


Docker容器网络基础
网络概述
1,Linux的namespace+cgroup
namespace和cgroup是Linux 内核的两大特性,namespace的诞生据说就是为了支持容器技术,那么这俩特性到底干了啥呢?
- namespace:linux支持多种类型的namespace,包括Network,IPC,PID, Mount, UTC, User。创建不同类型的namespace就相当于从不同资源维度在主机上作隔离。
- cgroup:为了不让某个进程一家独大,而其他进程饿死,所以它的作用就是控制各进程分配的CPU,Memory,IO等。
- namespace+cgroup也适用进程组,即多进程运行在一个单独的ns中,此时该ns下的进程就可以交互了。
参考:https://coolshell.cn/articles/17010.html
2,容器
"容器"这个概念其实是Linux本身就具有的,无非就是对一个"隔离环境"的另一种说法,或者说容器就是结合了namespace 和 cgroup 的一般内核进程,注意,容器就是个进程。
容器的实现有多种方式,其中Docker公司实现的docker 容器也是目前最为常用的一种容器技术,所以我们接下来就以docker为例,看看他的实现是怎么帮我们创建,管理这样一个个"互相隔离着的进程"。
所以,当我们使用Docker起一个容器的时候,Docker会为每一个容器创建属于他自己的namespaces,即各个维度资源都专属这个容器了,此时的容器就是一个孤岛,也可以说是一个独立VM就诞生了。当然他不是VM,网上关于二者的区别和优劣有一对资料.
更进一步,也可以将多个容器共享一个namespace,比如如果容器共享的是network 类型的namespace,那么这些容器就可以通过 localhost:[端口号] 来通信了。因为此时的两个容器从网络的角度看,和宿主机上的两个内核进程没啥区别。
在下面的详解部分会有试验来验证这个理论
一个参考:https://blog.jessfraz.com/post/containers-zones-jails-vms/
Docker容器网络详解
从范围上分:
单机网络:none,host, bridge
跨主机网络:overlay,macvlan,flannel等
从生成方式分:
原生网络:即利用宿主机操作系统本身就提供的功能构建的网络,包括:none,host, bridge
自定义网络:
docker容器实现中自带的网络驱动:bridge(自定义),overlay,macvlan,
使用第三方驱动实现的自定义网络:flannel等
在学习网络的时候肯定遇到过关于CNM这个概念,所以首先,我们一起学习下CNM&libnetwork
一. CNM&libnetwork
首先,Docker实现的容器技术中,针对网络这一块他抽象出一个模型来,就叫CNM(Container Networking Model),相当于只实现了一个框架,具体的实现可以使用原生Docker的,也可以自己实现然后接入本框架。其中libnetwork是Docker团队将Docker的网络功能从Docker的核心代码中分离出来形成的一个单独的库,libnetwork通过插件的形式接入CNM为Docker提供网络功能。
该模型包含三部分:
- Sandbox:容器的网络栈,包含interface,路由表,DNS设置等,可以看做就是linux network类型的namespace本身,该有的网络方面的东西都要有,另外还包含一些用于连接各种网络的endpoint
- Endpoint : 用来将sandbox接入到network中。典型的实现是Veth pair技术(Veth pair是Linux固有的,是一个成对的接口,用来做连接用)
- Network (框架): 具体的网络实现,比如是brige,VLAN等,同样它包含了很多endpoint(那一头)
一句话:sandbox代表容器,network代表由网络驱动构建的容器的网络,endpoint代表接入点即他连接了二者
CMN模型提供了2个可插拔的接口,让用户可以自己实现驱动然后接入该接口,支持驱动有两类:网络驱动和IPAM驱动,看看这俩类驱动干什么的?
-
Network Drivers: 即真正的网络实现,可以为Docker Engine或其他类型的集群网络同时提供多种驱动,但是每一个具体的网络只能实例化一个网络驱动。细分为本地网络驱动和远端网络驱动:
- 本地网络驱动:对应前面说到的原生网络
- 远端网络驱动:对应前面说的自定义网络
- IPAM Drivers — 构建docker网络的时候,每个docker容器如果不手动指定的话是会被分配ip地址的,这个分配的任务就是由该驱动完成的,同样的,Docker Engine还是给我们提供了缺省的实现。
整个的原理模型图如下,参见官网:

参考:https://success.docker.com/article/networking
(一定要好好看看这篇文章,我英文不行看了整整2天,很有收获)
好了,收,开始真正进入docker网络的学习,我们挑2个代表性的网络一起研究下
二. 单机网络---brige类型的网络
原理如下图(摘自https://success.docker.com/article/networking):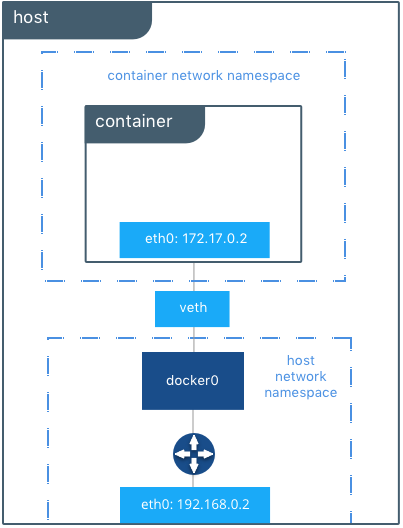
接下来听我慢慢道来,我们先按照步骤走一遍,然后再细抠里面的原理
1. 从实践开始
在主机上起两个docker容器,使用缺省网络即bridge网络,容器要使用有操作系统的镜像,要不不方便验证
1)进入任一个容器内
sh-4.2# ip addr
13: eth0@if14: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
inet 172.17.0.3/16 scope global eth0
附:容器中可能缺少诸多命令,可以在启动后安装如下工具:
yum install net-tools
yum install iputils
yum install iproute *
2)在宿主机上查看接口信息:
[root@centos network-scripts]# ip addr
4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
inet 172.17.0.1/16 scope global docker0
14: vetha470484@if13: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
16: veth25dfcae@if15: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
3) 在host上查看docker缺省会创建的三个网络
[root@centos ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
451a2ff68c71 bridge bridge local
7bd661f0c17f host host local
6c9bb2d42d95 none null local
4)再看下支撑网络背后的驱动,即这个叫“bridge”的bridge类型网络使用的驱动:一个名叫docker0的bridge(网桥)。网桥上挂两个interface:veth25dfcae, vetha470484
[root@centos network-scripts]# brctl show bridge name bridge id STP enabled interfaces docker0 8000.0242dee689ea no veth25dfcae #宿主机上16号接口,@if15,即和容器中15号端口是一对veth pair vetha470484 #宿主机上14号接口,@if13,即和容器中13号端口是一对veth pair
附:可能缺少命令,可以在启动后安装如下工具:
# yum install bridge-utils
#ln -s /var/run/docker/netns/ /var/run/netns ---用来在host上查看所有的namespace,缺省情况下ip netns show显示的是/var/run/netns中的内容,但是Docker启动后会清除
容器中也可能缺少命令,使用如下方式将宿主机上的命令拷贝到容器中
[root@node231 ~]# docker cp /usr/bin/netstat c121e2854008:/usr/bin/ [root@node231 ~]# docker cp /usr/sbin/ifconfig c121e2854008:/usr/sbin/ [root@node231 ~]# docker cp /usr/sbin/ip c121e2854008:/usr/sbin/
2. 解析Docker都做了什么
看容器(Sandbox), 接口的number是13的那个,他名字是eth0, 然后他@if14,这个就是endpoint,那么这个if14是谁?
看主机,有个网桥叫做docker0,有两个interface 他们的master是docker0,并且这两个interface的number分别是14,16,并且分别@if13和@if15,是的,if13正是容器中的接口,同理if14也是另一个容器中的接口,也就是说在host上的veth接口(NO.14)和容器中的eth接口(NO.13)正是一对veth pair,至此Endpoint作为容器和nework的连接的任务达成了。而docker0正是名叫bridge的Network的驱动。
最后,看一下路由吧
容器1:

sh-4.2# ip route default via 172.17.0.1 dev eth0 172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.3
# route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 172.17.0.1 0.0.0.0 UG 0 0 0 eth0
172.17.0.0 * 255.255.0.0 U 0 0 0 eth0
表示:目的是172.17的是一条直连路由,直接从eth0出去交给网关172.17.0.1(也就是docker0)
宿主机:
[root@centos ~]# ip route default via 192.168.12.2 dev ens33 proto dhcp metric 100 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 192.168.12.0/24 dev ens33 proto kernel scope link src 192.168.12.132 metric 100
# route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default gateway 0.0.0.0 UG 0 0 0 eth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
表示:目的是172.17的流量从docker0出去,
缺省的交给ens33接口给网关192.168.12.2(因为我的宿主机是个虚拟机,所以还是个小网ip),也就是说如果访问的是同网段(如加入同一网络的其他容器)则交给网桥docker0内部转发,否则走向世界
另外:详细的可以 看一下bridge网络,可以网络中有两个容器,ip,mac都有


[root@centos ~]# docker network inspect bridge
{
"Name": "bridge",
"Driver": "bridge",
"IPAM": { //负责给容器分配ip地址
"Config": [
{
"Subnet": "172.17.0.0/16",
"Gateway": "172.17.0.1"
}
]
},
"Containers": {
"9161f717c07ac32f96b1ede19d21a56a63f17fb69a63627f66704f5cec01ca27": {
"Name": "server.1.oeep0sn0121wrvrw3aunmf9ww",
"EndpointID": "5083992493b0a69fedb2adc02fe9c0aa61e59b068e16dd9371ec27e28d7d088c",
"MacAddress": "02:42:ac:11:00:02",
"IPv4Address": "172.17.0.2/16",""
},
"fb67b65aa43619779d0d4f9d2005815aea90586f0aba295436431f688239562b": {
"Name": "fervent_ritchie",
"EndpointID": "e402fa0f99f60199c8ba50263173ef3bc14ca75dbb597d2cbcd813dd4f8706f7",
"MacAddress": "02:42:ac:11:00:03",
"IPv4Address": "172.17.0.3/16",
}
},
插播:bridge的原理
在容器技术中,bridge扮演了一个非常重要的角色,懂得bridge的原理可以很好的定位网络问题,这里就不展开讨论,在我的[爬坑]系列有讲述,你只需要记住:不要把bridge想复杂,bridge是一个桥作为master,可以往桥上挂很多类型及个数的interface接口,当桥上有一个接口接收到数据后,只要不是给桥所在的宿主机本身,则桥会内部转发,数据会从其余接口同步冒出来
3. 网络转发原理总结
1)容器连接另一个容器
sh-4.2# ping 172.17.0.2 -c 2 PING 172.17.0.2 (172.17.0.2) 56(84) bytes of data. 64 bytes from 172.17.0.2: icmp_seq=1 ttl=64 time=95.9 ms
此时在网桥docker0上抓包得到如下:
# tcpdump -i docker0 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on docker0, link-type EN10MB (Ethernet), capture size 262144 bytes
08:41:52.493601 ARP, Request who-has 172.17.0.2 tell 172.17.0.3, length 28
08:41:52.493643 ARP, Reply 172.17.0.2 is-at 02:42:ac:11:00:02 (oui Unknown), length 28
08:41:52.493651 IP 172.17.0.3 > 172.17.0.2: ICMP echo request, id 1792, seq 0, length 64
08:41:52.493712 IP 172.17.0.2 > 172.17.0.3: ICMP echo reply, id 1792, seq 0, length 64
【小小结】
当在容器1中访问同宿主机上的另一个容器2,比如目标地址是172.17.0.2时
首先,容器内会查路由表,匹配第二条路由规则(172.17.0.0 * 255.255.0.0 U 0 0 0 eth0), 表示要从eth0网卡通过二层网络出去
但是,对于二层转发, 首先需要知晓目标地址的mac地址, 于是通过eth0广播arp
在veth pair原理中, 一端的arp报文会立刻出现在其对应的位于网桥上的另一端, 而
在网桥的原理中, 网桥会决定数据的转发, 其中对于arp广播报文, 他会广播给"插"在网桥上的所有"从设备"
于是, 容器2会回复arp给docker0, 紧接着arp应答被回给了容器1
然后,容器1就可以顺利封装二层报文并根据路由将报文发给docker0
最后, docker0将报文转发给真正的目的地址:容器2
2) 宿主机上连接容器
[root@host231 ~]# ping 172.17.0.2 -c 3 PING 172.17.0.2 (172.17.0.2) 56(84) bytes of data. 64 bytes from 172.17.0.2: icmp_seq=1 ttl=64 time=0.113 ms 64 bytes from 172.17.0.2: icmp_seq=2 ttl=64 time=0.086 ms
