迭代器和生成器
迭代器
导引:
场景,日常中遇到一个列表,想要取出列表中的每一个元素,怎么取。比如li=[1,2,3],取出li中的每一个元素,可以使用for循环,也可以使用while循环,但是for循环比较简单,所以常用。
那么for循环的运行的原理是什么,这就涉及到我们今天的知识:迭代器。
能够被for循环的数据类型:list、dic、str、set、tuple、f=open()文件、range、enumerate
首先介绍一种方法:
print(dir([]))
利用dir方法可以调用出一个一个数据类型的所有方法。比如列表的方法中会出现'__add__', '__class__', '__contains__', '__delattr__', '等方法,这些带有双下划线的方法又被称为双下划线方法。
双下划线方法:又称双下方法,它是利用C语言写好的代码,不止一种方法可以调用它。比如,'__add__',可以用‘+’来实现,所以一般很少用到'__add__',方法。
比如


print([1].__add__([2])) print([1]+[2]) print([1].__add__([2])) print([1]+[2]) #运行结果都是[1, 2]
python 内部的作用机理:
比如输入1+2,python解释器会首先调用python内置的_add_这个双下方法,然后输出结果3.
场景:求出ist、dic、str、range的所有方法,并找出他们公共的方法
print(dir([]))#显示所有列表的方法 print(dir({}))#显示所有字典的方法 print(dir(''))#显示所有字符串的方法 print(dir(range(10)))#显示所有列表的方法 #需求找到这些数据类型有哪些共同的方法:,用集合的交集功能 ret=set(dir([]))&set(dir({}))&set(dir(''))&set(dir(range(10))) print(ret)
执行这段代码以后可以发现'__iter__'这个方法赫然在列,这就是迭代方法。
那么现在知道数字即int方法不能使用for循环,那么如何判断:
1 print('__iter__' in dir(int)) 2 print('__iter__' in dir(list)) 3 print('__iter__' in dir(dict)) 4 print('__iter__' in dir(str)) 5 print('__iter__' in dir(range(10))) 6 print('__iter__' in dir(tuple)) 7 print('__iter__' in dir(enumerate([]))) 8 9 10 D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/2.作业.py 11 False 12 True 13 True 14 True 15 True 16 True 17 True 18 19 Process finished with exit code 0
说明数字int不能被迭代
通过上面的代码也说明,能够被for循环的代码就一定拥有'__iter__'方法,同理拥有'__iter__'方法,一定能够被迭代,且可以被for循环
可迭代协议:拥有'__iter__'方法,一定能够被迭代,且可以被for循环
也就是说自己可以创建一种数据类型,在这个数据类型中加上'__iter__'方法,那么这个数据类型就可被迭代,就可以使用for循环
引申:
print([].__iter__()) D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/2.作业.py <list_iterator object at 0x0000021B750A5A90> Process finished with exit code 0
引申出迭代器的定义:一个列表执行了__iter__()之后的返回值就是迭代器。
#对比 print(dir([].__iter__())) print(dir([])) #对比的方法:就是求这两个方法的差集; print(set(dir([].__iter__()))-set(dir([]))) #差集结果是:{'__length_hint__', '__next__', '__setstate__'}
其中
'__length_hint__',是求列表中元素的个数,
'__setstate__'是表示从函数的第几个位置开始取值
next:唯有next方法是能够迭代,通过next方法可以从迭代器中一个一个的取值
li=[1,2,3] interator=li.__iter__()#生成一个迭代器 print(interator.__next__())#取出第一个元素1,注意列表中本省并没有__next__()方法,列表中的迭代器中才有 print(interator.__next__())#取出第二元素2 print(interator.__next__())#取出第三个元素3 #通过next方法取出了列表中的所有元素
迭代器协议:只要内部含有'__next__'方法和__iter__方法的就是迭代器,两种方法必须同时存在
通过以下列子说明
from collections import Iterator from collections import Iterable print(isinstance([],Iterator))#结果说明列表不是一个迭代器 print(isinstance([],Iterable))#但是列表可迭代
延申下
