
小菜鸟 菜谈 KMP->字典树->AC自动机->trie 图 (改进与不改进)
本文的主要宗旨是总结自己看了大佬们对AC自动机和trie 图 的一些理解与看法。(前沿:本人水平有限,总结有误,希望大佬们可以指出)
KMP分割线-------------------------------------------------------------------------------------------------------------------------------------
引入:https://www.cnblogs.com/zhangtianq/p/5839909.html(KMP全面解释)
总结:KMP对于 单模匹配通过 next数组 去到失配该到的地方,复杂度达到(O(n))
字典树-----------------------------------------------------------------------------------------------------------------------------------------
字典树模板:


#include<string.h> #include<stdio.h> #include<malloc.h> #include<iostream> #include<algorithm> using namespace std; const int maxn = 26 + 1; struct Trie { int Next[maxn], v; inline void init(){ v = 1; memset(Next, -1, sizeof(Next)); } }; struct Trie Node[1000000]; // 字典树可能最多的节点数,注意开足了! int tot = 0; void CreateTrie(char *str) { int len = strlen(str); int now = 0; for(int i=0; i<len; i++){ int idx = str[i]-'a'; int nxt = Node[now].Next[idx]; if( nxt == -1){ nxt = ++tot; Node[nxt].init(); Node[now].Next[idx] = nxt; }else Node[nxt].v++; now = nxt; } // Node[now].v = //尾部标志 } int FindTrie(char *str) { int len = strlen(str); int now = 0; int nxt; for(int i=0; i<len; i++){ int idx = str[i]-'a'; if(Node[now].Next[idx] != -1) now = Node[now].Next[idx]; else return 0; } return Node[now].v;//返回该返回的值 }
引入:https://blog.csdn.net/weixin_39778570/article/details/81990417
一, 原理图
Trie树包含的字符串集合是{in, inn, int, tea, ten, to}

字典树又称为前缀树 ,我们很明显的可以的观察到从根节点到标记节点(黑色),都在字符串集合,反之不在: 例如 0->1->2 = in
二, 构造过程
假设我们要插入字符串”in”。我们一开始位于根,也就是0号节点,我们用P=0表示。我们先看P是不是有一条标识着i的连向子节点的边。没有这条边,于是我们就新建一个节点,也就是1号节点,然后把1号节点设置为P也就是0号节点的子节点,并且将边标识为i。最后我们移动到1号节点,也就是令P=1。 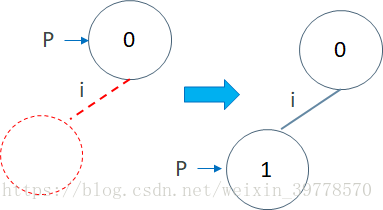
这样我们就把”in”的i字符插入到Trie中了。然后我们再插入字符n,也是先找P也就是1号节点有没有标记为n的边。还是没有,于是再新建一个节点2,设置为P也就是1号节点的子节点,并且把边标识为n。最后再移动到P=2。这样我们就把n也插入了。由于n是”in”的最后一个字符,所以我们还需要将P=2这个节点标记为终结点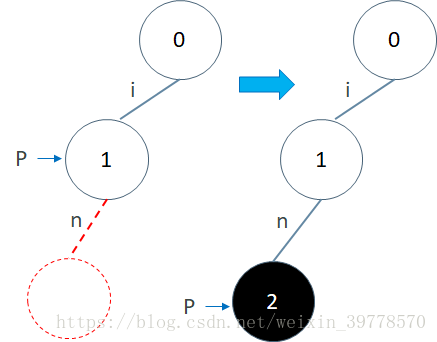
现在我们再插入字符串”inn”。过程也是一样的,从P=0开始找标识为i的边,这次找到1号节点。于是我们就不用创建新节点了,直接移动到1号节点,也就是令P=1。再插入字符n,也是有2号节点存在,所以移动到2号节点,P=2。最后再插入字符n这时P没有标识为n的边了,所以新建3号节点作为2号节点的子节点,边标识为n,同时将3号节点标记为终结点:
总的来说,对于目前想要插入字符串 W , 从根节点判断有无连线的 W[0] 的边,有就往下走到节点P,判断节点P有无连 W[1]的边,没有就新建一个节点X表示 P链接W[1] 后到达X;
三,怎么使用
如何查询Trie树中是不是包含字符串S,也就是之前提到的查找操作。查找其实比较简单。我们只要从根节点开始,沿着标识着S[1] -> S[2] -> S[3] … -> S[S.len]的边移动,如果最后成功到达一个终结点,就说明S在Trie树中;如果最后无路可走,或者到达一个不是终结点的节点,就说明S不在Trie树中。
例如:如果是查找”te”,就会从0开始经过5最后到达6。但是6不是终结点,所以te没在Trie树中。如果查找的是”too”,就会从0开始经过5和9,然后发现之后无路可走:9号节点没有标记为o的边连出去。所以too也不在Trie中。
四,盗取模板,嘻嘻
#include<string.h> #include<stdio.h> #include<malloc.h> #include<iostream> #include<algorithm> using namespace std; const int maxn = 26 + 1; struct Trie { int Next[maxn], v; inline void init(){ v = 1; memset(Next, -1, sizeof(Next)); } }; struct Trie Node[1000000]; // 字典树可能最多的节点数,注意开足了! int tot = 0; void CreateTrie(char *str) { int len = strlen(str); int now = 0; for(int i=0; i<len; i++){ int idx = str[i]-'a'; int nxt = Node[now].Next[idx]; if( nxt == -1){ nxt = ++tot; Node[nxt].init(); Node[now].Next[idx] = nxt; }else Node[nxt].v++; now = nxt; } // Node[now].v = //尾部标志 } int FindTrie(char *str) { int len = strlen(str); int now = 0; int nxt; for(int i=0; i<len; i++){ int idx = str[i]-'a'; if(Node[now].Next[idx] != -1) now = Node[now].Next[idx]; else return 0; } return Node[now].v;//返回该返回的值 }
