kubernetes创建资源的两种方式
一、创建方式分类:
命令 vs 配置文件
Kubernetes 支持两种方式创建资源:
1.用 kubectl 命令行的方式直接创建,比如:
kubectl run httpd-app --image=reg.yunwei.edu/learn/httpd:latest --replicas=2
删除
kubectl delete deployment httpd-app
在命令行中通过参数指定资源的属性。
2.通过配置文件和 kubectl apply (就是编排文件,我们可以把创建这个应用的过程写到编排文件里,然后让文件帮我创建应用)创建,要完成前面同样的工作,可执行命令:
kubectl apply -f httpd.yml
编排文件如下图,它一般都是以.yml为结尾的。

httpd.yml 的内容为:
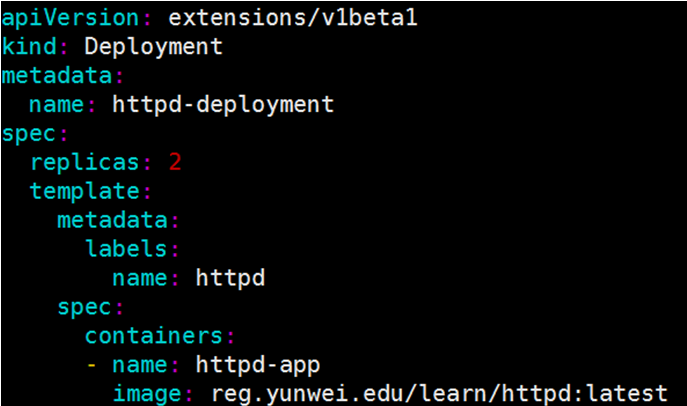
资源的属性写在配置文件中,文件格式为 YAML。
apiVersion: extensions/v1beta1 #API版本 kind: Deployment #启动应用的类型 metadata: #对该资源的元数据的描述,就是说针对于Deployment他的元数据是什么 name: httpd-deployment #元数据里面最少要有一个name参数 spec: #对这个应用规格的描述 replicas: 2 #副本数(我启动这个应用他帮我编排几份) template: #模板(最少包含metadata、labels、name) metadata: #元数据,这是关于规格的元数据 labels: #标签 name: httpd spec: #这是容器的规格 containers: #容器 - name: httpd-app #容器的名字 image: reg.yunwei.edu/learn/httpd:latest #容器应用的镜像
下面对这两种方式进行比较。
基于命令行的方式:
简单直观快捷,上手快。
适合临时测试或实验。
基于配置文件的方式:
配置文件描述了创建应用的过程,即应用最终要达到的状态。
配置文件提供了创建资源的模板,能够重复部署。
可以像管理代码一样管理部署。
适合正式的、跨环境的、规模化部署。
这种方式要求熟悉配置文件的语法,有一定难度。
后面我们都将采用配置文件的方式,大家需要尽快熟悉和掌握。
kubectl apply 不但能够创建 Kubernetes 资源,也能对资源进行更新,非常方便。不过 Kubernets 还提供了几个类似的命令,例如 kubectl create(他只是一个简单的创建过程)、kubectl replace、kubectl edit 和 kubectl patch。
为避免造成不必要的困扰,我们会尽量只使用 kubectl apply(因为它可以对资源进行更新),此命令已经能够应对超过 90% 的场景,事半功倍。
二: 读懂 Deployment YAML
Deployment 的配置格式
分析一个 Deployment 的配置文件。 其他 Controller(比如 DaemonSet)非常类似。

