
《读书笔记》记录
父与子的编程之旅(与小卡特一起学python)
- GUI :图形用户界面(graphical user interface),IDLE (Python GUI)
- bug : 意思是“臭虫”。程序员通常把讨厌的错误说成 bug。
- 变量名必须以字母或下划线字符开头。不能以数字开头,变量名中不能包含空格。
- Python 中创建对象包括两步。
- 第一步定义对象看上去什么样,会做什么,也是是定义对象的属性和方法,类似房子的蓝图
- 第二步是建立一个真正的对象,把这个对象称为类的一个实例,也叫类的实例化。类似于用蓝图盖房子·
- 初始化:表示开始时做好准备 ,__ init __ ()
- self 参数会告诉方法哪个对象调用它。这称为实例引用(instance reference)。
- 多态 — 同一个方法,不同的行为
- 继承:像父母学习
- 模块就是某个东西的一部分。模块(module)是包含在一个更大程序中的类似的部分。每个模块或部分都是硬盘上的一个单独的文件。可以把一个大程序分解为多个模块或文件。或者也可以反过来,从一个小的模块开始,逐渐增加其他部分来建立一个大程序。
- 为什么使用模块,类似于积木桶,搭建不同的积木需要不同的积木(模块),多个模块组成不同的程序,文件
- 这样做文件会更小,因而就能更容易地查找代码
- 一旦创建模块,这个模块就能在很多程序中使用。这样下一次需要相同的功 能时就不必再从头开始了
- 并不是所有模块都要使用。模块化意味着你可以使用各部分的不同组合来完 成不同的任务,就像利用同样的一组乐高积木可以搭建不同的东西一样。
- 创建模块,模块就是一个python文件
- 如何使用模块,调用模块,关键字是import
- 程序员把较小的命名空间(比如你的教室)称作局部命名空间,而较大的命名空间(如整个学校)称为全局命名空间。
- fahrenheit = my_module.c_to_f(celsius)
- 指定了命名空间( my _ module )以及函数名( c _ to _ f )
- 像素(pixel)这个词是“图像元素”(picture element)的简写。这表示屏幕上或图像中的一点。如果在一个图像浏览器中查看图片,充分放大(让图像非常大),就可以看到单个的像素。下面是一张照片的正常视图和放大视图,在放大视图中可以看到像素。
# 001:入门
print("I love pizza!")
print("pizza " * 20)
print("yum " * 40)
print("I'm full.")
# 002:猜数字
'''
import random
secret = random.randint(1, 99)
guess = 0
tries = 0
print("猜数字游戏")
print("数字1-99,有6次机会")
while guess != secret and tries < 6:
guess = int(input("你猜的数字是:"))
if guess < secret:
print("猜的太小了")
elif guess > secret:
print("猜的太大了")
tries += 1
if guess == secret:
print("恭喜你,猜对了")
else:
print("机会用完了,你没有猜对数字,秘密数字是%s" % secret)
'''
# 003: 一周有多少秒 打印名片
result = 7 * 24 * 60 * 60
print("一周有%s" % result)
print("我的名字是:奔奔,出生于2020年2月2号,我最喜欢的颜色是黑色")
# 舍入误差
c = 0.1 + 0.2
print(float(c))
# 同一行的输入
'''
print("请输入你的名字:", end="")
somebody = input()
print("hi", somebody, "how are you?")
'''
# 获取互联网信息
'''
import urllib.request
file = urllib.request.urlopen('http://helloworldbook2.com/data/message.txt')
message = file.read()
print(message)
'''
# GUI
import easygui
flavor = easygui.buttonbox("What is your favorite ice cream flavor?", choices=['Vanilla', 'Chocolate', 'Strawberry'])
easygui.msgbox("You picked " + flavor)
用Python写网络爬虫----李斌
-
当抓取的数据是现实生活中的真实数据(比如,营业地址、 电话清单)时, 是允许的。 但是, 如果是原创数据(比如, 意见和评论),通常就会受到版权限制,而不允许了 。
python网络爬虫实战-胡松涛
- 安装
- windows:pip install xxx
- linux:apt-get install xxx
- 编码,解码
- s.decode(xxx):将s解码成xxx
- s.encode(xxx):将s编码成xxx
- re模块-正则表达式
- scrapy安装
- windows:pip install scrapy
- linux:apt-get install python-scrapy
- xpath--基于lxml
- CSS选择器
- 爬虫实战一:金逸影城-今日影视
- 创建项目
- scrapy startproject todayMoive
- 创建爬虫
- scrapy genspider wuHanMoiveSpider jycinema.com
- scrapy.cfg
- 1.定义setting文件的位置
- 2.定义项目名称
- items.py
- 定义爬哪些内容
- settings.py
- 设置文件内容
- pipelines.py
- 对爬取的文件进行处理,包括存储
- spiders
- 所有爬虫文件
- 爬虫填空:items,settings,pipelines,wuHanMoiveSpider
-
import scrapy class TodaymoiveItem(scrapy.Item): # define the fields for your item here like: # 电影名字 moviename = scrapy.Field() # pass -
import scrapy from todayMoive.items import TodaymoiveItem class WuhanmoivespiderSpider(scrapy.Spider): name = 'wuHanMoiveSpider' allowed_domains = ['jycinema.com'] start_urls = ['http://www.jycinema.com/html/default/index.html'] def parse(self, response): subselector = response.xpath('//div[@class="banner"]/ul/li/div') items = [] for sub in subselector: item = TodaymoiveItem() item['moviename'] = sub.xpath('//span[@class="film-title"]/text()').extract() items.append(item) return items -
import time class TodaymoivePipeline(object): def process_item(self, item, spider): now = time.strftime('%Y-%m-%d',time.localtime()) filename = 'wuhan' + now + '.txt' with open(filename,'a') as f: f.write(item['moivename'][0].encode('utf-8') + '\n\n') return item -
ROBOTSTXT_OBEY = False ITEM_PIPELINES = { 'todayMoive.pipelines.TodaymoivePipeline': 300, }
-
- 创建项目
- 爬虫实战二:天气预报
-
import scrapy class WeatherItem(scrapy.Item): # define the fields for your item here like: # 名字 cityname = scrapy.Field() # 日期 week = scrapy.Field() # 图片 img = scrapy.Field() # 温度 temperature = scrapy.Field() # 天气 weather = scrapy.Field() # 风力 wind = scrapy.Field()
-
import scrapy from weather.items import WeatherItem class WhhanspiderSpider(scrapy.Spider): name = 'whhanspider' allowed_domains = ['www.tianqi.com/wuhan'] start_urls = [] citys = ['wuhan'] for city in citys: start_urls.append('http://www.tianqi.com/' + city + '/15/') def parse(self, response): subselector = response.xpath('//div[@class="weatherbox3"]/div/div') for sub in subselector: item = WeatherItem() item['cityname'] = response.xpath('//div[@class="more_day"]/a/text()').extract()[0][:2] item['week'] = sub.xpath('.//h3/b/text()').extract()[0] item['img'] = sub.xpath('.//li[@class="img"]/img/@src').extract()[0] item['temperature'] = sub.xpath('.//li[@class="temp"]/text()').extract()[0][-3:] + sub.xpath('.//li[@class="temp"]/b/text()').extract()[0] + '℃' item['weather'] = sub.xpath('.//li[@class="temp"]/text()').extract()[0][:-3] item['wind'] = sub.xpath('.//ul/li[4]/text()').extract()[0] yield item -
import time import json class WeatherPipeline(object): def __init__(self): today = time.strftime('%Y%m%d', time.localtime()) filename = today + '.txt' self.filename = open(filename, 'wb') def process_item(self, item, spider): text = json.dumps(dict(item), ensure_ascii=False) + '\n' self.filename.write(text.encode('utf-8')) return item def close_spider(self, spider): self.filename.close() -
ROBOTSTXT_OBEY = False DEFAULT_REQUEST_HEADERS = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/604.4.7 (KHTML, like Gecko) Version/11.0.2 Safari/604.4.7', 'Accept-Language': 'en', } ITEM_PIPELINES = { 'weather.pipelines.WeatherPipeline': 300, }
-
-
爬虫实战三:获取代理
-
查询response的内容
-
response.xpath('/*').extract()
-
-
代理
-
使用透明代理,对方服务器可以知道你使用了代理,并且也知道你的真实IP。
-
使用匿名代理,对方服务器可以知道你使用了代理,但不知道你的真实IP。
-
使用高匿名代理,对方服务器不知道你使用了代理,更不知道你的真实IP。
-
-
import scrapy class GetproxyItem(scrapy.Item): # define the fields for your item here like: # ip ip = scrapy.Field() # 端口号 port = scrapy.Field() # 类型 type = scrapy.Field() # 地方 location = scrapy.Field() # http/https protocol = scrapy.Field() # 来源 source = scrapy.Field() -
import scrapy from getproxy.items import GetproxyItem class ProxyXiciSpider(scrapy.Spider): name = 'proxy_xici' allowed_domains = ['www.xicidaili.com'] start_urls = ['http://www.xicidaili.com/nn/1', 'http://www.xicidaili.com/nn/2'] def parse(self, response): subSelector = response.xpath('//tr[@class="odd"]|//tr[@class=" "]') for sub in subSelector: item = GetproxyItem() item['ip'] = sub.xpath('./td[2]/text()').extract()[0] item['port'] = sub.xpath('./td[3]/text()').extract()[0] if sub.xpath('./td[4]/a/text()'): item['location'] = sub.xpath('./td[4]/a/text()').extract()[0] else: item['location'] = '移动' item['type'] = sub.xpath('./td[5]/text()').extract()[0] item['protocol'] = sub.xpath('./td[6]/text()').extract()[0] item['source'] = 'xicidaili' yield item -
import time import json class GetproxyPipeline(object): def __init__(self): today = time.strftime('%Y%m%d', time.localtime()) filename = today + '.txt' self.filename = open(filename, 'wb') def process_item(self, item, spider): text = json.dumps(dict(item), ensure_ascii=False) + '\n' self.filename.write(text.encode('utf-8')) return item def close_spider(self, spider): self.filename.close() -
ROBOTSTXT_OBEY = False DEFAULT_REQUEST_HEADERS = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/604.4.7 (KHTML, like Gecko) Version/11.0.2 Safari/604.4.7', 'Accept-Language': 'en', } ITEM_PIPELINES = { 'getproxy.pipelines.GetproxyPipeline': 300, } - 验证代理是否可用
-
import threading import time import json import telnetlib class TestProxy(object): def __init__(self): today = time.strftime('%Y%m%d', time.localtime()) self.filename = today + '.txt' self.sFile = self.filename self.dFile = r'alive.txt' self.URL = r'http://www.baidu.com' self.threads = 10 self.timeout = 3 self.aliveList = [] self.run() def run(self): with open(self.sFile, 'r',encoding='utf-8') as f: lines = f.readlines() line = lines.pop() line = json.loads(line) while lines: for i in range(self.threads): t = threading.Thread(target=self.linkWithProxy, args=(line,)) t.start() if lines: line = lines.pop() else: continue with open(self.dFile, 'w') as f: for i in range(len(self.aliveList)): f.write(self.aliveList[i] + '\n') def linkWithProxy(self, line): line = json.loads(line) protocol = line['protocol'].lower() ip = line['ip'] port = line['port'] server = protocol + '://' + line['ip'] + ':' + line['port'] print(server) try: response = telnetlib.Telnet(ip, port=port, timeout=self.timeout) except: print('%s 链接失败' % server) return else: print('%s 链接成功!' % server) self.aliveList.append(server) print(self.aliveList) if __name__ == '__main__': TP = TestProxy()
-
-
-
爬虫实战四:利用代理爬糗事百科
-
scrapy shell的简单使用
- response.body
- response.headers
- response.headers['Server']
- response.xpath() 使用 xpath
- response.css() 使用 css 语法选取内容
- view(response):调用浏览器,查看视图
- item.py
-
import scrapy class QiushiItem(scrapy.Item): # define the fields for your item here like: author = scrapy.Field() content = scrapy.Field() img = scrapy.Field() funNum = scrapy.Field() talkNum = scrapy.Field()
-
-
qiushiSpider.py
-
import scrapy from qiushi.items import QiushiItem class QiushispiderSpider(scrapy.Spider): name = 'qiushiSpider' allowed_domains = ['qiushibaike.com'] start_urls = ['http://qiushibaike.com/hot/page/3/'] def parse(self, response): print(response.request.headers['User-Agent']) subSelector = response.xpath('//div[@class="col1 old-style-col1"]/div') for sub in subSelector: item = QiushiItem() item['author'] = sub.xpath('.//h2/text()').extract()[0].strip() item['content'] = sub.xpath('.//div[@class="content"]/span/text()').extract()[0].strip() item['img'] = sub.xpath('.//div[@class="author clearfix"]//img/@src').extract()[0].strip() item['funNum'] = sub.xpath('.//span[@class="stats-vote"]/i/text()').extract()[0].strip() item['talkNum'] = sub.xpath('.//span[@class="stats-comments"]//i/text()').extract()[0].strip() yield item
-
-
pipelines.py
-
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import time import json class QiushiPipeline(object): def __init__(self): today = time.strftime('%Y%m%d', time.localtime()) filename = today + '.txt' self.filename = open(filename, 'wb') def process_item(self, item, spider): text = json.dumps(dict(item), ensure_ascii=False) + '\n' self.filename.write(text.encode('utf-8')) return item def close_spider(self, spider): self.filename.close()
-
-
settings.py
-
ROBOTSTXT_OBEY = False # 关闭系统的UA中间件,使用自己定义的中间件 DOWNLOADER_MIDDLEWARES = { # 自己写的 'qiushi.middlewares.customMiddlewares.CustomUserAgent': 5, # 系统的 'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware':None, } ITEM_PIPELINES = { 'qiushi.pipelines.QiushiPipeline': 300, }
-
-
在Setting同级目录建立包
-

