MySQL数据库InnoDB锁详解
前言
本篇主要是对MySQL锁的实现的分析和总结。中间很长一段是各种查询情况下的加锁分析,并搭配了完整的脚本和图例,有兴趣可以按文章内步骤验证,其实总结下来内容并不太多,耐心看完一起消除MySQL锁原理的迷雾。
锁分类
下面对InnoDB的锁从不同的角度进行分类,每种锁模式(lock mode)都有一个对应的英文代号。锁定的周期是一个事务的开始(begin)和提交(commit)。
共享锁和排他锁
从锁属性的角度,可以分为排他锁(exclusion lock)和共享锁(share lock):
排它锁(X):修改一行记录的时候,防止别人同时进行修改。
我们想象N个人往同一张纸上写文章来类比排他锁这个概念。大家写的文章肯定要各自独立,不然穿插在一起没法看了,为了保证这一点,我们弄了唯一一个凭证,大家一起来抢,只有抢到这个凭证的人才能去纸上写文章,有人在写的时候,其他人就得等着,等人家写完了把凭证还回来再重新去抢这个凭证。
总结下来是多个线程(N个人)修改数据同一数据时(往同一张纸上写文章)时,为了保证并发数据安全,要求线程抢到了锁(写文章的凭证)才能修改,未抢到锁的线程需要等待持锁的线程释放锁(还会凭证)后重新争夺。
共享锁(S):读取一行记录的时候,防止别人修改。
基于上面的想象,我们再考虑一个需求,现在有N个人想看这些写的文章了。因为看文章和写文章是两回事,于是我们单独弄了一种不限量的看文章的凭证,每个想看的人拿到这个凭证后才能查看。
看文章是不会改变纸上内容的,所以看文章的人之间不用限制,随便看。
但是为了保证每个人看到内容是完整的,我们就得限制一下,等人家写完了才能去看;
反过来人家在看的时候不能去改纸上的内容,不然边看边改看到的内容又不完整了。
总结下来是,持有共享锁的N个线程互相不需要等待,可以并行查询数据;有线程持有共享锁时,要获取排它锁的线程需要等待所有共享锁释放;有线程持有排他锁时,要获取共享锁的线程需要等待。这思路其实和JDK的读写锁(ReentrantReadWriteLock)一样。
下面排它锁和共享锁并发情况下等待的情况,互斥代表需要等待其他锁释放:
| X | S | |
|---|---|---|
| X | 互斥 | 互斥 |
| S | 互斥 | 不互斥 |
但是是否要加锁其实是业务线程自己决定的,就好像上面看文章和写文章的人自己决定要不要遵守这个规则,不遵守规则结果会导致数据混乱。
InnoDB默认情况下对增删改SQL执行加锁行为,对于查询语句,需要自行在末尾增加关键字来实现排它锁(FOR UPDATE)和共享锁(LOCK IN SHARE MODE)。
表级锁和行级锁
按照锁的粒度可以将MySQL锁分为表级锁和行级锁。锁的粒度越小,对资源锁定的范围越小,并发度越高,性能越高。锁粒度越大,刚好相反。
咱接着上面想象的场景,由于有锁存在,同时只能有一个人在纸上写文章,这一天下来挨个写产出肯定很低。其实很多人想写在纸上位置完全不一样,根本不会混在一起。为了提高效率,把纸撕成N份,各自在不同的部分写,如果写的是相同的部分才需要争夺凭证,读也是分开读。这就是锁粒度由粗(一张纸)到细(分成N份)、表锁和行锁的区别。
- 表级锁有意向锁(I)和自增锁两种类型,作用含义如下
意向锁加上锁属性又可以分成意向排他锁(IX)和意向共享锁(IS)。作用可以参考这篇 掘金-MySql InnoDB 中意向锁的作用。
自增锁是对自增字段所采用的特殊表级锁。
本文主要针对行级锁,所以这部分略过。
- 行级锁有以下三种
记录锁(locks rec but not gap):对指定索引条件加锁;
间隙锁(gap):对索引值往小的方向的间隙加锁,比如有两个索引值10和20,针对20的间隙锁范围是10 < gap < 20;
临建锁:记录锁+间隙锁,也就是锁定某一行记录的索引,以及索引之后到下个索引之前的间隙。
通过测试分析各种情况下MySQL如何加锁
到这我们通过命令行登陆MySQL数据库,来分析下可重复读和读已提交隔离级别下,各种情况下MySQL是如何加锁的。后面看起来内容很多,其实看过几种情况找到加锁规律,会觉得简单到不行,下面开始测试前的准备。
- 先登录数据库
# 登陆数据库
mysql -u root -p
- 打开锁信息开关,我们就可以通过命令行看加锁具体信息。
# 打开输出锁信息开关
set global innodb_status_output_locks = 1;
# 查询锁信息开关
show variables like '%innodb_status_output_locks%';
开关打开前后查看开关状态。


- 通过下面查看InnoDB状态信息,Transaction这一栏是锁详细信息。
show engine innodb status\G;

- 创建、使用测试库
# 创建测试库lock_test
create database lock_test;
# 使用测试库
use lock_test;
# 关闭自动提交,在未提交事务前锁不会释放,我们就可以长时间查看
set autocommit = 0;

- 关于聚簇索引的前置知识
InnoDB一定会建立一个聚餐索引,按主键(primary key)、唯一索引(Unique key)优先级来选定,如果都没有,则会内部建立一个6字节的rowId作为聚簇索引。
- 锁关键信息解释
lock_mode X后面没任何其他信息,代表默认的临建锁。
lock_mode X locks rec but not gap从locks rec but not gap翻译过来可理解为锁住记录但是排除间隙,等于简单的记录锁。
locks gap代表间隙锁。
可重复读(REPEATABLE-READ)
可重复读隔离级别加锁情况复杂度比读已提交隔离级别要高很多,因为MySQL会使用间隙锁来避免幻读问题。下面一起来看下各种情况下加锁情况吧。
无显示主键,无索引
# 创建无任何索引表t
create table t ( id int default null, name char ( 20 ) default null );
# 写入语句
insert into t values ( 10, '10' ),( 20, '20' ),( 30, '30' );
# 提交事务
commit;

- 开始事务,然后我们通过不加条件的查询语句后加上排它锁(FOR UPDATE)看看加锁信息
begin;
select * from t for update;
show engine innodb status\G;

lock mode IX代表给申请了意向排他锁,这个不是我们关注重点可以忽略。
第二行GEN_CLUST_INDEX锁定的是聚簇索引,lock_mode X代表锁具有排他属性,后面没其他信息也就代表默认的临建锁;还有个特殊的地方是supremum代表锁定最大索引之后的所有间隙。
后续列出了针对我们插入每一条记录建立的锁,他们都附带lock_mode X属性,代表默认使用临建锁。
这里我们用数学中的范围表示区间来展示锁区间:(-∞, 10],(10, 20], (20, 30],(30, +∞)
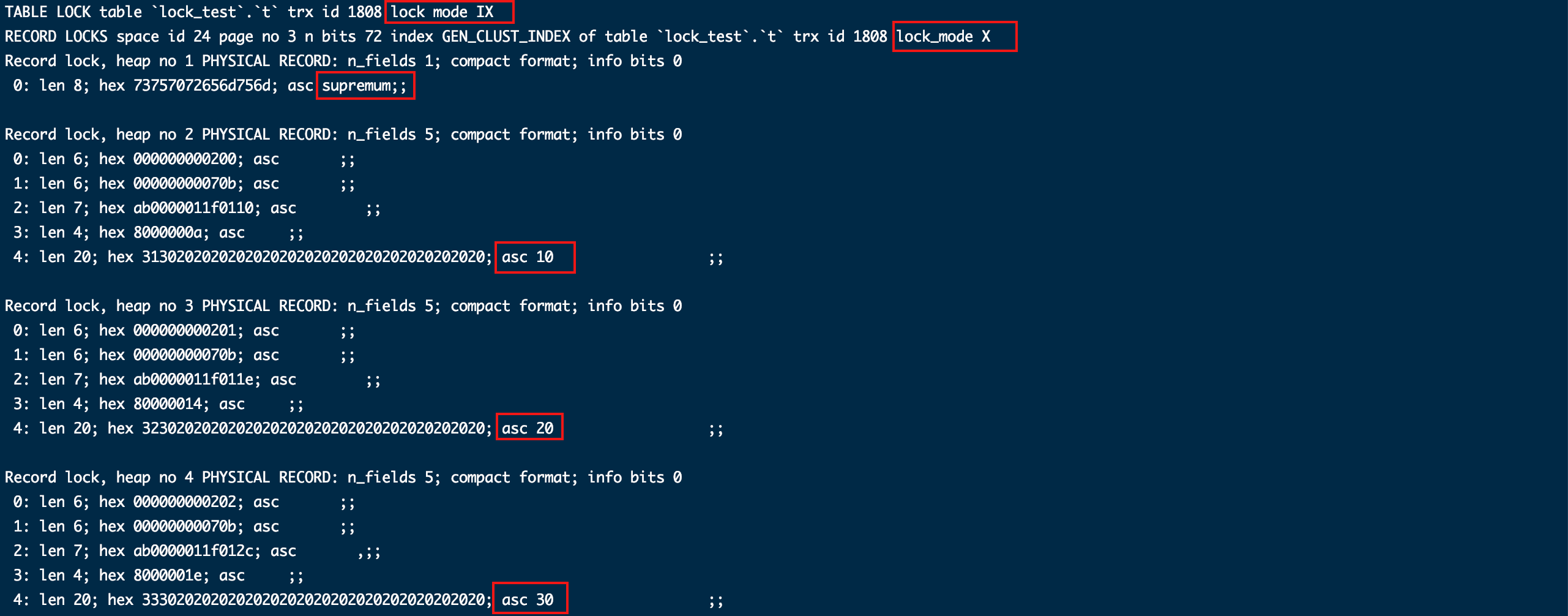
简单来说,锁覆盖了整个表,在未提交事务的情况下我们另起一个窗口登陆MySQL来执行一条插入语句,会发现写不进去最后超时了。
insert into t values ( 31, '31' );

