
python网络并发之进程
进程就是正在运行的程序,它是操作系统中,资源分配的最小单位.
资源分配:分配的是cpu和内存等物理资源
进程号是进程的唯一标识
同一个程序执行两次之后是两个进程
进程和进程之间的关系: 数据彼此隔离,通过socket通信
 View Code
View Code2.同步进程join
1.同步主进程和子进程 : join
(1) join 的基本使用(2) 多进程场景中的join
View Code2使用自定义进程类,创建进程
基本语法
View Code
进程分析图
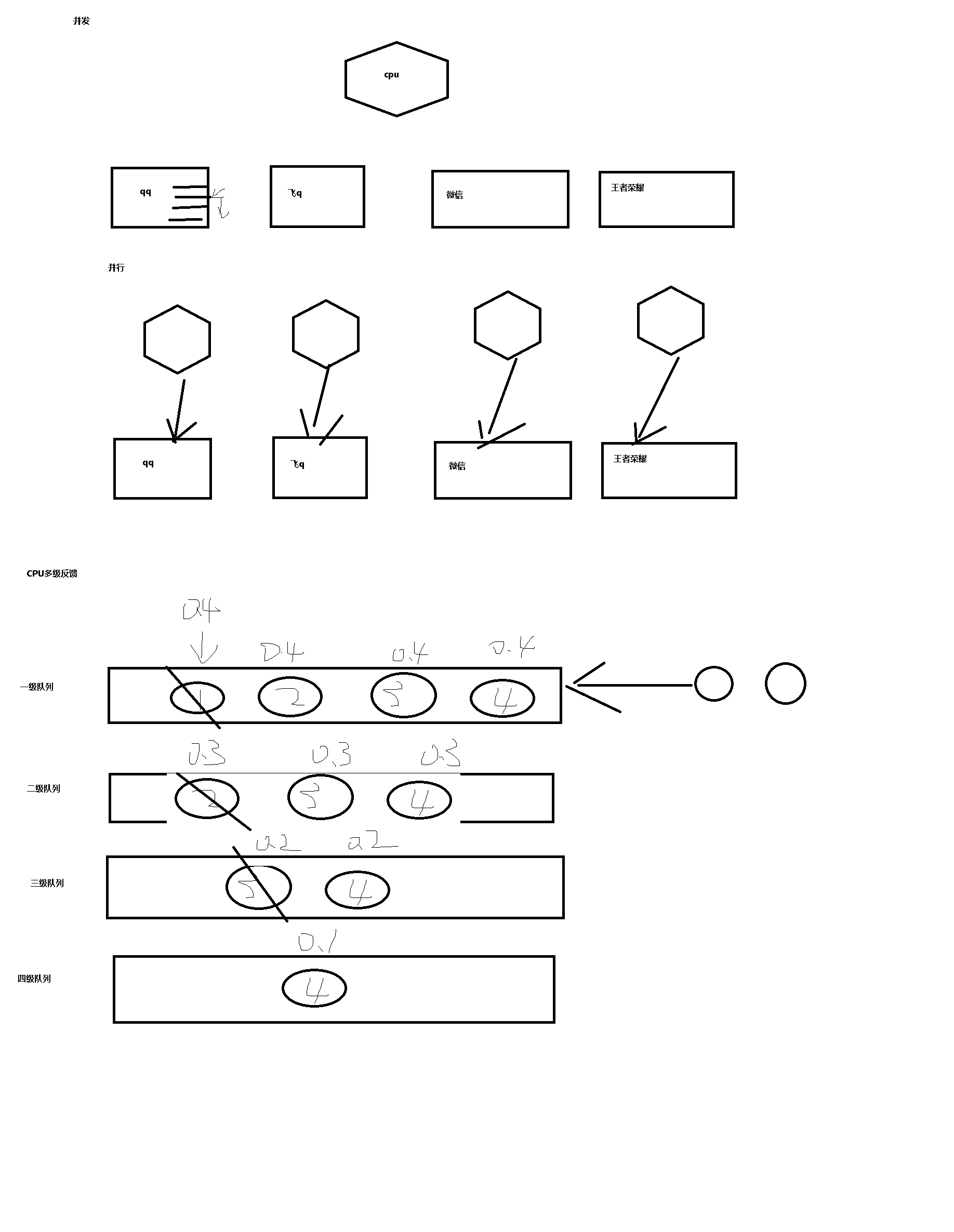
并发:一个cpu同一时间不停执行多个程序
并行:多个cpu同一时间不停执行多个程序
# 先来先服务fcfs(first come first server):先来的先执行
# 短作业优先算法:分配的cpu多,先把短的算完
# 时间片轮转算法:每一个任务就执行一个时间片的时间.然后就执行其他的.
# 多级反馈队列算法
越是时间长的,cpu分配的资源越少,优先级靠后
越是时间短的,cpu分配的资源越多
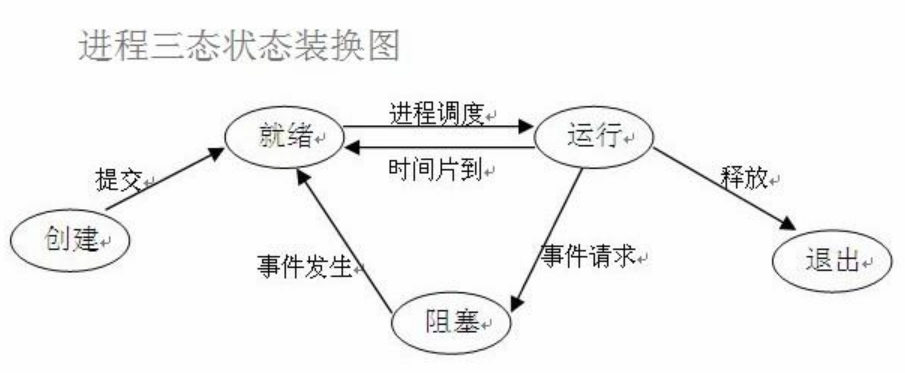
(1)就绪(Ready)状态
只剩下CPU需要执行外,其他所有资源都已分配完毕 称为就绪状态。
(2)执行(Running)状态
cpu开始执行该进程时称为执行状态。
(3)阻塞(Blocked)状态
由于等待某个事件发生而无法执行时,便是阻塞状态,cpu执行其他进程.例如,等待I/O完成input、申请缓冲区不能满足等等。