-
customMiddlewares.py
-
from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware class CustomUserAgent(UserAgentMiddleware): def process_request(self, request, spider): ua = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/604.4.7 (KHTML, like Gecko) Version/11.0.2 Safari/604.4.7' request.headers.setdefault('User-Agent', ua) -
这样就可以使用自己的中间件,去设置代理,UA等
-
设置代理后
-
from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware class CustomUserAgent(UserAgentMiddleware): def process_request(self, request, spider): ua = 'User-Agent:Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36' request.headers.setdefault('User-Agent', ua) class CustomProxy(object): def process_request(self, request, spider): request.meta['proxy'] = 'http://117.69.150.177:4216' # request.meta['proxy'] = 'https://218.203.132.117:808' -
settings.py
-
DOWNLOADER_MIDDLEWARES = { 'qiushi.middlewares.customMiddlewares.CustomUserAgent': 10, 'qiushi.middlewares.customMiddlewares.CustomProxy': 30, 'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware':None, 'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':20, }
-
-
-
怎么查询当前使用的IP?
-
-
-
-
爬虫实战五:爬虫攻防
-
研究表明,网络上60%的访问都是网络爬虫
-
封锁间隔时间破解
- scrapy设置DOWNLOAD_DELAY,代表多长时间访问一次网页,网站管理员会根据这个判断你的访问
-
# See also autothrottle settings and docs #DOWNLOAD_DELAY = 3
-
“打枪的不要,悄悄的进村”,如果没有太急的要求,可以设置的稍微大一点,5秒左右
-
封锁Cookies破解
-
cookies验证用户身份,如果一直使用同一个Cookies发送请求也会造成封禁
-
禁用cookies
-
# Disable cookies (enabled by default) #COOKIES_ENABLED = False
-
-
-
封锁User-agent破解
-
User-agent是身份标识,网址据此判断浏览器类型
-
破解方式很简单,准备一大堆user-agent,随机挑选一个使用就行
-
上个爬虫创建的Middlewares目录
-
resource.py
-
UserAgents = [ "Mozilla/5.0 (Linux; U; Android 2.3.6; en-us; Nexus S Build/GRK39F) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1", "Avant Browser/1.2.789rel1 (http://www.avantbrowser.com)", "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/532.5 (KHTML, like Gecko) Chrome/4.0.249.0 Safari/532.5", "Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US) AppleWebKit/532.9 (KHTML, like Gecko) Chrome/5.0.310.0 Safari/532.9", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/534.7 (KHTML, like Gecko) Chrome/7.0.514.0 Safari/534.7", "Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/9.0.601.0 Safari/534.14", "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/10.0.601.0 Safari/534.14", "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.20 (KHTML, like Gecko) Chrome/11.0.672.2 Safari/534.20", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.27 (KHTML, like Gecko) Chrome/12.0.712.0 Safari/534.27", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.24 Safari/535.1", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/15.0.874.120 Safari/535.2", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.36 Safari/535.7", "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10", "Mozilla/5.0 (Windows; U; Windows NT 6.0; en-GB; rv:1.9.0.11) Gecko/2009060215 Firefox/3.0.11 (.NET CLR 3.5.30729)", "Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6 GTB5", "Mozilla/5.0 (Windows; U; Windows NT 5.1; tr; rv:1.9.2.8) Gecko/20100722 Firefox/3.6.8 ( .NET CLR 3.5.30729; .NET4.0E)", "Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0.1) Gecko/20100101 Firefox/4.0.1", "Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0a2) Gecko/20110622 Firefox/6.0a2", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:7.0.1) Gecko/20100101 Firefox/7.0.1", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:2.0b4pre) Gecko/20100815 Minefield/4.0b4pre", ]
-
-
customMiddlewares.py
-
from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware # UA from qiushi.middlewares.resource import UserAgents import random class CustomUserAgent(UserAgentMiddleware): def process_request(self, request, spider): ua = 'User-Agent:Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36' request.headers.setdefault('User-Agent', ua) class CustomProxy(object): def process_request(self, request, spider): request.meta['proxy'] = 'http://117.69.150.177:4216' # request.meta['proxy'] = 'https://218.203.132.117:808' class RandomUserAgent(UserAgentMiddleware): def process_request(self, request, spider): ua = random.choice(UserAgents) request.headers.setdefault('User-Agent',ua) -
setting中禁用第一个中间件,只会设定一次,不能覆盖
-
DOWNLOADER_MIDDLEWARES = { # 'qiushi.middlewares.customMiddlewares.CustomUserAgent': 10, 'qiushi.middlewares.customMiddlewares.CustomProxy': 30, 'qiushi.middlewares.customMiddlewares.RandomUserAgent': 15, 'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware':None, 'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':20, }
-
-
-
-
-
封锁IP破解
-
在反爬虫中最容易发觉的是IP,同一IP访问次数过多,很显然是爬虫
-
使用代理池可以解决
-
在resource.py中加一个代理池
-
PROXIES = [ '1117.69.150.177:4216', '21.36.210.88:8080', '218.203.132.117:808', '111.229.224.145:8118', '120.26.199.103:8118', ]
-
-
customMiddlewares.py中加一个中间件
-
from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware # UA from qiushi.middlewares.resource import UserAgents # proxy from qiushi.middlewares.resource import PROXIES import random class CustomUserAgent(UserAgentMiddleware): def process_request(self, request, spider): ua = 'User-Agent:Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36' request.headers.setdefault('User-Agent', ua) class CustomProxy(object): def process_request(self, request, spider): request.meta['proxy'] = 'http://117.69.150.177:4216' # request.meta['proxy'] = 'https://218.203.132.117:808' class RandomUserAgent(UserAgentMiddleware): def process_request(self, request, spider): ua = random.choice(UserAgents) request.headers.setdefault('User-Agent',ua) class RandomProxy(object): def process_request(self, request, spider): proxy = random.choice(PROXIES) request.META['proxy'] = 'http://%s' %proxy -
在setting中设置一下就行了
-
DOWNLOADER_MIDDLEWARES = { # 'qiushi.middlewares.customMiddlewares.CustomUserAgent': 10, # 'qiushi.middlewares.customMiddlewares.CustomProxy': 30, 'qiushi.middlewares.customMiddlewares.RandomProxy': 5, 'qiushi.middlewares.customMiddlewares.RandomUserAgent': 15, 'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware':None, 'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':20, }
-
-
-
-
-
Beautiful soup爬虫
-
安装bs4
-
windows:pip install beautifulsoup4
-
liuux:apt-get install python-bs4
-
-
安装lxml解析器
-
windows
-
pip install lxml
- pip install wheel
-
-
linux:apt-get install python-lxml
-
-
BS简单使用
-
from bs4 import BeautifulSoup import requests response = requests.get('http://www.baidu.com') soup = BeautifulSoup(response.text,'lxml') print(soup.prettify()) print(soup.p) print(soup.find_all('input')[0]) print(soup.find_all('input')) print(soup.find_all('input',attrs={'name':'f'})[0])
-
-
-
Selenium模拟浏览器
-
安装Selenium
-
windows:pip install selenium
-
linux: apt-get install python-selenium
-
- 安装PhantomJS
- Windows:下载安装包,解压后将exe文件加入系统路径就行
- Linux:下载安装包,解压到系统路径,执行命令tar jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2
- cp phantomjs-2.1.1-linux-x86_64.tar.bz2/bin/phantomjs /usr/local/bin/
- 实战一:爬取年鉴数据
-
import re from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys from pyquery import PyQuery as pq from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait import time from bs4 import BeautifulSoup #browser = webdriver.Chrome() #Wait = WebDriverWait(browser,100) chrome_options = webdriver.ChromeOptions() # prefs = {'profile.managed_default_content_settings.images': 2,'download.default_directory': 'E:\\年鉴\\2016_中国统计年鉴'} prefs = {'download.default_directory': 'E:\\年鉴\\省级年鉴\\海南统计年鉴\\2008_海南统计年鉴'} chrome_options.add_experimental_option("prefs", prefs) browser = webdriver.Chrome(chrome_options=chrome_options) Wait = WebDriverWait(browser,100) def search(): browser.get('http://218.247.211.180:85/CSYDMirror') submit = Wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'body > div.navbox.clearfix > div > ul.linklist.fl > li.item0.mr9 > a'))) submit.click() time.sleep(1) print(browser.current_window_handle) #打印当前句柄 handles=browser.window_handles print(handles) browser.switch_to_window(handles[1])#换新网页的句柄,将browser定位到新网页 print(browser.current_window_handle) #打印切换后句柄 #输入省级统计年鉴名字+点击确定,方法改变采用点击上面标签的方式进行切换省份就不需要再输入省份的名字 shengfen=Wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#divGroup > span:nth-child(1) > a:nth-child(31)'))) shengfen.click() ''' NianJian=Wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#ResultList > div:nth-child(1) > div > div > h3 > a'))) NianJian.click() ''' time.sleep(2) Nianfen=Wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#ResultList > div:nth-child(1) > div > ul > li:nth-child(10) > a'))) Nianfen.click() time.sleep(2) #Wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#div_single_r > div.s_year.clearfix > a:nth-child(36)'))).click() #2012对应nth-child(6) def download_one_year(): html=browser.page_source soup = BeautifulSoup(html,'lxml') #print(soup.prettify()) for i in range(13,45): Wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#div_ml > ul > li:nth-child(' + str(i) + ') > a'))).click() time.sleep(3) Wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#ResultList_jy > table > tbody > tr:nth-child(2) > td:nth-child(1) > a'))).click() time.sleep(3) Wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#PDF'))).click() time.sleep(3) Wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#Model > div.s_name > img'))).click() time.sleep(5) print(i) def main(): search() download_one_year() if __name__=='__main__': main()
-
-
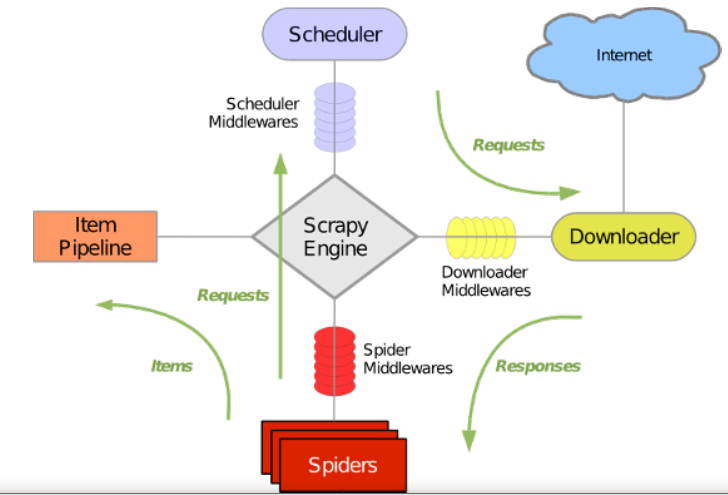
Scrapy_轻松定制网络爬虫
- scrapy使用Twisted这个异步网络库处理网络通信
- 绿线是数据流向
- 初始URL开始,调度器会将其交给下载器下载
- 下载后给爬虫分析,分析后有2种结果
- 结果一:一种是需要进一步爬取链接,如下一页链接,这些东西穿回调度器
- 结果二:需要保持的数据,交给管道文件进行后期处理,分析,过滤,存储等
Learning Scrapy(中文版)
- 看到网页的整个过程分四步
- 在浏览器输入URL。通过域名搜寻服务器,URL和其他像cooies等数据形成一个发送到服务器的request
- 服务器向浏览器发送HTML。
- HTML在浏览器内部转化成树结构:文档对象模型(DOM)
- 根据布局规范,树结构转化成真实画面
- URL包含2部分
- 通过DNS定位服务器。例如http://www.baidu.com,会产生一个www.baidu.com的DNS请求
- 解析服务器的IP地址,将刚才定位的网址,解析成类似http://173.194.81.83的地址
- HTML
- 服务器读取URL,回复HTML文档,本质是个文本文件。
- 尖括号的字符称为标签,标签之间的内容称为元素
- DOM树
- Mac OS中安装scrapy
- easy_install scrapy
- Scrapy 的抓取过程UR2IM

