函数的定义
背景
先介绍一个场景:读取一个字符串的长度
s='金老板小护士'
方法一:使用len()方法
s='金老板小护士' s1=len(s) print(s1)
方法二:使用for循环
s='金老板小护士' j=0 for i in s: j=j+1 print(j)
如上所示,使用len方法代码量大为减少,比使用for循环方便得多。但是这只是一个场景,恰好python有给我们提供的内置函数可以使用,但是在实际应用过程中会遇到各种各样的场景,并不是所有的场景都有内置函数可以调用,那么这就需要自定义函数。
小知识:python中的内置函数是由C语言写成的,只能实现基础的功能。
使用函数的原因:可读性强,复用性强。
定义一个函数
s='金老板小护士' def my_len():#def是定义函数的关键字,约定俗称,但是必须要写;my_len是函数名,命名规则跟变量的命名规则一致;后面的括号也是必须得有;且包装在里面的内容必须要缩进 j=0 for i in s: j=j+1 print(j) my_len()#这是调用函数的代码,上面只是形成了一个函数,如果不调用也不会出现结果。此外注意函数名括号必须和上面定义函数时候的写法完全一致, #注意上述代码的执行顺序按照代码行号是:1,2,8,3,4,5,6,也就是说在出现函数后,整个代码的顺序在遵从从上到下的顺序的基础上,进行了调整
但是需要注意的是,函数定义和函数的调用是分开的,也就是说函数被定义以后可以不被调用。
函数的返回值
从上面的代码看,上面的函数与len方法相比,只能机械的计算出s字符串代码的长度。假设有a和b两个字符串,那么使用len方法可以计算出len(a)+len(b),但是使用my_len()函数只能机械的打印出字符串的长度,与len方法相比还有差距。那么只需要在函数内部计算出函数的返回值,并不需要打印出来,这个功能就需要用到return.
接收返回值方法:变量名=函数()
对比以下两段代码:
s='金老板小护士' def my_len():#def是定义函数的关键字,约定俗称,但是必须要写;my_len是函数名,命名规则跟变量的命名规则一致;后面的括号也是必须得有 j=0 for i in s: j=j+1 print(j) # return j length=my_len() print(length) D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/14.py 6 None Process finished with exit code 0
对比
s='金老板小护士' def my_len():#def是定义函数的关键字,约定俗称,但是必须要写;my_len是函数名,命名规则跟变量的命名规则一致;后面的括号也是必须得有 j=0 for i in s: j=j+1 print(j) return j length=my_len()#这段代码是接收函数返回值的结果,有上面的return那么就必须有下面的这段接收代码。 print(length) D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/14.py 6 6 Process finished with exit code 0
函数返回值的3种情况
1、没有返回值
2、返回一个值
3、返回多个值
没有返回值
不写return
函数正常的结束,不写return的原因是只关心功能,不关心结果。
def func(): l=['金老板','二哥'] for i in l: print(i) ret=func() print(ret) D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/14.py 金老板 二哥 None Process finished with exit code 0
只写return
def func(): l=['金老板','二哥'] for i in l: print(i) return#本来要返回那个值,就需要在return后面加上该值,这里什么都不写,结果同样是none ret=func() print(ret) D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/14.py 金老板 二哥 None Process finished with exit code 0
和上面不写return时的代码结果一致,那么就会出现写了return和不写return的结果出现一致的情况。那么return的价值在于一旦写了return那么return后面的代码就不再执行
def func(): l=['金老板','二哥'] for i in l: print(i) return print('二哥二哥')#这段代码不再被执行 ret=func() print(ret) D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/14.py 金老板 二哥 None Process finished with exit code 0
再看一个案例
def func(): l=['金老板','二哥'] for i in l: print(i) if i=='金老板': return#注意此处的功能等同与break ret=func() print(ret) D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/14.py 金老板 None Process finished with exit code 0
return和break的区别
break:只是结束了for循环,并没有跳出自定义的函数
def func(): l=['金老板','二哥'] for i in l: print(i) if i=='金老板': break print('=='*3) ret=func() print(ret) D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/14.py 金老板 ====== None Process finished with exit code 0
