数据的存储——mySQL数据库
关系型数据库基于关系模型的数据库,而关系模型是通过二维表来保存的,所以它的存储方式就是行列组成的表,每一列是一个字段,每一行是一条记录。表可以看作是某个实体的集合,而实体之间存在联系,这就需要表与表之间的关联关系来体现,如主键外键的关联关系,多个表组成一个数据库,也就是关系型数据库。
关系型数据库有多种,如 SQLite、MySQL、Oracle、SQL Server、DB2等等。
MySQL简介
定义
mysql:是用于管理文件的软件
包含内容
服务端的软件:
socket服务端,
本地文件操作
解析指令【sql语句】
客户端软件:
socket客户端,
发送指令
解析指令【sql语句】
选择mysql的原因
现在每一个人的生活几乎都离不开数据库,如果没有数据库,很多事情都会变得非常棘手,也许根本无法做得到。银行、大学和图书馆就是几个严重依赖数据库系统的地方。在互联网上,使用搜索引擎、在线购物甚至是访问网站地址(http://www...)都离不开数据库。一个数据库通常都安装在称为数据库服务器的计算机上。目前市场上运行最快的 SQL (Structured Query Language结构化查询语言) 数据库之一就是MySQL Server,由瑞典的T.c.X. DataKonsultAB公司开发。MySQL可以从http://www.mysql.com/上下载,它提供了其它数据库少有的编程工具,而且 MySQL对于商业和个人用户是免费的。如果想用MySQL开发应用软件,必须支付一定的产品使用许可费用,具体情况可以访问MySQL"s licensing section。
MySQL的功能特点如下:
1. 可以同时处理几乎不限数量的用户;
2. 处理多达50,000,000以上的记录;
3. 命令执行速度快,也许是现今最快的;
4. 简单有效的用户特权系统。
数据库简介
从以上介绍可知,MySQL就是一个管理文件的软件,然后我们向其发送指令,其可以根据指令来执行数据的操作。那么类似的软件还有很多,如:sqllite、db2、oracle、access、sql、sever、MySQL,MongoDB、redis
这些数据库可以被分为两大类:
- 关系型数据库:存储的数据之间存在紧密的约束关系
如:sqllite、db2、oracle、access、sql、sever、MySQL
- 非关系型数据库:数据之间没有紧密的约束关系
如:MongoDB、redis
mysql的安装
在下载的时候,官网下载太慢,可以百度搜索镜像,在官网上会出来亚洲的镜像,选择日本即可。下载速度会快很多。
参考:https://blog.csdn.net/qq_37350706/article/details/81707862,
https://www.bilibili.com/video/av52900249/?p=2
按照步骤操作即可。
但是需要注意关键点
- 在my.ini文件中需要修改自己的安装地址和数据存储地址,
- 其次要使用windows PowerShell,而不是CMD命令
其他问题机解决方式汇总:
问题1:
MySQL 服务正在启动 ...
MySQL 服务无法启动。
服务没有报告任何错误。
请键入 NET HELPMSG 3534 以获得更多的帮助。
直接删除文件夹中的data文件夹然后:
PS D:\系统工具\MySQL\mysql-8.0.16-winx64\bin> mysqld --initialize-insecure
PS D:\系统工具\MySQL\mysql-8.0.16-winx64\bin> net start mysql
MySQL 服务正在启动 ...
MySQL 服务已经启动成功。
问题2:
PS D:\系统工具\MySQL\mysql-8.0.16-winx64\bin> net start mysql
发生系统错误 2。
系统找不到指定的文件。
PS D:\系统工具\MySQL\mysql-8.0.16-winx64\bin> mysqld --remove
Service successfully removed.
PS D:\系统工具\MySQL\mysql-8.0.16-winx64\bin> mysqld --install
Service successfully installed.