- The URL
- Scrapy shell http://www.baidu.com----先通过shell找出需要的数据
- 请求和响应

- response.body[:50]----打印body前50个字母
- 抓取对象
- 将响应文件提取信息,输入到Item
- 爬虫简单步骤
- 编写Items.py
- 编写爬虫
- 编写pipelines.py,保存到文件
- 编写middleware,py,设置UA,proxy,cookies等
- 编写settings.py,将中间件,管道文件启动
- 运行爬虫
- 后面之后在看。。。
Python爬虫开发与实战-范传辉
- IO编程:Input流
-
- 输入流
- 输出流
- 流=水管,数据=水管里的水,数据的传输需要假设2个水管,一个负责输入,一个负责输出
- open(name,mode,buffering)
- name:唯一强制参数,文件名,可以带存储路径
- mode:模式,默认读模式
- buffering:缓冲区,默认缓冲区为无
- 0:无缓冲
- 1:有缓冲,数据先写到内存,只有使用flush函数或close函数,数据才更新到硬盘
- 大于1:代表缓冲区的大小,单位是字节
- -1(任何负数):代表使用默认缓冲区的大小
- 文件读取
- f.read():一次将文件读入内存,如果文件过大就会出现内存不足
- f.read(size):可以指定读取大小,单位是字节
- f.readline():读一行
- f.readlines():一次读取所有内容,并按行返回列表
- 文件写入
- f.write():写入文件
- 操作文件和目录
- os.getcwd():获取当前工作目录
- os.listdir(路径):返回路径下所有文件和目录名
- os.remove(路径):删除一个文件
- os.removedirs(路径):删除多个空目录
- os.path.isfile(路径):判断是否为文件
- os.path.isdir(路径):判断是否为目录
- os.path.exists(路径):校验路径是否存在
- os.path.split(路径):分离路径下的目录名和文件名
- os.path.splittext(路径):分离扩展名
- os.getenv():读取环境变量
- os.putenv():设置环境变量
- os.name:你使用的平台,Windows--nt,linux/unix-posix
- os.rename(old,new):重命名文件
- os.makedirs(路径):创建多级目录
- os.mkdir():创建单个目录
- os.chmod(file):修改文件权限和时间戳
- os.path,getsize(文件名):获取文件大小
- shutil.copetree('olddir','newdir'):复制文件夹
- shutil.copefile('oldfile','newfile'):复制文件
- os.rmdir(目录名):只能删除空目录
- shutil.rmtree(目录名):目录内全删除
- os.getpid():获取当前进程ID
- os.getppid():获取父进程ID
- 序列化操作
- 将内存中的变量变成可存储或可传输的过程称为序列化
- cPickle.dumps(d):将python对象转化成str进行存储
- Pickle.loads(f):将str在转化成python对象
- 进程和线程
- 多进程
- OS模块中fork方法实现:fork方法调用一次返回两次----只能在linux上使用
-
import os if __name__ == '__main__': print("现在%s进程,正在运行。。。"%(os.getpid())) pid = os.fork() if pid < 0: print("fork出现错误") elif pid == 0: print('我有子进程%s,父进程%s'%(os.getpid(),os.getppid())) else: print("%s进程创建了一个子进程%s"%(os.getpid(),pid)) - 使用multiprocessing模块创建多进程
-
import os from multiprocessing import Process # 子进程需要执行的代码 def run_proc(name): print("子进程%s,ID为%s正在运行。。。" % (name, os.getpid())) if __name__ == '__main__': print("父进程ID为%s" % os.getpid()) for i in range(5): p = Process(target=run_proc, args=(str(i),)) print("进程将要运行。。。") p.start() p.join() print("进程结束!") - 通过进程池批量创建大量子进程,原因是手动限制进程数量太繁琐
-
import os, time, random from multiprocessing import Pool # 子进程需要执行的代码 def run_proc(name): print("子进程%s,ID为%s正在运行。。。" % (name, os.getpid())) time.sleep(random.random() * 3) print("子进程%s结束" % name) if __name__ == '__main__': print("父进程ID为%s" % os.getpid()) # 创建容量为3的进程池 p = Pool(processes=3) # 向进程池添加五个任务 for i in range(5): p.apply_async(run_proc, args=(i,)) print("等待所有子进程运行完成") p.close() p.join() print("所有进程结束!")
-
-
- 进程间的通信
- 进程间通信就是在不同进程之间传播或交换信息。
- 两种进程通信方式Queue和pipe
- Queue:多进程安全的队列
- Put
- blocked
- timeout
- Get
- blocked
- timeout
- 父进程创建三个子进程,子进程往队列写入数据
-
import os, time, random from multiprocessing import Process,Queue # 子进程需要执行的代码 def proc_write(q,urls): print("子进程%s,正在写入数据。。。" % os.getpid()) for url in urls: q.put(url) print('Put %s 进队列'%url) time.sleep(random.random()) print("子进程%s结束" % os.getpid()) def proc_read(q): print('子进程%s正在读数据。。'% os.getpid()) while True: url = q.get(True) print('Get %s 出队列'% url) if __name__ == '__main__': print("父进程ID为%s" % os.getpid()) # 父进程创造Queue并传给子进程 q = Queue() # 建立三个子进程 pro_writer1 = Process(target=proc_write,args=(q,['url_1','url_2','url_3'])) pro_writer2 = Process(target=proc_write,args=(q,['url_4','url_5','url_6'])) pro_reader = Process(target=proc_read,args=(q,)) # 启动子进程写入 pro_writer1.start() pro_writer2.start() # 启动子进程读取 pro_reader.start() # 等待写入的子进程结束 pro_writer1.join() pro_writer2.join() # 读取的子进程是死循环,只能自己结束 pro_reader.terminate() print("所有进程结束!")
-
- Put
- Queue:多进程安全的队列
- Pipe方法返回conn1,conn2代表管道的两端,全双工,都能收发
- 创建2个子进程,一个收,一个发
-
import multiprocessing import random import time, os def proc_send(pipe, urls): for url in urls: print("进程%s,正在发送:%s" % (os.getpid(), url)) pipe.send(url) time.sleep(random.random()) def proc_recv(pipe): while True: print("进程%s.正在接收:%s" % (os.getpid(), pipe.recv())) time.sleep(random.random()) if __name__ == '__main__': pipe = multiprocessing.Pipe() P1 = multiprocessing.Process(target=proc_send, args=(pipe[0], ['url_' + str(i) for i in range(10)])) P2 = multiprocessing.Process(target=proc_recv, args=(pipe[1],)) P1.start() P2.start() P1.join() P2.join()
-
- 创建2个子进程,一个收,一个发
- 多线程
- 多线程类似于同时执行多个不同程序,优点
- 运行时间长的放在后台处理
- 用户界面更吸引人,点击按钮触发事件的同时添加进度条显示进度
- 程序运行加快
- 需要等待的任务实现可以使用进程,用户输入,文件读写,网络收发
- 2个模块,thread和threading,thread是低级模块,threading已经完全取代
- 利用threading创建多线程
- 方法一:函数传入并创建Thread实例
-
import random import time,threading # 新线程执行代码 def thread_run(urls): print("目前线程%s正在运行。。。"%threading.current_thread().name) for url in urls: print("%s --->>>%s"%(threading.current_thread().name,url)) time.sleep(random.random()) print("%s 结束"%threading.current_thread().name) if __name__ == '__main__': print("%s正在运行。。。" % threading.current_thread().name) t1 = threading.Thread(target=thread_run,name='线程1',args=(['url_1','url_2','url_3'],)) t2 = threading.Thread(target=thread_run,name='线程2',args=(['url_4','url_5','url_6'],)) t1.start() t2.start() t1.join() t2.join() print("%s结束"%threading.current_thread().name)
-
- 方法2:直接继承threading.Thread并创建线程类,重写init,run方法
-
import random import time, threading # 继承并重写 class myThread(threading.Thread): def __init__(self, name, urls): threading.Thread.__init__(self, name=name) self.urls = urls def run(self): print("目前线程%s正在运行。。。" % threading.current_thread().name) for url in self.urls: print("%s --->>>%s" % (threading.current_thread().name, url)) time.sleep(random.random()) print("%s 结束" % threading.current_thread().name) if __name__ == '__main__': print("%s正在运行。。。" % threading.current_thread().name) t1 = myThread(name='线程1', urls=['url_1', 'url_2', 'url_3']) t2 = myThread(name='线程2', urls=['url_3', 'url_4', 'url_5']) t1.start() t2.start() t1.join() t2.join() print("%s结束" % threading.current_thread().name)
-
- 方法一:函数传入并创建Thread实例
- 利用threading创建多线程
- 线程同步
- 多个线程对某个数据进行修改,为了保证数据的正确性,需要对多个线程进行同步
- Lock和Rlock
- acquire
- release
-
import time, threading # 锁 mylock = threading.RLock() # 继承并重写 class myThread(threading.Thread): def __init__(self, name): threading.Thread.__init__(self, name=name) def run(self): global Num Num = 0 while True: mylock.acquire() print("%s被锁住,数字:%s" % (threading.current_thread().name, Num)) if Num >= 4: mylock.release() print("%s被释放,数字:%s" % (threading.current_thread().name, Num)) break Num += 1 print("%s被释放,数字:%s" % (threading.current_thread().name, Num)) mylock.release() if __name__ == '__main__': print("%s正在运行。。。" % threading.current_thread().name) t1 = myThread('线程1') t2 = myThread('线程2') t1.start() t2.start() print("%s结束" % threading.current_thread().name)
- 多线程类似于同时执行多个不同程序,优点
- 协程
- 又叫微线程,是一种用户级别的轻量线程
- 拥有自己的寄存器上下文和栈
- 在切换回来的时候保存有上一次调用状态,类似yield
- 在并发编程中,协程类似线程,每一个协程代表一个执行单元,拥有本地数据
- 只要使用yield提供协程的基本支持,gevent库是更好的选择
- 使用greenlet实现切换工作,
- 如果进行IO操作出现阻塞,切换到另一段没有阻塞的代码进行执行
- 等到阻塞消失,在切换回原来代码进行处理
- 本质是一种合理安排的串行方式
- 因为是自动切换,不等待IO,协程比一般多线程效率高
-
from gevent import monkey; monkey.patch_all() import gevent import requests def run_task(url): print('visit---->>>>%s' % url) try: response = requests.get(url) data = response.text print('%d bytes 从%s 接受' % (len(data), url)) except Exception as e: print(e) if __name__ == '__main__': urls = ['https://github.com/', 'https://www.python.org/', 'http://www.cnblogs.com/'] greenlets = [gevent.spawn(run_task, url) for url in urls] gevent.joinall(greenlets)
-
- 支持pool
-
from gevent import monkey; from gevent.pool import Pool monkey.patch_all() import gevent import requests def run_task(url): print('visit---->>>>%s' % url) try: response = requests.get(url) data = response.text print('%d bytes 从%s 接受' % (len(data), url)) except Exception as e: print(e) return 'url:%s----finish'% url if __name__ == '__main__': pool = Pool(2) urls = ['https://github.com/', 'https://www.python.org/', 'http://www.cnblogs.com/'] results = pool.map(run_task,urls) print(results)
-
-
分布式进程
-
将进程分布到多台机器上,充分利用多台机器完成复杂的任务
-
爬虫程序
-
抓取某个网站的全部图片
-
一个进程抓取图片的链接,将链接存储到队列中
- 另外的进程负责从队列中读取链接地址进行下载和存储到本地
-
-
将上面做成分布式
-
一台机器抓链接
-
其他机器负责下载存储,
-
主要问题是将队列暴露到网络中,让其他机器可以访问,分布就将这个过程进行封装
-