在插入等待锁的过程中我们通过第一个窗口再次执行语句查看锁状态,可以看到插入语句也是在申请排他临建锁(lock_mode X),由于被占用只能等待。
show engine innodb status\G;
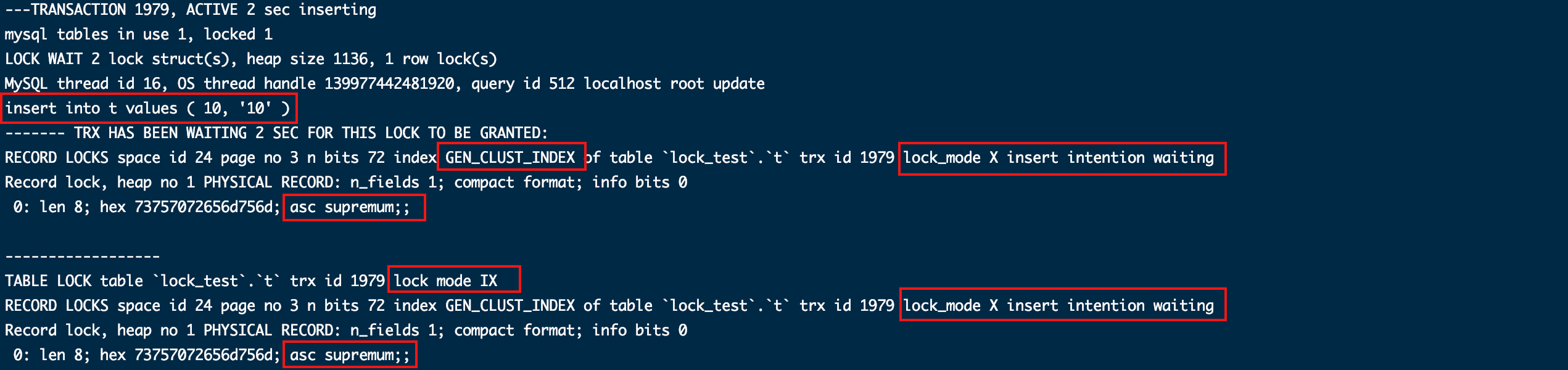
因为无条件的查询范围是全表,为了防止幻读问题(比如:开启一个事务先查全表发现有3行记录,其他线程刚好在查询之后插入一条,在之后事务里面再查询一次,发现结果变成了4条,就像产生了幻觉一样)加锁范围就必须覆盖全表,当然这不是表锁,是行级锁,只是效果相当于表锁了。
我们提交两个 窗口的事务接着往下看。
commit;
- 加非索引条件(id = 10)
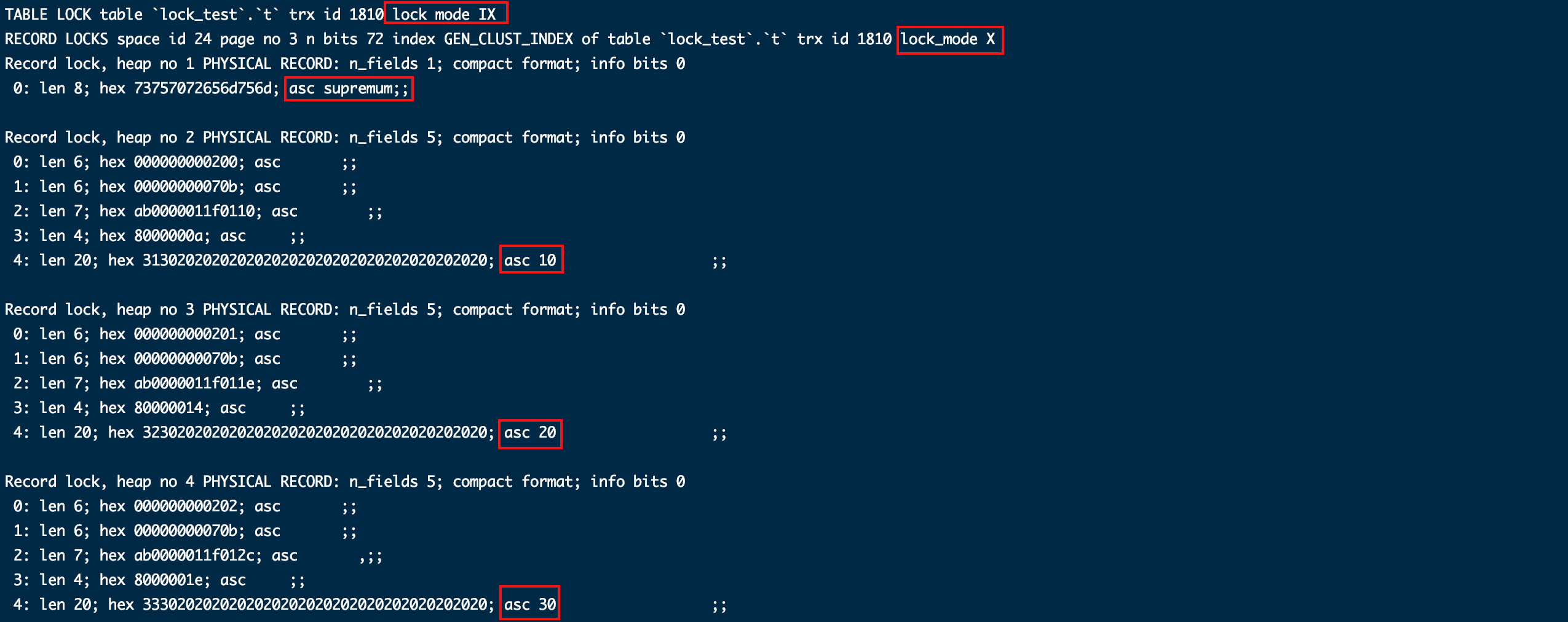
会发现加锁情况和上面一模一样,也许你会疑惑,指定条件了锁符合条件的就行了,还覆盖全表干啥?
这个问题还是从解决幻读的角度去考虑,假如只锁住id=10这一行,在事务内先查询得到1条记录,之后其他线程再插入一条id=10的记录,事务内再次查询就查出两条,蛋疼的幻读出现了,所以唯有覆盖全表的锁才能避免。
记住 “间隙锁是为了避免幻读的问题” 这结论,可重复读加锁看起来复杂就是因为避免幻读加了间隙锁。
begin;
select * from t where id = 10 for update;
show engine innodb status\G;
commit;
有显示主键,无索引
# 创建有主键为id的表t2
create table t2 ( id int primary key not null, name char ( 20 ) default null );
insert into t2 values ( 10, '10' ),( 20, '20' ),( 30, '30' );
commit;
- 无条件查询
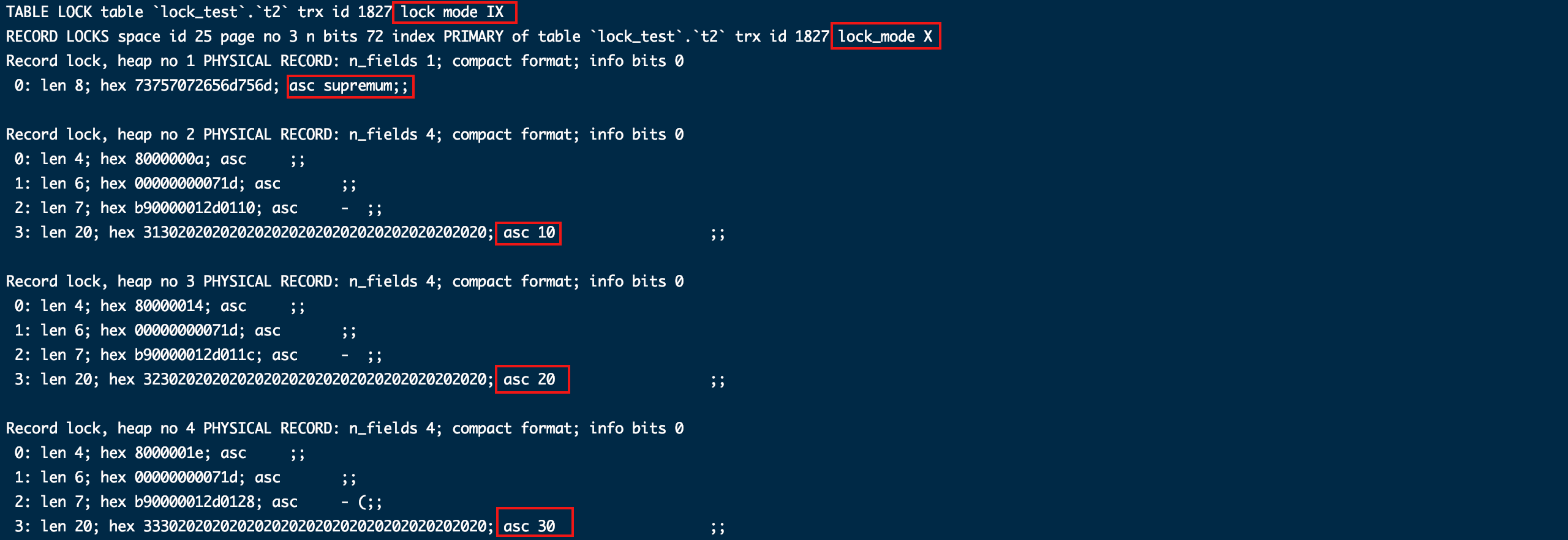
这种情况锁的范围也是临建锁+最大索引往后到正无穷大区间,也就是全表了。理由还是一样,查询范围是全表,为了避免幻读锁就必须覆盖全表。
begin;
select * from t2 for update;
show engine innodb status\G;
commit;
- 加主键索引条件(id = 10)
这次终于不一样了,lock_mode X本应该是默认的临建锁,但是后面加了几个新词(locks rec but not gap),翻译过来是锁定记录但是没有间隙,这就相当于简单的记录锁了,而且通过PRIMARY可以看出锁对象是主键,有主键时,主键就是聚簇索引。
因为根据id = 10可以确定查询的记录行,主键具有唯一属性,不可能再插入其他id = 10的记录,锁定这一行就可以避免幻读问题了。
begin;
select * from t2 where id = 10 for update;
show engine innodb status\G;
commit;

