
pandas读取大文件时memoryerror的解决办法
再用pd.read_csv读取大文件时,如果文件太大,会出现memoryerror的问题。
解决办法一:pd.read_csv的参数中有一个chunksize参数,为其赋值后,返回一个可迭代对象TextFileReader,对其遍历即可
reader = pd.read_csv(file_path, chunksize=20) # 每次读取20条数据

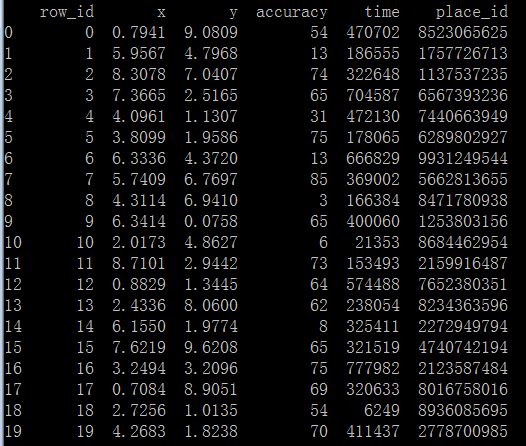
1 import pandas as pd 2 3 def knn(): 4 # 读取数据 5 file_path = './facebook/train.csv' 6 7 reader = pd.read_csv(file_path, chunksize=20) # 每块为20条数据(index) 8 9 for chunk in reader: 10 print(chunk) 11 break 12 13 if __name__ == '__main__': 14 knn()
代码执行结果如下:
解决办法二:pd.read_csv的参数中有一个iterator参数,默认为False,将其改为True,返回一个可迭代对象TextFileReader,使用它的get_chunk(num)方法可获得前num行的数据
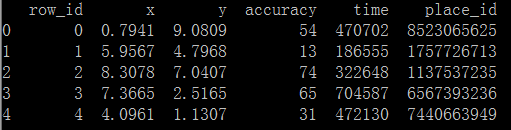
import pandas as pd def knn(): '''完成k近邻算法''' # 读取数据 file_path = './facebook/train.csv' reader = pd.read_csv(file_path, iterator=True) chunk = reader.get_chunk(5) # 获取前5行数据 print(chunk) if __name__ == '__main__': knn()
代码执行结果如下:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?