
linux-0.11进程启动代码笔记
一、概要
初始化结束后,先开启中断,操作系统从内核态切换到用户态,接下来进程 0(操作系统代码)创建进程 1,老进程进入死循环:
二、move_to_user_mode 函数
Linux 操作系统特权级分为内核态和用户态两种,之前都处于内核态。一旦转变为了用户态,之后的代码会一直处于用户态,除非发生中断,比如用户发出系统调用的中断指令,就会从用户态陷入内核态,当中断处理程序运行完后,通过中断返回指令重新回到用户态。
1.特权级检查
CPU 为了配合操作系统完成保护机制这一特性,分别设计了分段保护机制与分页保护机制。特权级的保护是分段保护机制的一种,当前正在执行的代码地址由 CS:EIP 指向的,CS 寄存器里是段选择子,低两位是 CPL ,也就是当前所处的特权级:

如果想要进行长跳转,低两位表示 RPL,也就是请求特权级。长跳转命令执行后,CPU 拿段选择子去全局描述符表(gdt)中寻找段描述符,从中找到段基址。段描述符结构如下图所示,其中的 DPL 是目标代码特权级,也就是即将跳转的代码的特权级:

综上所述,特权级的检查就是 CPL、RPL 和 DPL 的比较,通常 DPL 要等于 CPL 才能跳转成功。访问内存时也会做检查,处于内核态的代码可以访问所有数据,处于用户态的代码只能访问用户态的数据。总结:代码跳转只能发生在同一特权级的代码段之间,高特权级的代码可以访问低特权级的数据。
2.特权级转换
jmp 指令进行段间跳转只能跳转到同一特权级的代码段,那内核态的代码要如何跳转到用户态呢?中断和中断返回的方式可以做到这点。处于用户态的程序,通过触发中断陷入内核态,通过中断返回重新返回用户态。系统调用就是这样进行的,通过 int 0x80 中断指令进入内核态,CPU 执行完中断处理程序后,返回到用户态。有意思的是,即使没有通过中断进入用户态,也可以返回到用户态。也是通过这种方式,完成了内核态到用户态的切换。
这是一段内联汇编,先进行了五次压栈操作,然后执行中断返回指令 iret。因为中断返回理论上是要和中断指令配合使用的,但是又确实没有发生中断,因此需要假装发生中断,所以进行了五次压栈操作。发生中断时,CPU 会自动完成压栈操作,当执行 iret 指令后,会自动将压入的五个数据依次赋给 ss、esp、eflags、cs、eip 寄存器。
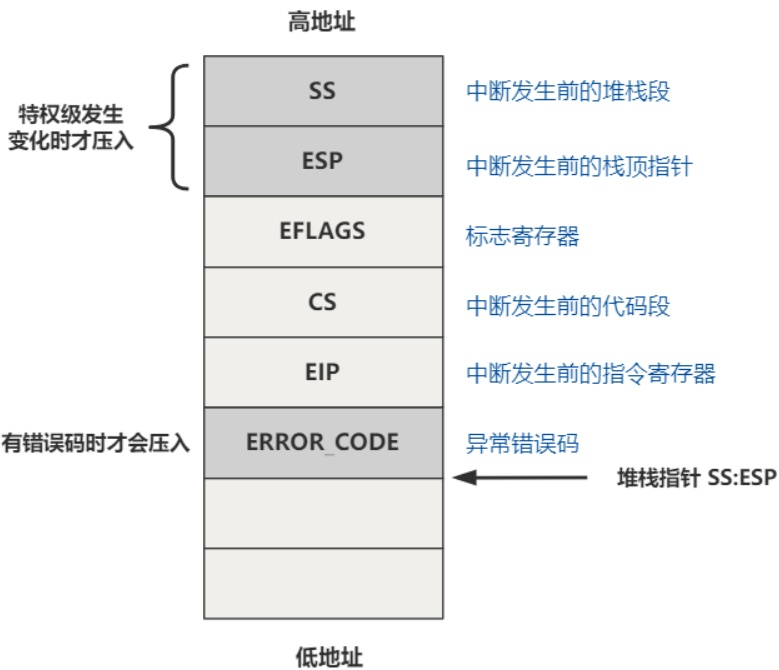
特权级的转换就靠 SS 和 CS 寄存器,这里面存放的是段选择子:

——CS 寄存器:0x0f转换成 1111,低两位表示特权级为用户态,第三位表示前面的描述符索引是从 GDT 还是 LDT 中取出,1 表示 LDT。
——SS 寄存器:0x17转换成 10111,解释同上。
