Kafka消息与索引详解
前言
以kafka_2.13-2.8.0为例,分析Kafka消息在磁盘上的存储结构、配置以及如何通过索引找到具体的消息数据。
分区目录
一个分区(Partition)有1到多个副本(Replica),是主从结构,主(Leader)负责处理读写请求,从(Follower)只负责同步数据并在主宕机的时候顶替主实现高可用。
在Kafka数据目录下存放着各分区目录(Partition),名称格式为 topic-partitionNo,如test-0代表名为test的Topic的0号分区。分区目录下存放消息的文件。
分段日志和索引
Kafka的消息是分段(Segment)存储在文件里的,当达到配置指定的条件就会创建新的分段文件。
每个分段都都对应消息日志(.log),偏移量索引(.index)和时间索引(.timeindex)三个文件,文件名为起始偏移量(Offset),代表这个文件第一条消息的偏移量值。

以下是日志分段和索引创建的配置项,详情见 Apache Kafka Broker 配置。除了log.index.interval.bytes只影响单个索引的创建时机,其他配置都会触发日志分段。
| 配置项 | 默认值 | 单位 | 描述 |
|---|---|---|---|
| log.roll.ms | null | 毫秒 | 新日志段滚出的最大时间。如果未设置,则使用log.roll.hours中的值 |
| log.roll.hours | 168 | 小时 | 新日志段滚出的最大时间,从属于log.roll.ms属性 |
| log.segment.bytes | 1073741824(1G) | B | 单个日志文件的最大大小 |
| log.index.size.max.bytes | 10485760(1MB) | B | 偏移索引的最大字节数 |
| log.index.interval.bytes | 4096(4 KB) | B | 将一个项添加到偏移索引中的间隔 |
消息具体结构
消息日志与索引关系
Kafka数据最终都会保持在磁盘上,对于消息有三个关键的文件消息日志(.log),偏移量索引(.index)和时间索引(.timeindex)。
消息日志保存的是消息的原数据,接收到的生产者(Producer)的消息会以追加的方式顺序写到这个文件中,顺序写效率远高于随机写,减轻了磁盘寻址压力。这是Kafka使用磁盘做存储却能保证高性能的原因之一。
每个消息都会有一个自增的偏移量值,从0开始,每条消息都递增这个值,所以偏移量代表即将到来的下一条消息的偏移量值。
Kafka中索引有偏移量索引和时间索引两种。它没有为每一条消息建立索引,那样索引文件会太过于庞大,而是分段建立,所以一个索引只能指明消息所在位置的范围,最终要在这个范围遍历查找。
时间索引指向的是偏移量索引,偏移量索引指向了消息日志二进制位置。通过时间戳或者偏移量最终都可以定位到消息的具体位置。
