
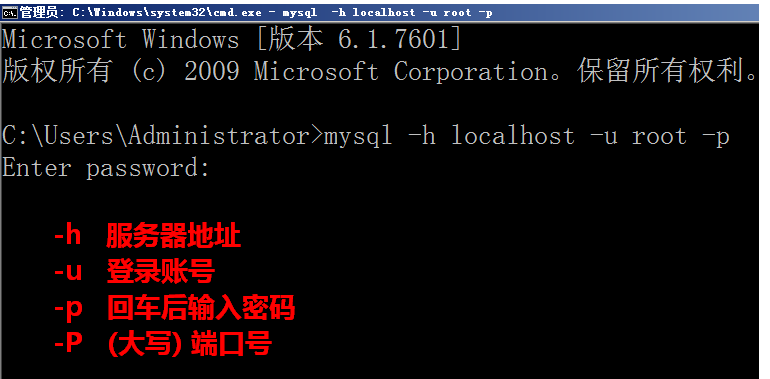
MySQL 基础操作
方式一: 通过图型界面工具,如 Navicat 等( 高级课使用 )
1、DDL语句 数据库定义语言: 数据库、表、视图、索引、存储过程,例如CREATE DROP ALTER
2、DCL语句 数据库控制语言: 例如控制用户的访问权限GRANT、REVOKE
3、DML语句 数据库操纵语言: 插入数据INSERT、删除数据DELETE、更新数据UPDATE
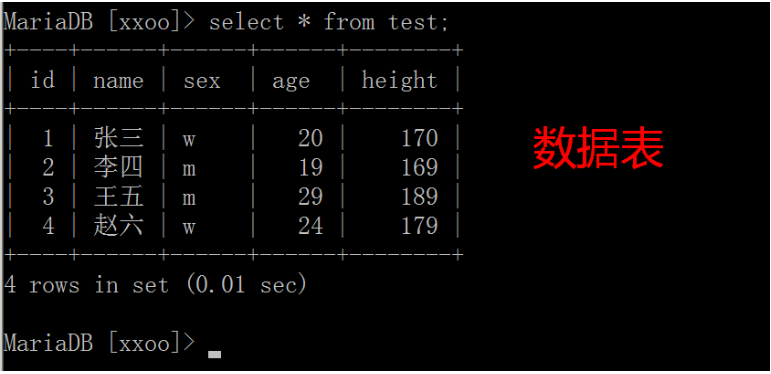
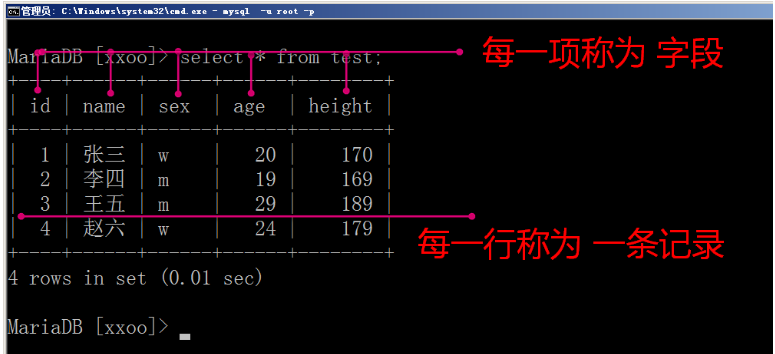
mysql数据库管理软件,记录事物一些数据特征: 由库,表,记录组成. 库相当于一个文件夹 表相当于一个文件 记录就是文件里面一条一条的内容 表中的成员属性就是一个一个字段 可以为每个项目建立一个数据库 关系型数据库:表与表之间有联系 比如:mysql,oracle,db2,sqlserver 非关系型数据库: key-value 键值对形式 没有表的概念 比如:redis,mongodb,memcache
SQL语句中的快捷键
\G 格式化输出(文本式,竖立显示)
\s 查看服务器端信息
\c 结束命令输入操作
\q 退出当前sql命令行模式
\h 查看帮助




创建数据库 create database 库名 default charset=utf8;
删除数据库 drop database 库名;
打开数据库
创建表: create table 表名(字段名1 类型,字段名2 类型)engine=innodb default charset=utf8;
创建表: 如果表不存在,则创建, 如果存在就不执行这条命令
create table if not exists 表名(
字段1 类型,
字段2 类型
);
删除表: drop table 表名;
表结构:
插入多条数据:insert into 表名(字段1,字段2,字段3) values(a值1,a值2,a值3),(b值1,b值2,b值3);
查询 select * from 表名;
select 字段1,字段2,字段3 from 表名;
select * from 表名 where 字段=某个值;
修改 update 表名 set 字段=某个值 where 条件;
update 表名 set 字段1=值1,字段2=值2 where 条件;
update 表名 set 字段=字段+值 where 条件;
删除
# ### mysql 卸载 # (1) windows 卸载 关闭服务 cmd : mysqld remove 删除已经解压的文件夹 重启电脑 # (2) linux 卸载 sudo apt-get autoremove --purge mysql-server-5.7 sudo apt-get remove mysql-common sudo rm -rf /etc/mysql/ /var/lib/mysql #清理残留数据 dpkg -l |grep ^rc|awk '{print $2}' |sudo xargs dpkg -P sudo apt autoremove sudo apt autoreclean
InnoDB
用于事务处理应用程序,支持外键和行级锁。如果应用对事物的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包括很多更新和删除操作,那么InnoDB存储引擎是比较合适的。InnoDB除了有效的降低由删除和更新导致的锁定,还可以确保事务的完整提交和回滚,对于类似计费系统或者财务系统等对数据准确要求性比较高的系统都是合适的选择。
MyISAM
如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不高,那么可以选择这个存储引擎。
Memory
将所有的数据保存在内存中,在需要快速定位记录和其他类似数据的环境下,可以提供极快的访问。Memory的缺陷是对表的大小有限制,虽然数据库因为异常终止的话数据可以正常恢复,但是一旦数据库关闭,存储在内存中的数据都会丢失。
#查看当前的默认存储引擎:
show variables like "default_storage_engine";
#更改表的存储引擎
alter table t1 engine = innodb;
方法2:
#my.ini文件
[mysqld]
default_storage_engine=INNODB
[快捷键] 快捷键:ctrl + l 清屏 快捷键:ctrl + c 终止 exit : 退出数据库 \q : 退出 \G : 垂直显示 [linux] mysql服务命令 service mysql stop service mysql start service mysql restart [windows] mysql服务命令 net stop mysql net start mysql # ### part1 登录的完整语法 # (1) 登录 mysql -u用户 -p密码 -hip地址 mysql -uroot -p -h默认本地ip localhost => 127.0.0.1 # (2) 退出 exit 或者 \q # ### part2 # 查询当前登录用户 select user() # 设置密码 set password = password("123456") # 去除密码 set password = password(""); # ### part3 VMnet8: nat VMnet1:host-only ipconfig [windows] ifconfig[linux] # 给具体某个ip设置一个账户连接linux create user "ceshi100"@"192.168.126.1" identified by "111"; # 给具体192.168.126.