

<scrapy爬虫>Spiders的用法
1、能够创建scrapy项目、编写个简单的蜘蛛并运行蜘蛛;
2、能够简单的使用scrapy shell 调试数据;
3、能够使用scrapy css选择器提取简单数据;
4、除了能够提取一页数据,还要能提取下一页、在下一页。
1、scrapy如何打开页面?
蜘蛛从互联网的本质出发,我们浏览页面都是一个:发送请求、返回请求的过程,那蜘蛛要发送请求,那总得要有请求链接,因此引出了scrapy spiders的第一个必须的常量:start_urls
URL有两种写法,一种作为类的常量、一种作为start_requests(self)方法的常量,无论哪一种写法,URL都是必须的!如果URL是定义在start_request(self)这个方法里面,那我们就要使用: yield scrapy.Request 方法发送请求:如下:
import scrapy
class simpleUrl(scrapy.Spider):
name = "simpleUrl"
# 另外一种初始链接写法
def start_requests(self):
urls = [ #爬取的链接由此方法通过下面链接爬取页面
'http://lab.scrapyd.cn/page/1/',
'http://lab.scrapyd.cn/page/2/',
]
for url in urls:
#发送请求
yield scrapy.Request(url=url, callback=self.parse)
这样写的一个麻烦之处就是我们需要处理我们的返回,也就是我们还需要写一个callback方法来处理response;因此大多数我们都是把URL作为类的常量,然后再加上另外一个方法:parse(response)
使用这个方法来发送请求,可以看到里面有个参数已经是:response(返回),也就是说这个方自动化的完成了:request(请求页面)-response(返回页面)的过程,我们就不必要再写函数接受返回,所以这样就比较方便了!
import scrapy
class simpleUrl(scrapy.Spider):
name = "simpleUrl"
start_urls = [ #另外一种写法,无需定义start_requests方法
'http://lab.scrapyd.cn/page/1/',
'http://lab.scrapyd.cn/page/2/',
]
def parse(self, response):
page = response.url.split("/")[-2]
filename = 'mingyan-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('保存文件: %s' % filename)
好了,这就是scrapy打开页面的方法;页面打开后是不是我们就该提取数据了?那scrapy如何提取?
2、scrapy如何提取数据?
如何获取页面里面的内容?类比,人类如何做的呢?肯定是用眼睛查找!同理scrapy也有眼睛,分别是:css选择器、xpath选择器、正则,这三双眼睛实现的功能都一样:万军从中直取上将,说白了就是查找的功能!标签属性值提取、标签内容提取;
一、scrapy xpath 属性提取

3、scrapy如何保存数据?
scrapy命令明细:全局命令
scrapy startproject(创建项目)、
scrapy crawl XX(运行XX蜘蛛)、
scrapy shell http://www.scrapyd.cn(调试网址为http://www.scrapyd.cn的网站),
startproject genspider settings runspider shell fetch view version
一、startproject
这个是见得最多,创建项目的,如,创建一个名为:scrapyChina的项目:
scrapy strartproject scrapychina
用法灰常简单,你能看到这里,应该已经用过多次了,就这么简单;
二、genspider
这个命令是给我们创建蜘蛛模板的,example是蜘蛛名,example.com是start_urls,明白之后根据项目创建一个有针对性的,既然是爬淘宝,那我们就输入 :名称不能和项目相同
scrapy genspider taobao taobao.com
查看命令帮助
scrapy genspider -h
可以看到,scrapy genspider有如下格式:
scrapy genspider [options] <name> <domain>
<name>和<domain>上面已经使用过![options] 是神马呢,可以看到,也就是可以加如下几个参数:
Options
=======
--help, -h show this help message and exit
--list, -l List available templates
--edit, -e Edit spider after creating it
--dump=TEMPLATE, -d TEMPLATE
Dump template to standard output
--template=TEMPLATE, -t TEMPLATE
Uses a custom template.
