

<爬虫>常见网址的爬虫整理
# 是告诉操作系统执行这个脚本的时候,调用/usr/bin下的python3解释器;
# !/usr/bin/python3
# -*- coding: utf-8 -*-
"""
请求URL分析 https://tieba.baidu.com/f?kw=魔兽世界&ie=utf-8&pn=50
请求方式分析 GET
请求参数分析 pn每页50发生变化,其他参数固定不变
请求头分析 只需要添加User-Agent
"""
# 代码实现流程
# 1. 实现面向对象构建爬虫对象
# 2. 爬虫流程四步骤
# 2.1 获取url列表
# 2.2 发送请求获取响应
# 2.3 从响应中提取数据
# 2.4 保存数据
import requests
class TieBa_Spier():
def __init__(self, max_page, kw):
# 初始化
self.max_page = max_page # 最大页码
self.kw = kw # 贴吧名称
self.base_url = "https://tieba.baidu.com/f?kw={}&ie=utf-8&pn={}"
self.headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
}
def get_url_list(self):
"""获取url列表"""
# 根据pn每50进入下一页,构建url列表
return [self.base_url.format(self.kw, pn) for pn in range(0, self.max_page * 50, 50)]
def get_content(self, url):
"""发送请求获取响应内容"""
response = requests.get(
url=url,
headers=self.headers
)
# print(response.text)
return response.content
def save_items(self, content, idx):
"""从响应内容中提取数据"""
with open('{}.html'.format(idx), 'wb') as f:
f.write(content)
return None
def run(self):
"""运行程序"""
# 获取url_list
url_list = self.get_url_list()
for url in url_list:
# 发送请求获取响应
content = self.get_content(url)
# 保存数据,按照url的索引+1命名保存的文件
items = self.save_items(content, url_list.index(url) + 1)
# 测试
# print(items)
if __name__ == '__main__':
# 最大页码,贴吧名
spider = TieBa_Spier(2, "神无月")
spider.run()
002.京东商品评论
# !/usr/bin/python3
# -*- coding: utf-8 -*-
import requests
import re
import pandas as pd
"""
请求URL分析 https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv4962&productId=5089225&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&rid=0&fold=1
请求方式分析 GET
请求参数分析 page每页加1发生变化,其他参数固定不变
请求头分析 不需要添加User-Agent
"""
# 代码实现流程
# 1. 实现面向对象构建爬虫对象
# 2. 爬虫流程四步骤
# 2.1 获取url列表
# 2.2 发送请求获取响应
# 2.3 从响应中提取数据
# 2.4 保存数据
class JD_Spier():
def __init__(self, max_page):
# 初始化
self.max_page = max_page # 最大页码
self.base_url = "https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv4962&productId=5089225&score=0&sortType=5&page={}&pageSize=10&isShadowSku=0&rid=0&fold=1"
def get_url_list(self):
"""获取url列表"""
# 根据page每1进入下一页,构建url列表
return [self.base_url.format(page) for page in range(0, self.max_page, 1)]
def get_content(self, url):
"""发送请求获取响应内容"""
response = requests.get(url=url)
# print(response.text)
return response.text
def save_items(self, content):
"""从响应内容中提取数据"""
with open('comment_iphone11.txt', 'a', encoding='utf-8') as f:
pat = '"content":"(.*?)","'
res = re.findall(pat, content)
for index, i in enumerate(res):
i = i.replace('\\n', '')
# print(i)
f.write(str(index) + ':' + i)
f.write('\n')
f.write('\n')
return None
def run(self):
"""运行程序"""
# 获取url_list
url_list = self.get_url_list()
for index, url in enumerate(url_list):
# 发送请求获取响应
try:
print('正在爬第%s页...' % index)
content = self.get_content(url)
# 保存数据
self.save_items(content)
except:
print('爬取第' + str(index) + '页出现问题')
continue
if __name__ == '__main__':
# 最大页码
spider = JD_Spier(99)
spider.run()
顺带做个词云图
from os import path
from scipy.misc import imread
import matplotlib.pyplot as plt
import jieba
from wordcloud import WordCloud
# 进行分词的数据
f = open('comment_iphone11.txt','r',encoding='utf-8')
text = f.read()
cut_text = ' '.join(jieba.lcut(text))
print(cut_text)
# 词云形状
color_mask = imread("201910051325286.jpg")
cloud = WordCloud(
# 注意字体在同路径
font_path='FZMWFont.ttf', # 字体最好放在与脚本相同的目录下,而且必须设置
background_color='white',
mask=color_mask,
max_words=200,
max_font_size=5000
)
word_cloud = cloud.generate(cut_text)
plt.imshow(word_cloud)
plt.axis('off')
plt.show()
效果图

003.豆瓣电影top250(三种解析)
# 目标:爬取豆瓣电影排行榜TOP250的电影信息
# 信息包括:电影名字,上映时间,主演,评分,导演,一句话评价
# 解析用学过的几种方法都实验一下①正则表达式.②BeautifulSoup③xpath
import requests
import re # 正则表达式
import json
from bs4 import BeautifulSoup # BS
from lxml import etree # xpath
# 进程池
from multiprocessing import Pool
import multiprocessing
def get_one_page(url):
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
def zhengze_parse(html):
pattern = re.compile(
'<em class="">(.*?)</em>.*?<img.*?alt="(.*?)".*?src="(.*?)".*?property="v:average">(.*?)</span>.*?<span>(.*?)</span>.*?'
+ 'class="inq">(.*?)</span>', re.S)
items = re.findall(pattern, html)
# print(items)
# 因为125个影片没有描述,根本没有匹配到- -,更改也简单,描述单独拿出来,这里我就不改了
for item in items:
yield {
'index': item[0],
'title': item[1],
'image': item[2],
'score': item[3],
'people': item[4].strip()[:-2],
'Evaluation': item[5]
}
def soup_parse(html):
soup = BeautifulSoup(html, 'lxml')
for data in soup.find_all('div', class_='item'):
index = data.em.text
image = data.img['src']
title = data.img['alt']
people = data.find_all('span')[-2].text[:-2]
score = data.find('span', class_='rating_num').text
# 第125个影片没有描述,用空代替
if data.find('span', class_='inq'):
Evaluation = data.find('span', class_='inq').text
else:
Evaluation = ''
yield {
'index': index,
'image': image,
'title': title,
'people': people,
'score': score,
'Evaluation': Evaluation,
}
def xpath_parse(html):
html = etree.HTML(html)
for data in html.xpath('//ol[@class="grid_view"]/li'):
index = data.xpath('.//em/text()')[0]
image = data.xpath('.//a/img/@src')[0]
title = data.xpath('.//a/img/@alt')[0]
people = data.xpath('.//div[@class="star"]/span[4]/text()')[0][:-2]
score = data.xpath('.//div[@class="star"]/span[2]/text()')[0]
# 第125个影片没有描述,用空代替
if data.xpath('.//p[@class="quote"]/span/text()'):
Evaluation = data.xpath('.//p[@class="quote"]/span/text()')[0]
else:
Evaluation = ''
yield {
'index': index,
'image': image,
'title': title,
'people': people,
'score': score,
'Evaluation': Evaluation,
}
def write_to_file(content, flag):
with open('豆瓣电影TOP250(' + str(flag) + ').txt', 'a', encoding='utf-8')as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
def search(Num):
url = 'https://movie.douban.com/top250?start=' + str(Num)
html = get_one_page(url)
for item in zhengze_parse(html):
write_to_file(item, '正则表达式')
for item in soup_parse(html):
write_to_file(item, 'BS4')
for item in xpath_parse(html):
write_to_file(item, 'xpath')
page = str(Num / 25 + 1)
print("正在爬取第" + page[:-2] + '页')
def main():
pool = Pool()
pool.map(search, [i * 25 for i in range(10)])
# # 提供页码--不用进程池
# for i in range(0, 10):
# Num = i * 25
# search(Num)
print("爬取完成")
if __name__ == '__main__':
# 打包之后,windows执行多进程出错,需要加入这一行
multiprocessing.freeze_support()
# 入口
main()
打包成exe可执行文件
pyinstaller -F 豆瓣电影排行.py
运行效果
004.今日头条(街拍美图)
# 拼接URL
from urllib.parse import urlencode
# 请求URL
import requests
# 文件操作
import os
# md5:类似加密,不会重复
from hashlib import md5
# 进程池
from multiprocessing.pool import Pool
# 延迟
import time
base_url = 'https://www.toutiao.com/api/search/content/?'
