
Python简单爬虫第五蛋!
第五讲!
今天天气不错,又是到了爬虫繁殖的季节了,啊呸,什么繁殖,应该是进化,这一期我们使用re模块来匹配提取我们需要的信息。
先来简单介绍有下正则表达式。
正则表达式就是用来表达若干个字符串的一个表达式,假定一堆字符串有共同的特征,就比如是开头都是apple开头的,后面接的是五花八门的字符串,例如apple123、apple456等等,这么多有共同特征的字符串,我们是可以用一个正则表达式来代表这一大堆字符串。
举个栗子,假设有下面一段字符串需要我们把qq号提取出来,qq123456789qq123456788qq123456787qq123456786qq123456785qq123456784qq123456783qq123456782qq123456781qq123456780,这个时候我们应该怎么做比较快呢?
先不急,我们慢慢道来,先讲一下正则表达式的基础要点:
首先正则表达式是由字符和操作符组成的,字符自然是我们常见的字符了,而操作符就是有特殊含义的字符,如下表:
|
操作符 |
说明 |
栗子(例子) |
|
. |
表示任何单字符 |
A、b、c、d等等单字符 |
|
[ ] |
字符集,给出单字符取值范围 |
[abc]表示a、b、c单字符 |
|
[^ ] |
非字符集,给出单字符排除范围 |
[^ab]表示非a或非b的单字符 |
|
* |
前一个字符0或无限次重复 |
Apple* 表示Appl、Apple、Applee等 |
|
+ |
前一个字符1或无限次重复 |
Apple+ 表示Apple、Applee等 |
|
? |
前一个字符0或1次重复 |
Apple? 表示Appl、Apple |
|
| |
左右任意一个表达式 |
Apple|pair 表示Apple、pair |
|
操作符 |
说明 |
例子 |
|
{m} |
重复前一个字符m次 |
Ab{2}c表示Abbc |
|
{m,n} |
重复前一个字符m至n次(包含n) |
Ab{1,2}c表示Abc、Abcc |
|
^ |
匹配字符串开头 |
^abc表示abc且在一个字符串的开头 |
|
$ |
匹配字符串结尾 |
$abc表示abc且在一个字符串的结尾 |
|
( ) |
分组标记,内部只能用 | 操作符 |
(abc)表示abc (abc|def)表示abc、def |
|
\d |
数字,[0-9] |
|
|
\w |
单词字符,[A-Za-z0-9_] |
|
经典的正则表达式
|
^[A-Za-z]+$ |
由26个字母组成的字符串 |
|
^[A-Za-z0-9]+$ |
有26个字母和数字组成的字符串 |
|
^-?\d+$ |
整数形式的字符串 |
|
^[0-9]*[1-9][0-9]*$ |
正整数形式的字符串 |
|
[1-9]\d{5} |
中国境内邮政编码,6位 |
|
[\u4e00-\u9fa5] |
匹配中文字符 |
|
\d{3}-\d{8}|\d{4}-\d{7} |
国内电话号码,010-689131536 |
这些可谓是正则表达式中的精髓,一定要记牢了!
下面我们用python中的re模块来实现一下re模块的神奇功能。
我们看见上面给的qq号字符串中,特征是都是以qq为开头后面是9位数字的qq号码,那么我们可以写出一个表示正则表达式的字符串:r’[1-9]\d{8}’
然后创建一个正则表达式对象:
Regex = re.compile(r’[1-9]\d{8}’)
然后用正则表达式的findall()方法找到所有的qq号了。
下面是结果:
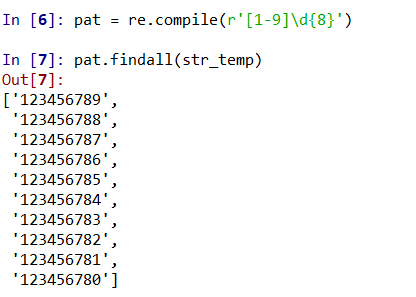
所以说,只要是找到出要匹配字符串的特征,写出正则表达式的字符串形式,然后创建一个正则表达式对象,就可以查找到我们需要的信息了,可谓是非常方便。
但是方便同时也会有麻烦假如要匹配的字符串没有那么好的规律性,那么正则表达式就难以表达出来,这也是一个很头疼的问题。
接下来只讲一个有用的方法,至于其他的方法,可以自己去找相关内容深入学习,这门教程只是讲述很简单的爬虫教程,所以常用的到方法会详细讲,少用或者不用的方法就略过了。
好,下面我们看re.finditer(pattern,string,flags=0)方法
第一个参数:正则表达式的字符串表示
第二个参数:待匹配的字符串
第三个参数:正则表达式使用的控制标记
该方法返回的是一个match对象的一个迭代器,而match对象就是包含我们匹配成功的字符串的一个对象。
看下面的例子:

用一个for循环来取迭代器的内容,这个迭代器就是re.finditer()方法返回的一个迭代对象,其中包含了匹配结果。
重要的是用了一个if判断语句,如果m是存在的,那么可以用group(0),来取出匹配的结果,其中m是一个match对象,该对象有一个group()方法,其中常用参数0,还有其他的参数使用方法,请自行查找相关资料学习。
今天讲到这里,只是一些基础的知识,但是基础决定与高楼大厦能建多高,还是要多多掌握好基础的内容,才能够跟得上下一讲,一个比较大的项目实战!
今天的代码:
1 import re 2 3 str_temp = ''' 4 qq123456789qq123456788qq123456787qq123456 5 786qq123456785qq123456784qq123456783qq1234 6 56782qq123456781qq123456780 7 ''' 8 9 pat = re.compile(r'qq\d{9}') 10 11 pat.findall(str_temp) 12 ''' 13 结果 14 ['qq123456789', 15 'qq123456788', 16 'qq123456787', 17 'qq123456786', 18 'qq123456785', 19 'qq123456784', 20 'qq123456783', 21 'qq123456782', 22 'qq123456781', 23 'qq123456780'] 24 ''' 25 26 pat = re.compile(r'[1-9]\d{8}') 27 28 pat.findall(str_temp) 29 ''' 30 结果 31 ['123456789', 32 '123456788', 33 '123456787', 34 '123456786', 35 '123456785', 36 '123456784', 37 '123456783', 38 '123456782', 39 '123456781', 40 '123456780'] 41 ''' 42 43 for m in re.finditer(r'[1-9]\d{8}',str_temp): 44 if m: 45 print(m.group(0)) 46 ''' 47 结果 48 123456789 49 123456788 50 123456787 51 123456786 52 123456785 53 123456784 54 123456783 55 123456782 56 123456781 57 123456780 58 '''

 浙公网安备 33010602011771号
浙公网安备 33010602011771号