


FCOS代码解读
论文解读:https://zhuanlan.zhihu.com/p/63868458
源码解读:
一:https://zhuanlan.zhihu.com/p/112126473

入门mmdetection(柒)---FCOS源码解读
前面六篇文章借助sq的经典之作(Faster R-CNN)熟悉了mmdetection整个的设计风格和训练流程,这篇笔记想分享一下FCOS在mmdetection中的源码实现。
FCOS大概是去年这个时候出来的文章,一出来就注定要引领新的潮流,单阶段网络逐渐成为学术界和工业界的新宠。但其实FCOS本质思想,一方面几年前Densebox就已经有类似的了,另一方面,无非是框的anchor变成了点的anchor,并不能说是真正的anchor-free,还是没有跳脱滑窗匹配的命运。整体而言,FCOS出来了还是很惊艳了我,对回归目标的编码方式、centerness的提出解决大框偏离问题以及利用FPN缓解歧义的场景(如人的手上拿了个网球)。来开始欣赏代码吧:
# FCOS类继承了单阶段检测器类SingleStageDetector
class FCOS(SingleStageDetector):
def __init__(self,backbone,neck,bbox_head,
train_cfg=None,test_cfg=None,pretrained=None):
super(FCOS, self).__init__(backbone, neck, bbox_head, train_cfg,
test_cfg, pretrained)FCOS类继承了单阶段检测器类,这个和之前Faster R-CNN继承了双阶段检测器一样,实现都在对应的父类里面,所以我们截取部分重要的单阶段的代码块来看。
class SingleStageDetector(BaseDetector):
def __init__(self,backbone,neck=None,bbox_head=None,
train_cfg=None,test_cfg=None,pretrained=None):
super(SingleStageDetector, self).__init__()
# 这里下面的build和之前介绍的一样,从config读取对应的type,然后返回一个实例
self.backbone = builder.build_backbone(backbone)
if neck is not None:
self.neck = builder.build_neck(neck)
# 这里self.bbox_head就是一个FCOSHead的实例
self.bbox_head = builder.build_head(bbox_head)
self.train_cfg = train_cfg
self.test_cfg = test_cfg
self.init_weights(pretrained=pretrained)所以初始化函数就是创建backbone,neck以及head的实例,其中和Faster R-CNN不一样的只有head使用的是FCOSHead。可以想象,这个FCOSHead类里面必然实现了一个前向,就是下图橘色框起来那个三个分支的图(分别是分类H * W *C, 回归 H * W* 4 以及 centerness H * W * 1),以及计算target和loss的代码。先继续看SingleStageDetector的实现:
# 训练的前向函数forward_train,在BaseDetector的成员函数forward()里会调用,
# 上一章讲过,forward()会在batch_processor调用,在训练流程控制里
# 传进来的参数都是data_loader的输出,这个以后有机会再看,总之能拿到数据集的图片和标签
def forward_train(self,img,img_metas,gt_bboxes,gt_labels,gt_bboxes_ignore=None):
x = self.extract_feat(img) #通过backbone和FPN提取多尺度的特征
outs = self.bbox_head(x) #即FCOSHead的实例调用成员函数forward
loss_inputs = outs + (gt_bboxes, gt_labels, img_metas, self.train_cfg)
losses = self.bbox_head.loss( # 计算loss
*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
return losses前向的代码封装的非常清晰,那么重点就是在FCOSHead里面了,我们来看这个类。
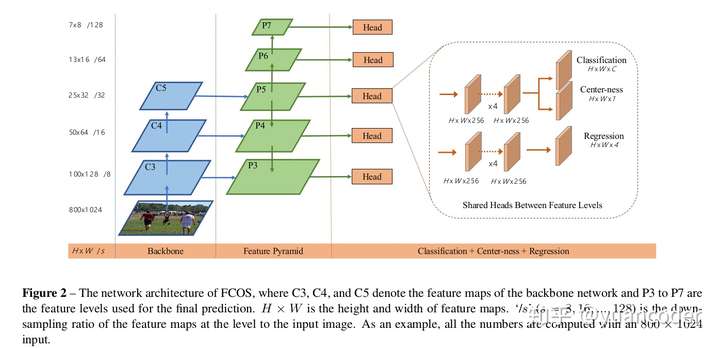
#首先初始化fcos头部网络结构,其实就是上图框框里的部分,
#两个分支,分别都有4个卷积,上面分叉为分类和centerness,下面接回归(当然,也可以把centerness和回归接在一起)
def _init_layers(self):
self.cls_convs = nn.ModuleList()
self.reg_convs = nn.ModuleList()
for i in range(self.stacked_convs):
chn = self.in_channels if i == 0 else self.feat_channels
#stacked_convs=4, 即接4个3*3的卷积,channel为256
self.cls_convs.append(
ConvModule(
chn,
self.feat_channels,
3,
stride=1,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
bias=self.norm_cfg is None))
self.reg_convs.append(
ConvModule(
chn,
self.feat_channels,
3,
stride=1,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
