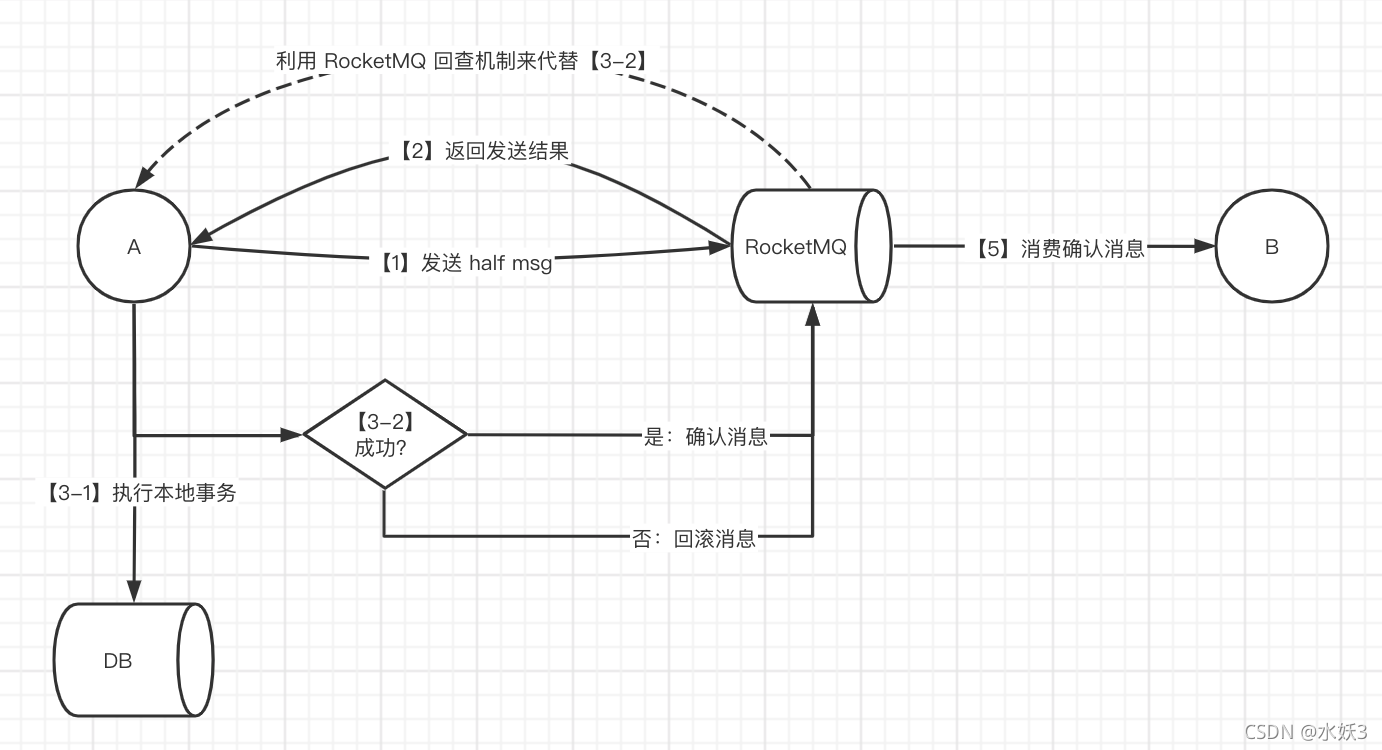
- 利用 RocketMQ 事务消息来实现分布式事务,执行本地事务前先向 RocketMQ 发送 haf msg,此时下游服务还消费不到,要向 RocketMQ 确认之后才可以被消费。
- 可以执行本地事务后主动通知 RocketMQ 确认/回滚消息,也可以利用回查机制,被动反馈。
总结
2PC、3PC、TCC 保证整个事务都完成后才会返回,用户需要等待,但是能得到最终结果。2PC、3PC 要求参与者自己具备事务功能,一般指操作数据库的服务。如果有参与者不具备事务功能,则 TCC 更合适,但是开发工作量会大些。
可靠消息服务、最大努力通知和事务消息适合高并发的场景。用户能很快得到反馈,它们保证最终一致性,但是整个时间相对长一点,需要考虑业务场景是否合适。一般在实时性要求不是那么强的场景,比如购物后,通知积分服务、推送物流通知等。
以上方案细究其实还有很多漏洞并未解决,但是没有银弹,这些方案基本足够了,其他极端情况可以采用鸵鸟算法,在极低概率下出现问题的时候再人工处理。一般 2PC、事务消息这种相对简单的方案反而用得更多。