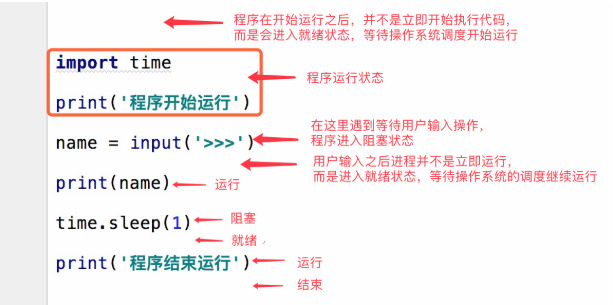
场景在多任务当中
同步:必须等我这件事干完了,你在干,只有一条主线,就是同步
异步:没等我这件事情干完,你就在干了,有两条主线,就是异步
阻塞:比如代码有了input,就是阻塞,必须要输入一个字符串,否则代码不往下执行
非阻塞:没有任何等待,正常代码往下执行.
# 同步阻塞 :效率低,cpu利用不充分
# 异步阻塞 :比如socketserver,可以同时连接多个,但是彼此都有recv
# 同步非阻塞:没有类似input的代码,从上到下执行.默认的正常情况代码
# 异步非阻塞:效率是最高的,cpu过度充分,过度发热 液冷
#可以给子进程贴上守护进程的名字,该进程会随着主进程代码执行完毕而结束(为主进程守护)
(1)守护进程会在主进程代码执行结束后就终止
(2)守护进程内无法再开启子进程,否则抛出异常(了解)
守护进程
守护进程守护的是主进程,当主进程所有代码执行完毕之后,立刻强制杀死守护进程;
View Code
监控报活
lock.acquire()# 上锁
lock.release()# 解锁
#同一时间允许一个进程上一把锁 就是Lock
加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行的修改,没错,速度是慢了,但牺牲速度却保证了数据安全。
#同一时间允许多个进程上多把锁 就是[信号量Semaphore]