bias=self.norm_cfg is None))
# 分类的channel数需要注意一下,因为后面用的focal loss,所以为类别数-1
# 即对coco数据集就不是81而是80
# 本质上来说focal_loss调用的是BCE,并不引入类间竞争
self.fcos_cls = nn.Conv2d(
self.feat_channels, self.cls_out_channels, 3, padding=1)
# 回归,输出channel为4,也和faster RCNN不一样,anchorbox有多个,anchor点只有一个
# 譬如假如有9种anchor box,那么Faster R-CNN这边应该是36,而fcos只有4,减少了计算量
self.fcos_reg = nn.Conv2d(self.feat_channels, 4, 3, padding=1)
# 预测centerness,channel为1
# centerness预测了当前anchor点的中心程度,推理的时候可以给框打分
# 不在中心的框乘了centerness之后得分就降低了,容易被NMS过滤掉
self.fcos_centerness = nn.Conv2d(self.feat_channels, 1, 3, padding=1)
self.scales = nn.ModuleList([Scale(1.0) for _ in self.strides])
# 初始化了网络结构和权重之后就可以前向了,来看forward函数
def forward(self, feats):
# 传进来的feats就是通过backbone和FPN提取多尺度的特征(一般是一个长度为5的tuple)
# 注意这边用map把FPN的多个level给拆解了,可以简单理解为并行计算了
return multi_apply(self.forward_single, feats, self.scales)
def multi_apply(func, *args, **kwargs):
pfunc = partial(func, **kwargs) if kwargs else func
map_results = map(pfunc, *args)
return tuple(map(list, zip(*map_results)))
def forward_single(self, x, scale):
cls_feat = x # 所以x其实是FPN的一个Level的特征
reg_feat = x
# 把输入特征分别前向过4个卷积(上一分岔路)
for cls_layer in self.cls_convs:
cls_feat = cls_layer(cls_feat)
#过分类对应的卷积层,输出是H*W*(numcls-1)
cls_score = self.fcos_cls(cls_feat)
#过centerness对应的卷积层,输出是H*W*1
centerness = self.fcos_centerness(cls_feat)
# 把输入特征分别前向过4个卷积(下一分岔路)
for reg_layer in self.reg_convs:
reg_feat = reg_layer(reg_feat)
# scale the bbox_pred of different level
# float to avoid overflow when enabling FP16
#过回归任务对应的卷积层,输出是H*W*4,注意最后跟了exp函数映射了值(作者似乎没解释原因)
bbox_pred = scale(self.fcos_reg(reg_feat)).float().exp()
# 返回值就是算出的这个三个部分分类回归和centerness
# 需要注意的是,之后multi_apply后返回的是和FPN尺度对应的多尺度的这些结果
return cls_score, bbox_pred, centerness前向部分其实就这么多,复杂的地方在后面计算target和loss的部分。
loss_inputs = outs + (gt_bboxes, gt_labels, img_metas, self.train_cfg)
# 可以看到传给loss计算的信息还挺多的哈
# 1 前向的输出,即网络推理出的三个部分分类、回归和centerness的结果
# 2 gt_bboxes和gt_labels以及图片信息
# 3 读进来的config
losses = self.bbox_head.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)铺垫都做完了,接下来就可以开始看核心的loss函数了,这里面的代码就是整个论文的核心。
先提前强调几点:
(1) 分类任务的target计算,如果一个anchor点落在gt框内部则为正样本(当然后来作者实验部分说这样不好,应该缩小到一定范围内会更好);进一步,有FPN的加持,很自然能想到分置的策略,就是把大小目标分到各个尺度的特征去负责检测,这样能在一定程度上避免歧义,即一个anchor点同时落在了多个框里;进一步,如果不幸的是分置并没有解决,两个目标差不多大,那么作者就暴力地取了最小的那个目标。
(2) 上面分置的实现是依赖于回归的target的计算的,回归的target如下图所示,算这个点和框的边界之间的距离(注意看论文谁减谁)。
(3) centerness的计算也是依赖于回归的target的。
综上,整个代码的思路是先准备好所有anchor点,然后算他们的回归target,然后算分类和centerness的target,然后计算各自的loss,只有正样本才需要计算回归和centerness。

def loss(self,cls_scores,bbox_preds,centernesses,
gt_bboxes,gt_labels,img_metas,cfg,gt_bboxes_ignore=None):
assert len(cls_scores) == len(bbox_preds) == len(centernesses)
# 获取FPN各个level的特征图的尺寸(高和宽)
featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