AC自动机-----------------------------------------------------------------------------------------------------------------------------------------
推荐博客:https://blog.csdn.net/bestsort/article/details/82947639
时间复杂度的总和为O(n+m),空间复杂度为O(Cn),其中C为使用的字符集的大小(用于建立前缀树)
模板:
#include<bits/stdc++.h> using namespace std; #define MAX_N 1000006 /// 主串长度 #define MAX_Tot 500005 /// 字典树上可能的最多的结点数 = Max串数 * Max串长 struct Aho{ struct state{ int next[26]; int fail,cnt; }st[MAX_Tot]; /// 节点结构体 int Size; /// 节点个数 queue<int> que;/// BFS构建fail指针的队列 void init(){ while(que.size())que.pop();/// 清空队列 for(int i=0;i<MAX_Tot;i++){/// 初始化节点,有时候 MLE 的时候,可以尝试将此初始化放到要操作的时候再来初始化 memset(st[i].next,0,sizeof(st[i].next)); st[i].fail=st[i].cnt=0; } Size=1;/// 本来就有一个空的根节点 } void insert(char *S){/// 插入模式串 int len=strlen(S);/// 复杂度为O(n),所以别写进for循环 int now=0;/// 当前结点是哪一个,从0即根开始 for(int i=0;i<len;i++){ char c = S[i]; if(!st[now].next[c-'a']) st[now].next[c-'a']=Size++; now=st[now].next[c-'a']; } st[now].cnt++;/// 给这个串末尾打上标记 } void build(){/// 构建 fail 指针 st[0].fail=-1;/// 根节点的 fail 指向自己 que.push(0);/// 将根节点入队 while(que.size()){ int top = que.front(); que.pop(); for(int i=0; i<26; i++){ if(st[top].next[i]){/// 如果当前节点有 i 这个儿子 if(top == 0) st[st[top].next[i]].fail=0;/// 第二层节点 fail 应全指向根 else { int v = st[top].fail;/// 走向 top 节点父亲的 fail 指针指向的地方,尝试找一个最长前缀 while(v != -1){/// 如果走到 -1 则说明回到根了 if(st[v].next[i]){/// 如果有一个最长前缀后面接着的也是 i 这个字符,则说明 top->next[i] 的 fail 指针可以指向这里 st[st[top].next[i]].fail = st[v].next[i]; break;/// break 保证找到的前缀是最长的 } v = st[v].fail;/// 否则继续往父亲的父亲的 fail 跳,即后缀在变短( KMP 思想 ) } if(v == -1) st[st[top].next[i]].fail=0;/// 如果从头到尾都没找到,那么就只能指向根了 } que.push(st[top].next[i]);/// 将这个节点入队,为了下面建立 fail 节点做准备 } } } } int get(int u){ int res = 0; while(u){ res = res + st[u].cnt; st[u].cnt = 0; u = st[u].fail; } return res; } int match(char *S){ int len = strlen(S);/// 主串长度 int res=0,now=0;/// 主串能够和多少个模式串匹配的结果、当前的节点是哪一个 for(int i=0; i<len; i++){ char c = S[i]; if(st[now].next[c-'a']) now=st[now].next[c-'a'];/// 如果匹配了,则不用跳到 fail 处,直接往下一个字符匹配 else { int p = st[now].fail; while( p!=-1 && st[p].next[c-'a']==0 ) p=st[p].fail;/// 跳到 fail 指针处去匹配 c-'a' ,直到跳到 -1 也就是没得跳的时候 if(p == -1) now = 0;/// 如果全部都不匹配,只能回到根节点了 else now = st[p].next[c-'a'];/// 否则当前节点就是到达了能够匹配的 fail 指针指向处 } if(st[now].cnt)/// 如果当前节点是个字符串的结尾,这个时候就能统计其对于答案贡献了,答案的贡献应该是它自己 + 它所有 fail 指针指向的节点 /// 实际也就是它匹配了,那么它的 fail 指向的前缀以及 fail 的 fail 实际上也应该是匹配了,所以循环跳 fail 直到无法再跳为止 res = res + get(now); } return res; } }ac; int T; int N; char S[MAX_N]; int main(){ // ac.init(); // ac.build(); // ac.match(); // ... return 0; }
AC自动机的常规开场: 前置技能 KMP , 字典树 (忘记的盆友看 个 面噢)
(1) 为什么学习AC自动机要先学习 KMP和字典树啊?
