粘包现象的解决方案
粘包出现的原因:
连续send两个小数据
两个recv,第一个recv()中的数字特别小。
本质上是不知道要接收多大的数据。
方案一:
首先先确定要发送的数据到底有多大,然后再按照数据的长度来接收数据。
sever端
import socket sk=socket.socket() sk.bind(('127.0.0.1',8080)) sk.listen() conn,addr=sk.accept() while 1: cmd=input('>>>>:') if cmd=='q': conn.send(b'q') break conn.send(cmd.encode('gbk')) num=conn.recv(1024).decode('utf-8') conn.send(b'ok') ret=conn.recv(int(num)).decode('gbk') print(ret) conn.close() sk.close()
client端口
import socket import subprocess sk=socket.socket() sk.connect(('127.0.0.1',8080)) while 1: cmd=sk.recv(1024).decode('gbk') if cmd=='q': break ret=subprocess.Popen(cmd,shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE) stdout=ret.stdout.read() stderr=ret.stderr.read() sk.send(str(len(stdout)+len(stderr)).encode('utf-8')) sk.recv(1024) sk.send(stdout) sk.send(stderr) sk.close()
方案的优势劣势分析:
好处:
确定了我们到底要接收多大的数据:
要在文件中配置一个配置项:就是每一次recv的大小,一般这个值叫做buffer,取4096,因为不能一次性把文件全部都读出来,这样内存容易卡死
当我们要发送大文件的时候,要明确的告诉接收方要发送多大的数据,以便接收方能够准确的接收到所有的数据
多用在文件传输过程中:
大文件的传输,一定是按照字节读,每一次读固定的字节。因为文本可以逐行读,但是视频不能,所以这里只能是逐字节读出来。
传输的过程中,一边读一边传,每一次都读固定的字节数据
不好的地方:
多了一次需要确定该文件大小的交互。
方案二:
利用struct模块
该模块可以把一个类型,如数字,转成固定长度的bytes
import struct ret=struct.pack('i',4096)#将4096转换成一个4个字节的数据 print(ret) res=struct.unpack('i',ret)#结果是一个元组 print(res[0])#还原得到4096这个数
注意struct模块能够将数据转换成4个字节,无论多大的数字都是4个字节。
import struct ret=struct.pack('i',409600)#将4096转换成一个4个字节的数据 print(ret,len(ret)) D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/clent1.py b'\x00@\x06\x00' 4#这也是四个字节,虽然不太像 Process finished with exit code 0
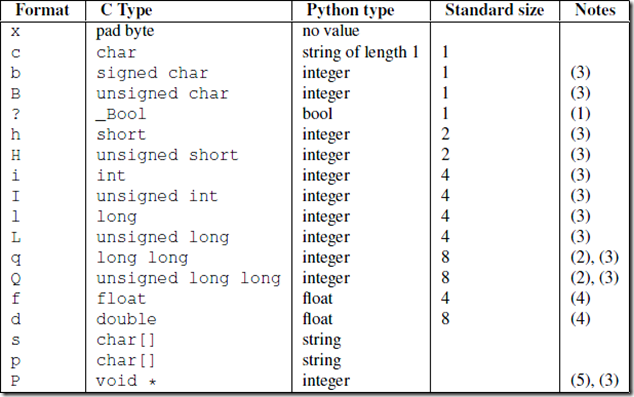
这是struct的一些属性,但是常用的就是i
sever端
import socket import struct sk=socket.socket() sk.bind(('127.0.0.1',8080)) sk.listen() conn,addr=sk.accept() while 1: cmd=input('>>>>:') if cmd=='q': conn.send(b'q') break conn.send(cmd.encode('gbk')) num=conn.recv(4)#这里利用struct已经确定是4个字节 num_i=struct.unpack('i',num) ret=conn.recv(int(num_i[0])).decode('gbk') print(ret) conn.close() sk.close()
client端口
import socket import subprocess import struct sk=socket.socket() sk.connect(('127.0.0.1',8080)) while 1: cmd=sk.recv(1024).decode('gbk') if cmd=='q': break ret=subprocess.Popen(cmd,shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE) stdout=ret.stdout.read() stderr=ret.stderr.read() len_num=len(stdout)+len(stderr) num_by=struct.pack('i',len_num) sk.send(num_by) sk.send(stdout) sk.send(stderr) sk.close()
我们再网络上传输的所有数据都叫数据包
数据包里的所有数据都叫做报文
报文里不只有数据还有IP地址、mac地址、端口号
所有的报文都有报头,只不过我们平时在使用tcp协议和udp协议的过程中,这些协议已经将为我么自动写好了报头
因此我们也可以自己定制报文
应用:在比较复杂的应用上就会用到
比如在传输文件的过程中可以带上文件的名字、文件的大小、文件的类型、存储的路径。
其实在网络传输的过程中,处处有协议
协议就是一堆报文和报头——字节
协议本身就是一种约定,但是最好的协议就是节省时间,节省内存资源。
利用报头来传输文件
sever端
import socket import struct import json sk=socket.socket() sk.bind(('127.0.0.1',8080)) sk.listen() buffer=1024#这里最好控制下数值,数字太大容易报错,以1024为宜 conn,addr=sk.accept() head_len=conn.recv(4) head_len=struct.unpack('i',head_len)[0] json_head=conn.recv(head_len).decode('utf-8') head=json.loads(json_head) filesize=head['filesize'] print(filesize) with open(head['filename'],'wb')as f: while filesize: print(filesize) if filesize>=buffer: content=conn.recv(buffer) f.write(content) filesize-=buffer else: content = conn.recv(filesize) f.write(content) filesize=0 break print(filesize) conn.close() sk.close()
client端口
import socket import json import struct import os sk=socket.socket() sk.connect(('127.0.0.1',8080)) buffer=1024#同理,这里最好控制下数值,数字太大容易报错,以1024为宜 #发送文件 head={'filepath':r'G:',#这里写文件路径 'filename':r'XXXX.webm',#这里写文件名称 'filesize':None} file_path=os.path.join(head['filepath'],head['filename']) filesize=os.path.getsize(file_path) head['filesize']=filesize json_head=json.dumps(head) bytes_head=json_head.encode('utf-8') #计算head的长度 head_len=len(bytes_head)#报头的长度 pack_len=struct.pack('i',head_len) sk.send(pack_len)#先发报头的长度 sk.send(bytes_head)#再发bytes类型的长度 with open(file_path,'rb')as f: while filesize: print(filesize) if filesize>=buffer: content=f.read(buffer)#每次读出的内容 sk.send(content) filesize-=buffer else: content = f.read(filesize) sk.send(content) break sk.close()
解决粘包问题:
出现粘包问题的原因:
首先只有在TCP协议中才会出现粘包现象
是因为TCP协议是面向流的协议
在发送的过程中还有缓存级制来避免数据丢失,因此在连续发送小数据的时候,以及接收大小不符的时候都容易出现粘包现象。本质上还是因为我们在接收数据的时候不知道发送数据的大小。
解决粘包的方案:
在传输大量数据之前告诉接收端要发送的数据的大小;通过struct模块可以更方便得解决这个问题。
struct模块:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号