代码注释如下,通过 EIP 寄存器的内容,找到偏移地址为 1 的代码,执行下去:
三、进程调度
创建进程是一个很能体现操作系统设计的地方,在读代码之前先了解一下进程调度规则是很有必要的。进程调度的本质是让各个进程在该运行的时候运行,当进程满足条件时,让 CPU 停下正在执行的进程去执行该执行的进程。
1.整体流程设计
有一个不受任何进程控制的不可抗力,每隔一段时间让 CPU 停下正在执行的指令,跳转到进程调度程序,由这个程序来决定接下来执行的命令的地址,这个不可抗力就是时钟中断。流程确定下来了,接下来就要设计一个数据结构来支持这个流程,这个数据结构就是 task_struct,它被用来记录进程的信息:
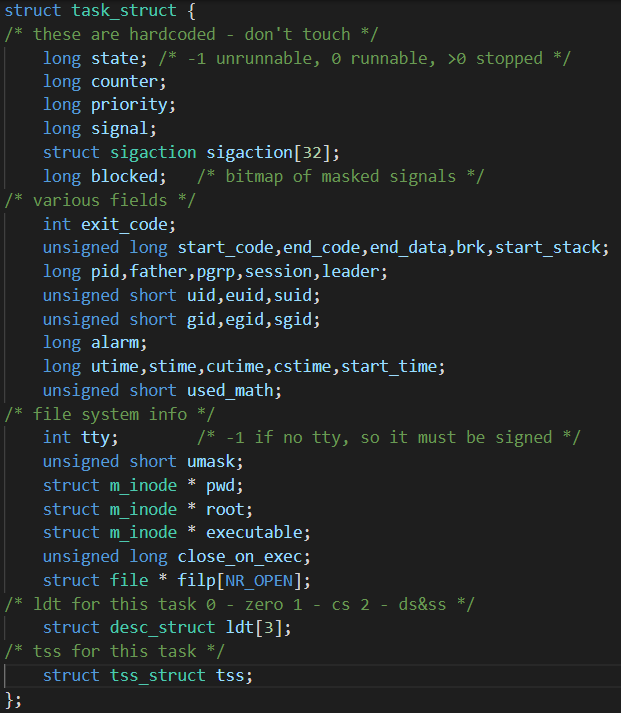
2.上下文环境
进程运行的本质就是执行指令,这个过程会涉及到寄存器、内存,有时也会涉及到外设端口。但是寄存器很少,一个进程可能就把寄存器用完了,其他进程就没有寄存器可用了。于是 task_struct 结构体中就有了一个结构体叫 tss_struct,用来存储这些寄存器的信息:
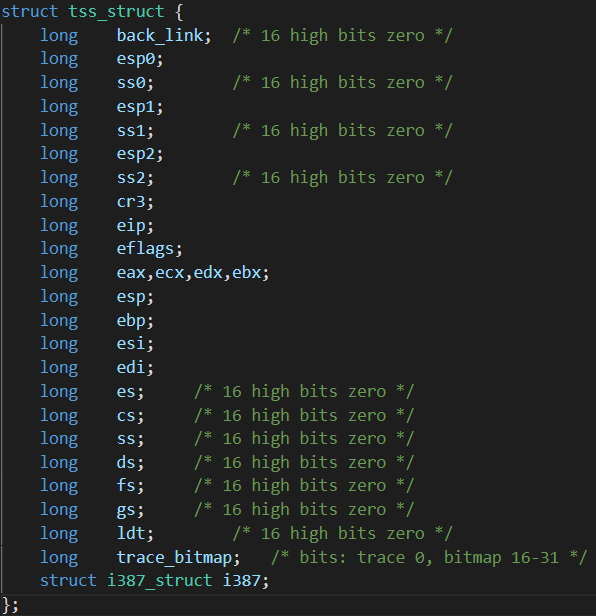
其中有个 cr3 寄存器,该寄存器用来指向页目录表首地址。指向不同的页目录表,其结构可以是完全不同的一套,那么不同进程线性地址到物理地址的映射关系就可以是不同的。专业的说法就是保存了内存映射的上下文信息。
3.时间片与优先级
优先级相同的情况下,如何判断一个进程该让出 CPU 切换到下一个进程呢?操作系统引入了时间片,在 task_struct 结构体中,用 counter 记录时间片这个信息,每次时钟中断到了都减一,如果减到 0 了,就触发切换进程的操作。Linux 下有个实时优先级的概念,实现原理如下:
1.确定每个进程能占用多少 CPU 时间,将优先级按照一定的权重转化为 CPU 时间片。
2.占用 CPU 时间多的先运行。
3.运行完后,扣除运行进程的 CPU 时间。
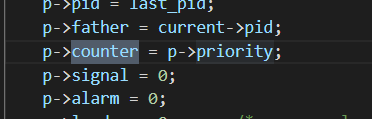
对应到代码,在 copy_process 函数中将优先级的值赋给时间片:
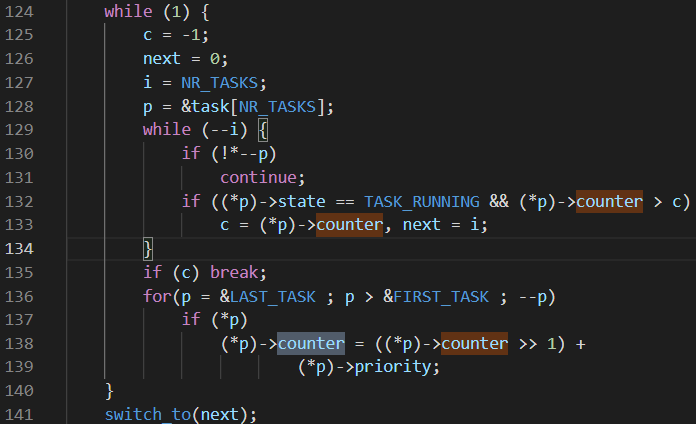
在 schedule 函数中,136 到 139 行按照一定规则计算出时间片,129 到 134 行做比较,选出时间片最大的进程,将进程号赋给 next 变量,通过 switch_to 函数切换。
4.进程状态
假如有以下这种场景:一个进程中,有一个等待接收信号的操作,但是这个信号可能要很久才能收到,此时可以主动选择放弃 CPU 的执行权,把自己的状态标记为等待中:

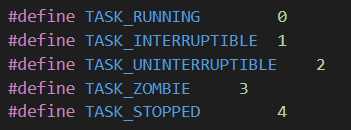
细分下来大于等于 0 的情况有五种:
——TASK_RUNNING:就绪状态,此时程序已被挂入运行状态,一旦取得 CPU 使用权即可进入运行状态。变成运行状态后 state 不变,但是指向当前进程的指针 current 会指向该进程。
——TASK_INTERRUPTIBLE:可中断等待状态,由于进程未获得唤醒所需要的资源,当获取到有效资源或收到唤醒信号后会转换成就绪状态。
——TASK_UNINTERRUPTIBLE:不可中断等待状态,与可中断等待状态不同的是,该状态不能被中断或信号量唤醒,只有获取有效资源时才能被唤醒。
——TASK_ZOMBIE:僵尸状态,进程由于某种原因终止,大部分资源被回收,但 task_struct 结构体还在,此时内核不会管这个进程,只有父进程可以杀死这个进程,或者等待足够长的时间由内核杀死这个进程。但是进程的 PID 资源还被占用着,一旦僵尸进程过多,会对系统性能造成影响。
——TASK_STOPPED:停止状态,收到 SIGSTOP 信号后,由就绪状态进入停止状态;收到 SIGCONT 信号时,又恢复到就绪状态。
四、进程调度过程
上面提到,进程调度依赖的硬件是时钟中断,shed_init 函数中为 0x20 中断设置了一个中断处理函数 timer_interrupt 函数,这个函数调用了 do_timer 函数,通过比较时间片的值和计数值来判断是否需要进行进程切换。
1.do_timer 函数
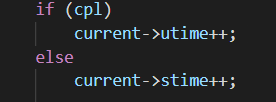
首先通过 timer_interrupt 函数传入的参数 cpl 来判断当前代码运行在何种特权级下,如果特权级为 0 表示内核程序在工作,将内核程序运行时间加一;否则表示在用户程序下工作,将用户程序运行时间加一。
如果有用户定时器存在,将链表第一定时器的值减一,如果等于 0,则将该项定时器去掉,并执行该定时器的处理函数:

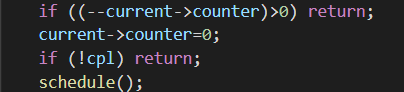
当进程时间走完后,调用 schedule 函数进行进程切换:
2.schedule 函数
正如注释所说,检查定时器的值,唤醒任何已获取信号的可中断任务:
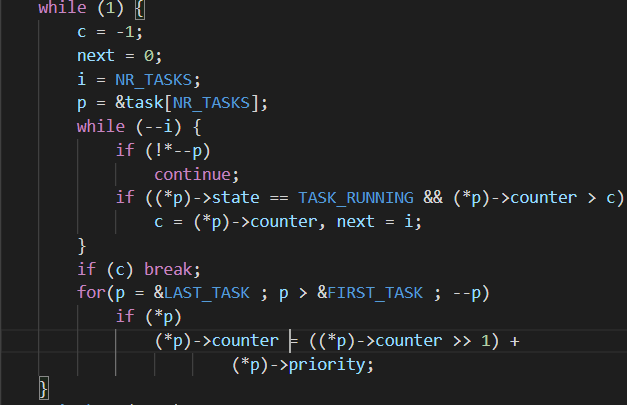
接下来,选择合适的任务号,交由 switch_to 函数进行切换。以下是任务调度函数的主要部分,while 循环用于寻找到任务数组中,时间片最大的任务;如果所有时间片都没有大于 0 的结果,通过下面的 for 循环,按照优先级计算合适的时间片,再次循环。知道找到时间片最大且大于 0 的任务,任务号赋给 next,切换任务:
五、fork 函数
通过 move_to_user_mode 函数,现在已经进入用户态。fork 函数负责创建一个新进程,所有用户进程想要创建一个新进程都要调用这个函数。在这段代码里它创建了进程 1,当前正在运行的是进程 0 ,它的管理结构在进程调度初始化的时候被创建并放入到了 task 数组里。当时钟中断到来之后,进程调度系统会从 task 数组中挑选合适的进程进行切换。
1.系统调用
这个函数是由 _syscall0 实现的:static inline _syscall0(int,fork);这个宏函数的实现如下图所示:
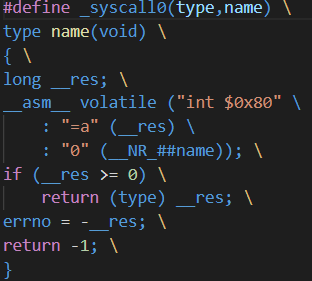
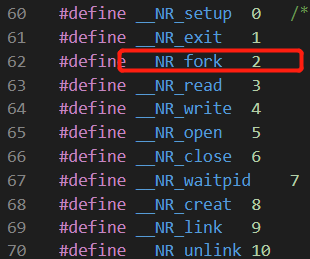
首先触发 0x80 中断号的中断,在 shed_init 函数中为这个中断设置的中断处理函数为 system_call 函数,__res 是函数返回值,## 用于连接两个变量,结果是 __NR_fork ,对应的值是 2,作为这个函数的输入参数:
system_call 函数经过一系列的寄存器值的保存后,调用地址为 sys_call_table + eax * 4 地址处的函数:

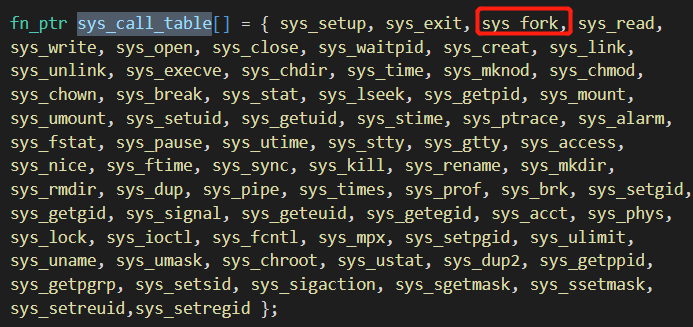
那么究竟是哪个函数呢,看一下系统调用函数表 sys_call_table,找到下标为 2 的函数,就是 sys_fork 了,这就是系统调用的整个过程:
2.进程基本信息的复制
sys_fork 函数调用了两个函数,分别是 _find_empty_process(找空闲的进程) 和 _copy_process(复制进程)。
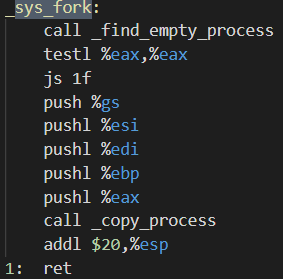
1.find_empty_process函数
2.copy_process
这个函数有一大段是对 tss 结构的复制,重要的代码如下:
3.copy_mem 函数
1.LDT 的赋值
如果开启了分页模式,逻辑地址转化为物理地址需要先经过分段机制转换为线性地址空间,再经过分页机制转换为物理地址。新进程中代码段和数据段的段基址应当存在 LDT 中,因此复制进程要首先对该进程的 LDT 赋值。
2.页表的复制
段表赋值完后,开始页表的复制,页表的复制主要依靠 copy_page_tables 函数实现的,这个函数很复杂,以后再看看吧。已知进程 0 的线性地址空间是 0-64M,进程 1 的线性地址空间是 64M-128M。现在要造一个进程 1 的页表,使得进程 0 和进程 1 最终映射到的物理地址空间都是 0 - 64M。