这个问题我们需要先来看下AC自动机解决什么问题。
例如 :给定5个单词:say she shr he her,然后给定一个字符串 yasherhs。问一共有多少单词在这个字符串中出现过 (着实经典)
回归本源算法(暴力...) 我枚举每个单词然后去主字符串里面匹配然后判断..太强咯,时间复杂度爆爆爆
我们想想优化:我们对单词组say she shr he her 建立 字典树 ,然后枚举主字符串的起点去字典树里面跑复杂度确实是少了一个级别,但还是不够。
我们回忆下kmp的匹配过程,在失配的时候它是从头开始吗?显然不是嘛。用一个next数组快速找到一个位置,那我们是不是可以同样运用相同的思想去运用于多模匹配呢?对头,于是AC自动机就被大佬build 出来了。
AC自动机是在字典树上KMP用一个fail指针指向失配应该去到的位置(作用等同于KMP的next)
(2)fail指针的原理是什么QQ?
引入:https://blog.csdn.net/silence401/article/details/52662605
- 构建失败指针是AC自动机的关键所在,可以说,若没有失败指针,所谓的AC自动机只不过是Trie树而已。
- 失败指针原理:
- 构建失败指针,使当前字符失配时跳转到另一段从root开始每一个字符都与当前已匹配字符段某一个后缀完全相同且长度最大的位置继续匹配,如同KMP算法一样,AC自动机在匹配时如果当前字符串匹配失败,那么利用失配指针进行跳转。由此可知如果跳转,跳转后的串的前缀必为跳转前的模式串的后缀,并且跳转的新位置的深度(匹配字符个数)一定小于跳之前的节点(跳转后匹配字符数不可能大于跳转前,否则无法保证跳转后的序列的前缀与跳转前的序列的后缀匹配)。所以可以利用BFS在Trie上进行失败指针求解。
- 失败指针利用:
- 如果当前指针在某一字符s[m+1]处失配,即(p->next[s[m+1]]==NULL),则说明没有单词s[1...m+1]存在,此时,如果当前指针的失配指针指向root,则说明当前序列的任何后缀不是是某个单词的前缀,如果指针的失配指针不指向root,则说明当前序列s[i...m]是某一单词的前缀,于是跳转到当前指针的失配指针,以s[i...m]为前缀继续匹配s[m+1]。
- 对于已经得到的序列s[1...m],由于s[i...m]可能是某单词的后缀,s[1...j]可能是某单词的前缀,所以s[1...m]中可能会出现单词,但是当前指针的位置是确定的,不能移动,我们就需要temp临时指针,令temp=当前指针,然后依次测试s[1...m],s[i...m]是否是单词。
- >>>简单来说,失败指针的作用就是将主串某一位之前的所有可以与模式串匹配的单词快速在Trie树中找出。
(3)那么fail指针怎么建立啊?