# tcpdump -i docker009:04:51.162143 IP host231 > 172.17.0.2: ICMP echo request, id 26537, seq 1, length 64 09:04:51.162193 ARP, Request who-has host231 tell 172.17.0.2, length 28 09:04:51.162210 ARP, Reply host231 is-at 02:42:0a:2c:0f:37 (oui Unknown), length 28 09:04:51.162215 IP 172.17.0.2 > host231: ICMP echo reply, id 26537, seq 1, length 64 09:04:52.161436 IP host231 > 172.17.0.2: ICMP echo request, id 26537, seq 2, length 64
【小小结】
当在宿主机上访问一个容器的ip,比如目标地址是172.17.0.2时
首先, 宿主机会查路由表,匹配路由规则:172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0), 表示要交给docker0
于是, 和上面的例子类似, 通过广播arp, 得到的正是目标容器的mac地址
之后, 就是正常的报文交互了
3) 容器连接外网
sh-4.2# ping www.baidu.com PING www.a.shifen.com (115.239.210.27) 56(84) bytes of data. 64 bytes from 115.239.210.27 (115.239.210.27): icmp_seq=1 ttl=127 time=5.38 ms
注:这里面要说明一下,从容器发外网的egress流量之所以能顺利得到应答,是因为它在出去的时候经过了iptables的NAT表,就是这里:
# iptables -t nat -L ... Chain POSTROUTING (policy ACCEPT) target prot opt source destination MASQUERADE all -- 172.17.0.0/16 anywhere MASQUERADE all -- 172.18.0.0/16 anywhere
这里如果对iptables的原理不是很清楚的,推荐这位大牛的博客:
http://www.zsythink.net/archives/1199/
4) 容器主动与外部建立tcp长连接
场景描述: 宿主机1(.82)上启动一个服务(假设名叫xserver),监听在23002端口上,
宿主机2(.231)上启动一个容器, 容器内起一个进程,与server建立了T2连接,此时情形如下:
1) 宿主机.82上,有tcp连接建立,与我建立连接的是宿主机2,端口号是宿主机2上的容器内的端口号
[root@tmp-82 ~]# netstat -auntp|grep 23002|grep 231 tcp 0 0 192.168.48.82:23002 192.168.48.231:60542 ESTABLISHED 86812/xserver
2)宿主机.231上的容器
[root@node231 ~]# docker exec -ti c121e2854008 /bin/sh sh-4.2# netstat -auntp|grep 60542 tcp 0 0 172.17.0.3:60542 192.168.48.82:23002 ESTABLISHED 152/gseeproxy sh-4.2# sh-4.2# ifconfig eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 172.17.0.3 netmask 255.255.0.0 broadcast 0.0.0.0 inet6 fe80::42:acff:fe11:3 prefixlen 64 scopeid 0x20<link>
sh-4.2# ip addr|grep eth0
104: eth0@if105: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP #和容器外的105号,即veth991ff8b是一对veth pair
inet 172.17.0.3/16 scope global eth0
3)宿主机.231
[root@node231 ~]# netstat -auntp|grep 60542 [root@node231 ~]# brctl show bridge name bridge id STP enabled interfaces cni0 8000.6692e7267260 no veth76a2a7a0 vetha79be695 vethac577f79 docker0 8000.02424ae76323 no veth991ff8b [root@node231 ~]# [root@node231 ~]# ifconfig cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450 inet 10.244.0.1 netmask 255.255.255.0 broadcast 0.0.0.0 inet6 fe80::6492:e7ff:fe26:7260 prefixlen 64 scopeid 0x20<link> ... docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 172.17.0.1 netmask 255.255.0.0 broadcast 0.0.0.0 inet6 fe80::42:4aff:fee7:6323 prefixlen 64 scopeid 0x20<link> ether 02:42:4a:e7:63:23 txqueuelen 0 (Ethernet) ... eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.48.231 netmask 255.255.255.0 broadcast 192.168.48.255 inet6 fe80::2a6e:d4ff:fe88:c83f prefixlen 64 scopeid 0x20<link> ether 28:6e:d4:88:c8:3f txqueuelen 1000 (Ethernet) ... veth991ff8b: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 ether 7a:c0:23:0d:0d:84 txqueuelen 0 (Ethernet) RX packets 8977 bytes 627125 (612.4 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 9680 bytes 541290 (528.6 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ...
[root@node231 ~]# ip addr |grep veth991ff8b #和容器内的104号,即veth991ff8b是一对veth pair
105: veth991ff8b@if104: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP
结果: 在宿主机1(.82)的xserver进程中, 访问容器失败,原因是
【验证4】容器提供服务,被动接收外部请求
如果想要被外网可以访问的到,需要在起容器的时候指定--publish/-p,即在host上找一个port与容器映射,这个host将代表容器对外打交道,这里就不展开了,网上资料很多,上面贴出的链接中也有讲解。
三. 单机网络---overlay类型的网络
上一个章节我们没有细说容器和linux的namespace之间的关系,因为在overlay类型的网络中,大量使用了linux的namespace技术,所以我们再展开讲。
overlay这个词不是docker家的,一直以来就有overlay类型的网络,意/译为"覆盖"型网络,其中VxLan技术就可以认为是一种overlay类型网络的实现,而在docker的overlay网络,使用的正是Vxlan技术。所以我们再跑偏一下,讲讲VxLAN
https://www.cnblogs.com/shuiguizi/p/10923841.html
水鬼子:简言之,可以暂时这么理解,宿主机上有一个叫做VTEP的组件。它的ip就是宿主机的ip,负责和其他宿主机连通形成隧道。这样宿主机上的VM就可以利用该隧道和其他host上的VM沟通了,然后还并不感知该隧道的存在。也许这么说并不严谨,但是有助于对overlay网络的理解。
另外,为了学习vxlan网络以及容器对vxlan网络的应用,我做了大量的实验,遇到了很多很多的坑,需要的可以参考:.[爬坑系列]之VXLan网络实现
oK,再“收”,回到docker 网络
前情提要:
我们也可以直接使用docker 提供的overlay驱动创建overlay网络,然后创建容器加入到该网络,但如果是Docker Engine 1.12之前,还需要一个k-v类型的存储介质。Docker Engine 1.12之后的由于集成了一个叫做“网络控制平面(control plane)”的功能,则不需要额外的存储介质了。在这里为了更好的理解,我们选择前者,大致的步骤如下:
【操作】:
1,安装启动etcd,安装方法
2,在一个host上创建overlay类型的网络,并创建容器使用该网络
3,在另一个容器上也可以看到该网络,然后也加入这个网络
root@master ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
731d1b63b387 ov_net2 overlay global
分别在两个节点上创建两个docker 容器
master:
docker run -ti -d --network=ov_net2 --name=centos21 centos:wxy /bin/sh
minion:
docker run -d --name nginx --network=ov_net2 nginx22
注:更详细的步骤网上很多,另外想要看我自己搭建的过程中遇到的坑等,请参见【爬坑系列】之docker的overlay网络配置
这里我只想展示overlay网络的深层实现,包括和namespace,vxlan的关系等
【解析】:
1)看一下namespace以及配置
ln -s /var/run/docker/netns/ /var/run/netns
//一个容器创建完了,就多了两个namespace
[root@master ~]# ip netns
a740da7c2043 (id: 9)
1-731d1b63b3 (id: 8)
第一个namespace:其实就是docker容器本身,它有两个接口,都是veth pair类型,对应的兄弟接口分别位于另一个namespace和系统namespace

root@master ~]# ip netns exec a740da7c2043 ip addr
44: eth0@if45: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether 02:42:0a:00:01:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.1.2/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:aff:fe00:102/64 scope link
valid_lft forever preferred_lft forever
46: eth1@if47: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:12:00:04 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet 172.18.0.4/16 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::42:acff:fe12:4/64 scope link
valid_lft forever preferred_lft forever
第二个namespace:他的作用是专门用来做vxlan转发的,核心是一个bro桥,桥上有两个接口,一个与容器(第一个ns )相连,另一个vxlan1接口充当 vxlan网络的vtep
[root@master ~]# ip netns exec 1-731d1b63b3 ip addr
2: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether 12:54:57:62:92:74 brd ff:ff:ff:ff:ff:ff
inet 10.0.1.1/24 scope global br0
valid_lft forever preferred_lft forever
inet6 fe80::842a:a1ff:fec8:da3b/64 scope link
valid_lft forever preferred_lft forever
43: vxlan1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master br0 state UNKNOWN group default
link/ether 12:54:57:62:92:74 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::1054:57ff:fe62:9274/64 scope link
valid_lft forever preferred_lft forever
45: veth2@if44: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master br0 state UP group default
link/ether ae:a1:58:8c:c2:0a brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::aca1:58ff:fe8c:c20a/64 scope link
valid_lft forever preferred_lft forever
结论:docker的overlay网络 = 2namespace + vxlan

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步