1 from collections.abc import Iterable 2 from collections.abc import Iterator 3 4 class A:#自定义一个数据类型 5 def __iter__(self):pass 6 def __next__(self):pass 7 8 a=A() 9 print(isinstance(a,Iterable)) 10 print(isinstance(a,Iterator)) 11 #运行结果皆为true,说明自己定义的这个数据类型符合迭代器协议,可以被迭代,可以使用for循环
只要是迭代器一定可迭代,但是可迭代不一定是迭代器,需要看是否有next方法
可迭代的.__iter__()方法就可以得到一个迭代器。就是加上.__iter__()方法,就能变成迭代器。
for循环其实就是使用了迭代器,学习这个以后,就能够深度理解for循环的机理,其次是为后面的生成器做知识铺垫
当我们遇到一个新的变量,不确定能不能使用for循环得到时候,就判断它是否可迭代
for循环的本质就是迭代器
迭代器的好处:
从从容器中一个一个的取值,会把所有的值都取到
节省内存空间:range和文件的句柄f。迭代器并不会在内存中再占用一大块内存,而是随着循环,每次生成一个。
比如range(100000)这是一个非常大的数字,但是利用可迭代的方法,可以使用range方法表现出来,而不用直接一次性写出100000个数字
生成一个模拟for循环的方法:
li=[1,2,3] interator=li.__iter__() while 1: print(interator.__next__()) #虽然结果会报错,以后再解决
惰性运算:不找生成器要值,迭代器就不会返回值
其次,生成器中的元素都是只能读一遍,
生成器
导引
# 普通函数 def generator(): print(1) return 'a' ret=generator() print(ret) D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/2.作业.py 1 a Process finished with exit code 0
对比
1 #生成器 2 def generator(): 3 print(1) 4 yield 'a' 5 ret=generator() 6 print(ret) 7 8 9 D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/2.作业.py 10 <generator object generator at 0x000002B3676F15E8> 11 12 Process finished with exit code 0
可以看出生成器在函数里面的内容没有执行,生成的结果是内存地址
总结:
只要含有yield关键字的函数都是生成器函数
yield不能和return共用且需要写在函数内
生成器函数:
含有yield关键字的函数就是生成器函数
特点:
调用函数之后函数不执行,返回一个生成器
每次调用next方法的时候会取到一个值
直到取完最后一个,在执行next的时候会报错
1 #普通函数 2 def generator():#在内存中定义一个生成器函数, 3 print(1) 4 yield 'a'#和return类似,yield同样也会返回一个值返回到函数外面,但是return运行后代码会结束运行,yield不会 5 ret=generator()#ret就叫做生成器 6 print(ret) 7 # ret.__iter__() 8 # ret.__next__() 9 #可以看到ret既有__iter__方法又有__next__方法,那么它是一个迭代器, 10 print(ret.__next__())#通过这个方法执行了函数中的代码 11 12 13 D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/2.作业.py 14 <generator object generator at 0x00000248534015E8> 15 1 16 a 17 18 Process finished with exit code 0
解释
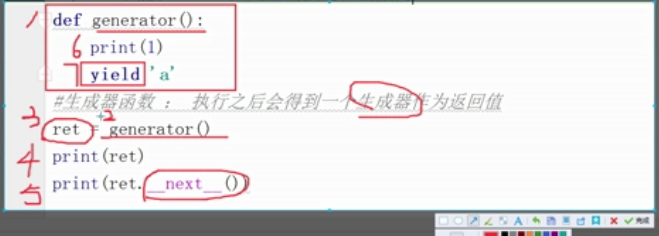
延申
1 def generator(): 2 print(1) 3 yield 'a' 4 print(2) 5 yield 'b' 6 g=generator() 7 # g.__next__() 8 print(g.__next__()) 9 10 11 D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/2.作业.py 12 1 13 a 14 15 Process finished with exit code 0
可以看出yield 'a'后面的代码就终止执行了
对比以下代码
1 def generator(): 2 print(1) 3 yield 'a' 4 print(2) 5 yield 'b' 6 g=generator() 7 g.__next__() 8 print(g.__next__()) 9 10 D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/2.作业.py 11 1 12 2 13 b 14 15 Process finished with exit code 0
上面的现象是自己发现的,暂时自己还不能解释,以后再说。
对比
