
c++网络编程入门概念及api总结
Linux 系统编程
- Linux 系统编程
- Chapter 1 系统编程入门
- Chapter 2 Linux 多进程开发
- Chapter 3 Linux 多线程开发
- Chapter 4 Linux 网络编程
Chapter 1 系统编程入门
1.1 GCC
-
区别 GCC 与 G++
- gcc 既能编译 c,也能编译 c++。只不过 gcc 在链接的时候,不能自动链接 C++的库。在编译阶段,g++会调用 gcc,二者是等价的。
__cplusplus宏:g++编译 .c 文件时会定义,按照严谨的 cpp 语法去执行;gcc 编译 .cpp 文件时也会定义。gcc -lstdc++即可解决 gcc 链接不了 c++库的问题
-
-D选项,可以指定一个编译时后的宏,可以方便调试。比如调试版本和 release 版本,就不用删除 log 了
1.2 静态库与动态库
1.2.1 静态库
# 编译,得到目标文件
gcc -c tes1.c tes2.c
# 打包成静态库: -r插入 -c -s起名
ar -rcs libxxx.a tes1.o tes2.o
# 使用:指定库名、库位置、头文件
gcc -o demo tes1.o tes2.o -l xxx -L ./lib -I ./include
-
优点:
- 加载速度快,因为打包到程序里面了
- 发布无需额外提供库,方便移植
-
缺点:
-
消耗资源,每个程序使用库,都要加载到内存。如果多个程序使用同一个库,那就太浪费了
-
更新发布麻烦,你把库发给别人,别人还要再编译一遍
-
1.2.2 动态库
# 编译得 与位置无关 的目标文件
gcc -fpic -c tes1.c tes2.c
# 编译成共享库
gcc -shared -o libxxx.so tes1.o tes2.o
# 使用共享库,指定:指定库名、库位置、头文件
# !!还要确保能找到库的绝对路径
可以使用ldd命令来查看可执行文件所依赖的动态库,找不到的会提示"not found"。
程序执行时,加载动态库的过程是由动态加载器ld-linux.so来完成的。他会依次寻找 elf 文件的 DT-RPATH 段(进程内存空间,改不了不用管)--->环境变量 LD_DIRECTORY_PATH--->/etc/ld.so.cache--->/lib /usr/lib,找不到就报错。因此可以有以下方式指定路径:
#(1)更改环境变量
export LD_DIRECTORY_PATH=$LD_DIRECTORY_PATH:{your_lib_directory}
# 当然也可以修改 ~/.bashrc 或 /etc/profile
#(2)更改 /etc/ld.so.cache,但这是一个二进制文件,要更改它的config文件
sudo echo {your_lib_directory} > /etc/ld.so.conf
#(3)添加到 /lib /usr/lib 【不推荐】
- 优点
- 可以实现进程间资源共享(共享库)
- 更新部署发布简单,用户不需要重新编译
- 可以控制何时加载动态库,使用到的时候才进入内存
- 缺点
- 加载速度比静态库稍慢
- 发布程序时需要提供依赖的动态库
1.3 makefile
- make 默认执行的是第一条规则,其他的都是为第一条服务的
- 模式匹配中,多个百分号表示的是同一串字符
.PHONY,伪目标,那么就不会与外面的同名文件,如 clean 比较
1.4 GDB
GDB 的功能,一般来说有:
|
|
 |
core-file core:查看core文件【通过ulimit -a查看,再设置 core 文件大小,编译时-g即可生成 core 文件】
-g只是把源文件的信息加入可执行程序中,并不是嵌入了源程序。因此调试时还需要能找到源程序
命令:
set args arg_1 arg_2:给程序设置参数
show args:显示参数
list 文件名 : 行号/函数名:显示某文件,改函数或行号,附近的代码l
break 文件名 : 行号/函数名:在该处设置断点b
info break:查看断点i
delete/disable/enable 断点编号:查看/删除/无效/生效断点d/del/dis/ena
break [pos] if [condition] :条件断点
start/run:开始,到第一行停下/开始,到断点停下start/r
continue:执行到下一个断点c
next:执行到下一行代码(不进入函数体)n
step:向下单步调式(有函数就进入函数)s
finish:跳出函数体(函数里面不能有断点)
util :跳出循环(循环内不能有可用的断点,且要停在循环的第一行/最后一行)
print/ptype 变量名:打印变量值/打印变量类型
display + 变量名:自动打印指定变量的值
undisplay + 编号 :取消打印对应变量
info display:查看显示信息i
set var 变量名 = 变量值:更改变量的值
set disassemble-nextline on:设置自动输出下一行代码的汇编
1.5 文件 IO
1.5.1 标准 C 库与系统 IO
C 库的 IO 函数是可以跨平台的。跨平台,要么是像 java 那样不同平台开发不同的虚拟机,要么是调用不同平台的系统 API,从而统一接口。
标准 C 库带有缓冲区,因此效率是更高的
C 库函数的 man 手册等级是 3,可以man 3 fwrite
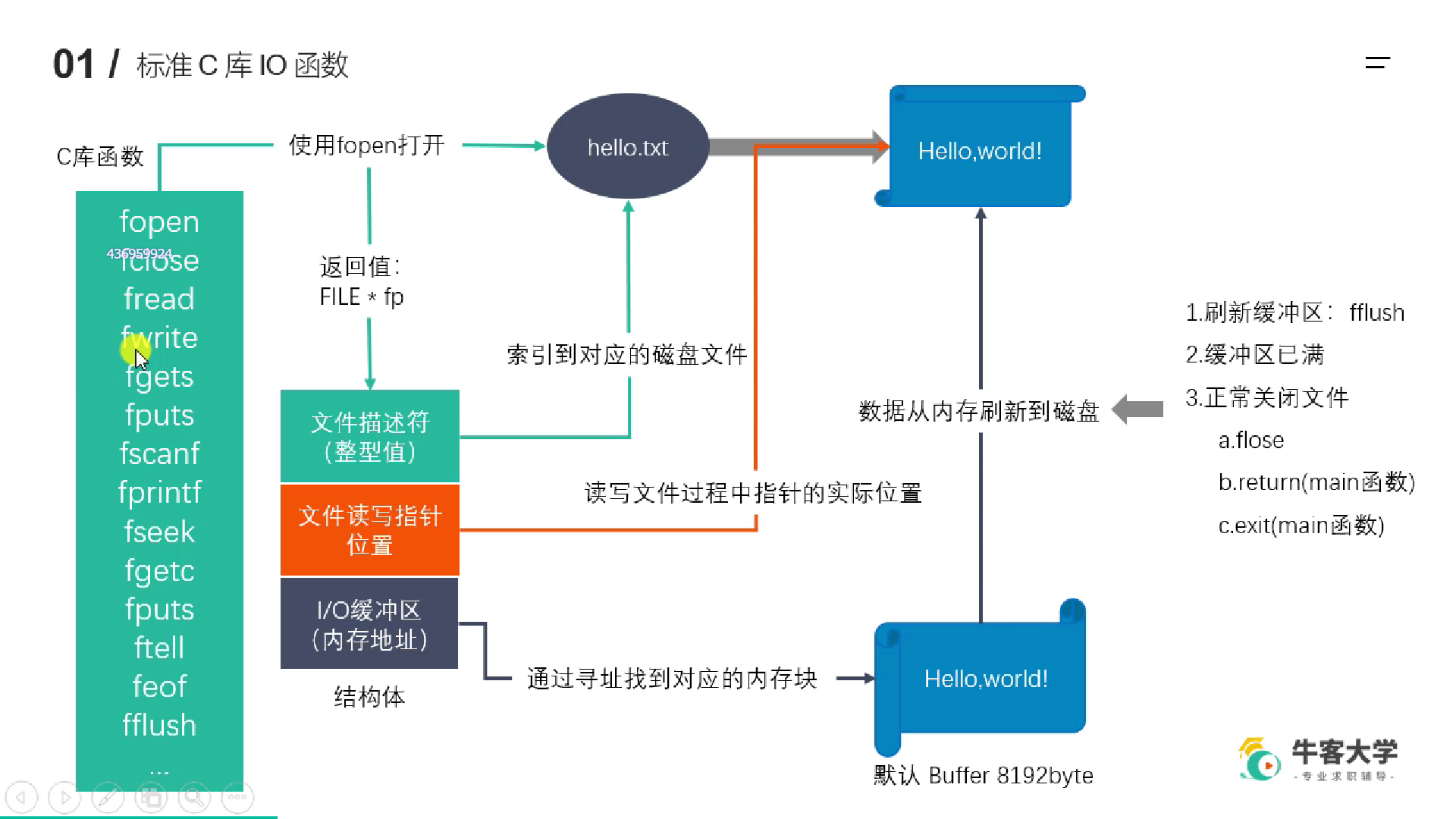
UNIX 系统 IO
C 库有缓冲区,可以提高读写效率,但注意,是效率,而不是速度。在网络通信情境中,我们希望能迅速收到对方发来的消息,那么此时应该使用系统 IO,即时读写。总不能我发来的信息,等半天了你还在缓冲区里呢
1.5.2 虚存与文件描述符
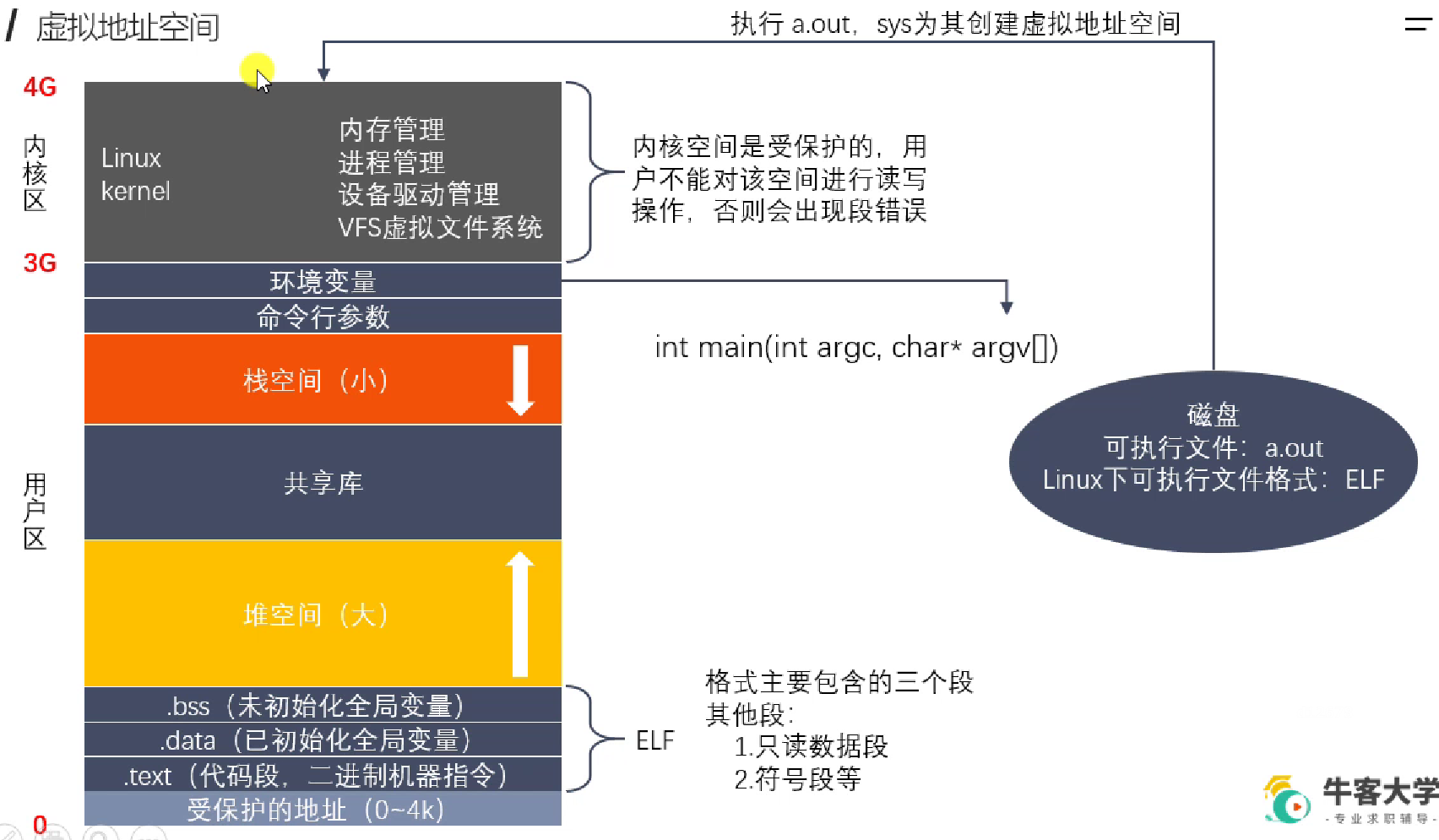
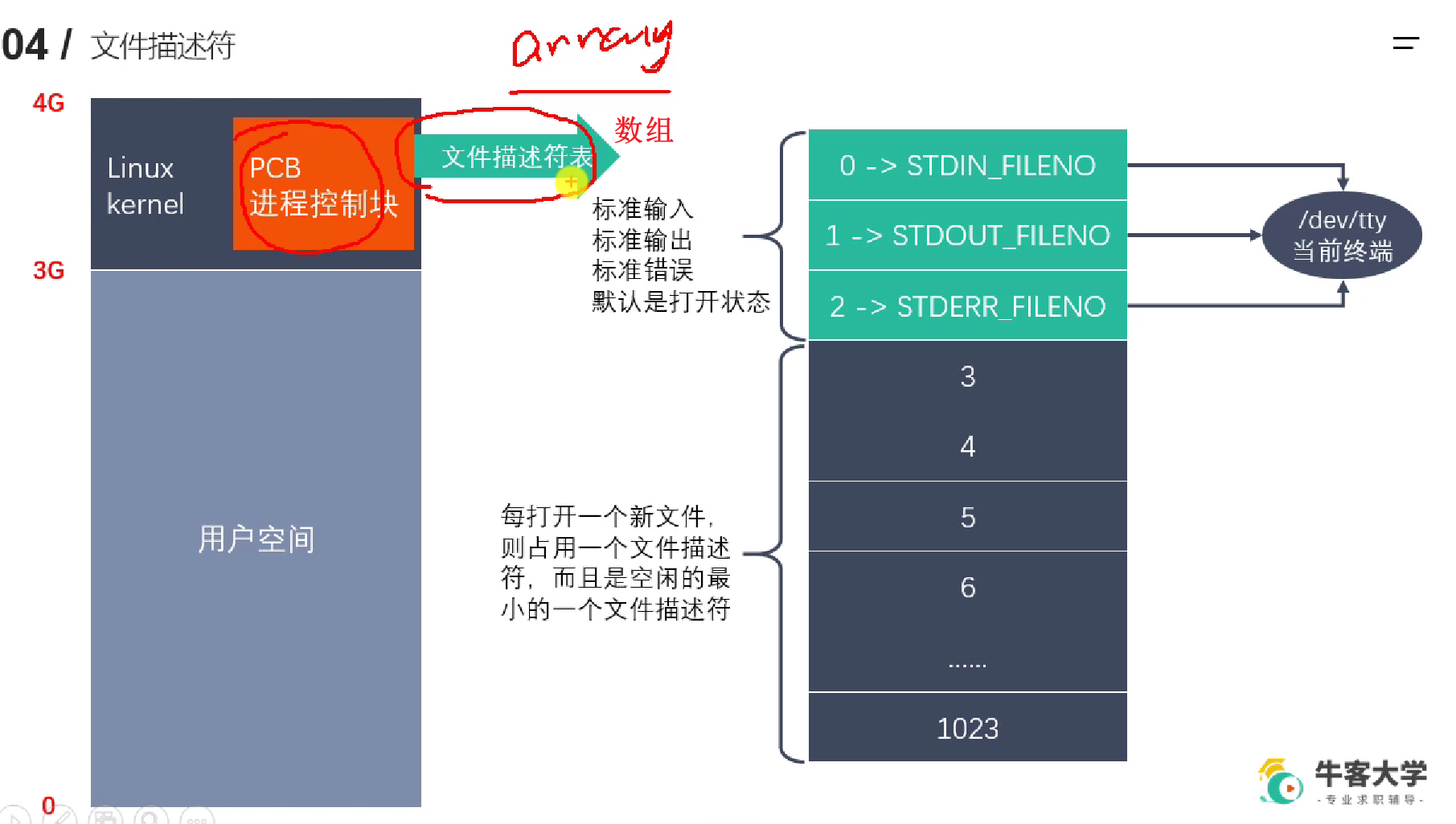
一个应用程序可以打开很多文件,因此需要一个数组,来存储其打开的文件描述符
所谓一切皆文件,0 1 2 是默认打开的,对应的就是当前终端,终端也是一个“文件”。
同一文件可以被打开多次,相互之间的文件描述符是不相同的,比如不同用途,一个只读,一个只写。文件释放掉时文件描述符才会释放。分配文件描述符时,就从尚未分配的数子中选择一个最小的。
1.5.3 Linux 系统 IO 函数
 系统 IO 在 man(2),标准 C 库在 man(3)。因此这里就不具体列举了,直接
系统 IO 在 man(2),标准 C 库在 man(3)。因此这里就不具体列举了,直接man 2
open
int open(const char *pathname, int flags, mode_t mode);
- 注意,这里不是重载(C++才重载),这里用到的是 可变参数
- open 函数失败返回 -1,然后,系统会恰当地设置一个“错误号”来标识此次错误的类型即
errno flags的几个可选项之间,采用的是 按位或 | ,其实就是给 flags(32 位)不同位上加个 1mode_t参数指定文件的权限,最终的权限 =mode & ~umaskumask作用就是抹去一些权限,保证你不会给错。- 在当前终端直接 umask 即即可输出,也可用函数
mode_t umask(mode_t mode)
errno:错误号,属于 Linux 系统函数库(而非属于函数),是全局变量,记录最近的错误号。
void perror(const char *s):打印 errno 对应的错误描述,其中参数 s 是用户描述,输出的样子是 用户描述(s) : errno 对应的错误
read & write
- 返回值为 0,是判断读到文件读完的标志
while((len = read(fd_read, buffer, sizeof(buffer))) > 0) - 对同一文件连续读写操作的时候,一定要注意,文件指针的位置
lseek
off_t lseek(int fd, off_t offset, int whence);
作用:把文件指针移动到whence + offset的位置
返回值:成功返回文件指针相对于文件开始的偏移量,失败返回 -1
- 对于参数 whence,有三个取值:
SEEK_SET:设置文件指针的偏移量为 offsetSEEK_CUT:设置文件指针的偏移量为 当前位置 + offsetSEEK_END:设置文件指针的偏移量为 文件大小 + offset
- lseek 一般有下面几个
- 移动文件指针到文件头,反复的读。不然就要关闭,再重新打开
lseek(fd, 0, SEEK_SET) - 获取当前文件指针的位置
lseek(fd, 0, SEEK_CUR) - 获取文件的大小
lseek(fd, 0, SEEK_END) - 拓展文件长度(比如在下载文件时,下载器是先占用这么大,再慢慢往里写数据)
lseek(fd, enlarge_size, SEEK_END),要写入一定内容才会真正拓展
- 移动文件指针到文件头,反复的读。不然就要关闭,再重新打开
stat & lstat
- 命令行:
stat [filename],用以查看文件的信息 int stat(const char *pathname, struct stat *statbuf);int lstat(const char *pathname, struct stat *statbuf);(当文件是软链接时,获取链接本身的信息)
struct stat {
dev_t st_dev; /* ID of device containing file */
ino_t st_ino; /* Inode number */
mode_t st_mode; /* File type and mode */
nlink_t st_nlink; /* Number of hard links */
uid_t st_uid; /* User ID of owner */
gid_t st_gid; /* Group ID of owner */
dev_t st_rdev; /* Device ID (if special file) */
off_t st_size; /* Total size, in bytes */
blksize_t st_blksize; /* Block size for filesystem I/O */
blkcnt_t st_blocks; /* Number of 512B blocks allocated */
};
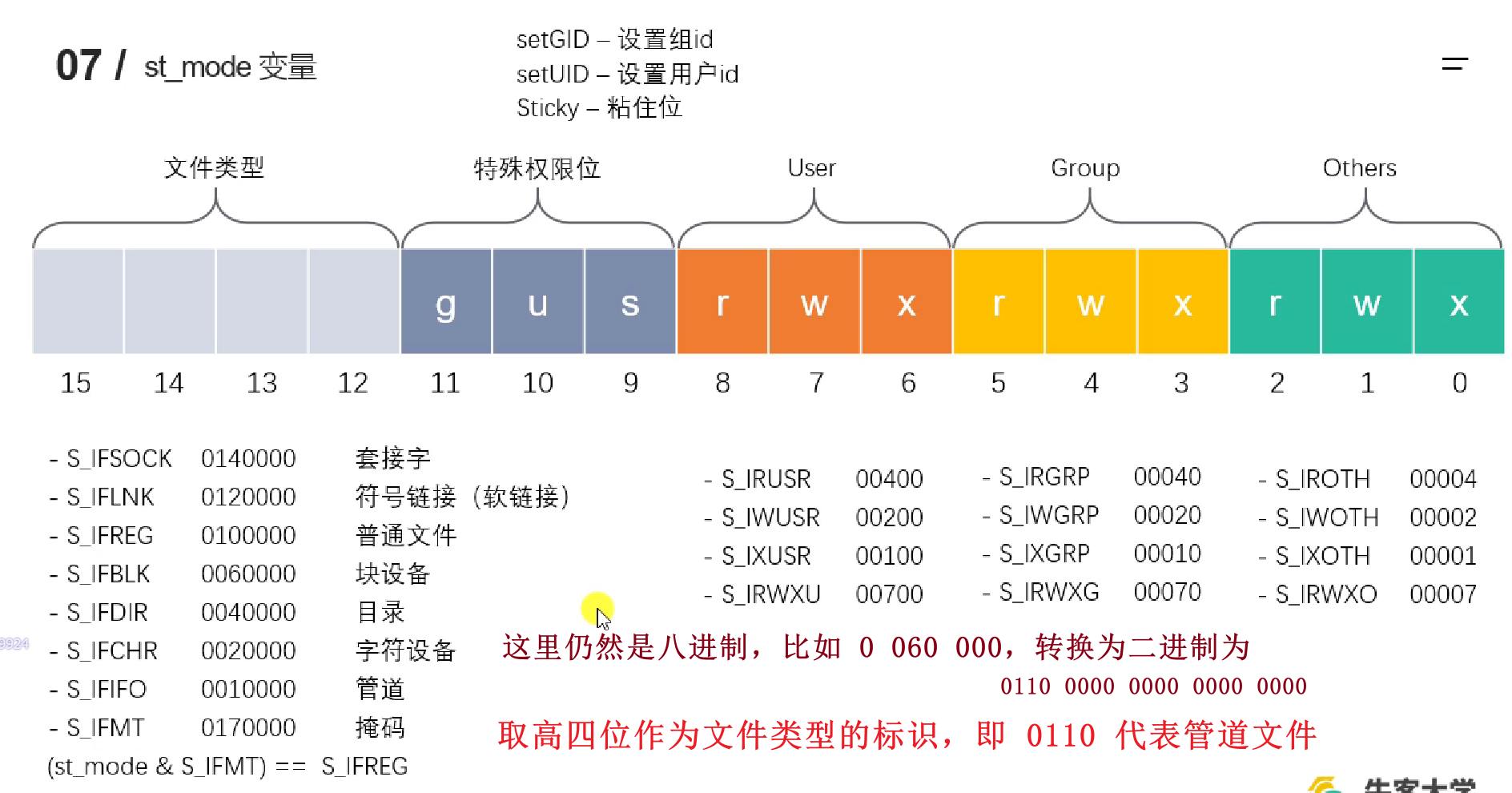
判断各区段的值,只需要按位与,即st.st_mode & S_FLAGS,得到的结果与各种宏进行比较即可。也正因如此,这些 FLAGS 的值看起来才这么“长”,因为它们都是 16 位的,直接与整个 st_mode 相与的,其余无关的位都置 0,起到一个过滤的作用。
文件属性 access...
access & chmod & truncate
-
int access("const char *pathname", int mode)mode:F_OK判断文件是否存在,R_OK, W_OK, X_OK判断文件的读/写/执行/权限
-
int chmod(const char *pathname, mode_t mode);- 系统中的用户和组,分别在文件
/etc/passwd和/etc/group。也可以是用id + username命令
- 系统中的用户和组,分别在文件
-
int truncate(const char *pathname, off_t length)- 缩减/扩张文件到指定大小
目录操作 mkdir...
mkdir & rmdir & rename & chdir & getcwd
int mkdir(const char *pathname, mode_t mode);
int rmdir(const char *pathname);
int rename(const char *oldpath, const char *newpath);
int chdir(const char *path);
char *getcwd(char *buf, size_t size);
对应 shell 的命令:mkdir、rmdir、mv、cd、pwd。查手册时要注意使用 man 2 makdir,否则默认打开的是第一章的 mkdir 命令
chdir:修改进程的工作目录(默认是在当前工作路径,即,在哪个目录启动程序,进程默认路径就在哪,而不是程序所在的文件夹!)
getcwd:返回值其实就是传递进去的 buffer 的地址
目录遍历 readdir...
man (3)
DIR *opendir(const char *dirname);
struct dirent *readdir(DIR *dirp);
int closedir(DIR *dirp);
-
DIR *opendir(const char *dirname);:- DIR : 目录流结构体(不对用户开放,也用不到,只有指定参数类型时用)
- 错误返回 NULL
-
struct dirent *readdir(DIR *dirp);- 会自动指向流中,下一个目录的位置【这里疑惑:man 中说返回值是,下一个目录的结构体指针?】
- 返回读取到的目录信息(即 dirent 结构体指针)。错误或到结尾返回 NULL。可以通过
errno来区分究竟是文件尾还是错误 -

