数据的存储--MongoDB
MongoDB的安装
教程:https://www.bilibili.com/video/av31240330?from=search&seid=2653908327394008284
https://germey.gitbooks.io/python3webspider/content/1.4.3-Redis%E7%9A%84%E5%AE%89%E8%A3%85.html
https://www.cnblogs.com/whowhere/p/9635956.html
https://blog.csdn.net/qq_20084101/article/details/82261195
以及RoboMongo安装过程https://www.cnblogs.com/zhaord/p/4229001.html
安装教程:
1、按照一般软件安装过程安装即可;
此处:会出现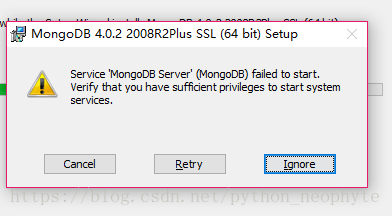 的问题,直接忽略即可。
的问题,直接忽略即可。
2、安装完成后,软件的配置:
在bin目录下,按住shift,右击,即可出现在此处打开powershell窗口,点击即可。
按照崔庆才老师的视频和文章一步一步安装即可,注意在写
命令的时候:稍微修改:
比如.\mongod -dbpath D:\MongDB\data\db,mongod前面需要加.\。
MongoDB的介绍
一、什么是MongoDB ?
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。
在高负载的情况下,添加更多的节点,可以保证服务器性能。
MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。
MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
二、MongoDB 优缺点
优点
文档结构的存储方式,能够更便捷的获取数据
内置GridFS,支持大容量的存储
海量数据下,性能优越
动态查询
全索引支持,扩展到内部对象和内嵌数组
查询记录分析
快速,就地更新
高效存储二进制大对象 (比如照片和视频)
复制(复制集)和支持自动故障恢复
内置 Auto- Sharding 自动分片支持云级扩展性,分片简单
MapReduce 支持复杂聚合
商业支持,培训和咨询
缺点
不支持事务操作
MongoDB 占用空间过大 (不过这个确定对于目前快速下跌的硬盘价格来说,也不算什么缺点了)
MongoDB没有如MySQL那样成熟的维护工具
无法进行关联表查询,不适用于关系多的数据
复杂聚合操作通过mapreduce创建,速度慢
模式自由,自由灵活的文件存储格式带来的数据错
MongoDB 在你删除记录后不会在文件系统回收空间。除非你删掉数据库。但是空间没有被浪费
三、优缺点详细解释
1.内置GridFS,支持大容量的存储:
GridFS是一个出色的分布式文件系统,可以支持海量的数据存储。
内置了GridFS了MongoDB,能够满足对大数据集的快速范围查询。
2.内置 Auto- Sharding 自动分片支持云级扩展性,分片简单
提供基于Range的Auto Sharding机制:
一个collection可按照记录的范围,分成若干个段,切分到不同的Shard上。
Shards可以和复制结合,配合Replica sets能够实现Sharding+fail-over,不同的Shard之间可以负载均衡。
查询是对客户端是透明的。客户端执行查询,统计,MapReduce等操作,这些会被MongoDB自动路由到后端的数据节点。
这让我们关注于自己的业务,适当的 时候可以无痛的升级。MongoDB的Sharding设计能力最大可支持约20 petabytes,足以支撑一般应用。
这可以保证MongoDB运行在便宜的PC服务器集群上。PC集群扩充起来非常方便并且成本很低,避免了“sharding”操作的复杂性和成本。
3.海量数据下,性能优越:
在使用场合下,千万级别的文档对象,近10G的数据,对有索引的ID的查询不会比mysql慢,而对非索引字段的查询,则是全面胜出。 mysql实际无法胜任大数据量下任意字段的查询,而mongodb的查询性能实在让我惊讶。写入性能同样很令人满意,同样写入百万级别的数 据,mongodb比我以前试用过的couchdb要快得多,基本10分钟以下可以解决。补上一句,观察过程中mongodb都远算不上是CPU杀手。
4.全索引支持,扩展到内部对象和内嵌数组
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。
5.MapReduce 支持复杂聚合
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。
与关系型数据库相比,MongoDB的缺点:
mongodb不支持事务操作:
所以事务要求严格的系统(如果银行系统)肯定不能用它。
mongodb不支持事务操作:
所以事务要求严格的系统(如果银行系统)肯定不能用它。
mongodb占用空间过大:
关于其原因,在官方的FAQ中,提到有如下几个方面:
1、空间的预分配:为避免形成过多的硬盘碎片,mongodb每次空间不足时都会申请生成一大块的硬盘空间,而且申请的量从64M、128M、256M那 样的指数递增,直到2G为单个文件的最大体积。随着数据量的增加,你可以在其数据目录里看到这些整块生成容量不断递增的文件。