return,不仅跳出了for循环,还提前终止了整个函数的运行
def func(): l=['金老板','二哥'] for i in l: print(i) if i=='金老板': return#注意此处的功能等同与break print('=='*3) ret=func() print(ret) D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/14.py 金老板 None Process finished with exit code 0
return None
def func(): l=['金老板','二哥'] for i in l: print(i) if i=='金老板': return None#这里的作用和不写return和只写return的结果都是一样的,但是也是一种结果出现none的原因 print('=='*3) ret=func() print(ret) D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/14.py 金老板 None Process finished with exit code 0
返回一个值
可以返回任何数据类型
只要有返回就可以接收到
再一个程序中有多个return,那么只是执行第一个return
def func(): return[1,2,3,4]#返回一个列表 print(func()) D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/14.py [1, 2, 3, 4] Process finished with exit code 0
返回字典
def func(): return{'k':'v'}#返回一个字典 print(func()) D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/14.py {'k': 'v'} Process finished with exit code 0
返回多个值
多个返回值用多个变量接收,有多少返回值就用多少个变量,
def func(): return 1,2 r1,r2=func()#用多个变量取接收 print(r1,r2) D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/14.py 1 2 Process finished with exit code 0
多个返回值用一个变量接收,得到一个元组
def func(): return 1,2,3 r1=func()#用1个变量取接收,返回值是元组 print(r1) D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/14.py (1, 2, 3) Process finished with exit code 0
结果是元组,元组是不可变数据类型。因为函数的结果不能被随意修改,所以使用元组数据类型很适合。这也是出现不可变数据类型的原因
小知识:
再python解释器中直接输入1,2,3,那么python就会直接将其认为是元组,
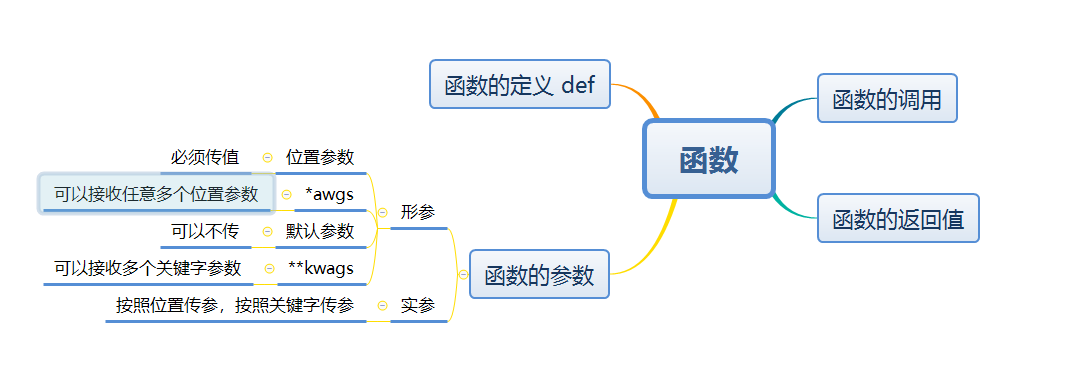
参数
举一个例子
s='金老板小护士' def my_len(): j=0 for i in s: j+=1 print(j) my_len()
与len方法相比,上述代码只能被用来计算s字符串的长度,不能计算除s以外的长度。那么这就需要用到参数的知识
def my_len(s):#自定义函数只需要0个参数,接收参数。那么s就叫做这个函数的参数,因为再这里不知道未来参数到底是什么,所以这里的参数又叫做形式参数或形参 j=0 for i in s: j+=1 return j s='金老板小鼠和'#注意这个s的字符串不能删除 ret= my_len(s)#传递参数,又叫做传参,实际参数又叫做实参 ret= my_len('大家一起来')#将“大家一起来”传递给第7行的代码 print(ret)
通过上面的代码在功能上已经很接近len方法的功能
1 def my_len(s):#自定义函数只需要0个参数,接收参数。那么s就叫做这个函数的参数,因为再这里不知道未来参数到底是什么,所以这里的参数又叫做形式参数或形参 2 j=0 3 for i in s:#注意这个s变量和定义函数处的s变量是完全一致的,而且也必须完全一致 4 j+=1 5 return j 6 s='金老板小鼠和'#注意这个s的字符串不能删除,但是这个s和上面两个s可以不一致。 7 ret= my_len(s)#传递参数,又叫做传参,实际参数又叫做实参,这里的s和第6行的s是一致的。 8 ret= my_len([1,2,3,4,5,6])#计算列表的长度 9 print(ret)
通过传参可以通过外部一个变量的变化来实现对函数实际结果的变化。
在上面的代码运行过程中实际上是首先运行第8行的代码,然后第8行的列表被转换为第7行的s,第7行的s有传值给第一行的函数,然后一步步运行下来
注意函数的运行顺序,这个例子很形象

参数的分类:
可分为三种形式:
1、没有参数
定义函数和调用函数时括号里面什么内容也不写
2、有一个参数、有多个参数三种形式
传什么就是什么
3、有多个参数
def my_sum(a,b):#定义一个做加法的函数 res=a+b return res ret=my_sum(1,2) print(ret)
位置参数
按照位置传参
def my_sum(a,b):#定义一个做加法的函数 res=a+b return res ret=my_sum(1,2)#将1传递给a,2传递给b,相当于固定了位置 print(ret)
按照关键字传参
def my_sum(a,b):#定义一个做加法的函数 res=a+b return res ret=my_sum(b=1,a=2)#在这里固定了a和b的值 print(ret)
位置传参和关键字传参也可以混着用,但是位置必须一一对应
def my_sum(a,b):#定义一个做加法的函数 res=a+b return res ret=my_sum(1,b=2)#但是不能写成a=2,也就是必须先按照位置传参再按照关键字传参 print(ret)
def my_sum(a,b):#定义一个做加法的函数 res=a+b return res ret=my_sum(a=1,2)#这会报错,因为这里既有位置传参也有关键字传参,所以会报错 print(ret)
形式参数
场景:统计全班同学的姓名和性别
位置传参:必须传,也就是和实参处必须一一对应,有几个参数就传几个值
def classmate(name,sex): print('%s : %s'%(name,sex)) classmate('大哥','男') classmate('二哥','男') classmate('三哥','男')
上面的代码可以实现这个功能,但是太复杂。加入全班绝大多数同学都是男生,那么就需要不停输入男,很麻烦可以这样
使用默认参数
默认参数:可以不传,如果不传就是使用默认的参数,如果传了就用传递的参数
def classmate(name,sex='男'): print('%s : %s'%(name,sex)) classmate('大哥') classmate('二哥') classmate('二姐','女')
动态参数:有*args和**kwargs两种
其中*args接收的是按照位置传参的值,组织成一个元组
场景:求不定个数的数字的和,按照一般思路,几个数字就要在定义函数的时候定义几个值,但是这样太麻烦。那么就需要用到动态参数,注意写法是*args
动态参数:可以接收任意多个参数,参数名之前加*
在定义的时候:注意是先定义位置参数、再定义动态参数、然后才是默认参数,可以参考print的英文文档,看格式就明白了
def my_sum(*args):#注意的这个args就是动态参数,由于求和的数字不确定,那么使用动态参数就可以避免写多个参数的问题.注意args可以写成*a,必须有*,但是args是习惯 j=0 for i in args: j=i+j return j print(my_sum(1,2,3)) print(my_sum(1,2,3,4)) print(my_sum(1,2,3,4,5))
场景
定义一个函数,全部按照关键字进行传值,那么在定义函数的时候,就可以类比动态参数,使用**kwargs来代替所有的关键字变量
接收的是按照关键字传参的值,组织成一个字典
def func(**kwargs): print(kwargs) func(a=1,b=2,c=3) func(a=1,b=2) func(a=1)
那么将*args和**kwargs结合起来就能实现接收所有的参数
但是
def func(*args,**kwargs):#注意这里必须是位置参数*args在关键字参数**kwargs之前 print(args,kwargs) func(1,2,3,a=1,b=2,c=3) D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/14.py (1, 2, 3) {'a': 1, 'b': 2, 'c': 3} Process finished with exit code 0
最后总结一下顺序:位置参数>动态参数>默认参数>关键字参数,在定义函数中必须按照这个顺序来写参数
动态参数的另一种传参方式
def func(*args): print(args) l=[1,2,3,4,5] #想把l列表中的每一个元素都放进函数中 #可以按照 func(l[0],l[1],l[2],l[3],l[4])#但是这样太复杂 D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/14.py (1, 2, 3, 4, 5) Process finished with exit code 0
可以想到动态参数的另一种传参形式
def func(*args):#站在形参的角度上,给变量加上*,就是组合所有传来的值 print(args) l=[1,2,3,4,5] func(*l)#站在实参的角度上,给一个序列加上*,就是将这个序列按照顺序打散 D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/14.py (1, 2, 3, 4, 5) Process finished with exit code 0
同理关键字传参
def func(**kwargs): print(kwargs) d={'a':1,'b':2} func(**d)#**d
函数的注释
def func(): ''' 函数实现的功能 参数1 参数2 :return:返回的是数字,字符串 '''
上面的格式就叫做函数的注释
小结:
默认参数陷阱
def func(l=[]):#默认参数是一个列表,列表属于可变数据类型 l.append(1) print(l) func() func([])#如果默认参数的值是一个可变数据类型,那么每一次调用函数的时候,如果不传值就共用这个数据类型的资源 func() func() D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/14.py [1] [1] [1, 1] [1, 1, 1] Process finished with exit code 0
def func(k,l={}):#默认参数是一个字典,字典属于可变数据类型 l[k]='v' print(l) func(1) func(2)#如果默认参数的值是一个可变数据类型,那么每一次调用函数的时候,如果不传值就共用这个数据类型的资源 func(3) D:\anoconda\python.exe F:/python/python学习/人工智能/第一阶段day2/14.py {1: 'v'} {1: 'v', 2: 'v'} {1: 'v', 2: 'v', 3: 'v'} Process finished with exit code 0
上面的例子就是默认参数的陷阱
总结:函数的一般模式
函数:
def 函数名(形参):
函数体
return 返回值
注意如果这里不写返回值,表示终止代码的运行到此终止;如果写返回值;则表示将返回值传给后面执行函数的部分即,f().

 浙公网安备 33010602011771号
浙公网安备 33010602011771号