# 第一步:根据特征图的高和宽打点anchor,和faster RCNN的框anchor的过程有点像,
# 只不过更简单不需要手工设计不同尺度和比例的anchor而已,详细看下面@111
all_level_points = self.get_points(featmap_sizes, bbox_preds[0].dtype,
bbox_preds[0].device)
# fcos_target看函数名就知道是根据anchor点和gt信息计算target了,详细看下面@222
labels, bbox_targets = self.fcos_target(all_level_points, gt_bboxes,
gt_labels)
num_imgs = cls_scores[0].size(0)
# cls_scores的每个元素是FPN的每个level的分类预测结果
# 如Size为([4, 80, 96, 168])代表NCHW,C为类别数目-1
# permute后变为([4, 96, 168, 80]),reshape后变为(64512, 80)
flatten_cls_scores = [
cls_score.permute(0, 2, 3, 1).reshape(-1, self.cls_out_channels)
for cls_score in cls_scores
]
flatten_bbox_preds = [
bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)
for bbox_pred in bbox_preds
]
flatten_centerness = [
centerness.permute(0, 2, 3, 1).reshape(-1)
for centerness in centernesses
]
# 继而将flatten的各个level的tensor拼接起来
flatten_cls_scores = torch.cat(flatten_cls_scores)
flatten_bbox_preds = torch.cat(flatten_bbox_preds)
flatten_centerness = torch.cat(flatten_centerness)
# labels和bbox_targets是这个batch里各个图的相同level的点anchor的标签拼起来的list
# list每个元素为一个tensor,list的长度为level的数目,
# 所以cat完就是所有level的target放到一整个tensor了
# 这些步骤和上面转换预测结果是一致的,举例说明:
# flatten_cls_scores的size是(所有点的预测结果,80)
# flatten_labels的size是(所有点的预测结果,),存的值是对应的类别的编号(pytorch会自动转成one-hot)
flatten_labels = torch.cat(labels)
flatten_bbox_targets = torch.cat(bbox_targets)
# repeat points to align with bbox_preds
flatten_points = torch.cat(
[points.repeat(num_imgs, 1) for points in all_level_points])
# 找到正样本的索引和数目
pos_inds = flatten_labels.nonzero().reshape(-1)
num_pos = len(pos_inds)
# 这边loss_cls是focal-loss,见cfg文件
loss_cls = self.loss_cls(
flatten_cls_scores, flatten_labels,
avg_factor=num_pos + num_imgs) # avoid num_pos is 0
pos_bbox_preds = flatten_bbox_preds[pos_inds]
pos_centerness = flatten_centerness[pos_inds]
# 只对正样本计算loss
if num_pos > 0:
pos_bbox_targets = flatten_bbox_targets[pos_inds]
# 根据框的target计算centerness的target,是一个[0,1]之间的连续值,1代表中心
pos_centerness_targets = self.centerness_target(pos_bbox_targets)
pos_points = flatten_points[pos_inds]
# 这里要把target转换回框的信息,因为我们要用iou_loss
pos_decoded_bbox_preds = distance2bbox(pos_points, pos_bbox_preds)
pos_decoded_target_preds = distance2bbox(pos_points,
pos_bbox_targets)
# centerness weighted iou loss
# 这边用centerness给IOU-loss加权似乎是论文没有介绍的trick
loss_bbox = self.loss_bbox(
pos_decoded_bbox_preds,
pos_decoded_target_preds,
weight=pos_centerness_targets,
avg_factor=pos_centerness_targets.sum())
# 这边注意下算centerness的loss的时候用的是BCE,
# target是一个连续值(一般我们用BCE的时候target总是离散的,要么0要么1)
loss_centerness = self.loss_centerness(pos_centerness,
pos_centerness_targets)
else:
loss_bbox = pos_bbox_preds.sum()
loss_centerness = pos_centerness.sum()