-
-
创建分布式的六步
-
建立队列Queue,用来进行进程间的通信。
-
把第一步中的队列在网络上注册,暴露给其他进程(主机),注册后获得网络队列,相当于本地队列的印象
-
建立一个对象实例manager,绑定端口和验证口令
-
启动第三步建立的实例,启动管理manager,监管信息通道
-
通过管理实例方法获得网络访问Queue对象,即再把网络队列实体化成可以使用的本地队列
-
创建任务到“本地”队列中,自动上传任务到网络队列中,分配任务进程进行处理
-
-
- 多进程
-
- 网络编程
-

- TCP
- UDP
-
- HTTP状态码
- 200:请求成功
- 301:请求资源网页等被永久转移到其他URL
- 404:请求资源不存在
- 500:服务器内部错误
- 1xx:信息,服务器接收到请求,需要请求者继续执行操作
- 2xx:成功,操作被成功接收并进行处理
- 3xx:重定向,需要进一步操作以完成请求
- 4xx:客户端错误,请求包含语法错误或无法完成请求
- 5xx:服务器错误,服务器在处理请求的过程中发生了错误
- HTTP请求头部信息
- GET:请求方式
- Host:用于指定请求资源的主机及端口号
- User-Agent:发出请求的信息,包含浏览器型号,版本,操作系统的信息
- Accept:指定客户端接收哪些类型的信息
- Connection:允许发送用于指定连接的选项
- If-Modified-Since:浏览器缓存页面最后修改时间,服务器会对比这个时间和服务器实际文件的最后修改时间。
- Http响应头部信息
- HTTP/1.1:协议标准及状态码
- Data:消息产生的日期及时间
- Content-Type:响应的实际正文媒体类型
- Connection:允许发送用于指定连接的选项
- Vary:用于验证缓存是否存在以及是否过期,若存在且没有过期就返回缓存去回复后续请求
- Cache-Control:用于缓存指令
- Expires:给出响应过期的时间和日期
- cookies及Session
- 初识网络爬虫
- requests
- 正则表达式
- Xpath
- BeautifulSoup
- CSS选择器
- 数据存储
- 存储为json
- 存储为csv
- mysql
- mongodb
- sqlite
- 动态网址爬取
- Ajax和动态HTML
- Ajax:异步JavaScript和XML
- 使用ajax不需要刷新整个页面,只需要对页面的局部进行更新
- DHTML:动态HTML
- 爬虫实战一:爬时光网某一影片的票房信息
- 在页面中可以看到票房

