Selenium
注意自己使用的是百分浏览器,在安装Chromedriver的时候始终有问题,后来改安装Chrome浏览器以后,解决了问题。关键点就是Chromedriver要放在和python同级的目录下。
完全模拟浏览器的操作。
虽然在使用requests的时候已经能够完成网页源代码的获取,但是在涉及到网页翻页或者加载Ajax等需要浏览器来实现的特殊功能的时候就需要用到Selenium库。
访问页面
from selenium import webdriver browser = webdriver.Chrome() browser.get("https://www.sogou.com/") print(browser.page_source) browser.close()
上述代码运行后,会自动打开Chrome浏览器,并打印百度首页的源代码,然后关闭浏览器
查找元素
查找单个元素
详见:http://www.cnblogs.com/MrCandy/p/4230031.html
selenium对web各元素的操作首先就要先定位元素,定位元素的方法主要有以下几种:
- 通过id定位元素:find_element_by_id("id_vaule")
- 通过name定位元素:find_element_by_name("name_vaule")
- 通过tag_name定位元素:find_element_by_tag_name("tag_name_vaule")
- 通过class_name定位元素:find_element_by_class_name("class_name")
- 通过css定位元素:find_element_by_css_selector();用css定位是比较灵活的
- 通过xpath定位元素:find_element_by_xpath("xpath")
- 通过link:find_element_by_link_text("text_vaule")或者find_element_by_partial_link_text()
以百度首页为例:下面是百度输入框的html代码,可以通过谷歌的审查元素或得
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
那么就可以
from selenium import webdriver browser = webdriver.Chrome() browser.get("https://www.baidu.com/") input_first=browser.find_element_by_id("kw") #CSS定位 input_second=browser.find_element_by_css_selector("#kw")#这就好比老师在讲前端的时候使用的便捷操作符,id是#,class是. #XPATH定位 input_third=browser.find_element_by_xpath("//input[@id='kw']")#注意这里的'kw'只能是单引号 print(input_first) print(input_second) print(input_third) browser.close()
CSS定位详解:
https://www.cnblogs.com/yoyoketang/p/6128580.html
Xpath定位详解:
XPath是一种在XML文档中定位元素的语言。
Xpth和CSS定位的对比
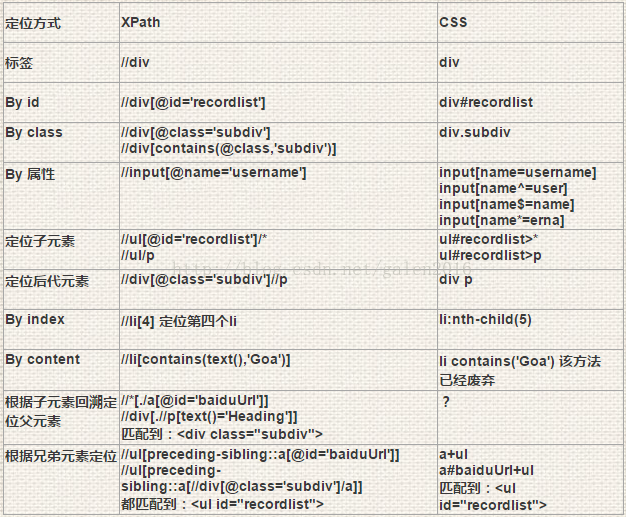
查找多个元素
查找多个元素和查找单个元素的方法一样,具体示例如下:
from selenium import webdriver browser = webdriver.Chrome() browser.get("https://www.taobao.com/") css_1=browser.find_elements_by_css_selector(".layer")#找到所有class是layer的标签 print(css_1) for i in css_1: print(i) browser.close()
当然还有其他方法
find_elements_by_name
find_elements_by_id
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
元素交互操作
对于获取的元素调用交互方法
实现功能:首先在淘宝的搜索框里面输入“ipad",1秒后清空,接着输入”iphone“开始搜索。
from selenium import webdriver import time broswer=webdriver.Chrome() broswer.get("https://www.taobao.com") input_str=broswer.find_element_by_id("q") input_str.send_keys("ipad") time.sleep(1) input_str.clear() input_str.send_keys("iphone") button=broswer.find_element_by_class_name("btn-search")#注意这里本来是class="btn-search tb-bg",但是tb-bg前面这个空格比较麻烦,所以索性只写btn-search即可 button.click()
交互动作-ActionChains
参考:https://www.cnblogs.com/lunvo/p/9182965.html
ActionChains是一个动作链,主要用于鼠标在浏览器上的复杂操作。
ActionChains是自动执行低级交互的一种方式,例如:鼠标移动,鼠标点按,键盘操作,文本操作等。
当我们调用这里的方法时,这些操作会被先储存在一个队列中,当我们调用perform()方法时,队列中的操作会被按顺序执行,执行后队列被清空。
from selenium import webdriver from selenium.webdriver import ActionChains broswer=webdriver.Chrome() broswer.get("https://www.sina.com.cn") sinanews=broswer.find_elements_by_css_selector("a[title='新闻']") #定义ActionChains actions=ActionChains(broswer) #将鼠标移动到新浪新闻上点击 actions.click(sinanews).perform() #在新浪新闻的搜索页面中的搜索框内搜索 actions=ActionChains(broswer) input_str=broswer.find_elements_by_css_selector(".cheadSeaKey") button=broswer.find_elements_by_css_selector(".cheadSeaSmt") actions.click(input_str).perform() actions.send_keys("iphone").perform() actions.click(button).perform()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号