return dict(
loss_cls=loss_cls,
loss_bbox=loss_bbox,
loss_centerness=loss_centerness)@111我们跳转到这里来看下get_points这个打点anchor的过程:
def get_points(self, featmap_sizes, dtype, device):
mlvl_points = []
# 对FPN的每个level循环
for i in range(len(featmap_sizes)):
# 下面可以看到append的是当前level的(h*w, 2)个点
mlvl_points.append(
self.get_points_single(featmap_sizes[i], self.strides[i],
dtype, device))
return mlvl_points
def get_points_single(self, featmap_size, stride, dtype, device):
h, w = featmap_size
# 把feature map的每个点映射回原图
# feature map的尺度越大(stride越小),则点越密集
x_range = torch.arange(
0, w * stride, stride, dtype=dtype, device=device)
y_range = torch.arange(
0, h * stride, stride, dtype=dtype, device=device)
#meshgrid的结果stack后就是在原图上打的anchor点,记住最后加一个offset:stride // 2,让起点不是0
# 论文解释是能在感受野的中心
y, x = torch.meshgrid(y_range, x_range)
# points的size就是(h*w, 2)
points = torch.stack(
(x.reshape(-1), y.reshape(-1)), dim=-1) + stride // 2
return points # 结束了跳转回loss函数@222打完点就是算target了,因为有三个任务,所以要算三个target,分别是分类,回归和centerness。
def fcos_target(self, points, gt_bboxes_list, gt_labels_list):
assert len(points) == len(self.regress_ranges)
num_levels = len(points)
# expand_as这个函数就是把一个tensor变成和函数括号内一样形状的tensor
# [None]是对应维度增加一维度
# 这里就是把FPN各个层对应的尺度限制转化一下size方便下面用
# 一般情况就是五个范围:regress_ranges=
# ((-1, 64), (64, 128), (128, 256), (256, 512),(512, INF))
expanded_regress_ranges = [
points[i].new_tensor(self.regress_ranges[i])[None].expand_as(
points[i]) for i in range(num_levels)
]
concat_regress_ranges = torch.cat(expanded_regress_ranges, dim=0)
# concat_points代表把各个level的anchor点按照最高维度拼接一下
# points的第i个元素的size为(hi*wi,2),拼接完的shape为(所有level的点的数目,2)
# 之所以合并是为了丢到一个tensor里一起算
concat_points = torch.cat(points, dim=0)
# 对一个batch里的每个图单独算,跳转到下面@333看这个函数fcos_target_single
# 可以看到是算的每个图的每个anchor点的分类target和回归target,然后拼成list
labels_list, bbox_targets_list = multi_apply(
self.fcos_target_single,
gt_bboxes_list,
gt_labels_list,
points=concat_points,
regress_ranges=concat_regress_ranges)
# split to per img, per level
# num_points代表每个level里anchor点的数目
num_points = [center.size(0) for center in points]
# 根据每个level里anchor点的数目拆分每张图的label
# labels_list每个元素是当前图的每个level里的每个点的标签
labels_list = [labels.split(num_points, 0) for labels in labels_list]
bbox_targets_list = [
bbox_targets.split(num_points, 0)
for bbox_targets in bbox_targets_list
]
# concat per level image
concat_lvl_labels = []
concat_lvl_bbox_targets = []
for i in range(num_levels):
# 把这个batch里各个图的相同level的点anchor的标签拼起来
concat_lvl_labels.append(
torch.cat([labels[i] for labels in labels_list]))
concat_lvl_bbox_targets.append(
torch.cat(
[bbox_targets[i] for bbox_targets in bbox_targets_list]))
#总之,我们是拿到了每个batch里每个图的每个level的点anchor的分类标签和回归标签了