--force If the spider already exists, overwrite it with the
template
详细帮助
scrapy genspider -l
得到如下信息
Available templates: basic crawl csvfeed xmlfeed
这里的意思是可用的模板,那也就是说我们可以用上面的模板输出我们的蜘蛛文件,但是要结合下面的参数 -t 一起用,来,试一下:
scrapy genspider -t crawl taobao2 taobao.com
执行之后,你会发现,又给我们创建了一个名为:taobao2的蜘蛛,但是里面的蜘蛛格式是:crawl类型:
三、settings
它就是方便你查看到你对你的scray设置了些神马参数!比如我们想得到蜘蛛的下载延迟,我们可以使用:
scrapy settings --get DOWNLOAD_DELAY
比如我们想得到蜘蛛的名字:
scrapy settings --get BOT_NAME
四、runspider
运行蜘蛛除了使用:scrapy crawl XX之外,我们还能用:runspider,前者是基于项目运行,后者是基于文件运行,也就是说你按照scrapy的蜘蛛格式编写了一个py文件,那你不想创建项目,那你就可以使用runspider,比如你编写了一个:scrapyd_cn.py的蜘蛛,你要直接运行就是:
scrapy runspider scrapy_cn.py
五、shell
主要是调试用,里面还有很多细节的命令,这里的话你需要记住它的使用方法,比如我们要调试http://www.scrapyd.cn
scrapy shell http://www.scrapyd.cn
然后我们可以直接执行命令,response,比如我们要测试我们获取标题的选择器正不正确,我们可以这样:
response.css("title").extract_first()
基本上,这就是这个命令最常用的用法,应该记住它就是调试用的
六、fetch
这个命令其实也可以归结为调试命令的范畴!它的功效就是模拟我们的蜘蛛下载页面,也就是说用这个命令下载的页面就是我们蜘蛛运行时下载的页面,这样的好处就是能准确诊断出,我们的到的html结构到底是不是我们所看到的,然后能及时调整我们编写爬虫的策略
scrapy fetch http://www.scrapyd.cn
就这样,如果你要把它下载的页面保存到一个html文件中进行分析,我们可以使用window或者linux的输出命令,这里演示window下如下如何把下载的页面保存:
scrapy fetch http://www.scrapyd.cn >d:/3.html
经过这个命令,scrapy下载的html文件已经被存储,接下来你就全文找找,看有木有那个节点,木有的话,毫无悬念,使用了异步加载!
七、view
和fetch类似都是查看蜘蛛看到的是否和你看到的一致,便于排错,用法:
scrapy view http://www.scrapyd.cn
八、version
查看scrapy版本,用法:
scrapy version
scrapy 命令行:scrpay项目命令
crawl check list edit parse bench
1、crawl:运行蜘蛛
例:我们要运行name = scrapyd_cn的蜘蛛,我们可以这样:
scrapy crawl scrapyd_cn
2、check:检查蜘蛛
3、list:显示有多少个蜘蛛
这里的蜘蛛就是指spider文件夹下面xx.py文件中定义的name,你有10个py文件但是只有一个定义了蜘蛛的name,那只算一个蜘蛛,比如我们在:AoiSolas目录下运行这个命令:
scrapy list
它其实就是得到了我们的蜘蛛名字!
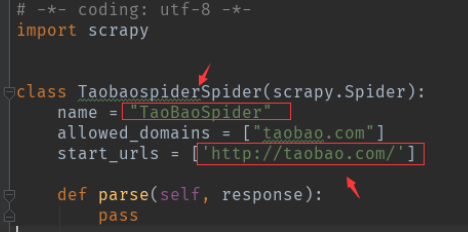
scrapy.Spider
name:定义此蜘蛛名称的字符串。
allowed_domains:包含允许此蜘蛛爬行的域的字符串的可选列表。
start_urls:当没有指定特定的URL时,蜘蛛将从中开始爬行的URL列表。
custom_settings:运行此spider时,将从项目范围配置中重写的设置字典。它必须被定义为类属性,因为在实例化之前更新了设置。-----用来覆盖全局配置

crawler:此属性由 from_crawler() 初始化类后的类方法,并链接到 Crawler 此蜘蛛实例绑定到的对象。Crawler封装了项目中的许多组件,用于它们的单入口访问(例如扩展、中间件、信号管理器等)。
settings:用于运行此蜘蛛的配置。这是一个 Settings 实例
logger:用蜘蛛创建的python记录器 name . 您可以使用它通过它发送日志消息
from_crawler(crawler, *args, **kwargs):这是Scrapy用来创建蜘蛛的类方法。此方法设置了 crawler 和 settings 新实例中的属性,以便稍后在蜘蛛代码中访问它们。

start_requests():此方法必须返回一个iterable,其中包含对此spider进行爬网的第一个请求。当蜘蛛被打开爬取的时候,它被称为 Scrapy。Scrapy只调用一次

class MySpider(scrapy.Spider):
name = 'myspider'
def start_requests(self):
return [scrapy.FormRequest("http://www.example.com/login",
formdata={'user': 'john', 'pass': 'secret'},
callback=self.logged_in)]
def logged_in(self, response):
# here you would extract links to follow and return Requests for
# each of them, with another callback
pass
