


MobileNet V3与Lite R-ASPP 总结
论文名称:《Searching for MobileNetV3》
感谢github上大佬们开源,开源代码整理如下:
(1)PyTorch实现1:https://github.com/xiaolai-sqlai/mobilenetv3
(2)PyTorch实现2:https://github.com/kuan-wang/pytorch-mobilenet-v3
(3)PyTorch实现3:https://github.com/leaderj1001/MobileNetV3-Pytorch
(4)Caffe实现:https://github.com/jixing0415/caffe-mobilenet-v3
(5)TensorFLow实现:https://github.com/Bisonai/mobilenetv3-tensorflow

 4
4  收藏
收藏简介

该论文基于神经架构搜索技术提出下一代轻量级网络结构,M o b i l e N e t V 3 {\rm MobileNetV3}MobileNetV3,实验结果表明该模型在目标检测和语义分割任务上均达到了实时性的S O T A {\rm SOTA}SOTA。论文原文
0. Abstract
M o b i l e N e t V 3 {\rm MobileNetV3}MobileNetV3基于神经架构搜索技术得到。论文首先探索了搜索算法与网络设计如何协同工作,进而根据资源因素设计出两种M o b i l e N e t V 3 {\rm MobileNetV3}MobileNetV3。最后,在目标检测和语义分割任务上,M o b i l e N e t V 3 {\rm MobileNetV3}MobileNetV3均达到了实时性的S O T A {\rm SOTA}SOTA。
论文贡献:(一)基于神经架构搜索技术得到轻量级网络M o b i l e N e t V 3 {\rm MobileNetV3}MobileNetV3;(二)探讨了非线性函数的使用场景;(三)在语义分割任务中提出新的轻量级解码器;(四)在多项实时性视觉任务上达到S O T A {\rm SOTA}SOTA。
1. Introduction
论文主要介绍了设计M o b i l e N e t V 3 {\rm MobileNetV3}MobileNetV3的过程,包括但不限于高效的搜索技术、非线性变换、网络设计和解码器。最后,论文给出详尽的实验证明了上述方法的有效性。
2. Related Work
这部分主要介绍前人有关轻量级网络的工作。
S q u e e z e N e t {\rm SqueezeNet}SqueezeNet大量使用基于1 × 1 1\times11×1卷积的压缩和扩展模块,以此来减少参数量;M o b i l e N e t V 1 {\rm MobileNetV1}MobileNetV1基于深度可分离卷积显著改善了模型;M o b i l e N e t V 2 {\rm MobileNetV2}MobileNetV2引入反向残差结构在多项实时性视觉任务上达到S O T A {\rm SOTA}SOTA;S h u f f l e N e t {\rm ShuffleNet}ShuffleNet基于分组卷积和通道混洗进一步减少计算量;C o n d e n s e N e t {\rm CondenseNet}CondenseNet在训练阶段学习分组卷积来保持各层之间高效的密集连接以供特征重用;S h i f t N e t {\rm ShiftNet}ShiftNet提出基于移位操作的点卷积来代替空间卷积。
为了自动化地设计模型,基于强化学习来搜索网络结构得到大家的广泛关注。通常,一个完备的搜索空间会带来资源量的指数级增加。因此,早期的架构搜索技术集中在单元结构的搜索上,然后多次复用该单元。近来,M n a s N e t {\rm MnasNet}MnasNet提出基于模块级的搜索空间来设计不同分辨率的层。为降低搜索的计算成本,当前大多算法使用基于梯度的优化方法。
量化是通过降低计算精度来提高模型性能的另一项重要技术;知识蒸馏提供了另一种设计小型网络的思路,即在一个大的教师网络的指导下生成小的精确的学生网络。
3. Efficient Mobile Building Blocks
M o b i l e N e t V 1 {\rm MobileNetV1}MobileNetV1使用深度可分离卷积代替传统卷积,其主要分为深度卷积和点卷积两部分,显著降低了卷积计算参数。
M o b i l e N e t V 2 {\rm MobileNetV2}MobileNetV2引入带线性瓶颈块的反向残差结构,提出仅在高维空间使用非线性变换以此来减少信息损失。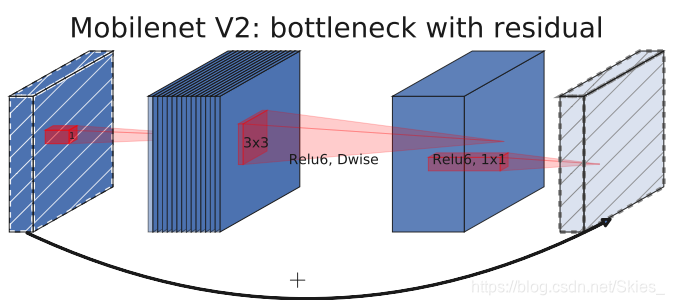
M n a s N e t {\rm MnasNet}MnasNet基于M o b i l e N e t V 2 {\rm MobileNetV2}MobileNetV2而设计,其提出在瓶颈结构中引入基于压缩和激励的轻量级注意力模块。
而M o b i l e N e t V 3 {\rm MobileNetV3}MobileNetV3使用了上述层的组合,并提出S w i s h {\rm Swish}Swish非线性激活函数。同时,为了得到高效的网络结构,在压缩、激励和S w i s h {\rm Swish}Swish模块中,均使用H a r d S i g m o i d {\rm Hard\ Sigmoid}Hard Sigmoid激活函数。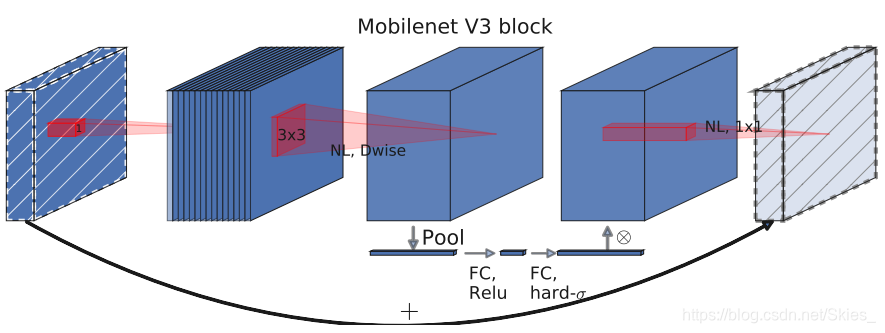
4. Network Search
4.1 Platform-Aware NAS for Block-wise Search
M o b i l e N e t V 3 {\rm MobileNetV3}MobileNetV3主要基于资源受限N A S {\rm NAS}NAS(M n a s N e t {\rm MnasNet}MnasNet)和N e t A d a p t {\rm NetAdapt}NetAdapt得到,通过在前者的基础上加上后者等其它优化方法。
但作者发现,用于搜索大型模型的奖励机制(基于强化学习的N A S {\rm NAS}NAS中的概念)不适用于小型模型。具体地,基于平衡模型的精度A C C ( m ) ACC(m)ACC(m)、延时L A T ( m ) LAT(m)LAT(m)和目标延时T A R TARTAR,使用多目标奖励A C C ( m ) × [ L A T ( m ) / T A R ] w ACC(m)\times[LAT(m)/TAR]^wACC(m)×[LAT(m)/TAR]w来得到近似帕累托最优解。而对于小型模型来说,模型精度的变化较大,因此作者提出使用一个权重因子w ww来补偿不同延时下的精度变化。基于该优化因子w ww,作者采用随机搜索的方法得到一个初始模型,然后使用N e t A d a p t {\rm NetAdapt}NetAdapt等优化方法得到一个小型的M o b i l e N e t V 3 {\rm MobileNetV3}MobileNetV3。
4.2 NetAdapt for Layer-wise Search
N e t A d a p t {\rm NetAdapt}NetAdapt是一项与资源受限N A S {\rm NAS}NAS互补的一项技术,它允许微调单个层,其过程如下:
1、基于资源受限N A S {\rm NAS}NAS随机得到一个初始网络结构;
2、对于每一步,执行如下操作:
- 生成一组候选结构,且每种结构相比于上一步的结构延迟减少δ \deltaδ
- 对于每个候选结构,使用前一步预训练模型填充新的候选结构,并截断和随机初始化缺失的权重。对每个候选结构微调T TT次,并得到大致的精度
- 根据某准则选出最好的模型
3、不断重复之前的步骤,直到达到既定目标
选择最终模型的准则包括最小化精度变化等,论文提出将最小化延时变化与精度变化之比作为最终准则,即最大化Δ A c c ∣ Δ l a t e n c y ∣ \frac{\Delta{\rm Acc}}{|\Delta{\rm latency}|}∣Δlatency∣ΔAcc。
得到最终的模型后,使用M o b i l e N e t V 2 {\rm MobileNetV2}MobileNetV2的方法重新随机训练模型,具体的改动为减少扩展层的大小和减少瓶颈模块,同时保留残差连接。
在迭代过程中,T = 10000 {\rm T=10000}T=10000,δ = 0.01 ∣ L ∣ \delta=0.01|L|δ=0.01∣L∣。
5. Network Improvements
5.1 Redesigning Expensive Layers
作者发现,基于神经架构搜索得到的模型,一些前面层和最后层的计算代价较高。作者提出针对这些层的改进,在减小计算代价的同时不降低模型的精度。
第一个改动是针对后面几层,当前,基于M o b i l e N e t V 2 {\rm MobileNetV2}MobileNetV2的模型在最后层使用1 × 1 1\times11×1卷积来增加维度从而使用非线性变换,但升维的操作会引入大量计算量。为了减少延时和保留高维特征,作者提出将该层移动至最后的平均池化层。这时,原来的7 × 7 7\times77×7卷积使用1 × 1 1\times11×1卷积代替,平衡了计算代价和模型精度。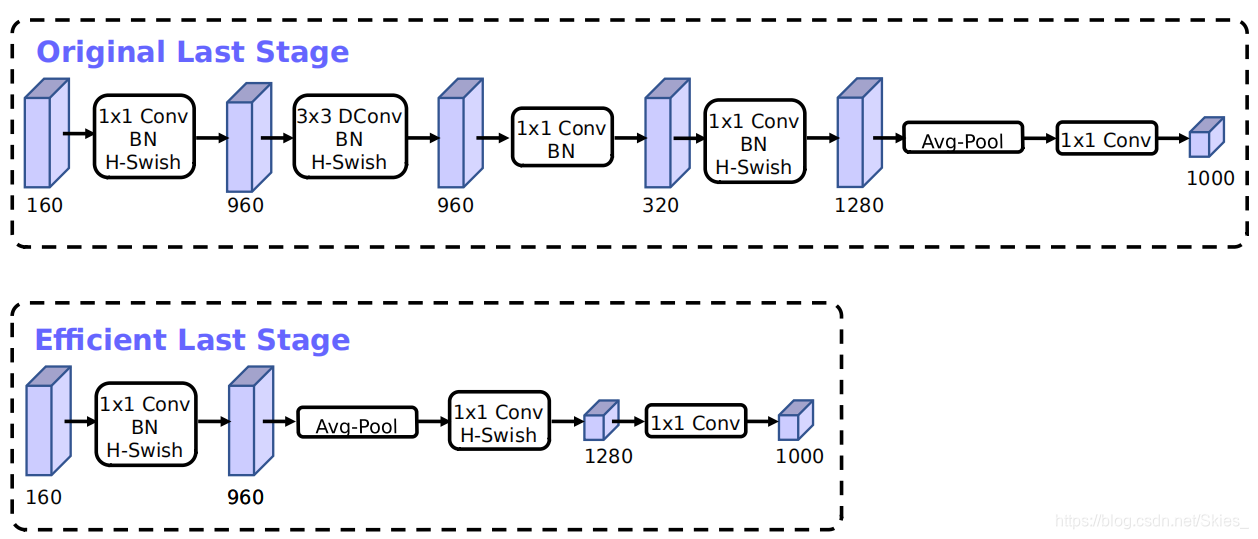
另一个改动是针对前面层,当前移动端模型使用32 3232个3 × 3 3\times33×3的卷积作为初始卷积以提取目标轮廓特征,作者提出减少卷积核的数量,使用不同的非线性变换来减少计算代价。将卷积核数量减少至16 1616,同时保持前者的精度。
5.2 Nonlinearities
S w i s h {\rm Swish}Swish非线性激活函数定义如下:s w i s h x = x ⋅ σ ( x ) (1) {\rm swish}\ x=x\cdot\sigma(x)\tag{1}swish x=x⋅σ(x)(1)
尽管该激活函数提高了模型精度,但使用S i g m o i d {\rm Sigmoid}Sigmoid函数使其计算代价较高。论文提出了两点解决方法,将S i g m o i d {\rm Sigmoid}Sigmoid函数替换掉:h − s w i s h [ x ] = x R e L U 6 ( x + 3 ) 6 (2) {\rm h-swish}[x]=x\frac{{\rm ReLU}6(x+3)}{6}\tag{2}h−swish[x]=x6ReLU6(x+3)(2)
尽管h a r d {\rm hard}hard-s w i s h {\rm swish}swish无法显著提高模型精度,但从部署的角度来看它更适合:首先,R e L U 6 {\rm ReLU6}ReLU6的实现对硬件友好;其次,在量化过程中,相比于S i g m o i d {\rm Sigmoid}Sigmoid函数它不会带来较大精度的损失;最后,R e L U 6 {\rm ReLU6}ReLU6可以通过一个分段函数实现,从而降低内存的访问次数。
其次,随着网络的加深,由于特征图的尺寸变小,所以非线性实现代价逐渐变小。作者发现,s w i s h {\rm swish}swish函数在网络的后面部分的效果更好,因此,作者进将其引入模型的后半部分。
5.3 Large squeeze-and-excite
在M o b i l e N e t V 3 {\rm MobileNetV3}MobileNetV3中,作者加压缩激励模块设为扩展层通道数的1 / 4 1/41/4。这样,既增加了模型精度,也在参数适量增加的前提下没有明显提高延时。
5.4 MobileNetV3 Definitions
作者设计了两个版本的M o b i l e N e t V 3 {\rm MobileNetV3}MobileNetV3,其结构分别如下: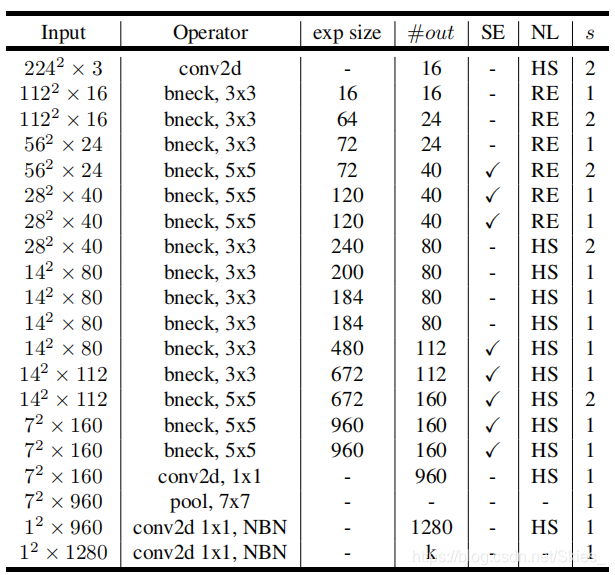
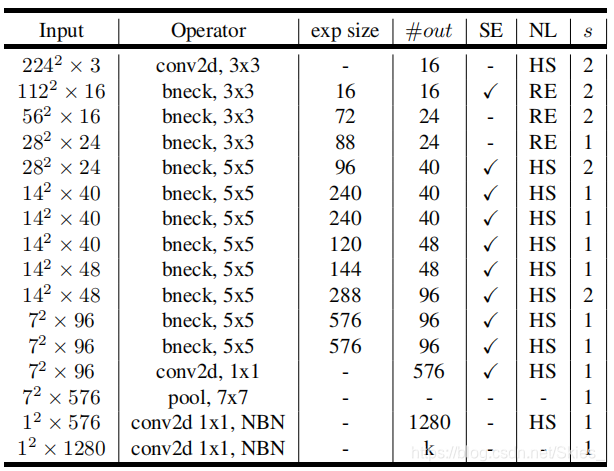
图中,H S {\rm HS}HS表示h − w i s h {\rm h-wish}h−wish,R E {\rm RE}RE表示R e L U {\rm ReLU}ReLU,N B N {\rm NBN}NBN表示不使用B N {\rm BN}BN。
6. Experiments
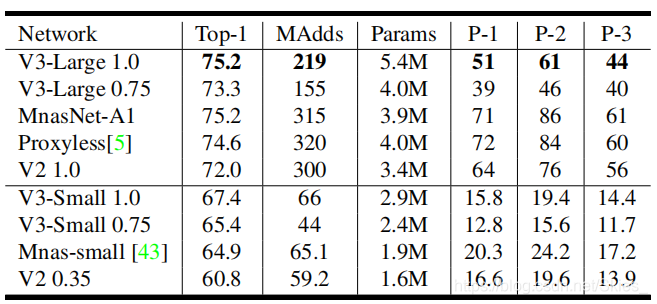

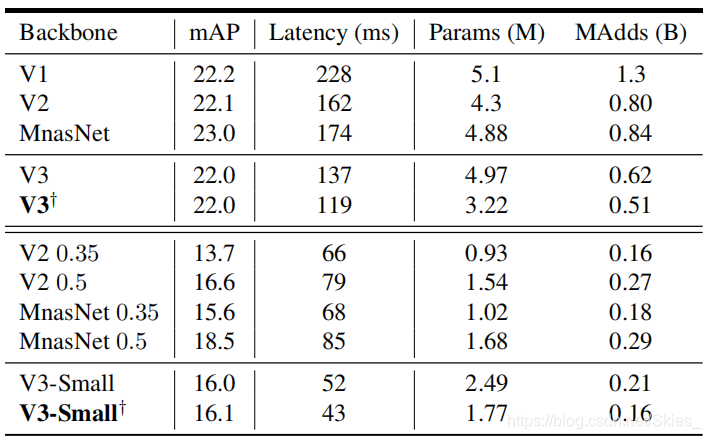
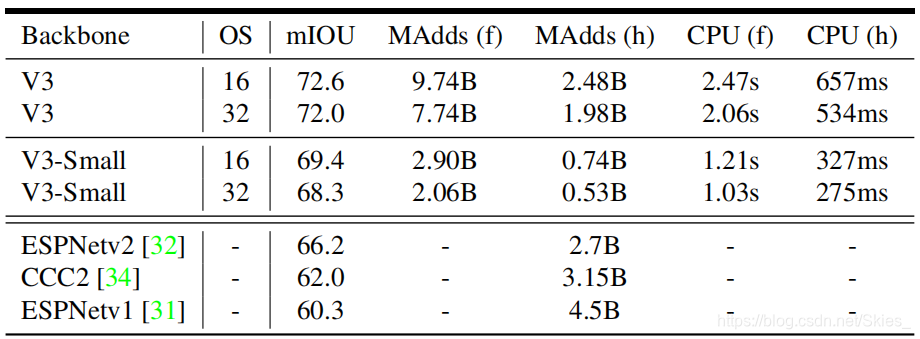
7. Conclusions and future work
论文提出基于神经架构搜索的M o b i l e N e t V 3 {\rm MobileNetV3}MobileNetV3,得到两种不同大小的模型以满足不同的实时性需求。关于神经架构搜索的内容,可参考此文章。
参考
- Howard A, Sandler M, Chu G, et al. Searching for mobilenetv3[C]//Proceedings of the IEEE International Conference on Computer Vision. 2019: 1314-1324.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
2019-01-18 批数据提取
2019-01-18 保存和提取
2019-01-18 classification.py