- 加唯一索引条件(id = 10)和非索引条件(name = '10')
这种情况也只是锁定主键值为10的聚簇索引,id = 10已经限制了范围,虽然加了name条件,也只是在前面结果中再进行过滤而已,针对前面条件上锁就可以解决问题了。
还有种更好的理解方式 “行级锁是针对索引的,非索引列对加锁无影响”。因为name不是索引列,所以只对主键上了锁,因为通过主键条件能确定查询的记录,所以只对相应记录加锁。
begin;
select * from t2 where id = 10 and name = '10' for update;
show engine innodb status\G;
commit;

- 弄个or条件看看(id = 10 or name = '10')
begin;
select * from t2 where id = 10 or name = '10' for update;
show engine innodb status\G;
explain select * from t2 where id = 10 or name = '10' for update;
commit;
这次好像完蛋了,锁回到开始那种覆盖全表的状态,为啥???行级锁是针对索引的,可查询条件明明有用到主键索引,为啥?
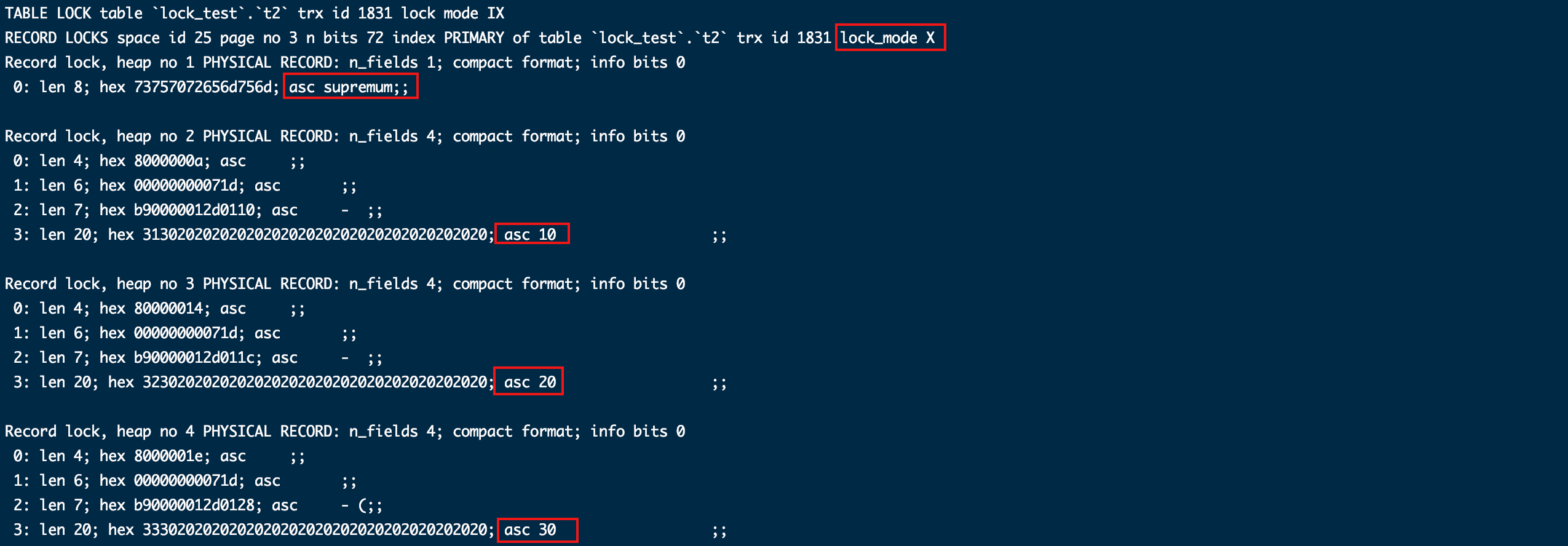
再补充一句结论 “只对实际使用到的索引加锁”,通过语句分析(explain)会发现语句使用的索引为NULL,因为or条件导致索引失效了。合并这俩结论,它是简单推导加锁结果的钥匙,我们往下看。