parse(response):这是Scrapy在请求未指定回调时用来处理下载响应的默认回调。这个 parse 方法负责处理响应,并返回 爬取 的数据和/或更多的URL。此方法以及任何其他请求回调都必须返回 Request 和/或DICT或 Item 物体。
log(message[, level, component]):通过Spider的 logger ,保持向后兼容性。
closed(reason):蜘蛛关闭时调用。此方法为 spider_closed 信号。
Item Pipeline-项目管道(数据清洗,去重,存储到数据库)
项目管道的典型用途有:
- 清理HTML数据
- 验证抓取的数据(检查项目是否包含某些字段)
- 检查重复项(并删除它们)
- 将爬取的项目存储在数据库中
编写自己的项目管道
每个item pipeline组件都是一个python类,必须实现以下方法:
process_item(self, item, spider)---通过yield生成的item,spider是运行的爬虫实例
对每个项管道组件调用此方法。 process_item() 必须:返回包含数据的dict,返回 Item (或任何后代类)对象,返回 Twisted Deferred 或提高 DropItem 例外。删除的项不再由其他管道组件处理。
成功返回:返回 Item (或任何后代类)对象,
失败返回:DropItem
open_spider(self, spider):当spider打开时调用此方法
close_spider(self, spider):当spider关闭时调用此方法。
from_crawler(cls, crawler):获取项目的配置信息
例子:价格处理pipeLine
from scrapy.exceptions import DropItem
class PricePipeline(object):
vat_factor = 1.15
def process_item(self, item, spider):
if item.get('price'):
if item.get('price_excludes_vat'):
item['price'] = item['price'] * self.vat_factor
return item
else:
raise DropItem("Missing price in %s" % item)
例子:写入JSON
import json
class JsonWriterPipeline(object):
def open_spider(self, spider):
self.file = open('items.jl', 'w')
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item
例子:写入Mongo
import pymongo
class MongoPipeline(object):
collection_name = 'scrapy_items'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert_one(dict(item))
return item
例子:下载图片
import scrapy
import hashlib
from urllib.parse import quote
class ScreenshotPipeline(object):
"""Pipeline that uses Splash to render screenshot of
every Scrapy item."""
SPLASH_URL = "http://localhost:8050/render.png?url={}"
def process_item(self, item, spider):
encoded_item_url = quote(item["url"])
screenshot_url = self.SPLASH_URL.format(encoded_item_url)
request = scrapy.Request(screenshot_url)
dfd = spider.crawler.engine.download(request, spider)
dfd.addBoth(self.return_item, item)
return dfd
def return_item(self, response, item):
if response.status != 200:
# Error happened, return item.
return item
# Save screenshot to file, filename will be hash of url.
url = item["url"]
url_hash = hashlib.md5(url.encode("utf8")).hexdigest()
filename = "{}.png".format(url_hash)
with open(filename, "wb") as f:
f.write(response.body)
# Store filename in item.
item["screenshot_filename"] = filename
return item
例子:去重
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item
DownLoader Middleware--下载器中间件
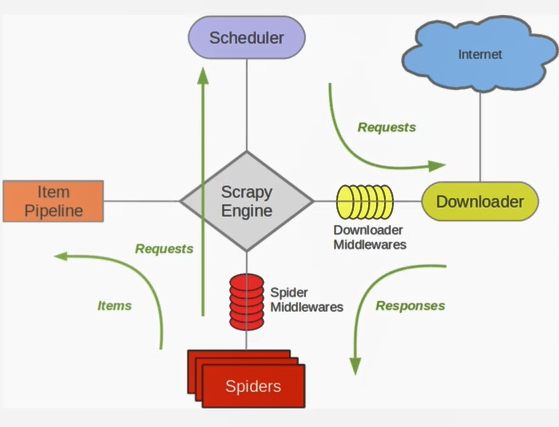
可以在request进入下载器的时候和response进入爬虫的时候,,在这个过程中可以对request和response进行改写
下载器中间件是Scrapy请求/响应处理的钩子框架。
编写自己的下载中间件
主要入口点是 from_crawler 类方法,它接收 Crawler 实例。这个 Crawler 例如,对象允许您访问 settings .
