
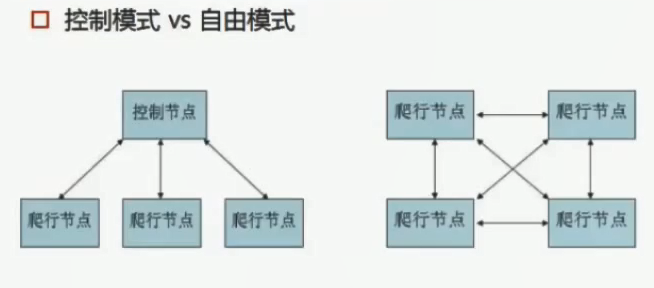
<分布式爬虫>分布式爬虫
- URLManager:爬虫系统的核心,负责URL的重要性排序,分发,调度,任务分配
- ContentAcceptor:负责收集来自爬虫爬到的页面或其他内容,爬虫一般将一批页面打包发给ContentAcceptor,ContentAcceptor将其存储到分布式文件系统或分布式数据库或直接交给ContentParse
- ProxyManager:负责管理用到的所有Proxy,负责管理可以用来爬取的IP,

- redis基本操作
-
# 操作redis数据库 import redis r = redis.Redis( host= 'localhost', port= 6379, db= 1, ) r.set('k1','v1') r.set('k2','v2') r.set('k3','v3') print(r.get('v1')) print(r.keys()) print(r.dbsize()) r.delete('k2') print(r.dbsize()) print(dir(r)) # pipeline p = r.pipeline() p.set('k4','v4') p.set('k5','v5') p.incr('num') p.incr('num') # 每次增加1 # 批量执行 p.execute() print(r.get('num'))
-
- redis实现队列
- 生产消费者模式
-
# 生成者,消费者模式 import redis class Task: def __init__(self): # 连接数据库 self.rcon = redis.Redis(host='localhost', db=5) # 队列名字 self.queue = 'task:prodcons:queue' def process_task(self): while True: # 从队列中拿东西,b代表阻塞的,l代表从左边取数据,b代表线程的安全性 task = self.rcon.blpop(self.queue, 0)[1] print('Task', task) Task().process_task()
-
- 订阅模式
-
# 订阅者模式 import redis class Task: def __init__(self): # 连接数据库 self.rcon = redis.Redis(host='localhost', db=5) self.ps = self.rcon.pubsub() self.ps.subscribe('task:pubsub:channel') def process_task(self): for i in self.ps.listen(): if i['type'] == 'message': print('Task:', i['data']) Task().process_task()
-
- 安装方式
- 源代码分析
- connection.py---连接redis和一些相关配置--为了解决跨机器的消息传递问题
-
import six from scrapy.utils.misc import load_object from . import defaults # redis的连接参数 SETTINGS_PARAMS_MAP = { 'REDIS_URL': 'url', 'REDIS_HOST': 'host', 'REDIS_PORT': 'port', 'REDIS_ENCODING': 'encoding', } def get_redis_from_settings(settings): # 拿到redis信息,配置redis params = defaults.REDIS_PARAMS.copy() params.update(settings.getdict('REDIS_PARAMS')) # XXX: Deprecate REDIS_* settings. for source, dest in SETTINGS_PARAMS_MAP.items(): val = settings.get(source) if val: params[dest] = val # Allow ``redis_cls`` to be a path to a class. if isinstance(params.get('redis_cls'), six.string_types): # 反射,知道名字创建对象 params['redis_cls'] = load_object(params['redis_cls']) return get_redis(**params) # Backwards compatible alias. from_settings = get_redis_from_settings def get_redis(**kwargs): redis_cls = kwargs.pop('redis_cls', defaults.REDIS_CLS) url = kwargs.pop('url', None) if url: return redis_cls.from_url(url, **kwargs) else: return redis_cls(**kwargs)
-
- dupefilter.py----解决去重的问题
-
# 重点,去重函数 def request_seen(self, request): """Returns True if request was already seen. Parameters ---------- request : scrapy.http.Request Returns ------- bool """ # 拆链接,变成键值对,对参数的数组进行排序 fp = self.request_fingerprint(request) # This returns the number of values added, zero if already exists. # s代表set,往集合里面插入元素,判断是否能插入,如果重复adder==0 added = self.server.sadd(self.key, fp) return added == 0
-
- picklecompat.py---序列化和反序列化,将数据序列化成一个字符串,使其能存储到redis中
-
"""A pickle wrapper module with protocol=-1 by default.""" # 做序列化和反序列化 try: import cPickle as pickle # PY2 except ImportError: import pickle def loads(s): return pickle.loads(s) def dumps(obj): return pickle.dumps(obj, protocol=-1)
-
- pipelines.py----不同的爬虫给予不同的key,
-
default_serialize = ScrapyJSONEncoder().encode class RedisPipeline(object): def __init__(self, server, key=defaults.PIPELINE_KEY, serialize_func=default_serialize): self.server = server # 给每个爬虫不同的key,当不同爬虫同时工作的时候防止数据相互干扰 self.key = key # 做序列化的函数serialize_func self.serialize = serialize_func def process_item(self, item, spider): # 爬虫爬到的东西分发出去 return deferToThread(self._process_item, item, spider)