无显示主键,有索引
# 创建只有普通索引id的表
create table t3 ( id int default null, name char ( 20 ) default null ,key idx_id(id));
insert into t3 values ( 10, '10' ),( 20, '20' ),( 30, '30' );
commit;
- 无条件查询
锁覆盖全表了,这个应该好理解,但是用 “只对实际使用到的索引加锁” 来解释好像有点不通,因为全表扫描没用到索引也加锁了,并且,从GEN_CLUST_INDEX看锁的是聚簇索引,那我们再完善下结论 “只对实际使用到的索引加锁,未使用到索引则锁定聚簇索引,范围是全表”
begin;
select * from t3 for update;
show engine innodb status\G;
commit;
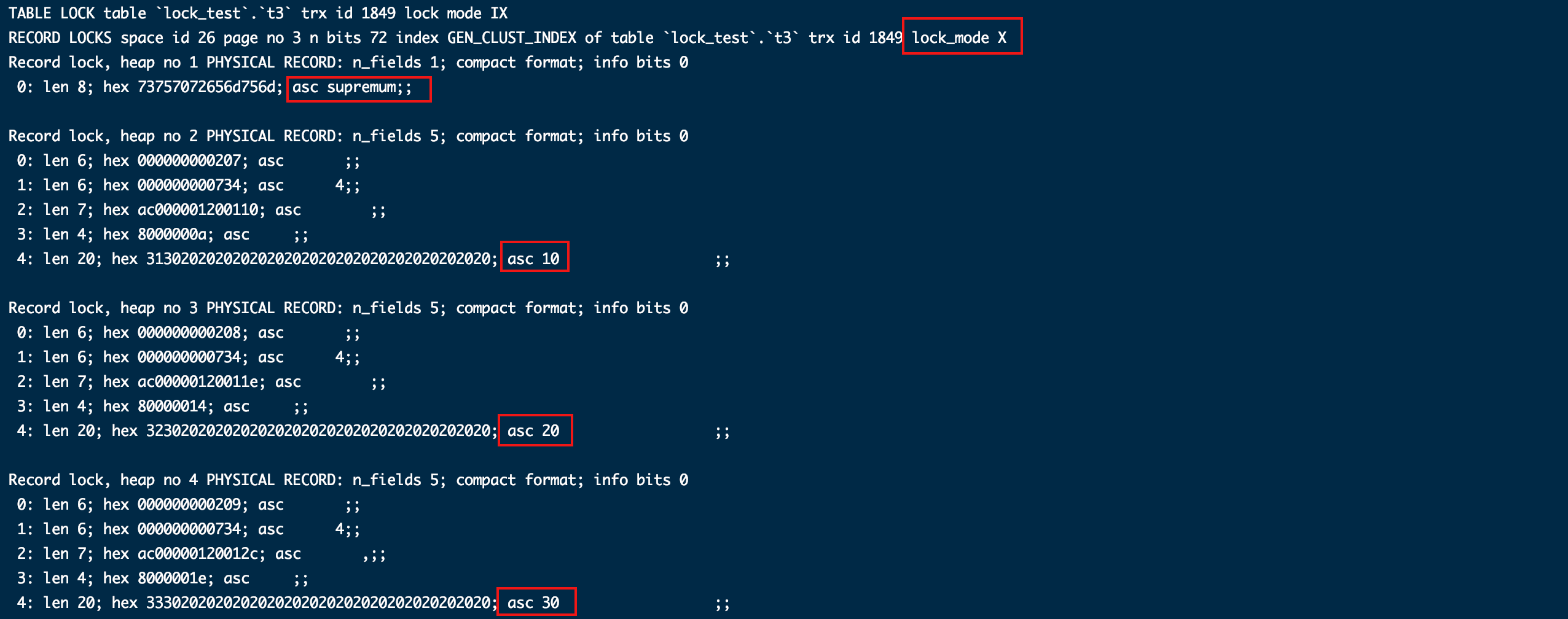
- 加普通索引条件(id = 10)
begin;
select * from t3 where id = 10 for update;
show engine innodb status\G;
这次情况不一样了,但是别慌,结论在这里进一步完善。
首先解释下加锁情况,第一段可以看出对索引idx_id加了临建锁(-∞, 10],这个原因好理解,因为这个索引不是唯一的,事务执行过程中其他线程是可以插入相同值为10的记录,从而导致幻读问题。本应该加覆盖全表的临建锁,但是从最后一段可以看出对索引idx_id加了间隙锁(locks gap),并且是10到20之间(before rec),范围等于(10, 20)。因为10之后有20这条记录,20以及以后的范围并不会对查询条件为10的语句造成幻读问题。所以加个10到20的间隙锁够了,细粒度锁并发度更高。
假如没有20这条记录,那后面间隙锁就得扩大到下个记录30之前,如果没有30这条记录,那就得到正无穷大了。
从这里可以看出锁的建立跟表的数据是有直接关系的,其实哪怕从之前全表范围的索引也可以看出来,虽然是全表,那也是根据表数据有关系的。
再看中间这段GEN_CLUST_INDEX和lock_mode X locks rec but not gap代表给聚簇索(GEN_CLUST_INDEX 代表聚簇索引)引加了简单的记录锁(locks rec but not gap)索引记录当然是id = 10这一行。
综合以上,我们总结出 “有用到索引,会对索引加锁外,还会对聚簇索引加记录锁”。
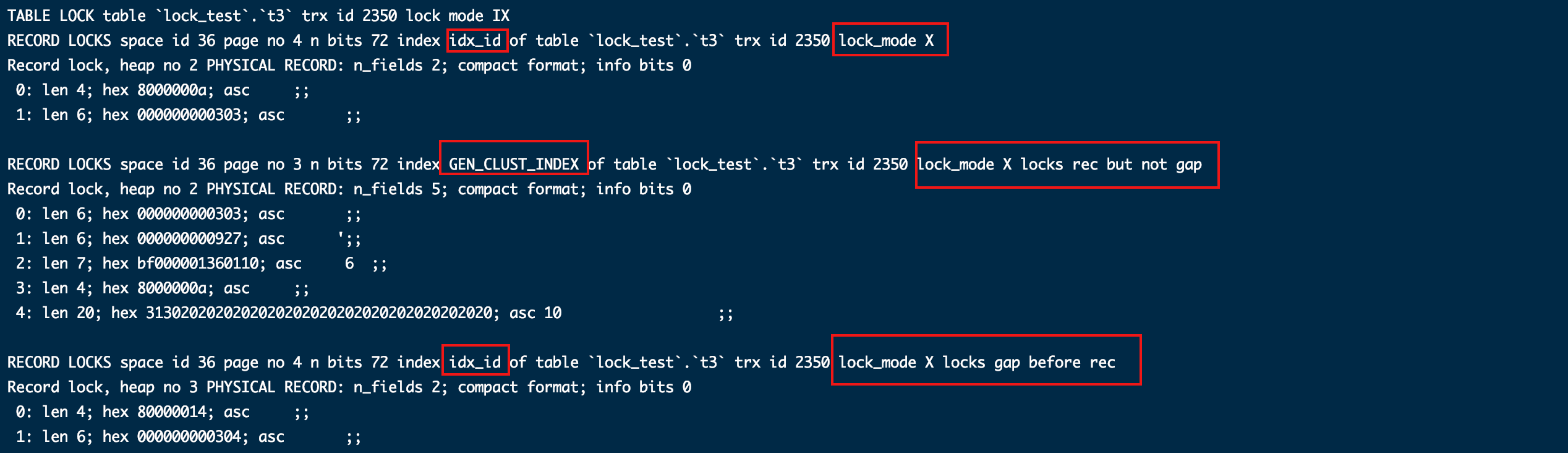
我们在未提交事务的情况下,另开窗口插入数据。
insert into t3 values ( 19, '19' );
insert into t3 values ( 20, '20' );
可以看到在锁范围内的19超时,在锁范围外的20成功了,验证了以上加锁的解释。