1 def generator(): 2 print(1) 3 yield 'a'#这里的yield执行完以后将a返回给第8行,但是函数没有结束 4 print(2) 5 yield 'b' 6 g=generator() 7 # g.__next__() 8 print(g.__next__()) 9 print(g.__next__())#在次执行next的时候,继续打印出函数中的所有内容,这就是yield和return的区别,如果是return就不会继续执行第4,5行的代码了 10 11 D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/2.作业.py 12 1 13 a 14 2 15 b 16 17 Process finished with exit code 0
由以上代码可知,使用生成器,可以使用外面的next方法来控制函数内部内容的执行;
1 def generator(): 2 print(1) 3 yield 'a'#这里的yield执行完以后将a返回给第8行,但是函数没有结束 4 print(2) 5 yield 'b' 6 g=generator() 7 #同理由于g同样是一个迭代器,那么就可以使用for循环 8 for i in g: 9 print(i) 10 11 12 D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/2.作业.py 13 1 14 a 15 2 16 b 17 18 Process finished with exit code 0
但是从以上结果可知,使用for循环是直接执行完所有的函数内容;不能中间中断,next方法可以随时控制函数执行的进度
1 #场景:生成200万个哇哈哈 2 def wahaha(): 3 for i in range(2000000): 4 yield '哇哈哈%s'%i#这里一边生产出wahaha 5 g=wahaha()#调用生成器函数得到一个生成器 6 for j in g: 7 print(j)#这边一边输出,每次内存中只有一个,所以不会一下子卡死内存
只想取到前50个哇哈哈
1 #场景:生成200万个哇哈哈 2 def wahaha(): 3 for i in range(2000000): 4 yield '哇哈哈%s'%i#这里一边生产出wahaha 5 g=wahaha() 6 count=0 7 for j in g: 8 count+=1 9 print(j) 10 if count>50:#但是这里我只想取到前50个哇哈哈 11 break
继续
#场景:生成200万个哇哈哈 def wahaha(): for i in range(2000000): yield '哇哈哈%s'%i#这里一边生产出wahaha g=wahaha() count=0 for j in g: count+=1 print(j) if count>50:#但是这里我只想取到前50个哇哈哈 break print('****',g.__next__())#使用next方法后又继续增加到第51个
1 li=[1,2,3] 2 for i in li: 3 print(i) 4 if i==2: 5 break 6 for i in li:#由结果可以看出代码在执行到这里的时候又从头开始执行,那是因为列表是可迭代的,但是并不是一个迭代器,在for循环内部会生成迭代器,也就是每一个for 循环都是一个单独的迭代器,所以这里新生的这个迭代器会从头开始执行 7 print(i) 8 9 10 D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/2.作业.py 11 1 12 2 13 1 14 2 15 3 16 17 Process finished with exit code 0
由结果可以看出代码在执行到这里的时候又从头开始执行,那是因为列表是可迭代的,但是并不是一个迭代器,在for循环内部会自动生成迭代器,也就是每一个for 循环都是一个单独的迭代器,所以在第二个for循环这里会新生的这个迭代器会从头开始执行。
对比
1 #场景:生成200万个哇哈哈 2 def wahaha(): 3 for i in range(2000000): 4 yield '哇哈哈%s'%i#这里一边生产出wahaha 5 g=wahaha() 6 g1=wahaha() 7 print(g.__next__()) 8 print(g1.__next__()) 9 #g和g1是两个完全不同的迭代器,所以两个迭代器都是从头开始执行
总结:从生成器中取值的几个方法:
1、next
2、for
3、数据类型的强制转换
对于第三种方法的说明
def wahaha(): for i in range(20): yield 'wahaha%s'%i g=wahaha() print(list(g))#这里就利用了列表中list方法的强制转换,结果是一个列表,说明通过list方法实现了从生成器中提取到了值;但是与前两种方法相比,这种方法占内存
1 #场景:用户一边通过文件输入,我这边就能通过写的程序看到用户输入的内容 2 f=open('演示',encoding='utf-8')#注意这里是读,所以mode=r被省略 3 while 1: 4 line=f.readline() 5 if line.strip(): 6 print(line.strip())
这里有一个问题就是老师的这段代码执行起来很快,但是自己执行起来非常慢,不知道原因
监听功能