可以通过配置参数 log.index.interval.bytes控制两个索引间隔的字节数,超过这个大小就建立新索引。这个值越小,索引越密集,查询快但是文件体积大。
消息日志(.log)
通过消息日志(.log)可以看到每条消息具体的内容。
# 只输出消息日志描述信息
kafka-dump-log.sh --files /var/kafka-logs/test-0/00000000000000023147.log
# 输出消息日志完整信息
kafka-dump-log.sh --files /var/kafka-logs/test-0/00000000000000023147.log --print-data-log
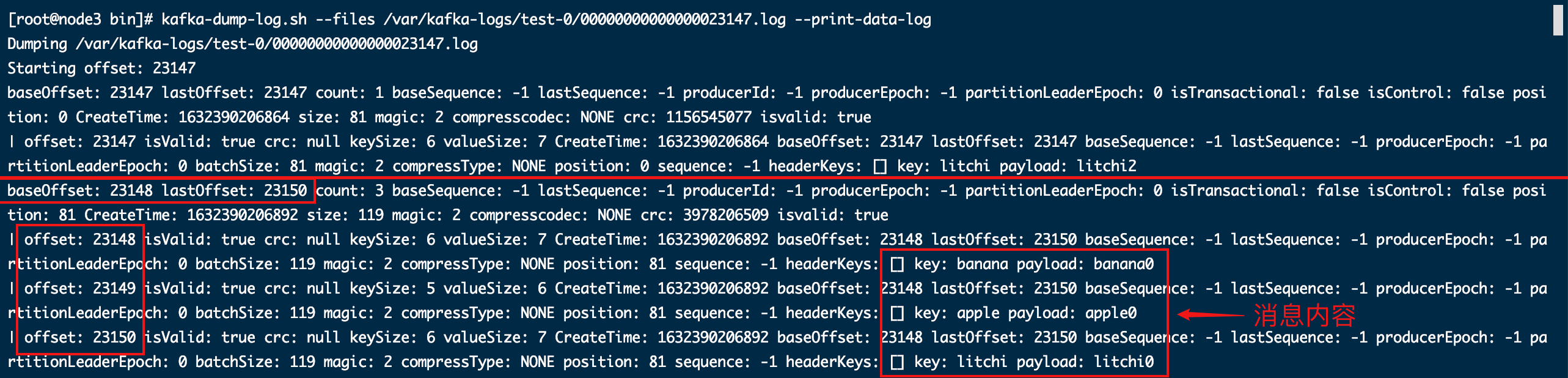
可以看到下图这个消息日志起始偏移量(Starting offset)是23147,代表这个日志第一条消息的偏移量,这个偏移量同时也是消息日志和两个索引文件的文件名。
每n条消息组成一批(batch),每一批消息对应有一个描述信息,记录了这批消息的大小,偏移量范围baseOffset和lastOffset,位置(position)以及大小(batchSize)等信息。
描述信息下面就是对应这一批具体的消息。如下图:
偏移量索引(.index)
# 查看偏移量索引内容
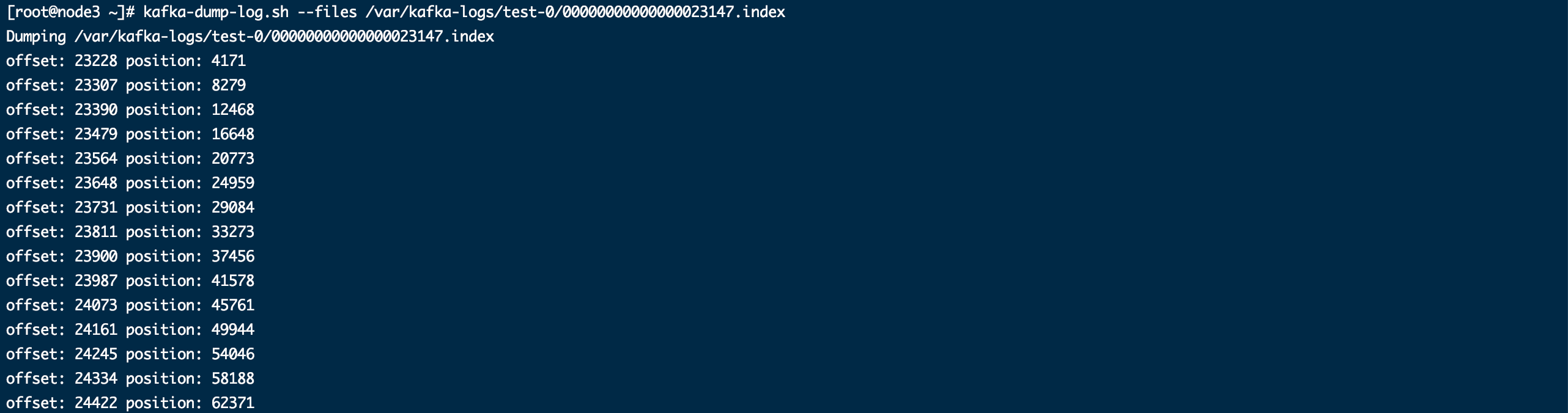
kafka-dump-log.sh --files /var/kafka-logs/test-0/00000000000000023147.index
偏移量索引是稀疏结构,每隔一段记录一条消息的索引。Offset指消息的偏移量,position指这个偏移量的消息所在的一批(batch)消息在.log中的起始二进制位置。
时间索引(.timeindex)
# 查看时间索引内容
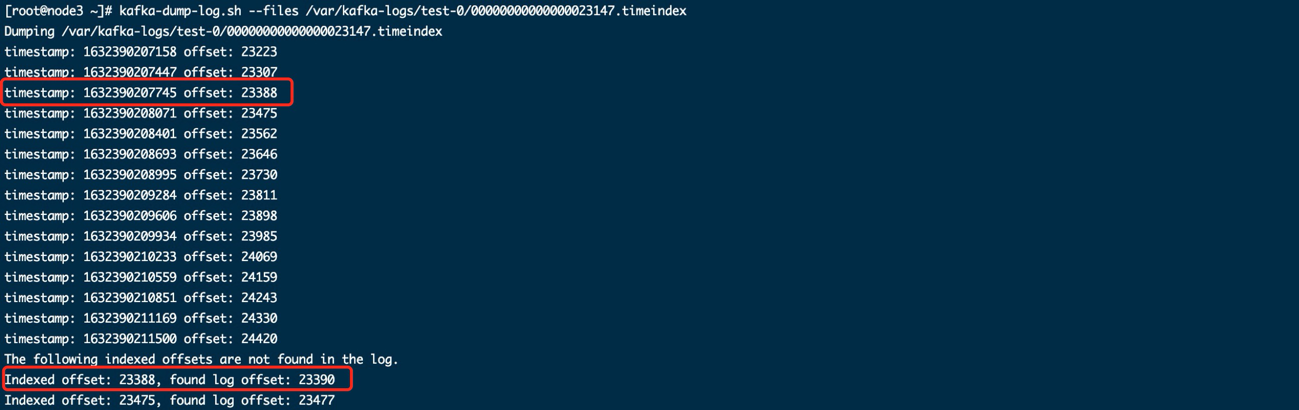
kafka-dump-log.sh --files /var/kafka-logs/test-0/00000000000000023147.timeindex
时间索引也是稀疏结构,每隔一段记录一条消息的索引。时间戳(timestamp)指这条消息的创建时间,Offset指这个消息的偏移量。
上面这条指令同时会输出根据时间戳索引查找消息的结果,比如创建时间为1632390207745的消息偏移量为23388,这条消息所在那一批消息的起始偏移量(Indexed offset / baseOffset:)为23388,终止偏移量(found log offset / lastOffset:)为23390,这一批消息一起有23390 ~ 23388 = 3条消息。
通过索引检索消息过程
通过时间戳检索消息
以查创建时间(CreateTime)为1632390207806的消息为例
去时间索引文件(.timeindex)中比较时间戳可以得到处于1632390207745~1632390208071区间,那对应的偏移量(offset)区间为23388 ~23475;