classscrapy.downloadermiddlewares.DownloaderMiddleware
process_request(request, spider):对于通过下载中间件的每个请求调用此方法。
返回 None :对整个框架无影响
返回 Response 对象:不在调用其他中间件的process_request方法,而会执行其他中间件的process_response
返回 Request 对象:将request重新放入调度队列,一直重复
返回 IgnoreRequest :异常,被其他中间件的process_exception() 进行捕获,如果它们都不处理异常,则请求的errback函数 (Request.errback ),如果没有代码处理引发的异常,则忽略该异常,不记录该异常(与其他异常不同)。
请求的时候加代理,可以执行此方法


process_response(request, response, spider):
返回 Response 对象:继续运行其他中间件的process_response方法,对其他中间件没有什么影响
返回 Request 对象:不会在调用其他中间键的process_response方法,将request重新加入调度队列中进行下载
返回 IgnoreRequest异常:调用异常处理方法,进行异常处理
改写状态码

process_exception(request, exception, spider):捕捉异常,处理异常
返回 None :不影响其他操作,Scrapy将继续处理异常,执行其他中间件的 process_exception() 方法,直到没有中间件,默认的异常处理开始。
返回 Response 对象:执行其他中间件的 process_response() 方法,Scrapy不会调用其他process_exception方法。
返回 Request 对象:重新加入调度队列以便将来下载。Scrapy不会调用其他process_exception方法。
可以进行失败的重试

捕捉异常后,可以添加代理再次重试

超时时间的设定-在spider中

from_crawler(cls, crawler):获取项目的配置信息
CookiesMiddleware
此中间件允许使用需要cookie的站点,例如那些使用会话的站点。
请思考 parse()方法的工作机制:
1. 因为使用的yield,而不是return。parse函数将会被当做一个生成器使用。scrapy会逐一获取parse方法中生成的结果,并判断该结果是一个什么样的类型;
2. 如果是request则加入爬取队列,如果是item类型则使用pipeline处理,其他类型则返回错误信息。
3. scrapy取到第一部分的request不会立马就去发送这个request,只是把这个request放到队列里,然后接着从生成器里获取;
4. 取尽第一部分的request,然后再获取第二部分的item,取到item了,就会放到对应的pipeline里处理;
5. parse()方法作为回调函数(callback)赋值给了Request,指定parse()方法来处理这些请求 scrapy.Request(url, callback=self.parse)
6. Request对象经过调度,执行生成 scrapy.http.response()的响应对象,并送回给parse()方法,直到调度器中没有Request(递归的思路)
7. 取尽之后,parse()工作结束,引擎再根据队列和pipelines中的内容去执行相应的操作;
8. 程序在取得各个页面的items前,会先处理完之前所有的request队列里的请求,然后再提取items。
7. 这一切的一切,Scrapy引擎和调度器将负责到底。
CrawlSpiders
创建带模板的spider
scrapy genspider -t crawl tencent tencent.com
spider
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
from mySpider.items import TencentItem
class TencentSpider(CrawlSpider):
name = "tencent"
allowed_domains = ["hr.tencent.com"]
start_urls = [
"http://hr.tencent.com/position.php?&start=0#a"
]
page_lx = LinkExtractor(allow=("start=\d+"))
rules = [
Rule(page_lx, callback = "parseContent", follow = True)
]
def parseContent(self, response):
for each in response.xpath('//*[@class="even"]'):
name = each.xpath('./td[1]/a/text()').extract()[0]
detailLink = each.xpath('./td[1]/a/@href').extract()[0]
positionInfo = each.xpath('./td[2]/text()').extract()[0]
peopleNumber = each.xpath('./td[3]/text()').extract()[0]
workLocation = each.xpath('./td[4]/text()').extract()[0]
publishTime = each.xpath('./td[5]/text()').extract()[0]
#print name, detailLink, catalog,recruitNumber,workLocation,publishTime
item = TencentItem()
item['name']=name.encode('utf-8')
item['detailLink']=detailLink.encode('utf-8')
item['positionInfo']=positionInfo.encode('utf-8')
item['peopleNumber']=peopleNumber.encode('utf-8')
item['workLocation']=workLocation.encode('utf-8')
item['publishTime']=publishTime.encode('utf-8')
yield item
# parse() 方法不需要写
# def parse(self, response):
# pass
Logging
Scrapy提供了log功能,可以通过 logging 模块使用。
可以修改配置文件settings.py,任意位置添加下面两行,效果会清爽很多。
LOG_FILE = "TencentSpider.log"
LOG_LEVEL = "INFO"
Log levels
-
Scrapy提供5层logging级别:
-
CRITICAL - 严重错误(critical)
- ERROR - 一般错误(regular errors)
- WARNING - 警告信息(warning messages)
- INFO - 一般信息(informational messages)
- DEBUG - 调试信息(debugging messages)
logging设置
通过在setting.py中进行以下设置可以被用来配置logging:
LOG_ENABLED默认: True,启用loggingLOG_ENCODING默认: 'utf-8',logging使用的编码LOG_FILE默认: None,在当前目录里创建logging输出文件的文件名LOG_LEVEL默认: 'DEBUG',log的最低级别LOG_STDOUT默认: False 如果为 True,进程所有的标准输出(及错误)将会被重定向到log中。例如,执行 print "hello" ,其将会在Scrapy log中显示。
发送POST请求
class mySpider(scrapy.Spider):
# start_urls = ["http://www.example.com/"]
def start_requests(self):
url = 'http://www.renren.com/PLogin.do'
# FormRequest 是Scrapy发送POST请求的方法
yield scrapy.FormRequest(
url = url,
formdata = {"email" : "mr_mao_hacker@163.com", "password" : "axxxxxxxe"},
callback = self.parse_page
)
def parse_page(self, response):
# do something
模拟登陆
通常网站通过 实现对某些表单字段(如数据或是登录界面中的认证令牌等)的预填充。
使用Scrapy抓取网页时,如果想要预填充或重写像用户名、用户密码这些表单字段, 可以使用 FormRequest.from_response() 方法实现。
下面是使用这种方法的爬虫例子:
import scrapy
class LoginSpider(scrapy.Spider):
name = 'example.com'
start_urls = ['http://www.example.com/users/login.php']
def parse(self, response):
return scrapy.FormRequest.from_response(
response,
formdata={'username': 'john', 'password': 'secret'},
callback=self.after_login
)
def after_login(self, response):
# check login succeed before going on
if "authentication failed" in response.body:
self.log("Login failed", level=log.ERROR)