别忘记提交两个窗口的事务再继续。
commit;
无显示主键,有唯一索引
# 创建唯一主键为id的表
create table t4 ( id int default null, name char ( 20 ) default null, unique key uk_id ( id ) );
insert into t4 values ( 10, '10' ),( 20, '20' ),( 30, '30' );
commit;
- 无条件查询
begin;
select * from t4 for update;
show engine innodb status\G;
commit;
这不用想锁聚簇索引,范围是全表了,没用到索引嘛。
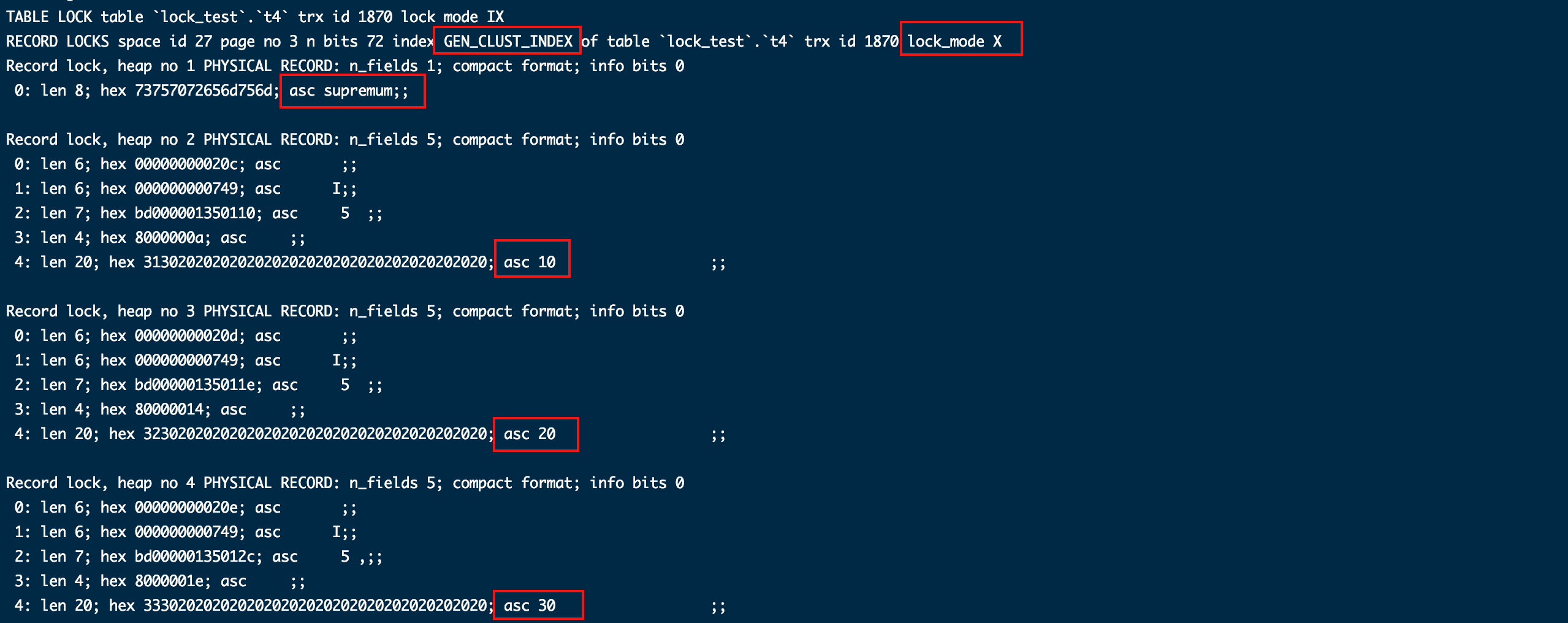
- 加唯一索引条件(id = 10)
begin;
select * from t4 where id = 10 for update;
show engine innodb status\G;
commit;
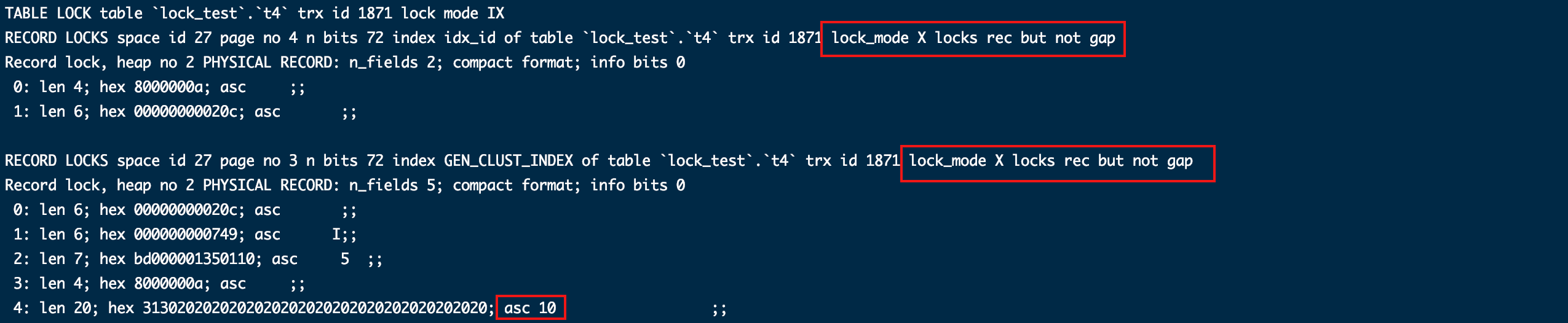
从第一段可以看出对idx_id加了记录锁,只锁定这一行索引,因为索引是唯一的,不可能有插入相同数据导致幻读的情况。
从后面一段GEN_CLUST_INDEX和lock_mode X locks rec but not gap,可以看出给聚簇索引加了记录锁。其实这个聚簇索引就是唯一索引,因为没有主键则优先用为索引列作聚簇索引。
这里可以总结出 “当使用有唯一特性的索引时只需要加记录锁”。
有显示主键,有索引
# 创建id为主键,name为普通索引的表
create table t5 ( id int not null, name char ( 20 ) default null ,primary key(id),key idx_name(name));
insert into t5 values ( 10, '10' ),( 20, '20' ),( 30, '30' );
commit;
- 无条件查询
begin;
select * from t5 for update;
show engine innodb status\G;
commit;
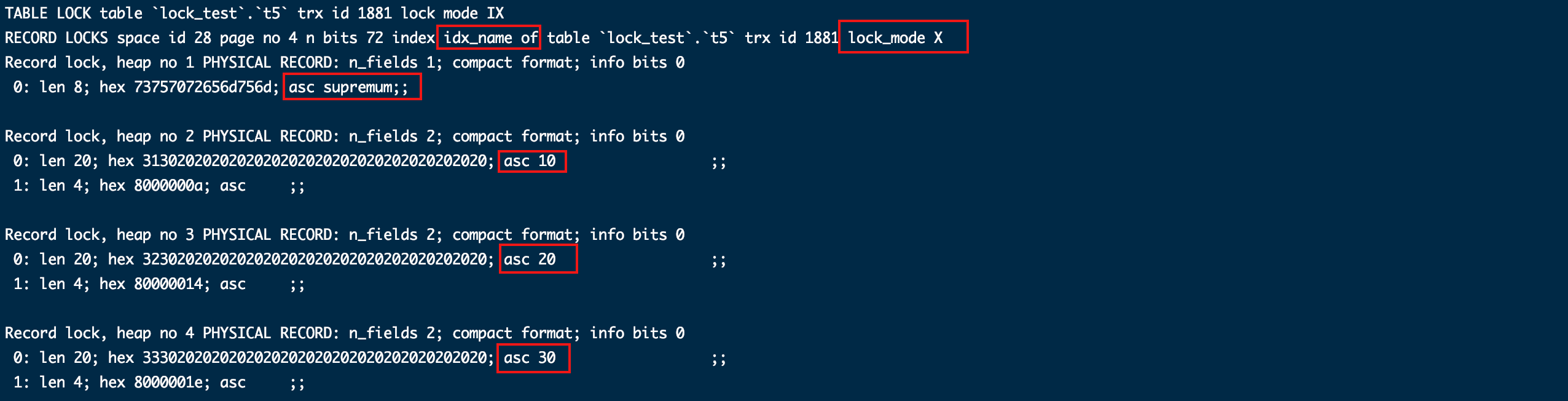
这次虽然大不一样但是又一样。根据之前的经验可以推断出这种情况下肯定会加覆盖全表的锁,只不过这种情况下加在了普通索引idx_name上,并且给主键索引加了行锁。
- 加普通索引条件(name = '10')
begin;
select * from t5 where name = '10' for update;
show engine innodb status\G;
commit;
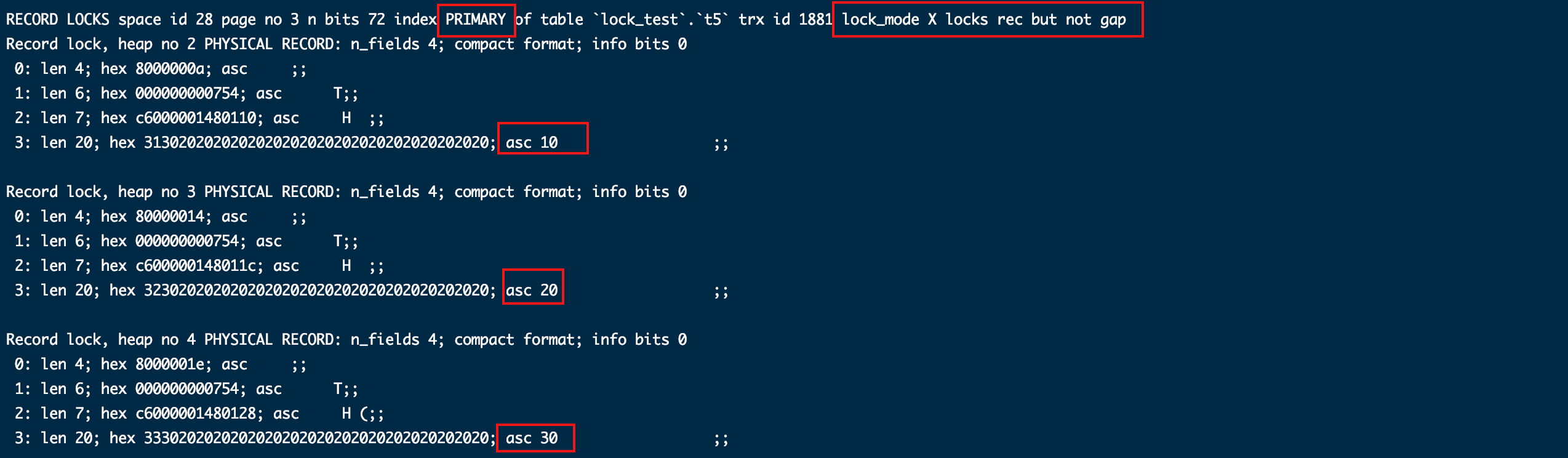
给idx_name索引加了临建锁和间隙锁:
idx_name、lock_mode X和asc 10代表针对idx_name等于10这个索引加了临建锁,范围是(-∞,10];
idx_name、lock_mode X locks gap和asc 20代表针对idx_name等于20加了间隙锁,范围是(10, 20)。
PRIMARY、lock_mode X locks rec but not gap和asc 10代表给主键索引等于10加了行锁。
- 加唯一索引条件(id = 10)
begin;
select * from t5 where id = 10 for update;
show engine innodb status\G;
commit;
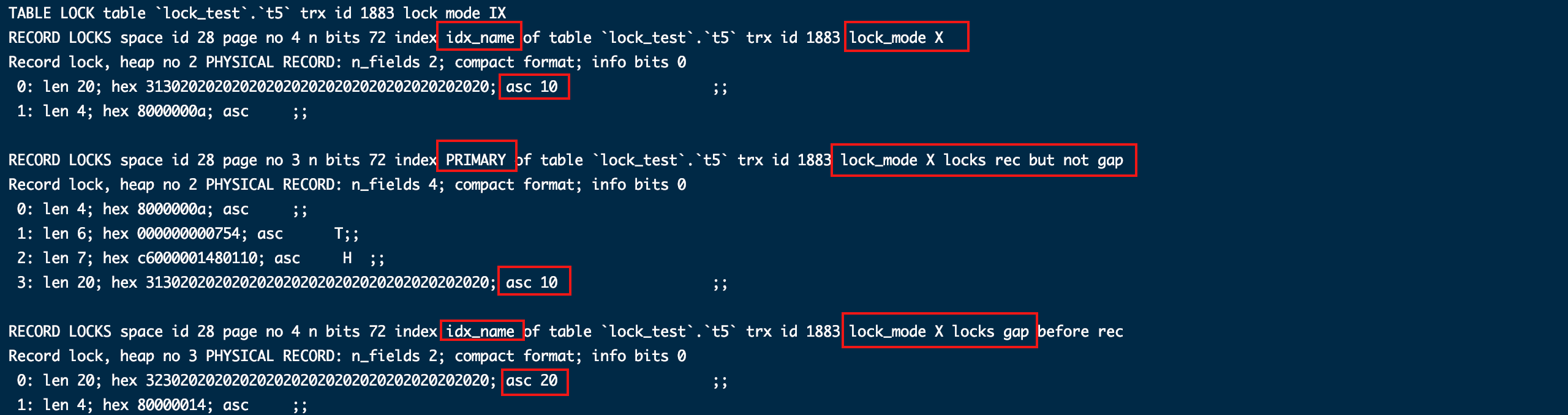
只给主键索引加了行锁。