信号量是锁的变形: 实际实现是 计数器 + 锁,同时允许多个进程上锁
# 互斥锁Lock : 互斥锁就是进程的互相排斥,谁先抢到资源,谁就上锁改资源内容,为了保证数据的同步性
# 注意:多个锁一起上,不开锁,会造成死锁.上锁和解锁是一对.
锁 lock 互斥锁 12306抢票

from multiprocessing import Process,Lock """ 上锁和解锁是一对, 连续上锁不解锁是死锁 ,只有在解锁的状态下,其他进程才有机会上锁 """ """ # 创建一把锁 lock = Lock() # 上锁 lock.acquire() # lock.acquire() # 连续上锁,造成了死锁现象; print("我在袅袅炊烟 .. 你在焦急等待 ... 厕所进行时 ... ") # 解锁 lock.release() """ # ### 12306 抢票软件 import json,time,random # 1.读写数据库当中的票数 def wr_info(sign , dic=None): if sign == "r": with open("ticket",mode="r",encoding="utf-8") as fp: dic = json.load(fp) return dic elif sign == "w": with open("ticket",mode="w",encoding="utf-8") as fp: json.dump(dic,fp) # dic = wr_info("w",dic={"count":0}) # print(dic , type(dic) ) # 2.执行抢票的方法 def get_ticket(person): # 先获取数据库中实际票数 dic = wr_info("r") # 模拟一下网络延迟 time.sleep(random.uniform(0.1,0.7)) # 判断票数 if dic["count"] > 0: print("{}抢到票了".format(person)) # 抢到票后,让当前票数减1 dic["count"] -= 1 # 更新数据库中的票数 wr_info("w",dic) else: print("{}没有抢到票哦".format(person)) # 3.对抢票和读写票数做一个统一的调用 def main(person,lock): # 查看剩余票数 dic = wr_info("r") print("{}查看票数剩余: {}".format(person,dic["count"])) # 上锁 lock.acquire() # 开始抢票 get_ticket(person) # 解锁 lock.release() if __name__ == "__main__": lock = Lock() lst = ["梁新宇","康裕康","张保张","于朝志","薛宇健","韩瑞瑞","假摔先","刘子涛","黎明辉","赵凤勇"] for i in lst: p = Process( target=main,args=( i , lock ) ) p.start() """ 创建进程,开始抢票是异步并发程序 直到开始抢票的时候,变成同步程序, 先抢到锁资源的先执行,后抢到锁资源的后执行; 按照顺序依次执行;是同步程序; """
信号量 Semaphore 可以控制锁的数量
"""Semaphore = lock + 数量 """ from multiprocessing import Semaphore , Process import time , random """ # 同一时间允许多个进程上5把锁 sem = Semaphore(5) #上锁 sem.acquire() print("执行操作 ... ") #解锁 sem.release() """ def singsong_ktv(person,sem): # 上锁 sem.acquire() print("{}进入了唱吧ktv , 正在唱歌 ~".format(person)) # 唱一段时间 time.sleep( random.randrange(4,8) ) # 4 5 6 7 print("{}离开了唱吧ktv , 唱完了 ... ".format(person)) # 解锁 sem.release() if __name__ == "__main__": sem = Semaphore(5) lst = ["赵凤勇" , "沈思雨", "赵万里" , "张宇" , "假率先" , "孙杰龙" , "陈璐" , "王雨涵" , "杨元涛" , "刘一凤" ] for i in lst: p = Process(target=singsong_ktv , args = (i , sem) ) p.start() """ # 总结: Semaphore 可以设置上锁的数量 , 同一时间上多把锁 创建进程时,是异步并发,执行任务时,是同步程序; """ # 赵万里进入了唱吧ktv , 正在唱歌 ~ # 赵凤勇进入了唱吧ktv , 正在唱歌 ~ # 张宇进入了唱吧ktv , 正在唱歌 ~ # 沈思雨进入了唱吧ktv , 正在唱歌 ~ # 孙杰龙进入了唱吧ktv , 正在唱歌 ~
锁

# 阻塞事件 :
e = Event()生成事件对象e
e.wait()动态给程序加阻塞 , 程序当中是否加阻塞完全取决于该对象中的is_set() [默认返回值是False]
# 如果是True 不加阻塞
# 如果是False 加阻塞
# 控制这个属性的值
# set()方法 将这个属性的值改成True
# clear()方法 将这个属性的值改成False
# is_set()方法 判断当前的属性是否为True (默认上来是False)
事件 (Event) 红绿灯