-
- queue.py---实现分布式队列
-
from scrapy.utils.reqser import request_to_dict, request_from_dict from . import picklecompat class Base(object): """Per-spider base queue class""" def __init__(self, server, spider, key, serializer=None): """Initialize per-spider redis queue. Parameters ---------- server : StrictRedis Redis client instance. spider : Spider Scrapy spider instance. key: str Redis key where to put and get messages. serializer : object Serializer object with ``loads`` and ``dumps`` methods. """ if serializer is None: # Backward compatibility. # TODO: deprecate pickle. serializer = picklecompat if not hasattr(serializer, 'loads'): raise TypeError("serializer does not implement 'loads' function: %r" % serializer) if not hasattr(serializer, 'dumps'): raise TypeError("serializer '%s' does not implement 'dumps' function: %r" % serializer) self.server = server self.spider = spider self.key = key % {'spider': spider.name} self.serializer = serializer def _encode_request(self, request): """Encode a request object""" obj = request_to_dict(request, self.spider) return self.serializer.dumps(obj) def _decode_request(self, encoded_request): """Decode an request previously encoded""" obj = self.serializer.loads(encoded_request) return request_from_dict(obj, self.spider) def __len__(self): """Return the length of the queue""" raise NotImplementedError def push(self, request): """Push a request""" raise NotImplementedError def pop(self, timeout=0): """Pop a request""" raise NotImplementedError def clear(self): """Clear queue/stack""" self.server.delete(self.key) class FifoQueue(Base): """Per-spider FIFO queue""" def __len__(self): """Return the length of the queue""" return self.server.llen(self.key) def push(self, request): """Push a request""" self.server.lpush(self.key, self._encode_request(request)) def pop(self, timeout=0): """Pop a request""" if timeout > 0: data = self.server.brpop(self.key, timeout) if isinstance(data, tuple): data = data[1] else: data = self.server.rpop(self.key) if data: return self._decode_request(data) # 优先队列 class PriorityQueue(Base): """Per-spider priority queue abstraction using redis' sorted set""" def __len__(self): """Return the length of the queue""" return self.server.zcard(self.key) def push(self, request): """Push a request""" data = self._encode_request(request) score = -request.priority # We don't use zadd method as the order of arguments change depending on # whether the class is Redis or StrictRedis, and the option of using # kwargs only accepts strings, not bytes. self.server.execute_command('ZADD', self.key, score, data) def pop(self, timeout=0): """ Pop a request timeout not support in this queue class """ # use atomic range/remove using multi/exec pipe = self.server.pipeline() pipe.multi() # 做一个排序 pipe.zrange(self.key, 0, 0).zremrangebyrank(self.key, 0, 0) results, count = pipe.execute() if results: return self._decode_request(results[0]) class LifoQueue(Base): """Per-spider LIFO queue.""" # 队列长度 def __len__(self): """Return the length of the stack""" return self.server.llen(self.key) # 插入数据进队列 def push(self, request): """Push a request""" self.server.lpush(self.key, self._encode_request(request)) # 从队列删除数据 def pop(self, timeout=0): """Pop a request""" if timeout > 0: # b代表阻塞,防止数据混乱 data = self.server.blpop(self.key, timeout) if isinstance(data, tuple): data = data[1] else: data = self.server.lpop(self.key) if data: # 如果得到数据,将序列化数据还原 return self._decode_request(data) # TODO: Deprecate the use of these names. SpiderQueue = FifoQueue SpiderStack = LifoQueue SpiderPriorityQueue = PriorityQueue