-
int closedir(DIR *dirp);
dup & dup2
int dup(int oldfd);
- 选择一个最小的未被使用的文件描述符,来指向 oldfd 指向的文件,即复制出来了一个文件描述符
int dup2(int oldfd, int newfd);
-
用指定的 newfd 来指向 oldfd 指向的文件。如果 newfd 指向的有文件,则先执行 close 操作。这里 oldfd 必须是一个有效值,否则 newfd 没有意义。如果二者相同,则等于什么都没做。返回值就是 newfd
-
可以用
dup2来进行输入输出重定向,比如默认的输出是标准输出(fd1=STDOUT_FILENO),现在想让它输出到文件中(fd2=12),那么,就可以dup2(fd2, STDOUT_FILENO);
注意!重定向,是被更改的那一方作为 newfd,比如想重定向标准输出,则标准输出因该作为 newfd。因为 dup2 的作用是,关闭newfd指向的文件,并让其指向oldfd
fcntl
int fcntl(int fd, int cmd, ... /*args*/);
参数cmd:命令,其实就是函数定义的一些宏,作用有五个:(列出了常用的两个)
-
复制文件描述符:
F_DUPFD,返回一个新的文件描述符 -
设置/获取文件状态:
F_GETFL,获取文件描述符对应的状态,即open函数中的flag
F_SETFL,设置文件的状态 flag- 注意,3 个必选项不可以修改(只读、只写、读写,以及一些创建文件的选项等)
- 可以修改的 flags 有
O_APPEND、O_NONBLOCK(设置成非阻塞) . . .
阻塞/非阻塞:描述的函数调用的行为,函数对当前进程的影响。如,可籍此将管道文件设置为非阻塞
int fd = open("xxx");
// 首先要获取当前文件的FLAG
int flag = fcntl(fd, F_GETFL); // 失败返回-1,成功返回flag
// 然后,修改的时候,注意不是直接替换
flag |= O_APPEND; // 添加
flag &= ~O_APPEND; // 删除
int ret = fcntl(fd, F_SETFL, flag); // 失败返回-1,成功返回0
Chapter 2 Linux 多进程开发
2.1 进程概述
2.1.1 区别程序 & 进程


- 多道程序、时间片、并发&并行
2.1.2 进程控制块(PCB)
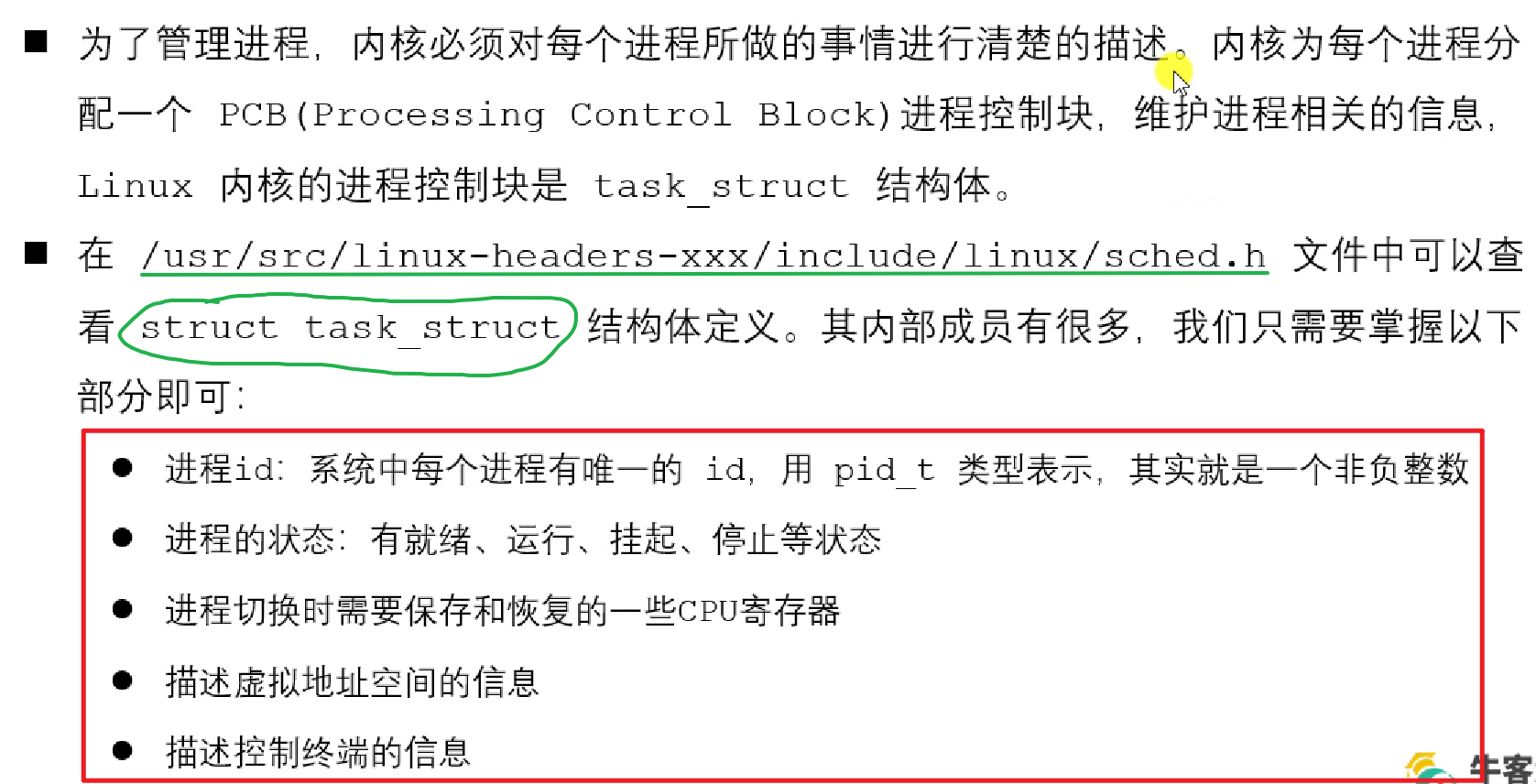

2.1.3 进程状态

其实内核实现是不区分就绪态和运行态的。你占有 cpu 就是运行态,不占有就是就绪态
新建态:新建后进入就绪列表
终止态:可能是运行结束,也可能是被高权限者终结。终结后,进程不再继续执行,但仍然会留在操作系统中等待善后。等其他进程完成了对终止进程信息抽取后,操作系统才会将其从系统中删除。
2.1.4 进程相关命令
 |
 |
 |
 |
{cmd} &:在命令后面加上一个&可以让其在后台运行(会定时将结果输出到前台来,但不影响输入输出)
2.1.5 进程号和相关函数

2.2 进程操作
2.2.1 进程创建 fork()
-
pid_t fork(void):复制当前进程,但是运行在不同内存空间(仔细查看 fork(2)手册中的 DESCRIPTION)-
创建成功,函数会返回两次:父进程中返回子进程 pid,子进程中返回 0
-
创建失败:父进程中返回-1,并设置 errno:
-
EAGAIN:当前系统进程数达到上限 -
ENOMEM:当前系统内存不足
-
-
-
如何区分父子进程?:利用 fork()函数的返回值。返回值为 0 说明是子进程,否则说明是父进程。由于父子进程是共享代码段的,因此通过添加一个 if-else 判断,来实现,两个进程执行相同代码,在某些地方又执行不同代码的效果。
-
理解子进程创建:
- 我们说,子进程“拷贝”一份父进程的虚拟地址空间(内核区也会拷贝)。但其实这么想会好些:子进程复制父进程的数据空间(数据段)、栈、堆;共享父进程的正文段,也即二者执行相同的代码,只是开始位置有些不同,但并非是,你有一段代码,我有另一段。原因往下看。
- 子进程共享父进程的代码,是从 fork()后开始执行的
- 注意,是直接复制了一份内存空间,因此里面的什么变量啊的都是两份,改动互不影响
-
实际上,复制的实现,是通过“写时拷贝”(copy-on-write)来实现的,即,fork 后并不会真的直接复制一段内存,而是通过“只读共享”的方式,让父、子进程共用一段内存。只有在需要写入数据的时候,才真正进行拷贝,使得二者拥有独自的空间。
-
父子进程共享文件,共用相同的文件描述符、相同的文件偏移指针,引用计数增加
-
父子进程区别:
- fork()函数返回值不同
- PCB 中一些数据不一样,比如当前进程 pid、父进程 ppid(就是说,内核区也不是完全相同的)
- 信号集不同
-
父子进程共同点
- 子进程刚被 fork 出来时,和父进程的:用户区数据、文件描述符表都是一样的
2.2.2 GDB 多进程调试
- GDB 默认只能跟踪一个进程,可以在 fork 函数调用之前,设置其跟踪的是子进程还是父进程(默认父进程)
set follow-fork-mode [ parent | child ] - 跟踪一个进程了,那另一个呢?另一个可以选择脱离 GDB 调试(直接运行到结束),也可以选择被 GDB 挂起。(detach:脱离)
set detach-on-fork [ on | off ] - 查看调试的进程:
info inferiors - 切换当前调试的进程:
inferior id - 使进程脱离 GDB 的调试:
detach inferiors id
2.3 exec 函数族
函数族:一系列具有相同/相似功能的函数(C 语言中没有重载)
2.3.1 exec 函数族功能:
- 能够在当前进程中,调用一个别的可执行程序。调用成功后,本进程的代码段、数据段、堆栈等所有信息都会被替换掉,相当于完全变成了另一个进程。此时调用函数也就不存在了,自然也就不会有返回值。只有失败了才会返回-1,从源程序调用点接着往下执行。
- 但一般情况下,调用程序都是有别的任务的,你这么直接替换了怎么能行。因此,常用的做法是,先
fork()一个子进程,然后再子进程中调用 exec 函数族,来,一下子,把子进程变成一个实现别的功能的新进程,而不只是原进程的拷贝了 - 具体实现过程为:用指定程序,去把调用程序虚拟地址空间中的用户区替换掉,内核区保持不变。即,什么进程 id、父进程 id、当前工作目录这些内核区的框架不变,但是实际执行的内容却改变了。金蝉脱壳
2.3.2 exec 函数族介绍
总览

其中只有最后一个
execve()函数是 UNIX 的,别的都属于标准 C 库函数,是对 execve()的封装
函数名其实就指明了函数的参数的传递方式
execl()
int execl(const char *path, const char *args1, ...);
-
path:要调用的文件路径。推荐使用绝对路径 -
args:参数列表,直接传入多个,其中第一个参数约定为文件名,并且最后以NULL结尾(哨兵)
例如:int ret_flag = execl("/usr/bin/ls", "ls", "-h", "-al", "/home/usr", NULL)。即 ls -alh ~
-
注意到,shell 命令也是可以执行的,它也不过是个可执行程序嘛。这个
-,在命令既有参数又有文件名等时,不加是不行的。 -
注意有可能会产生孤儿进程
-
被 execl 族函数替换后,整个进程都变了,包括代码段等等。因此,原进程中 execl 函数后的代码将不会被执行!
execlp()
int execlp(const char *file, const char *args1, ...)
file:调用文件的文件名args:仍然是参数列表
2.4 进程控制
2.4.1 进程退出
void exit(int status):标准 C 库的退出,在 stdlib.h 中
void _exit(int status):系统调用,在 unisd.h 中
-
status是退出时状态,父进程在回收子进程资源时能够获取到 -
区别在于,调用
exit()时,会先调用退出处理函数、刷新 IO 缓冲、关闭文件描述符等工作,然后再调用系统调用_exit()退出进程。 -
举个例子,
printf("hello\nworld");然后调用exit(0),这是是能输出 hello\nworld 的。但是如果调用的是_exit(),那就只会输出一个 hello。因为 C 库的 IO 是带有缓冲区的,\n 会刷新缓冲,因此 hello 一定能输出。但是调用_exit(),此时 world 尚在缓冲区里,但进程直接就退出了,没有输出 -
exit()会把 status 返回给父进程,就跟 main 的 return 一样,main 是被系统调用的,return 也是把状态返回给上一级。但只是对 main 而言,这两个一样的。
-
区分 exit 与 return,只需要品味他们的名字即可。exit 是进程退出,而 return 是返回,在 main 函数中调用别的函数,func,func 和 main 都是在同一个进程中。这时 return 是返回,也即堆栈弹栈,是返回到调用者 main,main 还在;而 exit 是终结进程,main 也没了。
2.4.2 孤儿进程
孤儿进程:父进程运行结束,但是子进程还在运行,那么它就是孤儿进程
-
每当出现孤儿进程,操作系统就会把它的父进程设置为
init(pid = 1),init 会循环 wait()它已经退出的子进程,并最终回收其资源,做善后工作。因此孤儿进程并不会有什么危害 -
显然,对孤儿进程,其 ppid = 1
2.4.3 僵尸进程
僵尸进程:每个进程结束后,内核都会释放掉该进程的所有资源、打开的文件、占用的内存等。但是仍为其保留一定的资源,主要是保留 PCB 信息(包括进程号、退出状态、运行时间等),需要父进程去释放。因此,子进程终止,且父进程还没来得及回收时,这时子进程残留资源(PCB)存放于内核中,即变成僵尸进程。
- 僵尸进程是不能被
kill -9杀死的 - 系统进程号数量是有上限的。如果产生大量僵尸进程,一直占用着 pid,那么就有可能导致操作系统无法产生新的进程,因此需要去避免。
- 僵尸进程是有父进程的。如果 kill 父进程,那么僵尸进程就会被 init 函数托管,并释放
- 但是一般是不会直接 kill 父进程的,而是在其中调用 wait()或 waitpid()来处理僵尸进程
- 父进程可以通过调用
wait()或waitpid(),来获取其退出状态的同时,杀死该进程
2.4.4 wait & waitpid
-
wait 类函数,用于等待一个进程,直至其状态发生改变(终止、挂起、kill),然后获取它的信息。
-
对于进程终止(terminiate)的情况,调用 wait 可以让系统能够回收其资源,而不是让其变成僵尸进程。
-
如果状态已经改变,则函数立即返回,否则调用 wait 的进程会被挂起,直到其等待的进程收到了一个不可被忽视的信号。
-
区别在于,wait 会被阻塞,waitpid 可以设置不被阻塞,还可以指定等待哪个子进程结束。阻塞即,父进程 wait 不到时,就会停下手头的工作,去一直 wait 子进程,直至其结束。
-
一次 wait 函数只能清理一个子进程,清理多个应使用循环。
pid_t wait(int *wstatus);
-
wstatus:一个 int 类型地址,是传出参数,用于获取返回值。返回值还要传入一些宏中,即可获得一些有用的状态:Wait-IF-EXIT-EnD,Wait-EXITSTATUS,Wait-IF-SIGNAL-EnD,Wait-TERM-SIGnal......
pid_t waitpid(pid_t pid, int *wstatus, int options);
pidpid > 0:即表示等待 pid 对应的子进程pid =0:回收当前进程组的所有子进程,即当前调用者的进程组pid = -1:回收所有的子进程,即使你跑到了别的组(最常用)pid < -1:等待任意一个,gpid 等于参数绝对值的,组内的,任一子进程
options:设定阻塞/非阻塞0:阻塞WNOHANG:非阻塞,立即返回
- 返回值
> 0:返回子进程 pid= 0:(只有非阻塞情况下才会返回 0,即options = WNOHANG)表示还有子进程活着= -1:错误或者没有子进程了
2.5 进程间通信
2.5.1 基本概念

子进程“复制”了父进程的东西,但是那叫“读时共享、写时拷贝”,写的时候,是两个相互独立的区域。在逻辑上,二者是隔离的。只不过是实现上,有一段共享的时候。
进程是独立的,但不是孤立的
2.5.2 进程间通信方式
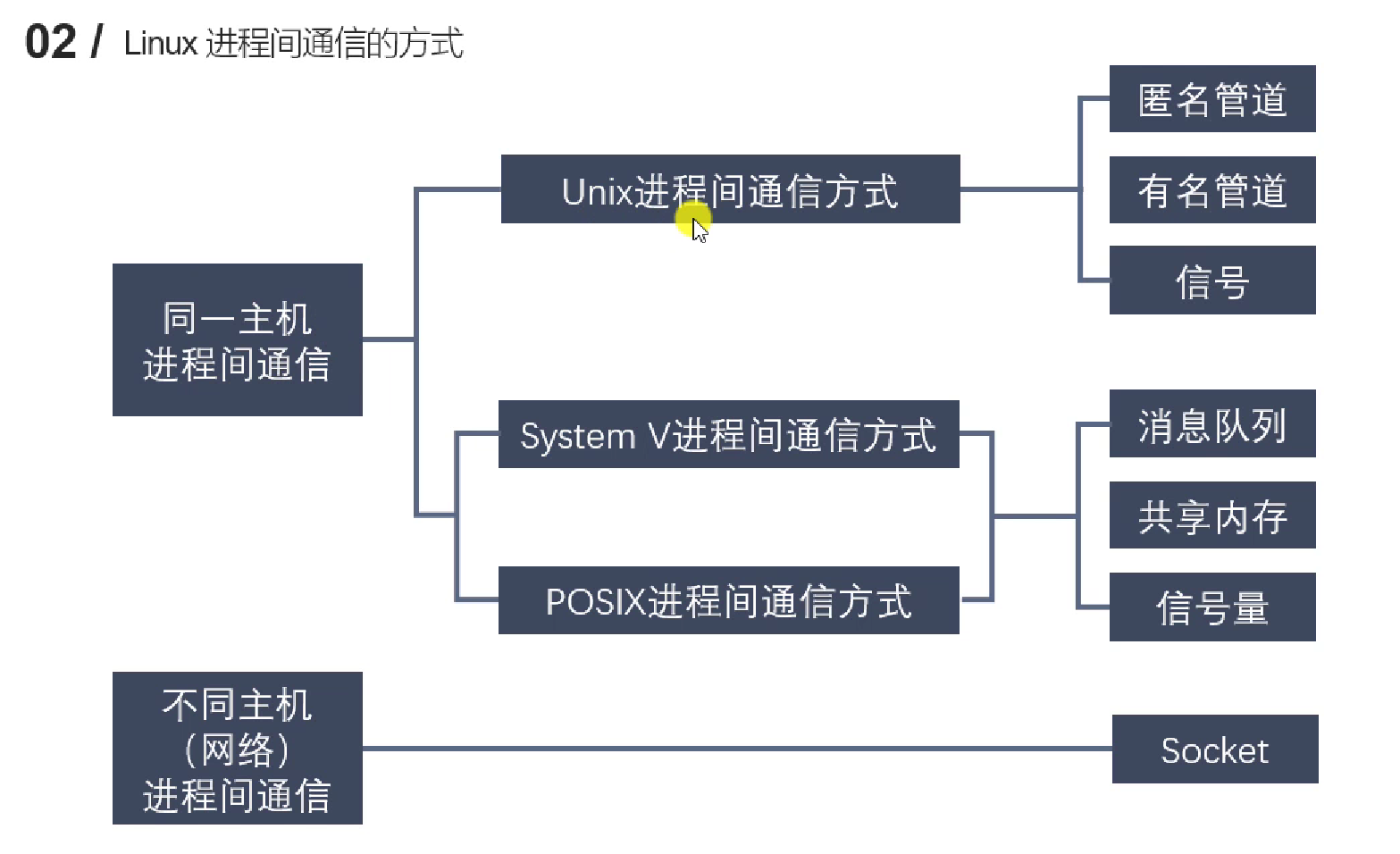
2.5.3 匿名管道(管道)
匿名管道概述
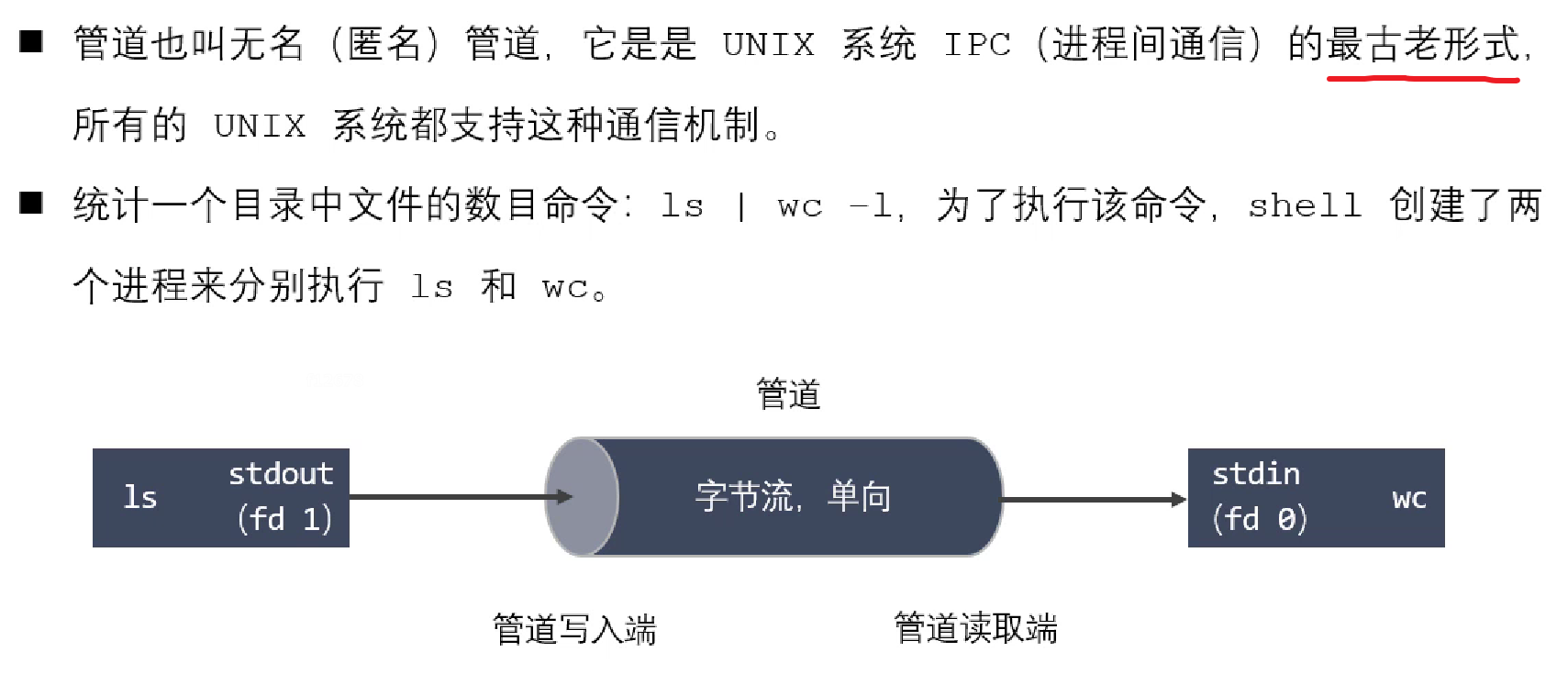
管道的特点