""" # 阻塞事件 : e = Event()生成事件对象e e.wait()动态给程序加阻塞 , 程序当中是否加阻塞完全取决于该对象中的is_set() [默认返回值是False] # 如果是True 不加阻塞 # 如果是False 加阻塞 # 控制这个属性的值 # set()方法 将这个属性的值改成True # clear()方法 将这个属性的值改成False # is_set()方法 判断当前的属性是否为True (默认上来是False) """ from multiprocessing import Process,Event import time , random # 1 ''' e = Event() # 默认属性值是False. print(e.is_set()) # 判断内部成员属性是否是False e.wait() # 如果是False , 代码程序阻塞 print(" 代码执行中 ... ") ''' # 2 ''' e = Event() # 将这个属性的值改成True e.set() # 判断内部成员属性是否是True e.wait() # 如果是True , 代码程序不阻塞 print(" 代码执行中 ... ") # 将这个属性的值改成False e.clear() e.wait() print(" 代码执行中 .... 2") ''' # 3 """ e = Event() # wait(3) 代表最多等待3秒; e.wait(3) print(" 代码执行中 .... 3") """ # ### 模拟经典红绿灯效果 # 红绿灯切换 def traffic_light(e): print("红灯亮") while True: if e.is_set(): # 绿灯状态 -> 切红灯 time.sleep(1) print("红灯亮") # True => False e.clear() else: # 红灯状态 -> 切绿灯 time.sleep(1) print("绿灯亮") # False => True e.set() # e = Event() # traffic_light(e) # 车的状态 def car(e,i): # 判断是否是红灯,如果是加上wait阻塞 if not e.is_set(): print("car{} 在等待 ... ".format(i)) e.wait() # 否则不是,代表绿灯通行; print("car{} 通行了 ... ".format(i)) """ # 1.全国红绿灯 if __name__ == "__main__": e = Event() # 创建交通灯 p1 = Process(target=traffic_light , args=(e,)) p1.start() # 创建小车进程 for i in range(1,21): time.sleep(random.randrange(2)) p2 = Process(target=car , args=(e,i)) p2.start() """ # 2.包头红绿灯,没有车的时候,把红绿灯关了,省电; if __name__ == "__main__": lst = [] e = Event() # 创建交通灯 p1 = Process(target=traffic_light , args=(e,)) # 设置红绿灯为守护进程 p1.daemon = True p1.start() # 创建小车进程 for i in range(1,21): time.sleep(random.randrange(2)) p2 = Process(target=car , args=(e,i)) lst.append(p2) p2.start() # 让所有的小车全部跑完,把红绿灯炸飞 print(lst) for i in lst: i.join() print("关闭成功 .... ")
# IPC Inter-Process Communication
# 实现进程之间通信的两种机制:
# 管道 Pipe
# 队列 Queue
# put() 存放
# get() 获取
# get_nowait() 拿不到报异常
# put_nowait() 非阻塞版本的put
q.empty() 检测是否为空 (了解)
q.full() 检测是否已经存满 (了解)
进程队列
from multiprocessing import Process,Queue # 引入线程模块; 为了捕捉queue.Empty异常; import queue # 1.基本语法 """顺序: 先进先出,后进后出""" # 创建进程队列 q = Queue() # put() 存放 q.put(1) q.put(2) q.put(3) # get() 获取 """在获取不到任何数据时,会出现阻塞""" # print( q.get() ) # print( q.get() ) # print( q.get() ) # print( q.get() ) # get_nowait() 拿不到数据报异常 """[windows]效果正常 [linux]不兼容""" try: print( q.get_nowait() ) print( q.get_nowait() ) print( q.get_nowait() ) print( q.get_nowait() ) except : #queue.Empty pass # put_nowait() 非阻塞版本的put # 设置当前队列最大长度为3 ( 元素个数最多是3个 ) """在指定队列长度的情况下,如果塞入过多的数据,会导致阻塞""" # q2 = Queue(3) # q2.put(111) # q2.put(222) # q2.put(333) # q2.put(444) """使用put_nowait 在队列已满的情况下,塞入数据会直接报错""" q2 = Queue(3) try: q2.put_nowait(111) q2.put_nowait(222) q2.put_nowait(333) q2.put_nowait(444) except: pass # 2.