

集合进阶
双列集合
双列集合的特点:
- D双列集合一次需要存一对数据,分别为键和值
- 键不能重复,值可以重复
- 键和值是一一对应的,每一个键只能找到自己对应的值
- 键+值这个整体我们称之为“键值对”或者“键值对对象”,在Java中叫做"Entry对象"
MAP的常用API
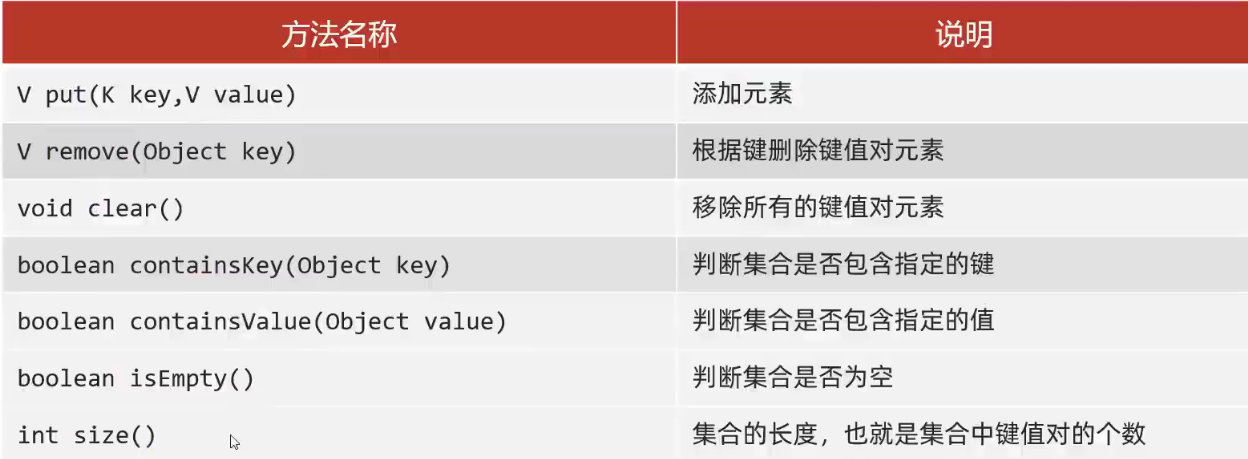
Map<String,String> m = new HashMap<>();
/*put方法的细节:
添加/覆盖
在添加数据的时候,如果键不存在,那么直接把键值对对象添加到map集合当中,方法返回nul1
在添加数据的时候,如果键是存在的,那么会把原有的键值对对象覆盖,会把被覆盖的值进行返回。
*/
m.put("郭靖","黄蓉");
//清空
m.clear();
//判断是否包含
boolean keyResult = m.containsKey("郭靖");
boolean ValueResult = m.containsValue("黄蓉");
boolean result = m.isEmpty();
int size = m.size();
遍历方式
键找值
//3.1获取所有的键,把这些键放到一个单列集合当中
Set<String> keys = map.keySet();
//3.2遍历单列集合,得到每一个键
for (String key : keys) {
//System.out.printIn(key);
//3.3 利用map集合中的键获取对应的值get
String value = map.get(key);
System.out.println(key + "=" + value);
}
通过键值对
//3.1 通过一个方法获取所有的键值对对象,返回一个Set集合
Set<Map.Entry<String, String>> entries = map.entrySet();
//3.2 遍历entries这个集合,去得到里面的每一个键值对对象
for (Map.Entry<String, String> entry : entries){
//3.3 利用entry调用get方法获取键和值
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "=" + value);
}
通过Lambda表达式
map.forEach((key,value)-> System.out.println(key + "=" + value));
HashMap
- HashMap是Map里面的一个实现类
- 没有额外需要学习的特有方法,直接使用Map里面的方法就可以了
- 特点都是由键决定的:无序、不重复、无索
- HashMap跟HashSet底层原理是一模一样的,都是哈希表结构
- .依赖hashCode方法和equals方法保证键的唯一
- 如果键存储的是自定义对象,需要重写hashCode和equals方法如果值存储自定义对象,不需要重写hashCode和equals方法
HashMap<Student,String> hm = new HashMap<>();
//2.创建三个学生对象
Student s1 = new Student( name: "zhangsan", age: 23);
Student s2 = new Student( name: "lisi", age: 24);
Student s3 = new Student( name: "wangwu",age: 25);
//3.添加元素
hm.put(s1,"江苏");hm.put(s2,"浙江");hm.put(s3,"福建");
//4.遍历集合
//第一种
Set<Student> keys = hm.keySet();
for (Student key : keys){
String value = hm.get(key);
System.out.println(key + "=" + value);
}
//第二种
Set<Map.Entry<Student, String>> entries = hm.entrySet();
for (Map.Entry<Student, String> entry : entries) {
student key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "=" + value);
}
//Lambda
hm.forEach((student, s)-> System.out.println(student + "=" + s));
统计:
//如果要统计的东西比较多,不方便使用计数器思想
//我们可以定义map集合,利用集合进行统计。
HashMap<String,Integer> hm = new HashMap<>();
for (String name : list){
//判断当前的景点在map集合当中是否存在
if(hm.containsKey(name)){
//存在
//先获取当前景点已经被投票的次数
int count = hm.get(name);
//表示当前景点又被投了一次
count++;
//把新的次数再次添加到集合当中
hm.put(name,count);
}else{
hm.put(name,1);
}
}
System.out.printIn(hm);
//3.求最大值