2、字段名所占用的空间:为了保持每个记录内的结构信息用于查询,mongodb需要把每个字段的key-value都以BSON的形式存储,如果 value域相对于key域并不大,比如存放数值型的数据,则数据的overhead是最大的。一种减少空间占用的方法是把字段名尽量取短一些,这样占用 空间就小了,但这就要求在易读性与空间占用上作为权衡了。
3、删除记录不释放空间:这很容易理解,为避免记录删除后的数据的大规模挪动,原记录空间不删除,只标记“已删除”即可,以后还可以重复利用。
4、可以定期运行db.repairDatabase()来整理记录,但这个过程会比较缓慢
MongoDB没有如MySQL那样成熟的维护工具,这对于开发和IT运营都是个值得注意的地方。
MongoDB的使用
来源参考:https://germey.gitbooks.io/python3webspider/content/5.3.1-MongoDB%E5%AD%98%E5%82%A8.html
连接MongoDB
连接 MongoDB 我们需要使用 PyMongo 库里面的 MongoClient,一般来说传入 MongoDB 的 IP 及端口即可,第一个参数为地址 host,第二个参数为端口 port,端口如果不传默认是 27017。
import pymongo client=pymongo.MongoClient(host='localhost',port=27017)
通过上面的代码即可完成mongo对象的创建,此外MongoClient的第一个参数host还可以直接传MongoDB的链接字符串,mongodb 开头,代码如下:
client=MongoClient('mongodb://localhost:27017')
指定数据库
MongoDB 中还分为一个个数据库,我们接下来的一步就是指定要操作哪个数据库,在这里我以 test 数据库为例进行说明,所以下一步我们需要在程序中指定要使用的数据库。调用 client 的 test 属性即可返回 test 数据库,
db=client.test
等价于
db=client['test']
指定集合
MongoDB 的每个数据库又包含了许多集合 Collection,与关系型数据库中的表类似,下一步我们需要指定要操作的集合,在这里我们指定一个集合名称为 students,学生集合,还是和指定数据库类似,指定集合也有两种方式:
collection=db.students
等价于
collection=db['students']
这样我们便声明了一个 Collection 对象
插入数据
接下来我们便可以进行数据插入了,对于 students 这个集合Collection,我们新建一条学生数据,以字典的形式表示:
student={ 'id':'20190101', 'name':'Tom', 'age':20, 'gender':'male' }
调用 collection 的 insert() 方法即可插入数据,代码如下:
import pymongo client=pymongo.MongoClient(host='localhost',port=27017) db=client['test'] collection=db.students student={ 'id':'20190101', 'name':'Tom', 'age':20, 'gender':'male' } result=collection.insert_one(student)#注意在python3中不支持insert,而是支持insert_one,或者insert_many print(result) print(result.inserted_id)
结果:
<pymongo.results.InsertOneResult object at 0x000001D50DDA4488>
5cebdea920a9a9f93c37de4a
也可以同时插入多条数据,
import pymongo client=pymongo.MongoClient(host='localhost',port=27017) db=client['test'] collection=db.students student1={ 'id':'20190101', 'name':'Tom', 'age':20, 'gender':'male' } student2={ 'id':'20190102', 'name':'JACK', 'age':20, 'gender':'male' } result=collection.insert_many([student1,student2])#注意在python3中不支持insert,而是支持insert_one,或者insert_many print(result) print(result.inserted_ids)
结果是
<pymongo.results.InsertManyResult object at 0x000001A04771F848> [ObjectId('5cebe026b7c61f3ffe883afc'), ObjectId('5cebe026b7c61f3ffe883afd')]
查询
插入数据后我们可以利用 find_one() 或 find() 方法进行查询,find_one() 查询得到是单个结果,find() 则返回一个生成器对象。
import pymongo client=pymongo.MongoClient(host='localhost',port=27017) db=client['test'] collection=db.students result=collection.find_one({'name':'Tom'}) print(result) print(type(result))
结果是
{'_id': ObjectId('5cebdddded5ac7d2e55b22ac'), 'id': '20190101', 'name': 'Tom', 'age': 20, 'gender': 'male'}
<class 'dict'>
可以发现它多了一个 _id 属性,这就是 MongoDB 在插入的过程中自动添加的。我们也可以直接根据 ObjectId 来查询,这里需要使用 bson 库里面的 ObjectId。
import pymongo from bson.objectid import ObjectId client=pymongo.MongoClient(host='localhost',port=27017) db=client['test'] collection=db.students result=collection.find_one({'_id':ObjectId('5cebdddded5ac7d2e55b22ac')}) print(result) print(type(result))
结果完全一样
{'_id': ObjectId('5cebdddded5ac7d2e55b22ac'), 'id': '20190101', 'name': 'Tom', 'age': 20, 'gender': 'male'}
<class 'dict'>
对于多条数据的查询,我们可以使用 find() 方法,例如在这里查找年龄为 20 的数据,示例如下:
import pymongo client=pymongo.MongoClient(host='localhost',port=27017) db=client['test'] collection=db.students results=collection.find({'age': 20}) print(results) for result in results: print(result)
结果是
返回结果是 Cursor 类型,相当于一个生成器,我们需要遍历取到所有的结果,每一个结果都是字典类型。
<pymongo.cursor.Cursor object at 0x000001C6ACA65AC8> {'_id': ObjectId('5cebdddded5ac7d2e55b22ac'), 'id': '20190101', 'name': 'Tom', 'age': 20, 'gender': 'male'} {'_id': ObjectId('5cebddeef3518b3b23e7ddbd'), 'id': '20190101', 'name': 'Tom', 'age': 20, 'gender': 'male'} {'_id': ObjectId('5cebde9b81244c5461351451'), 'id': '20190101', 'name': 'Tom', 'age': 20, 'gender': 'male'} {'_id': ObjectId('5cebdea920a9a9f93c37de4a'), 'id': '20190101', 'name': 'Tom', 'age': 20, 'gender': 'male'} {'_id': ObjectId('5cebdff23d62e91174af2025'), 'id': '20190101', 'name': 'Tom', 'age': 20, 'gender': 'male'} {'_id': ObjectId('5cebdff23d62e91174af2026'), 'id': '20190102', 'name': 'JACK', 'age': 20, 'gender': 'male'} {'_id': ObjectId('5cebe002fecf127f22fc1e50'), 'id': '20190101', 'name': 'Tom', 'age': 20, 'gender': 'male'} {'_id': ObjectId('5cebe002fecf127f22fc1e51'), 'id': '20190102', 'name': 'JACK', 'age': 20, 'gender': 'male'} {'_id': ObjectId('5cebe026b7c61f3ffe883afc'), 'id': '20190101', 'name': 'Tom', 'age': 20, 'gender': 'male'} {'_id': ObjectId('5cebe026b7c61f3ffe883afd'), 'id': '20190102', 'name': 'JACK', 'age': 20, 'gender': 'male'}
有点疑惑,为何结果是6个?
如果要查询年龄大于 20 的数据,则写法如下:
results=collection.find({'age':{'$gt':20}})
在这里查询的条件键值已经不是单纯的数字了,而是一个字典,其键名为比较符号 $gt,意思是大于,键值为 20,这样便可以查询出所有年龄大于 20 的数据。
在这里将比较符号归纳如下表:
| 符号 | 含义 | 示例 |
|---|---|---|
| $lt | 小于 | {'age': {'$lt': 20}} |
| $gt | 大于 | {'age': {'$gt': 20}} |
| $lte | 小于等于 | {'age': {'$lte': 20}} |
| $gte | 大于等于 | {'age': {'$gte': 20}} |
| $ne | 不等于 | {'age': {'$ne': 20}} |
| $in | 在范围内 | {'age': {'$in': [20, 23]}} |
| $nin | 不在范围内 | {'age': {'$nin': [20, 23]}} |
另外还可以进行正则匹配查询,例如查询名字以 M 开头的学生数据,示例如下:
results=collection.find({'name':{'$regex':'^M.*'}})
在这里使用了 $regex 来指定正则匹配,^M.* 代表以 M 开头的正则表达式,这样就可以查询所有符合该正则的结果。
在这里将一些功能符号再归类如下:
| 符号 | 含义 | 示例 | 示例含义 |
|---|---|---|---|
| $regex | 匹配正则 | {'name': {'$regex': '^M.*'}} |
name 以 M开头 |
| $exists | 属性是否存在 | {'name': {'$exists': True}} |
name 属性存在 |
| $type | 类型判断 | {'age': {'$type': 'int'}} |
age 的类型为 int |
| $mod | 数字模操作 | {'age': {'$mod': [5, 0]}} |
年龄模 5 余 0 |
| $text | 文本查询 | {'$text': {'$search': 'Mike'}} |
text 类型的属性中包含 Mike 字符串 |
| $where | 高级条件查询 | {'$where': 'obj.fans_count == obj.follows_count'} |
自身粉丝数等于关注数 |
计数
要统计查询结果有多少条数据,可以调用 count() 方法,如统计所有数据条数:
count=collection.find().count() print(count)
或者统计符合某个条件的数据:
count=collection.find({'age':20}).count()#20岁的有多个,也可以按照上面的语法设置大于20岁的
print(count)
结果是一个数值,即符合条件的数据条数。
排序
可以调用 sort() 方法,传入排序的字段及升降序标志即可,示例如下:
import pymongo client=pymongo.MongoClient(host='localhost',port=27017) db=client['test'] collection=db.students results=collection.find().sort('name',pymongo.ASCENDING) print(results) for result in results: print(result)
结果是
<pymongo.cursor.Cursor object at 0x000001C9B1025A90> {'_id': ObjectId('5cebdff23d62e91174af2026'), 'id': '20190102', 'name': 'JACK', 'age': 20, 'gender': 'male'} {'_id': ObjectId('5cebe002fecf127f22fc1e51'), 'id': '20190102', 'name': 'JACK', 'age': 20, 'gender': 'male'} {'_id': ObjectId('5cebe026b7c61f3ffe883afd'), 'id': '20190102', 'name': 'JACK', 'age': 20, 'gender': 'male'} {'_id': ObjectId('5cebdddded5ac7d2e55b22ac'), 'id': '20190101', 'name': 'Tom', 'age': 20, 'gender': 'male'} {'_id': ObjectId('5cebddeef3518b3b23e7ddbd'), 'id': '20190101', 'name': 'Tom', 'age': 20, 'gender': 'male'} {'_id': ObjectId('5cebde9b81244c5461351451'), 'id': '20190101', 'name': 'Tom', 'age': 20, 'gender': 'male'} {'_id': ObjectId('5cebdea920a9a9f93c37de4a'), 'id': '20190101', 'name': 'Tom', 'age': 20, 'gender': 'male'} {'_id': ObjectId('5cebdff23d62e91174af2025'), 'id': '20190101', 'name': 'Tom', 'age': 20, 'gender': 'male'} {'_id': ObjectId('5cebe002fecf127f22fc1e50'), 'id': '20190101', 'name': 'Tom', 'age': 20, 'gender': 'male'} {'_id': ObjectId('5cebe026b7c61f3ffe883afc'), 'id': '20190101', 'name': 'Tom', 'age': 20, 'gender': 'male'}
还有另外一种表达方式
import pymongo client=pymongo.MongoClient(host='localhost',port=27017) db=client['test'] collection=db.students results=collection.find().sort('name',pymongo.ASCENDING) print([result['name'] for result in results])#for循环的简写形式,注意这个中括号
结果是
['JACK', 'JACK', 'JACK', 'Tom', 'Tom', 'Tom', 'Tom', 'Tom', 'Tom', 'Tom']
在这里我们调用了 pymongo.ASCENDING 指定升序,如果要降序排列可以传入 pymongo.DESCENDING。
偏移
在某些情况下我们可能想只取某几个元素,在这里可以利用skip() 方法偏移几个位置,比如偏移 2,就忽略前 2 个元素,得到第三个及以后的元素。
import pymongo client=pymongo.MongoClient(host='localhost',port=27017) db=client['test'] collection=db.students results=collection.find().sort('name',pymongo.ASCENDING).skip(2)# print([result['name'] for result in results])#for循环的简写形式
结果是
['JACK', 'Tom', 'Tom', 'Tom', 'Tom', 'Tom', 'Tom', 'Tom']
另外还可以用 limit() 方法指定要取的结果个数,示例如下:
import pymongo client=pymongo.MongoClient(host='localhost',port=27017) db=client['test'] collection=db.students results=collection.find().sort('name',pymongo.ASCENDING).skip(2).limit(2) print([result['name'] for result in results])#for循环的简写形式
结果是
['JACK', 'Tom']
值得注意的是,在数据库数量非常庞大的时候,如千万、亿级别,最好不要使用大的偏移量来查询数据,很可能会导致内存溢出,可以使用类似如下操作来进行查询:
from bson.objectid import ObjectId collection.find({'_id': {'$gt': ObjectId('593278c815c2602678bb2b8d')}})
这时记录好上次查询的 _id。
更新
对于数据更新可以使用 update() 方法,指定更新的条件和更新后的数据即可,例如:
import pymongo client=pymongo.MongoClient(host='localhost',port=27017) db=client['test'] collection=db.students condition={'name':'Tom'} student=collection.find_one(condition) student['age']=29 result=collection.update_one(condition,{'$set':student})#注意这里可以使用replace_one,update_one,update_many,但在使用update的时候,需要在第二个参数使用 $ 类型操作符作为字典的键名 print(result) print(result.matched_count,result.modified_count)
在这里我们将 name 为 Tom 的数据的年龄进行更新,首先指定查询条件,然后将数据查询出来,修改年龄,之后调用 update() 方法将原条件和修改后的数据传入,即可完成数据的更新。
删除
删除操作比较简单,直接调用 remove() 方法指定删除的条件即可,符合条件的所有数据均会被删除,示例如下:
import pymongo client=pymongo.MongoClient(host='localhost',port=27017) db=client['test'] collection=db.students result=collection.remove({'name':'Tom'}) print(result)
结果
DeprecationWarning: remove is deprecated. Use delete_one or delete_many instead. result=collection.remove({'name':'Tom'}) {'n': 0, 'ok': 1.0}
当然py3中已经全部替换成了delete_one或者delete_many

 浙公网安备 33010602011771号
浙公网安备 33010602011771号