进程间的通信IPC def func(q): # 2.子进程获取主进程存放的数据 res = q.get() print(res,"<22>") # 3.子进程中存放数据 q.put("刘一缝") if __name__ == "__main__": q3 = Queue() p = Process(target=func,args=(q3,)) p.start() # 1.主进程存入数据 q3.put("赵凤勇") # 为了等待子进程把数据存放队列后,主进程在获取数据; p.join() # 4.主进程获取子进程存放的数据 print(q3.get() , "<33>")
JoinableQueue 队列
""" put 存放 get 获取 task_done 计算器属性值-1 join 配合task_done来使用 , 阻塞 put 一次数据, 队列的内置计数器属性值+1 get 一次数据, 通过task_done让队列的内置计数器属性值-1 join: 会根据队列计数器的属性值来判断是否阻塞或者放行 队列计数器属性是 等于 0 , 代码不阻塞放行 队列计数器属性是 不等 0 , 意味着代码阻塞 """ from multiprocessing import JoinableQueue jq = JoinableQueue() jq.put("王同培") # +1 jq.put("王伟") # +2 print(jq.get()) print(jq.get()) # print(jq.get()) 阻塞 jq.task_done() # -1 jq.task_done() # -1 jq.join() print(" 代码执行结束 .... ") # ### 2.使用JoinableQueue 改造生产着消费者模型 from multiprocessing import Process,Queue import time,random # 消费者模型 def consumer(q,name): while True: # 获取队列中的数据 food = q.get() time.sleep(random.uniform(0.1,1)) print("{}吃了{}".format(name,food)) # 让队列的内置计数器属性-1 q.task_done() # 生产者模型 def producer(q,name,food): for i in range(5): time.sleep(random.uniform(0.1,1)) # 展示生产的数据 print( "{}生产了{}".format( name , food+str(i) ) ) # 存储生产的数据在队列中 q.put(food+str(i)) if __name__ == "__main__": q = JoinableQueue() p1 = Process( target=consumer,args=(q , "赵万里") ) p2 = Process( target=producer,args=(q , "赵沈阳" , "香蕉" ) ) p1.daemon = True p1.start() p2.start() p2.join() # 必须等待队列中的所有数据全部消费完毕,再放行 q.join() print("程序结束 ... ")
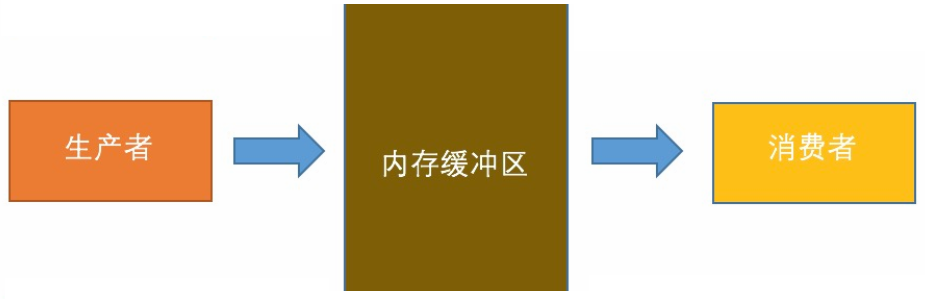
生产者与消费者模型 爬虫案例
""" # 爬虫案例 1号进程负责抓取其他多个网站中相关的关键字信息,正则匹配到队列中存储(mysql) 2号进程负责把队列中的内容拿取出来,将经过修饰后的内容布局到自个的网站中 1号进程可以理解成生产者 2号进程可以理解成消费者 从程序上来看 生产者负责存储数据 (put) 消费者负责获取数据 (get) 生产者和消费者比较理想的模型: 生产多少,消费多少 . 生产数据的速度 和 消费数据的速度 相对一致 """ # 1.基础版生产着消费者模型 """问题 : 当前模型,程序不能正常终止 """ """ from multiprocessing import Process,Queue import time,random # 消费者模型 def consumer(q,name): while True: # 获取队列中的数据 food = q.get() time.sleep(random.uniform(0.1,1)) print("{}吃了{}".format(name,food)) # 生产者模型 def producer(q,name,food): for i in range(5): time.sleep(random.uniform(0.1,1)) # 展示生产的数据 print( "{}生产了{}".format( name , food+str(i) ) ) # 存储生产的数据在队列中 q.put(food+str(i)) if __name__ == "__main__": q = Queue() p1 = Process( target=consumer,args=(q , "赵万里") ) p2 = Process( target=producer,args=(q , "赵沈阳" , "香蕉" ) ) p1.start() p2.start() p2.join() """ # 2.