- 加唯一索引条件(id = 10)和普通索引条件(name = '10')
begin;
select * from t5 where id = 10 and name = '10' for update;
show engine innodb status\G;
commit;
只加了主键列的行锁,因为能确定唯一列。

有显示主键,有唯一索引
create table t6 ( id int not null, name char ( 20 ) default null, primary key ( id ),unique key idx_name(name));
insert into t6 values ( 10, '10' ),( 20, '20' ),( 30, '30' );
commit;
- 无条件查询
begin;
select * from t6 for update;
show engine innodb status\G;
commit;
给唯一索引idx_name加了覆盖全表锁,给主键id加了行锁。
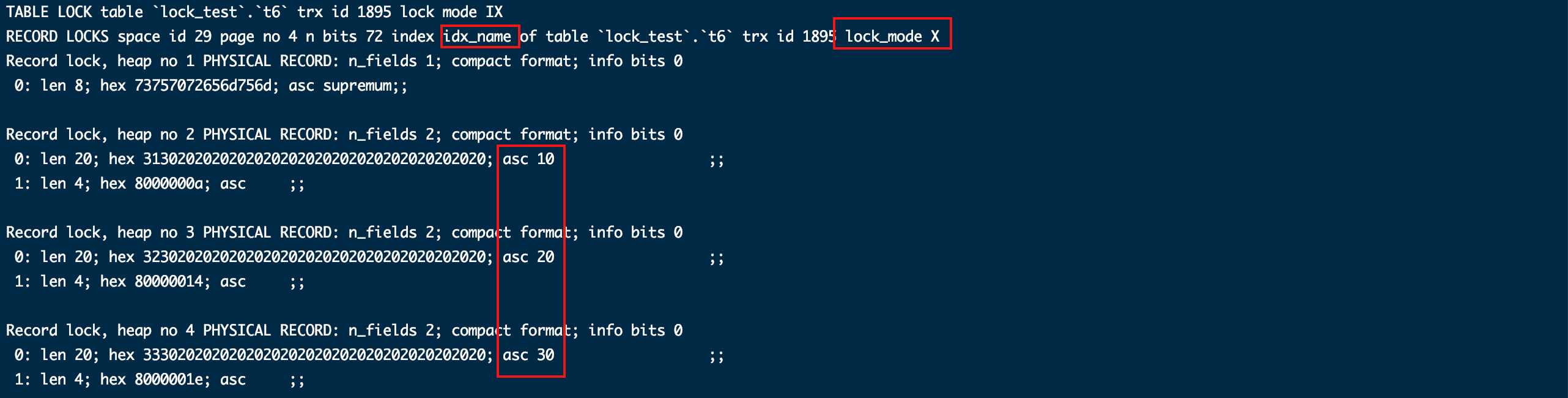
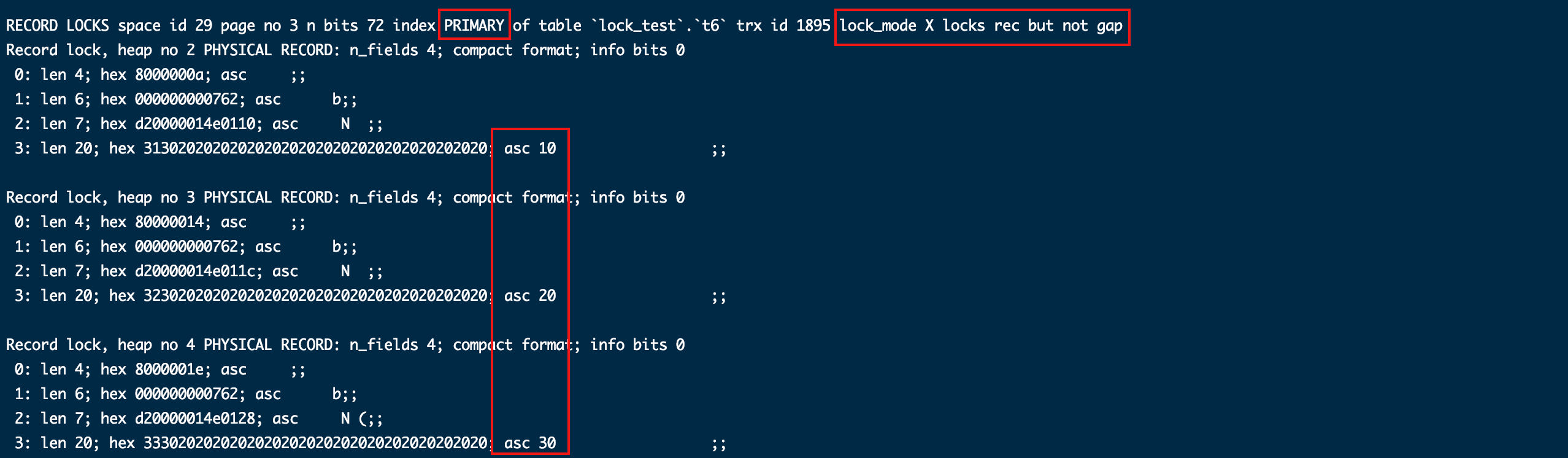
- 加唯一索引条件(name = '10')
begin;
select * from t6 where name = '10' for update;
show engine innodb status\G;
commit;
对唯一索引和主键加了行锁。