return
# continue scraping with authenticated session...
修改替换链接

scrapy模拟登录的三种方式
注意:模拟登陆时,必须保证settings.py里的 COOKIES_ENABLED(Cookies中间件) 处于开启状态
COOKIES_ENABLED = True 或 # COOKIES_ENABLED = False
策略一:直接POST数据(比如需要登陆的账户信息)
# -*- coding: utf-8 -*-
import scrapy
class Renren1Spider(scrapy.Spider):
name = "renren1"
allowed_domains = ["renren.com"]
def start_requests(self):
url = 'http://www.renren.com/PLogin.do'
# FormRequest 是Scrapy发送POST请求的方法
yield scrapy.FormRequest(
url = url,
formdata = {"email" : "mr_mao_hacker@163.com", "password" : "axxxxxxxe"},
callback = self.parse_page)
def parse_page(self, response):
with open("mao2.html", "w") as filename:
filename.write(response.body)
策略二:标准的模拟登陆步骤
正统模拟登录方法: 首先发送登录页面的get请求,获取到页面里的登录必须的参数(比如说zhihu登陆界面的 _xsrf) 然后和账户密码一起post到服务器,登录成功
# -*- coding: utf-8 -*-
import scrapy
class Renren2Spider(scrapy.Spider):
name = "renren2"
allowed_domains = ["renren.com"]
start_urls = (
"http://www.renren.com/PLogin.do",
)
# 处理start_urls里的登录url的响应内容,提取登陆需要的参数(如果需要的话)
def parse(self, response):
# 提取登陆需要的参数
#_xsrf = response.xpath("//_xsrf").extract()[0]
# 发送请求参数,并调用指定回调函数处理
yield scrapy.FormRequest.from_response(
response,
formdata = {"email" : "mr_mao_hacker@163.com", "password" : "axxxxxxxe"},#, "_xsrf" = _xsrf},
callback = self.parse_page
)
# 获取登录成功状态,访问需要登录后才能访问的页面
def parse_page(self, response):
url = "http://www.renren.com/422167102/profile"
yield scrapy.Request(url, callback = self.parse_newpage)
# 处理响应内容
def parse_newpage(self, response):
with open("xiao.html", "w") as filename:
filename.write(response.body)
策略三:直接使用保存登陆状态的Cookie模拟登陆
如果实在没办法了,可以用这种方法模拟登录,虽然麻烦一点,但是成功率100%
# -*- coding: utf-8 -*-
import scrapy
class RenrenSpider(scrapy.Spider):
name = "renren"
allowed_domains = ["renren.com"]
start_urls = (
'http://www.renren.com/111111',
'http://www.renren.com/222222',
'http://www.renren.com/333333',
)
cookies = {
"anonymid" : "ixrna3fysufnwv",
"_r01_" : "1",
"ap" : "327550029",
"JSESSIONID" : "abciwg61A_RvtaRS3GjOv",
"depovince" : "GW",
"springskin" : "set",
"jebe_key" : "f6fb270b-d06d-42e6-8b53-e67c3156aa7e%7Cc13c37f53bca9e1e7132d4b58ce00fa3%7C1484060607478%7C1%7C1486198628950",
"t" : "691808127750a83d33704a565d8340ae9",
"societyguester" : "691808127750a83d33704a565d8340ae9",
"id" : "327550029",
"xnsid" : "f42b25cf",
"loginfrom" : "syshome"
}
# 可以重写Spider类的start_requests方法,附带Cookie值,发送POST请求
def start_requests(self):
for url in self.start_urls:
yield scrapy.FormRequest(url, cookies = self.cookies, callback = self.parse_page)
# 处理响应内容
def parse_page(self, response):
print "===========" + response.url
with open("deng.html", "w") as filename:
filename.write(response.body)
知乎爬虫参考
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from scrapy.spiders import CrawlSpider, Rule
from scrapy.selector import Selector
from scrapy.linkextractors import LinkExtractor
from scrapy import Request, FormRequest
from zhihu.items import ZhihuItem
class ZhihuSipder(CrawlSpider) :
name = "zhihu"
allowed_domains = ["www.zhihu.com"]
start_urls = [
"http://www.zhihu.com"
]
rules = (