- 在response中无法看到票房
- 在链接的返回值中能找到票房信息
-
http://service.library.mtime.com/
Movie.api?Ajax_CallBack=true&
Ajax_CallBackType=Mtime.Library.Services&
Ajax_CallBackMethod=GetMovieOverviewRating&
Ajax_CrossDomain=1&
Ajax_RequestUrl=http%3A%2F%2Fmovie.mtime.com%2F262895%2F&t=202051722325381387&Ajax_CallBackArgument0=262895 -
var result_202051722325381387 = { "value": { "isRelease": true, "movieRating": { "MovieId": 262895, //电影ID "RatingFinal": 6.3, //综合评分 "RDirectorFinal": 6.5, //导演评分 "ROtherFinal": 6.9, //音乐评分 "RPictureFinal": 7.1, //画面评分 "RShowFinal": 0, // "RStoryFinal": 6.3, //故事评分 "RTotalFinal": 0, "Usercount": 1596, //参与评分人数 "AttitudeCount": 1944, //想看电影人数 "UserId": 0, "EnterTime": 0, "JustTotal": 0, "RatingCount": 0, "TitleCn": "", "TitleEn": "", "Year": "", "IP": 0 }, "movieTitle": "囧妈", //电影名字 "tweetId": 0, "userLastComment": "", "userLastCommentUrl": "", "releaseType": 1, "boxOffice": { "Rank": 0, //排名 "TotalBoxOffice": "0.1", //总票房 "TotalBoxOfficeUnit": "万", //总票房单位 "TodayBoxOffice": "0.0", //今日票房 "TodayBoxOfficeUnit": "万", //今日票房单位 "ShowDays": 0, //上映时间,单位天 "EndDate": "2020-03-15 23:55" } }, "error": null }; var movieOverviewRatingResult = result_202051722325381387;
-
-
直接访问就可以找到数据
-
import requests user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/604.4.7 (KHTML, like Gecko) Version/11.0.2 Safari/604.4.7' headers = { 'User-Agent': user_agent } r = requests.get('http://service.library.mtime.com/Movie.api?Ajax_CallBack=true&Ajax_CallBackType=Mtime.Library.Services&Ajax_CallBackMethod=GetMovieOverviewRating&Ajax_CrossDomain=1&Ajax_RequestUrl=http%3A%2F%2Fmovie.mtime.com%2F262895%2F&t=20205201193216373&Ajax_CallBackArgument0=262895', headers=headers) print(r.text)
-
- 在页面中可以看到票房
-
Selenium+PhantomJS:用无窗口浏览器直接渲染出AJAS文件,然后访问即可
- 案例1:百度的简单访问
-
# 与百度首页交互 from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC option = webdriver.ChromeOptions() # option.add_argument('headless') # 要换成适应自己操作系统的chromedriver # driver = webdriver.Chrome(chrome_options=option) chrome_options = webdriver.ChromeOptions() driver= webdriver.Chrome(chrome_options=chrome_options) url = 'https://www.baidu.com' # 打开网站 driver.get(url) # 打印当前页面标题 print(driver.title) # 在搜索框中输入文字 timeout = 5 search_content = WebDriverWait(driver, timeout).until( # lambda d: d.find_element_by_xpath('//input[@id="kw"]') EC.presence_of_element_located((By.XPATH, '//input[@id="kw"]')) ) search_content.send_keys('python') import time time.sleep(3) # 模拟点击“百度一下” search_button = WebDriverWait(driver, timeout).until( lambda d: d.find_element_by_xpath('//input[@id="su"]')) search_button.click() # 打印搜索结果 search_results = WebDriverWait(driver, timeout).until( # lambda d: d.find_elements_by_xpath('//h3[@class="t c-title-en"] | //h3[@class="t"]') lambda e: e.find_elements_by_xpath('//h3[contains(@class,"t")]/a[1]') ) # print(search_results) for item in search_results: print(item.text) driver.close()
-
- 案例1:百度的简单访问
- 分析Ajax接口
- 案例1:当当网抓评论,网页缩短,就一个一直删除看看能否删除,直到找到最短URL
-
# 抓取当当网书评 # http://product.dangdang.com/25340451.html import json import requests from lxml import etree for i in range(1,5): # url = 'http://product.dangdang.com/index.php?r=comment/list&productId=25340451&pageIndex=1' url = 'http://product.dangdang.com/index.php?r=comment/list&productId=25340451&categoryPath=01.07.07.04.00.00&mainProductId=25340451&mediumId=0&pageIndex={}'.format(i) header = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 ' '(KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36' } response = requests.get(url, headers=header, timeout=5 ) # print(response.text) result = json.loads(response.text) # comment_html = result['data']['list']['html'] # tree = etree.HTML(comment_html) # comments = tree.xpath('//div[@class="items_right"]') # for item in comments: comment_time = item.xpath('./div[contains(@class,"starline")]/span[1]/text()')[0] comment_content = item.xpath('./div[contains(@class,"describe_detail")]/span[1]//text()')[0] print(comment_time) print(comment_content)
-
- 案例二:非小号
-
# 抓取非小号的图表接口 # https://www.feixiaohao.com/currencies/raiden-network-token/ import requests import json header = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 ' '(KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36' } # url = 'https://api.feixiaohao.com/coinhisdata/raiden-network-token/1540252714000/1540339114000/' # url = 'https://dncapi.feixiaohao.com/api/coin/charts?code=raiden-network-token&type=d&webp=0' url = 'https://dncapi.bqiapp.com/api/coin/web-charts?code=raiden-network-token&type=d&webp=1' response = requests.get(url, headers=header, timeout=5 ) result = json.loads(response.text) print(result) print(result.keys())
-
- 案例三:金色财经,快讯
-
# 抓取金色财经快讯接口 # https://www.jinse.com/lives import requests import json header = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 ' '(KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36' } url = 'https://api.jinse.com/v4/live/list?limit=20&reading=false&flag=up' response = requests.get(url, headers=header, timeout=5 ) result = json.loads(response.text) # print(result) # json格式分析工具:http://www.bejson.com/ for item in result['list'][0]['lives']: # print(item) timestamp = item['created_at'] content = item['content'] print(timestamp) print(content)
-
- 案例四:36氪快讯
-
# 抓取36氪快讯 # https://36kr.com/newsflashes import requests import json header = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 ' '(KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36' } url = 'https://36kr.com/api/newsflash?&per_page=20' response = requests.get(url, headers=header, timeout=5 ) # print(json.loads(response.text)) data = json.loads(response.text)['data'] # print(data) items = data['items'] # print(items) for item in items: # print(item) item_info = {} title = item['title'] item_info['title'] = title description = item['description'] item_info['content'] = description published_time = item['published_at'] item_info['published_time'] = published_time print(item_info)
-
-
链家爬虫
-
import requests from bs4 import BeautifulSoup import json from mongodatabase import database_mongo # 思路分析 和 伪代码(汉字 开发思路) # 1.查找入口 分析 url https://bj.lianjia.com/ # 2.准确的url : https://bj.lianjia.com/ershoufang/rs%E4%B8%9C%E5%9F%8E%E5%8C%BA/ class Lianjia_Spider(object): # 2.python 代码 实现发送请求 def __init__(self): self.place = input('请输入想抓取的地区:') self.base_url = 'https://bj.lianjia.com/ershoufang/rs' + self.place # 最大的数据集合 self.data_list = [] def get_data(self): # 不同页面 应该有不同的 url data = requests.get(self.base_url).content.decode('utf-8') return data # 3.接收返回的数据 解析 def parse_data(self, data): # 3.1 将 爬虫获取的数据 解析类型转换 soup = BeautifulSoup(data, 'lxml') # 3.2 根据css选择器 提取数据验证 列表数组 # 1.解析出数据列表 data_list = soup.select('.sellListContent li') # 遍历 每一个条数据 提取详细信息 for li in data_list: # 用字典 标识数据 key:Value dict_data = {} # 1.房屋标题 # li -- > a --> img --->alt if len(li.select('a img')) > 0: dict_data['room_name'] = li.select('a img')[0].get('alt') # 2. 房屋信息 if len(li.select('.houseInfo')) > 0: dict_data['content'] = li.select('.houseInfo')[0].get_text() # 3. 价格 if len(li.select('.totalPrice')) > 0: dict_data['price'] = li.select('.totalPrice')[0].get_text() # 将所有的 dict 数据 再次放入一个 大篮子里面 self.data_list.append(dict_data) # 4.保存数据 本地文件 def save_data_file(self): # 首先保存到 本地文件查看 看是否是静态数据页面 # 写入本地文件 必须是字符串类型 所以我们需要转换类型 data_str = json.dumps(self.data_list) with open('data.json', 'w') as f: f.write(data_str) print('数据保存成功!') # 5. 保存到 mongo数据库里面 def save_mongo_base(self): # 1.有数据库 data_base = database_mongo('127.0.0.1',27017,'Lianjia','room') # 2. 保存 data_base.save_data(self.data_list) print('保存成功!') # 6.开启爬虫 def start(self): data = self.get_data() # 2. 解析数据 self.parse_data(data) # 3. 保存数据 文件 # spider.save_data_file() # 4. 保存数据库 self.save_mongo_base() if __name__ == '__main__': Lianjia_Spider().start()
-
- 案例1:当当网抓评论,网页缩短,就一个一直删除看看能否删除,直到找到最短URL
- Ajax和动态HTML
-
Scrapyd
- 部署和运行scrapy spider的应用。使用JSON API部署并控制API
- 可以管理多个工程
- 安装scrapyd
- pip install scrapyd
- 测试
- scrapyd
- 将scrapy部署到scrapyd
- 安装上传工具
- pip install scrapyd-client
- 上传方法
- python scrapy-deploy的安装路径 targe 主机地址 project 工程名
- 安装调度工具curl
- 安装上传工具
`
简明python教程---swaroop
- .pyc文件
- 因为模块的导入比较费时,为了使模块的导入加快,创建的字节编译文件
- pyc是一种二进制文件,是由py文件经过编译后,生成的文件,是一种byte code,py文件变成pyc文件后,加载的速度有所提高,而且pyc是一种跨平台的字节码,是由python的虚拟机来执行的,这个是类似于JAVA或者.NET的虚拟机的概念。
- 关键词:二进制,跨平台,字节码,加快加载速度
- 软件开发过程
- 什么(分析)
- 如何(设计)
- 编写(实施)
- 测试(测试与调试)
- 使用(实施或开发)
- 维护(优化)
漫画算法(小灰的算法之旅)---魏梦舒(程序猿小灰)
小灰和大黄:菜鸟和大神
- 什么是算法?:算法就是用于解决某一类问题的公式和思想(高斯算法的例子)
- 衡量算法好坏的标准
- 时间复杂度:运行时间,时间成本
- 又叫渐进时间复杂度,指当n趋向于无穷大时,T(n)的极值
- O(f(n),渐进时间复杂度用O表示,又叫大O表示法
- 空间复杂度:占用空间,空间成本
- 执行算法的时间成本
- 如何计算
- 常量空间:O(1)
- 固定长度的存储空间,和输入规模没有直接关系
- 线性空间:O(n)
- 算法的分配空间是一个线性的集合,如数组,列表,集合大小与输入规模成正比
- 二维空间:O(n^2)
- 算法分配空间是一个二维数组集合,长宽都和输入规模成正比
- 递归空间:O(n)
- 递归代码,会专门分配一块存储,叫“方法调用栈”
- 进入一个新方法,执行入栈操作,将调用方法和参数压入栈中
- 返回时,执行出栈操作,将调用的方法和参数信息弹出栈
- 递归操作所需要的内存与递归的深度成正比
- 常量空间:O(1)
- 时间复杂度:运行时间,时间成本
- 应用场景
- 运算
- 查找
- 排序
- 最优决策
- 面试
- 衡量算法好坏的标准
- 什么是数据结构?:是数据的组织,管理和存储格式,其目的是高效的访问和修改数据
- 常见的组成方式
- 线性结构
- 数组:python中的列表---正规军
- 有限个相同类型的变量所组成的有序集合,顺序存储
- 数组的基本操作
- 读取元素
- 更新元素
- 插入元素
- 尾部插入:等同于更新操作
- 中间插入:后面的元素向后挪一位,
- 超范围插入:创建2倍大小的数组,复制原数组元素,然后进行插入
- 删除元素
- 优势
- 非常高效的随机访问能力,下标找元素,例二分查找
- 劣势
- 插入和删除都会被迫移动其他元素,影响效率
- 适合场景:读操作多,写操作少
- 链表:地下党,只知道上下级姓名和地址,其他一概不知,单线联络
- 单链表
- 双向链表
- 存储方式:随机存储,不需要连续的内存空间
- 基本操作
- 查找节点
- 更新节点
- 插入节点
- 尾部插入
- 头部插入
- 中间插入
- 删除元素
- 尾部删除
- 头部删除
- 中间删除
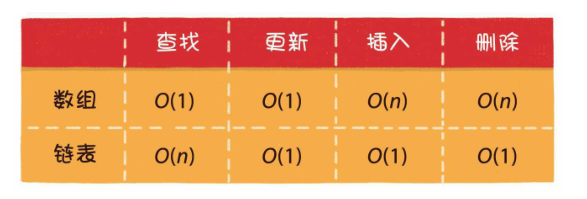
- 单链表
- 栈

- 可以用线性表实现,也可用链表实现
- 基本操作
- 入栈
- 出栈
- 输出顺序和输入顺序相反,通常用来做历史的回溯
- 网页的上一级页面的制作
- 网页的上一级页面的制作
- 队列

