01 Spark架构与运行流程
HDFS
HDFS(Hadoop分布式文件系统)源自于Google的GFS论文,发表于2003年10月,HDFS是GFS的实现版。HDFS是Hadoop体系中数据存储管理的基础,它是一个高度容错的系统,能检测和应对硬件故障,在低成本的通用硬件上运行。HDFS简化了文件的一次性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适用带有数据集的应用程序。HDFS提供一次写入多次读取的机制,数据以块的形式,同时分布存储在不同的物理机器上。
HDFS默认的最基本的存储单位是64MB的数据块,和普通文件系统一样,HDFS中的文件被分成64MB一块的数据块存储。它的开发是基于流数据模式访问和处理超大文件的需求。
超大文件
超大文件:是指进行存储的文件达到MB、GB、TB级的大文件。
流式数据访问
流式数据访问:一次写入、多次读取的访问模式。
商用硬件
在节点出现故障时,HDFS会继续运行,用户不会察觉到明显的中断情况。这是由于HDFS的高可用性和容错性是通过软件来实现的,也由此使得它不需要价格高的设备来保障,大街小巷能买到的普通硬件就能用作搭建HDFS。
HDFS并不是所有场景都适用。
1)由于HDFS的优势是海量数据传输,在低延迟的数据访问中就并不适用,10ms以下的访问可以无视HDFS。HDFS会用延迟来换取数据的高吞吐量。
2)存在的小文件较多时,HDFS也不适用。这主要是由于HDFS的整个文件存储在NameNode中,它能对数据库的存储位置进行定位,因此NameNode的内存量是被文件的数量限制的。而大量的小文件会占用很大一部分内存,在进行数据处理时会合并这些小文件。
3)在多处写和随机修改的场景中,由于HDFS的文件不支持多个写入或任意位置的修改,所以HDFS也不适用。
MapReduce
Mapduce(分布式计算框架)源自于Google的MapReduce论文,发表于2004年12月,Hadoop MapReduce是Google Reduce 克隆版。MapReduce是一种分布式计算模型,用以进行海量数据的计算。它屏蔽了分布式计算框架细节,将计算抽象成Map 和Reduce两部分,其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce非常适合在大量计算机组成的分布式并行环境里进行数据处理。
HBase
Hbase(分布式列存数据库)源自Google的BigTable论文,发表于2006年11月,HBase是Google Table的实现。HBase是一个建立在HDFS之上,面向结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。HBase采用了BigTable的数据模型,即增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
YARN
YARN(分布式资源管理器)是下一代MapReduce,即MRv2,是在第一代MapReduce基础上演变而来的,主要是为了解决原始Hadoop扩展性差,不支持多计算框架而提出的。YARN是下一代Hadoop计算平台,是一个通用的运行时框架,用户可以编写自己的极端框架,在该运行环境中运行。
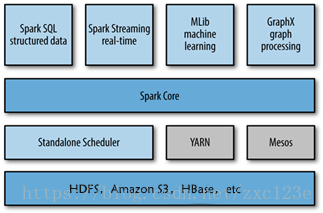
Spark
Spark(内存DAG计算模型)是一个Apche项目,被标榜为“快如闪电的集群计算”,它拥有一个繁荣的开源社区,并且是目前最活跃的Apache项目。最早Spark是UC Berkeley AMP Lab所开源的类Hadoop MapReduce的通用计算框架,Spark提供了一个更快、更通用的数据处理平台。和Hadoop相比,Spark平台可以让你的程序在内存中运行时速度提升100倍,或者在磁盘上运行时速度提升10倍。
:Spark具有如下4个主要特点:
①运行速度快;②容易使用;③通用性;④运行模式多样
①Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比MapReduce更灵活;
②Spark提供了内存计算,中间结果直接存放内存中,带来更高的迭代运算效率;
③Spark基于DAG的任务调度执行机制,要优于MapReduce的迭代执行机制。
3. 用图文描述你所理解的Spark运行架构,运行流程。