


Tensorflow学习教程------代价函数
Tensorflow学习教程------代价函数
二次代价函数(quadratic cost):
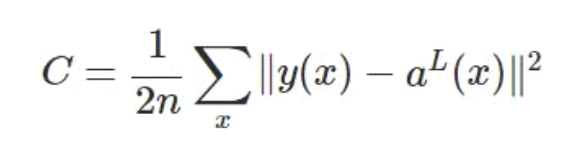
其中,C表示代价函数,x表示样本,y表示实际值,a表示输出值,n表示样本的总数。为简单起见,使用一个样本为例进行说明,此时二次代价函数为: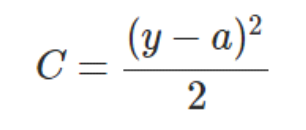
假如我们使用梯度下降法(Gradient descent)来调整权值参数的大小,权值w和偏置b的梯度推导如下:
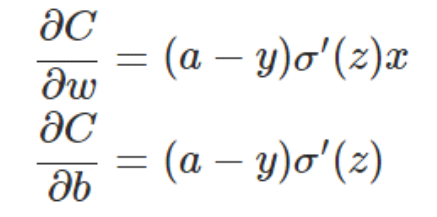
其中,z表示神经元的输入,σ表示激活函数。w和b的梯度跟激活函数的梯度成正比,激活函数的梯度越大,w和b的大小调整得越快,训练收敛得就越快。假设我们的激活函数是sigmoid函数: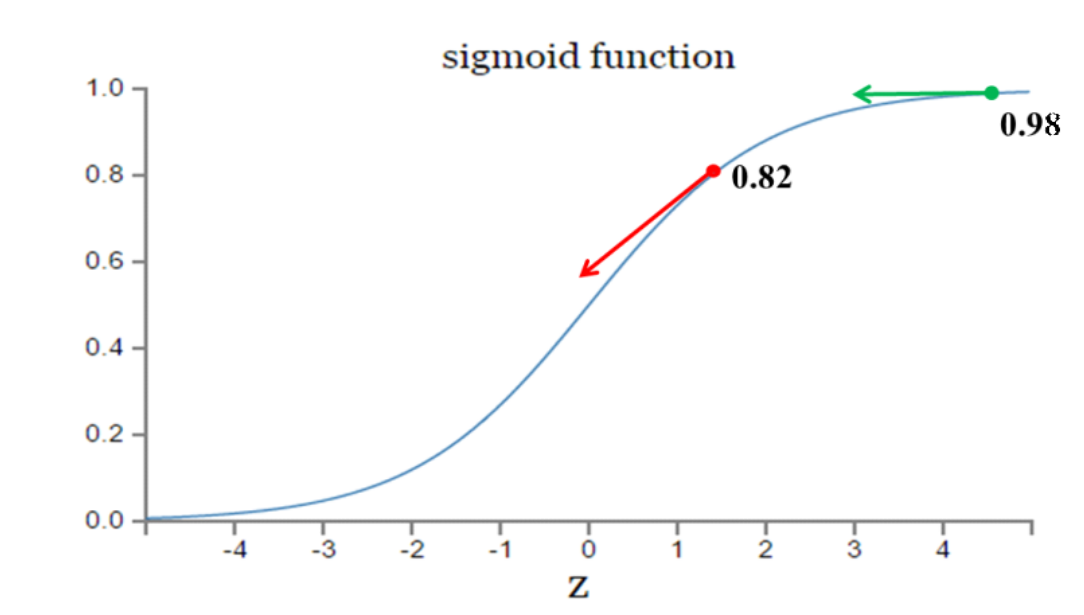
假设我们目标是收敛到1.0。1点为0.82离目标比较远,梯度比较大,权值调整比较大。2点为0.98离目标比较近,梯度比较小,权值调整比较小。调整方案合理。
假如我们目标是收敛到0。1点为0.82目标比较近,梯度比较大,权值调整比较大。2点为0.98离目标比较远,梯度比较小,权值调整比较小。调整方案不合理。
交叉熵代价函数(cross-entropy):
换一个思路,我们不改变激活函数,而是改变代价函数,改用交叉熵代价函数:
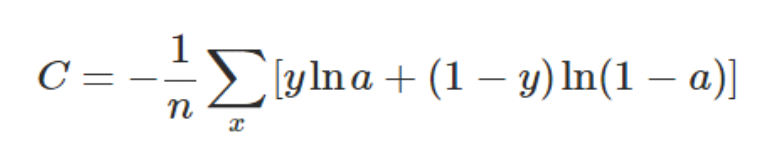
其中,C表示代价函数,x表示样本,y表示实际值,a表示输出值,n表示样本的总数。