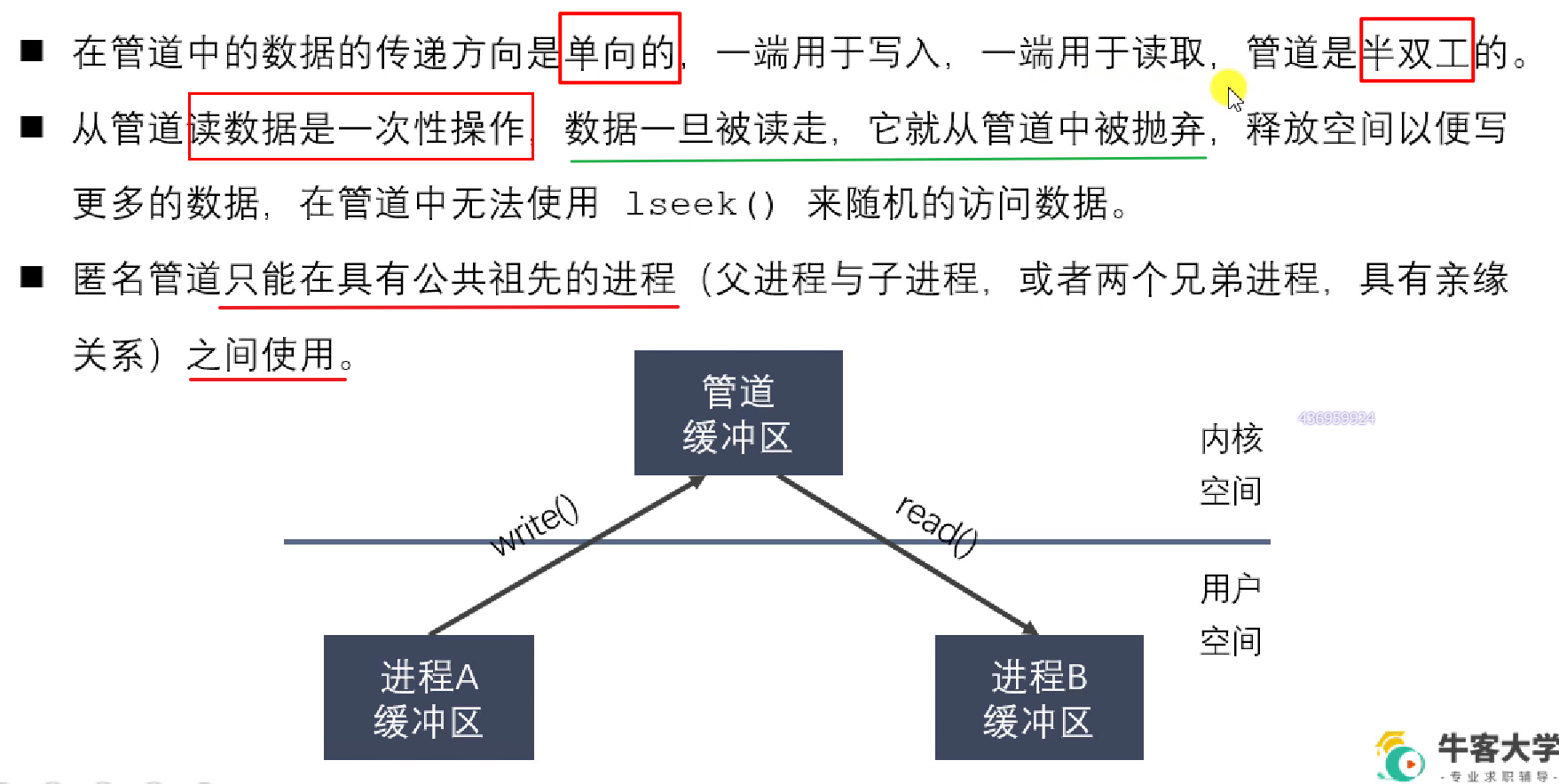
亲缘关系的进程能够共享管道的原因:
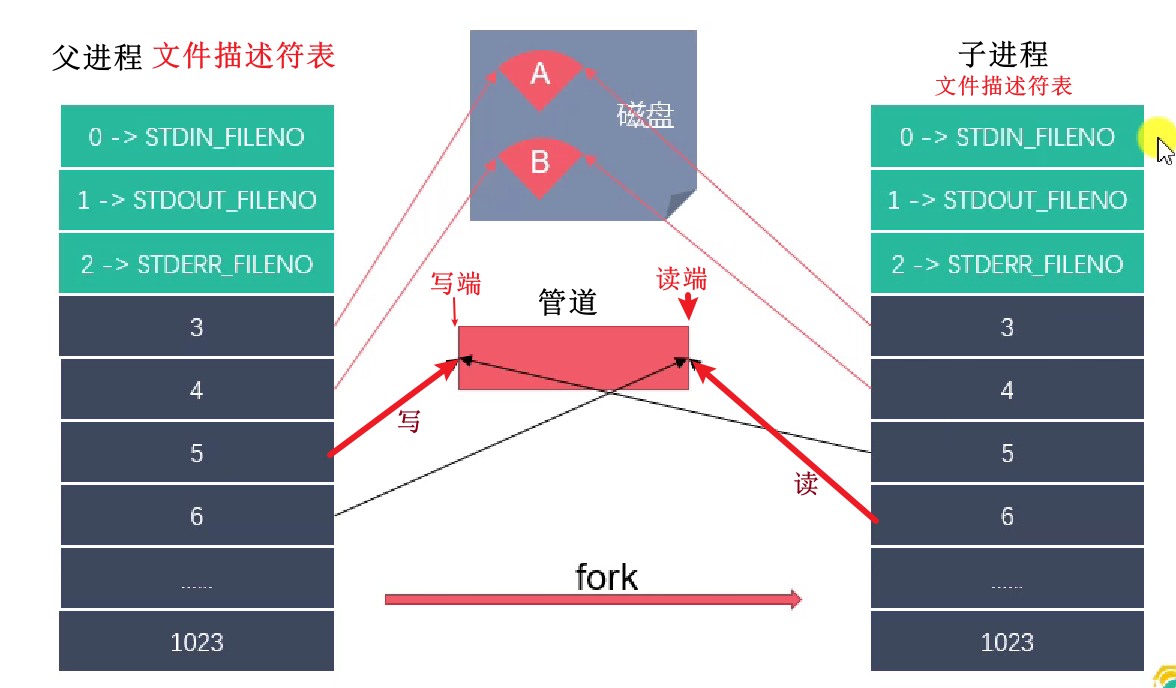
父子进程共享文件描述符表,管道具有文件的性质,因此可以操作同一个管道
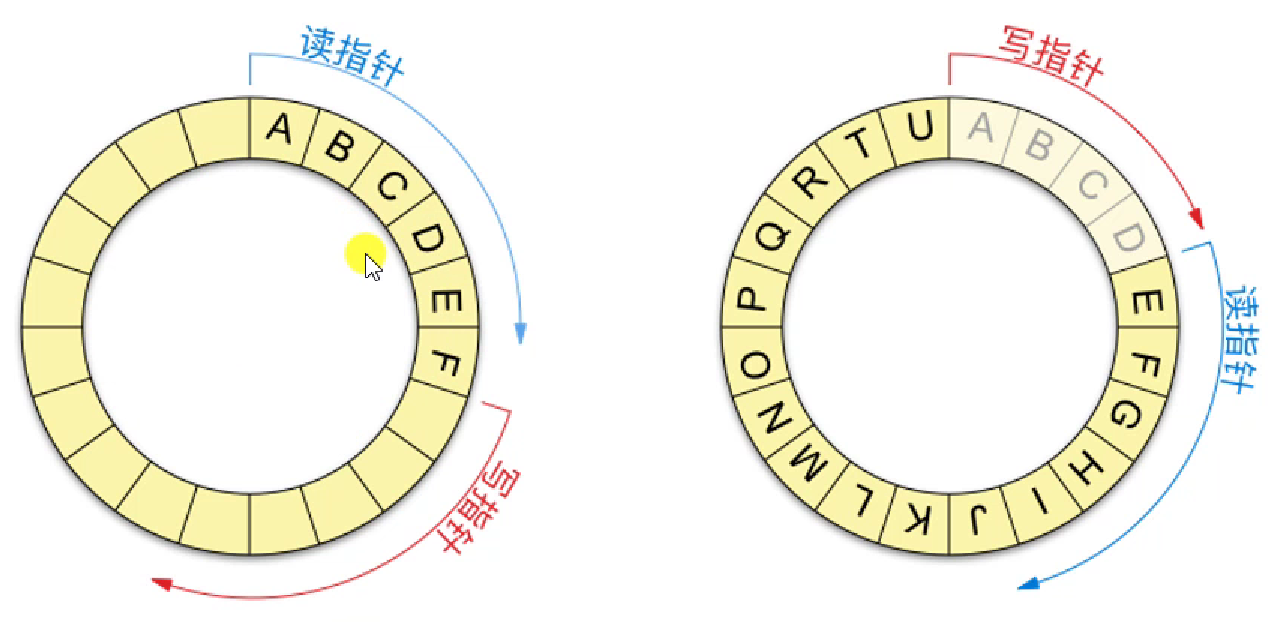
管道的数据结构
环形队列。因为使用普通队列的话,写过的地方就不好再用了,采用环形队列可以节省内存空间。
 |
 |
匿名管道创建
int pipe(int pipefd[2]);
参数:一个 int 数组,是传出参数。pipefd[0]对应管道的读端(输出),pipefd[1]对应管道的写端(输入)
返回值:成功返回 0,失败返回-1
- 注意,要在 fork 之前创建 pipe!
- 管道默认是阻塞的,如果空了,则 read 阻塞,如果满了,则 write 阻塞
- 管道是有大小的,如果传递的数据超过管道大小会被忽略。(可以循环写)
- 循环读取管道后,可以把读出的值清空(memset)。否则,最后一次读出的值可能并不能填满 buff,那么输出的结果后面就会有一些不该出现的值
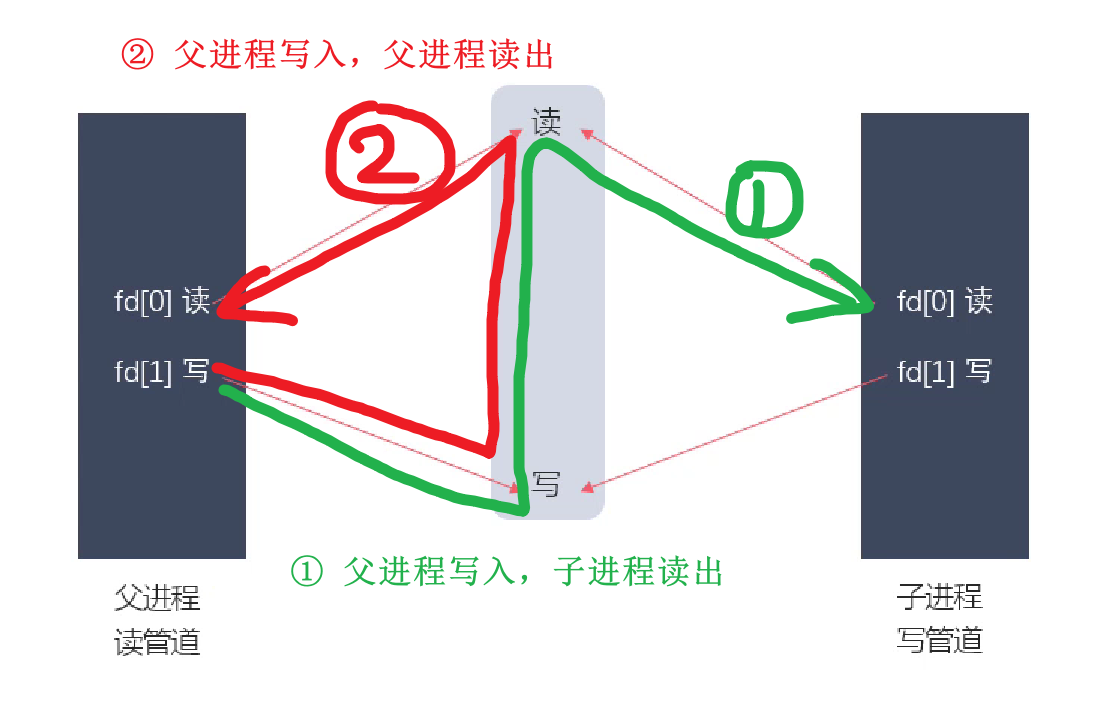
- 如果用匿名管道进行交互通信,则有可能产生一些问题:期待是父进程写,子进程读。但完全有可能产生进程读出自己写的内容的情况!因此,使用匿名管道时,一般只做,一方就是读的并且 close 写端,另一方就是写的并且关闭读端。
插播一些有用的函数
long fpathconf(int fd, int name);:用于获取文件的一些信息,比如最大链接数、最长名字、最大管道尺寸等等,通过 name 传递一个宏值来指定功能。如_PC_LINNK_MAX, _PC_PAYH_MAX, _PC_PIPE_BUF等等等void bzero(void *s, size_t n);:将 s 指针指向位置开头的 n 字节用\0填充(可能会受,头文件是 string.h 还是 strings.h 的影响)void *memset(void *s, int c, size_t n);:将 s 指针指向位置开头的 n 字节用常字符(int)c填充,并返回一个指向 s 区域的指针void *memcpy(void *dest, const void *src, size_t n);:内存拷贝(利用内存映射来拷贝文件时可以用)
管道读写特点总结
都是在阻塞 IO 的情况下讨论:
- 写端全部关闭(fd[1]的引用计数 = 0),如果管道中的数据被读取完了,那么再次读取,read()会
返回0,相当于读到了文件末尾 - 写端没有全部关闭(fd[1]的引用计数 > 0),如果管道中的数据读完了,且没有再往里写,那么再次读取,read()会
被阻塞。(如果设置了非阻塞,那么 read 将会返回-1) - 同理,读端都关闭了,此时再往里面写,则该进程会收到一个信号
SIGPIPE,通常会导致管道异常终止 - 读端没有全部关闭,此时往里写,写满的时候,write()会
被阻塞
那么,管道也是一个文件,因此自然也可以设置管道文件的文件描述符的属性 ==> fcntl(),将其设为非阻塞
2.5.4 有名管道


