


基于caffe模型的模型裁剪和量化
基于caffe模型的模型裁剪和量化
原论文《 Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman coding》https://arxiv.org/abs/1510.00149;
摘要:
通过剪枝、权重共享和权重量化以及哈夫曼编码等方法,作者在AlexNet和VGG-16 等模型上使用这些方法,可以在没有精度损失的情况下,把alexnet模型参数压缩35倍,把VGG模型参数压缩49倍。
1、剪枝就是去掉一些不必要的网络权重,只保留对网络重要的权重参数
2、权值共享就是多个神经元的链接采用同一个权值,权重量化就是用更少的比特来标志一个权值
3、对权值进行哈夫曼编码减少冗余
方法:
2.1 剪枝
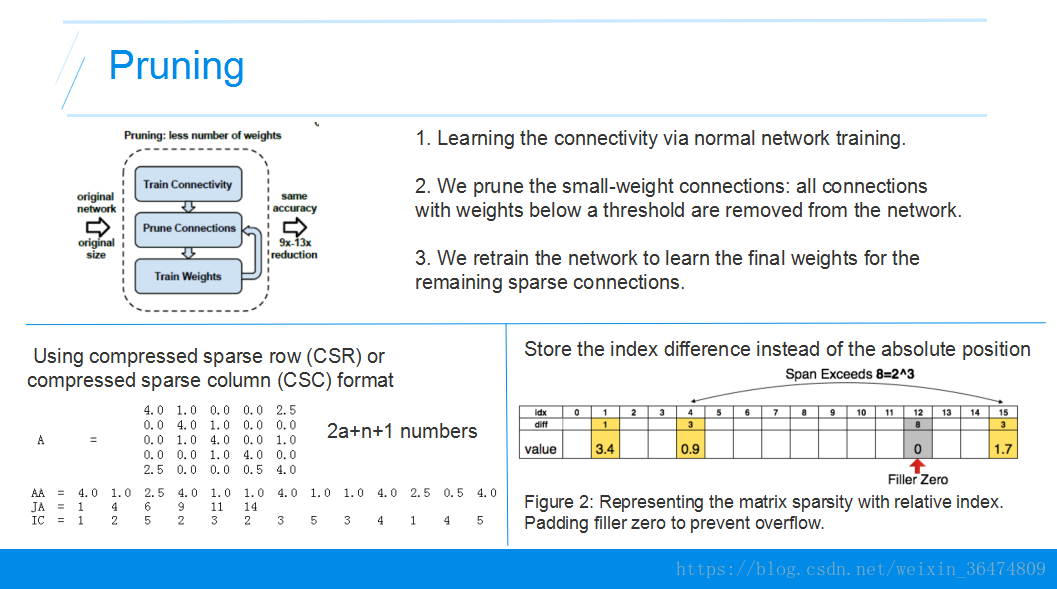
剪枝生成稀疏矩阵:设置一个阈值,把小于阈值的链接设置为0,后续不在参与训练,然后对网络进行训练,得到一个稀疏的权值矩阵。韩松论文,其余的:https://blog.csdn.net/weixin_36474809/article/details/80643784
2.2 代码实现:
cafffe的代码实现: https://github.com/may0324/DeepCompression-caffe;韩松的论文实现结果:https://github.com/songhan/Deep-Compression-AlexNet。定义了mask变量,对权重比较小的值,裁剪后设置mask位,后续迭代运算时不对裁剪的权重进行diff计算。
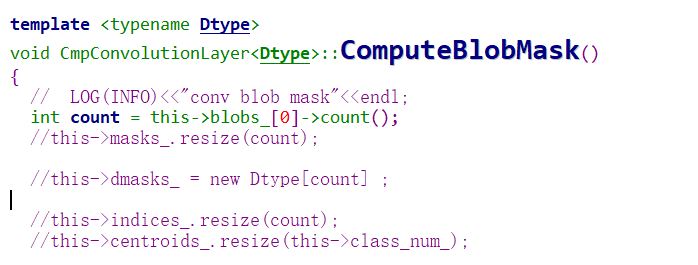
代码中有计算mask 的函数。对权重取绝对值,然后排序,排序后根据设置的裁剪系数,确定需要裁剪权重的阈值。
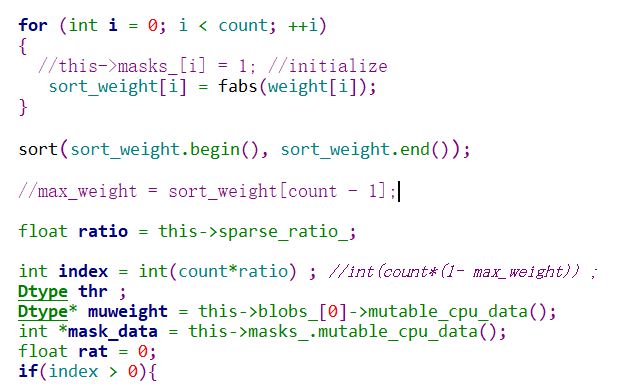
代码只对卷机层和全连接层做了裁剪处理,卷积层和全连接层的代码分别实现在类 CmpConvolutionLayer和CmpInnerProductLayer ;
其中类CmpConvolutionLayer的实现如下:
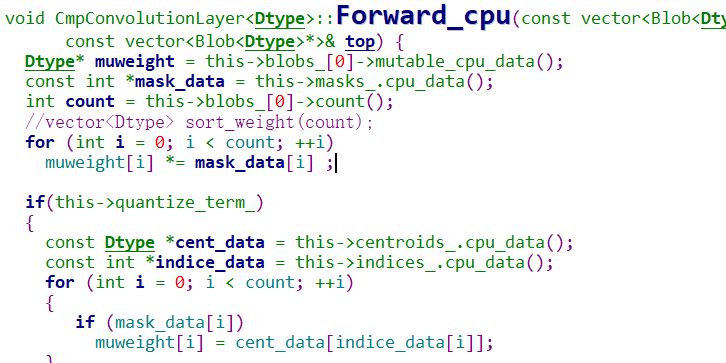
前向计算计算时,会先和maskdata 做计算;被裁剪的权重不在参与计算,
后向梯度更新的时候,也不在参与梯度更新,需要更新的diff也会与mask计算;
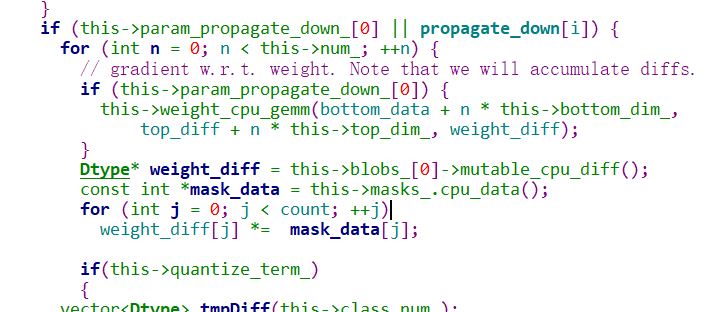
全连接层的计算类似。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