问题3:
ERROR 1045 (28000): Access denied for user 'ODBC'@'localhost' (using password: NO)
可以看出上面的问题括号中using password: NO,所以这里不用输密码
直接:
PS D:\系统工具\MySQL\mysql-8.0.16-winx64\bin> mysql -u root -p
Enter password:此处不用输密码直接回车下一步,即可
修改密码:
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '自己的密码';
然后直接回车即可
然后刷新mysql:
flush privileges;
直接下一步
python链接数据库
利用 PyMySQL 连接一下 MySQL 并创建一个名为 spiders的新数据库代码如下:
import pymysql db = pymysql.connect(host='localhost',user='root', password='tiankong123', port=3306) cursor=db.cursor() cursor.execute('SELECT VERSION()') data=cursor.fetchone()#fetchone()函数它的返回值是单个的元组,也就是一行记录,如果没有结果,那就会返回null print('Database version:',data) cursor.execute("CREATE DATABASE spiders DEFAULT CHARACTER SET utf8mb4") db.close()
结果是:
Database version: ('8.0.16',)
代码具体运行过程:
在这里我们通过 PyMySQL 的 connect() 方法声明了一个 MySQL 连接对象,需要传入 MySQL 运行的 host 即 IP,此处由于 MySQL 在本地运行,所以传入的是 localhost,如果 MySQL 在远程运行,则传入其公网 IP 地址,然后后续的参数 user 即用户名,password 即密码,port 即端口默认 3306。
连接成功之后,我们需要再调用 cursor() 方法获得 MySQL 的操作游标,利用游标来执行 SQL 语句,例如在这里我们执行了两句 SQL,用 execute() 方法执行相应的 SQL 语句即可,第一句 SQL 是获得 MySQL 当前版本,然后调用fetchone() 方法来获得第一条数据,也就得到了版本号,另外我们还执行了创建数据库的操作,数据库名称叫做 spiders,默认编码为 utf-8,由于该语句不是查询语句,所以直接执行后我们就成功创建了一个数据库 spiders,接着我们再利用这个数据库进行后续的操作。
创建表
在上面创建完成的spiders数据库的基础上,进行后续操作:
新创建一个数据表,执行创建表的 SQL 语句即可,创建一个用户表 students,在这里指定三个字段,结构如下:
| 字段名 | 含义 | 类型 |
|---|---|---|
| id | 学号 | varchar |
| name | 姓名 | varchar |
| age | 年龄 | int |
创建表的示例代码如下:
import pymysql db=pymysql.connect(host='localhost',user='root',password='tiankong123',port=3306,db='spiders') cursor=db.cursor() sql = 'CREATE TABLE IF NOT EXISTS students (id VARCHAR(255) NOT NULL, name VARCHAR(255) NOT NULL, age INT NOT NULL, PRIMARY KEY (id))' cursor.execute(sql) db.close()
运行之后我们便创建了一个名为 students 的数据表,结果为:
插入数据
我们将数据解析出来后的下一步就是向数据库中插入数据了,例如在这里我们爬取了一个的学生信息,学号为 20120001,名字为 Bob,年龄为 20,那么如何将该条数据插入数据库呢,实例代码如下:
import pymysql id='20120001' name='Bob' age=20 db=pymysql.connect(host='localhost',user='root',password='tiankong123',port=3306,db='spiders') cursor=db.cursor() sql = 'INSERT INTO students(id,name,age)values(%s,%s,%s)'#注意这里的写法,直接用格式化符 %s 来实现 try: cursor.execute(sql,(id,user,age)) db.commit() except: db.rollback() db.close()