-
- scheduler.py ---各种操作的调度
-
import importlib import six from scrapy.utils.misc import load_object from . import connection, defaults # TODO: add SCRAPY_JOB support. class Scheduler(object): # 默认用什么队列,设定默认信息 def __init__(self, server, persist=False, flush_on_start=False, queue_key=defaults.SCHEDULER_QUEUE_KEY, queue_cls=defaults.SCHEDULER_QUEUE_CLASS, dupefilter_key=defaults.SCHEDULER_DUPEFILTER_KEY, dupefilter_cls=defaults.SCHEDULER_DUPEFILTER_CLASS, idle_before_close=0, serializer=None): if idle_before_close < 0: raise TypeError("idle_before_close cannot be negative") self.server = server self.persist = persist self.flush_on_start = flush_on_start self.queue_key = queue_key self.queue_cls = queue_cls self.dupefilter_cls = dupefilter_cls self.dupefilter_key = dupefilter_key self.idle_before_close = idle_before_close self.serializer = serializer self.stats = None def __len__(self): return len(self.queue) @classmethod def from_settings(cls, settings): kwargs = { 'persist': settings.getbool('SCHEDULER_PERSIST'), 'flush_on_start': settings.getbool('SCHEDULER_FLUSH_ON_START'), 'idle_before_close': settings.getint('SCHEDULER_IDLE_BEFORE_CLOSE'), } # If these values are missing, it means we want to use the defaults. optional = { # TODO: Use custom prefixes for this settings to note that are # specific to scrapy-redis. 'queue_key': 'SCHEDULER_QUEUE_KEY', 'queue_cls': 'SCHEDULER_QUEUE_CLASS', 'dupefilter_key': 'SCHEDULER_DUPEFILTER_KEY', # We use the default setting name to keep compatibility. 'dupefilter_cls': 'DUPEFILTER_CLASS', 'serializer': 'SCHEDULER_SERIALIZER', } for name, setting_name in optional.items(): val = settings.get(setting_name) if val: kwargs[name] = val # Support serializer as a path to a module. if isinstance(kwargs.get('serializer'), six.string_types): kwargs['serializer'] = importlib.import_module(kwargs['serializer']) server = connection.from_settings(settings) # Ensure the connection is working. server.ping() return cls(server=server, **kwargs) @classmethod def from_crawler(cls, crawler): instance = cls.from_settings(crawler.settings) # FIXME: for now, stats are only supported from this constructor instance.stats = crawler.stats return instance def open(self, spider): self.spider = spider try: # 根据你传的队列名字,创建队列 self.queue = load_object(self.queue_cls)( server=self.server, spider=spider, key=self.queue_key % {'spider': spider.name}, serializer=self.serializer, ) except TypeError as e: raise ValueError("Failed to instantiate queue class '%s': %s", self.queue_cls, e) try: # 实例化出来 self.df = load_object(self.dupefilter_cls)( server=self.server, key=self.dupefilter_key % {'spider': spider.name}, debug=spider.settings.getbool('DUPEFILTER_DEBUG'), ) except TypeError as e: raise ValueError("Failed to instantiate dupefilter class '%s': %s", self.dupefilter_cls, e) if self.flush_on_start: self.flush() # notice if there are requests already in the queue to resume the crawl if len(self.queue): spider.log("Resuming crawl (%d requests scheduled)" % len(self.queue)) def close(self, reason): if not