- 在构造完Tire树之后,接下去的工作就是构造失败指针。构造失败指针的过程概括起来就一句话:设这个节点上的字母为C,沿着它父亲节点的失败指针走,直到走到一个节点,它的子结点中也有字母为C的节点。然后把当前节点的失败指针指向那个字母也为C的儿子。如果一直走到了root都没找到,那就把失败指针指向root。具体操作起来只需要:先把root加入队列(root的失败指针指向自己或者NULL),这以后我们每处理一个点,就把它的所有儿子加入队列。
-
观察构造失败指针的流程:对照图来看,首先root的fail指针指向NULL,然后root入队,进入循环。从队列中弹出root,root节点与s,h节点相连,因为它们是第一层的字符,肯定没有比它层数更小的共同前后缀,所以把这2个节点的失败指针指向root,并且先后进入队列,失败指针的指向对应图中的(1),(2)两条虚线;从队列中先弹出h(右边那个),h所连的只有e结点,所以接下来扫描指针指向e节点的父节点h节点的fail指针指向的节点,也就是root,root->next['e']==NULL,并且root->fail==NULL,说明匹配序列为空,则把节点e的fail指针指向root,对应图中的(3),然后节点e进入队列;从队列中弹出s,s节点与a,h(左边那个)相连,先遍历到a节点,扫描指针指向a节点的父节点s节点的fail指针指向的节点,也就是root,root->next['a']==NULL,并且root->fail==NULL,说明匹配序列为空,则把节点a的fail指针指向root,对应图中的(4),然后节点a进入队列。接着遍历到h节点,扫描指针指向h节点的父节点s节点的fail指针指向的节点,也就是root,root->next['h']!=NULL,所以把节点h的fail指针指向右边那个h,对应图中的(5),然后节点h进入队列...由此类推,最终失配指针如图所示。

(4)我怎么用啊?
-
最后,我们便可以在AC自动机上查找模式串中出现过哪些单词了。匹配过程分两种情况:(1)当前字符匹配,表示从当前节点沿着树边有一条路径可以到达目标字符,此时只需沿该路径走向下一个节点继续匹配即可,目标字符串指针移向下个字符继续匹配;(2)当前字符不匹配,则去当前节点失败指针所指向的字符继续匹配,匹配过程随着指针指向root结束。重复这2个过程中的任意一个,直到模式串走到结尾为止。
-
对例子来说:其中模式串为yasherhs。对于i=0,1。Trie中没有对应的路径,故不做任何操作;i=2,3,4时,指针p走到左下节点e。因为节点e的count信息为1,所以cnt+1,并且讲节点e的count值设置为-1,表示改单词已经出现过了,防止重复计数,最后temp指向e节点的失败指针所指向的节点继续查找,以此类推,最后temp指向root,退出while循环,这个过程中count增加了2。表示找到了2个单词she和he。当i=5时,程序进入第5行,p指向其失败指针的节点,也就是右边那个e节点,随后在第6行指向r节点,r节点的count值为1,从而count+1,循环直到temp指向root为止。最后i=6,7时,找不到任何匹配,匹配过程结束。
- AC自动机时间复杂性为:O(L(T)+max(L(Pi))+m)其中m是模式串的数量
AC自动机往往是在节点处添加一些东西去维护自己想要的东西;
(5)来几个例题噢
HDU 2222
题意 : 给出 n 个模式串再给出一个主串,问你有多少个模式串曾在这个主串上出现过
#include<bits/stdc++.h> using namespace std; #define MAX_N 1000006 /// 主串长度 #define MAX_Tot 500005 /// 字典树上可能的最多的结点数 = Max串数 * Max串长 struct Aho{ struct state{ int next[26]; int fail,cnt; }st[MAX_Tot]; /// 节点结构体 int Size; /// 节点个数 queue<int> que;/// BFS构建fail指针的队列 void init(){ while(que.size())que.pop();/// 清空队列 for(int i=0;i<MAX_Tot;i++){/// 初始化节点,有时候 MLE 的时候,可以尝试将此初始化放到要操作的时候再来初始化 memset(st[i].next,0,sizeof(st[i].next)); st[i].fail=st[i].cnt=0; } Size=1;/// 本来就有一个空的根节点 } void insert(char *S){/// 插入模式串 int len=strlen(S);/// 复杂度为O(n),所以别写进for循环 int now=0;/// 当前结点是哪一个,从0即根开始 for(int i=0;i<len;i++){ char c = S[i]; if(!st[now].next[c-'a']) st[now].next[c-'a']=Size++; now=st[now].next[c-'a']; } st[now].cnt++;/// 给这个串末尾打上标记 } void