去偏移量索引(.index)中比较偏移量可以得到这个这个时间范围对应的偏移量(offset)区间为2330723479,对应消息批次(batch)二进制地址(position)区间为827916648。

再通过二进制地址(position)区间在消息日志(.index)中进行二分查找,找到匹配的三条数据offset=23400、23401、23402

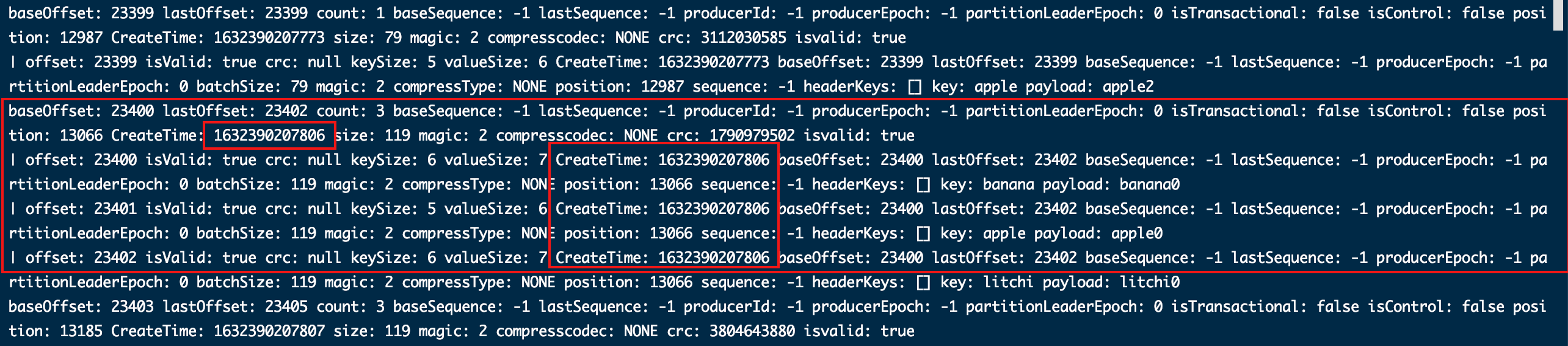

一批消息创建时间不一致
看到这发现每个批次的描述信息的创建时间好像和这一批消息的创建时间是一样的,但仔细查看虽然大多是这样,但也有不一样的。如下图:

通过偏移量检索消息
以偏移量(offset)为23350的消息为例。

再通过二进制地址(position)区间在消息日志(.index)中进行顺序查找,最终找到对应数据。




 浙公网安备 33010602011771号
浙公网安备 33010602011771号