① apiVersion 是当前配置格式的版本。
② kind 是要创建的资源类型,这里是 Deployment。
③ metadata 是该资源的元数据,name 是必需的元数据项。
④ spec 部分是该 Deployment 的规格说明。
⑤ replicas 指明副本数量,默认为 1。
⑥ template 定义 Pod 的模板,这是配置文件的重要部分。
⑦ metadata 定义 Pod 的元数据,至少要定义一个 label。label 的 key 和 value 可以任意指定。
⑧ spec 描述 Pod 的规格,此部分定义 Pod 中每一个容器的属性,name 和 image 是必需的。
运行yaml配置文件:
执行如下命令:
#运行pod
kubectl apply -f httpd.yml #删除pod
kubectl delete -f http.yml
(1)伸缩(Scale Up/Down): 是指在线增加或减少 Pod 的副本数。直接写改yaml配置文件的replicas: 参数即可
出于安全考虑,默认配置下 Kubernetes 不会将 Pod 调度到 Master 节点。
演示:
编排文件如下
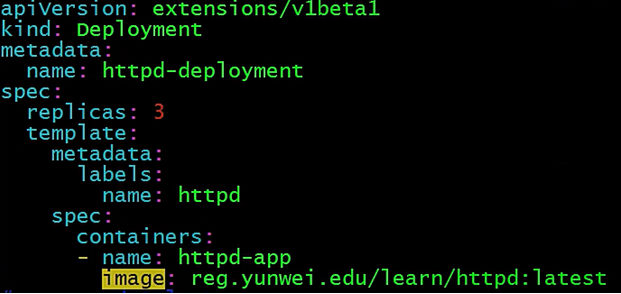
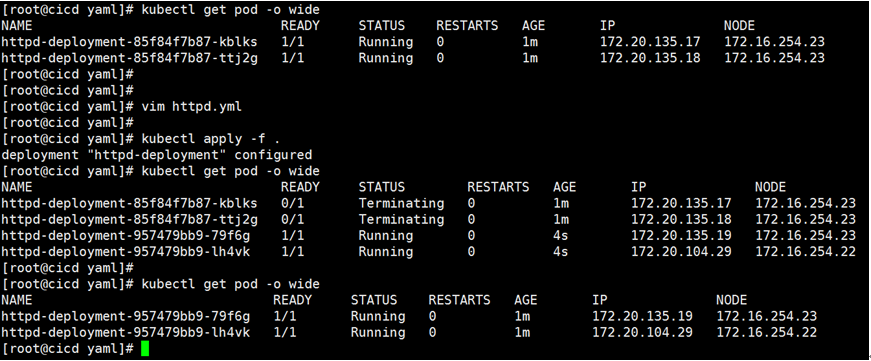
现在我们通过编排文件启动一下这个应用
kubectl apply –f httpd.yml
然后我们获取一下pod
kubectl get pod

我们在查看一下pod的详细信息
kubectl get pod –o wide

现在是每个节点都有一个pod,因为我们设置的3副本,假如说有一天我172.16.254.23节点宕机了,那么他节点上的两个pod就不能正常工作了,那么怎么办么?它会把这两个pod迁移到172.16.254.22这个节点上,在22节点运行了3个副本,这就是弹性伸缩。
你还可以直接从三副本设置成1副本
vim httpd.yml replicas: 1 kubectl apply –f httpd.yml

(2)节点故障(Failover): 比如Kubernetes 检查到 k8s-node3 不可用,将 k8s-node3 上的 Pod 标记为 Unknown 状态,并在 k8s-node2 上新创建两个 Pod,维持总副本数为原指定副本数 3。
当 k8s-node3恢复后,Unknown 的 Pod 会被删除,不过已经运行的 Pod 不会重新调度回 k8s-node3。
(3)用 label 控制 Pod 的位置: 默认配置下,Scheduler 会将 Pod 调度到所有可用的 Node。不过有些情况我们希望将 Pod 部署到指定的 Node,比如将有大量磁盘 I/O 的 Pod 部署到配置了 SSD 的 Node;或者 Pod 需要 GPU,需要运行在配置了 GPU 的节点上。(指定应用的启动)
Kubernetes 是通过 label 来实现这个功能的。label 是 key-value 对,各种资源都可以设置 label,灵活添加各种自定义属性。
演示:
我们先查看默认的node的标记(label)方式
kubectl get node --show-labels