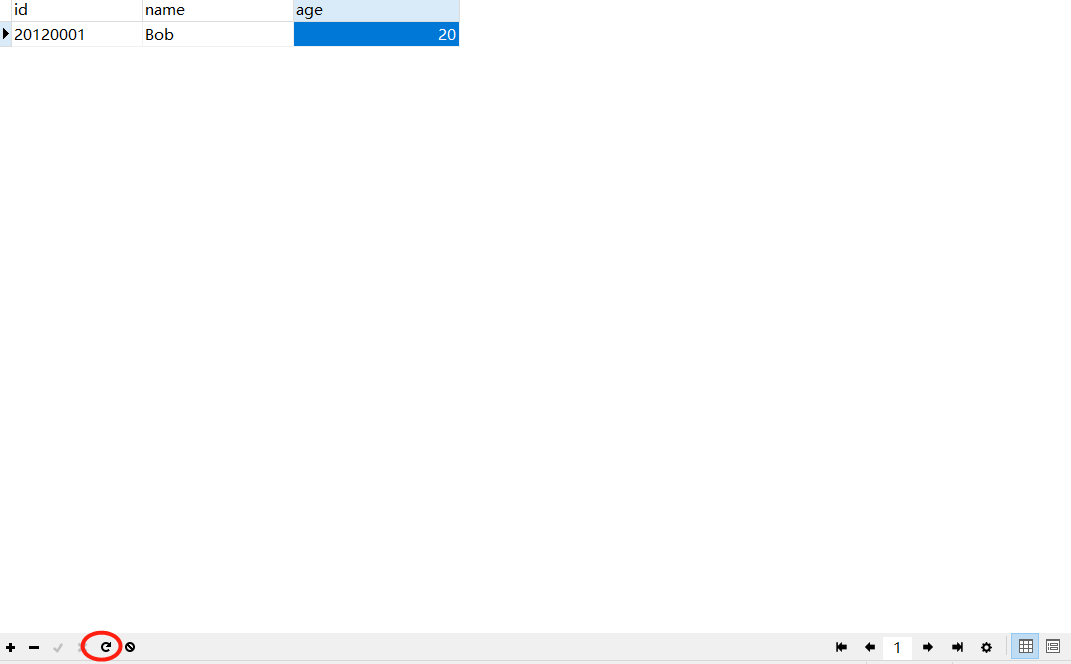
注意运行完代码以后,在Navicat里面要点一下这个刷新一下才会出来结果。
注意
之后值得注意的是,需要执行 db 对象的 commit() 方法才可实现数据插入,这个方法才是真正将语句提交到数据库执行的方法,对于数据插入、更新、删除操作都需要调用该方法才能生效。
接下来我们加了一层异常处理,如果执行失败,则调用rollback() 执行数据回滚,相当于什么都没有发生过一样。
在这里就涉及一个事务的问题,事务机制可以确保数据的一致性,也就是这件事要么发生了,要么没有发生,比如插入一条数据,不会存在插入一半的情况,要么全部插入,要么整个一条都不插入,这就是事务的原子性,另外事务还有另外三个属性,一致性、隔离性、持久性,通常成为 ACID 特性。
归纳如下:
| 属性 | 解释 |
|---|---|
| 原子性(atomicity) | 一个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。 |
| 一致性(consistency) | 事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。 |
| 隔离性(isolation) | 一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。 |
| 持久性(durability) | 持续性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。 |
新增字段的操作
如果需要增加一个性别gender,那么再继续往代码里面添加就会比较麻烦,那么这时候可以构造一个字典来进行实现相关效果。
import pymysql data={ 'id':'20120001', 'name':'Bob', 'age':20 } db = pymysql.connect(host='localhost', user='root', password='tiankong123', port=3306, db='spiders') cursor = db.cursor() table='students' keys=','.join(data.keys()) print(keys) values=','.join(['%s']*len(data)) print(values) sql='INSERT INTO {table}({keys}) VALUES({values})'.format(table=table,keys=keys,values=values) try: if cursor.execute(sql,tuple(data,values())): print('Sucessful') db.commit() except: print('Failed') db.rollback() db.close()
说明
在这里我们传入的数据是字典的形式,定义为 data 变量,表名也定义成变量 table。接下来我们就需要构造一个动态的 SQL 语句了。
首先我们需要构造插入的字段,id、name 和 age,在这里只需要将data的键名拿过来,然后用逗号分隔即可。所以 ', '.join(data.keys()) 的结果就是 id, name, age,然后我们需要构造多个 %s 当作占位符,有几个字段构造几个,比如在这里有两个字段,就需要构造 %s, %s, %s ,所以在这里首先定义了长度为 1 的数组 ['%s'] ,然后用乘法将其扩充为 ['%s', '%s', '%s'],再调用 join() 方法,最终变成 %s, %s, %s。所以我们再利用字符串的 format() 方法将表名,字段名,占位符构造出来,最终sql语句就被动态构造成了:
INSERT INTO students(id, name, age) VALUES (%s, %s, %s)
最后再 execute() 方法的第一个参数传入 sql 变量,第二个参数传入 data 的键值构造的元组,就可以成功插入数据了。
如此以来,我们便实现了传入一个字典来插入数据的方法,不需要再去修改 SQL 语句和插入操作了。
更新数据
数据更新操作实际上也是执行 SQL 语句,最简单的方式就是构造一个 SQL 语句然后执行:
import pymysql data={ 'id':'20120001', 'name':'Bob', 'age':20 } db = pymysql.connect(host='localhost', user='root', password='tiankong123', port=3306, db='spiders') cursor = db.cursor() table='students' keys=','.join(data.keys()) values=','.join(['%s']*len(data)) sql='UPDATE students SET age=%s WHERE name=%s'#更新数据的sql语句 try: if cursor.execute(sql,(25,'Bob')): print('Sucessful') db.commit() except: print('Failed') db.rollback() db.close()
在这里同样是用占位符的方式构造 SQL,然后执行 excute() 方法,传入元组形式的参数,同样执行 commit() 方法执行操作。
如果要做简单的数据更新的话,使用此方法是完全可以的。
但是在实际数据抓取过程中,在大部分情况下是需要插入数据的,但是我们关心的是会不会出现重复数据,如果出现了重复数据,我们更希望的做法一般是更新数据而不是重复保存一次,另外就是像上文所说的动态构造 SQL 的问题,所以在这里我们在这里重新实现一种可以做到去重的做法,如果重复则更新数据,如果数据不存在则插入数据,另外支持灵活的字典传值。
import pymysql data={ 'id':'20120001', 'name':'Bob', 'age':20 } db = pymysql.connect(host='localhost', user='root', password='tiankong123', port=3306, db='spiders') cursor = db.cursor() table='students' keys=','.join(data.keys()) values=','.join(['%s']*len(data)) sql='INSERT INTO {table} ({keys}) VALUES ({values}) ON DUPLICATE KEY UPDATE'.format(table=table,keys=keys,values=values) update= ','.join([" {key}=%s".format(key=key) for key in data]) sql+=update try: if cursor.execute(sql,tuple(data.values())*2): print('Sucessful') db.commit() except: print('Failed') db.rollback() db.close()
说明
在这里构造的 SQL 语句其实是插入语句,但是在后面加了 ON DUPLICATE KEY UPDATE,这个的意思是如果主键已经存在了,那就执行更新操作,比如在这里我们传入的数据 id 仍然为 20120001,但是年龄有所变化,由 20 变成了 21,但在这条数据不会被插入,而是将 id 为 20120001 的数据更新。
相比上面介绍的插入操作的 SQL,后面多了一部分内容,那就是更新的字段,ON DUPLICATE KEY UPDATE 使得主键已存在的数据进行更新,后面跟的是更新的字段内容。所以这里就变成了 6 个 %s。所以在后面的 execute() 方法的第二个参数元组就需要乘以 2 变成原来的 2 倍。
如此一来,我们就可以实现主键不存在便插入数据,存在则更新数据的功能了。
删除数据
删除操作相对简单,使用 DELETE 语句即可,需要指定要删除的目标表名和删除条件,而且仍然需要使用 db 的 commit() 方法才能生效,实例如下:
import pymysql db = pymysql.connect(host='localhost', user='root', password='tiankong123', port=3306, db='spiders') table='students' condition='age>20' sql='DELETE FROM {table} WHERE {condition}'.format(table=table,condition=condition) try: cursor.execute(sql) db.commit() except: db.rollback() db.close()
在这里指定了表的名称,删除条件。因为删除条件可能会有多种多样,运算符比如有大于、小于、等于、LIKE等等,条件连接符比如有 AND、OR 等等,所以不再继续构造复杂的判断条件,在这里直接将条件当作字符串来传递,以实现删除操作。
查询数据