% 这个网段下的所有ip设置账户 create user "ceshi101"@"192.168.126.%" identified by "222"; # 给所有ip下的主机设置账户 create user "ceshi102"@"%" identified by "333"; USAGE 没有任何权限 # 查看具体某个ip下的用户权限 show grants for "ceshi102"@"%"; +--------------------------------------+ | Grants for ceshi102@% | +--------------------------------------+ | GRANT USAGE ON *.* TO 'ceshi102'@'%' | +--------------------------------------+ # 授权语法 grant 权限 on 数据库.表 to "用户名"@"ip地址" identified by "密码"; """ select 查询数据的权限 insert 添加数据的权限 update 更改数据的权限 delete 删除数据的权限 * 所有 """ # 授予查询权限 grant select,insert on *.* to "ceshi102"@"%" identified by "333"; # 授予所有权限 grant all on *.* to "ceshi102"@"%" identified by "333"; # 移除删除权限(删除数据库/表) revoke drop on *.* from "ceshi102"@"%" # 移除所有权限 revoke all on *.* from "ceshi102"@"%" # 刷新权限,立刻生效 flush privileges # ### part4 [必须熟练] """ mysql命令中,不区分大小写 [linux]路径 sudo find / -name db001 sudo su root 切换到最高权限账户 cd mysql /var/lib/mysql/数据库... [windows]路径 D:\MySQL5.7\mysql-5.7.25-winx64\data """ # (1) 操作数据库 [文件夹] 增: # 创建数据库 create database db001 charset utf8; 查: # 查看数据库 show databases; # 查看建库语句; show create database db001; +----------+----------------------------------------------------------------+ | Database | Create Database | +----------+--------------------------- -------------------------------------+ | db001 | CREATE DATABASE `db001` /*!40100 DEFAULT CHARACTER SET utf8 */ | +----------+----------------------------------------------------------------+ CREATE DATABASE `db002` /*!40100 DEFAULT CHARACTER SET utf8 */ 改: alter database db002 charset gbk; 删: # 删除数据库 drop database db001 # (2) 操作数据表 [文件] 增: # 选择数据库 use db001 # 创建表 create table t1(id int , name char); 查: # 查看所有表 show tables; # 查看建表语句 show create table t1; """ Table: t1 Create Table: CREATE TABLE `t1` ( `id` int(11) DEFAULT NULL, `name` char(1) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8 1 row in set (0.00 sec) """ # 查看表结构 desc t1; +-------+---------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+-------+ | id | int(11) | YES | | NULL | | | name | char(1) | YES | | NULL | | +-------+---------+------+-----+---------+-------+ 改: # modify 只能改变类型 alter table t1 modify name char(5); # change 改变类型+字段名 alter table t1 change name name123 char(4); # add 添加字段 alter table t1 add age int; # drop 删除字段 alter table t1 drop age; # rename 更改表明 alter table t1 rename t1111111; 删: drop table t1; # (3) 操作记录 [文件的内容] 增: # 一次插入一条数据 insert into t1(id,name) values(1,'abcd'); # 一次插入多条数据 insert into t1(id,name) values(2,"王文"),(3,"刘文波"),(4,"康裕康"),(5,"张保障"); # 不指定具体字段,默认把字段全部插一遍 insert into t1 values(6,"沈思雨"); # 可以具体指定某个字段进行插入 insert into t1(name) values("张宇"); 查: # * 所有 select * from t1; # 查询单个字段 select id from t1; # 查询多个字段 select id,name from t1; 改: # update 表名 set 字段=值 where 条件 update t1 set name="王伟" where id = 2; # 不加条件有风险,一改全改,一定加where update t1 set name="王伟" ; 删: # 删除的时候,必须加上where delete from t1 where id = 1; # 删除所有数据,一删全删,一定加where delete from t1; # 删除所有 (数据+重置id) truncate table t1; # ### part5 常用数据类型 # 整型 tinyint 1个字节 有符号范围(-128~127) 无符号(0~255) unsigned 小整型值 int 4个字节 有符号范围(-21亿 ~ 21亿左右) 无符号(0~42亿) 大整型值 create table t3(id int , sex tinyint); insert into t3(id,sex) values(4000000000,127) error out of range insert into t3(id,sex) values(13,128) error Out of range insert into t3(id,sex) values(13,127); # 浮点型 float(255,30) 单精度 double(255,30) 双精度 decimal(65,30) 金钱类型 (用字符串的形式来存储小数) create table t4(f1 float(5,3) , f2 double(5,3) , f3 decimal(5,3) ); insert into t4 values(1.7777777777777777777777777,1.7777777777777777777777777,1.7777777777777777777777777); insert into t4 values(11.7777777777777777777777777,11.7777777777777777777777777,11.7777777777777777777777777); insert into t4 values(111.7777777777777777777777777,111.7777777777777777777777777,111.7777777777777777777777777); error out of range insert into t4 values(1.7,1.7,1.7); error 整数位最多保留2位 , 小数位最多保留3位;存在四舍五入 # float 小数位默认保留5位,double 小数位默认保留16位,decimal 默认保留整数,四舍五入 create table t5(f1 float , f2 double , f3 decimal); insert into t5 values(1.7777777777777777777777777,1.7777777777777777777777777,1.7777777777777777777777777); create table t6(f1 float(7,3)); insert into t6 values(1234.5678); +----------+ | f1 | +----------+ | 1234.568 | +----------+ # 整数位最多保留4位,小数位最多保留3位 # 默认double保留的小数位更多,float保留的小数位少;decimal保留整数位 insert into t6 values(12345.67); # 字符串 char(字符长度) varchar(字符长度) char(11) 定长:固定开辟11个字符长度的空间(手机号,身份证号),开辟空间的速度上来说比较快,从数据结构上来说,需谨慎,可能存在空间浪费. max = 255 varchar(11) 变长:动态最多开辟11个字符长度的空间(评论,广告),开辟空间的速度上来说相对慢,从数据结构上来说,推荐使用,不存在空间浪费 max > 255 text 文本类型:针对于文章,论文,小说. max > varchar create table t7(c char(11), v varchar(11) , t text); insert into t7 values("11111","11111","11111"); insert into t7 values("你好啊你好啊你好啊你好","你好啊你好啊你好啊你好","你好啊你好啊你好啊你好"); # concat 可以把各个字段拼接在一起 select concat(c,"<=>",v,"<=>",t) from t7; # 数据库内部方法 select user() select concat() select database() select now() # 枚举和集合 enum 枚举 : 从列出来的数据当中选一个 (性别) set 集合 : 从列出来的数据当中选多个 (爱好) create table t8( id int , name varchar(10) , sex enum("男性","兽性","人妖") , money float(5,3) , hobby set("吃肉","抽烟","喝酒","打麻将","嫖赌") ); # 正常写法 insert into t8(id,name,sex , money , hobby) values(1,"张保障","兽性",2.6,"打麻将,吃肉,嫖赌"); # 自动去重 insert into t8(id,name,sex , money , hobby) values(1,"张保障","兽性",2.6,"打麻将,吃肉,嫖赌,嫖赌,嫖赌,嫖赌,嫖赌,嫖赌"); # 异常写法 : 不能选择除了列出来的数据之外的其他值 error 报错 insert into t8(id,name,sex , money , hobby) values(1,"张保障","人妖12",2.6,"打麻将,吃肉,嫖赌12");
# ### char varchar(补充) char 字符串长度 255个 varchar 字符串长度 21845个 # ### part1 时间类型 date YYYY-MM-DD 年月日(节假日,纪念日) time HH:MM:SS 时分秒(体育竞赛,记录时间) year YYYY 年份 (历史,酒的年份) datetime YYYY-MM-DD HH:MM:SS 年月日 时分秒(上线时间,下单时间) create table t1(d date, t time, y year, da datetime); insert into t1 values("2020-11-3",9:19:30","2020","2020-11-3 9:19:30"); insert into t1 values(now(), now(), now(), now()); timestamp YYYYMMDDHHMMSS(时间戳) 自动更新时间(以当前时间戳) datetime没有 create table t2(dt datatime, ts timesstamp); insert into t2 values(20201103092530 , 20201103092530); insert into t2 values(null,null); # 区别 timestamp 自动更新时间(以当前时间戳)datetime没有 insert into t2 values(20390102101010 , 20390102101010); error # 超越2038 # ### part2 v约束:对编辑的数据进行类型的限制,不满足约束条件的报错 unsigned : 无符号 not null : 不为空 default : 默认值 unique : 唯一值 primary key : 主键 auto_increment:自增加一 zerofill : 零填充 foreign key : 外键 # unsigned 无符号 create table t3(id int unsigned); insert into t3 values(-1); error insert into t3 values(4000000000); success # not null : 不为空 create table t4(id int not null , name varchar(11)); insert into t4 values(1,"张宇"); insert into t4 values(null,"张宇");error insert into t4(name) values("李四");error # default :默认值 create table t5(id int not null , name varchar(11) default"沈思雨"); insert into t5 values(1,null); insert into t5(id) values(2); create table t5_2(id int not nill default "111" , name varchar(11) default"沈思雨"); insert into t5_2 values(); # 在values里面不写值,默认使用默认值; # unique :唯一值,加入唯一索引(索引的提出是为了加快速度,一味地乱加索引不会提高查询效率) # 唯一 可为null 标记处: UNI create table t6(id int unique , name char(10) default"赵万里"); insert into t6(id) values(1); insert into t6(id) values(1);error insert into t6(id) values(null); insert into t6(id) values(null); # id变成了多个null # primary key :主键[唯一+不可nill] PRI标记数据的唯一特征 #创建主键 create table t7(id int primary key , name varchar(10) default "赵沈阳"); insert into t7(id) values(1); insert into t7(id) values(1);error insert into t7(id) values(null);error # unique + not null => PRI create table t8(id int unique not null , name varchar(10) default "赵沈阳"); # primary key / unique + not null => 优先把primary key 作为主键; create table t9(id1 int unique not null , id2 int primary key); # 一个表只能设置单个字段为一个主键; create table t10(id1 int primary key , id2 int primary key); error # auto_increment:自增加一(一般配合 主键或者unique 使用) create table t11(id int primary key auto_increment , name varchar(255) default "敬文栋) insert into t11 values(1"张三"); insert into t11 values(null,"李四"); insert into t11(id) values(null); # 使用默认值或者自增插入数据 insert into t11 values(); # 删除数据 delete from t11; # 删除数据 + 重置id truncate table t11; # zerofill : 零填充(配合int使用,不够5位拿0来填充) create table t12(id int(5) zerofill); insert into t12 values(123456); insert into t12 values(12); # ### part3 """ 主键索引:PRI [primary key] 唯一索引:UNI [unique] 普通索引:MUL [index] """ #1.联合唯一索引 """unique(字段1,字段2,字段3......) 合在一起,该数据不能重复""" create table t1_server(id int , server_name varchar(10) not null , ip varchar15) not null , port int not null ,unique(ip,port)); insert into t1_server values(1,"阿里","192.168.11.251",3306); insert into t1_server values(1,"阿里","192.168.11.251",80); insert into t1_server values(1,"阿里","192.168.11.251",80); insert into t1_server values(1,"阿里","192.168.11.251",80); error create table t2_server(id int , server_name varchar(10) not null , ip varchar(15) not null, port int not null , unique(id,port)); insert into t2_server values(1,"腾讯","192.168.11.251",3306); insert into t2_server values(1,"腾讯","192.168.11.251",3306);error insert into t2_server values(1,"腾讯",null,null);# 注意点:允许插入多个空值; +------+-------------+----------------+------+ | id| server_ name | ip | Iport| +------+-------------+----------------+------+ |1 |腾讯| 192.168.11.251 | 3306 | |1 |腾讯| NULL | NULL | |1 |腾讯| NULL | NULL | |1 |腾讯| NULL | NULL | |1 |腾讯| NULL | NULL | +------+-------------+----------------+------+ # 2.联合唯一主键 create table t3_server(id int ,server_name varchar(10) not null , ip varchar(15 , port int , primary key(ip,port)); insert into t3_server values(1,"华为","192.168.11.251",3306); insert into t3_server values(1,"华为","192.168.11.251",3307); """ 总结: primary key(字段1,字段2...) 联合唯一主键 , 单个字段情况,可以设置一个主键,如果是多个字段只能设置成联合主键,合在一起表达一个主键概念; unique(字段1,字段2...) 联合唯一索引 index(字段1,字段2...) 