Rule(LinkExtractor(allow = ('/question/\d+#.*?', )), callback = 'parse_page', follow = True),
Rule(LinkExtractor(allow = ('/question/\d+', )), callback = 'parse_page', follow = True),
)
headers = {
"Accept": "*/*",
"Accept-Encoding": "gzip,deflate",
"Accept-Language": "en-US,en;q=0.8,zh-TW;q=0.6,zh;q=0.4",
"Connection": "keep-alive",
"Content-Type":" application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36",
"Referer": "http://www.zhihu.com/"
}
#重写了爬虫类的方法, 实现了自定义请求, 运行成功后会调用callback回调函数
def start_requests(self):
return [Request("https://www.zhihu.com/login", meta = {'cookiejar' : 1}, callback = self.post_login)]
def post_login(self, response):
print 'Preparing login'
#下面这句话用于抓取请求网页后返回网页中的_xsrf字段的文字, 用于成功提交表单
xsrf = Selector(response).xpath('//input[@name="_xsrf"]/@value').extract()[0]
print xsrf
#FormRequeset.from_response是Scrapy提供的一个函数, 用于post表单
#登陆成功后, 会调用after_login回调函数
return [FormRequest.from_response(response, #"http://www.zhihu.com/login",
meta = {'cookiejar' : response.meta['cookiejar']},
headers = self.headers, #注意此处的headers
formdata = {
'_xsrf': xsrf,
'email': '1095511864@qq.com',
'password': '123456'
},
callback = self.after_login,
dont_filter = True
)]
def after_login(self, response) :
for url in self.start_urls :
yield self.make_requests_from_url(url)
def parse_page(self, response):
problem = Selector(response)
item = ZhihuItem()
item['url'] = response.url
item['name'] = problem.xpath('//span[@class="name"]/text()').extract()
print item['name']
item['title'] = problem.xpath('//h2[@class="zm-item-title zm-editable-content"]/text()').extract()
item['description'] = problem.xpath('//div[@class="zm-editable-content"]/text()').extract()
item['answer']= problem.xpath('//div[@class=" zm-editable-content clearfix"]/text()').extract()
return item
反爬虫,在下载中间键
-
动态设置User-Agent(随机切换User-Agent,模拟不同用户的浏览器信息)
-
禁用Cookies(也就是不启用cookies middleware,不向Server发送cookies,有些网站通过cookie的使用发现爬虫行为)
- 可以通过
COOKIES_ENABLED控制 CookiesMiddleware 开启或关闭
- 可以通过
-
设置延迟下载(防止访问过于频繁,设置为 2秒 或更高)
-
Google Cache 和 Baidu Cache:如果可能的话,使用谷歌/百度等搜索引擎服务器页面缓存获取页面数据。
-
使用IP地址池:VPN和代理IP,现在大部分网站都是根据IP来ban的。
-
使用 Crawlera(专用于爬虫的代理组件),正确配置和设置下载中间件后,项目所有的request都是通过crawlera发出。
-
DOWNLOADER_MIDDLEWARES = { 'scrapy_crawlera.CrawleraMiddleware': 600 } CRAWLERA_ENABLED = True CRAWLERA_USER = '注册/购买的UserKey' CRAWLERA_PASS = '注册/购买的Password'
-
下载中间件是处于引擎(crawler.engine)和下载器(crawler.engine.download())之间的一层组件,可以有多个下载中间件被加载运行。
process_request(self, request, spider)
-
当每个request通过下载中间件时,该方法被调用。
-
process_request() 必须返回以下其中之一:一个 None 、一个 Response 对象、一个 Request 对象或 raise IgnoreRequest:
-
如果其返回 None ,Scrapy将继续处理该request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download handler)被调用, 该request被执行(其response被下载)。
-
如果其返回 Response 对象,Scrapy将不会调用 任何 其他的 process_request() 或 process_exception() 方法,或相应地下载函数; 其将返回该response。 已安装的中间件的 process_response() 方法则会在每个response返回时被调用。
-
如果其返回 Request 对象,Scrapy则停止调用 process_request方法并重新调度返回的request。当新返回的request被执行后, 相应地中间件链将会根据下载的response被调用。
-