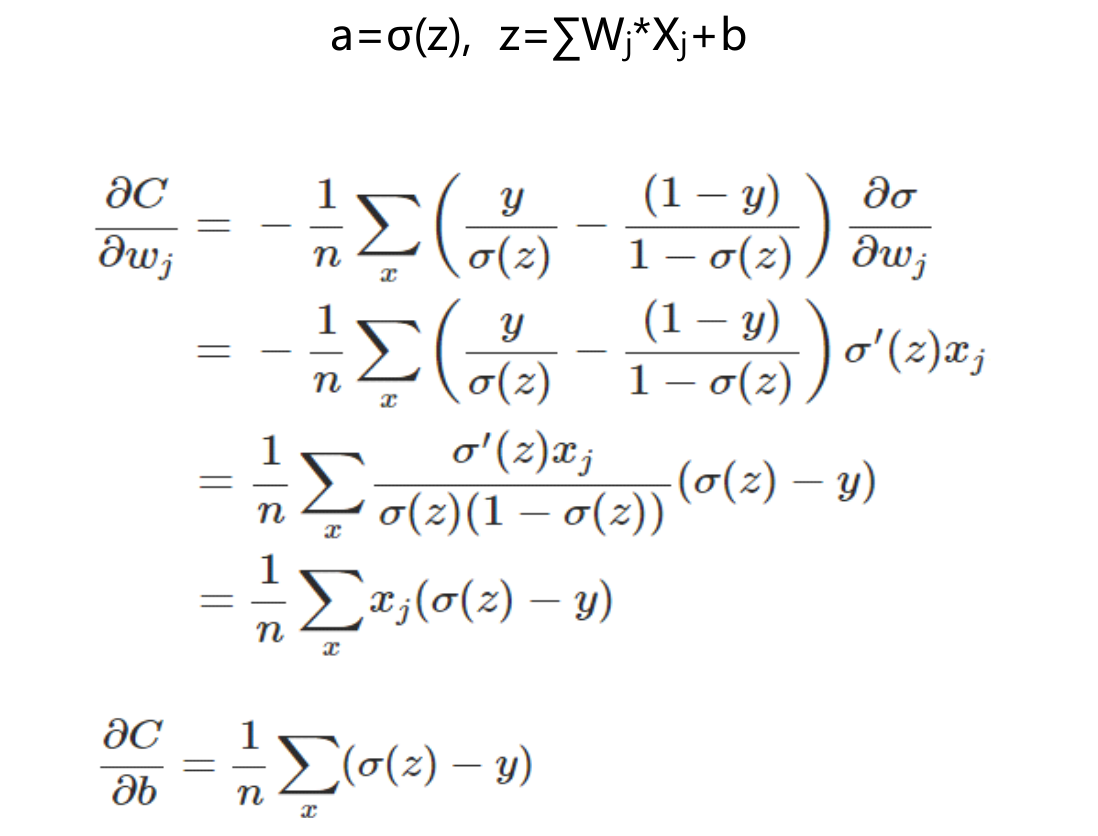
权值和偏置值的调整与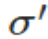 无关,另外,梯度公式中的
无关,另外,梯度公式中的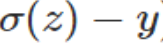 表示输出值与实际值的误差。所以当误差越大时,梯度就越大,参数w和b的调整就越快,训练的速度也就越快。如果输出神经元是线性的,那么二次代价函数就是一种合适的选择。如果输出神经元是S型函数,那么比较适合用交叉熵代价函数。
表示输出值与实际值的误差。所以当误差越大时,梯度就越大,参数w和b的调整就越快,训练的速度也就越快。如果输出神经元是线性的,那么二次代价函数就是一种合适的选择。如果输出神经元是S型函数,那么比较适合用交叉熵代价函数。
对数释然代价函数(log-likelihood cost):
对数释然函数常用来作为softmax回归的代价函数,然后输出层神经元是sigmoid函数,可以采用交叉熵代价函数。而深度学习中更普遍的做法是将softmax作为最后一层,此时常用的代价函数是对数释然代价函数。
对数似然代价函数与softmax的组合和交叉熵与sigmoid函数的组合非常相似。对数释然代价函数在二分类时可以化简为交叉熵代价函数的形式。
在tensorflow中用:
tf.nn.sigmoid_cross_entropy_with_logits()来表示跟sigmoid搭配使用的交叉熵。
tf.nn.softmax_cross_entropy_with_logits()来表示跟softmax搭配使用的交叉熵。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