int max = 0;
Set<Map.Entry<String, Integer>> entries = hm.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
int count = entry.getValue();
if(count > max){
max = count;
}
}
System.out.println(max);
LinkedHashMap
- 由键决定:有序、不重复、无索引。
- 这里的有序指的是保证存储和取出的元素顺序一致
- 原理:底层数据结构是依然哈希表,只是每个键值对元素又额外的多了一个双链表的机制记录存储的顺序。
LinkedHashMap<String,Integer> lhm = new LinkedHashMap<>();
//2.添加元素
lhm.put("a",123);
lhm.put("a",123);
lhm.put("b",456);
lhm.put("c",789);
//{a=123,b=456, c=789}
TreeMap
- TreeMap跟TreeSet底层原理一样,都是红黑树结构的。
- 由键决定特性:不重复、无索引、可排序
- 可排序:对键进行排序
- 注意:默认按照键的从小到大进行排序,也可以自己规定键的排序规则
- 代码书写两种排序规则:
- 实现Comparable接口,指定比较规则。
- 创建集合时传递Comparator比较器对象,指定比较规则。
//1.创建集合对象
//Integer Double 默认情况下都是按照升序排列的
//string 按照字母再ASCII码表中对应的数字升序进行排列
TreeMap<Integer,String> tm = new TreeMap<><new Comparator<Integer>()
@Override
public int compare(Integer o1, Integer o2) {
//o1:当前要添加的元素//o2: 表示已经在红黑树中存在的元素
return o2 - ol;
//降序
}
//排序:
//如果题目中没有要求对结果进行排序,默认使用HashMap
//如果题目中要求对结果进行排序,请使用TreeMap
String s = "aababcabcdabcde";
TreeMap<Character,Integer> tm = new TreeMap<>();
for (int i = ; i < s.length(); i++){
char c = s.charAt(i);
}
if(tm.containsKey(c)){
int count = tm.get(c);
count++;
tm.put(c,count);else{
tm.put(c,1);
}
}
StringBuilder sb= new StringBuilder();
tm.forEach((key,value)->sb .append(key).append("(").append(value).append(")"));
System.out.println(sb);
HashMap TreeMap源码没看
可变参数
格式:属性类型...名字
int...args
//底层:可变参数底层就是一个数组
/*可变参数的小细节:
1.在方法的形参中最多只能写一个可变参数
2.在方法当中,如果出了可变参数以外,还有其他的形参,那么可变参数要写在最后
*/
Collections
集合工具类
常用API
//批量添加元素
public static <T> boolean addAll(Collection<T> c,elements)
//打乱List集合元素的顺序
public static void shuffle(List<?> list)
//排序
public static <T> void sort(List<T> list)
//根据指定的规则进行排序
public static <T> void sort(List<T> list,Comparator<T> c)
//以二分查找法查找元素
public static <T> int binarySearch (List<T> list, T key)
//拷贝集合中的元素
public static <T> void copy(List<T> dest, List<T> src)
//使用指定的元素填充集合
public static <T> int fill (List<T> list, T obj)
//根据默认的自然排序获取最大/小值
public static <T> void max/min(Collection<T> coll)
//交换集合中指定位置的元素
public static <T> void swap(List<?> list,int i,int j)
//例子:
v ArrayList<String> list = new ArrayList<>();
//2.批量添加元素
Collections.addAll(list, "abc" ,"bcd","qwer","df","asdf","zxcv","1234","qwer");
//3.打乱数据
Collections.shuffle(list);
练习看完整体再回看。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App