self.persist: self.flush() def flush(self): self.df.clear() self.queue.clear() def enqueue_request(self, request): # 需不需要去重 if not request.dont_filter and self.df.request_seen(request): self.df.log(request, self.spider) return False if self.stats: self.stats.inc_value('scheduler/enqueued/redis', spider=self.spider) # 如果不是重复的,丢进队列里面去 self.queue.push(request) return True def next_request(self): # 取出队列中的数据 block_pop_timeout = self.idle_before_close request = self.queue.pop(block_pop_timeout) # 拿走了多少任务 if request and self.stats: self.stats.inc_value('scheduler/dequeued/redis', spider=self.spider) return request def has_pending_requests(self): return len(self) > 0
-
- spiders.pyfrom scrapy import signalsfrom scrapy.exceptions import DontCloseSpider
-
from scrapy.spiders import Spider, CrawlSpider from . import connection, defaults from .utils import bytes_to_str class RedisMixin(object): """Mixin class to implement reading urls from a redis queue.""" redis_key = None redis_batch_size = None redis_encoding = None # Redis client placeholder. server = None def start_requests(self): """Returns a batch of start requests from redis.""" return self.next_requests() def setup_redis(self, crawler=None): if self.server is not None: return if crawler is None: # We allow optional crawler argument to keep backwards # compatibility. # XXX: Raise a deprecation warning. crawler = getattr(self, 'crawler', None) if crawler is None: raise ValueError("crawler is required") settings = crawler.settings if self.redis_key is None: self.redis_key = settings.get( 'REDIS_START_URLS_KEY', defaults.START_URLS_KEY, ) self.redis_key = self.redis_key % {'name': self.name} if not self.redis_key.strip(): raise ValueError("redis_key must not be empty") if self.redis_batch_size is None: # TODO: Deprecate this setting (REDIS_START_URLS_BATCH_SIZE). self.redis_batch_size = settings.getint( 'REDIS_START_URLS_BATCH_SIZE', settings.getint('CONCURRENT_REQUESTS'), ) try: self.redis_batch_size = int(self.redis_batch_size) except (TypeError, ValueError): raise ValueError("redis_batch_size must be an integer") if self.redis_encoding is None: self.redis_encoding = settings.get('REDIS_ENCODING', defaults.REDIS_ENCODING) self.logger.info("Reading start URLs from redis key '%(redis_key)s' " "(batch size: %(redis_batch_size)s, encoding: %(redis_encoding)s", self.__dict__) self.server = connection.from_settings(crawler.settings) # The idle signal is called when the spider has no requests left, # that's when we will schedule new requests from redis queue crawler.signals.connect(self.spider_idle, signal=signals.spider_idle) def next_requests(self): """Returns a request to be scheduled or none.""" use_set = self.settings.getbool('REDIS_START_URLS_AS_SET', defaults.START_URLS_AS_SET) fetch_one = self.server.spop if use_set else self.server.lpop # XXX: Do we need to use a timeout here? found = 0 # TODO: Use redis pipeline execution. while found < self.redis_batch_size: data = fetch_one(self.redis_key) if not data: # Queue empty. break req = self.make_request_from_data(data) if req: yield req found += 1 else: self.logger.debug("Request not made from data: %r", data) if found: self.logger.debug("Read %s requests from '%s'", found, self.redis_key) def make_request_from_data(self, data): # 拼连接 url = bytes_to_str(data, self.redis_encoding) return self.make_requests_from_url(url) def schedule_next_requests(self): """Schedules a request if available""" # TODO: While there is capacity, schedule a batch of redis requests. for req in self.next_requests(): self.crawler.engine.crawl(req, spider=self) def spider_idle(self): """Schedules a request if available, otherwise waits.""" # XXX: Handle a sentinel to close the spider. self.schedule_next_requests() raise DontCloseSpider class RedisSpider(RedisMixin, Spider): @classmethod def from_crawler(self, crawler, *args, **kwargs): obj = super(RedisSpider, self).from_crawler(crawler, *args, **kwargs) obj.setup_redis(crawler) return obj class RedisCrawlSpider(RedisMixin, CrawlSpider): @classmethod def from_crawler(self, crawler, *args, **kwargs): obj = super(RedisCrawlSpider, self).from_crawler(crawler, *args, **kwargs) obj.setup_redis(crawler) return obj
-
- connection.py---连接redis和一些相关配置--为了解决跨机器的消息传递问题
- 生产消费者模式
-
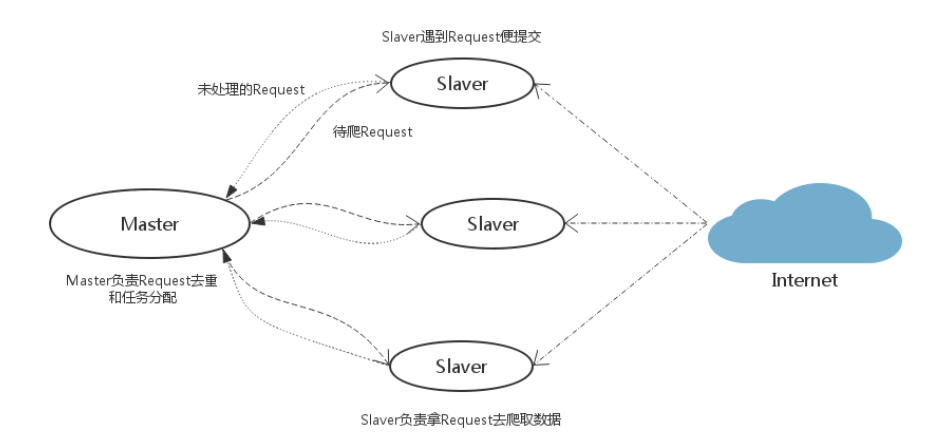
Scrapy-redis提供了下面四种组件(components):(四种组件意味着这四个模块都要做相应的修改)
SchedulerDuplication FilterItem PipelineBase Spider
- redis中会有三个库
- 存数据:pIpeline统一存储,所有分布式爬虫爬到的数据都放在redis数据库
- 存请求
- 存指纹
- 步骤
- request先进行指纹比对
- 没有发过放入请求队列
- 从队列中出队列给下载器下载
- settings.py
-
# -*- coding: utf-8 -*- # 指定使用scrapy-redis的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 指定使用scrapy-redis的去重 DUPEFILTER_CLASS = 'scrapy_redis.dupefilters.RFPDupeFilter' # 指定排序爬取地址时使用的队列, # 默认的 按优先级排序(Scrapy默认),由sorted set实现的一种非FIFO、LIFO方式。 SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue' # 可选的 按先进先出排序(FIFO) # SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderQueue' # 可选的 按后进先出排序(LIFO) # SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderStack' # 在redis中保持scrapy-redis用到的各个队列,从而允许暂停和暂停后恢复,也就是不清理redis queues SCHEDULER_PERSIST = True # 只在使用SpiderQueue或者SpiderStack是有效的参数,指定爬虫关闭的最大间隔时间 # SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 通过配置RedisPipeline将item写入key为 spider.name : items 的redis的list中,供后面的分布式处理item # 这个已经由 scrapy-redis 实现,不需要我们写代码 ITEM_PIPELINES = { 'example.pipelines.ExamplePipeline': 300, 'scrapy_redis.pipelines.RedisPipeline': 400 } # 指定redis数据库的连接参数 # REDIS_PASS是我自己加上的redis连接密码(默认不做) REDIS_HOST = '127.0.0.1' REDIS_PORT = 6379 #REDIS_PASS = 'redisP@ssw0rd' # LOG等级 LOG_LEVEL = 'DEBUG' #默认情况下,RFPDupeFilter只记录第一个重复请求。将DUPEFILTER_DEBUG设置为True会记录所有重复的请求。 DUPEFILTER_DEBUG =True # 覆盖默认请求头,可以自己编写Downloader Middlewares设置代理和UserAgent DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Accept-Language': 'zh-CN,zh;q=0.8', 'Connection': 'keep-alive', 'Accept-Encoding': 'gzip, deflate, sdch' }
-
-
pipeline.py
-
# -*- coding: utf-8 -*- from datetime import datetime class ExamplePipeline(object): def process_item(self, item, spider): #utcnow() 是获取UTC时间 item["crawled"] = datetime.utcnow() # 爬虫名 item["spider"] = spider.name return item
-
-
items.py
-
# -*- coding: utf-8 -*- from scrapy.item import Item, Field class youyuanItem(Item): # 个人头像链接 header_url = Field() # 用户名 username = Field() # 内心独白 monologue = Field() # 相册图片链接 pic_urls = Field() # 年龄 age = Field() # 网站来源 youyuan source = Field() # 个人主页源url source_url = Field() # 获取UTC时间 crawled = Field() # 爬虫名 spider = Field()
-
-
spider
-