1 def tell(): 2 f = open('演示',encoding='utf-8') 3 while True: 4 line = f.readline() 5 if line.strip(): 6 yield line.strip() 7 8 g=tell() 9 for i in g: 10 if 'python'in i:#如果输入的内容中含有python则打印出来,这就有点类似于监听的功能了 11 print(i)
同样的问题,自己的电脑执行的非常慢,无法做到同步输入,同步显示的状态。
生成器函数进阶
1 def genarotor(): 2 print(123) 3 yield 1 4 print(1234) 5 yield 2 6 print(1235) 7 8 9 g=genarotor()#当执行这段代码的时候,看见函数中存在yield,这里就立即生成一个生成器 10 ret=g.__next__() 11 print(ret) 12 ret=g.__next__()#这里的执行的函数内容是从第一个yiled之后开始到第二个yield之后结束 13 print(ret) 14 ret=g.__next__()#当代码执行到这里的时候,在函数中没有发现yield,那么就会执行 print(1235),然后报错 15 print(ret) 16 17 18 D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/2.作业.py 19 Traceback (most recent call last): 20 123 21 1 22 1234 23 2 24 File "F:/python/python学习/人工智能/第一阶段day2/2.作业.py", line 14, in <module> 25 ret=g.__next__() 26 StopIteration 27 1235 28 29 Process finished with exit code 1
对比
1 def genarotor(): 2 print(123) 3 content=yield 1#当执行完__next__()后,看到这里有yield,程序结束在等号的右边,等号的左边尚未开始执行。当程序开始执行send('hello')的时候,程序开始从右边向左边执行,将'hello'传给content,形成最终结果 4 print('+++',content)# 5 print(1234) 6 yield 2 7 print(1235) 8 9 g=genarotor()# 10 ret=g.__next__() 11 print(ret) 12 ret=g.send('hello')#send的功能与next类似,但是send可以传值 13 print(ret) 14 15 16 D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/2.作业.py 17 123 18 1 19 +++ hello 20 1234 21 2 22 23 Process finished with exit code 0
send获取下一个值的效果和next基本一致,都是从上一个yield之后指执行到下一个yield之前结束
只是在获取下一个值的时候,给上一个yield的位置传递一个数据
使用send的注意事项
第一次使用生成器的时候,是用next获取下一个值
最后一个yield不能接受外部的值
若非要给最后一个yield传值,则可以追加一个yield,但是不返回任何值
1 def genarotor(): 2 print(123) 3 content=yield 1# 4 print('+++',content)# 5 print(1234) 6 yield #这里的yield不返回任何值 7 8 9 g=genarotor()# 10 ret=g.__next__() 11 print(ret) 12 ret=g.send('hello')#send的功能与next类似,但是send可以传值 13 print(ret) 14 15 16 D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/2.作业.py 17 123 18 1 19 +++ hello 20 1234 21 None 22 23 Process finished with exit code 0
生成器的应用
1、求移动平均值
1 def average(): 2 sum=0 3 count=0 4 avg=0 5 while 1: 6 num = yield 7 sum+=num 8 count+=1 9 avg=sum/count 10 yield avg 11 12 avg1=average() 13 avg1.__next__() 14 ret=avg1.send(10) 15 print(ret)
上面的代码只能求出一个数字的移动平均值,推广的广泛
1 def average(): 2 sum=0 3 count=0 4 avg=0 5 while 1: 6 num = yield avg#将返回值写在这里 7 sum+=num 8 count+=1 9 avg=sum/count 10 11 avg1=average() 12 avg1.__next__() 13 ret=avg1.send(10) 14 ret=avg1.send(30) 15 print(ret)
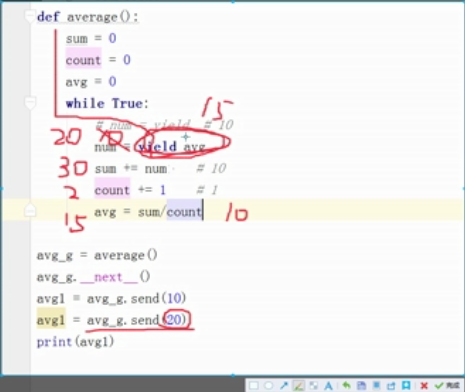
加上装饰器