headers = {
'Referer': 'https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
def get_page(offset):
# https://www.toutiao.com/api/search/content/?aid=24&app_name=web_search&offset=0&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&en_qc=1&cur_tab=1&from=search_tab&pd=synthesis
# 根据链接传入params,offset是变化的
params = {
'aid': '24',
'app_name': 'web_search',
'offset': offset,
'format': 'json',
'keyword': '街拍',
'autoload': 'ture',
'count': '20',
'en_qc': '1',
'cur_tab': '1',
'from': 'search_tab',
'pd': 'synthesis',
}
url = base_url + urlencode(params)
# 返回json格式的数据
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error', e.args)
def get_images(json):
if json:
items = json.get('data')
for item in items:
# 标题
title = item.get('title')
# 图片列表
images = item.get('image_list')
for image in images:
# 返回单个图片链接+标题的字典
yield {
'image': image.get('url'),
'title': title,
}
def save_image(item):
# 如果没有文件夹就创建文件夹
dirs = 'F:\\domo'
if not os.path.exists(dirs):
os.mkdir("F:\\domo")
# 改变当前工作目录
os.chdir('F:\\domo')
# 如果没有item传过来title命名的文件,就创建一个
if not os.path.exists(item.get('title')):
os.mkdir(item.get('title'))
try:
# 请求图片URL
response = requests.get(item.get('image'))
if response.status_code == 200:
# 构造图片名字
file_path = '{0}\\{1}.{2}'.format(item.get('title'), md5(response.content).hexdigest(), 'jpg')
# 如果不存在这张图片就以二进制方式写入
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(response.content)
else:
print("已经下载过这个文件了", file_path)
except:
print("图片下载失败")
GROUP_START = 1
GROUP_END = 20
def main(offset):
json = get_page(offset)
for item in get_images(json):
print(item)
save_image(item)
if __name__ == '__main__':
pool = Pool()
# 构造一个offset列表 20-400(20页)
groups = ([x * 20 for x in range(GROUP_START, GROUP_END + 1)])
# 多进程运行main函数
pool.map(main, groups)
# 关闭进程池
pool.close()
# 等待还没运行完的进程
pool.join()
爬10页左右就不给数据了,需要添加UA池
总结:1.os模块的基本操作
os.chdir('路径') --------------------表示改变当前工作目录到路径
os.path.exists('文件名') ------------当前目录下是否存在该文件,存在返回Ture,不存在返回False
os.mkdir()-----------创建文件夹
2. 用MD5值命名文件,可以有效的解决重复抓取的问题
3.进程池能大大降低爬取时间
005.微博
# url拼接
from urllib.parse import urlencode
# 去掉html标签
from pyquery import PyQuery as pq
# 请求
import requests
# 链接mongo
from pymongo import MongoClient
# 爬的太快大概36页的时候就会出现418,加点延迟吧
import time
# 连接
client = MongoClient()
# 指定数据库
db = client['weibo']
# 指定表
collection = db['weibo_domo2']
max_page = 100
# 存储到mongoDB
def save_to_mongo(result):
if collection.insert(result):
print("saved to mongo")
# https://m.weibo.cn/api/container/getIndex?containerid=1076032830678474&page=2
# 找到X-Requested-With: XMLHttpRequest的Ajax请求
# 基础url,之后利用urlencode进行拼接
base_url = 'https://m.weibo.cn/api/container/getIndex?'
# https://m.weibo.cn/api/container/getIndex?type=uid&value=1005052830678474&containerid=1005051005052830678474
headers = {
'host': 'm.weibo.cn',
# 手机端打开,查到链接,在解析
# 'Referer': 'https://m.weibo.cn/p/1005052830678474',
'Referer': 'https://m.weibo.cn/u/2202323951',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
def get_page(page):
params = {
'type': 'uid',
'value': '2202323951',
# 'containerid': '1076032830678474',
'containerid': '1076032202323951',
'page': page,
}
url = base_url + urlencode(params)
print(url)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
# response = json.dump(response.text)
return response.json(), page
except requests.ConnectionError as e:
print('Error', e.args)
def parse_page(json, page: int):
if json:
# 只需要data下的cards内的数据
items = json.get('data').get('cards')
# index 下标
for index, item in enumerate(items):
# 在第一页,index==1没有mblog,只有这个没用,所以直接循环会导则索引报错
# 跳过这段
if index == 1 and page == 1:
continue
else:
item = item.get('mblog')
weibo = {}
# 微博ID
# "id":"4349509976406880",
weibo['ID'] = item.get('id')
# 微博内容 使用pq去掉html标签
weibo['text'] = pq(item.get('text')).text()
# 发表所用手机
weibo['phone'] = item.get('source')
# 发表时间
weibo['time'] = item.get('edit_at')
# 赞数量 attitudes:态度,意思,姿态
weibo['attitudes'] = item.get('attitudes_count')
# 评论数 comment:评论
weibo['comments'] = item.get('comments_count')
# 转发数 repost:转帖
weibo['reposts'] = item.get('reposts_count')
yield weibo
if __name__ == '__main__':
for page in range(1, max_page + 1):
json = get_page(page)
# *json==*args 将返回的json和page传入
results = parse_page(*json)
time.sleep(3)
for result in results:
print(result)
save_to_mongo(result)
总结:
1.不加延迟爬到36-38页会出现418 (418 I’m a teapot 服务器拒绝尝试用 “茶壶冲泡咖啡”。)
2. Ajax请求中可能在中间出现不是你想要的数据,例如微博page1,index1代表的是关注列表,关注的信息,不是你想要的数据
3.使用手机端获取Ajax数据,比在PC端,容易很多.
