

ShardingSphereJDBC+MybatisPlus实现分库分表
前言
这篇是ShardingSphere-JDBC+Springboot+MybatisPlus+Druid分库分表的简单例子,我们用一个订单表为例,通过简单配置实现数据分片到多个数据库的多个表中。
主要配置和代码已经在文中给出,完整例子可以参考 GitHub - fruitbasket-litchi-shardingjdbc。
准备数据库
在一个或两个MySQL服务上创建两个数据库(order_database),执行下面的脚本创建三个订单表(t_order、t_order_0、t_order_1)。
- t_order只是为了MybatisPlus逆向生成CRUD代码(Mapper、Service和Controller),生成完代码可以删掉
- t_order_0和t_order_1是保存订单数据的两个分表
DROP TABLE IF EXISTS `t_order`;
CREATE TABLE `t_order` (
`order_id` bigint NOT NULL AUTO_INCREMENT,
`user_id` int NOT NULL,
`description` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
DROP TABLE IF EXISTS `t_order_0`;
CREATE TABLE `t_order_0` (
`order_id` bigint NOT NULL AUTO_INCREMENT,
`user_id` int NOT NULL,
`description` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB AUTO_INCREMENT=671005327373635585 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1` (
`order_id` bigint NOT NULL AUTO_INCREMENT,
`user_id` int NOT NULL,
`description` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB AUTO_INCREMENT=671005326614466562 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
引入Maven依赖
<properties>
<java.version>1.8</java.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spring-boot-dependencies.version>2.3.12.RELEASE</spring-boot-dependencies.version>
<shardingsphere.version>5.0.0</shardingsphere.version>
<mybatis-plus-boot-starter.version>3.4.3.4</mybatis-plus-boot-starter.version>
<lombok.version>1.18.22</lombok.version>
<mybatis-spring-boot-starter>2.2.0</mybatis-spring-boot-starter>
<druid.version>1.2.8</druid.version>
<mybatis-plus-generator.version>3.4.1</mybatis-plus-generator.version>
<freemarker.version>2.3.31</freemarker.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot-dependencies.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>${shardingsphere.version}</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus-boot-starter.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>${druid.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>${mybatis-plus-generator.version}</version>
</dependency>
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
<version>${freemarker.version}</version>
</dependency>
</dependencies>
Springboot配置文件
配置数据源,指定两个库(db0、db1)的数据源(druid)、地址和用户名密码等信息。
配置数据库和表的分片算法(sharding-algorithms),并指定分片算法表达式(algorithm-expression),给算法自定义别名(database-inline、t-order-inline)。表达式中(如:db$->{user_id % 2})的意思是数据库名字为db加上$->{user_id % 2}的结果,也就是user_id%2的结果(0或1),拼起来意思是根据user_id分散到数据库db0或db1中。表达式中$->{}也可以写成${},为了避免和SpringBoot配置冲突建议不写${}形式。