- 同样可以用线性表实现,也可以用链表实现
- 基本操作
- 入队
- 出队
- 输入顺序和输出顺序一致,可以用来做历史的回放
- 多线程锁的顺序,爬虫中待爬取的URL的存取
- 双端队列,栈+队列
- 优先队列,谁优先级最高,谁先出队:二叉堆来实现
- 哈希表(散列表)
- 就是python中的字典,键值对的形式
- 如何通过键找出对应的值?
- 哈希函数
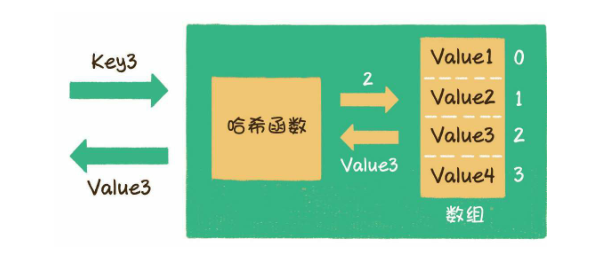
- 值存在list中,哈希函数,我们可以把字符串或其他类型的Key,转化成数组的下标index。
- 基本操作
- 写操作,put
- 读操作,get
- 扩容,resize
- 数组:python中的列表---正规军
- 树
- 二叉树
- 存储
- 链式存储
- 数组存储
- 链式存储
- 二叉树的作用
- 查找:索引
-
如果左子树不为空,则左子树上所有节点的值均小于根节点的值
如果右子树不为空,则右子树上所有节点的值均大于根节点的值
左、右子树也都是二叉查找树 -
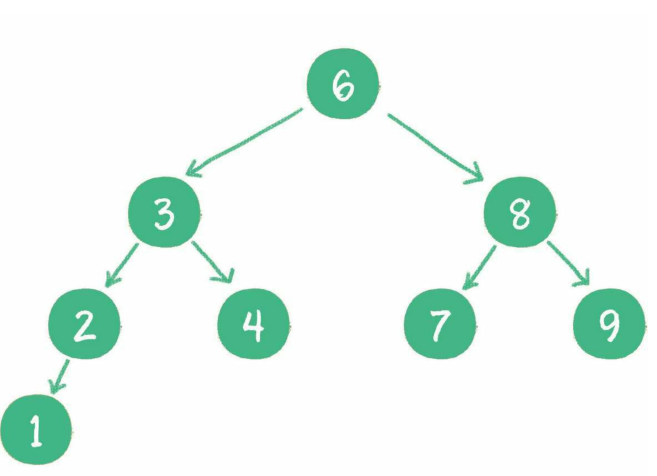
- 查找一个数,时间复杂度等于数的深度,比如查找4,3步就能找到,类似于二分查找
- 时间复杂度:O(logn)
-
- 维持相对顺序
- 二叉查找树又叫二叉排序树
- 新放入的值会按照规则放在合适的位置,以维持相对顺序
- 存在致命问题,插入9,8,7...
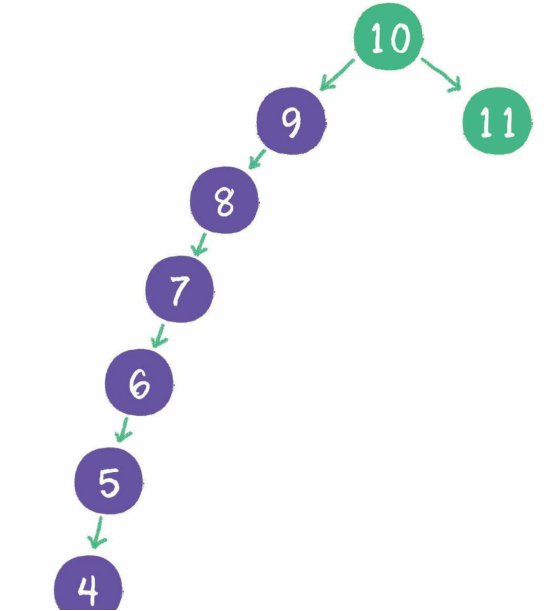
- 解决方法涉及到树的自平衡:红黑树、AVL树、树堆等
- 查找:索引
- 二叉树的遍历
-
1. 深度优先遍历(前序遍历、中序遍历、后序遍历)。
-
2. 广度优先遍历(层序遍历)
-
- 存储
- 二叉堆
- 根节点叫作堆顶
- 最大堆
- 最大堆的任何一个父节点的值,都大于或等于它左、右孩子节点的值。
- 堆顶是整个堆中的最大元素
- 最小堆
- 最小堆的任何一个父节点的值,都小于或等于它左、右孩子节点的值。
- 堆顶是整个堆中的最小元素
- 二叉堆的自我调整
- 插入节点,插入到最后一位,按照二叉堆的规则交互位置,使插入的节点放在合适的位置
- 删除节点,,删除根节点,让最后一位补在根节点
- 构建二叉堆,非叶子节点依次下沉
- 二叉堆的应用
- 实现堆排序和优先队列的基础
- 优先队列
- 最大优先队列:实现方式取最大堆堆顶元素
- 最小优先队列:实现方式取最小堆堆顶元素
- 二叉树
- 排序算法
- 时间复杂度是O(n 2 )的排序算法
-
冒泡排序:小的上浮,大的下沉(实现方式,交换)
- 鸡尾酒排序
- 先找最大的放右边,在找最小的放左边,重复
- 排序过程就像钟摆一样,第1轮从左到右,第2轮从右到左,第3轮再从左到右……
- 适用场景,大部分元素就已经有序
- 鸡尾酒排序
-
选择排序:
-
插入排序
-
希尔排序(希尔排序比较特殊,它的性能略优于O(n 2 ),但又比不上O(nlogn),姑且把它归入本类)
-
- 时间复杂度为O(nlogn)的排序算法
- 快速排序:冒泡排序的改进,每次挑选一个基准元素,比他小的在左边,比他大的在右边,分治法
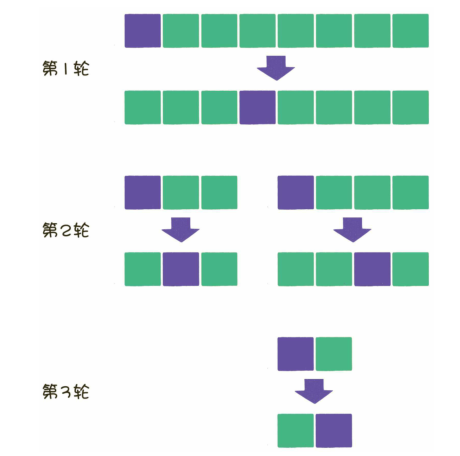
- 基准元素的选择
- 选第一个元素
- 归并排序
- 堆排序
- 利用二叉堆的特点,每次找出堆顶元素,实现排序
- 快速排序:冒泡排序的改进,每次挑选一个基准元素,比他小的在左边,比他大的在右边,分治法
- 时间复杂度为线性的排序算法
- 计数排序
- 利用数组下标来确定元素的正确位置
- 建立数组,每有一个元素相应位置元素加1,然后利用数组的下标进行排序
- 计数的长度=最大值-最小值+1
- 解决相同元素的排序问题:从第二个元素开始,每个元素加上前一个元素的数字,就可以确定该元素位于什么位置
- 桶排序
- 创建桶,确定区间范围
- 遍历原始数列,把元素对号入座放入各个桶中
- 对每个桶内部的元素分别进行排序(显然,只有第1个桶需要排序)。
- 遍历所有的桶,输出所有元素。
- 0.5,0.84,2.18,3.25,4.5
- 创建桶,确定区间范围
- 基数排序
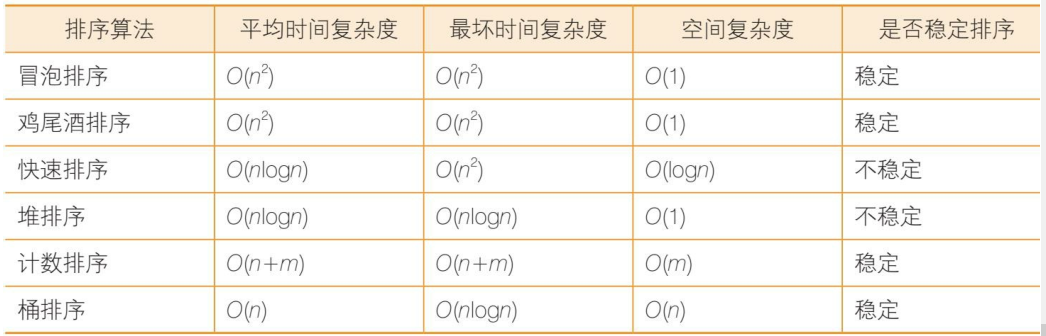
- 计数排序
- 时间复杂度是O(n 2 )的排序算法
- 图
- 其他数据结构
- 跳表
- 哈希链表
- 位图
- 线性结构
- 面试中的算法
- 有一个单向链表,链表中可能有环,如何用程序判断?
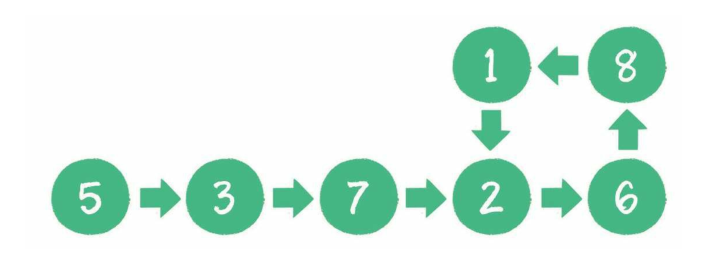
- 方法1:遍历链表,如果元素有重复就说明有环,比较前面所有节点(重复了2遍)O(n2) O(1)
- 方法2:以节点ID做一个哈希表,用于存储遍历的数据,每次遍历比较数据,重复说明有环(多了一个哈希表做缓存)O(n) O(n)
- 方法3:创建2个指针,P1每次移动一位,P2每次移动2位,如果指向同一节点就说明有环----利用追击问题的思想,速度不一样迟早追上。O(n) O(1)
- 问题扩展:如果链表有环,如何求出环的长度以及环的节点?
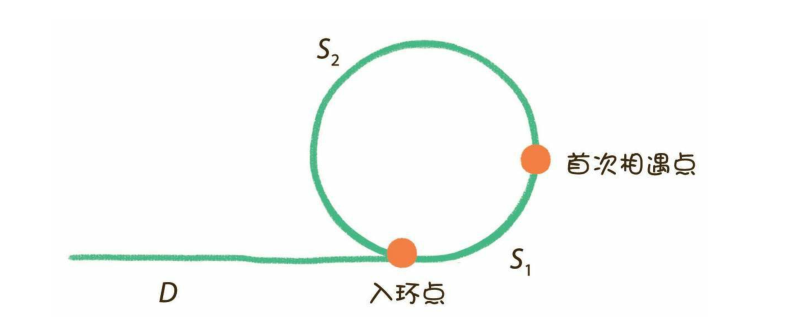
- 方法1:让2个指针从相遇位置重新开始,下次相遇走的前进的次数就是环的长度。
- 2(D+S 1 ) = D+S 1 +n(S 1 +S 2 ) ------D = (n-1)(S 1 +S 2 )+S 2
- 只要把其中一个指针放回到头节点位置,另一个指针保持在首次相遇点,两个指针都是每次向前走1步。那么,它们最终相遇的节点,就是入环节点。
- 然后根据入环点,求出环的各个节点
- 实现一个栈,有入栈,出栈,取最小元素三个方法且时间复杂度都是O(1)
- 方法1:一个栈实现入栈,出栈,利用另一个栈实现最小元素的管理

- 入栈存储最小元素在栈B,没有一个新的最小值让其入栈
- 如果出栈是最小值,让B也出栈,这样栈B永远都保存栈A的最小值
- 方法1:一个栈实现入栈,出栈,利用另一个栈实现最小元素的管理
- 写一段代码求两个整数的最大公约数,要尽可能优化算法的性能
- 辗转相处法,欧几里得算法。一个定理:两个正整数a和b(a>b),它们的最大公约数等于a除以b的余数c和b之间的最大公约数。
- 计算出a除以b的余数c,把问题转化成求b和c的最大公约数;然后计算出b除以c的余数d,把问题转化成求c和d的最大公约数;再计算出c除以d的余数e,把问题转化成求d和e的最大公约数……以此类推,逐渐把两个较大整数之间的运算简化成两个较小整数之间的运算,直到两个数可以整除,或者其中一个数减小到1为止。
- 更相减损术。两个正整数a和b(a>b),它们的最大公约数等于a-b的差值c和较小数b的最大公约数。---九章算术
- 例如10和25,25减10的差是15,那么10和25的最大公约数,等同于10和15的最大公约数。直到两个数可以相等为止,最大公约数就是最终相等的这两个数的值。
- 辗转相处法,欧几里得算法。一个定理:两个正整数a和b(a>b),它们的最大公约数等于a除以b的余数c和b之间的最大公约数。
- 实现一个方法,来判断一个正整数是否是2的整数次幂(如16是2的4次方,返回true;18不是2的整数次幂,则返回false)。要求性能尽可能高。
- 笨方法:给一个数,乘2与其比较,比他小就继续乘,比他大就Flase,等于就true
- 方法1:二进制的角度,对于一个整数n,只需要计算n&(n-1)的结果是不是0。这个方法的时间复杂度只有O(1)。
- 有一个无序整型数组,如何求出该数组排序后的任意两个相邻元素的最大差值?要求时间和空间复杂度尽可能低。
- 笨方法1:排序,遍历求差
- 方法2:利用计数排序的思想,创建最大值-最小值的空间,找出0出现最多的次数
- 方法3:利用桶排序的思想,根据数组长度n建立跨度为(max-min)/(n-1),n个桶,不需要排序找出每个桶的最大值最小值,然后找出最大相邻差
- 用栈来模拟一个队列,要求实现队列的两个基本操作:入队、出队。
- 两个栈,压入顺序相反,一个作为入队,一个作为出队
- 假设给出一个正整数,请找出这个正整数所有数字全排列的下一个数。(在一个整数所包含数字的全部组合中,找到一个大于且仅大于原数的新整数。)
- 字典序算法。保持高位不变,低位在最小的范围内变换顺序。至于变换顺序的范围大小,则取决于当前整数的逆序区域。
- 从后向前查看逆序区域,找到逆序区域的前一位,也就是数字置换的边界。
- 让逆序区域的前一位和逆序区域中大于它的最小的数字交换位置。
- 把原来的逆序区域转为顺序状态 。
- 字典序算法。保持高位不变,低位在最小的范围内变换顺序。至于变换顺序的范围大小,则取决于当前整数的逆序区域。
- 给出一个整数,从该整数中去掉k个数字,要求剩下数字形成的新整数尽可能小。应该如何选取被去掉的数字?其中整数长度大于或等于k,给出的整数的大小可以超过long类型的数字范围。
- 贪心算法:依次求得局部最优解,最终得到全局最优解的思想
- 简化思想,删除1个数字,怎么变的最小-----删除高位
- 把原整数的所有数字从左到右进行比较,如果发现某一位数字大于它右面的数字,那么在删除该数字后,必然会使该数位的值降低,因为右面比它小的数字顶替了它的位置。
- 贪心算法:依次求得局部最优解,最终得到全局最优解的思想
- 给出两个很大的整数,要求实现程序求出两个整数之和。例如2个100位的和
- 用数组存储每一位元素,426 709 752 31 8+95 481 253 129
- 创建两个整型数组,数组长度是较大整数的位数+1。把每一个整数倒序存储到数组中,整数的个位存于数组下标为0的位置,最高位存于数组的尾部。之所以倒序存储,是因为这样更符合从左到右访问数组的习惯。
- 创建结果数组,结果数组的长度同样是较大整数的位数+1,+1的目的很明显,是给最高位进位预留的
- 遍历两个数组,从左到右按照对应下标把元素两两相加,就像小学生计算竖式一样。进位放在下一位
- 把result数组的全部元素再次逆序,去掉首位的0,就是最终结果。522191005447
- 创建两个整型数组,数组长度是较大整数的位数+1。把每一个整数倒序存储到数组中,整数的个位存于数组下标为0的位置,最高位存于数组的尾部。之所以倒序存储,是因为这样更符合从左到右访问数组的习惯。
- 优化方案,没必要分的这么细,只需要拆分到可以计算就行,int -2 147 483 648~2 147 483 647,9位一个就行
- 用数组存储每一位元素,426 709 752 31 8+95 481 253 129
- 很久很久以前,有一位国王拥有5座金矿,每座金矿的黄金储量不同,需要参与挖掘的工人人数也不同。例如有的金矿储量是500kg黄金,需要5个工人来挖掘;有的金矿储量是200kg黄金,需要3个工人来挖掘……如果参与挖矿的工人的总数是10。每座金矿要么全挖,要么不挖,不能派出一半人挖取一半的金矿。要求用程序求出,要想得到尽可能多的黄金,应该选择挖取哪几座金矿?