4.启动mongo需要先指定dbpath(数据存储的地方),查询插入文件的数量
形如:mongod --dbpath="F:\MongoDB\Server\3.4\data"
形如: db.weibo_domo2.find().count()
5.最终爬取出了朱子奇的所有微博,一共959条
006.猫眼电影top100
https://www.cnblogs.com/shuimohei/p/10400814.html
007.百度百科
https://www.cnblogs.com/shuimohei/p/10339891.html
008.斗鱼直播
'''
Ajax含有很多加密参数,我们无法直接进行爬取,只能借助Selenium
'''
# !/usr/bin/env python
# -*- coding:utf-8 -*-
import unittest
from selenium import webdriver
from bs4 import BeautifulSoup as bs
import time
class douyu(unittest.TestCase):
# 初始化方法,必须是setUp()
def setUp(self):
# self.driver = webdriver.Chrome()
self.driver = webdriver.PhantomJS()
self.num = 0
self.count = 0
# 测试方法必须有test字样开头
def testDouyu(self):
self.driver.get("https://www.douyu.com/directory/all")
while True:
soup = bs(self.driver.page_source, "lxml")
# 房间名, 返回列表
names = soup.find_all("h3", {"class": "DyListCover-intro"})
# 直播间热度, 返回列表
numbers = soup.find_all("span", {"class": "DyListCover-hot"})
print(names,numbers)
for name, number in zip(names, numbers):
self.num += 1
print(
u"直播间热度: -" + number.get_text().strip() + u"-\t房间名: " + name.get_text().strip() + u'-\t直播数量' + str(
self.num))
result = u"直播间热度: -" + number.get_text().strip() + u"-\t房间名: " + name.get_text().strip() + u'-\t直播数量' + str(
self.num)
with open('123.txt', 'a', encoding='utf-8') as f:
f.write(result)
# self.count += int(number.get_text().strip())
# 如果在页面源码里找到"下一页"为隐藏的标签,就退出循环
if self.driver.page_source.find("dy-Pagination-disabled dy-Pagination-next") != -1:
break
#网络不好,加个延时,也可以考虑用直到标签能够点击的判断
time.sleep(1)
# 一直点击下一页
self.driver.find_element_by_class_name("dy-Pagination-next").click()
time.sleep(1)
# 测试结束执行的方法
def tearDown(self):
# 退出PhantomJS()浏览器
print("当前网站直播人数" + str(self.num))
print("当前网站总热度" + str(self.count))
self.driver.quit()
if __name__ == "__main__":
# 启动测试模块
unittest.main()
selenium还是慢了点,加了延时后更慢了
009.阳光热线问政平台
1.创建项目
scrapy startproject dongguan
2.创建爬虫
scrapy genspider -t crawl sun wz.sun0769.com
3.items.py
import scrapy
class DongguanItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
data = scrapy.Field()
num = scrapy.Field()
content = scrapy.Field()
url = scrapy.Field()
4.sun.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from dongguan.items import DongguanItem
class SunSpider(CrawlSpider):
name = 'sun'
allowed_domains = ['wz.sun0769.com']
start_urls = ['http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1']
rules = (
# 翻页
Rule(LinkExtractor(allow=r'page=\d+'), follow=True),
# 每个链接的
Rule(LinkExtractor(allow=r'id=\d+'), callback='parse_item', follow=False),
)
def parse_item(self, response):
print(response.url)
print(response)
item = DongguanItem()
item['title'] = response.xpath('//p[@class="focus-details"]/text()').extract_first()
item['data'] = response.xpath('//span[@class="fl"]/text()').extract()[0][4:]
item['num'] = response.xpath('//span[@class="fl"]/text()').extract()[2][3:]
# normalize-space,xpath中去掉\r\t\n
item['content'] = response.xpath('normalize-space(//div[@class="details-box"]/pre/text())').extract_first()
item['url'] = response.url