优化模型 """特点 : 手动在队列的最后,加入标识None, 终止消费者模型""" """ from multiprocessing import Process,Queue import time,random # 消费者模型 def consumer(q,name): while True: # 获取队列中的数据 food = q.get() # 如果最后一次获取的数据是None , 代表队列已经没有更多数据可以获取了,终止循环; if food is None: break time.sleep(random.uniform(0.1,1)) print("{}吃了{}".format(name,food)) # 生产者模型 def producer(q,name,food): for i in range(5): time.sleep(random.uniform(0.1,1)) # 展示生产的数据 print( "{}生产了{}".format( name , food+str(i) ) ) # 存储生产的数据在队列中 q.put(food+str(i)) if __name__ == "__main__": q = Queue() p1 = Process( target=consumer,args=(q , "赵万里") ) p2 = Process( target=producer,args=(q , "赵沈阳" , "香蕉" ) ) p1.start() p2.start() p2.join() q.put(None) # 香蕉0 香蕉1 香蕉2 香蕉3 香蕉4 None """ # 3.多个生产者和消费者 """ 问题 : 虽然可以解决问题 , 但是需要加入多个None , 代码冗余""" from multiprocessing import Process,Queue import time,random # 消费者模型 def consumer(q,name): while True: # 获取队列中的数据 food = q.get() # 如果最后一次获取的数据是None , 代表队列已经没有更多数据可以获取了,终止循环; if food is None: break time.sleep(random.uniform(0.1,1)) print("{}吃了{}".format(name,food)) # 生产者模型 def producer(q,name,food): for i in range(5): time.sleep(random.uniform(0.1,1)) # 展示生产的数据 print( "{}生产了{}".format( name , food+str(i) ) ) # 存储生产的数据在队列中 q.put(food+str(i)) if __name__ == "__main__": q = Queue() p1 = Process( target=consumer,args=(q , "赵万里") ) p1_1 = Process( target=consumer,args=(q , "赵世超") ) p2 = Process( target=producer,args=(q , "赵沈阳" , "香蕉" ) ) p2_2 = Process( target=producer,args=(q , "赵凤勇" , "大蒜" ) ) p1.start() p1_1.start() p2.start() p2_2.start() # 等待所有数据填充完毕 p2.join() p2_2.join() # 把None 关键字放在整个队列的最后,作为跳出消费者循环的标识符; q.put(None) # 给第一个消费者加一个None , 用来终止 q.put(None) # 给第二个消费者加一个None , 用来终止 # ...
# 进程池:
# 开启过多的进程并不一定提高你的效率,
# 如果cpu负载任务过多,平均单个任务执行的效率就会低,反而降低执行速度.
1个人做4件事,4个人做4件事,4个人做1件事
显然后者执行速度更快,
前者是并发,后者是并行
利用进程池,可以开启cpu的并行效果
# apply 开启进程,同步阻塞,每次都要等待当前任务完成之后,在开启下一个进程
# apply_async 开启进程,异步非阻塞,(主进程 和 子进程异步)
Manager ( list 列表 , dict 字典 ) 进程之间共享数据
from multiprocessing import Process , Manager ,Lock def mywork(data,lock): # 共享字典 """ lock.acquire() data["count"] -= 10 lock.release() """ # 共享列表 data[0] += 1 if __name__ == "__main__": lst = [] m = Manager() lock = Lock() # 多进程中的共享字典 # data = m.dict( {"count":5000} ) # print(data , type(data) ) # 多进程中的共享列表 data = m.list( [100,200,300] ) # print(data , type(data) ) """""" # 进程数超过1000,处理该数据,死机(谨慎操作) for i in range(10): p = Process(target=mywork,args=(data,lock)) p.start() lst.append(p) # 必须等待子进程所有计算完毕之后,再去打印该字典,否则报错; for i in lst: i.join() print(data)