如果其raise一个 IgnoreRequest 异常,则安装的下载中间件的 process_exception() 方法会被调用。如果没有任何一个方法处理该异常, 则request的errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录(不同于其他异常那样)。
-
-
参数:
request (Request 对象)– 处理的requestspider (Spider 对象)– 该request对应的spider
process_response(self, request, response, spider)
当下载器完成http请求,传递响应给引擎的时候调用
-
process_request() 必须返回以下其中之一: 返回一个 Response 对象、 返回一个 Request 对象或raise一个 IgnoreRequest 异常。
-
如果其返回一个 Response (可以与传入的response相同,也可以是全新的对象), 该response会被在链中的其他中间件的 process_response() 方法处理。
-
如果其返回一个 Request 对象,则中间件链停止, 返回的request会被重新调度下载。处理类似于 process_request() 返回request所做的那样。
-
如果其抛出一个 IgnoreRequest 异常,则调用request的errback(Request.errback)。 如果没有代码处理抛出的异常,则该异常被忽略且不记录(不同于其他异常那样)。
-
-
参数:
request (Request 对象)– response所对应的requestresponse (Response 对象)– 被处理的responsespider (Spider 对象)– response所对应的spider
-
当引擎传递请求给下载器的过程中,下载中间件可以对请求进行处理 (例如增加http header信息,增加proxy信息等);
-
在下载器完成http请求,传递响应给引擎的过程中, 下载中间件可以对响应进行处理(例如进行gzip的解压等)
要激活下载器中间件组件,将其加入到 DOWNLOADER_MIDDLEWARES 设置中。 该设置是一个字典(dict),键为中间件类的路径,值为其中间件的顺序(order)。
中间件案例
# middlewares.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import random
import base64
from settings import USER_AGENTS
from settings import PROXIES
# 随机的User-Agent
class RandomUserAgent(object):
def process_request(self, request, spider):
useragent = random.choice(USER_AGENTS)
request.headers.setdefault("User-Agent", useragent)
class RandomProxy(object):
def process_request(self, request, spider):
proxy = random.choice(PROXIES)
if proxy['user_passwd'] is None:
# 没有代理账户验证的代理使用方式
request.meta['proxy'] = "http://" + proxy['ip_port']
else:
# 对账户密码进行base64编码转换
base64_userpasswd = base64.b64encode(proxy['user_passwd'])
# 对应到代理服务器的信令格式里
request.headers['Proxy-Authorization'] = 'Basic ' + base64_userpasswd
request.meta['proxy'] = "http://" + proxy['ip_port']
反爬很厉害,可以利用百度快照爬到网页数据
2. 修改settings.py配置USER_AGENTS和PROXIES
- 添加USER_AGENTS:
-
USER_AGENTS = [ "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5" ]
-
- 添加代理IP设置PROXIES:
-
ROXIES = [ {'ip_port': '111.8.60.9:8123', 'user_passwd': 'user1:pass1'}, {'ip_port': '101.71.27.120:80', 'user_passwd': 'user2:pass2'}, {'ip_port': '122.96.59.104:80', 'user_passwd': 'user3:pass3'}, {'ip_port': '122.224.249.122:8088', 'user_passwd': 'user4:pass4'}, ]
-
- 除非特殊需要,禁用cookies,防止某些网站根据Cookie来封锁爬虫。
-
COOKIES_ENABLED = False
-
- 设置下载延迟
-
DOWNLOAD_DELAY = 3
-
- 最后设置setting.py里的DOWNLOADER_MIDDLEWARES,添加自己编写的下载中间件类。
-
DOWNLOADER_MIDDLEWARES = { #'mySpider.middlewares.MyCustomDownloaderMiddleware': 543, 'mySpider.middlewares.RandomUserAgent': 1, 'mySpider.middlewares.ProxyMiddleware': 100 }
-
-
Settings
Scrapy设置(settings)提供了定制Scrapy组件的方法。可以控制包括核心(core),插件(extension),pipeline及spider组件。比如 设置Json Pipeliine、LOG_LEVEL等。
参考文档:http://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/settings.html#topics-settings-ref
内置设置参考手册
-
BOT_NAME-
默认: 'scrapybot'
-
当您使用 startproject 命令创建项目时其也被自动赋值。
-
-
CONCURRENT_ITEMS-
默认: 100
-
Item Processor(即 Item Pipeline) 同时处理(每个response的)item的最大值。
-
-
CONCURRENT_REQUESTS-
默认: 16
-
Scrapy downloader 并发请求(concurrent requests)的最大值。
-
-
DEFAULT_REQUEST_HEADERS-
默认: 如下