这里另外配置了主键生成器(key-generators),并为这个配置自定义别名(snowflake),生成类型为雪花算法(SNOWFLAKE)。
下面tables中的是对一个或多个表进行单独配置。
配置数据库策略(databaseStrategy),指定分片字段(shardingColumn)为user_id、分片算法名称(shardingAlgorithmName)为database-inline(上面自定义的别名)。
再往下配置表策略(tableStrategy)和主键生成策略(keyGenerateStrategy)也是一个意思,用上面定义的配置。
spring:
shardingsphere:
# 数据源
datasource:
names: db0,db1
db0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://mysql_node0:3306/order_database?characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: root
db1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://mysql_node1:3306/order_database?characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: root
rules:
sharding:
# 分片算法
sharding-algorithms:
# 数据库
database-inline:
type: INLINE
props:
algorithm-expression: db$->{user_id % 2}
# t-order表
t-order-inline:
type: INLINE
props:
algorithm-expression: t_order_$->{order_id % 2}
# 主键生成策略
key-generators:
snowflake:
type: SNOWFLAKE
props:
worker-id: 001
tables:
t_order:
actualDataNodes: db$->{0..1}.t_order_$->{0..1}
# 数据策略
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database-inline
# 表策略
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t-order-inline
# 主键策略
keyGenerateStrategy:
column: order_id
keyGeneratorName: snowflake
props:
sql-show: true
mybatis-plus:
mapper-locations: classpath*:mapper/*.xml
配置结果是添加的数据根据user_id%2确定分片的数据库(db0、db1)/(mysql_node0、mysql_node1),再根据order_id%2保存到分片的表中。也就意味着共有4个表来存储订单数据。
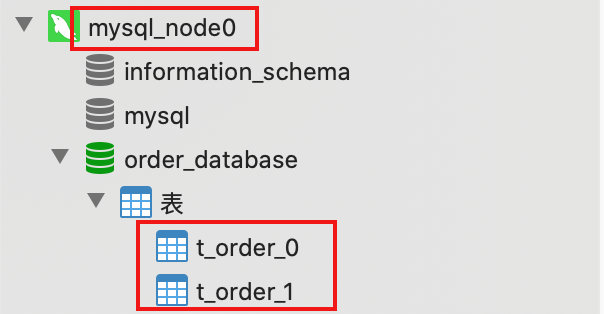
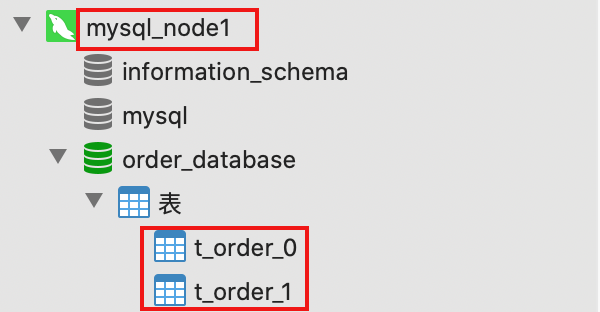
测试接口
这里提供了添加数据(add,http://localhost:8080/order/add)和列出数据(list,http://localhost:8080/order/list)两个接口。
package cn.fruitbasket.litchi.shrdingjdbc.controller;
import cn.fruitbasket.litchi.shrdingjdbc.entity.TOrder;
import cn.fruitbasket.litchi.shrdingjdbc.service.ITOrderService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.concurrent.ThreadLocalRandom;
import static java.util.stream.Collectors.toList;
@RestController
@RequestMapping("order")
public class TOrderController {
@Autowired
private ITOrderService itOrderService;
@GetMapping("add")
public String add() {
TOrder order = new TOrder()
.setUserId(ThreadLocalRandom.current().nextInt(0, Integer.MAX_VALUE))
.setDescription("测试订单");
itOrderService.save(order);
return order.toString();
}
@GetMapping("list")
public String list() {
return itOrderService.list().stream()
.map(tOrder -> tOrder.toString() + "<br>").collect(toList()).toString();
}
}
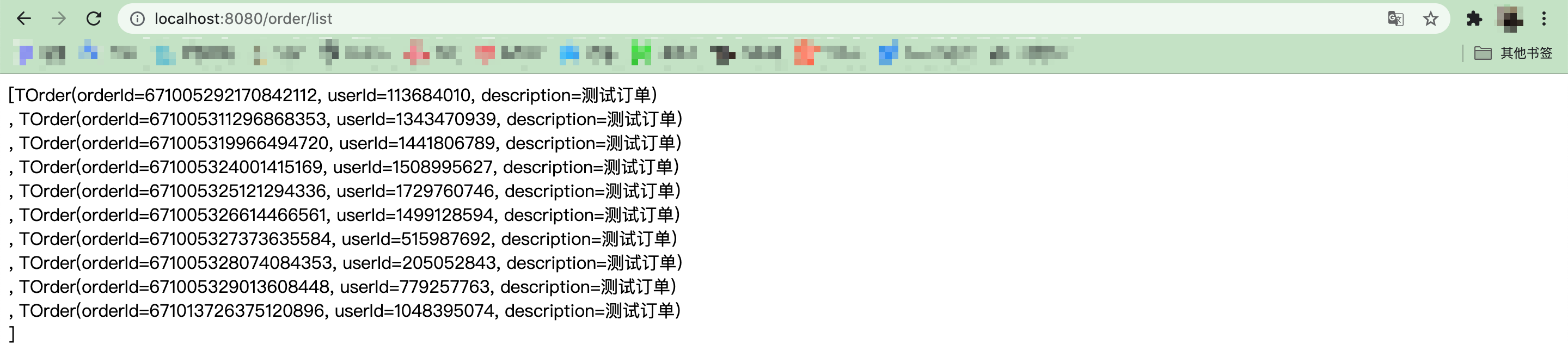
测试
通过浏览器GET方式访问接口,查看数据库可以看到数据分散到了不同表中。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY