


FCOS官方代码详解(二):Architecture(head)
https://blog.csdn.net/laizi_laizi/article/details/105519290
上一篇写到head部分就感觉太长了,还是分开来写:FCOS官方代码详解(一):Architecture(backbone)
这一篇就继续把architecture中的fcos_head分析一下,脑海中一直要有这图的印象: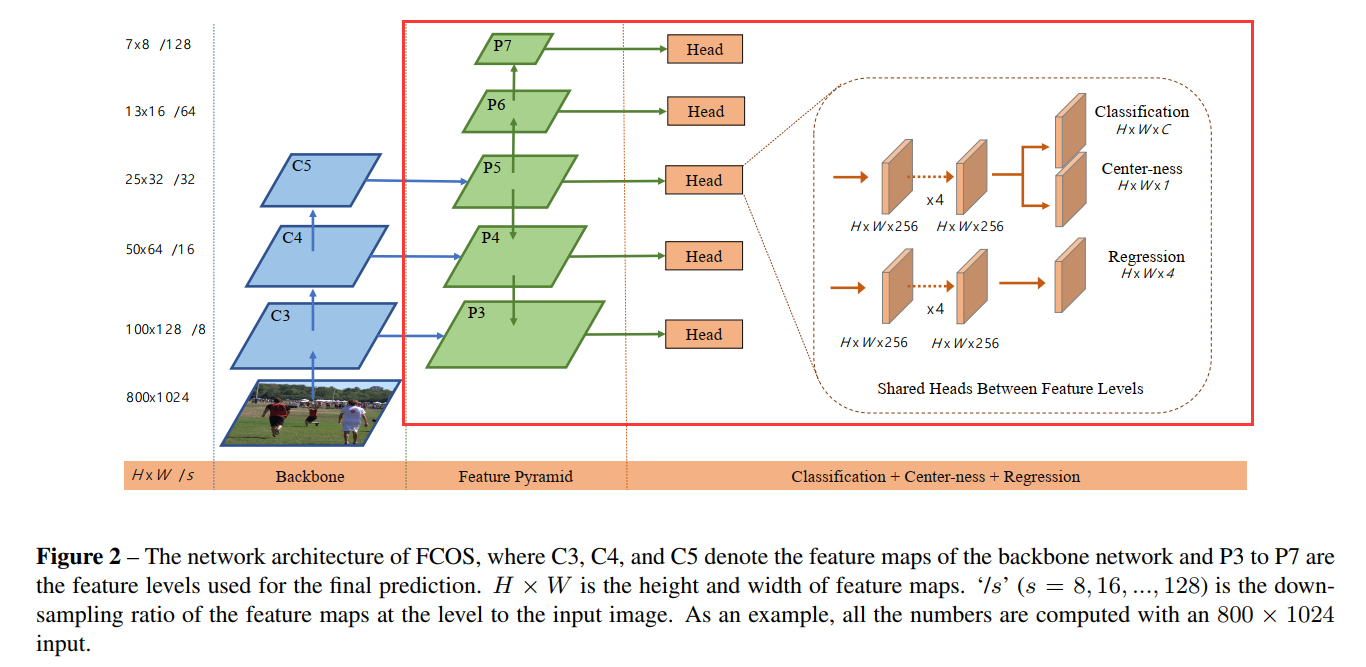
fcos_head
在类GeneralizedRCNN初始化的时候还有这么一句:self.rpn = build_rpn(cfg, self.backbone.out_channels),其实这里没改过来,实际构造的是fcos_head,返回的是build_fcos(cfg, in_channels),具体代码在fcos_core/modeling/rpn/fcos/fcos.py
然后build_fcos返回的是FCOSModule
def build_fcos(cfg, in_channels):
return FCOSModule(cfg, in_channels)
- 1
- 2
看一下FCOSModule()的初始化部分
class FCOSModule(torch.nn.Module):
"""
Module for FCOS computation. Takes feature maps from the backbone and
FCOS outputs and losses. Only Test on FPN now.
"""
def __init__(self, cfg, in_channels):
super(FCOSModule, self).__init__()
head = FCOSHead(cfg, in_channels) # 构造fcos的头部
box_selector_test = make_fcos_postprocessor(cfg)
loss_evaluator = make_fcos_loss_evaluator(cfg)
self.head = head
self.box_selector_test = box_selector_test
self.loss_evaluator = loss_evaluator
self.fpn_strides = cfg.MODEL.FCOS.FPN_STRIDES # eg:[8, 16, 32, 64, 128]
def forward(self, images, features, targets=None): # 调用的时候:self.rpn(images, features, targets)
pass
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
那就转过去看一下FCOSHead:
class FCOSHead(torch.nn.Module):
def __init__(self, cfg, in_channels):
"""
Arguments:
in_channels (int): number of channels of the input feature
这个就是fpn每层的输出通道数,根据之前分析,都是一样的,如256
"""
super(FCOSHead, self).__init__()
# TODO: Implement the sigmoid version first.
num_classes = cfg.MODEL.FCOS.NUM_CLASSES - 1 # eg:80
self.fpn_strides = cfg.MODEL.FCOS.FPN_STRIDES # eg:[8, 16, 32, 64, 128]
self.norm_reg_targets = cfg.MODEL.FCOS.NORM_REG_TARGETS # eg:False 直接回归还是归一化后回归
self.centerness_on_reg = cfg.MODEL.FCOS.CENTERNESS_ON_REG # eg:False centerness和哪个分支共用特征
self.use_dcn_in_tower = cfg.MODEL.FCOS.USE_DCN_IN_TOWER # eg:False
cls_tower = []
bbox_tower = []
# eg: cfg.MODEL.FCOS.NUM_CONVS=4头部共享特征时(也称作tower)有4层卷积层
for i in range(cfg.MODEL.FCOS.NUM_CONVS):
if self.use_dcn_in_tower and \
i == cfg.MODEL.FCOS.NUM_CONVS - 1:
conv_func = DFConv2d
else:
conv_func = nn.Conv2d
# cls_tower和bbox_tower都是4层的256通道的3×3的卷积层,后加一些GN和Relu
cls_tower.append(
conv_func(
in_channels,
in_channels,
kernel_size=3,
stride=1,
padding=1,
bias=True
)
)
cls_tower.append(nn.GroupNorm(32, in_channels))
cls_tower.append(nn.ReLU())
bbox_tower.append(
conv_func(
in_channels,
in_channels,
kernel_size=3,
stride=1,
padding=1,
bias=True
)
)
bbox_tower.append(nn.GroupNorm(32, in_channels))
bbox_tower.append(nn.ReLU())
self.add_module('cls_tower', nn.Sequential(*cls_tower))
self.add_module('bbox_tower', nn.Sequential(*bbox_tower))
# cls_logits就是网络的直接分类输出结果,shape:[H×W×C]
self.cls_logits = nn.Conv2d(
in_channels, num_classes, kernel_size=3, stride=1,
padding=1
)
# bbox_pred就是网络的回归分支输出结果,shape:[H×W×4]
self.bbox_pred = nn.Conv2d(
in_channels, 4, kernel_size=3, stride=1,
padding=1
)
# centerness就是网络抑制低质量框的分支,shape:[H×W×1]
self.centerness = nn.Conv2d(
in_channels, 1, kernel_size=3, stride=1,
padding=1
)
# initialization 这些层里面的卷积参数都进行初始化
for modules in [self.cls_tower, self.bbox_tower,
self.cls_logits, self.bbox_pred,
self.centerness]:
for l in modules.modules():
if isinstance(l, nn.Conv2d):
torch.nn.init.normal_(l.weight, std=0.01)
torch.nn.init.constant_(l.bias, 0)
# initialize the bias for focal loss 我只知道分类是用focal loss,可能是一种经验trick?
prior_prob = cfg.MODEL.FCOS.PRIOR_PROB
bias_value = -math.log((1 - prior_prob) / prior_prob)
torch.nn.init.constant_(self.cls_logits.bias, bias_value)
# P3-P7共有5层特征FPN,缩放因子,对回归结果进行缩放
self.scales = nn.ModuleList([Scale(init_value=1.0) for _ in range(5)])
def forward(self, x):
logits = []
bbox_reg = []
centerness = []
# 我想这里的x应该是fpn出来的各层特征,因为x根据下一句看是可迭代的
for l, feature in enumerate(x):
# 要注意,不图层经过tower之后的特征图大小是不一样的
# 还有一点就是,不同层的特征都是共享一个tower,无论是cls分支还是bbox分支
cls_tower = self.cls_tower(feature)
box_tower = self.bbox_tower(feature)
logits.append(self.cls_logits(cls_tower))
# 根据centerness_on_reg选择对应的tower特征
if self.centerness_on_reg:
centerness.append(self.centerness(box_tower))
else:
centerness.append(self.centerness(cls_tower))
bbox_pred = self.scales[l](self.bbox_pred(box_tower)) # 得到缩放后的bbox_pred
if self.norm_reg_targets:
bbox_pred = F.relu(bbox_pred)
if self.training:
bbox_reg.append(bbox_pred)
else:
bbox_reg.append(bbox_pred * self.fpn_strides[l])
else:
bbox_reg.append(torch.exp(bbox_pred))
return logits, bbox_reg, centerness
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 关于在回归分支为什么要有一个指数e的运算,原论文这么说:
Moreover, since the regression targets are always positive, we employ exp(x) to map any real number to (0, + ∞ +\infty+∞) on the top of the regression branch
- 关于上面代码中的对于bbox_pred缩放,在原论文中只有这么一块说到:

可以看到为了能够继续在不同级的特征共享head,这里把回归预测结果乘以一个缩放因子,这个因子是tensor,是可以更新,即可以学习的,当然分类分支不需要。
这里放一下我打印出来的head部分:
(rpn): FCOSModule(
(head): FCOSHead(
(cls_tower): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): GroupNorm(32, 256, eps=1e-05, affine=True)
(2): ReLU()
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): GroupNorm(32, 256, eps=1e-05, affine=True)
(5): ReLU()
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): GroupNorm(32, 256, eps=1e-05, affine=True)
(8): ReLU()
(9): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(10): GroupNorm(32, 256, eps=1e-05, affine=True)
(11): ReLU()
)
(bbox_tower): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): GroupNorm(32, 256, eps=1e-05, affine=True)
(2): ReLU()
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): GroupNorm(32, 256, eps=1e-05, affine=True)
(5): ReLU()
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): GroupNorm(32, 256, eps=1e-05, affine=True)
(8): ReLU()
(9): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(10): GroupNorm(32, 256, eps=1e-05, affine=True)
(11): ReLU()
)
(cls_logits): Conv2d(256, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bbox_pred): Conv2d(256, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(centerness): Conv2d(256, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(scales): ModuleList(
(0): Scale()
(1): Scale()
(2): Scale()
(3): Scale()
(4): Scale()
)
)
(box_selector_test): FCOSPostProcessor()
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
至此,整个FCOS的网络结构就理清楚了!关于FCOSModule的前向传播代码可以放训练的部分一起讲!
分类:
目标检测--anything


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
2019-01-07 tf-maskrcnn