1 def func(func): 2 def inner(*args,**kwargs): 3 g=func(*args,**kwargs) 4 g.__next__() 5 return g 6 return inner#这里这个装饰器在获取生成器之后,进行next激活,没有其他功能 7 8 @func 9 def average(): 10 sum=0 11 count=0 12 avg=0 13 while 1: 14 num = yield avg#将返回值写在这里 15 sum+=num 16 count+=1 17 avg=sum/count 18 19 avg1=average() 20 ret=avg1.send(10) 21 print(ret) 22 ret=avg1.send(30) 23 print(ret)
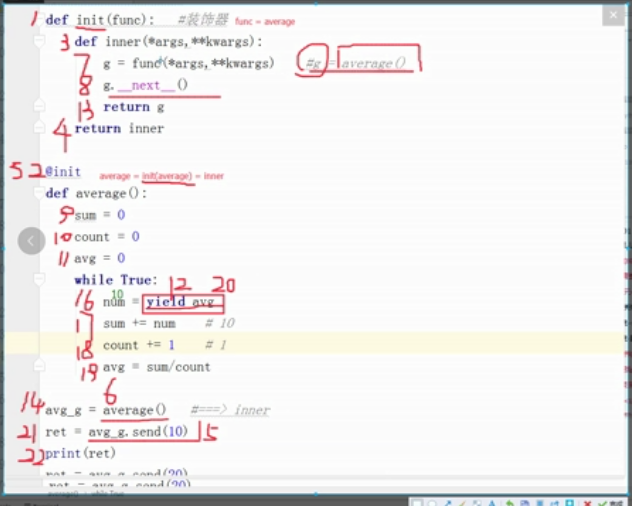
python 3 版本中关于生成器的新功能
例子:
1 def generator(): 2 a='abcdf' 3 b='12345' 4 for i in a: 5 yield i 6 for i in b: 7 yield i 8 9 g=generator() 10 for i in g: 11 print(i)
对比
1 def generator(): 2 a='abcdf' 3 b='12345' 4 yield from a 5 yield from b 6 #yield from是一个python3中新加入的功能,比上面的代码更加简洁 7 8 g=generator() 9 for i in g: 10 print(i)
send总结:
send的作用范围和next一模一样
第一次不能用send
函数的最后一个yield不能接受新的值
总结:
迭代器:
可迭代协议:含有iter方法的都是可迭代的
迭代器协议:含有next和iter的都是迭代器
特点:节省内存空间,方便逐个取值,一个迭代器只能取一次
生成器:所有的生成器都是迭代器,迭代器满足的功能和条件生成器都满足
生成器函数:含有yield关键字的函数都是生成器函数
生成器函数的特点:
调用之后函数内的代码不执行,返回生成器
每从生成器中去一个值就会执行一段代码,遇见yield就会停止
如何从生成器中取值:
for循环:如果没有break就会一直取直到取完
next:每次只取一个
send:不能用在第一个,取下一个值的时候给上一个位置传一个新的值
数据类型的强制转换:会一次性把所有数据都读到内存中
生成器表达式:(条件成立想放在生成器中的值 for i in 可迭代的 if条件)
作业
这是自己写的代码:参考了老师的代码
1 # #处理文件,用户指定要查找的文件和内容,将文件中包含要查找内容的每一行都输出到屏幕 2 str=input('请输入您查找的内容:') 3 def file_check(): 4 with open('file',mode='r+',encoding='utf-8')as f:#f叫做句柄,因为是从英文handler翻译而来,它能够被操作整个文件 5 for i in f: 6 if str in i: 7 yield i 8 g=file_check() 9 for i in g: 10 print(i.strip())
这是老师写的代码
def file_check(): with open('file', mode='r+', encoding='utf-8')as f: # f叫做句柄,因为是从英文handler翻译而来,它能够被操作整个文件 for i in f: if 'dll' in i: yield i g=file_check() for j in g: print(j)
但是这个代码还没有完,因为这是针对file文件的特殊例子,而题目要求是一般情况,所以这就需要用到传参,自己写的代码进阶
# #处理文件,用户指定要查找的文件和内容,将文件中包含要查找内容的每一行都输出到屏幕 str=input('请输入您查找的内容:') def file_check(filename): with open(filename,mode='r+',encoding='utf-8')as f:#f叫做句柄,因为是从英文handler翻译而来,它能够被操作整个文件 for i in f: if str in i: yield i g=file_check('file')#这里的文件名必须带引号 for i in g: print(i.strip())
老师写的代码进阶
1 def file_check(filename,aim): 2 with open(filename,mode='r+',encoding='utf-8')as f:#f叫做句柄,因为是从英文handler翻译而来,它能够被操作整个文件 3 for i in f: 4 if aim in i: 5 yield i 6 g=file_check('file','dll')#这里的文件名必须带引号 7 for i in g: 8 print(i.strip())
2、写生成器,从文件中读取内容,在每一次读取到的内容之前加上“***”之后再返回给用户。这是自己根据上面那道题的代码自己写出来的
1 #写生成器,从文件中读取内容,在每一次读取到的内容之前加上“***”之后再返回给用户 2 def generator(filename): 3 with open(filename,encoding='utf-8')as f: 4 for i in f: 5 yield '***'+i 6 7 g=generator('file') 8 for i in g: 9 print(i.strip())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号