- 加主键索引条件(id = 10)
begin;
select * from t6 where id = 10 for update;
show engine innodb status\G;
commit;
只对加了主键行锁。

- 加主键索引条件(id = 10)和唯一索引条件(name = '10')
begin;
select * from t6 where id = 10 and name = '10' for update;
show engine innodb status\G;
explain select * from t6 where id = 10 and name = '10' for update;
commit;
只加了主键行锁,因为从执行分析看,只用到了主键。


读已提交(READ-COMMITTED)
读已提交隔离级别不会解决幻读问题,所以加锁方式都是行锁,非常简单。
# 将当前连接事务隔离级别设置为读已提交
set session transaction isolation level read committed;
# 提交事务
commit;
# 查看当前连接事务隔离级别
select @@transaction_isolation;
表无显示主键和索引
create table t7 ( id int default null, name char ( 20 ) default null );
insert into t7 values ( 10, '10' ),( 20, '20' ),( 30, '30' );
commit;
- 无条件查询
begin;
select * from t7 for update;
show engine innodb status\G;
commit;
针对聚簇索引给所有查出的列加了记录锁。
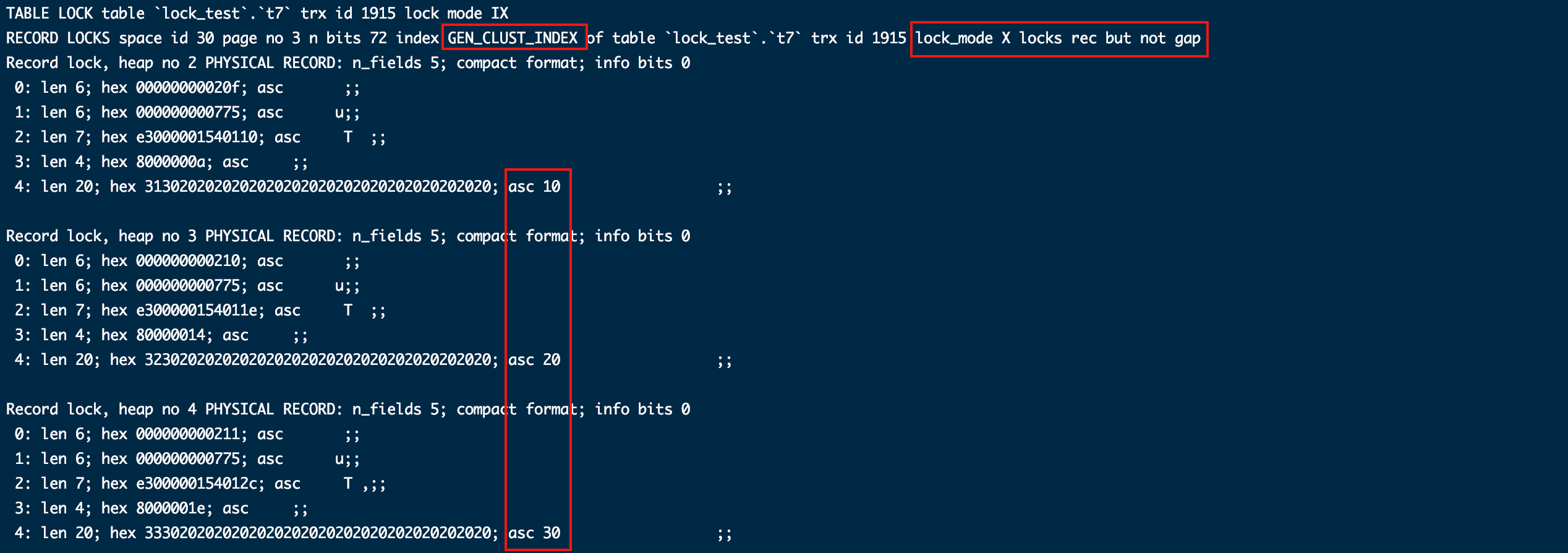
- 加非索引列条件
begin;
select * from t7 where id = 10 for update;
show engine innodb status\G;
commit;
针对聚簇索引给查出的唯一列加了记录锁。

表有显示主键无索引
create table t8 ( id int primary key not null, name char ( 20 ) default null );
insert into t8 values ( 10, '10' ),( 20, '20' ),( 30, '30' );
commit;
- 无条件查询
begin;
select * from t8 for update;
show engine innodb status\G;
commit;
针对主键索引给所有查出的列加了记录锁。
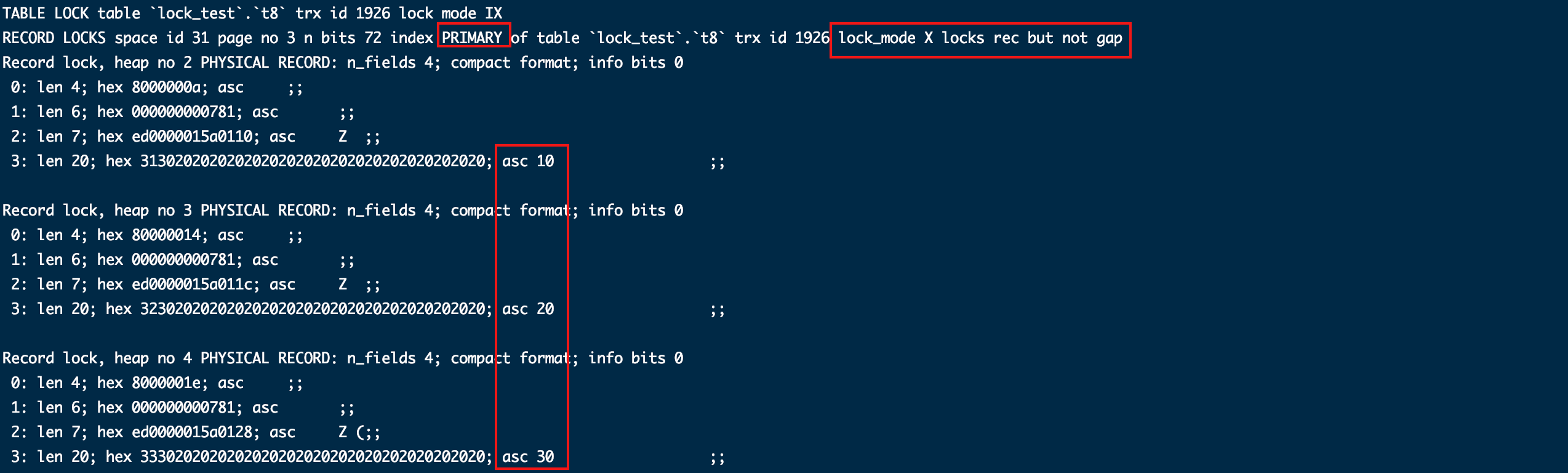
- 加主键索引条件(id = 10)
begin;
select * from t8 where id = 10 for update;
show engine innodb status\G;
commit;
针对主键索引给查出的唯一列加记录锁。