联合普通索引 """ #3.foreign key: 外键,把多张表通过一个关键字联合在一起(该字段可以设置成外键,作业是可以联级更新或者联级删除) """ foreign key(classid) references class1(id) 被关联的字段,必须具备唯一属性; """ student1: id name age classid 1 wangtongpei 58 1 2 liutifeng 85 1 3 wangwen 18 2 class1: id classname 1 python32 2 python33 #创建class1 create table class1(id int , classname varchar(255)); alter table class1 add unique(id); #创建student1 create table student1( id int primary ket auto_increment, name varchar(255), age int, classid int, foreign key(classid) references class(id) ); # 添加数据 insert into class1 values(1,"python32"); insert into class1 values(2,"python33"); insert into class1 values(3,"python34"); insert into student1 values(null,"wangtongpei",58,1); insert into student1 values(null,"liuyifeng",85,1); insert into student1 values(null,"wangwen",18,2); # 没有关联的数据可以直接删除 delete from class1 where id = 1; # 有关联的数据不能直接删除,要先把关联的数据删掉之后再删除 delete from student1 where id = 3; delete from class1 where id = 2; # 联级更新,联级删除 """ 联级更新 on delete cascade 联级删除 on update cascade """ #创建class2 create table class2(id int primary ley auto_increment , classname varchar(255)); #创建student2 create table student2( id int primary key autp_increment, name varchar(255), age int, classid int, foreign key(classid) referrnces class2(id) on delete cascade on update cascade ); # 添加数据 insert into class2 values(1,"python32"); insert into class2 values(2,"python33"); insert into class2 values(3,"python34"); insert into student2 values(null,"wangtongpei"58,1); insert into student2 values(null,"liuyifeng"85,1); insert into student2 values(null,"wangwen"18,2); #联级删除 update class2 set id = 100 where classname="python33"; # ### part4 表与表之间的关系 (1)一对一:id name age sex address guanlian id userid kother father .... (2)一对多(多对一):编辑和学生之间的关系,一个班级可以对应多个学生,反过来,多个学生可以对应一个班级; (3)多对多:一个学生可以同事学习多个学科,一个学科同时可以被多个学生学习 一本书可以呗多个作者共同编写,一个作者可以写多本书 xueke (表1) id name 1 Math 2 English 3 wuli student (表2) id name 1 wangwen 2 wangwei 3 wangtongpei relation (关系表3) """ 吧xid 和 sid 这两个关联字段设置成外键, 关联xueke表里的id(对应的xid), 关联student表里的id(对应的sid) """ xid sid 1 1 1 2 1 3 2 1 2 2 2 3 # ### part5 存储引擎:存储数据的一种结构方式 # 概念: 表级锁:只要有一个线程执行修改表中的相关操作,就会上锁,其他线程默认等待; 行级锁:针对于当前表中的这条记录,这一行进行上锁,其他数据仍然可以被其他线程修改,实现高并发,高可用 事务处理:执行sql语句时,必须所有的操作全部成功,才最终提交数据,有一条失败,直接回滚,恢复到先前状态 begin :开启事务 commit :提交数据 rollback:回滚数据 MyISAM: 表级锁 (5.5版本之前的默认存储引擎) InnoDB:事务处理,行级锁,外键(5.5版本之后的默认存储引擎) MEMORY:把数据放在内存中,临时缓存; BLACKHOLE:anything you write to it disappears 一般用于同步主从数据库;(放在主数据库和从数据库之间的一台服务器;) """ 主数据库:增删改 从数据库:查询 配置:一主一从,一主多从,多主多从 """ create table muisam1(id int) engine=MyISAM; .frm 表结构 .MYD 表数据 .MYI 表索引 create table innodb1(id int) engine=InnoDB; .frm 表结构 .ibd 表数据+表索引 create table memory1(id int) engine=MEMORY; .frm 只有表结构,数据存放在内存中 create table memoey1(id int) engine=BLACKHOLE; .frm 只有表结构