yield item
5.pipelines.py
import json
class DongguanPipeline(object):
def __init__(self):
self.filename = open('dongguan.txt', 'wb')
def process_item(self, item, spider):
text = json.dumps(dict(item), ensure_ascii=False) + '\n'
self.filename.write(text.encode('utf-8'))
return item
def close_spider(self, spider):
self.filename.close()
6.settings.py
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'dongguan.pipelines.DongguanPipeline': 300,
}
# 日志文件名和处理等级
LOG_FILE = "dg.log"
LOG_LEVEL = "DEBUG"
7.运行爬虫
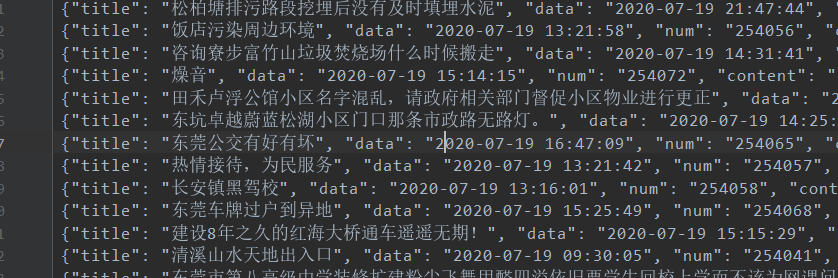
scrapy crawl sun
8.运行效果
010.新浪网分类资讯整站爬虫
1.创建项目
scrapy startproject sina
2.创建爬虫
scrapy genspider xinlang sina.com.cn
3.items.py
# -*- coding: utf-8 -*- import scrapy import sys, importlib importlib.reload(sys) class SinaItem(scrapy.Item): # 第一层:大类的标题 和 url parentTitle = scrapy.Field() parentUrls = scrapy.Field() # 第二层:小类的标题 和 子url subTitle = scrapy.Field() subUrls = scrapy.Field() # 存储到本地:小类目录存储路径 subFilename = scrapy.Field() # 第三层:小类下的子链接 sonUrls = scrapy.Field() # 抓到数据:文章标题和内容 head = scrapy.Field() content = scrapy.Field()
4.xinlang.py----新闻的解析方式太多了,没有写完全
# -*- coding: utf-8 -*-
import scrapy
# 创建文件夹
import os
from sina.items import SinaItem
class XinlangSpider(scrapy.Spider):
name = 'xinlang'
allowed_domains = ['sina.com.cn']
start_urls = ['http://news.sina.com.cn/guide/']
def parse(self, response):
items = []
# 用xpath找出所有大类的URL和标题 19个
parentUrls = response.xpath('//div[@id="tab01"]/div/h3/a/@href').extract()
parentTitle = response.xpath('//div[@id="tab01"]/div/h3/a/text()').extract()
# 找出所有小类的ur 和 标题 299个
subUrls = response.xpath('//div[@id="tab01"]/div/ul/li/a/@href').extract()
subTitle = response.xpath('//div[@id="tab01"]/div/ul/li/a/text()').extract()
# 爬取所有大类
for i in range(0, len(parentTitle)):
# 指定大类目录的路径和目录名
parentFilename = "./Data/" + parentTitle[i]
# 如果目录不存在,则创建目录
if (not os.path.exists(parentFilename)):
os.makedirs(parentFilename)
# 爬取所有小类
for j in range(0, len(subUrls)):
item = SinaItem()
# 保存大类的title和urls
item['parentTitle'] = parentTitle[i]
item['parentUrls'] = parentUrls[i]
# 检查小类的url是否以同类别大类url开头,如果是返回True (sports.sina.com.cn 和 sports.sina.com.cn/nba)
if_belong = subUrls[j].startswith(item['parentUrls'])
# 如果属于本大类,将存储目录放在本大类目录下
if (if_belong):
subFilename = parentFilename + '/' + subTitle[j]
# 如果目录不存在,则创建目录
if (not os.path.exists(subFilename)):
os.makedirs(subFilename)
# 存储 小类url、title和filename字段数据
item['subUrls'] = subUrls[j]
item['subTitle'] = subTitle[j]
item['subFilename'] = subFilename
items.append(item)
# 发送每个小类url的Request请求,得到Response连同包含meta数据 一同交给回调函数 second_parse 方法处理
for item in items:
yield scrapy.Request(url=item['subUrls'], meta={'meta_1': item}, callback=self.second_parse)
# 对于返回的小类的url,再进行递归请求
def second_parse(self, response):
# 提取每次Response的meta数据
meta_1 = response.meta['meta_1']
# 取出小类里所有子链接,只要a标签下的链接
sonUrls = response.xpath('//a/@href').extract()
items = []
for i in range(0, len(sonUrls)):
# 检查每个链接是否以大类url开头、以.shtml结尾,如果是返回True,确保是个新闻
if_belong = sonUrls[i].endswith('.shtml') and sonUrls[i].startswith(meta_1['parentUrls'])
# 如果属于本大类,获取字段值放在同一个item下便于传输
if (if_belong):
item = SinaItem()
item['parentTitle'] = meta_1['parentTitle']
item['parentUrls'] = meta_1['parentUrls']
item['subUrls'] = meta_1['subUrls']
item['subTitle'] = meta_1['subTitle']
item['subFilename'] = meta_1['subFilename']
item['sonUrls'] = sonUrls[i]
items.append(item)
# 发送每个小类下子链接url的Request请求,得到Response后连同包含meta数据 一同交给回调函数 detail_parse 方法处理
for item in items:
yield scrapy.Request(url=item['sonUrls'], meta={'meta_2': item}, callback=self.detail_parse)
# 数据解析方法,获取文章标题和内容
def detail_parse(self, response):
item = response.meta['meta_2']
content = ""
head = response.xpath('//h1[@class="main-title"]/text()').extract()
content_list = response.xpath('//div[@class="article"]/p/text()').extract()
# 如果新闻的类型没有匹配到
if len(content_list) < 1:
# 按照新闻中心的匹配http://news.sina.com.cn/w/2004-12-20/11314575163s.shtml
head = response.xpath('//th[@class="f24"]//h1/text()').extract()
content_list = response.xpath('//td[@class="l17"]/font/p/text()').extract()
if len(content_list) < 1:
# http://news.sina.com.cn/c/2012-09-21/092225223127.shtml
head = response.xpath('//div[@class="blk_content"]/h1/text()').extract()
content_list = response.xpath('//div[@id="artibody"]/p/text()').extract()
if len(content_list) < 1:
# http://news.sina.com.cn/c/2014-09-24/145630907684.shtml
head = response.xpath('//h1[@id="artibodyTitle"]/text()').extract()
content_list = response.xpath('//div[@id="artibody"]/p/text()').extract()
if len(content_list) < 1:
# http://news.sina.com.cn/c/2014-09-24/145630907684.shtml
head = response.xpath('//h1[@class="main-title"]/text()').extract()
content_list = response.xpath('//div[@id="artibody"]/p/text()').extract()
if len(content_list) < 1:
# http://news.sina.com.cn/c/2014-09-24/145630907684.shtml
head = response.xpath('//h1[@id="artibodyTitle"]/font/text()').extract()
content_list = response.xpath('//div[@id="artibody"]//span/text()').extract()
if len(head) < 1:
# 漏网只鱼
head = ['error']
content_list = [response.url]
# 将p标签里的文本内容合并到一起
for content_one in content_list:
content += content_one
item['head'] = head
item['content'] = content
yield item
5.pipelines.py
import json
from scrapy import signals
class SinaPipeline(object):
def process_item(self, item, spider):
sonUrls = item['sonUrls']
# 文件名为子链接url中间部分,并将 / 替换为 _,保存为 .txt格式
filename = sonUrls[7:-6].replace('/', '_')
filename += ".txt"
fp = open(item['subFilename'] + '/' + filename, 'w', encoding='utf-8')
fp.write(item['content'])
fp.close()
return item
6. settings.py
BOT_NAME = 'sina'
SPIDER_MODULES = ['sina.spiders']
NEWSPIDER_MODULE = 'sina.spiders'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 0.5
ITEM_PIPELINES = {
'sina.pipelines.SinaPipeline': 300,
}
# 日志文件名和处理等级
LOG_FILE = "dg.log"
LOG_LEVEL = "DEBUG"
7.main.py
在项目根目录下新建main.py文件,用于调试
from scrapy import cmdline
cmdline.execute('scrapy crawl xinlang'.split())
8.执行程序
运行main.py文件即可
9.效果
能爬一部分新闻,不够完善
请求成功次数:4416
最大深度:2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号