命令行:mkfifo [fifoname]
int mkfifo(const char *pathname, mode_t mode);
-
参数
-
pathname:带路径的文件名 -
mode:与open()的 mode 相同 -
成功返回 0,失败返回-1 并设置 errno
-
-
打开最好是,你是写的,就
O_WRONLY,你要是读的,就O_RDONLY
有名管道读写特点
(其实同匿名管道)
- 对于只读/只写的进程来说,只有只读的进程打开管道,或者只有只写的进程打开管道,都会导致该进程阻塞。换言之,必须要同时有读写进程,才不会在打开这一步就被阻塞。
- 读:
- 管道中有数据,则返回读取到的字节数
- 管道中无数据时,
- 若写端没有全部关闭,则
read()阻塞; - 若写端全部关闭,则
read()返回0
- 若写端没有全部关闭,则
- 写:
- 若读端全部关闭,则收到
SIGPIPE信号(管道破裂),导致写端异常终止。 - 若读端未全部关闭:
- 管道未满,则返回实际写入的字节数
- 管道满了,则
write()阻塞
- 若读端全部关闭,则收到
- 总结:不管是有名还是匿名管道(在不设置非阻塞情况下):
读的重点在管道中有没有数据。有就读,没有就阻塞。如果既没有数据,又没有人写了,那就说明读完了,返回 0;而写更在乎有没有人在读,如果没有读的人了,那直接终止。如果有,那就继续写,写满了就阻塞。
2.5.5 内存映射
参考读物:mmap 内存映射原理
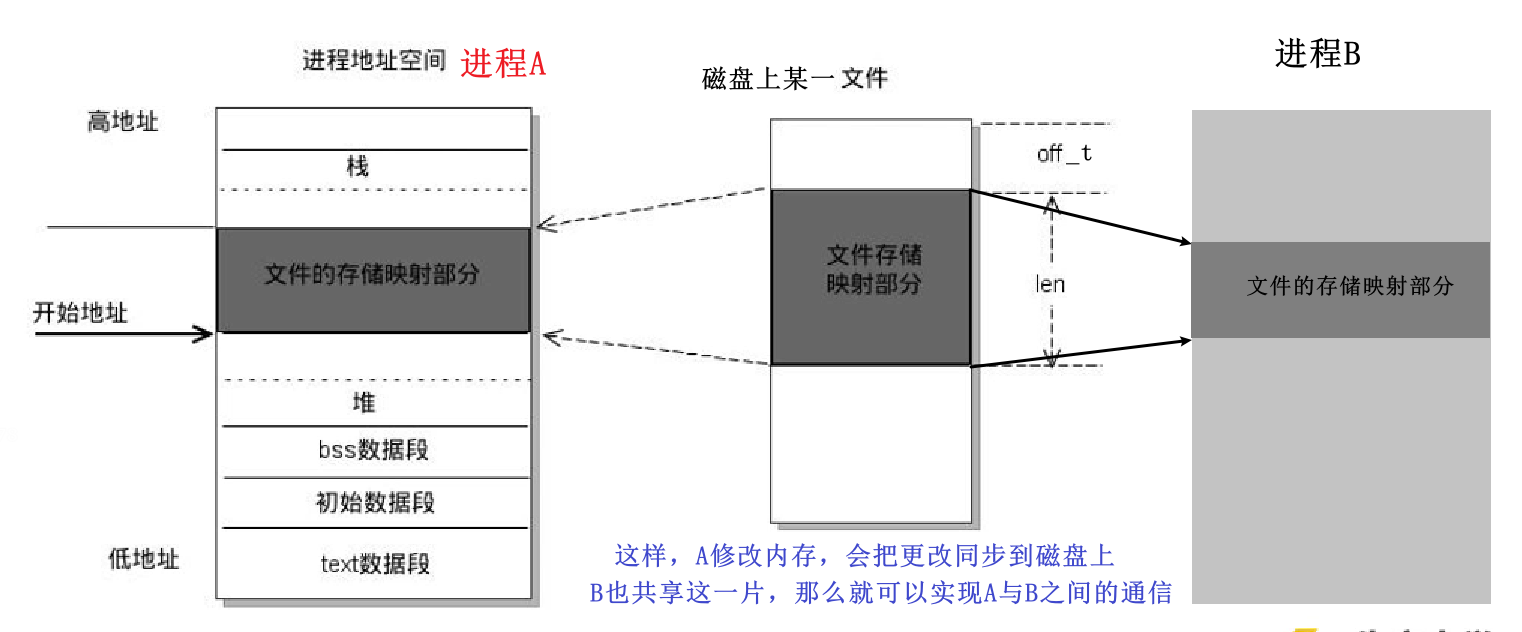
内存映射 (Memory-mapped I/O) 是将磁盘文件的数据映射到内存,用户通过修改内存就能修改磁盘文件。
内存映射函数
#include<sys/mman.h>
// 映射到内存
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
// 解除映射
void munmap(void *addr, size_t length);
-
内存映射函数 m-map():
-
addr:指定映射的内存起始地址。(最好传递NULL,由内核选择地址进行映射) -
length:要映射的数据长度,要求大于 0 ;如果 length 未达到一页,则映射一页的大小【分页】。建议直接映射文件的大小(stat、lseek) -
prot:对申请内存映射区的操作权限,不能和打开的文件的权限冲突。最起码要有读的权限。通常是读,或者读写即可。PROT_READ,PROT_WRITE,PROT_EXEC,PROT_NONE,相或 -
flags:内存的权限-
MAP_SHARED:共享,即映射区的数据回自动与磁盘文件进行同步。如果要完成进程间通信则必须选择此 flags -
MAP_PRIVATE:不会与文件同步,如果发生数据改变,则会创建一个 copy,而不会改写源文件 -
MAP_ANONYMOUS:实现匿名映射,即不需要文件实体了。那么① 只能实现父子进程之间的映射
② 参数也要改变,
fd = -1,offset = 0,flags = MAP_SHARED | MAP_ANONYMOUS
-
-
fd:open 一个磁盘文件。注意,不能为空文件!且 open 指定的权限不能与 prot 权限冲突 -
offset:必须指定 4K 整数倍。一般不用管,即置 0 -
返回值:- 成功返回映射内存区的起始地址
- 失败返回
MAP_FAILED,即(void *) -1
-
-
接触内存映射函数 m-un-map()
addr:要接触映射的内存始址length:要和 mmap 的参数一样
实现进程间通信
(指的是文件映射。匿名映射前面提过,设置参数MAP_ANONYMOUS,只能实现父子进程之间的通信)
- 有关系的进程(父子进程):在
fork()之前,先选择一个非空文件,并创建内存映射区。然后子进程复制父进程地址空间,即可实现父子进程共享内存映射区(注意,这与写时拷贝也不冲突) - 无关系的进程:准备一个非空磁盘文件,两个进程分别对该文件进程内存映射得到各自内存指针,然后开始共享内存。
- 内存映射为非阻塞通信。因此,比如父子进程通信时,要确保别写的还没写完,就读了,那肯定读不到
问题总结
-
如果对 mmap()的返回值(ptr)做++操作
(ptr++),munmap()是否能够成功?- 可以。但是要注意备份,即传递给 munmap 的地址应当是分配内存的首地址
-
如果 open()
O_RDONLY,mmap()时 prot 参数指定PROT_READ | PROT_WRITE会怎样?- 会映射失败,返回
MAP_FAILED。prot 的权限 <= open 的权限
- 会映射失败,返回
-
如果文件偏移量为 1000 会怎样?
- 会映射失败,返回
MAP_FAILED。必须为 4K(4096)的整数倍
- 会映射失败,返回
-
mmap()什么情况下会调用失败?
- 空文件、权限错误(没有读权限或与 open 不一致)、偏移量不对
-
可以 open()的时候
O_CREAT一个新文件来创建映射区吗?- 可以,但是创建文件的大小为 0 会失败。可以对新的文件进行拓展(lseek、truncate)
-
mmap()后关闭文件描述符,对 mmap()映射有没有影响
- 不会。映射区仍然存在,尚未释放。mmap 对传进来的 fd 进行了拷贝,你的关闭了,它同步的还在
-
对
ptr越界操作令怎样?- 系统实际分配的,是 length 对应的分页大小。越界会段错误
内存映射不只可以进行进程通信,还可以实现比如文件复制等功能。牢记其原理:把文件映射到内存中,并且建立内存与文件之间的同步,把文件操作变成内存操作即可。
2.5.6 信号
信号概述
 |
 |
-
查看信号详细信息:
man 7 signal -
信号默认的五种处理动作:
Term:终止进程Ign:当前进程忽略掉这个信号Core:终止进程,并生成一个 core 文件Stop:暂停当前进程Cont:继续执行当前被暂停的进程
-
信号的几种状态:
产生、未决、递达 -
SIGKILL和SIGSTOP不能被捕捉、阻塞或者忽略,只能执行默认动作
信号一览
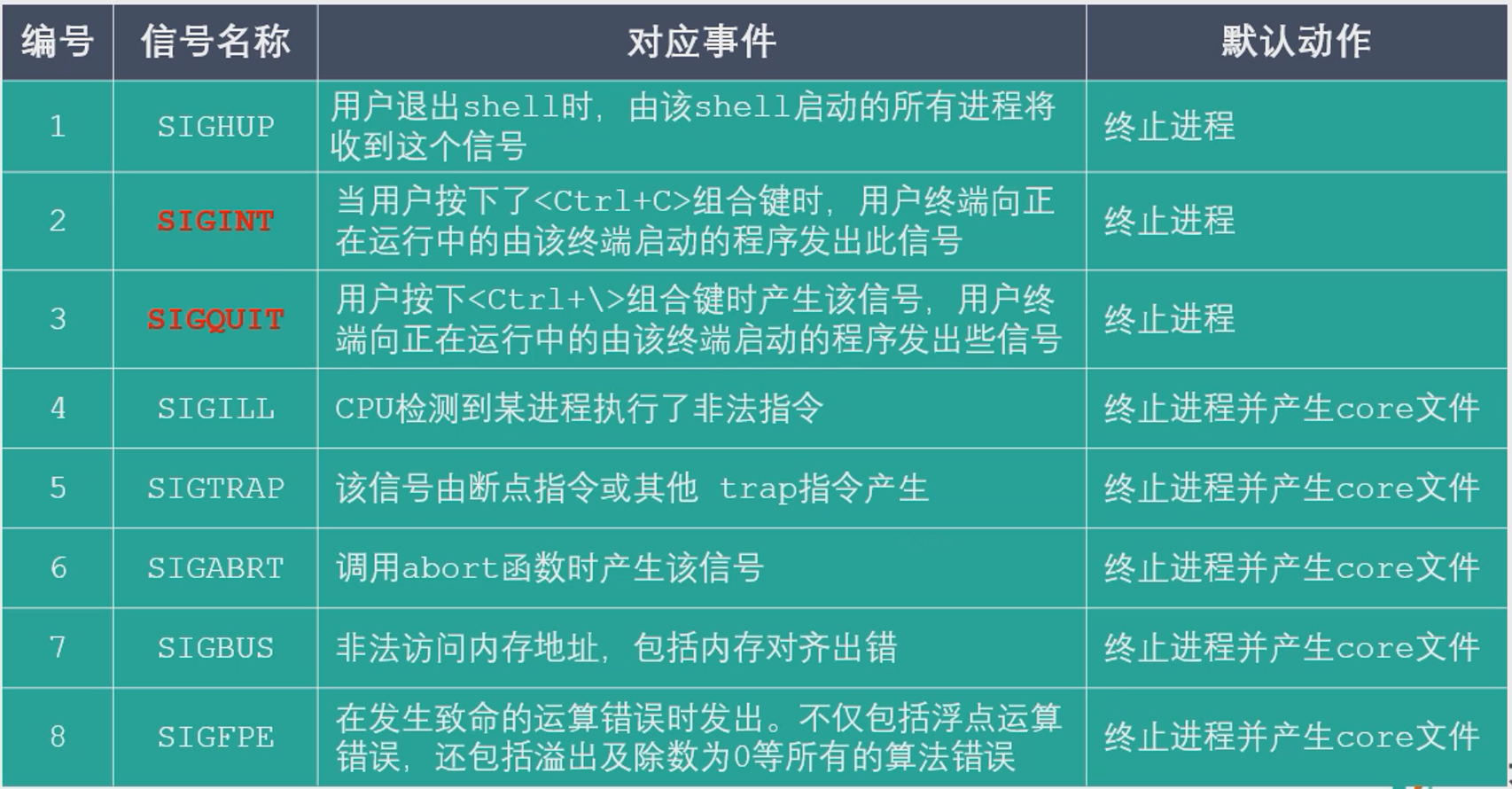 |
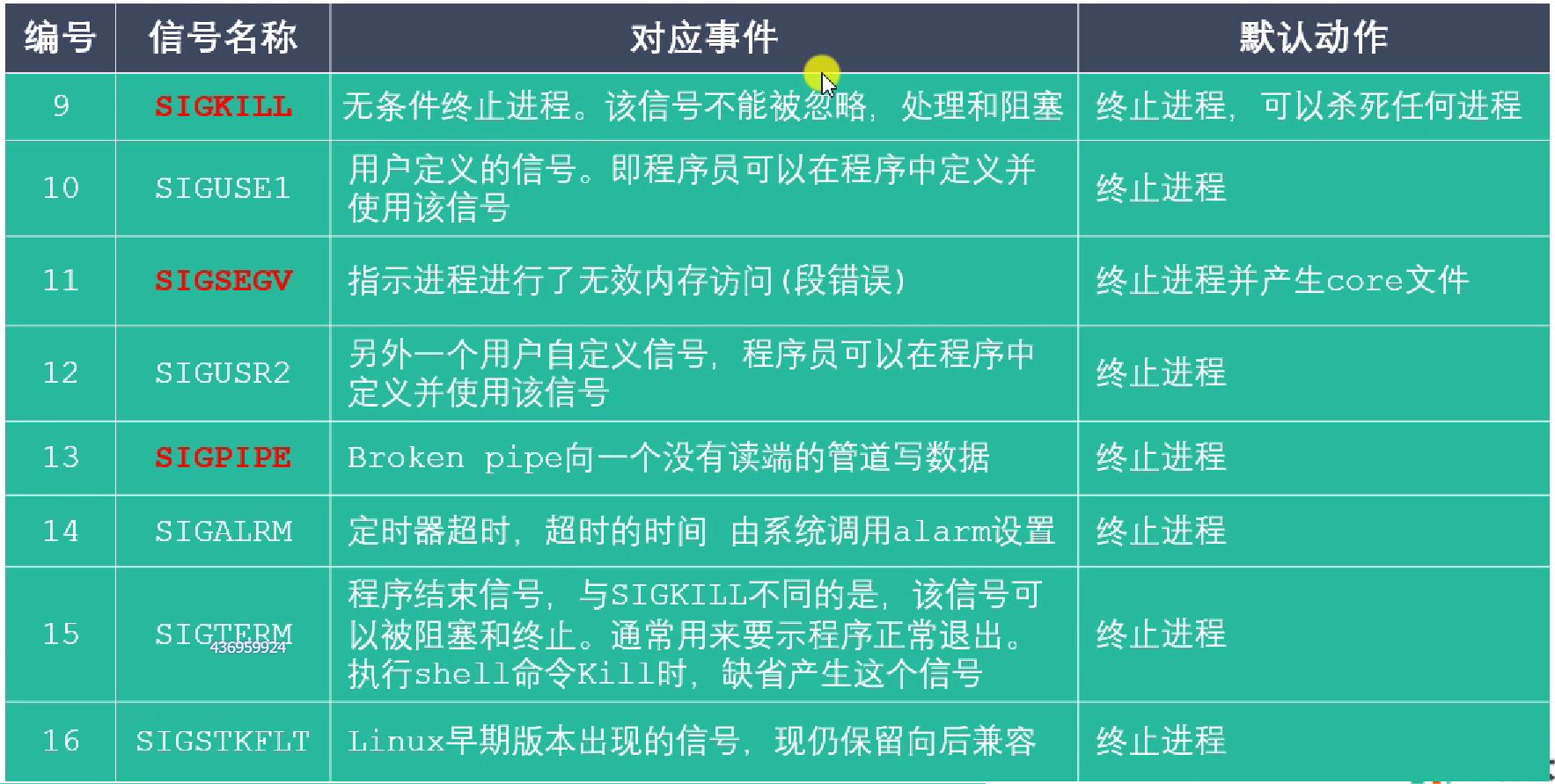 |
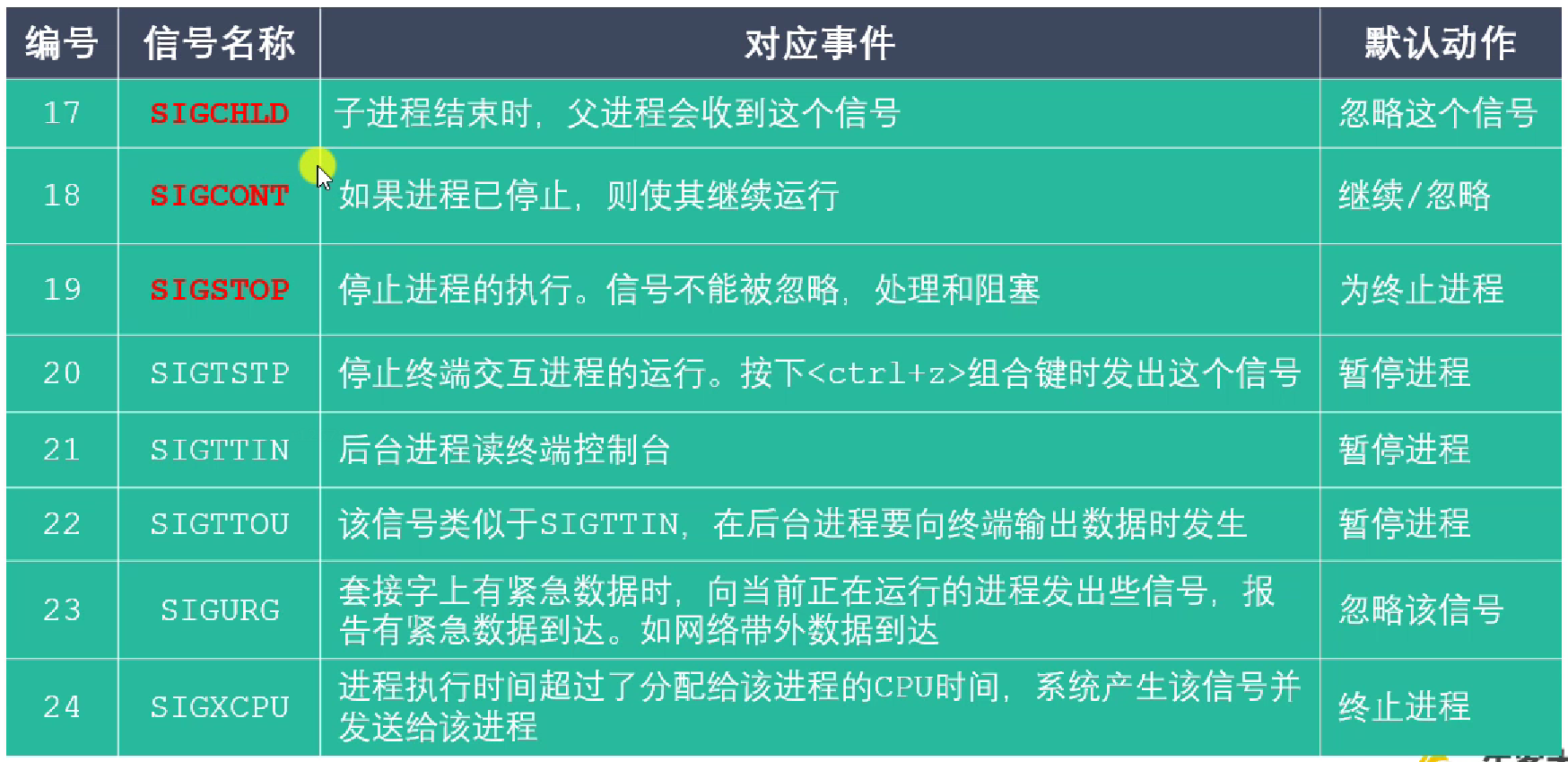 |
 |
2.5.7 信号相关函数
int kill(pid_t pid, int sig);
int raise(int sig);
void abord(void);
kill & raise & abord
-
kill:给指定进程发信号。注意,不一定是发送信号 9-
pid:取> 0,表示发送给该进程,0,发给当前进程组的所有进程,-1,发给所有有资格发送信号去的进程(除了 init),<-1给绝对值对应的进程组 -
sig:取0表示不发送信号 -
成功返回 0,失败返回-1
-
-
raise:只给当前进程/线程发送信号。成功返回 0,失败返回-1 -
abord:默认终止当前进程
unsigned int alarm(unsigned int seconds);
int setitimer(int which, const struct itimerval *new_val, struct itimerval *old_value);
alarm & setitimer
-
alarm():设置定时器,当时间到了的时候,给当前进程发送SIGALRM信号,默认终止当前进程。每个进程都有且只有一个计时器seconds:倒计时时间(秒),设置为 0 无效,即可通过alarm(0)取消定时器- 返回值:之前没有设置定时器则返回 0,之前有定时器则返回其剩余的时间
-
setitimer():也是设置定时器,可以替代 alarm 函数,可以周期性定时,精度更高(微秒)which:指定定时器以什么时间计时ITIMER_REAL:真实时间,时间到达发送SIGALRM信号ITIMER_VIRTUAL:用户时间,时间到发发送SIGVTALRMITIMER_PROF:进程在用户态和内核态的时间,时间到达发送SIGPROF
new_val:一个结构体,设置定时器的属性(这有一份示例代码)
struct itimerval { /*定时器的结构*/ struct timeval it_interval; /* Interval for periodic timer,后面每次间隔时间 */ struct timeval it_value; /* Time until next expiration,延迟多久开始执行定时器 */ }; /* 就是说,只有第一次闹钟是等待it_value值后“响”,后面每隔it_interval值“响”一下 */ struct timeval { /*时间的结构*/ time_t tv_sec; /* seconds */ suseconds_t tv_usec; /* microseconds ,两个都要设置,否则可能是随机值*/ };old_val:记录上一次定时的时间参数(传出参数),不用可以设置为NULL- 成功返回 0,失败返回-1
信号捕捉 signal
#include <signal.h>
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);
signum:要捕捉的信号,就是那一堆宏。SIGKILL和SIGSTOP不可被捕捉、忽略handler:捕捉后要如何处理,是一个指向参数为 int(即信号编号),返回值为 void 的函数的函数指针SIG_IGN:忽略信号SIG_DFL:采用信号默认的处理方式回调函数:让内核调用你写的某一个函数来进行处理(回调函数介绍)- 返回值:成功返回上一次设置的回调函数的指针(第一次为 NULL),失败返回
SIG_ERR
- 注册信号捕捉,要提前注册好,等信号来了再注册就来不及了,程序就直接结束了
信号捕捉 sigaction
建议使用 sigaction 而不是 signal,因此 sigaction 能满足更多的标准,更通用。
// 检查或者改变信号的处理方式(新版信号捕捉)
int sigaction(int signum, const struct sigaction *act, struct sigaction *oldact);
struct sigaction {
void (*sa_handler)(int); // 信号处理函数①
void (*sa_sigaction)(int, siginfo_t *, void *); //信号处理函数②,不常用,由flags指定
sigset_t sa_mask; // 在信号捕捉函数执行过程中,临时阻塞一些信号,不用记得清空
int sa_flags; // 指定信号的处理方式,一堆宏值,其中0表示用①,SA_SIGINFO表示用②
void (*sa_restorer)(void); // 废弃掉了,指定NULL即可
};
sigaction:
signum:要捕捉的信号,除了 sigkill 和 sigstopact:捕捉到信号后的处理动作oldact:上一次的处理动作,不用传入NULL
信号集
 |
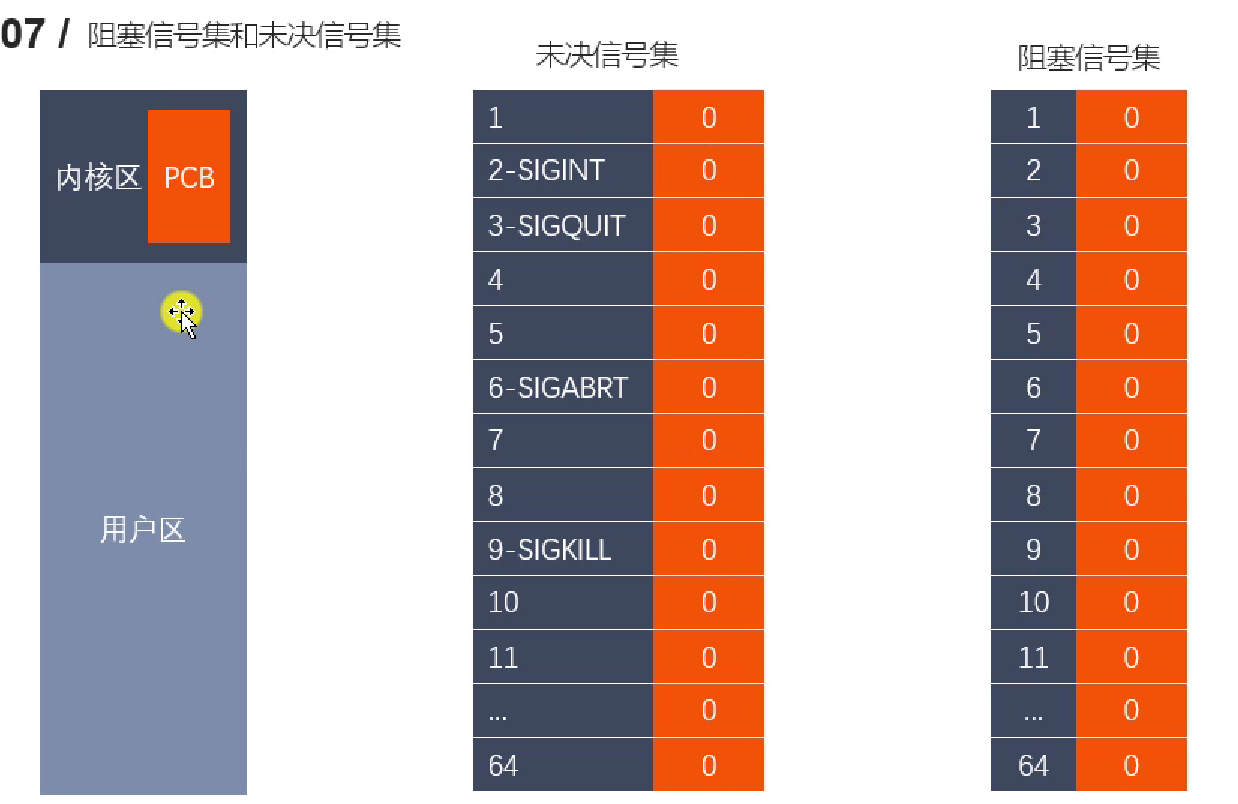 |
-
信号集在 PCB 中其实就是一个 01 数组(位图),信号尚未被处理,那就在未决信号集里面,值 1;阻塞了,那就在阻塞信号集里面值 1。
-
未决信号集中的信号不能马上被处理,还需要先跟阻塞信号集中对应的值比较,如果非阻塞,就发给进程去处理,发之后,就是送达状态,未决位就置 0 了
-
不能直接设置这些位,而是要借用对信号集的一些操作函数来实现改变。比如阻塞信号集默认都非阻塞,但可以通过函数来设置阻塞。
信号集相关函数
注意:下面这些函数操作的都是你自己创建的信号集,就是一个类似的数组,然后要通过一个系统调用sigpromask才能映射到系统中的阻塞信号集中。一般操作的都是阻塞非阻塞属性(sigprocmask),未决信号集只有获取这个动作(sigpending)。
注意:在多线程环境中,应当使用 pthread_sigmask(),其参数含义与作用完全相同
// sigset就是一个你自己创建的无符号长整型数组,函数什么清空添加删除,都是操作的这个数组
typedef __sigset_t sigset_t;
#define _SIGSET_NWORDS (1024 / (8 * sizeof (unsigned long int)))
typedef struct{
unsigned long int __val[_SIGSET_NWORDS];
} __sigset_t;
// 将信号集中的参数全部置为0/1,set是传出参数,即操作的信号集,成功返回0失败返回-1
int sigemptyset(sigset_t *set);
int sigfillset(sigset_t *set);
// 将信号集中的某个信号置为1/0,表示阻塞/不阻塞这个信号,成功返回0失败返回-1
int sigaddset(sigset_t *set, int signum);
int sigdelset(sigset_t *set, int signum);
// 判断信号是否阻塞。返回1表述信号阻塞,0表示不阻塞,-1表示错误
int sigismember(const sigset_t *set, int signum);
/* 将自定义信号集中的数据设置到内核 阻塞 信号集中:设置阻塞、解除阻塞、替换 */
int sigprocmask(int how, const sigset_t *set, sigset_ *oldset);
/* 获取内核中的 未决 信号集*/
int sigpending(sigset_t *set);
sigprocmask:将自定义信号集中的数据设置到内核中:设置阻塞、解除阻塞、替换
how:设置函数工作的方式。不妨设内核中的阻塞集为 mask,用户自定义的为 setSIG_BLOCK:将用户设置阻塞信号添加到内核中,mask = mask | set,set 中为 1 的内核中置为 1SIG_UNBLOCK:根据用户设置的数据,解除内核中的阻塞,mask &= ~set,set 中为 1 的内核中置为 0SIG_SETMASK:根据用户的信号集覆盖内核中的阻塞集,mask == set,set 是啥就是啥
set:用户自定义的信号集oldset:传出内核中原来的数据集,即做一个备份,不用设置为NULL- 返回值,成功返回 0,失败返回-1,设置错误号
EFAULT出错,EINVAL传入的 how 非法
信号捕捉过程
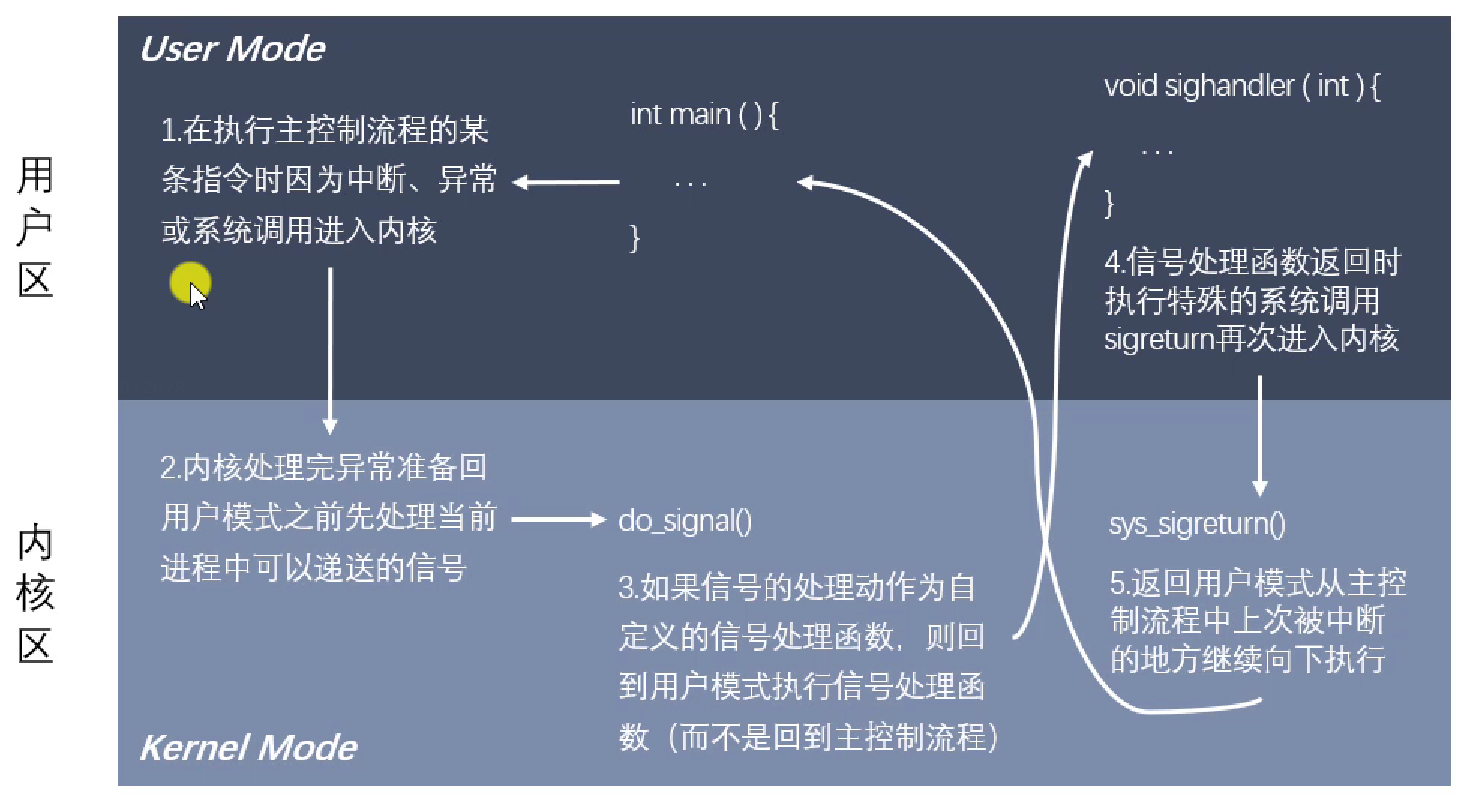
- 信号从开始执行回调函数,其未决状态会置为 0。此时再来一个相同的信号,未决变为 1,但是此时回调函数在执行过程中,新来的信号是执行不了的,会被阻塞在那里。
- 回调函数处理过程中使用的是临时阻塞信号集,你要是没设置那就还是原来的
- 前 32 个常规信号是不支持排队的,因为它只能记录 0 或者 1。后 32 个信号可以存储有多少个信号在排队
SIGCHILD 信号
在以下三种情况下,会给父进程发送SIGCHILD信号,而父进程默认会忽略此信号
- 子进程终止
- 子进程收到
SIGSTOP信号而暂停 - 子进程处在停止态,然后收到
SIGCONT信号被唤醒时
- 问题 0,之前解决僵尸进程的办法是,不断循环 wait,这显然是不合理的,怎么优雅回收子进程资源呢?
- 解决 0思路很简单,可以在父进程中捕捉 SIGCHILD 信号,等子进程结束时再调用 wait 回收它就好了
- 这里会有一个问题 1,假如子进程很多,它们都在同一时间结束,前面提到过,常规信号是不支持排队的,因此,收到第一个 SIGCHILD 信号去执行 handler 的过程中,会到达很多别的 SIGCHILD 信号,他们最终都只是未决队列里的同一个 1,等 handler 结束再回来的时候,再把这个“一个”未决的信号送达。等于是,一堆子进程就执行了两次 handler。
- 解决 1方法也很简单,在 handler 中循环调用非阻塞的
waitpid函数,当前有终止的子进程就回收,如果没有(返回值为 0 或-1)就 break 结束 handler,返回主控函数,不影响父进程的正常工作。这样就可以实现,收到一次信号,就可以回收当前所有已经终止的子进程。
- 解决 1方法也很简单,在 handler 中循环调用非阻塞的
- 然后又有一个问题 2:如果子进程很快就结束了,快到父进程注册信号捕捉这个系统调用还没结束,那岂不是就不能回收掉这个子进程了?因为这个子进程发送的 SIGCHILD 信号是被父进程默认忽略掉的
- 是的,解决 2办法是,在父进程中,先设置一个信号集,阻塞掉 SIGCHILD 信号,然后注册信号捕捉,等注册成功,在对 SIGCHILD 信号接触阻塞,即可。
2.5.8 共享内存
共享内存是效率最高的进程间通信方式,注意与内存映射区分,内存映射还是基于文件的,只不过少了一次从内核缓冲拷贝到用户缓冲的时间,直接实现磁盘和用户缓冲区之间的同步
比较的时候要记住,凡是通过文件的 IO,不论读写,用户都是与内核的缓冲区进行交互的,内核缓冲区才负责读写文件,是用户—内核—文件的模式
 |
 |
共享内存操作函数
key_t ftok(const char *pathname, int proj_id); // 获取一个创建共享内存的key,也可以自己指定
int shmget(key_t key, size_t size, int shmflg); // 创建物理共享
void *shmat(int shmid, const void *shmaddr, int shmflg); // 映射到自己的虚地址空间
int shmdt(const void *shmaddr); // 解除共享,从自己的虚地址空间中移除
int shmctl(int shmid, int cmd, struct shmid_ds *buf); // 读取或设置共享内存的一些属性
key_t ftok(const char *pathname, int proj_id);
-
ftok():根据文件名和给定的 int 值,生成一个共享内存的 key。如果文件和 int 值不变,那 key 值在哪生成都是一样的。所以可以由此实现不同进程用同一个 key 来创建/获取共享内存。- pathname:必须是一个已经存在的可以访问的文件
- proj_id:只会使用低八位,因此可以传入一个字符 'a', 'b'
int shmget(key_t key, size_t size, int shmflg); -
shmget():创建或获取共享内存标识,默认内存全部清 0-
key:key_t 类型(整形),共享内存的标识符,一般用 16 进制表示,非 0。A 进程开辟了一段共享内存,获取这段内存的 ID。但是 B 怎么找到这块内存呢?所以 key,就是“暗号”,让 AB 可以定位到同一段物理共享内存,当然,他们返回的 shmid 也是一样的。
-
size:共享内存的大小,向上取整到分页大小,即按页对齐。如果是获取,那置为 0 就行了
-
shmflg:指定属性,如内存权限(八进制),和附加属性(创建|存在与否)
用法:
IPC_CREAT | IPC_EXCL | 0664。存在判断必须要与创建连用才行 -
返回值:成功返回共享内存引用的 ID(不是 key),失败返回 -1
void *shmat(int shmid, const void *shmaddr, int shmflg); -
-
shmat():将一个物理的共享内存和当前进程关联(放进自己的虚拟地址空间中,在共享区)-
shmid:共享内存的标识 ID,由
shmget返回值获取 -
shmaddr:共享内存在虚拟地址空间的起始地址,指定
NULL,让内核去指定。自己指定有可能出错 -
shmflg:对共享内存的操作,无非是读写等权限,注意,必须要有读权限
SHM_RDONLY指定只读,0默认是读写都有 -
返回值:成功返回共享内存虚拟地址空间的起始地址,失败返回((void*)-1)
-
写入的时候可以用
memcpy(),来把你想写的东西拷贝进去 -
读出的时候,也可以用
memcpy(),还可以把void *类型指针转换成char *读取
int shmdt(const void *shmaddr); -
-
shmdt():解除共享内存和当前进程的关联,参数即虚拟共享内存的起始地址,成功返回 0,失败返回-1int shmctl(int shmid, int cmd, struct shmid_ds *buf); -
shmctl():操作共享内存,常用来删除。内存只有主动删除才消失,与创建进程存在与否无关。-
shmid:共享内存的 ID
-
cmd:要进行的操作
IPC_STAT:获取共享内存当前状态,此时参数buf是传出参数IPC_SET:设置共享内存状态,此时参数buf是传入参数IPC_RMID:标记共享内存为待删除,此时参数buf没有用,设置NULL
-
buf:一个
shmid_ds结构体指针,存放需要设置或读出的参数,作用与cmd的选择有关struct shmid_ds { struct ipc_perm shm_perm; /* Ownership and permissions */ size_t shm_segsz; /* Size of segment (bytes) */ time_t shm_atime; /* Last attach time */ time_t shm_dtime; /* Last detach time */ time_t shm_ctime; /* Creation time/time of last modification via shmctl() */ pid_t shm_cpid; /* PID of creator */ pid_t shm_lpid; /* PID of last shmat(2)/shmdt(2) */ shmatt_t shm_nattch; /* No. of current attaches */ ... }; -
所谓删除是,先标记删除,将共享内存段的
key置 0,表示要删除这一段共享内存。只有等到共享内存的链接数为 0 的时候,才会真正删除这段内存。因此可以对一段内存进行多次删除,反正只有最后一个进程的删除动作才有效。 -
链接数等信息,就是保存在一个
shmid_ds结构体中
-
共享内存操作命令
# (1) ipcs 显示进程间通信的一些信息
ipcs -a # 打印当前系统中 所有的 进程间通信方式 的信息
ipcs -m # 打印出使用 共享内存 进行进程间通信的信息
ipcs -q # 打印出使用 消息队列 进行进程间通信的信息
ipcs -s # 打印出便用 信 号 进行进程间通信的信息
# (2) ipcrm 进程间通信媒介的 删除手段
ipcrm -M {shmkey} # 移除用 shkey 创建的 共享内存段
ipcrm -m {shmid} # 移除用 shmid 标识的 共享内存段
ipcrm -Q {msgkey} # 移除用 msqkey 创建的 消息队列
ipcrm -q {msqid} # 移除用 msqid 标识的 消息队列
ipcrm -S {semkey} # 移除用 semkey 创建的 信号
ipcrm -s {semid} # 移除用 serid 标识的 信号
共享内存和内存映射的区别
- 共享内存可以直接创建,内存映射需要依赖文件(匿名映射除外)
- 共享内存效率更高,内存映射需要与磁盘同步
- 共享内存操作的是同一块内存,内存映射是,每一个进程在自己的虚拟内存中都有一块独立的内存,只不过这块内存通过一个共同的文件关联了起来
- 数据安全:
- 进程退出,共享内存还在(需要主动调用删除才行)只不过进程不再与之关联,但内存映射区不在了
- 电脑断电,没电了内存自然是消失了,但是由于磁盘文件还在,因此内存映射区的数据还在
- 生命周期,共享内存需要手动删除,且进程关联数为 0 时,才会真正被删除。而内存映射区,进程退出后就自动销毁了
2.5.9 守护进程
控制终端
终端是一个设备(命令tty可以查看),用户通过终端登录后,获得一个 shell 进程(命令echo $$显示当前 shell 的 pid),这个进程的控制终端(Controlling Terminal)即是此终端。
进程中,控制终端的信息是写在 PCB 中的,因此,从此 shell 启动的所有进程,其控制终端都是本终端(因为 fork()会复制 PCB),标准输入输出错误默认指向控制终端,因此也就都是指向本终端。
可以在控制终端输入一些命令来控制进程,但这只对前台进程有效。因为后台进程(在启动命令后面加一个$或者用Ctrl + Z即可得到后台进程)是没有控制终端的。
进程组 & 会话
 |
 |
-
相关进程放在同一个组里,方便管理,比如修改进程优先级,直接把组的改了就行了
-
创建会话的两步,第一步会话首进程创建一个进程组,组号等于自己的进程号;第二步,会话首进程创建一个会话,会话号等于自己的进程号。因为会话是进程组的集合嘛,得先创建一个组
-
控制终端的第一个程序,会创建一个会话。一个终端只有一个会话;任意时刻,一个终端都有且只有一个前台进程组。下面是一个示例
find / 2 > /dev/null | wc -l &
sort < longlist | uniq -c
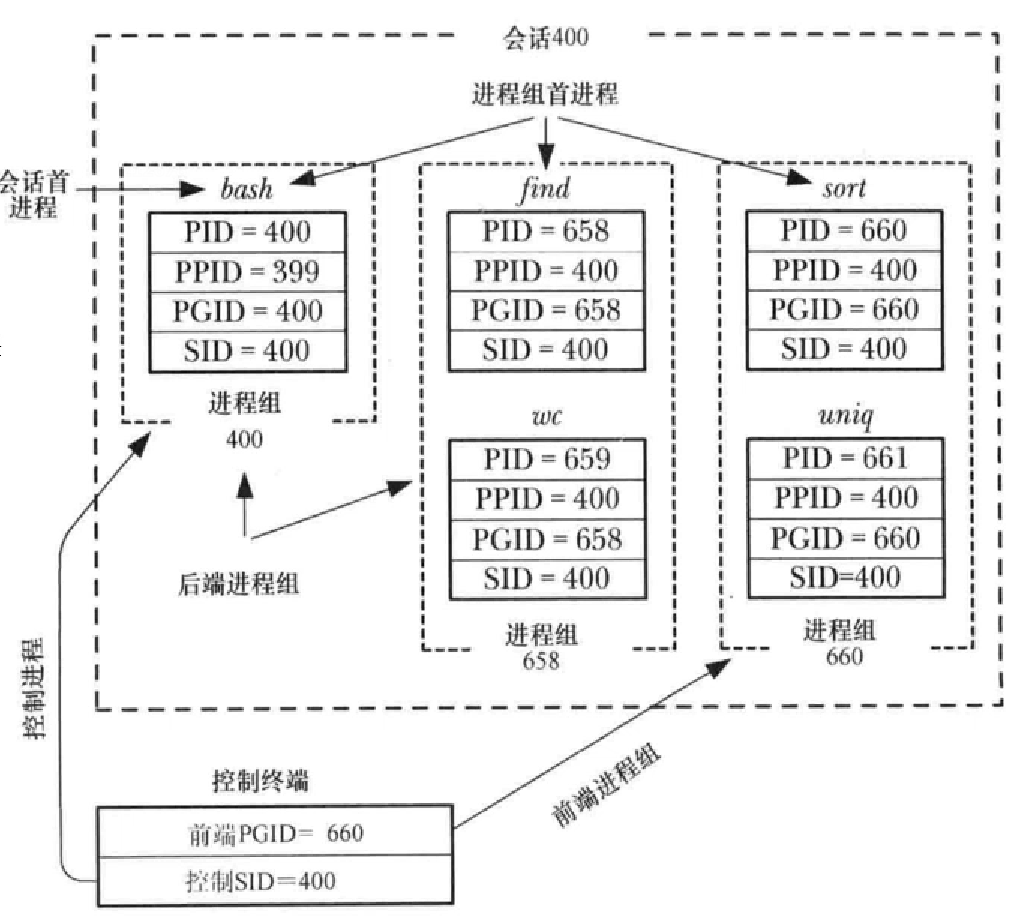 |
 |
守护进程概念