现在的每个节点的labels都是一样的,都是公平的,现在我们给23升个级,给它打个别的标记。
比如执行如下命令标注 k8s-node3 是配置了 SSD 的节点。
#这是先给要想启动到的节点打个标记
kubectl label node 172.16.254.23 disktype=ssd
然后我们在看一下各个node的标记
kubectl get node --show-labels

disktype=ssd 已经成功添加到 k8s-node3,除了 disktype,Node 还有几个 Kubernetes 自己维护的 label。
有了 disktype 这个自定义 label,接下来就可以指定将 Pod 部署到 k8s-node3。编辑 httpd.yml:
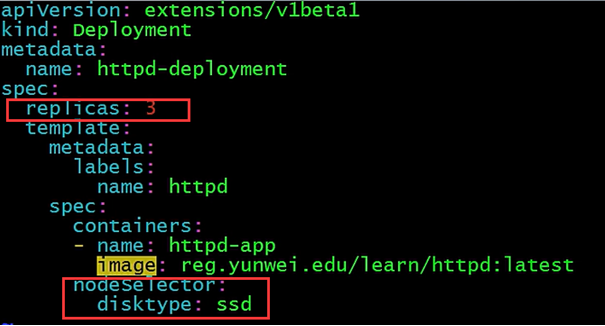
在 Pod 模板的 spec 里通过 nodeSelector (选择)指定将此 Pod 部署到具有:label disktype=ssd 的 Node 上。我们将副本数调为3,看看是否pod都起在了标有disktype=ssd 的labels上。
执行编排文件
kubectl apply –f http.yml
获取pod详细信息
kubectl get pod –o wide

要删除 label disktype,执行如下命令:
kubectl label node k8s-node1 disktype-
即删除。 不过此时 Pod 并不会重新部署,依然在原来的node上运行。

kubectl get node --show-labels

除非在 nginx.yml 中删除 nodeSelector 设置,然后通过 kubectl apply 重新部署。 Kubernetes 会删除之前的 Pod 并调度和运行新的 Pod。
Kubernetes 会删除之前的 Pod 并调度和运行新的 Pod。
三、DaemonSet:
DeamonSet应用
Deployment 部署的副本 Pod 会分布在各个 Node 上,每个 Node 都可能运行好几个副本。DaemonSet 的不同之处在于:每个 Node 上最多只能运行一个副本。
DaemonSet 的典型应用场景有:
在集群的每个节点上运行存储 Daemon,比如 glusterd 或 ceph。
在每个节点上运行日志收集 Daemon,比如 flunentd 或 logstash。
在每个节点上运行监控 Daemon,比如 Prometheus Node Exporter 或 collectd。
其实 Kubernetes 自己就在用 DaemonSet 运行系统组件。执行如下命令:
kubectl get daemonset --namespace=kube-system

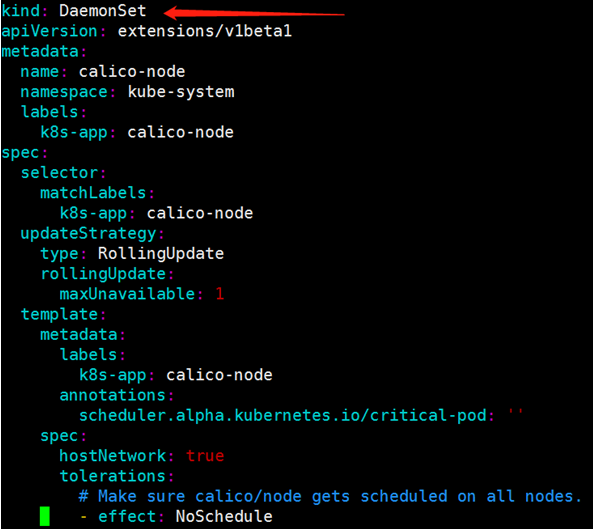
DaemonSet calico-node(网络组件)分别负责在每个节点上运行 calico-node 组件。
kubectl get daemonset –n kube-system –o wide
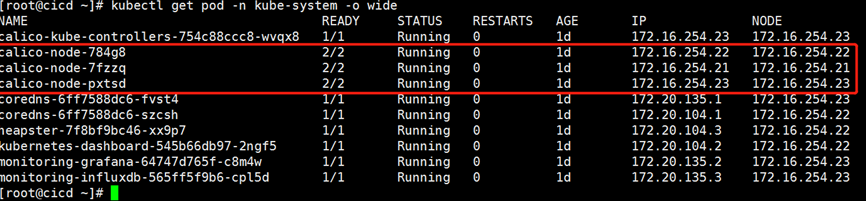
因为 calico-node 属于系统组件,需要在命令行中通过 --namespace=kube-system 指定 namespace kube-system。如果不指定则只返回默认 namespace default 中的资源。
calico的编排文件如下: