爬虫
爬虫入门知识:
爬虫的定义
抓取网页数据的程序;
爬虫怎么抓取网页数据:
如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网络抓取自己的猎物(数据)爬虫指的是:向网站发起请求,获取资源后分析并提取有用数据的程序;从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用。
爬虫的分类:
爬虫按照获取资源的目的可分为通用爬虫和聚焦爬虫两大类,具体说明如下:
通用爬虫:
搜索引擎用的爬虫。
目标:
就是尽可能把互联网上所有的网页下载下来,放到本地服务器形成备份。再对这些网页做相关处理(提取关键字、去掉广告)最后提供一个用户检索接口。
比如在使用百度搜索的时候,会出现百度快照。那么这个百度快照就是百度搜索引擎将网页在百度自己服务器上的备份。
抓取流程:
首先选择一部分已有的URL,把这些URL放到待爬取的队列中;
从队列中选取这些URL,然后解析DNS得到主机IP,然后去这个IP对应的服务器里下载HTML页面保存到搜索引擎的本地服务器
之后把这个爬过的URL放入已经爬取的队列
分析这些页面内容,找出网页里其他的URL链接,继续执行第二步,直到爬取条件结束
搜索引擎如何获取新网张的站点的URL:
主动向搜索引擎提交网址;
在其他网站上的外部链接:
搜索引擎会和DNS服务上进行合作,可以快速收录新的网站
通用爬虫并不是万物皆可爬,需要遵守相应的规则:
Robots协议,协议会指明通用爬虫可以爬取网页的权限
Robots.txt并不是所有爬虫都遵守,一般只有大型的搜索引擎都会遵守,自己的个人爬虫不用管。
通用爬虫工作流程:
爬取网页——存储数据——内容处理——提供检索/排名服务
搜索引擎排名:
1、PageRank:根据网站流量(点击量/浏览量/人气)统计,流量越高,越值钱;
2、竞价排名:谁给钱多,谁排名就高
注意一个域名一定对应一个IP地址,但是一个IP地址不一定对应一个域名
当在搜索框内输入百度进行检索的时候,内部发生了什么:
当输入百度后,首先会把URL地址发送给DNS进行解析,返回得到一个IP
DNS就是将域名解析成IP的方法
通用爬虫的缺点:
只能提供和文本相关的内容(HTML、word、PDF)等等,但是不能提供多媒体文件。
提供的结果前篇一律,不能针对不同背景领域的人提供不同的搜索结果
不能理解人类语义上的检索
聚焦爬虫:
爬虫程序员写的针对某种内容的爬虫。
为了通用爬虫的弊端而出现聚焦爬虫。
面向主题爬虫,面向需求爬虫,会针对某种特定的内容去爬取信息,而且会保证信息和需求尽可能相关。
为何选择python来做爬虫
可以做爬虫有很多语言:如PHP、JAVA、C++、python
PHP:虽然是世界上最好的语言,但是他天生不是干这个的,而且对线程、异步支持不太好,并发处理能力不太好,
爬虫是工具性程序,对速度和效率要求很高;
Java的网络生态圈很完善(就是开发过程中遇到的所有问题都能够在网上找到答案),是python爬虫最大的对手,但是Java语言本重构成本比较高,任何修改都会导致代码的大量变大。爬虫经常需要修改部分
C++:运行效率和性能最强,但是学习成本很高,代码成型比较慢,能用C++做爬虫,只能说是能力表现,但是不是正确的选择。也就是说世界上能真正精通C++的人很少,招聘懂c++的人来做爬虫有大才小用的感觉。
python:语法又没,代码简洁、开发效率高、支持的模块多、相关的HTTP请求模块多;还有强大的爬虫Scrapy,以及成熟高效的scrapy redis分布式策略。
而且,调用其他接口也很方便
爬虫的基本流程

使用爬虫的基本流程就是:模拟浏览器发送请求->获取网页代码)->对获取的网页源代码进行解析->提取有用的数据->存放于数据库或文件中
发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
Request模块缺陷:不能执行JS 和CSS 代码
发送请求的基本原理
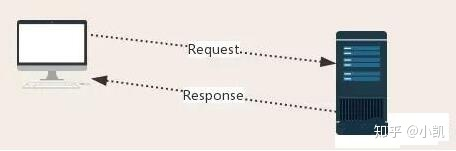
Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socketserver)
Response:服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)
ps:浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
浏览器发送HTTP请求的过程:
1、当用户在浏览器的地址栏中输入一个URL并按下回车键以后,浏览器会向HTTP服务器发送HTTP请求。HTTP请求主要分为GET和POST请求两种方法。
2、当我们在浏览器输入url:https://www.baidu.com的时候,服务器会把Respose文件对象发送给浏览器。
3、浏览器分析Respose中的HTML,发现其中引用了很多文件,比如Image文件,CSS文件,JS文件。浏览器会自动再次发送Response方法去获取图片,CSS文件,或者JS文件。
4、当所有的文件都被下载成功以后,网页会根据HTML语法结构,万恒的显示出来。
URL: Uniform Resource Locator的缩写,统一资源定位符,用于完整地描述Internet上网页和其他资源地址的一种标识方法。
获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
解析内容
利用re、xpath、BeautifulSoup4、Jsonpath、pyquery等模块对HTML的数据进行解析,从大量HTML代码中找到我们所需要的数据。
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
保存数据
数据库(MySQL,Mongdb、Redis)
文件
网页三大特征:
每个网页都有自己的url(统一资源定位)来进行定位;
网页都使用HTML(超文本标记语言)来描述也页面信息;
网页都使用HTTPS(超文本传输协议)协议来传输HTML数据;
爬虫的基本原理
如何抓取HTML页面:
HTTP请求处理,urllib、urllib2、requests.利用这些模块能够模拟浏览器发送请求,获取服务器的响应文件;
request
请求方式
request主要有两种请求方式:GET / POST
GET请求和POST请求的区别
GET请求:
- 请求参数会在浏览器的地址栏中显示,所以不安全;
- 请求参数长度限制长度在1K之内;
- GET请求没有请求体,无法通过request.setCharacterEncoding()来设置参数的编码;
POST请求:
- 请求参数不会显示浏览器的地址栏,相对安全;
- 请求参数长度没有限制;
请求的URL
url全球统一资源定位符,用来定义互联网上一个唯一的资源 例如:一张图片、一个文件、一段视频都可以用url唯一确定。
URL组成解析
scheme://host[:port#]/path/.../[?query-string][#anchor]
scheme:协议(例如:http,https,ftp)
host:服务器的IP地址或者域名;
port:服务器的端口(如果是走协议默认端口,缺省端口80)
path:访问资源路径;
query-string:参数,发送给http服务器的数据;
anchor:锚(跳转到网页指定锚点的位置)
客户端HTTP请求
URL只是标识资源位置,而HTTP是用来提交和获取资源,客户端发送一个HTTP请求到服务器的请求信息,包括以下格式:
请求行、请求头部、空行、请求数据
HTTP请求主要会分为GET和Post两种方法:
GET是从服务器上获取数据,POST是向服务器传送数据
GET请求参数显示,都显示在浏览器网址上,HTTP服务器根据该请求所包含URL中的参数来产生相应内容,即GET请求的参数是URL的一部分;
POST请求参数在请求体当中,消息长度没有限制而且以隐式的方式进行传送,通常用来向HTTP服务器提交量比较大的数据(比如请求中包含许多参数或者文件上传等)请求的参数包含在Content-Type消息头里,指明该信息体的媒体类型和编码。
请求头
User-agent:请求头中如果没有user-agent客户端配置,服务端可能将你当做一个非法用户host;比如在爬取百度首页的时候,如果不加请求头会被拦截,无法获取完整的HTML。
cookies:cookie用来保存登录信息
注意: 一般做爬虫都会加上请求头。
请求头需要注意的参数:
(1)Referrer:访问源至哪里来(一些大型网站,会通过Referrer 做防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent:访问的浏览器(要加上否则会被当成爬虫程序)
(3)cookie:请求头注意携带
请求体
如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到)
如果是post方式,请求体是format data
响应Response
响应状态码
200:代表成功
301:代表跳转
404:文件不存在
403:无权限访问
502:服务器错误
respone header
响应头需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/:可能有多个,是来告诉浏览器,把cookie保存下来
(2)Content-Location:服务端响应头中包含Location返回浏览器之后,浏览器就会重新访问另一个页面
3、preview就是网页源代码
如何采集动态HTML、验证码的处理
通用的动态页面采集、Selenium+PhantomJS(无界面)来模拟真实的浏览器加载数据