守护进程创建步骤
- 执行
fork(),之后父进程退出,子进程继续执行。- 因为下面要创建一个会话,创建会话的进程,不能是进程组的首进程(步骤 2 解释原因),而你执行父进程的时候,它默认就会创建一个进程组。因此,让它生成一个子进程来创建会话,子进程的 pid 和它的 pgid 是不一样的。
- 父进程退出之后,会被 shell 得知,并输出一个 shell 提示符。显然我们不希望要这个提示符
- 子进程调用
setsid()开启一个新的会话- 创建一个新的会话,不会连接控制终端,因此这个新的会话就不会有控制终端。注意,是没有控制终端了,但不是说这个进程没有终端。这点在步骤 5 中有解释。
- 为什么要用子进程创建会话呢?因为,如果使用父进程,父进程本身会有一个进程组(它是首进程),进程组的 pgid 就是父进程的 pid,父进程也是在一个会话 A 里面的。如果选择父进程来创建一个新的会话 B,那么首先,他会创建一个进程组,这个组的 pgid 和它的 pid 是一样的。好的,现在问题就出现了:在会话 A 和会话 B 这两个会话里面,有两个组号相同的进程组。这是不行的。因此,创建会话的进程,不能是进程组的首进程。(换言之:因为什么进程创建新会话,都要先以自身为组长创建进程组,而一个进程不能当两个组的组长,组长走了,原来的组还在呢)
- 清除进程的
umask,以确保当守护进程创建文件和目录时拥有所需的权限 - 修改进程的当前工作目录,通常会改为根目录
/ - 关闭守护进程从其父进程继承而来的所有打开者的文件描述符
- 守护进程是一直运行着的,如果不关闭文件描述符,那这些个文件就会被一直占用,删不掉
- 关闭文件描述符 0、1、2,然后打开
/dev/null,并使用 dup2()重定向到这个设备- 创建一个新会话脱离控制终端,但是终端还是有的,会继承父进程的文件描述符。因此要把这些都关闭,以防止误操作
- 而有些操作会用到这些描述符。因此就重定向到 null,写到里面的东西都会被丢弃掉
- 执行核心业务逻辑
Chapter 3 Linux 多线程开发
3.1 线程概述
3.1.1 线程 & 进程
 |
 |
插播一段别的知识:
未初始化数据段,即
.bss里面存放的是,未初始化,或初始化为 0 的,全局变量或静态变量。而.data数据段,里面存放的是初始化为 非 0 的全局变量或静态变量。在程序运行起来之后,这俩是合在一块的,统称为数据区。之所以弄这个区别,是因为,bss 段里面的变量只有个符号,其实并没有实际分配内存,只有在运行起来后,连接器才会把后面跟着的这一块 bss 区,全部清零。而 data 段里面的,你初始化了 1000 个 int 的数组,它就真真切切的占用了 1000*4B 的空间,可执行程序就会大一些。
3.1.2 共享与非共享

线程之间共享同一个虚拟地址空间,只有一些地方有区别,比如不同线程间,有各自的.text段和栈空间
信号掩码即阻塞信号集,每个线程都有自己的阻塞信号集。每个线程都有自己的 error
3.2 线程操作

3.2.1 创建线程
// 创建线程:传出线程号,指定线程属性(NULL)、线程业务(函数指针)和线程执行需要的参数(void*)
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);
// 获取线程自己的 tid,类似getpid()
pthread_t pthread_self();
// 用于比较两个线程的线程号是否相等。因为不同平台线程号的实现不同,有的用的是结构体,就没法 == 了
int pthread_equal(pthread_t t1, pthread_t t2);
-
进程是一个比较大的概念,是用来分配资源的单位,线程是用来调度的单位。main 函数中执行的是主线程,其余的是子线程。
-
参数
thread:传出参数,创建成功后,会把子线程的 id 存放在其指向的那一块缓存中,再返回attr:设置线程的属性,一般使用`NULL``start_routine:即线程要执行的代码。是一个指向 参数为 void* 返回值也为 void* 的函数 的函数指针arg:给线程要执行的函数 传递其需要的参数返回值:成功返回 0, 失败返回 一个错误号(不是 -1 了,也不同于 errno,不能 perror 了)。现在的错误处理函数定义在 string.h 头文件中:char *strerror(int errnum);
-
pthread不是标准库,因此有时编译不成功时,记得加上-pthread选项(或者加-lpthread指定也一样)
3.2.2 终止线程
void pthread_exit(void *retval);
- 在哪个线程中调用,即表示终止哪个线程。参数是你自己的 返回值
retval:传出自己的返回值,可以在pthread_join()中获取到- 其实对子线程(返回值为 void*)来说,用这个退出,跟它调用 return 退出是一样的,即
return retval;
- 其实对子线程(返回值为 void*)来说,用这个退出,跟它调用 return 退出是一样的,即
- 谁调用,谁退出,但在主线程中执行退出,不会影响其他线程的运行。而主线程如果正常运行到 return 0 结束,相当于进程退出了,整个虚拟地址空间都不存在了,那自然所有的线程也就都没了。
- 线程(包括主线程)调用了 pthread_exit 后就结束了,后面的代码就不再执行了。主线程 pthread_exit 后,不会像 return 和 exit 那样释放所有资源,但并不意味着这之间的代码还能执行。
(对指针熟练了可以跳过下面这两段话)
线程返回值,不能返回局部变量。每个线程有自己的栈,线程退出了,这块栈也就销毁了。那么你返回的值,再去读取,可能就不是原来的值了。因此要返回全局或者静态变量,而这个,也正是下面 pthread_join 第二个参数是个二级指针的原因。因为返回值是个“全局”(指针类型)变量,你获取到之后,如果传递的是一级指针,是不就等于 C 语言函数传参里面的,传值方法?也就是说,你不能去修改它,因此要想能回这个值进行修改,就要返回一个指向它的指针,指向指针的指针,那就是二级指针。
换言之,join 的工作过程其实就是,如果 retval 非空,则把目标线程的返回值(一个 void* 类型的数据),拷贝到 retval 指向的地址。(这里不要钻牛角尖,指向指针的指针,还是个指针,也还是指向一块存放数据的内存。只不过对这块内存的解读是,又是一个指针。类型不就是标记怎么解读比特数据的么)看出区别了没,其实跟之前传出参数一样,之前是用指针传出(而不是传值),现在也是用指针传出。区别就在,这次要传的参数,是一个指针。
3.2.3 回收线程
// 连接终止的线程,连接的目的,就是回收其资源,并获取其返回值
int pthread_join(pthread_t thread, void **retval);
子进程有一部分不能自己释放的资源,需要父进程回收。子线程也有,也需要回收,不同的是,任何线程都可以去回收另一个结束的线程。(一般也都是主线程调用)
-
回收不了会阻塞;一次只能回收一个,回收多个需要用循环
-
参数
thread:需要回收的子线程的 tidretval:回收子线程的返回值(不管是 return 返回的,还是调用 pthread_exit() 返回的,一样)返回值:成功返回 0, 失败返回错误号
3.2.4 线程分离
// 分离指定的线程
int pthread_detach(pthread_t thread);
- 被分离标记的线程,其结束的时候,会自动把资源归还给操作系统,不需要回收
- 不能 detach 一个已经被 detach 的线程(unspecified behavior)
- 也不能 join 一个已经被 detach 的线程(ivalid argument)
3.2.5 线程取消
// 取消指定线程(让线程终止)
int pthread_cancel(pthread_t thread);
-
线程可以被取消与否,取决于被取消线程的一些属性,(即创建线程时的第二个参数
pthread_attr_t) -
被取消的线程,不是立马终止的,而是要运行到一些被定义好的取消点(cancellation point,可以
man 7 pthreads查看)时,才会被终止。大致上可以理解为,要运行到某些系统调用处,发生内核与用户态切换时,才会被终止。
3.2.6 线程属性
 |
 |
// 设置/获取线程的分离属性
int pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate);
int pthread_attr_getdetachstate(const pthread_attr_t *attr, int *detachstate);
// PTHREAD_CREATE_DETACHED PTHREAD_CREATE_JOINABLE
首先要创建线程属性变量,然后对其进行初始化pthread_attr_init,然后设置其属性。设置了分离状态PTHREAD_CREATE_DETACHED就说明,不需要别的进程来 join 我,我结束了自己会释放。然后pthread_create创建线程,把 attr 传进去就好了。
设置了 detach 属性,就不能再去 pthread_detach 或者 pthread_join 了,跟执行一次pthread_detach()一样
3.3 线程同步
3.3.1 概述
 |
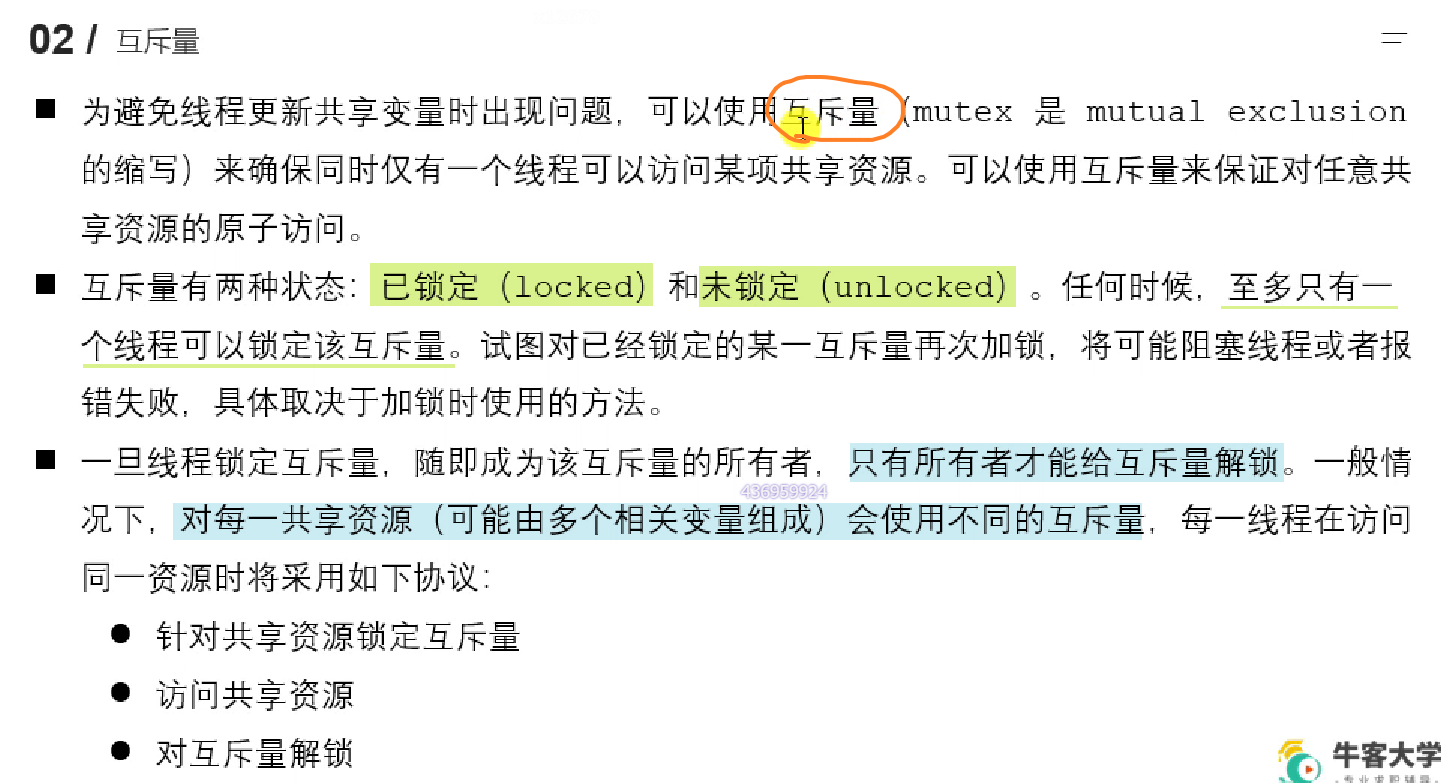 |
3.3.2 互斥锁 mutex
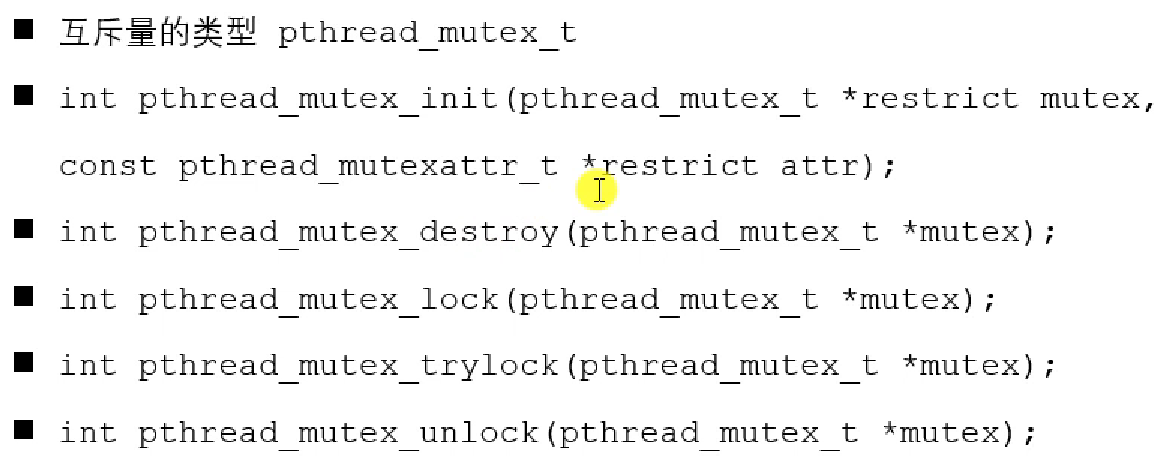
restrict:C 语言修饰符,被修饰的指针,不能被别的指针操作
锁的使用步骤:创建锁(全局) 初始化锁(使用前) 加锁(阻塞)或尝试加锁(非阻塞) 操作 解锁
初始化一个已经被初始化的锁,和销毁正在被用着的锁,都是未定义行为。但是一个锁被销毁后,是可以再被重新初始化的。合理的去 destory 锁,反正在主线程退出之后 destory,和退出之前,但是别的线程还在用着呢的时候 destory,都是不合适的。个人认为,本身他也就是一个栈上的变量而已,全局的联合体变量。你 destroy 它,它也不会释放空间,只是变得可以再被 init 了而已。没有需要就不 destroy 了
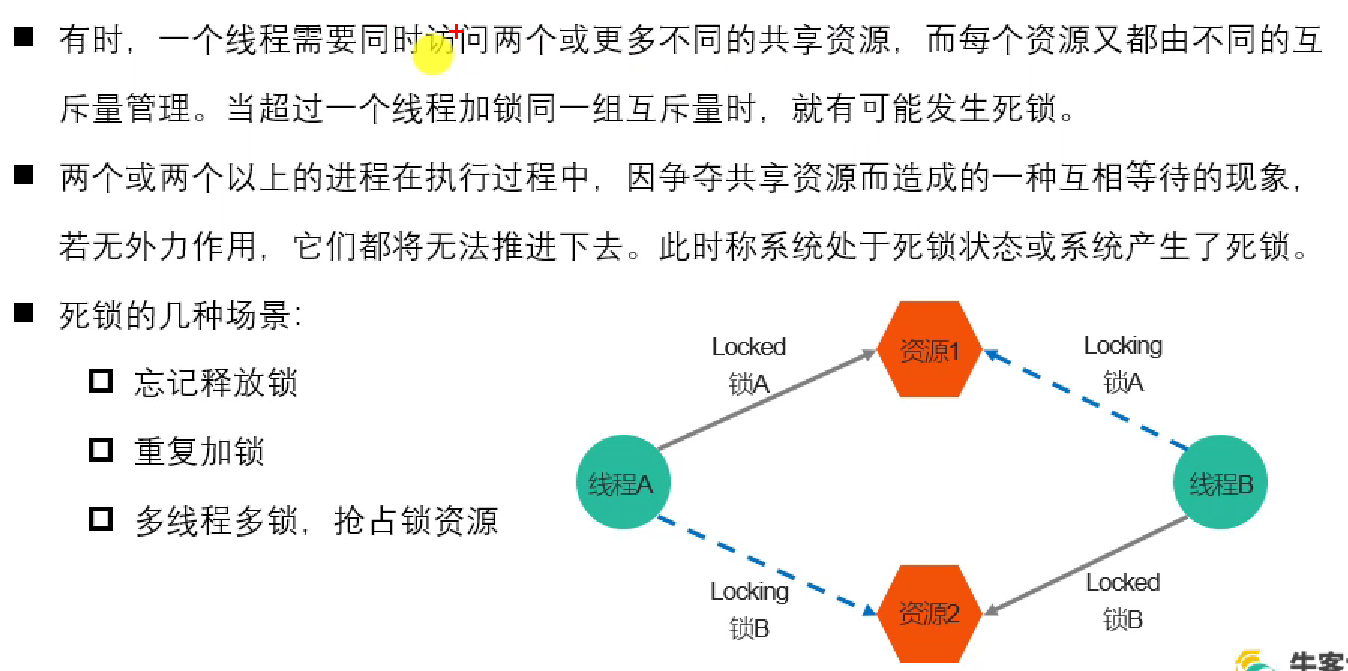
3.3.3 死锁
3.3.4 读写锁 rwlock

- 读可以共享,写的时候不许读
- 写是独占的
- 写的优先级更高
3.3.5 条件变量

- 条件变量不是锁,是配合锁来更好实现线程同步的。可以实现,满足某个条件时通知线程来做,不满足时就阻塞。至于互斥的访问临界区,那还是得锁来做。
wait是一直等待,直到被通知,timedwait是等待指定时间,如果没收到通知就不等了- 注意,当
pthread_cond_wait(&cond, &mutex)等待 cond 被阻塞的时候,系统会自动解锁,等到信号,准备就绪的时候,mutex 这个锁又会被加上 signal是至少通知一个正在等待的,broadcast是通知阻塞队列里的全部
3.3.6 信号量

-
同样的,信号量也是用来阻塞线程的,可以实现同步互斥前驱关系等,并不能保证线程安全,也即,想要保证多线程数据安全,仍然需要配合锁来实现(当然,单个信号量,值取 01,那跟锁一样了)
-
信号量是有值的,条件变量是没有值的,是看满不满足条件
-
sem_init:初始化信号量- sem:定义的 sem_t 类型的信号量的地址
- pshared:指定是用于线程间同步还是进程间同步。
0表示线程间同步,非0表示进程间同步 - value:信号量的值
-
sem_wait:V 对信号量加锁,使信号量值减一,如果 value 大于零则直接返回;如果 value 小于 0 则阻塞 -
sem_post:P 对信号量解锁,使信号量值加一,如果让信号量的值大于 0,则唤醒一个被 wait 阻塞的线程
3.3.7 同步模型
- 生产者消费者模型:光有信号量是不够的,还要加互斥锁
- 哲学家进餐模型:
- ...
Chapter 4 Linux 网络编程
4.1 网络的结构模式
4.1.1 Client/Server 模型

4.1.2 Browser/Server

4.1.3 MAC IP
每个网卡的 mac 地址是全球唯一的,由制造商烧录在网卡中
IP,Internet Protocal Address,分配一个逻辑地址,屏蔽物理地址的差异
子网掩码
端口(port),0-65535(2^16-1)
4.2 网络协议模型
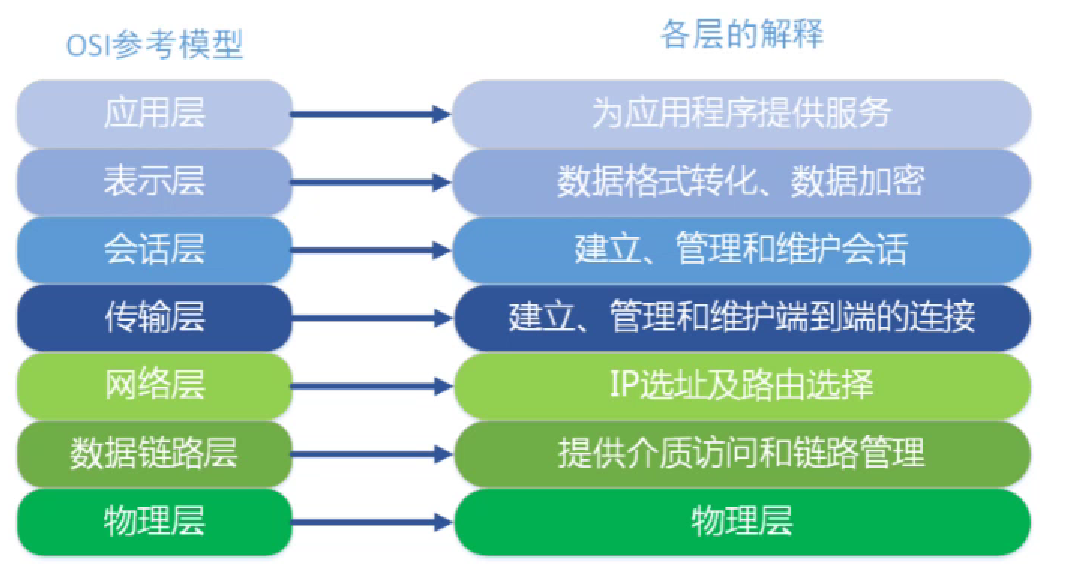
4.2.1 OSI 七层模型

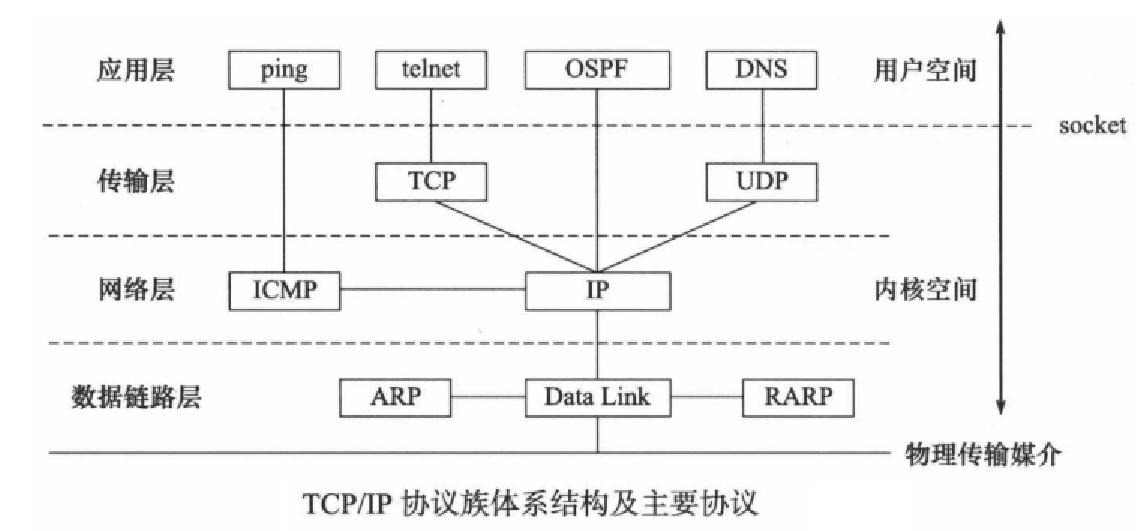
4.2.2 TCP/IP 四层协议
 |
 |
4.3 协议一览
协议,即网络协议的简称,是通信计算机双方必须遵从的一组约定,比如怎样建立连接,怎样互相识别等。只有遵守这个约定,之间才能互相通信交流。
协议的三要素是,语法、语义、时序。为了使数据在网上从源到达目的,网络通信的参与方必须遵守相同的规则,这套规则称为协议(protocal),他最终体现为,在网络上传输的数据包格式。
协议往往分成几个层次,分层的定义是为了使某一层协议的改变,不影响其他层次。

 |
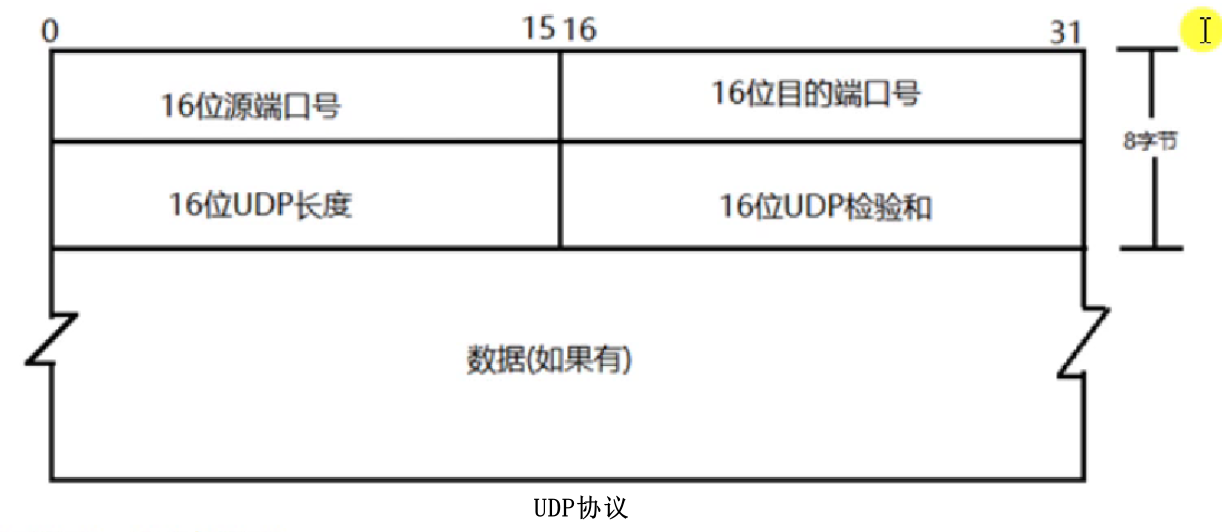 |
 |
 |
4.4 网络通信的过程
4.4.1 封装与分用
上层协议是如何便用下层协议提供的服务的呢?其实这是通过封装 (encapsulation) 实现的。应用程序数据在发送到物理网络上之前,将沿着协议栈从上往下依次传递。每层协议都将在上层数据的基础上加上自己的头部信息(有时还包括尾部信息)以实现该层的功能,这个过程就称为封装。
当帧到达目的主机时,将沿着协议栈自底向上依次传递。各层协议依次处理帧中本层负责的头部数据,以获取所需的信息,并是终将处理后的帧交给目标应用程序。这个过程称为分用 (demultiplexing)。分用是依靠头部信息中的类型字段实现的。
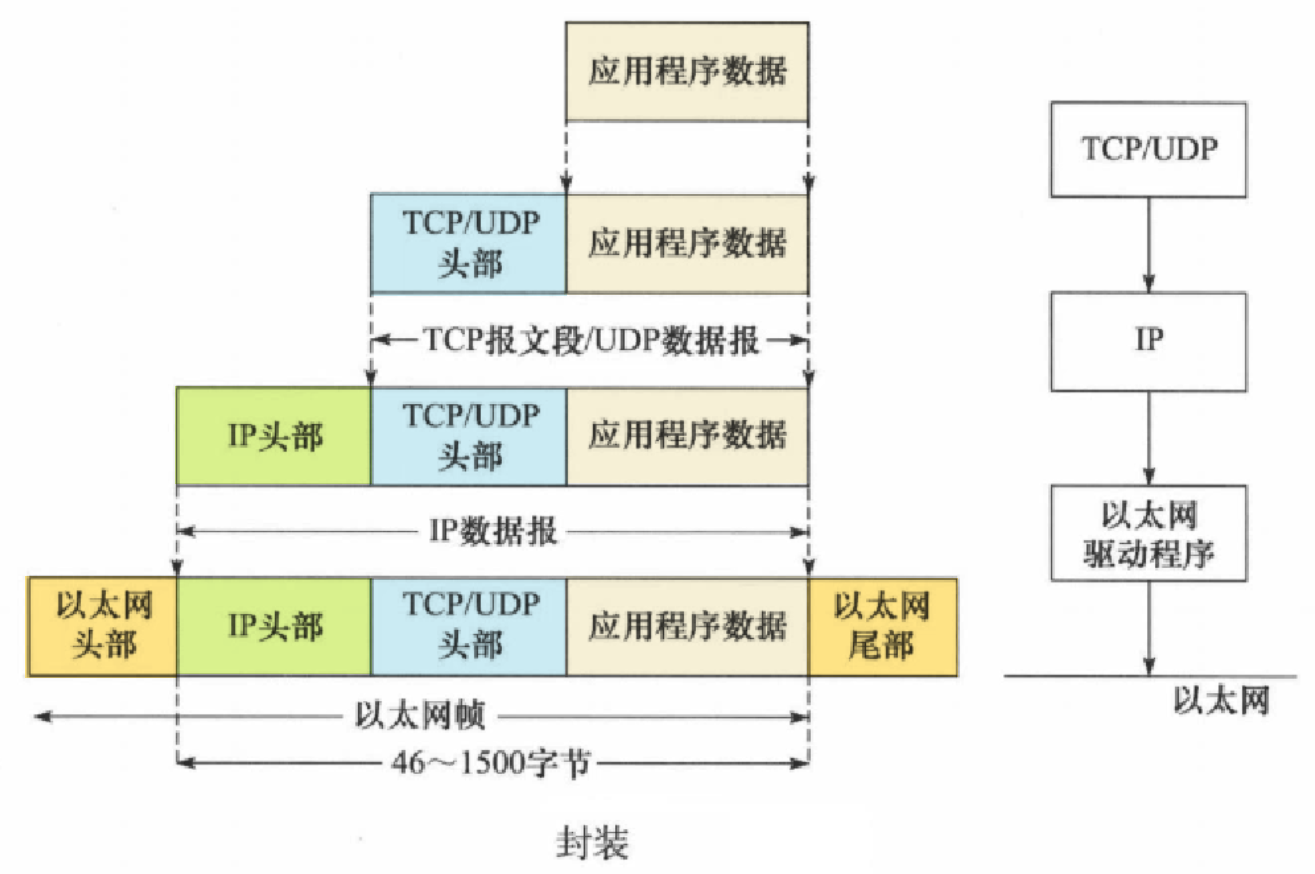 |
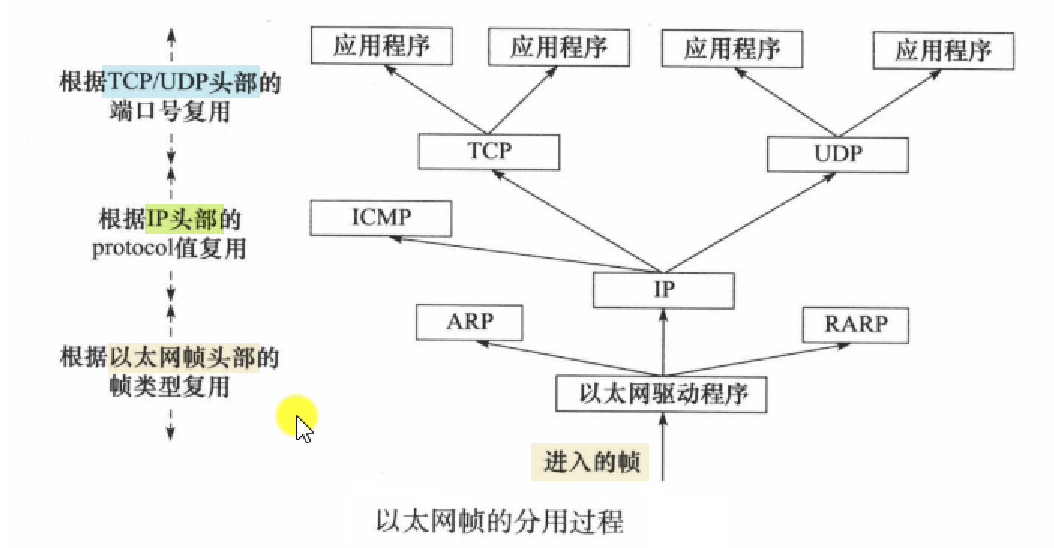 |
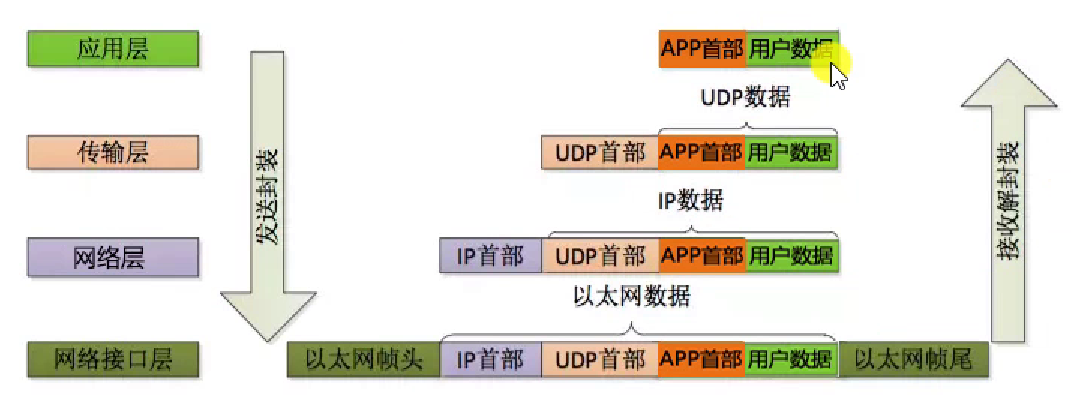
4.4.2 ARP 协议
地址解析协议:通过 IP 找 MAC 地址。把 ip 封装成 ARP 包,加上以太网帧头尾,进行广播,与目标地址相同的进行应答。
命令:arp -a