表无显示主键有索引
create table t9 ( id int default null, name char ( 20 ) default null, key idx_id ( id ) );
insert into t9 values ( 10, '10' ),( 20, '20' ),( 30, '30' );
commit;
- 无条件查询
begin;
select * from t9 for update;
show engine innodb status\G;
commit;
针对聚簇索引给查出的所有列加记录锁。
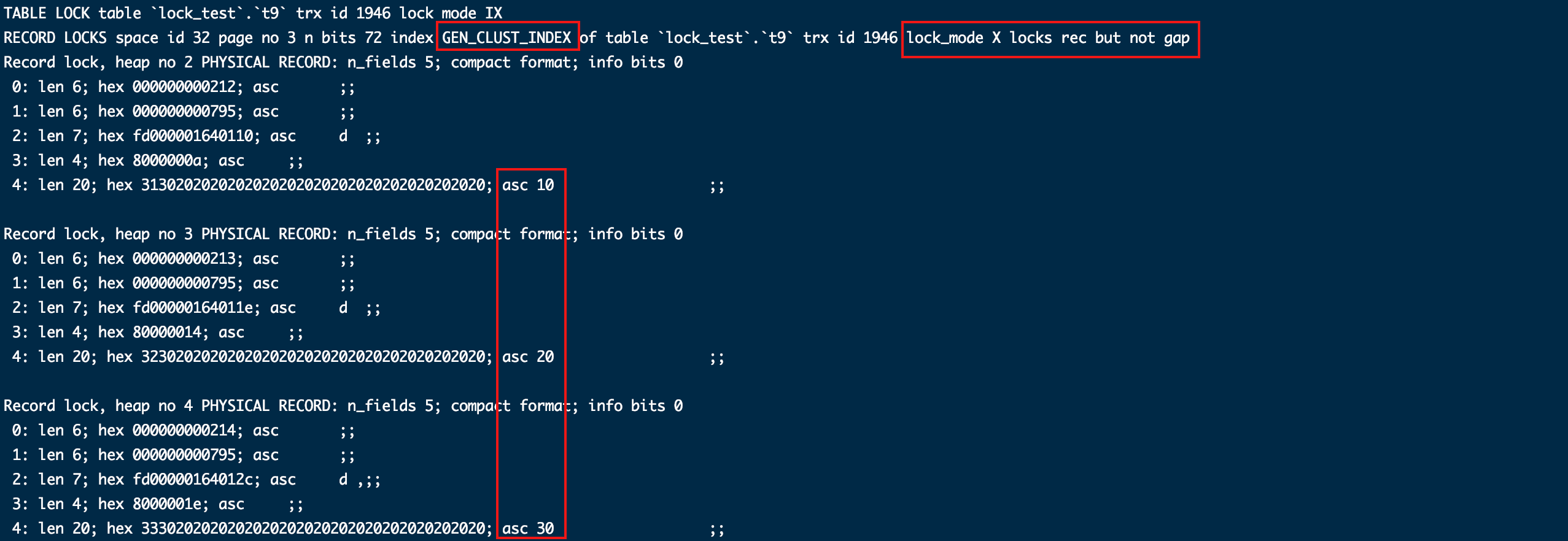
- 加普通索引条件(id = 10)
begin;
select * from t9 where id = 90 for update;
show engine innodb status\G;
commit;
针对普通索引和唯一索引给查出的唯一列加了记录锁。

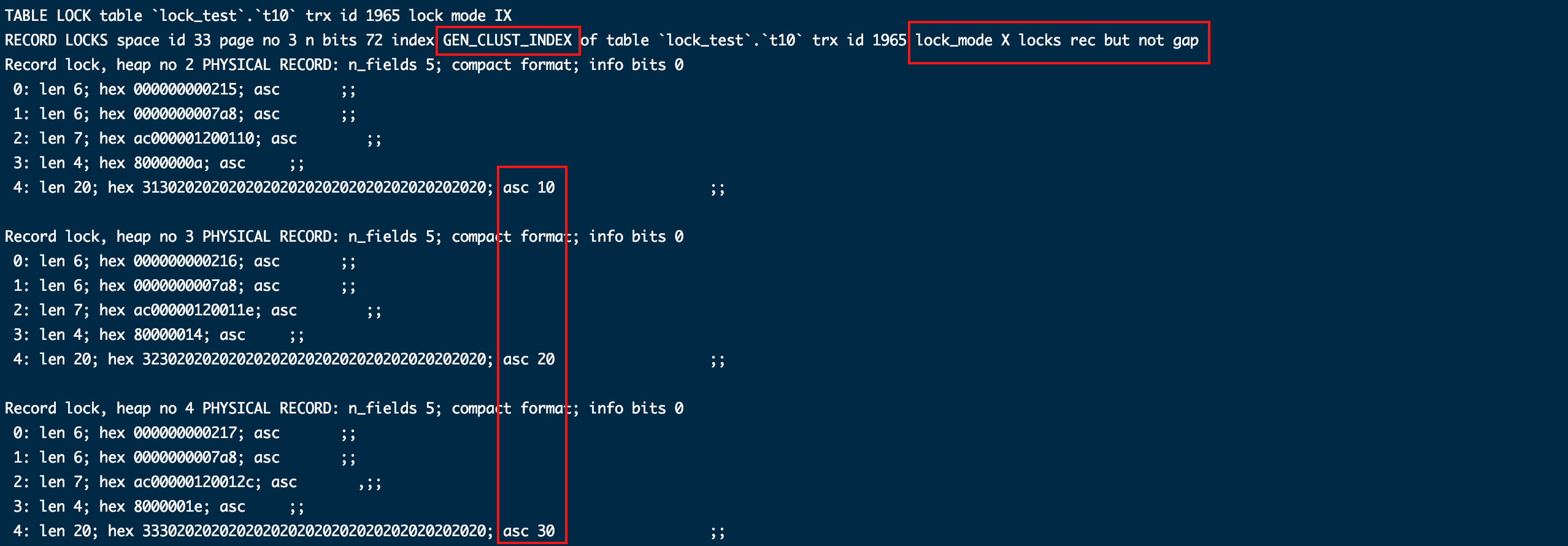
表无显示主键,有唯一索引
create table t10 ( id int default null, name char ( 20 ) default null, unique key uk_id ( id ) );
insert into t10 values ( 10, '10' ),( 20, '20' ),( 30, '30' );
commit;
- 无条件查询
begin;
select * from t10 for update;
show engine innodb status\G;
commit;
因为当前只有10、20、30三条数据,只针对聚簇索引给key为这3个值加了行锁。
不过有个奇怪的地方,有主键应该显示加锁索引是PRIMARY,而不是GEN_CLUST_INDEX。虽然有主键情况下主键就是聚簇索引。
其他情况
其他情况没必要再挨个查看了,结果都是行锁。
加锁情况总结
可重复读
-
可重复读隔离级别利用锁可以解决幻读问题,解决的方式是在记录锁的基础上加上间隙锁,这也是这种隔离级别下加锁情况较为复杂的原因
-
针对索引加锁,并且是语句使用到的所有索引,非索引列对加锁无影响
-
索引的建立和当前表的数据是有直接关系的,哪怕是覆盖全表的锁,也是根据表记录分段创建组合实现
-
索引具有唯一属性,就只加记录锁,否则加临建锁(记录锁+间隙锁)
-
不管有没有使用到索引,最终都会给聚簇索引加锁;
有用到索引时,聚簇索引就只加记录锁;
没有用到索引时,如果没有普通索引会给聚簇索引加覆盖全表的锁(临建锁+到正无穷大的间隙锁);有普通索引就给普通索引加覆盖全表的锁,给聚簇索引加记录锁
读已提交
-
读已提交隔离级别无法解决幻读问题,只会根据查询条件添加上行锁,比较简单。
-
锁建立跟表数据/查询到的数据有直接关系,查询一个不存在的列是不会加锁

 浙公网安备 33010602011771号
浙公网安备 33010602011771号