# -*- coding:utf-8 -*- from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule # 使用redis去重 from scrapy.dupefilters import RFPDupeFilter from example.items import youyuanItem import re # class YouyuanSpider(CrawlSpider): name = 'youyuan' allowed_domains = ['youyuan.com'] # 有缘网的列表页 start_urls = ['http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p1/'] # 搜索页面匹配规则,根据response提取链接 list_page_lx = LinkExtractor(allow=(r'http://www.youyuan.com/find/.+')) # 北京、18~25岁、女性 的 搜索页面匹配规则,根据response提取链接 page_lx = LinkExtractor(allow =(r'http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p\d+/')) # 个人主页 匹配规则,根据response提取链接 profile_page_lx = LinkExtractor(allow=(r'http://www.youyuan.com/\d+-profile/')) rules = ( # 匹配find页面,跟进链接,跳板 Rule(list_page_lx, follow=True), # 匹配列表页成功,跟进链接,跳板 Rule(page_lx, follow=True), # 匹配个人主页的链接,形成request保存到redis中等待调度,一旦有响应则调用parse_profile_page()回调函数处理,不做继续跟进 Rule(profile_page_lx, callback='parse_profile_page', follow=False), ) # 处理个人主页信息,得到我们要的数据 def parse_profile_page(self, response): item = youyuanItem() item['header_url'] = self.get_header_url(response) item['username'] = self.get_username(response) item['monologue'] = self.get_monologue(response) item['pic_urls'] = self.get_pic_urls(response) item['age'] = self.get_age(response) item['source'] = 'youyuan' item['source_url'] = response.url #print "Processed profile %s" % response.url yield item # 提取头像地址 def get_header_url(self, response): header = response.xpath('//dl[@class=\'personal_cen\']/dt/img/@src').extract() if len(header) > 0: header_url = header[0] else: header_url = "" return header_url.strip() # 提取用户名 def get_username(self, response): usernames = response.xpath("//dl[@class=\'personal_cen\']/dd/div/strong/text()").extract() if len(usernames) > 0: username = usernames[0] else: username = "NULL" return username.strip() # 提取内心独白 def get_monologue(self, response): monologues = response.xpath("//ul[@class=\'requre\']/li/p/text()").extract() if len(monologues) > 0: monologue = monologues[0] else: monologue = "NULL" return monologue.strip() # 提取相册图片地址 def get_pic_urls(self, response): pic_urls = [] data_url_full = response.xpath('//li[@class=\'smallPhoto\']/@data_url_full').extract() if len(data_url_full) <= 1: pic_urls.append(""); else: for pic_url in data_url_full: pic_urls.append(pic_url) if len(pic_urls) <= 1: return "NULL" # 每个url用|分隔 return '|'.join(pic_urls) # 提取年龄 def get_age(self, response): age_urls = response.xpath("//dl[@class=\'personal_cen\']/dd/p[@class=\'local\']/text()").extract() if len(age_urls) > 0: age = age_urls[0] else: age = "0" age_words = re.split(' ', age) if len(age_words) <= 2: return "0" age = age_words[2][:-1] # 从age字符串开始匹配数字,失败返回None if re.compile(r'[0-9]').match(age): return age return "0"
-
-
运行程序:
- Master端打开 Redis:
redis-server - Slave端直接运行爬虫:
scrapy crawl youyuan - 多个Slave端运行爬虫顺序没有限制。
- Master端打开 Redis:
- 将自己的scrapy爬虫改成分布式爬虫只需要
- settings.py中放入
-
# 指定使用scrapy-redis的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 指定使用scrapy-redis的去重 DUPEFILTER_CLASS = 'scrapy_redis.dupefilters.RFPDupeFilter' # 指定排序爬取地址时使用的队列, # 默认的 按优先级排序(Scrapy默认),由sorted set实现的一种非FIFO、LIFO方式。 SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'
ITEM_PIPELINES = { 'example.pipelines.ExamplePipeline': 300, 'scrapy_redis.pipelines.RedisPipeline': 400 }
-
- spider中修改继承的爬虫和导入的包
-
from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule # 使用redis去重 from scrapy.dupefilters import RFPDupeFilter from example.items import youyuanItem import re # class YouyuanSpider(CrawlSpider):
-
- 其他就是网络设置跟redis设置的问题了,爬虫不需要改了
- settings.py中放入


 浙公网安备 33010602011771号
浙公网安备 33010602011771号