4.5 字节序
4.6.1 字节序理解
即大端小端。大端指:整数的高位在低地址,输出是“顺”的;小端指:低位在高地址,输出是“反”的。
举个例子,0x112233,最高字节是 11,最低字节是 33,则大端时输出其字节(访存是从低地址开始,往高地址读取),最高位在低地址,所以是 0x11,0x22,0x33;即与人读的顺序(从左往右)一致,人先看先读的就是高位。小端则相反,先拿到的是低位数据,因为低位放在低地址。
可以通过强制转为unsigned char *输出每一 byte,也可以创建一个 union,里面定义一个数据类型 x,一个char 数组,这样输出 char 数组就可以得知 x 的字节序
4.6.2 字节序转换函数
TCP/IP 中将网络字节序规定为:大端序。发送端如果是小端机则要先转换为大端序,接收端按大端序解释,后面随便(转换成你的主机字节序)。
网络中端口、IP 都没有负数,都采用 unsigned 格式。【注意是整数类型之间的转换,与inet_pton()等函数区别】
#include <arpa/inet.h>
/* h->host; n->net; s->short(unsigned short: 2B); l->long(unsigned int: 4B) */
uint16_t htons(uint16_t hostshort); // short 一般用来转换 端口 地址(2B)
uint16_t ntohs(uint16_t netshort);
uint32_t htonl(uint32_t hostlong); // long 一般用来转换 IP 地址(4B)
uint32_t ntohl(uint32_t netlong);
这里有一个定义 ip 的操作:先定义到字节数组里面,然后对其进行指针类型转换即可。
char buff[4] = {192, 168, 5, 11};
unsigned long x = *((unsigned long *)buff);
unsigned long y = htonl(x);
unsigned char *p = (unsigned char *)&x;
unsigned char *q = (unsigned char *)&y;
printf("x: %d.%d.%d.%d\n", *p, *(p + 1), *(p + 2), *(p + 3));
printf("y: %d.%d.%d.%d\n", *q, *(q + 1), *(q + 2), *(q + 3));
4.6 IP 地址转换函数
作用:格式转换
- 点分十进制 IP 地址/16 进制 IPv6 地址(即字符串) 网络字节序整数(二进制数)
- 主机字节序 网络字节序
/*a->address; n->network,即网络字节序的整数; p->point,即点分十进制字符串*/
#include<arpa/inet.h>
// 【不推荐使用】
in_addr_t inet_addr(const char *cp); // 字符串IP 转换为 大端 整数 IP
int inet_aton(const char *cp, struct in_addr *inp);
char *inet_ntoa(struct in_addr in);
// 下面俩同时适用IPv4和IPv6【推荐使用】
int inet_pton(int af, const char *src, void *dst);
const char *inet_ntop(int af, const void *src, char *dst, socklen_t size);
af:地址族,AF_INET,AF_INET6二选一src:点分十进制 IP 字符串 or 网络字节序的二进制整数dst:【传出参数】网络字节序的二进制整数 or 点分十进制 IP 字符串size:指定 dst 的大小(dst 字符数组的大小)返回值:转换后的地址,与dst中内容一样(整数 to 字符串的情况)
4.7 TCP 介绍
4.7.1 三握&四挥
-
为什么要三次握手而不是两次?
- 因为如果 A 第一次请求连接时,发生了超时重传,重传的与 B 建立并完成了连接。但是第一次超时的连接请求,兜兜转转又传到了 B,如果采用的两次握手,则 B 又一次与 A 建立了连接,在 A 不知情的情况下,这显然是不合适的。如果采用三次握手,则 B 收到这个迟到的请求后,会向 A 进行确认,而 A 直到这是一个过期的请求,因此不予理会,那么建立连接失败。(被动方重传的是它的 FIN,直到收到主动方的 ACK 为止)
-
为什么主动断开的一方,要等待 2MSL(Maximum Segment Lifetime:两倍的最长报文段寿命)才能关闭
-
保证 A 发的最后一个确认报文段(即第四次挥手)能准确到达 B,如果 A 不等待 2MSL 就关闭,且此时第四次回收的报文丢了,A 无法再重传,那么 B 就无法正常关闭。
-
同采用三次握手的原因类似,等待 2MSL 可以保证本次连接中产生的所有报文段都从网络中消失。以免产生“已失效的连接请求报文段”等问题。
-
4.7.2 滑动窗口
4.7.3 拥塞控制
4.7.4 TCP 通信流程
 |
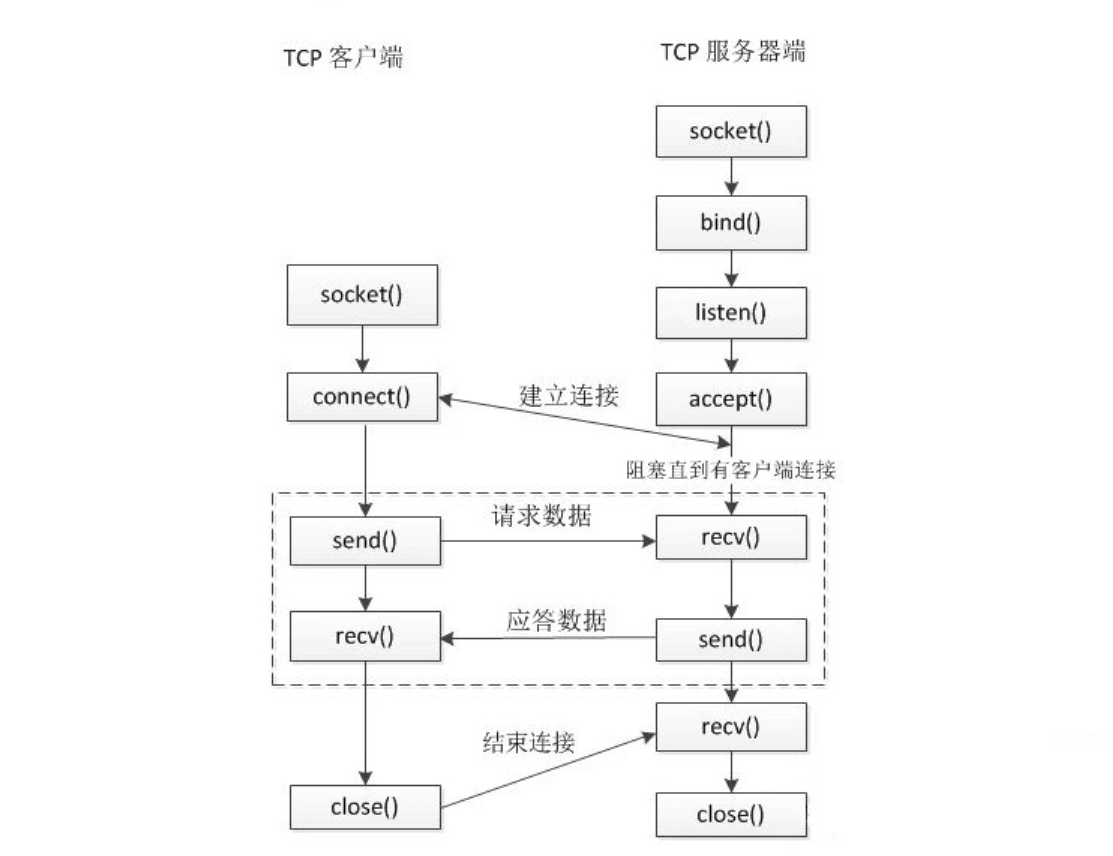 |
4.7.5 TCP 状态转换
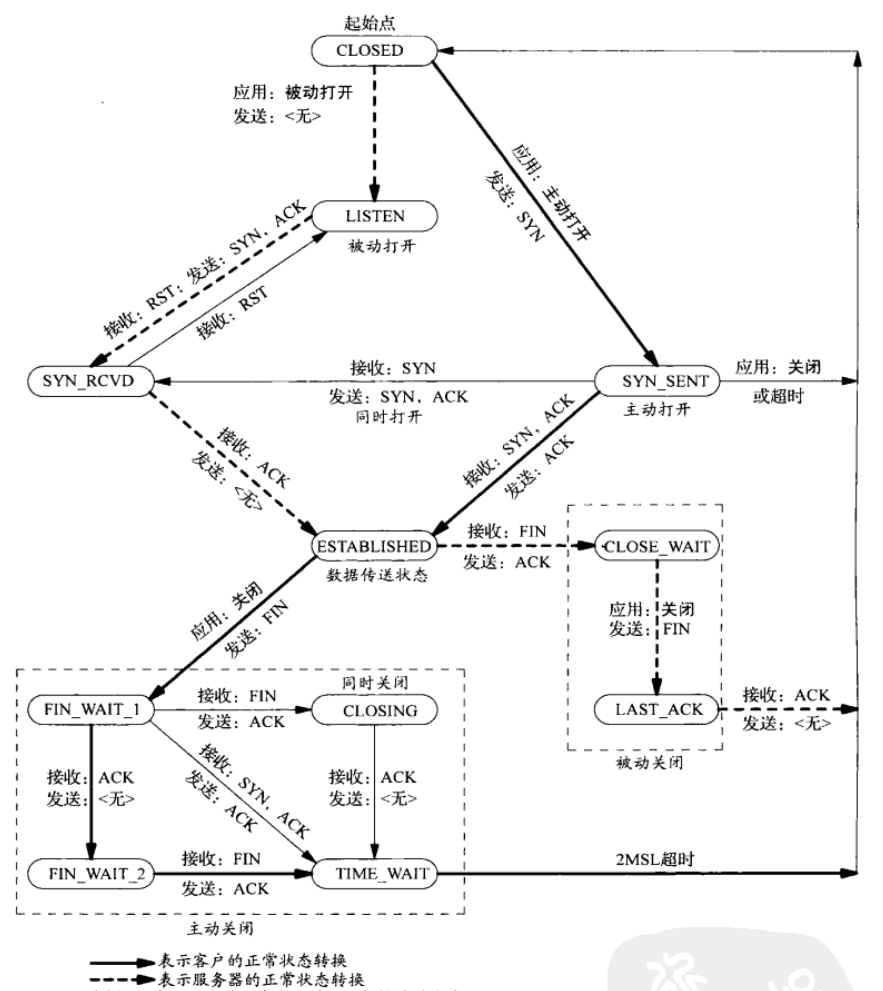 |
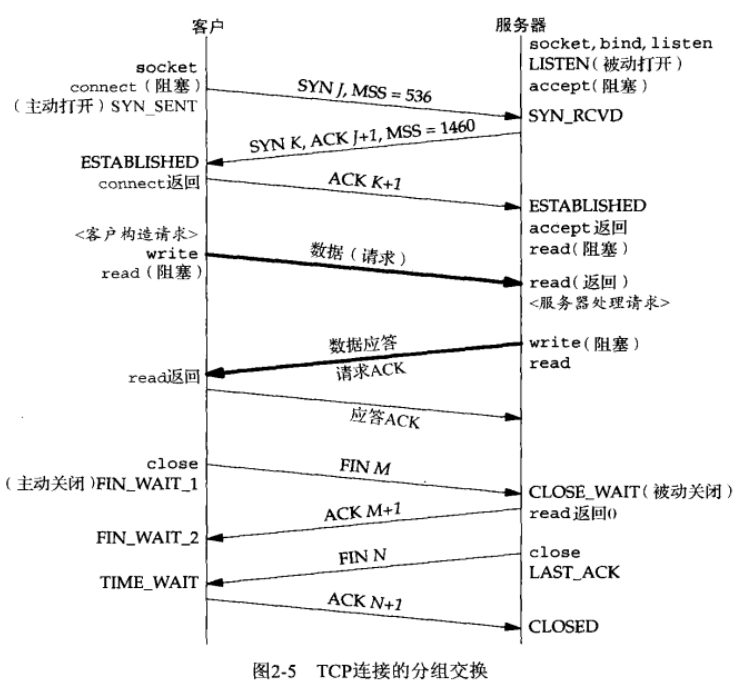 |
4.7.6 半关闭状态
第一次挥手后,被动方给主动方发送 ACK,但尚未发送 FIN,此时主动方进入 FIN_WAIT_2 状态,这时的主动方,可以接受被动方发来的消息,但是无法发出消息,即半关闭(半连接)状态。可以通过 API 来控制这一状态。
int shutdown(int sockfd, int how);
how:允许 shutdown 操作选择以下几种方式
SHUT_RD(0):关闭 sockfd 上的读功能,该套接字不再接收数据,其接收缓冲区中的数据将被直接丢弃SHUT_WR(1):关闭 sockfd 上的写功能,进程无法再对此 socket 进行写操作SHUT_RWDR(2):关闭 sockfd 读写功能,相当于调用 shutdown 两次
注意区别:使用close() 中止连接,即发送 FIN,但这只是减少 socket 描述符的引用计数,不会直接关闭。只有等引用计数减为 0 时才真正关闭。而 shutdown() 是立刻关闭连接,或者关闭一个方向,不考虑引用计数。即多进程通信时,一个进程调用 close 并不会影响别的进程通信,但有人调用的 shutdown 则都不能通信了。
4.8 socket 通信
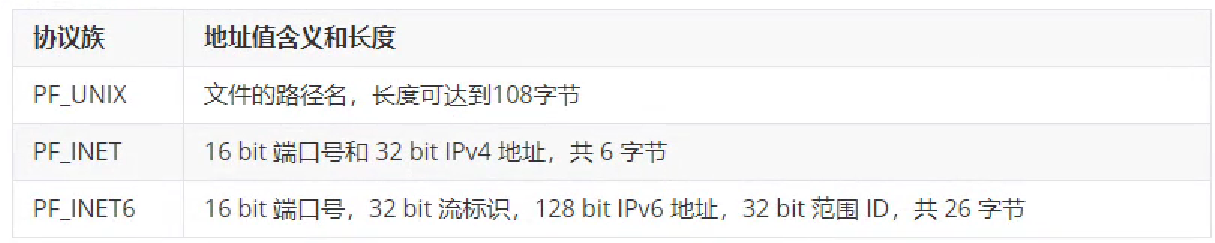
4.8.1 socket 地址
socket(套接字(插座)),就是对网络中不同主机上的应用进程之间进行双向通信的端点的抽象,一个套接字就是网络上进程通信的一端。上联应用进程,下联网络协议栈。socket 是一个伪文件。
(1)通用 socket 地址
表示 socket 地址的是一个结构体,有两个:sockaddr 和 sockaddr_storage,定义如下:
#include <bits/socket.h>
typedef unsigned short int sa_family_t; // 2B
struct sockaddr {
sa_family_t sa_family; // 表示地址族类型,与协议族对应,通常可以混用
char sa_data[14]; // 存放socket地址值。不同协议族的地址具有不同的长度和含义
};
struct sockaddr_storege {
sa_family_t sa_family;
unsigned long int __ss_align;
char __ss_padding[ 128 - sizeof(__ss_align) ];
};
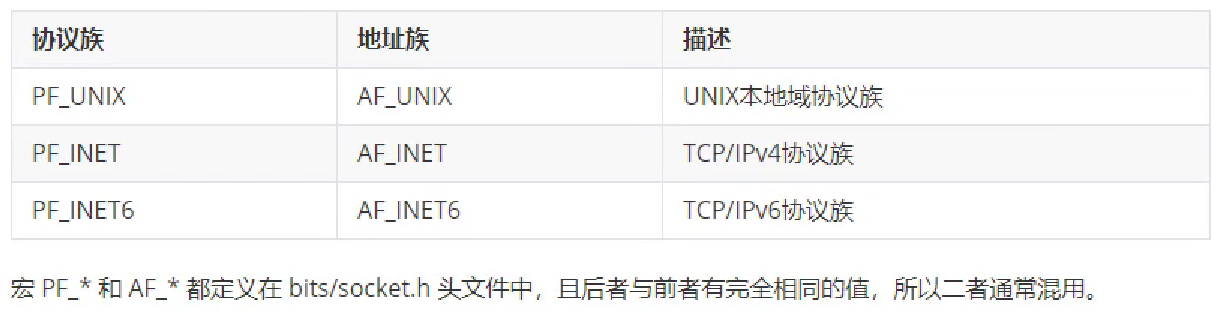 |
 |
上图可见,sockaddr 中的 14B 的 data 是不够容纳所有协议的地址的,因此又新定义了一个 sockaddr_storage,以便容纳更长的地址,并且它是内存对齐的。
(2)专用 socket 地址
很多网络编程的函数诞生是早于 IPv4 协议的,当时用的都是 sockaddr 结构体,为了向前兼容,现在 sockaddr 退化成了,类似 void* 的作用,就是说,不管你是什么地址,统统转为 sockaddr 类型传给函数。至于这个地址到底怎么解释,是sockaddr_in还是sockaddr_in6,由协议族字段确定,然后函数内部再强制类型转换为相应的地址。
所有的专用 socket 地址(包括 socket_storage)都要强制转换为通用 socket 地址类型(即 sockaddr),因为所有 socket 编程接口的地址参数类型都是sockaddr
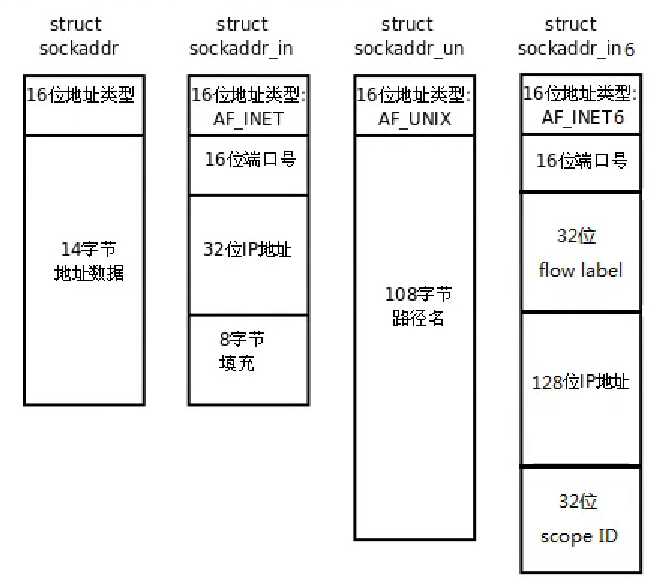
/* sockaddr_in: TCP/IP协议族中IPv4的sock地址,sockaddr_in6 则是IPv6的地址 */
#include <netinet/in.h>
struct sockaddr_in {
sa_family_t sin_family; // 协议族(AF_INET <=> PF_INET)
in_port_t sin_port; // 端口号(16位无符号,2B)
struct in_addr sin_addr; // IP地址(32位五符号,4B)
/*填充的部分*/
unsigned char sin_zero[sizeof(struct sockaddr) - __SOCKADDR_COMMON_SIZE -
sizeof(in_port_t) - sizeof(struct in_addr)];
};
// 类型参考
struct in_addr {
in_addr_t s_addr;
};
typedef uint16_t in_port_t;
typedef uint32_t in_addr_t;
#define __SOCKADDR_COMMAN_SIZE ( sizeof(unsigned short int) )
-
sockaddr_in 地址指定方法为:
struct sockaddr_in addr; // 开始赋值: addr.sin_family = AF_INET; // IPv4 addr.sin_port = hton(9999); // 字节序转换 // 使用 IP 转换函数给需要的整形 sin_addr 赋值 inet_pton(AF_INET,"192.168.5.11", (void*)&addr.sin_addr.s_addr); // 也可以采用下面偷懒的写法。客户端不行,客户端一定要指定你想连接哪个服务器 addr.sin_addr = INADDR_ANY; // 其实就是0.0.0.0,表示客户端进来任意地址都可以绑定
4.8.2 socket 函数
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h> // 包含了这个,上面的两个可以省略
/* 1. 服务端建立 */
int socket (int domain, int type, int protocal);
int bind (int sockfd, const struct sockaddr *addr, socklen_t addrlen);
int listen (int sockfd, int backlog); /* /proc/sys/net/core/somaxconn */
int accept (int sockfd, struct sockaddr *addr, socklen_t *addrlen);//长度是指针!!
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
/* 2.1 读写函数 */
ssize_t write (int sockfd, const void *buf, size_t len);
ssize_t read (int sockfd, void *buf, size_t len);
/* 2.2 socket 专有的读写函数(就多了个 flags 选项) */
ssize_t recv (int sockfd, void *buf, size_t len, int flags);
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags,
struct sockaddr *src_addr, socklen_t *src_addr_len);
ssize_t send (int sockfd, const void *msg, size_t len, int flags);
ssize_t sendto (int sockfd, const void *msg, size_t len, int flags,
const struct sockaddr *to_addr, socklen_t to_addr_len);
/* 3. 关闭socket连接,参见 4.7.6 半关闭 */
int close (int sockfd);
int shutdown (int sockfd, int how);
/* 4. 设置 socket 属性,参见 4.9.3 端口复用 */
int getsockopt(int sockfd, int level, int optname, void *optval, socklen_t*optlen);
int setsockopt(int sockfd, int level, int optname,const void *optval, socklen_t optlen);
- socket():获取一个套接字(
cman 2 socket)domain:协议族,AF_INET , AF_INET6, AF_UNIX/AF_LOCAL...type:通信过程中使用的协议类型(流 报...),SOCK_STREAM,SOCK_DGRAM,SOCK_SEQPACKET...protocal:具体的协议,一般传0。流式协议默认TCP,报式默认UDP返回值:成功返回 socket 文件描述符,失败返回 -1
- bind(): 将 套接字 和 本地的 IP + 端口 绑定。
sockfd:上一步创建的 socketaddr:本地(服务器的) IP 和 端口 结构体addrlen:addr 的大小返回值:成功 0, 失败 -1
- listen():监听指定 socket 上的链接。listen 时有两个队列:已连接的和未连接的
sockfd:要监听的 socket,即刚通过socket()获得的那个backlog:两个套接字队列的总最大长度(似乎与 man 手册不一样,查)(在 somaxconn 中定义)
- accept():从用于 listen 的那个 socket 获取进来的客户端信息,然后返回一个用于通信的新 socket【阻塞】
sockfd:用于监听的那个 socket(即listen()用的那个),因为要从里面的缓冲区读取客户端的数据addr:传出参数,记录连接成功后,链进来的 客户端的 IP 和 端口addrlen:是指针!!!,不能直接 sizeof 了,先定义一个变量。返回值:成功返回用于通信的 socket 描述符,失败返回 -1
- connect():客户端调用,用于连接服务器
sockfd:客户端自己创建的,用于通信的文件描述符addr:要连接的服务器的 IP 和 端口addrlen:addr 的 size返回值:成功 0,失败 -1
- recv():从指定 sockfd 中接收消息到 buf 中,其
flags取值如下:recv(2)MSG_WAITALL:阻塞,直到所有的 request 都满足才返回,除非中间出现错误或异常(信号、断连)MSG_DONTWAIT:不阻塞,不能读就直接返回MSG_CMSG_CLOEXEC:一执行,就把接受的 fd 关闭(只接收一次呗)0:啥也不干,跟 read 一样
- send():给指定 sockfd 发送 buf 中的内容,其
flags取值如下:send(2)MSG_DONTWAIT:不阻塞,不给发就返回MSG_NOSIGNAL:不产生SIGPIPE信号MSG_EOF:shutdown 发送方向的连接,并发送一个数据尾标识(仅对 IPv4 的 TCP 有效)0:啥也不干,跟 write 一样
4.9 并发服务器开发
4.9.1 多进程并发
基本模型:
- 父进程循环 accept(),阻塞等待。有客户端链接进来,则创建一个子进程去与之通信,父进程继续回去阻塞等待 accept。
- 父进程中应注册信号捕捉函数捕捉
SIGCHILD信号,以便在子进程完成通信后回收它。回收的处理函数应当是一个非阻塞的循环 waitpid,有子进程在工作就返回父进程,使其得以继续监听。 - 注意,执行回调函数回收子进程,相当于一次软中断。而accept() 是会被系统中断打断的,也就是说,等回调函数返回时,accpet 会被打断,返回 -1,并设置
errno为EINTR。要解决这个问题,便要在 accept 的返回值为 -1 时进行一次判断,如果errno == EINTR,则 continue 即可。
4.9.2 多线程并发
多线程的思想同多进程类似,也是主线程负责监听,接收到一个就创建一个子线程去处理。这里有一些关于传参的问题:
-
创建线程,我有多个参数:客户端信息、线程号、通信文件描述符......,如何把这些参数传递给线程的回调函数呢?
很简单,只需要创建一个结构体,然后传递结构体指针即可。 -
创建的结构体,如果放在主线程的 while 循环中,即一个局部变量,那肯定是不行滴,传参不能传局部变量的指针,因为下一个循环它就没有了。
法一:给结构体在堆上分配内存(用 malloc 或 new),缺点是需要自己管理内存
法二:把结构体创建成一个全局变量。但是既然是多线程环境,如果要同时提供多个服务,都要传参,那肯定是需要一个结构体数组了。 -
既然要预先创建数组,那你得指定大小呀。指定了大小,就会有不够用的问题。也即,首先要确定,怎么从数组中找出当前可以用的结构体呢?如果找不到(用完了)又该怎么办呢?
首先是怎么找:当然是循环遍历了。如果是遍历结构体数组,那么开始时要对结构体数组进行初始化,将其中的客户端文件描述符置为-1,线程使用完后同样置为-1。这样,遍历找 client_fd 不是 -1 的结构体就好了
也可以设置一个可用数组,甚至可以采用位图的方法,专门描述哪些结构体数组可用。
比如结构体数组大小设置为 128,那意思就是,我这个服务器,最多只能并发 128 个线程。那多的请求呢?比如遍历到最后没找着,那就让其先睡一会儿,然后再去从头或者别的地儿遍历一下。找不着接着睡
另外,对子线程采用pthread_join来回收显然也是不可取的,因为它会阻塞主线程。设置分离属性即可。
4.9.3 端口复用
- 防止服务器重启时,之前绑定的端口还没释放
- 程序突然退出系统而没有释放端口
比如正在运行的 server 和 client,突然 server 被关掉了,此时使用 netstat -anp 命令会发现,client 处于 close_wait 状态,服务器不存在了,监听端口状态也没了,但是这条连接的,服务器端口还在,并处于 fin_wait_2 状态,此时再结束客户端,服务器端口则处于 time_wait 状态(过一会就结束了)
就是说,服务器关闭了,但是 TCP 协议的任务还没完成,端口还被占用着。如果在这个 2MSL 的时间内,我想重启服务器,那么会发现,端口被占用了启动不了。为了避免这种情况,我们可以在绑定端口之前,指定端口复用属性。
netstat -anp
# -a 所有 socket
# -n 显示正在使用 socket 的程序的名称
# -p 直接使用 IP 地址,而不通过域名服务器
int getsockopt(int sockfd, int level, int optname, void *optval, socklen_t *optlen);
int setsockopt(int sockfd, int level, int optname,const void *optval, socklen_t optlen);
以上两个是设置/获取 socket 属性的函数,不只可以用来设置端口复用(UNP7.2(P150))
端口复用要在服务器绑定之前设置(socket 之后,bind 之前 setsockopt)
- sockfd:打开的 socket 描述符
- level:级别,选
SOL_SOCKET(把选项解释为 通用套接字代码) - optname:选项的名称,选
SO_REUSEADDR或SO_REUSEPORT - optval:端口复用的值,
0表示不可以复用,1表示可以复用【int 型】 - optlen:optval 的长度,注意是否是指针。(因为 optval 不只是 int,还可以是 struct,参见 UNP)
4.10 IO 模型
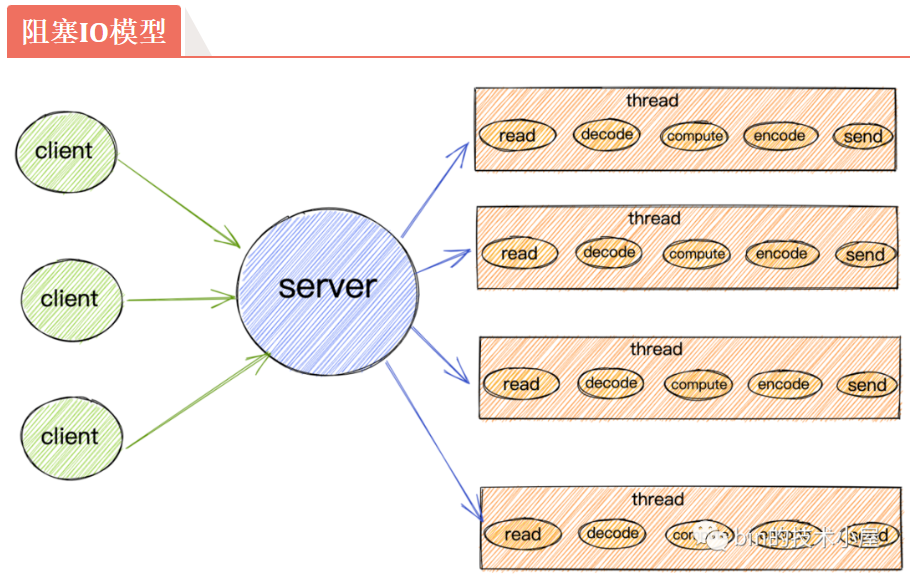
4.10.1 BIO(阻塞)
- 好处是不占用 CPU 资源,但是效率不高。accept 会阻塞,read 也会阻塞,服务器就干不了别的事了,一次一个
解决方法是,创建多个线程,让别的线程去进行交互,这样主线程一直监听,就可以实现并发。
- 这样仍有缺点:可能会瞬间产生大量的线程,大量的线程并发会消耗很多资源,而其中大部分都是在阻塞中,并没有干活
但根本的问题没解决:即这是一个阻塞的模型,阻塞,就导致程序不能走下去,才会有后面的一系列问题
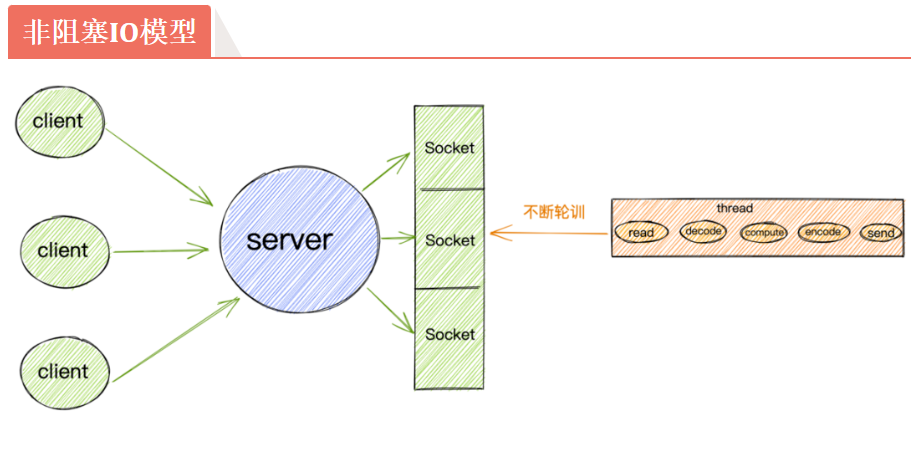
4.10.2 NIO(非阻塞)
要遍历去询问准备好了没(O(n))。这种模型已经可以做到:用很少的线程去处理多个连接了。
- 但是仍有弊端:每一次遍历寻找就绪的 socket,都是一次系统调用,不断调用非常浪费 CPU 资源。那不系统调用了,这轮询的工作直接让内核去做不就行了?
=> IO 多路转接/复用技术,
委托内核去帮我们做轮询 => select ,但是 select 只告诉你到了几个,不会说具体哪一个
内核直接帮你把谁到了都检测出来 => epoll
 |
 |
 |
 |
4.10.3 根本区别
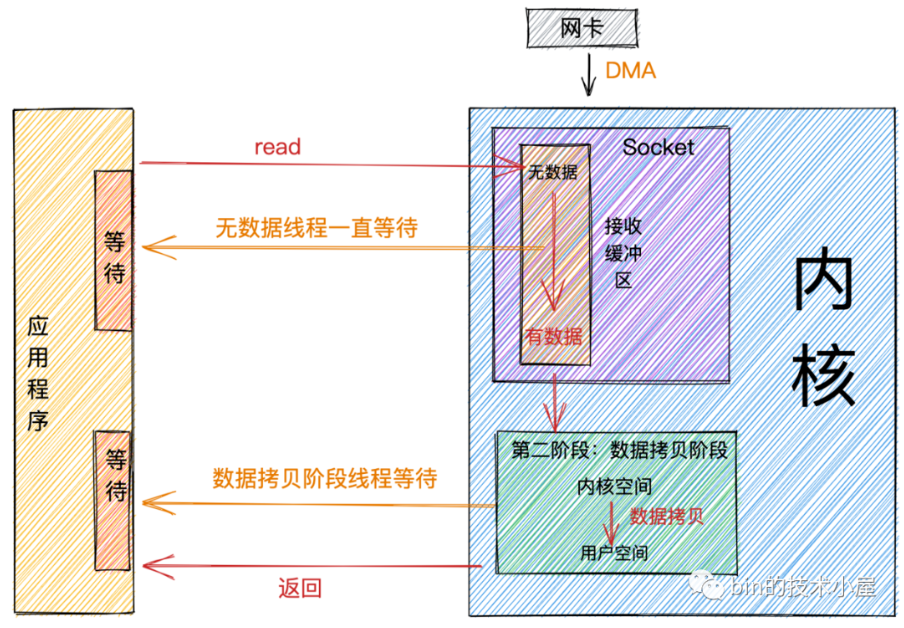
对网络数据包接收流程可以分为两个阶段:
- 数据准备阶段: 在这个阶段,网络数据包到达网卡,通过
DMA的方式将数据包拷贝到内存中,然后经过硬中断,软中断,接着通过内核线程ksoftirqd经过内核协议栈的处理,最终将数据发送到内核Socket的接收缓冲区中。 - 数据拷贝阶段: 当数据到达
内核Socket的接收缓冲区中时,此时数据存在于内核空间中,需要将数据拷贝到用户空间中,才能够被应用程序读取。
 |
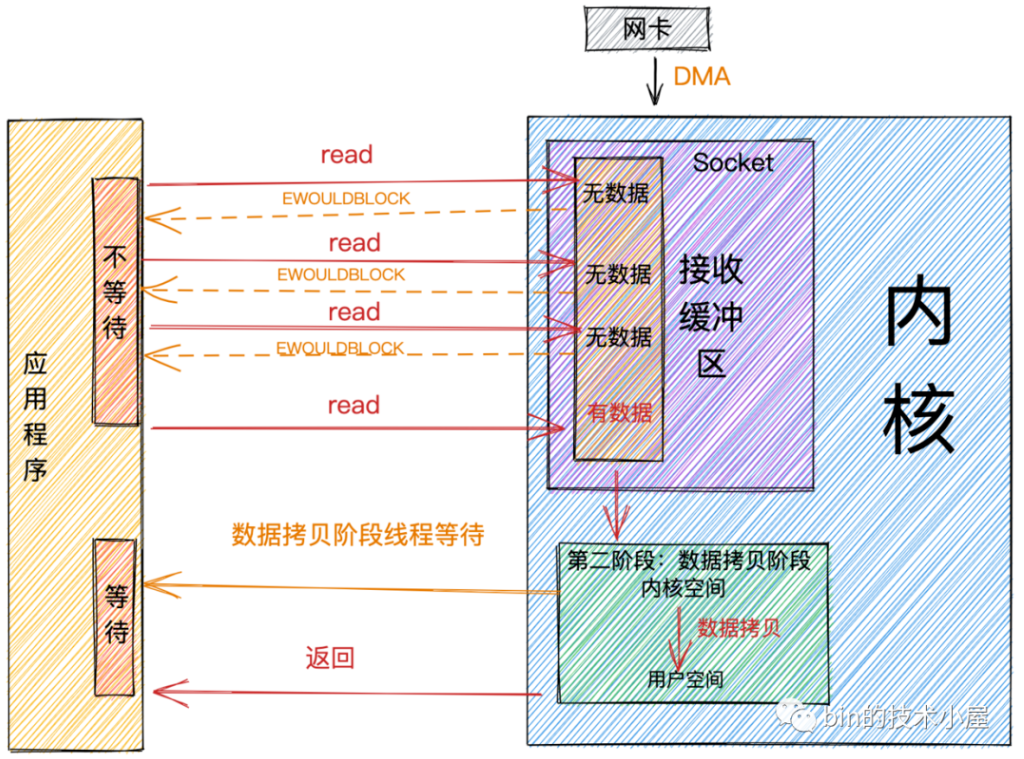 |
阻塞 IO ,就是会在第一阶段,数据准备阶段 阻塞,非阻塞 IO 就是在第一阶段不阻塞,如果读不到,就直接返回。而无论阻塞非阻塞,在第二阶段都是阻塞的。在第二阶段阻塞的叫同步 IO,在第二阶段不阻塞的叫异步 IO
4.10.4 同步与异步 IO
同步模式在数据准备好后,是由用户线程的内核态来执行第二阶段。所以应用程序会在第二阶段发生阻塞,直到数据从内核空间拷贝到用户空间,系统调用才会返回。
异步模式下是由内核来执行第二阶段的数据拷贝操作,当内核执行完第二阶段,会通知用户线程 IO 操作已经完成,并将数据回调给用户线程。所以在异步模式下 数据准备阶段和数据拷贝阶段均是由内核来完成,不会对应用程序造成任何阻塞。
基于以上特征,我们可以看到异步模式需要内核的支持,比较依赖操作系统底层的支持。
4.11 IO 多路复用
I/O 多路复用使得程序能够同时监听多个文件描述,能够提高程序的性能。Linux 下实现 I/O 多路复用的系统调用主要有:select、poll、epoll
4.11.1 select
主旨思想:
- 首先要构建一个文件描述的列表,将要监听的文件描述符添加到其中
- 调用一个系统函数(select),监听该列表中的文件描述符,(阻塞)直到其中有人进行了 IO 操作才返回
- 返回时会告诉有多少文件描述符到达了数据
#include <sys/select.h>
/* 让内核监听列表中的文件描述符 */
/* sizeof(fd_set) = 128B = 1024 位,用位来表示对应的文件描述符 */
int select (int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds,
struct timeval *timeout);
void FD_CLR (int fd, fd_set *set); // 将 fd 对应的标志位置 0
void FD_SET (int fd, fd_set *set); // 将 fd 对应的标志为置 1
int FD_ISSET(int fd, fd_set *set); // 判断 fd 对应的标志位是否为 1,并返回该标志位值
void FD_ZERO (fd_set *set); // 将 set 中标志位全置为 0
nfds:委托内核进行检测的文件描述符 最大数量 + 1(加 1 才能遍历到 max,因为从 0 开始嘛)readfds:【传入传出参数】设置位,让内核检查读缓冲,看对应文件描述符上是否有谁发来数据可读,有的话不变,没有的话,就会把对应的位置为 0,再从内核拷贝回用户态writefds:让内核检查写缓冲,看是否有空余位置可写exceptfds:检查异常timeout:设置等待多久;如果为 0 表示不阻塞,为 NULL 表示永久阻塞返回值:大于 0 表示有 n 个文件描述符发生了变化,0 表示超时了且没有检测到,-1 表示失败
工作原理