build(){/// 构建 fail 指针 st[0].fail=-1;/// 根节点的 fail 指向自己 que.push(0);/// 将根节点入队 while(que.size()){ int top = que.front(); que.pop(); for(int i=0; i<26; i++){ if(st[top].next[i]){/// 如果当前节点有 i 这个儿子 if(top == 0) st[st[top].next[i]].fail=0;/// 第二层节点 fail 应全指向根 else { int v = st[top].fail;/// 走向 top 节点父亲的 fail 指针指向的地方,尝试找一个最长前缀 while(v != -1){/// 如果走到 -1 则说明回到根了 if(st[v].next[i]){/// 如果有一个最长前缀后面接着的也是 i 这个字符,则说明 top->next[i] 的 fail 指针可以指向这里 st[st[top].next[i]].fail = st[v].next[i]; break;/// break 保证找到的前缀是最长的 } v = st[v].fail;/// 否则继续往父亲的父亲的 fail 跳,即后缀在变短( KMP 思想 ) } if(v == -1) st[st[top].next[i]].fail=0;/// 如果从头到尾都没找到,那么就只能指向根了 } que.push(st[top].next[i]);/// 将这个节点入队,为了下面建立 fail 节点做准备 } } } } int get(int u){ int res = 0; while(u){ res = res + st[u].cnt; st[u].cnt = 0; u = st[u].fail; } return res; } int match(char *S){ int len = strlen(S);/// 主串长度 int res=0,now=0;/// 主串能够和多少个模式串匹配的结果、当前的节点是哪一个 for(int i=0; i<len; i++){ char c = S[i]; if(st[now].next[c-'a']) now=st[now].next[c-'a'];/// 如果匹配了,则不用跳到 fail 处,直接往下一个字符匹配 else { int p = st[now].fail; while( p!=-1 && st[p].next[c-'a']==0 ) p=st[p].fail;/// 跳到 fail 指针处去匹配 c-'a' ,直到跳到 -1 也就是没得跳的时候 if(p == -1) now = 0;/// 如果全部都不匹配,只能回到根节点了 else now = st[p].next[c-'a'];/// 否则当前节点就是到达了能够匹配的 fail 指针指向处 } if(st[now].cnt)/// 如果当前节点是个字符串的结尾,这个时候就能统计其对于答案贡献了,答案的贡献应该是它自己 + 它所有 fail 指针指向的节点 /// 实际也就是它匹配了,那么它的 fail 指向的前缀以及 fail 的 fail 实际上也应该是匹配了,所以循环跳 fail 直到无法再跳为止 res = res + get(now); } return res; } }aho; int T; int N; char S[MAX_N]; int main(){ scanf("%d",&T); while(T--){ aho.init(); scanf("%d",&N); for(int i=0;i<N;i++){ scanf("%s",S); aho.insert(S); } aho.build(); scanf("%s",S); printf("%d\n",aho.match(S)); } return 0; }
HDU 2896
题目大意:给出若干病毒的特征码,不超过500个。每个病毒的特征码长度在20~200之间。现在有若干网站的源代码,要检测网站的源代码中是否包含病毒。网站的个数不超过1000个,每个网站的源代码长度在7000~10000之间。已知如果包含病毒,最多包含三个病毒。输出每个含病毒网站包含的病毒的编号等信息,最后输出含病毒网站的个数
#include<queue> #include<stdio.h> #include<string.h> using namespace std; const int Max_Tot = 1e5 + 10; const int Max_Len = 1e4 + 10; const int Letter = 128; struct Aho{ struct StateTable{ int Next[Letter]; int fail, id; }Node[Max_Tot]; int Size; queue<int> que; inline void init(){ while(!que.empty()) que.pop(); memset(Node[0].Next, 0, sizeof(Node[0].Next)); Node[0].fail = Node[0].id = 0; Size = 1; } inline void insert(char *s, const int id){ int len = strlen(s); int now = 0; for(int i=0; i<len; i++){ int idx = s[i]; if(!Node[now].Next[idx]){ memset(Node[Size].Next, 0, sizeof(Node[Size].Next)); Node[Size].fail = Node[Size].id = 0; Node[now].Next[idx] = Size++; } now = Node[now].Next[idx]; } Node[now].id = id; } inline void BuildFail(){ Node[0].fail = -1; que.push(0); while(!que.empty()){ int top = que.front(); que.pop(); for(int i=0; i<Letter; i++){ if(Node[top].Next[i]){ if(top == 0) Node[ Node[top].Next[i] ].fail = 0; else{ int v = Node[top].fail; while(v != -1){ if(Node[v].Next[i]){ Node[ Node[top].Next[i] ].fail = Node[v].Next[i]; break; }v = Node[v].fail; }if(v == -1) Node[ Node[top].Next[i] ].fail = 0; }que.push(Node[top].Next[i]); } } } } inline void Get(int u, bool *used){ while(u){ if(!used[Node[u].id] && Node[u].id) used[Node[u].id] = true; u = Node[u].fail; } } bool Match(char *s, bool *used){ int now = 0; bool ok = false; for(int i=0; s[i]; i++){ int idx = s[i]; if(Node[now].Next[idx]) now = Node[now].Next[idx]; else{ int p = Node[now].fail; while(p!=-1 && Node[p].Next[idx]==0){ p = Node[p].fail; } if(p == -1) now = 0; else now = Node[p].Next[idx]; } if(Node[now].id) { Get(now, used); ok = true; } } if(ok) return true; return false; } }ac; char S[Max_Len]; bool used[501]; int main(void) { int n, m; memset(used, false, sizeof(used)); while(~scanf("%d", &n)){ ac.init(); for(int i=1; i<=n; i++){ scanf("%s", S); ac.insert(S, i); } ac.BuildFail(); int ans = 0; scanf("%d", &m); for(int i=1; i<=m; i++){ scanf("%s", S); if(ac.Match(S, used)){ printf("web %d:", i); for(int j=1; j<=n; j++){ if(used[j]){ printf(" %d", j); used[j] = false; } }puts(""); ans++; } } printf("total: %d\n", ans); } return 0; }
HDU 3065
文本出现了多少种单词,每种单词出现多少次
#include<queue> #include<stdio.h> #include<string.h> using namespace std; const int Max_Tot = 5e5 + 10; const int Max_Len = 2e6 + 10; const int Letter = 26; struct Aho{ struct StateTable{ int Next[Letter]; int fail, id; }Node[Max_Tot]; int Size; queue<int> que; inline void init(){ while(!que.empty()) que.pop(); memset(Node[0].Next, 0, sizeof(Node[0].Next)); Node[0].fail = Node[0].id = 0; Size = 1; } inline void insert(char *s, int id){ int