- 动态规划题目,和著名的“背包问题”类似
- 假设一个金矿挖或不挖
- 不挖---简化为10人4金矿问题,可以继续往下递归
- 挖,确定一个金矿,简化成7人4金矿的问题,继续递归
- 就按照这个思想找出问题的边界,求出最优解

- 在一个无序数组里有99个不重复的正整数,范围是1~100,唯独缺少1个1~100中的整数。如何找出这个缺失的整数?
- 笨方法:创建哈希表,遍历,找出没有的数字
- 笨方法2:排序,找出不连续的数字
- 方法3:1-100的累加和减去存储的累加和就是缺失的数字
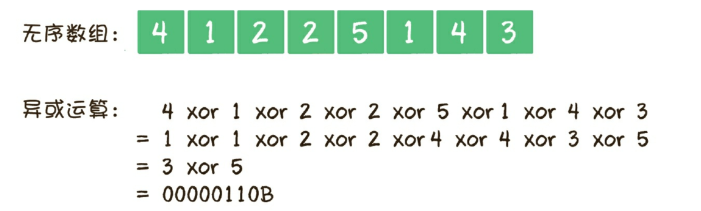
- 扩展:一个无序数组里有若干个正整数,范围是1~100,其中99个整数都出现了偶数次,只有1个整数出现了奇数次,如何找到这个出现奇数次的整数?
- 全部异或,最后剩下的数就是所求的数
- 全部异或,最后剩下的数就是所求的数
- 扩展2:假设一个无序数组里有若干个正整数,范围是1~100,其中有98个整数出现了偶数次,只有2个整数出现了奇数次,如何找到这2个出现奇数次的整数?
- 分治法
- 异或运算
- 按照倒数的第二位不同,分为2类扩展1的问题
- 在根据扩展1,求得答案
- 有一个单向链表,链表中可能有环,如何用程序判断?
- 算法的实际应用
- 一个关于用户标签的需求,太多标签数据库太乱,数据查询慢
- Bitmap算法,又叫作位图算法。位图表示内存中连续的二进制位(bit)所组成的数据结构,该算法主要用于对大量整数做去重和查询操作
- 第1步,建立用户名和用户ID的映射。
- 让每一个标签存储包含此标签的所有用户ID,每一个标签都是一个独立的Bitmap。
- 现在公司的业务越来越复杂,我们需要抽出一个用户系统,向各个业务系统提供用户的基本信息。业务方对用户信息的查询频率很高,一定要注意性能问题哦。
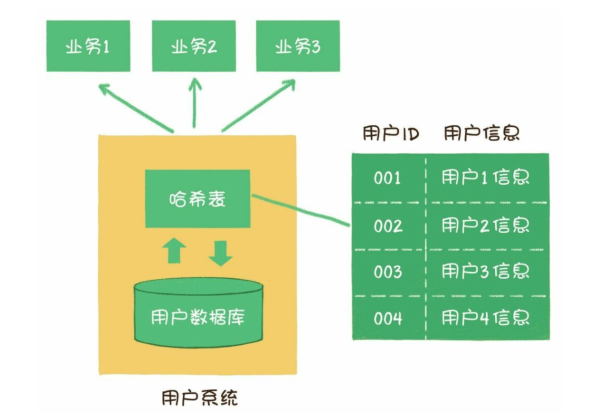
- 哈希表内存不够,引起服务器宕机
- LRU全称Least Recently Used,也就是最近最少使用的意思,是一种内存管理算法,
- 这个算法基于一种假设:长期不被使用的数据,在未来被用到的几率也不大。因此,当数据所占内存达到一定阈值时,我们要移除掉最近最少被使用的数据。
- 1. 假设使用哈希链表来缓存用户信息,目前缓存了4个用户,这4个用户是按照被访问的时间顺序依次从链表右端插入的。
- 2. 如果这时业务方访问用户5,由于哈希链表中没有用户5的数据,需要从数据库中读取出来,插入到缓存中。此时,链表最右端是最新被访问的用户5,最左端是最近最少被访问的用户1。
- 3. 接下来,如果业务方访问用户2,哈希链表中已经存在用户2的数据,这时我们把用户2从它的前驱节点和后继节点之间移除,重新插入链表的最右端。此时,链表的最右端变成了最新被访问的用户2,最左端仍然是最近最少被访问的用户1。
- 4. 接下来,如果业务方请求修改用户4的信息。同样的道理,我们会把用户4从原来的位置移动到链表的最右侧,并把用户信息的值更新。这时,链表的最右端是最新被访问的用户4,最左端仍然是最近最少被访问的用户1。
- 5. 后来业务方又要访问用户6,用户6在缓存里没有,需要插入哈希链表中。假设这时缓存容量已经达到上限,必须先删除最近最少被访问的数据,那么位于哈希链表最左端的用户1就会被删除,然后再把用户6插入最右端的位置。
- redis的底层也是类似LRU实现的
- 迷宫寻路
- AI找到主角
- A星寻路算法,寻找有效路径的算法。
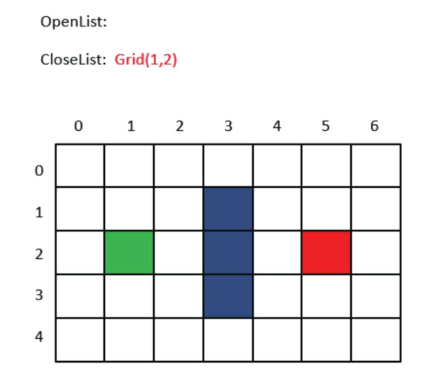
- 迷宫游戏的场景通常都是由小方格组成的。假设我们有一个7×5大小的迷宫,上图中绿色的格子是起点,红色的格子是终点,中间的3个蓝色格子是一堵墙。

- G:从起点走到当前格子的成本,也就是已经花费了多少步。
- H:在不考虑障碍的情况下,从当前格子走到目标格子的距离,也就是离目标还有多远。
- F:G和H的综合评估,也就是从起点到达当前格子,再从当前格子到达目标格子的总步数。
- 第1步,把起点放入OpenList,也就是刚才所说的可到达格子的集合。
- 第2步,找出OpenList中F值最小的方格作为当前方格。虽然我们没有直接计算起点方格的F值,但此时OpenList中只有唯一的方格Grid(1,2),把当前格子移出OpenList,放入CloseList。代表这个格子已到达并检查过了。
- 第3步,找出当前方格(刚刚检查过的格子)上、下、左、右所有可到达的格子,看它们是否在OpenList或CloseList当中。如果不在,则将它们加入OpenList,计算出相应的G、H、F值,并把当前格子作为它们的“父节点”。

- 每个格子的左下方数字是G,右下方是H,左上方是F。
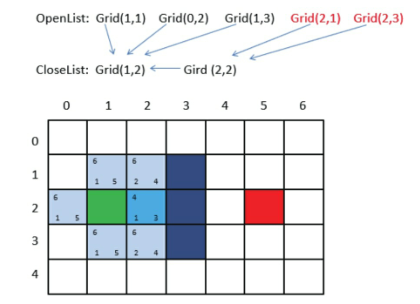
- A星寻路的第2轮操作。
- 第1步,找出OpenList中F值最小的方格,即方格Grid(2,2),将它作为当前方格,并把当前方格移出OpenList,放入CloseList。代表这个格子已到达并检查过了。
- 第2步,找出当前方格上、下、左、右所有可到达的格子,看它们是否在OpenList或CloseList当中。如果不在,则将它们加入OpenList,计算出相应的G、H、F值,并把当前格子作为它们的“父节点”。
- 第3轮寻路
- 第1步,找出OpenList中F值最小的方格。由于此时有多个方格的F值相等,任意选择一个即可,如将Grid(2,3)作为当前方格,并把当前方格移出OpenList,放入CloseList。代表这个格子已到达并检查过了。
- 重复
- 第1步,找出OpenList中F值最小的方格。由于此时有多个方格的F值相等,任意选择一个即可,如将Grid(2,3)作为当前方格,并把当前方格移出OpenList,放入CloseList。代表这个格子已到达并检查过了。

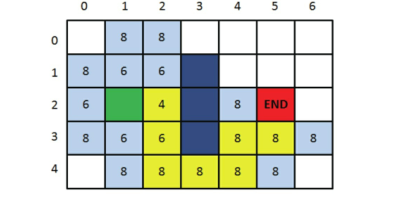
- 像这样一步一步来,当终点出现在OpenList中时,我们的寻路之旅就结束了。
- 还记得刚才方格之间的父子关系吗?我们只要顺着终点方格找到它的父亲,再找到父亲的父亲……如此依次回溯,就能找到一条最佳路径了。
- 第1步,找出OpenList中F值最小的方格,即方格Grid(2,2),将它作为当前方格,并把当前方格移出OpenList,放入CloseList。代表这个格子已到达并检查过了。
- 迷宫游戏的场景通常都是由小方格组成的。假设我们有一个7×5大小的迷宫,上图中绿色的格子是起点,红色的格子是终点,中间的3个蓝色格子是一堵墙。
- A星寻路算法,寻找有效路径的算法。
- 拼手气红包的实现
- 1. 所有人抢到的金额之和要等于红包金额,不能多也不能少。
- 2. 每个人至少抢到1分钱。
- 3. 要保证红包拆分的金额尽可能分布均衡,不要出现两极分化太严重的情况。
- 方法1:二倍均值法:就是把每次随机金额的上限定为剩余人均金额的2倍。
- 100元,5个人,范围都是[0.01,39.99],平均是20元
- 方法虽然公平,但也存在局限性,即除最后一次外,其他每次抢到的金额都要小于剩余人均金额的2倍,并不是完全自由地随机抢红包。
- 方法2:线段切割法