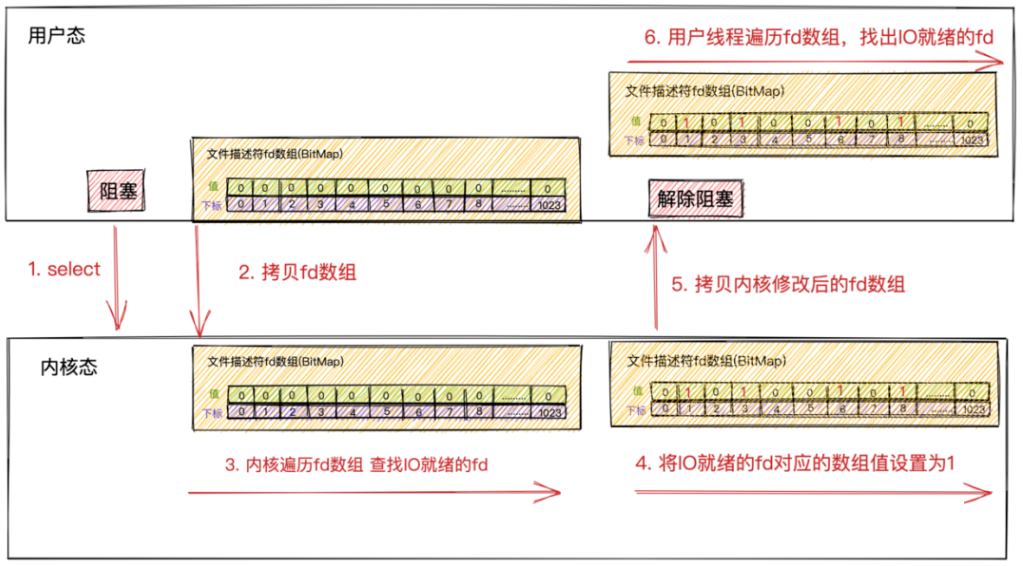
- select 会修改用户传进去的 fdset,因此如果你下次还想要监听相同的文件描述符,那就要重新填充 fdset
- select 只是把活跃的 fd 置 1,返回给用户。用户仍需要再遍历一次,才能找到活跃的 fd
- 你要做的就是,每接收到一个新的客户端,就把它的 sockfd 添加到 fdset 中,交给 select 去监听
编写代码
- 在 accept 之前,先定义一个 fdset,把监听的文件描述符加进去,然后传给 select,让内核去遍历这个 set
- 这里有一个细节:传给 select 的,应当是一个中间值(即新建一个 temp_set)因为内核会修改传入的 set,这显然是我们不希望的。定义一个中间值,每次循环都把我们定义的 set 赋值给它
- select 返回,如果返回的 tempset 里面,listen_fd 是 1,这个文件描述符上有数据,就说明有新的客户端进来了,需要去进行链接,即 accept,得到客户端的文件描述符,之后,将它添加到 set 中,更新 maxfd,然后传给内核继续 select 遍历
- 循环遍历 select 返回的 set,找到所有返回的文件描述符,然后处理上面的数据
- 如果处理数据时发现客户端断开连接,那么也应该清除其 set 位
【问题来了】,select 怎么多线程呢?新客户端进来之后,如果要创建新线程,那么新线程不还是要 BIO
select 的缺点:
- 需要在内核态和用户态来回拷贝 fdset(两次拷贝)(当然还有两次切换)
- 每次对内核返回的 set 都要进行遍历,O(n)
- select 支持的文件描述符太少了,就 1024
- fset 集合不能重用,每次都需要重置(内核会修改传入的 fdset,虽然有别的办法,但总归是机制不方便)
4.11.2 poll
poll 和 select 没有本质上的区别,只不过是,select 用的是 fdset 这么个位数组来传给内核,而 poll 用的是一个 pollfd 结构体数组来和内核传递消息。这就没有了 fd 最多 1024 的限制(但仍受限于系统的 fd 上限,这是显然的)。结构体数组中同时包括了文件描述符 和读写事件的区分,因此不需要分成三个 fdset 来传参
至于工作的过程,仍然需要拷贝,仍然需要轮询,仍不是能解决 C10k 问题(处理 10k 个并发连接)的好调度
#include <poll.h>
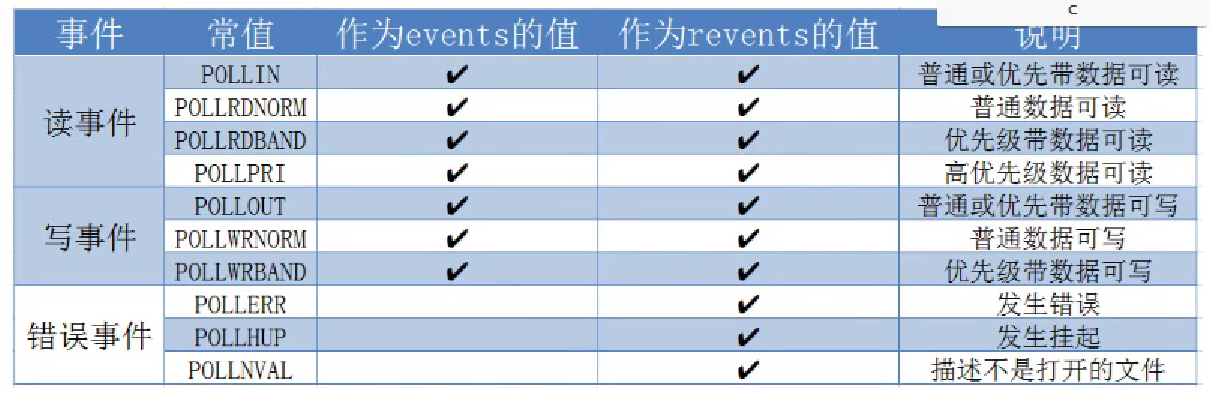
struct pollfd {
int fd; /* 委托内核进行检测的文件描述符 */
short events; /* 委托内核检测什么事 */
short revents; /* 内核反馈实际上发生了什么事 */
};
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
fds:同文件描述符表,只不过换成了结构体数组,没有 1024 的限制了nfds:fds 数组的有效下标 + 1timeout:0 不阻塞,-1 阻塞,>1 表示要阻塞的 毫秒 数返回值:-1 失败,n:fds 中有 n 个文件描述符有变化宏取值:使用多个用|,判断是否相等用&【注意,不能用 == 判断与某个宏值相等】
代码编写
- 创建一个 fds 结构体数组,初始化第一个元素为监听文件描述符,nfds 先置为 0,调用 poll
- 检查 poll 返回的数组,如果
fds[0].revents & PILLIN,说明有新客户端,则进行 accept;然后将新的客户端文件描述符加入到 fds 数组中,要用 for 循环遍历找空位,以免浪费,更新 nfds - 然后遍历 fds 数组,查找
revents & POLLIN的 fd,进行通信
poll 缺点
poll 改进了 select 的 3 4 缺点,即使用了一个结构数组,数组项可以重用了,也没有上限了。但仍有缺点:
- 仍然需要在内核态和用户态拷贝
- 仍然需要遍历。虽然告诉了你那几个发生了改变,但是并没有指出到底是谁,还是需要遍历
4.11.3 epoll
select 的性能瓶颈
无论是 select 还是 poll,它们都存在着下列问题:
- 内核不会保存我们要监听的 sockfd 列表,因此每次调用,都需要来回拷贝一整份的数组红黑树
- 内核不会通知具体是哪些 fd 就绪,只是在他们的数组位上打上标记,用户需要遍历才能找到双链表
- 内核也是通过遍历来寻找就绪的 socket fd 的回调函数
epoll 对这三个问题都进行了解决。它会在内核中创建一个 epoll 对象,这里面包括一个红黑树rbr:用来存放用户需要监听的文件描述符,和一个双向链表rdlist:用来保存内核找到的就绪描述符,并返回给用户。当然还有别的数据,比如一个阻塞队列wq:存放的是阻塞在 epoll 上的用户进程,在 IO 就绪的时候 epoll 可以通过这个队列找到这些阻塞的进程并唤醒它们,从而执行 IO 调用读写 Socket 的数据。
下面先看 epoll 的 API
epoll API
#include<sys/epoll.h>
/**epoll_create
* @brief : 创建一个新的 epoll 实例(即内核中创建了一块数据结构)
* - 需要检测的文件描述符信息(红黑树)
* - 和就绪列表,存放内核检测到发生变化的文件描述符(双链表)
* @parameter:
* A size: 没有意义,随便指定。(历史遗留问题,因为之前是用hash实现的)
* @return: -1失败,>0 指向内核实例的文件描述符*/
int epoll_create(int size);
struct epoll_event {
unint32_t events; // 发生了什么事件
epoll_data_t data; // 用户数据(Union),一般只用到 fd
};
typedef union epoll_data {
void *ptr;
int fd; // 用这个传递 fd(注意这是个 Union)
unint32_t u32;
unint64_t u64;
}epoll_data_t;
/**epoll_ctl
* @brief: 对 epoll 实例进行管理,比如添加个文件描述符
* @parameter:
* 1. epfd : create 返回的文件描述符,操作内核实例
* 2. op : 要进行什么操作
* # EPOLL_CTL_ADD: 往红黑树中添加文件描述符
* # EPOLL_CTL_MOD: 修改
* # EPOLL_CTL_DEL: 删除
* 3. fd : 要操作/添加的文件描述符
* 4. event: 检测文件描述符什么事件(结构体,包括事件和文件描述符(跟fd一样))
* # EPOLLIN : 写入
* # EPOLLOUT
* # EPOLLERR
*/
int epoll_ctl (int epfd, int op, int fd, struct epoll_event *event);
/**epoll_wait
* @brief : 真正的调用函数
* @parameter:
1. epfd :
2. event : 结构体数组,【传出参数】保存发生变化的文件描述符,以及发生了肾莫事
同样是一个指针,ctl函数中传入的是单个,wait函数传出的是数组
3. maxevent : 前一个结构体数组的大小
4. timeout : 0不阻塞,-1阻塞直到检测到数据发生变化,>0阻塞时常,单位毫秒
@return : 成功返回发生变化的文件描述符的个数 >0,失败返回-1
*/
int epoll_wait (int epfd, struct epoll_event *events, int maxevents, int timeout);
工作原理
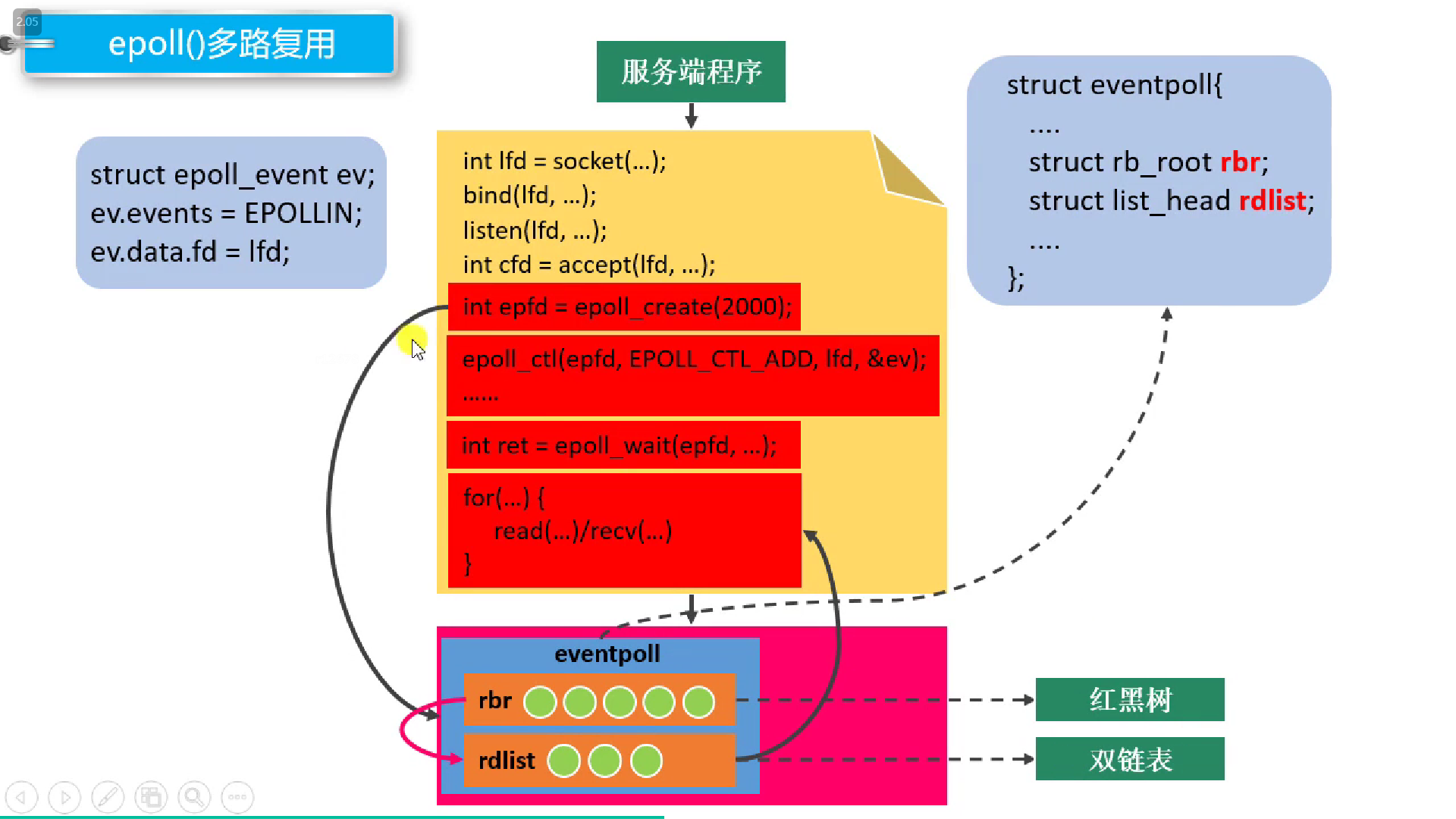
可见 epoll 解决了如下问题:
- 内核态和用户态来回拷贝的问题:直接在内核态创建一个数据结构
- 内核态增删:创建一个红黑树,高效增删
- 内核态查找就绪:注册回调函数,就绪了直接定位
- 返回后用户不只谁变化,还需要遍历:创建一个就绪链表,返回的直接就是所有变化的
❓ epoll 的回调函数
ep_poll_callback正是epoll同步 IO 事件通知机制的核心所在,也是区别于select,poll采用内核轮询方式的根本性能差异所在。(⛓️内核角度看 IO 模型,源码实现,以后再看)
epoll 优势总结
- 内核中通过
红黑树管理海量的连接,所以在调用epoll_wait获取IO就绪的 socket 时,不需要传入监听的 socket 文件描述符。从而避免了海量的文件描述符集合在用户空间和内核空间中来回复制。 - epoll 仅会通知
IO就绪的 socket。避免了在用户空间遍历的开销 - epoll 通过在 socket 的 等待队列 上注册回调函数
ep_poll_callback通知用户程序IO就绪的 socket。避免了在内核中轮询的开销。
代码编写
- 调用
epoll_create,直接在内核创建一个数据结构(红黑树),返回文件描述符。通过文件描述符可以去操作这个内核区的实例 - 调用
epoll_ctl把监听文件描述符添加EPOLL_CTL_ADD进内核的红黑树中 - 调用
epoll_wait来让内核干活,返回一个发生变化的文件描述符列表epoll_event结构体数组 - 遍历结构体数组的每一个,如果是监听的变了,就 accept,同时把新客户 ADD 进去;如果是别的,就进行数据传输,如果传输完了就把该客户 DEL 掉
两种工作模式
(1)LT 模式(水平触发)
缺省即为此模式,可以同时支持阻塞和非阻塞 socket。这种模式下,内核会告诉你一个文件描述符是否就绪了,然后你可以对此就绪的 fd 进行 IO 操作。如果你不操作,或者没操作完(没读完),内核下一次还是会继续通知你这个 fd 可操作。
即:只要 fd 缓冲区中有数据,epoll 就会一直通知(每一轮),直到读完
(2)ET 模式(边缘触发)
一种高速的工作方式,只支持 non-block socket,描述符变为就绪状态的时候,内核会通知你一次,后面就不会再为这个 fd 发送更多的信息了,直到某些操作导致其变为非就绪状态
即:只在第一次 fd 就绪的时候通知一下,后面不管是读完没读完,还是一直没读导致 fd 又变为非就绪,都不会再通知了。直到你进行了某些操作使其变为非就绪,才会再新的轮次中发送有关该 fd 的可用通知
两种模式比较
ET 很大程度上减少了 epoll 时间被重复出发的次数,因此效率比 LT 高。必须使用非阻塞接口,以免由于一个 fd 阻塞而把多个 fd 饿死
本质区别就在于:
- LT 模式下,线程调用 epoll_wait 操作一通 sockfd 之后,再次调用 epoll_wait 的时候,epoll_wait 会检查 socket 缓冲区中是否还有数据,是否读干净了。如果没读干净,那么就会把这个 sockfd 再次放进
rdlist中,然后下次调用的时候还会返回这个 sockfd,还能接着读 - 而 ET 模式下,这一次调用了 epoll_wait 之后,直接就把就绪队列
rdlist清空了,因此,不管你读没读,完没完,你下次都读不到这个 sockfd 了。除非,这个 socket 上有新的 IO 数据到达,根据 epoll 的工作过程,该 socket 会被再次放入rdllist中。
4.12 IO 线程模型
5 种 IO 模型是从内核空间的视角,来剖析网络数据的收发模型。而站在用户空间的视角,即可得到两种 IO 线程模型。即 Reactor 模型和 Proactor 模型
这些用户空间的IO线程模型都是在讨论当多线程一起配合工作时谁负责接收连接,谁负责响应 IO 读写、谁负责计算、谁负责发送和接收,仅仅是用户 IO 线程的不同分工模式罢了。
4.12.1 Reactor
Reactor是利用NIO(非阻塞)对IO线程进行不同的分工
- 使用 IO 多路复用模型比如
select, poll, epoll, kqueue,进行 IO 事件的注册和监听。 - 将监听到就绪的 IO 事件分发
dispatch到各个具体的处理Handler中进行相应的 IO 事件处理。
Reactor 模型依赖 IO 多路复用技术(epoll),来实现监听 IO 事件,不断的分发dispatch,就像一个反应堆一样,看起来像不断的产生 IO 事件,因此我们称这种模式为Reactor模型。
具体分为三类:
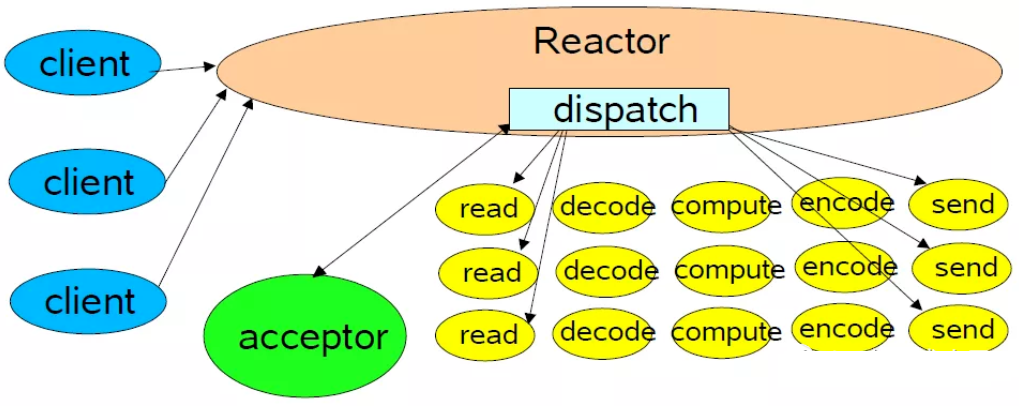 |
 |
 |
| 单Reactor单线程 | 单Reactor多线程 | 主从Reactor |
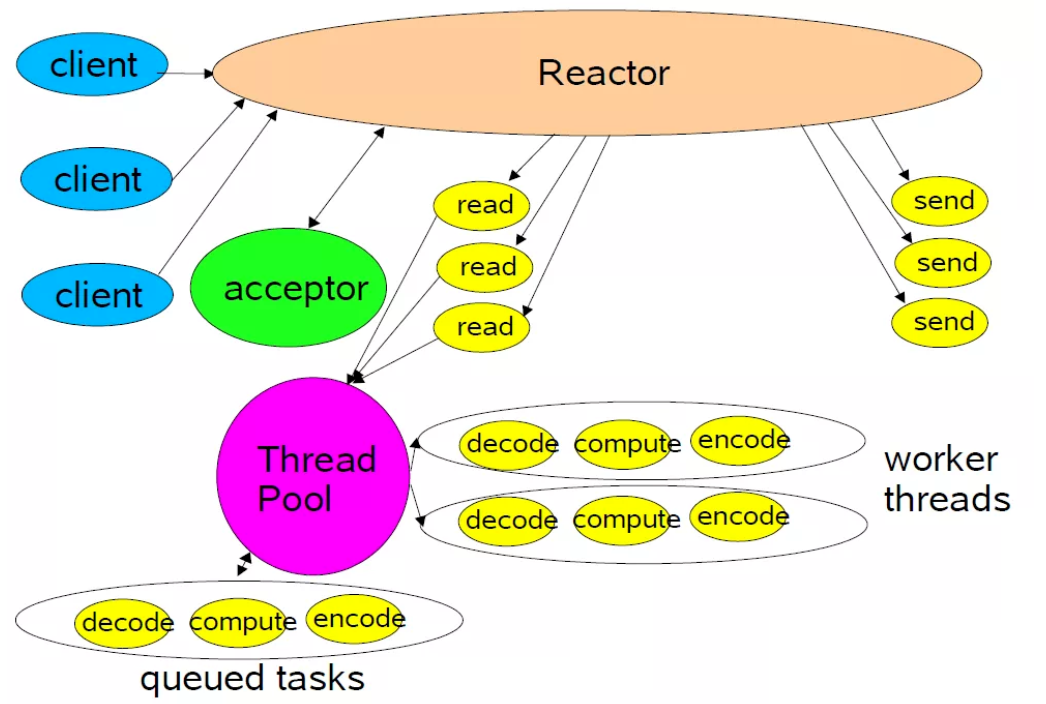
单 Reactor 单线程
- 单 Reactor 意味着只有一个 epoll 对象,用来监听所有的事件,比如连接事件,读写事件。
- 单线程 意味着只有一个线程来调用
epoll_wait,获取 IO 就绪的 Socket,然后对这些就绪的 Socket 执行读写,以及后边的业务处理也依然是这个线程。
相当于一个线程(小老板)要完成 accept 事件(迎客) 、接受 IO 请求(顾客点菜)、业务处理(做菜)、IO 响应(上菜)、断开连接(送客)
单 Reactor 多线程
- 仍然是一个 epoll 对象监听所有 IO 事件, 一个线程来调用
epoll_wait来获取所有就绪 socket - 但是处理 IO 事件的对应的业务 Handler 时,使用的是线程池,因此提高了执行效率
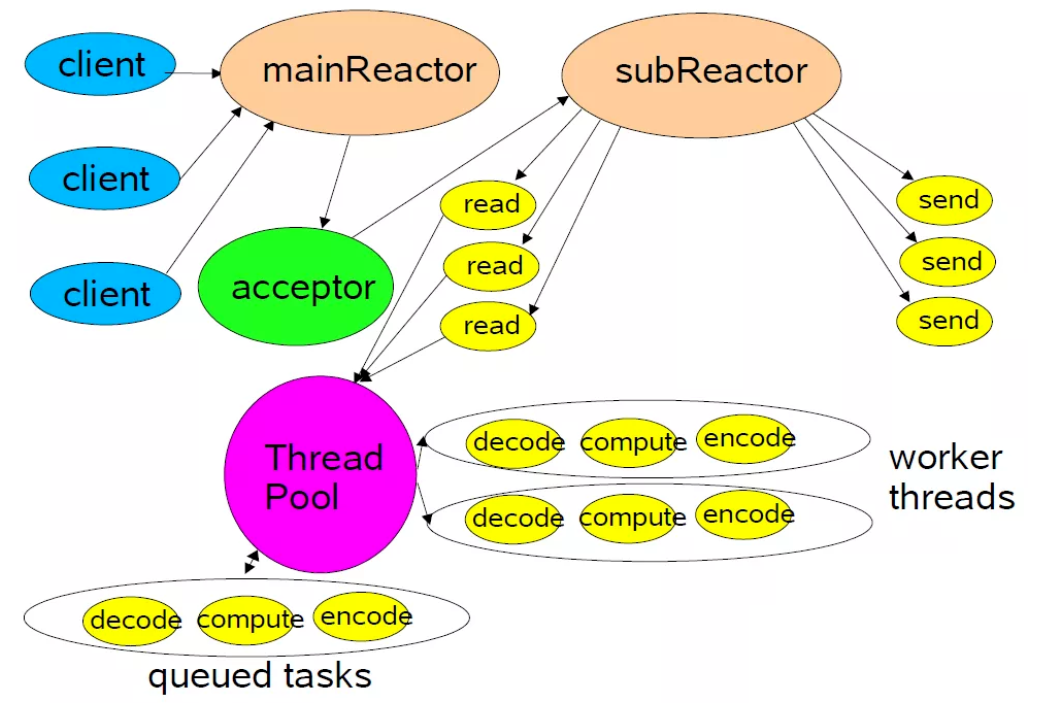
主从 Reactor
- 主 Reactor 专门用来迎接客人(接受新连接),对应的 Handler 就是 acceptor
- 从 Reactor 则负责招待客人(后续业务),在 acceptor 中将要监听的
read 事件注册到从 Reactor中,由从 Reactor 来监听 socket 上的读写事件
注意:这里向
从Reactor注册的只是read事件,并没有注册write事件,因为read事件是由epoll内核触发的,而write事件则是由用户业务线程触发的(什么时候发送数据是由具体业务线程决定的),所以write事件理应是由用户业务线程去注册。
用户线程注册
write事件的时机是只有当用户发送的数据无法一次性全部写入buffer时,才会去注册write事件,等待buffer重新可写时,继续写入剩下的发送数据、如果用户线程可以一股脑的将发送数据全部写入buffer,那么也就无需注册write事件到从Reactor中。
4.12.2 Proactor
Proactor是基于AIO对IO线程进行分工的一种模型。前边我们介绍了异步IO模型,它是操作系统内核支持的一种全异步编程模型,在数据准备阶段和数据拷贝阶段全程无阻塞。
ProactorIO 线程模型将 IO事件的监听,IO操作的执行,IO结果的dispatch统统交给内核来做。
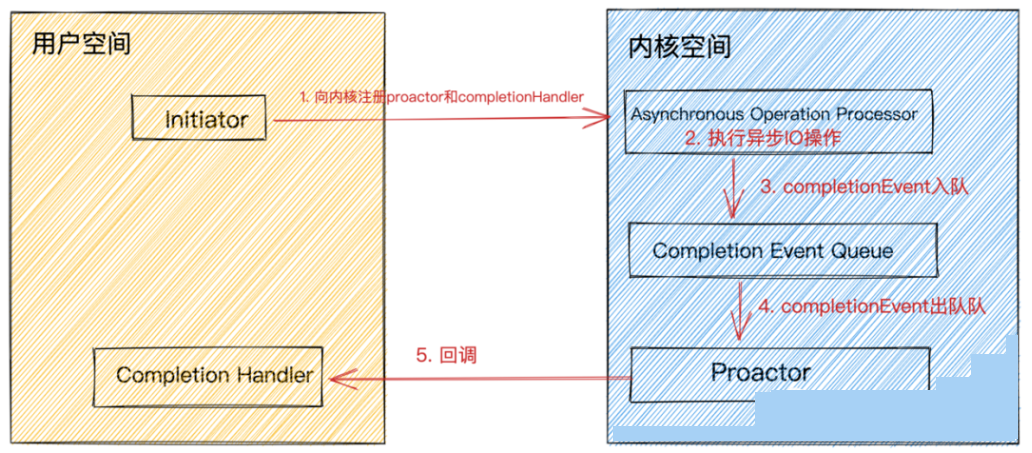
模型组件介绍
completion handler为用户程序定义的异步 IO 操作回调函数,在异步 IO 操作完成时会被内核回调并通知 IO 结果。Completion Event Queue异步 IO 操作完成后,会产生对应的IO完成事件,将IO完成事件放入该队列中。Asynchronous Operation Processor负责异步IO的执行。执行完成后产生IO完成事件放入Completion Event Queue队列中。Proactor是一个事件循环派发器,负责从Completion Event Queue中获取IO完成事件,并回调与IO完成事件关联的completion handler。Initiator初始化异步操作(asynchronous operation)并通过Asynchronous Operation Processor将completion handler和proactor注册到内核。
执行过程
- 用户线程发起
aio_read,并告诉内核用户空间中的读缓冲区地址,以便内核完成IO操作将结果放入用户空间的读缓冲区,用户线程直接可以读取结果(无任何阻塞)。 Initiator初始化aio_read异步读取操作(asynchronous operation),并将completion handler注册到内核。
在
Proactor中我们关心的IO完成事件:内核已经帮我们读好数据并放入我们指定的读缓冲区,用户线程可以直接读取。在Reactor中我们关心的是IO就绪事件:数据已经到来,但是需要用户线程自己去读取。
- 此时用户线程就可以做其他事情了,无需等待 IO 结果。而内核与此同时开始异步执行 IO 操作。当
IO操作完成时会产生一个completion event事件,将这个IO完成事件放入completion event queue中。 Proactor从completion event queue中取出completion event,并回调与IO完成事件关联的completion handler。- 在
completion handler中完成业务逻辑处理。
4.12.3 两线程模型比较
Reactor是基于NIO实现的一种 IO 线程模型,Proactor是基于AIO实现的 IO 线程模型。Reactor关心的是IO 就绪事件,Proactor关心的是IO 完成事件。Proactor中,用户程序需要向内核传递用户空间的读缓冲区地址。Reactor则不需要。这也就导致了在Proactor中每个并发操作都要求有独立的缓存区,在内存上有一定的开销。Proactor的实现逻辑复杂,编码成本较Reactor要高很多。Proactor在处理高耗时 IO时的性能要高于Reactor,但对于低耗时 IO的执行效率提升并不明显。
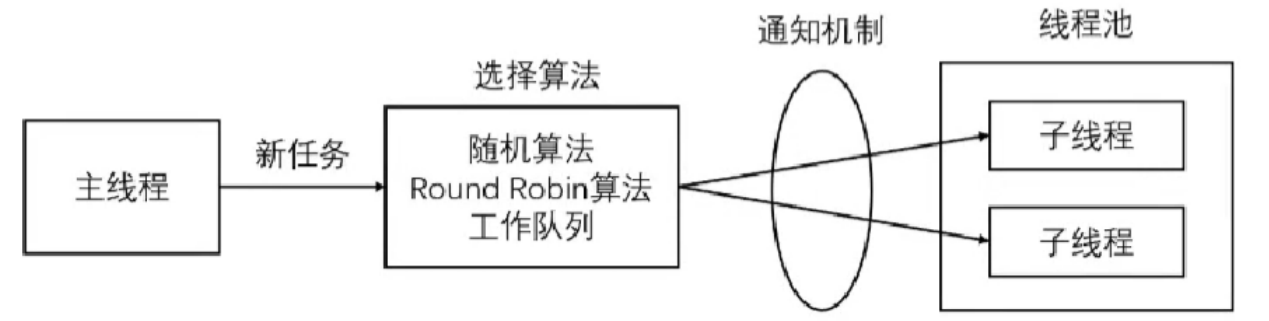
4.14 线程池
池是一组资源的集合,在服务器启动之初就被完全创建好并初始化,是静态资源。线程池是由服务器预先创建的一组子线程,线程池中的线程数量,应该和 CPU 核心数量差不多。线程池中的所有子线程运行着相同的代码,当有新任务到来时,主线程通过某种方式选择一个子线程来位置服务。空间换时间。
相比动态创建子线程,选择一个已经存在的子线程代价小得多。至于如何选择:
- 主线程使用某种算法来选择。
- 主线程和子线程共享一个工作队列,子线程在上面睡眠,有新任务来就唤醒


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?