Tesseract:机器学习库,机器图像识别系统,可以处理简单的验证码,复杂的验证码可以通过使用手动输入
Scrapy框架:
高定制性(因为使用了异步网络框架twisted,所以数据下载的速度非常快,提供了数据存储、数据下载、提取规则等组件。
国内还有一个pyspider框架
分布式策略:
注意分布式策略只有在数据非常庞大的时候才有用,一般数据量较小的情况下,基本上用不到
建立在scrapy redis基础上
scrapy redis,以scrapy的基础上添加了一套以Redis数据库为核心的一套组件,让Scrapy框架支持分布式的功能。主要在Redis里请求指纹去重、请求分配、数据临时存储。
爬虫和反爬虫
爬虫做到最后最头疼的不是复杂的页面,而是和网站的反爬虫的机制
反爬虫机制:User-Agent、代理、验证码、动态数据加载、加密数据
一般反爬虫机制到封代理就结束了,因为往后做,成本越来越高;
爬虫和爬虫之间的斗争,最后一定是爬虫获胜。因为只要是真实用户能够浏览的网页数据,爬虫就一定能够爬取下来。
Fiddler
在抓包的时候需要用到 Fiddler工具,具体教程参考https://blog.csdn.net/ychgyyn/article/details/82154433
urllib2库的基本使用
所谓网页抓取就是把url地址中指定的网络资源从网络流中读取出来,保存到本地,在python中有很多库可以用来抓取网页,但是urllib2比较常见。
注意在python3中urllib2改为urllib.request
在python3中使用requests库,比urllib库要好得多
获取网页源代码的代码
import requests
response=requests.get("https://www.sogou.com/")
print(response.text)
上面的代码可以获取搜狗首页完整的页面源代码但是加入把搜狗换成百度即
import requests
response=requests.get("https://www.baidu.com/",headers=headers)
print(response.text)
因为百度的首页有反爬虫机制,所以不能获取完整的页面源代码,这就需要加上headers来对爬虫进行伪装即
import requests
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"}
response=requests.get("https://www.baidu.com/",headers=headers)#注意这里必须把headers加上
print(response.text)
User-Agent是反爬虫的第一步。
获取状态码:
200获取信息正常
4开头:表示服务器页面出错;
5开头:表示服务器出错
import requests
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"}
response=requests.get("https://www.baidu.com/",headers=headers)#注意这里必须把headers加上
print(response.text)
print(response.status_code)#获取状态码
User-Agent——list:
因为往后爬虫需要爬取各种各样的网站,单一的User-Agent不能满足要求,这样可以写一个User-Agent——list来防止被网站识破而被封掉
import requests
import random
# import ssl
# context = ssl._create_unverified_context()
user_list=[
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"
]
agent=random.choice(user_list)
print(agent)
headers={"User-Agent": agent}
print(headers)
response=requests.get("https://blog.csdn.net/u011318077/article/details/86532127",headers=headers,verify=False)#注意这里必须把headers加上,由于requests目前还不是非常完善,所以涉及到证书问题,在这里加上verify=False后可以避免证书问题的困扰
print(response.text)
print(response.status_code)#获取状态码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号