{ 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', }Scrapy HTTP Request使用的默认header。
-
-
DEPTH_LIMIT-
默认: 0
-
爬取网站最大允许的深度(depth)值。如果为0,则没有限制。
-
-
DOWNLOAD_DELAY-
默认: 0
-
下载器在下载同一个网站下一个页面前需要等待的时间。该选项可以用来限制爬取速度, 减轻服务器压力。同时也支持小数:
DOWNLOAD_DELAY = 0.25 # 250 ms of delay- 默认情况下,Scrapy在两个请求间不等待一个固定的值, 而是使用0.5到1.5之间的一个随机值 * DOWNLOAD_DELAY 的结果作为等待间隔。
-
-
DOWNLOAD_TIMEOUT-
默认: 180
-
下载器超时时间(单位: 秒)。
-
-
ITEM_PIPELINES-
默认: {}
-
保存项目中启用的pipeline及其顺序的字典。该字典默认为空,值(value)任意,不过值(value)习惯设置在0-1000范围内,值越小优先级越高。
ITEM_PIPELINES = { 'mySpider.pipelines.SomethingPipeline': 300, 'mySpider.pipelines.ItcastJsonPipeline': 800, }
-
-
LOG_ENABLED-
默认: True
-
是否启用logging。
-
-
LOG_ENCODING-
默认: 'utf-8'
-
logging使用的编码。
-
-
LOG_LEVEL-
默认: 'DEBUG'
-
log的最低级别。可选的级别有: CRITICAL、 ERROR、WARNING、INFO、DEBUG 。
-
-
USER_AGENT-
默认: "Scrapy/VERSION (+http://scrapy.org)"
-
爬取的默认User-Agent,除非被覆盖。
-
-
PROXIES: 代理设置-
示例:
PROXIES = [ {'ip_port': '111.11.228.75:80', 'password': ''}, {'ip_port': '120.198.243.22:80', 'password': ''}, {'ip_port': '111.8.60.9:8123', 'password': ''}, {'ip_port': '101.71.27.120:80', 'password': ''}, {'ip_port': '122.96.59.104:80', 'password': ''}, {'ip_port': '122.224.249.122:8088', 'password':''}, ]
-
-
COOKIES_ENABLED = False- 禁用Cookies
{'downloader/exception_count': 1781, # 异常数量
'downloader/exception_type_count/twisted.internet.error.ConnectionRefusedError': 34, # 链接错误数量
'downloader/exception_type_count/twisted.internet.error.TimeoutError': 1724, # 超时数量
'downloader/exception_type_count/twisted.web._newclient.ResponseFailed': 7, # 页面响应错误数量
'downloader/exception_type_count/twisted.web._newclient.ResponseNeverReceived': 16, # 没有找到的数量
'downloader/request_bytes': 11834762, # 请求字节大小
'downloader/request_count': 30080, # 请求次数
'downloader/request_method_count/GET': 30080, # GET请求次数
'downloader/response_bytes': 762108730, # 响应字节大小
'downloader/response_count': 28299, # 响应次数
'downloader/response_status_count/200': 28299, # 状态码为200的次数
'finish_reason': 'finished', # 爬虫结束原因
'finish_time': datetime.datetime(2019, 8, 5, 8, 22, 4, 856127), # 爬虫结束时间
'log_count/ERROR': 1, # 日志记录ERROR等级次数
'log_count/INFO': 52, # 日志记录INFO等级次数
'log_count/WARNING': 7, # 日志记录WARNING等级次数
'memusage/max': 315863040, # 最大占用内存
'memusage/startup': 58642432, # 启动占用内存
'request_depth_max': 1, # 最大请求深度
'response_received_count': 28299, # 接收响应次数
'retry/count': 1773, # 重尝试次数
'retry/max_reached': 8, # 最大重尝试次数
'retry/reason_count/twisted.internet.error.ConnectionRefusedError': 34, # 重尝试链接报错次数
'retry/reason_count/twisted.internet.error.TimeoutError': 1716, # 重尝试超时报错次数
'retry/reason_count/twisted.web._newclient.ResponseFailed': 7, # 页面错误重尝试次数
'retry/reason_count/twisted.web._newclient.ResponseNeverReceived': 16, # 没有找到重尝试次数
'scheduler/dequeued': 30080, # 调度器移除
'scheduler/dequeued/memory': 30080,
'scheduler/enqueued': 30080,
'scheduler/enqueued/memory': 30080,
'start_time': datetime.datetime(2019, 8, 5, 7, 59, 16, 803793)} # 爬虫开始时间
2019-08-05 08:22:04 [scrapy.core.engine] INFO: Spider closed (finished) # 爬虫结束

 浙公网安备 33010602011771号
浙公网安备 33010602011771号