import pymysql db = pymysql.connect(host='localhost', user='root', password='tiankong123', port=3306, db='spiders') sql='SELECT * FROM students WHERE age>=20' try: cursor.excute(sql) print('count:',cursor.rowcount) one=cursor.fetchone() print('One:',one) results=cursor.fetchall() print('Results:',results) print('Results type:',type(results)) for row in results: print(row) except: print('Error')
说明
在这里我们构造了一条 SQL 语句,将年龄 20 岁及以上的学生查询出来,然后将其传给 execute() 方法即可,注意在这里不再需要 db 的 commit() 方法。然后我们可以调用 cursor 的 rowcount 属性获取查询结果的条数,当前示例中获取的结果条数是 4 条。
然后我们调用了 fetchone() 方法,这个方法可以获取结果的第一条数据,返回结果是元组形式,元组的元素顺序跟字段一一对应,也就是第一个元素就是第一个字段 id,第二个元素就是第二个字段 name,以此类推。随后我们又调用了fetchall() 方法,它可以得到结果的所有数据,然后将其结果和类型打印出来,它是二重元组,每个元素都是一条记录。我们将其遍历输出,将其逐个输出出来。
但是这里注意到一个问题,显示的是4条数据,fetall() 方法不是获取所有数据吗?为什么只有3条?这是因为它的内部实现是有一个偏移指针来指向查询结果的,最开始偏移指针指向第一条数据,取一次之后,指针偏移到下一条数据,这样再取的话就会取到下一条数据了。所以我们最初调用了一次 fetchone() 方法,这样结果的偏移指针就指向了下一条数据,fetchall() 方法返回的是偏移指针指向的数据一直到结束的所有数据,所以 fetchall() 方法获取的结果就只剩 3 个了,所以在这里要理解偏移指针的概念。
所以我们还可以用 while 循环加 fetchone() 的方法来获取所有数据,而不是用 fetchall() 全部一起获取出来,fetchall() 会将结果以元组形式全部返回,如果数据量很大,那么占用的开销会非常高。所以推荐使用如下的方法来逐条取数据:
import pymysql db = pymysql.connect(host='localhost', user='root', password='tiankong123', port=3306, db='spiders') sql='SELECT * FROM students WHERE age>=20' try: cursor.excute(sql) print('count:',cursor.rowcount) row=cursor.fetchone() while row: print('Row:',row) row = cursor.fetchone() except: print('Error')
这样每循环一次,指针就会偏移一条数据,随用随取,简单高效。
mysql写入数据的一次尝试
import pymysql company = '阿里巴巴' title = '测试标题' href = '测试链接' source = '测试来源' date = '测试时间' db = pymysql.connect(host='localhost', port=3306, user='root', password='tiankong123',database='spider', charset='utf8') cur = db.cursor() # 获取会话指针,用来调用SQL语句 cur.execute("CREATE TABLE test (company VARCHAR(255) NOT NULL,title VARCHAR(255) NOT NULL,href VARCHAR(255) NOT NULL, date VARCHAR(255) NOT NULL, source VARCHAR(255) NOT NULL, PRIMARY KEY (company))") sql = 'INSERT INTO test(company, title, href, date, source) VALUES (%s, %s, %s, %s, %s)' cur.execute(sql, (company, title, href, date, source)) db.commit() cur.close() db.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号