- 5个人,抢红包就找到4个随机点即可
- AI找到主角
- 一个关于用户标签的需求,太多标签数据库太乱,数据查询慢
- end
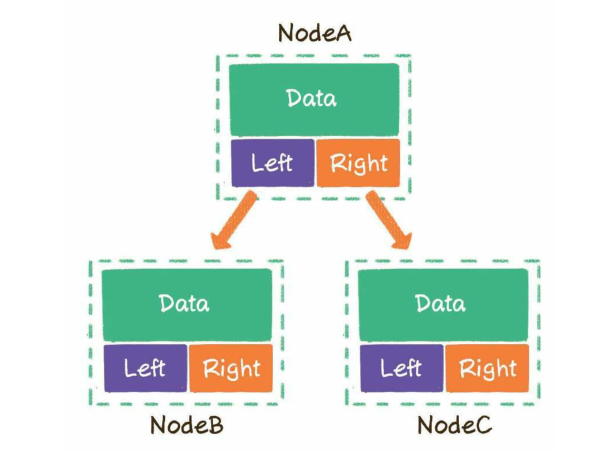
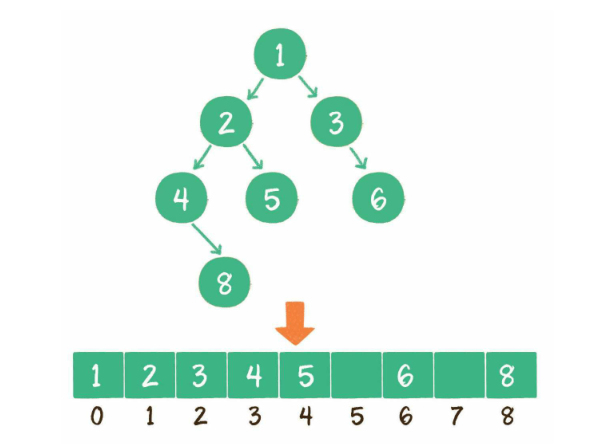

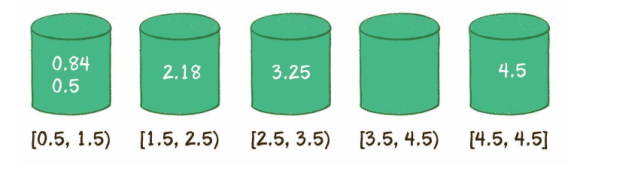

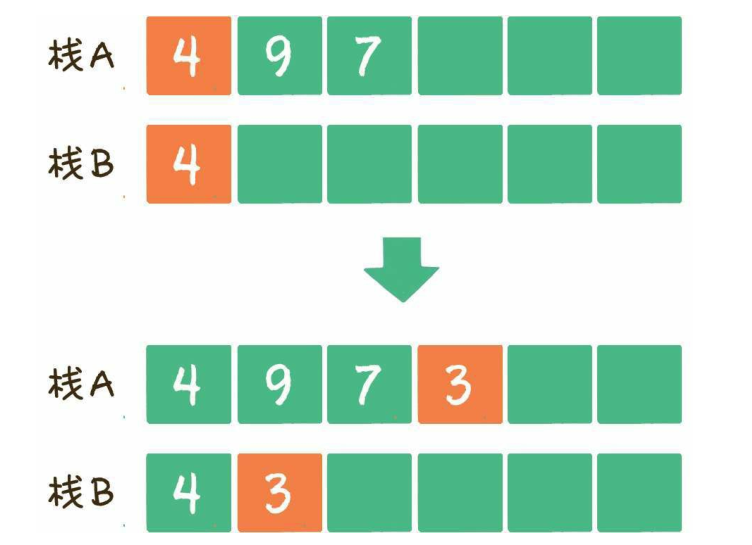











算法图解----袁国忠译
-
二分查找---猜数字,仅限有序
-
240 000个单词,二分查找最多需要18步
-
- 大O表示法
- O(log n),也叫对数时间---二分查找
- O(n),也叫线性时间---简单查找
- O(n * log n),快速排序
- O(n 2 ),选择排序
- O(n!)---旅行商问题
- 旅行商问题
- 有一位旅行商。他需要前往5个城市。同时要确保旅程最短,求可能的路线。
- 如果使用全排列,涉及n个城市时,需要执行n!(n的阶乘)次操作才能计算出结果。因此运行时间为O(n!),即阶乘时间。
- 有一位旅行商。他需要前往5个城市。同时要确保旅程最短,求可能的路线。
- 选择排序
- 内存的工作原理
- 储存柜,标号代表地址
- 数组:连续的
- 链表:不需要连续,当然可以连续
- 选择排序:找出最大,重复并排序,一次需要查找n个,需要执行n次操作,O(n2)
- 内存的工作原理
- 快速排序
- 分而治之
- 找出基线条件,这种条件尽可能简单
- 不断将问题分解(或者说缩小规模),直到符合基线条件
- 快速排序
- 选择基准值
- 将数组分为两个子数组:小于基准和大于基准
- 对这2个子数组进行快速排序
-
def quicksort(array): if len(array) < 2: return array else: pivot = array[0] less = [i for i in array[1:] if i <= pivot] greater = [i for i in array[1:] if i > pivot] return quicksort(less) + [pivot] + quicksort(greater) print(quicksort([10, 5, 2, 3]))
- 散列表---字典
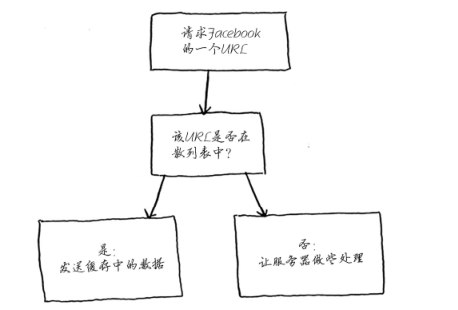
- 所谓缓存就是网址将数据记住,而不再重新计算
- 所谓缓存就是网址将数据记住,而不再重新计算
- 分而治之
- 广度优先搜索
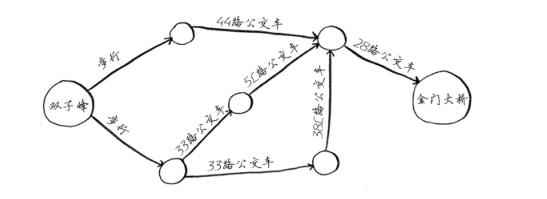
- 旧金山从双子峰到金门大桥
- 旧金山从双子峰到金门大桥
- 看着有点混乱,到此为止了

疯狂python讲义----李刚
自强学堂Django教程---涂伟忠
- 基础
- 一些python基础
- Html,css,js基础
- 口号:DRY(Don't Repeat Yourself)
- 结构
- urls.py
-
⽹址⼊⼝,关联到对应的views.py中的⼀个函数,访问⽹址就对应⼀个函数。
-
-
views.py
-
处理⽤户发出的请求,从urls.py中对应过来, 通过渲染templates中的⽹⻚可以将显示内容,⽐如登陆后的⽤户名,⽤户请求的数据,输出到⽹⻚。
-
- models.py
- 与数据库操作相关,存⼊或读取数据时⽤到这个,当然⽤不到数据库的时候 你可以不使⽤。
- forms.py
-
表单,⽤户在浏览器上输⼊数据提交,对数据的验证⼯作以及输⼊框的⽣成等⼯作。
-
- templates ⽂件夹
-
views.py 中的函数渲染templates中的Html模板,得到动态内容的⽹⻚,当然可以⽤缓存来提⾼速度。
-
- admin.py
- 后台
- settings.py
- Django 的设置,配置⽂件,⽐如 DEBUG 的开关,静态⽂件的位置等。
- urls.py
- 安装
- liunx:sudo apt-get install python-django -y
- windows:pip install Django
Think python(如何像计算机科学家一样思考) -
-
编程是易于出错的。由于比较奇怪的原因,编程的错误被称为虫子(bugs), 并且追踪它们的过程被称为捉虫或调试(debugging)。
-
Syntax errors语法错误:Python只能执行语法正确的程序。否则,解释器显示一个错误信息。语法指的是一个程序的结构以及关于那些结构的规则。 例如,括号必须成对出现等,否则就会报语法错误。
-
Runtime errors运行时错误:第二类错误是运行时错误,之所以这么叫,是因为程序开始运行以后,这些错误才出现这些错误也被称为异常(exceptions)
-
Semantic errors语义错误: 如果你的程序中有一个语义错误,在计算机不会生成错误信息的意义上, 它将成功运行。但是,它不会做正确的事情。
-
当你排除了所有的不可能,无论剩下的是什么, 不管多么难以置信,一定是真相。--夏洛克.福尔摩斯
代码规范
-
不要在行尾加分号, 也不要用分号将两条命令放在同一行
- 每行不超过 80 个字符
- 宁缺毋滥的使用括号
- 用 4 个空格来缩进代码
- 顶级定义之间空两行, 方法定义之间空一行---比如函数或者类定义,为顶级定义
- 按照标准的排版规范来使用标点两边的空格
- 括号内不要有空格.
- 不要在逗号, 分号, 冒号前面加空格, 但应该在它们后面加(除了在行尾).
- 参数列表, 索引或切片的左括号前不应加空格.
- 在二元操作符两边都加上一个空格,算术操作符两边的空格该如何使用, 需要你自己好好判断. 不过两侧务必要保持一致.
- 当’=’用于指示关键字参数或默认参数值时, 不要在其两侧使用空格.
- 不要用空格来垂直对齐多行间的标记, 因为这会成为维护的负担(适用于:, #, =等):
- 确保对模块, 函数, 方法和行内注释使用正确的风格
- 如果一个类不继承自其它类, 就显式的从object继承. 嵌套类也一样
- 即使参数都是字符串, 使用%操作符或者格式化方法格式化字符串. 不过也不能一概而论, 你需要在+和%之间好好判定
- 在文件和sockets结束时, 显式的关闭它
- 每个导入应该独占一行
- 通常每个语句应该独占一行
- 在 Python 中, 对于琐碎又不太重要的访问函数, 你应该直接使用公有变量来取代它们,这样可以避免额外的函数调用开销. 当添加更多功能时, 你可以用属性(property)来保持语法的一致性.
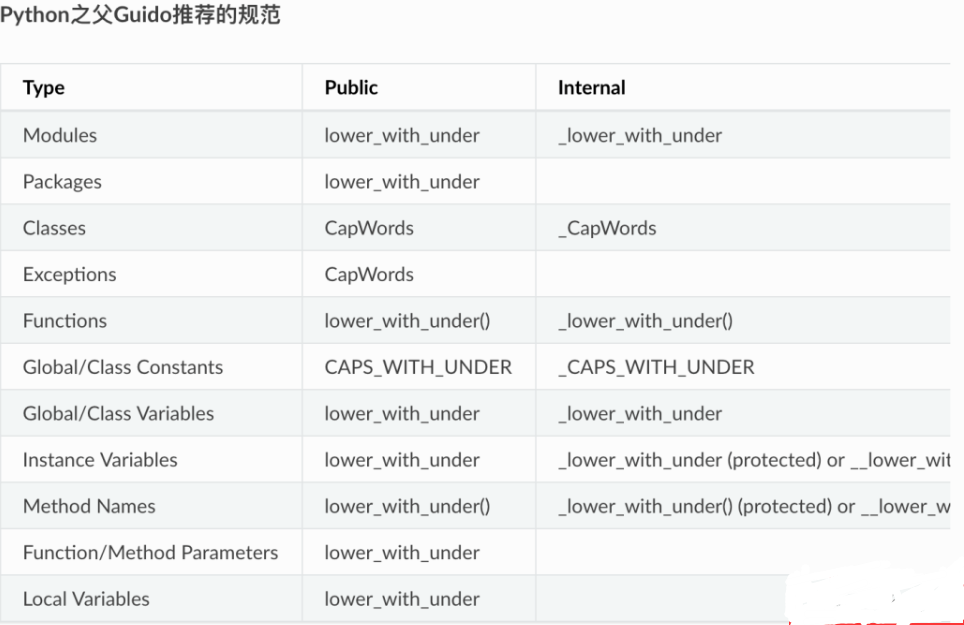
- 命名
- 即使是一个打算被用作脚本的文件, 也应该是可导入的. 并且简单的导入不应该导致这个脚本的主功能(main functionality)被执行, 这是一种副作用. 主功能应该放在一个main()函数中.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号