len = strlen(s); int now = 0; for(int i=0; i<len; i++){ int idx = s[i] - 'A'; if(!Node[now].Next[idx]){ memset(Node[Size].Next, 0, sizeof(Node[Size].Next)); Node[Size].fail = Node[Size].id = 0; Node[now].Next[idx] = Size++; } now = Node[now].Next[idx]; } Node[now].id = id; } inline void BuildFail(){ Node[0].fail = -1; que.push(0); while(!que.empty()){ int top = que.front(); que.pop(); for(int i=0; i<Letter; i++){ if(Node[top].Next[i]){ if(top == 0) Node[ Node[top].Next[i] ].fail = 0; else{ int v = Node[top].fail; while(v != -1){ if(Node[v].Next[i]){ Node[ Node[top].Next[i] ].fail = Node[v].Next[i]; break; }v = Node[v].fail; }if(v == -1) Node[ Node[top].Next[i] ].fail = 0; }que.push(Node[top].Next[i]); } } } } inline void Get(int u, int *arr){ while(u){ if(Node[u].id) arr[Node[u].id]++; u = Node[u].fail; } } inline void Match(char *s, int *arr){ int now = 0; for(int i=0; s[i]; i++){ if(!(s[i] >= 'A' && s[i] <= 'Z')){ now = 0; continue; } int idx = s[i] - 'A'; if(Node[now].Next[idx]) now = Node[now].Next[idx]; else{ int p = Node[now].fail; while(p!=-1 && Node[p].Next[idx]==0) p = Node[p].fail; if(p == -1) now = 0; else now = Node[p].Next[idx]; } if(Node[now].id) Get(now, arr); } } }ac; char S[Max_Len]; int arr[1001]; char str[1001][51]; int main(void) { memset(arr, 0, sizeof(arr)); int n; while(~scanf("%d", &n)){ ac.init(); for(int i=1; i<=n; i++){ scanf("%s", str[i]); ac.insert(str[i], i); } ac.BuildFail(); scanf("%s", S); ac.Match(S, arr); for(int i=1; i<=n; i++){ if(arr[i]){ printf("%s: %d\n", str[i], arr[i]); arr[i] = 0; } } } return 0; }
Trie图-----------------------------------------------------------------------------------------------------------------------------------------
模板:
#include<queue> #include<stdio.h> #include<string.h> using namespace std; const int Max_Tot = 1e2 + 10; const int Letter = 4; const int MOD = 1e5; int maxn; int mp[128]; struct Aho{ struct StateTable{ int Next[Letter]; int fail, flag; }Node[Max_Tot]; int Size; queue<int> que; inline void init(){ while(!que.empty()) que.pop(); memset(Node[0].Next, 0, sizeof(Node[0].Next)); Node[0].fail = Node[0].flag = 0; Size = 1; } inline void insert(char *s){ int now = 0; for(int i=0; s[i]; i++){ int idx = mp[s[i]]; if(!Node[now].Next[idx]){ memset(Node[Size].Next, 0, sizeof(Node[Size].Next)); Node[Size].fail = Node[Size].flag = 0; Node[now].Next[idx] = Size++; } now = Node[now].Next[idx]; } Node[now].flag = 1; } //1) 如果son[i]不存在,将它指向 当前结点now的fail指针指 //向结点的i号后继(保证一定已经计算出来)。 //2) 如果son[i]存在,将它的fail指针指向 当前结点now的fail //指针指向结点的i号后继(保证一定已经计算出来)。 inline void BuildFail(){ Node[0].fail = 0; for(int i=0; i<Letter; i++){ if(Node[0].Next[i]){ Node[Node[0].Next[i]].fail = 0; que.push(Node[0].Next[i]); }else Node[0].Next[i] = 0;///必定指向根节点 } while(!que.empty()){ int top = que.front(); que.pop(); if(Node[Node[top].fail].flag) Node[top].flag = 1; for(int i=0; i<Letter; i++){ int &v = Node[top].Next[i]; if(v){ que.push(v); Node[v].fail = Node[Node[top].fail].Next[i]; }else v = Node[Node[top].fail].Next[i]; } } } inline void BuildMatrix(){ } }ac; char S[11]; int main(void) { int n, m; while(~scanf("%d %d", &m, &n)){ ac.init(); for(int i=0; i<m; i++){ scanf("%s", S); ac.insert(S); } ac.BuildFail(); ac.BuildMatrix(); } return 0; }
推荐博客:https://blog.csdn.net/xaiojiang/article/details/52299258
http://www.doc88.com/p-9913363530128.html
http://hihocoder.com/problemset/problem/1036
在多模匹配下有奇效呀
(1)Trie 树(字典树)我就知道,Trie 图是什么?

Trie 图就是在AC自动机上面补边
网上的大佬都说AC自动机可以搞定的,Trie图都可以做,有了后缀数组与后缀自动机的教训,我还是两个都学习吧
(2)给我介绍介绍下Tire图呗
NO帕普论哦
https://wenku.baidu.com/view/15c5a3ea02d276a201292e67.html(下面是引用该作者)




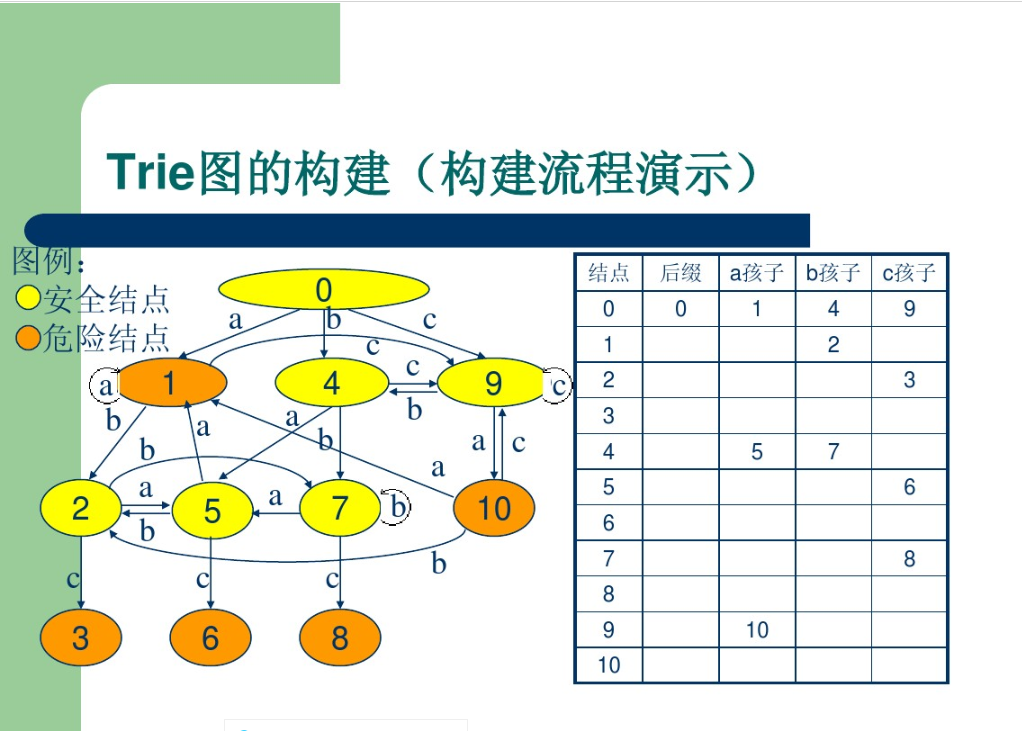

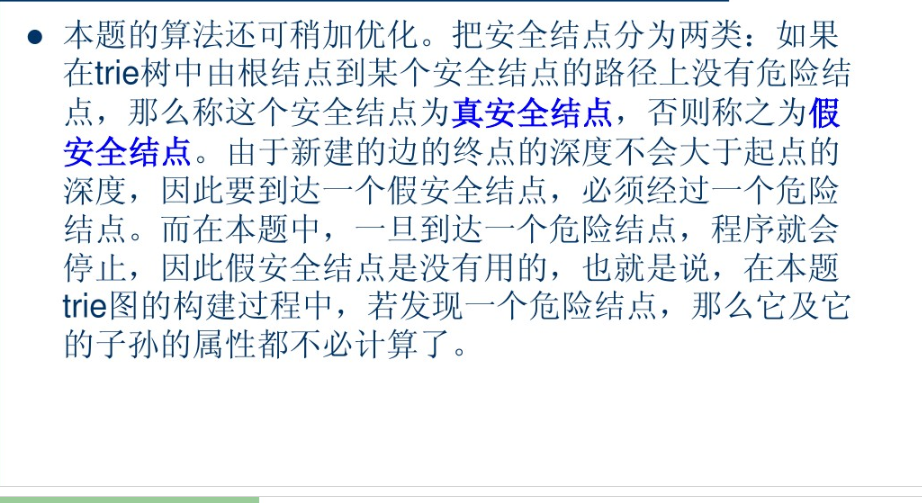



















总结:
查找每个节点的后缀结点
层序遍历Trie树的每个结点:
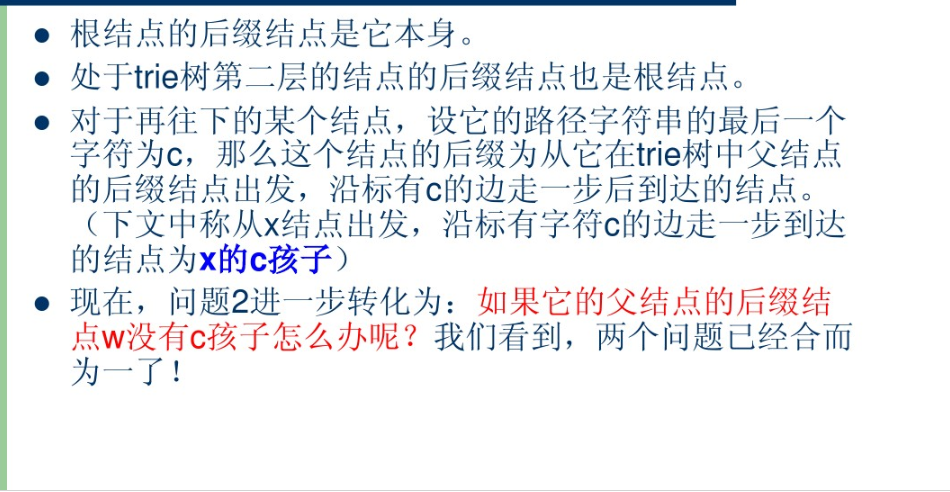
对于根节点root的后缀结点是根节点root本身;
对于根节点root的儿子结点,即根节点的下层结点,它们的后缀结点是根节点root;
对于其余的结点的后缀结点的查找:
设当前结点为q,结点q的父结点为结点p,结点p指向结点q的边上的字符为‘A’,结点p的后缀结点是结点p2。那么结点q的后缀结点就是结点p2沿标有字符'A'的边走一步后到达的结点。
注意:如果结点p2没有字符为‘A’的边,那么这个时候就找结点p2的后缀结点p3,如果结点p3有字符为‘A’的 边, 那么结点p3沿标有字符'A'的边走一步后到达的结点就是结点q的后缀结点。如果结点p3也没有字符为'A'的边,那么就找结点p3的后缀结点p4直到根节点root,直到结点root,结点root也没有字符为'A'的边,那么结点q的后缀就设置为结点root。
连接新边
在找到后缀结点后,同时对当前结点q进行新边的连接。设结点q的后缀结点为结点q2。那么需要连接的新边就是结点q2存在而结点q没有的边,那么结点q就新建一条边指向结点q2所指向的结点。例如:结点q有两个儿子结点:结点q通过边‘A’指向一个儿子结点;结点q通过边'B'指向一个儿子结点。结点q2有两个儿子结点:结点q2通过边‘C’指向结点e;结点q2通过边'B'指向结点f。那么这时就需要结点q新建一条边‘C’指向结点e,结点q2不做任何修改。
AC自动机与Trie 图的区别:http://www.doc88.com/p-9913363530128.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号