# 回到loss函数继续看
return concat_lvl_labels, concat_lvl_bbox_targets @333看fcos_target_single对每张图单独算的这个函数,这里面写的有点绕,需要静下心来把各个变量的size搞清楚就很清晰了:
def fcos_target_single(self, gt_bboxes, gt_labels, points, regress_ranges):
num_points = points.size(0)
num_gts = gt_labels.size(0)
if num_gts == 0:
return gt_labels.new_zeros(num_points), \
gt_bboxes.new_zeros((num_points, 4))
# gt_bboxes的size为(num_gts,4)
# 所以areas就是算各个gt的面积,size为(num_gts,)
areas = (gt_bboxes[:, 2] - gt_bboxes[:, 0] + 1) * (
gt_bboxes[:, 3] - gt_bboxes[:, 1] + 1)
# 所以repeat就是把对应维度复制(一维要向上补),size为(num_points,num_gts)
areas = areas[None].repeat(num_points, 1)
regress_ranges = regress_ranges[:, None, :].expand(num_points, num_gts, 2)
# gt_bboxes的size为(num_gts,4),加个[None]就是加一维,变为[1,num_gts,4]
# 继续expand变为指定维度(num_points, num_gts, 4)
gt_bboxes = gt_bboxes[None].expand(num_points, num_gts, 4)
# points之前说了size为(num_points,2),所以xs就是(num_points,)
xs, ys = points[:, 0], points[:, 1]
# 所以[:, None]就是(num_points,1),expand之后就是(num_points,num_gts)
xs = xs[:, None].expand(num_points, num_gts)
ys = ys[:, None].expand(num_points, num_gts)
#gt_bboxes的size为(num_points, num_gts, 4),取[..., 0]后变为(num_points, num_gts)
#所以很明显这里其实就是每个点和每个框之间的上下左右的差值
left = xs - gt_bboxes[..., 0]
right = gt_bboxes[..., 2] - xs
top = ys - gt_bboxes[..., 1]
bottom = gt_bboxes[..., 3] - ys
# stack完了之后就变为(num_points, num_gts,4)
bbox_targets = torch.stack((left, top, right, bottom), -1)
# 找到(l,r,t,b)中最小的,如果最小的大于0,那么这个点肯定在对应的gt框里面,则置1,否则为0
inside_gt_bbox_mask = bbox_targets.min(-1)[0] > 0
# 找到(l,r,t,b)中最大的,如果最大的满足范围约束,则置1,否则为0
max_regress_distance = bbox_targets.max(-1)[0]
inside_regress_range = (
max_regress_distance >= regress_ranges[..., 0]) & (
max_regress_distance <= regress_ranges[..., 1])
# areas的size为(num_points,num_gts),我们将框外面的点对应的area置为无穷
areas[inside_gt_bbox_mask == 0] = INF
# 将不满足范围约束的也置为无穷,因为下面的代码要找最小的
areas[inside_regress_range == 0] = INF
# 找到每个点对应的面积最小的gt框(因为可能有多个,论文取了最小的)
# min_area和min_area_inds的size都为(num_points,)
min_area, min_area_inds = areas.min(dim=1)
# labels的size为(num_gts,),gt_labels[min_area_inds]的操作就是
# 生成和min_area_inds的size一样的tensor,每个位置的值是索引对应的gt_label值
# 所以labels的size为(num_points,),即为每个点的label
labels = gt_labels[min_area_inds]
# 注意一下把负样本置0,因为如果点是负样本,则areas.min(dim=1)因为都是INF
# 所以最小的索引取第一个为0,则对应第一个label值是不对的,要修正为负样本0
labels[min_area == INF] = 0
# 生成的bbox_targets的size为(num_points,4),即每个点对应的target
bbox_targets = bbox_targets[range(num_points), min_area_inds]
# 所以返回值为每个点的分类label和回归target
# size分别为(num_points,)和(num_points,4)
return labels, bbox_targetsfcos大致训练的过程就是这样了。赶紧训练一个玩玩吧~
----------------分割线--------------------
最近非常沮丧,负能量爆炸,看到老詹带领湖人接连战胜雄鹿和快船,算是给自己重燃了斗志,追求卓越,负重前行!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
2019-01-07 tf-maskrcnn