spark实时任务修改状态异常
首先看到下面的timing out就是超时,再看前面的state是状态,大致意思就是说修改状态超时,因为我的是sparkStreaming任务,它是批次处理数据的,每个批次结束后都会修改状态,而超时大致就与这个地方有关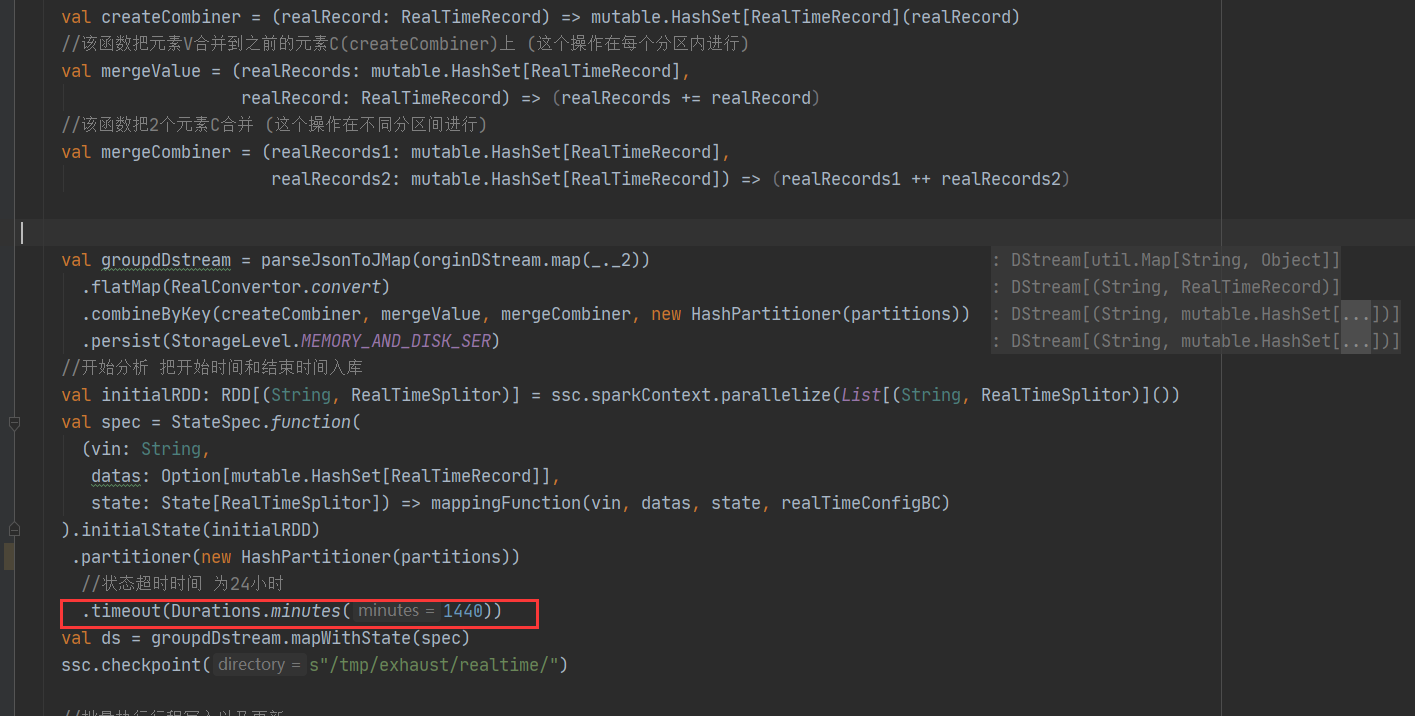
此处设置的超时时间是24小时,此处将其注释掉就ok
java.lang.IllegalArgumentException: requirement failed: Cannot update the state that is timing out
at scala.Predef$.require(Predef.scala:233)
at org.apache.spark.streaming.StateImpl.update(State.scala:156)
at com.dfssi.dataplatform.analysis.exhaust.realTime.RealTimeFromKafka.mappingFunction(RealTimeFromKafka.scala:119)
at com.dfssi.dataplatform.analysis.exhaust.realTime.RealTimeFromKafka$$anonfun$6.apply(RealTimeFromKafka.scala:66)
at com.dfssi.dataplatform.analysis.exhaust.realTime.RealTimeFromKafka$$anonfun$6.apply(RealTimeFromKafka.scala:66)
at org.apache.spark.streaming.StateSpec$$anonfun$1.apply(StateSpec.scala:180)
at org.apache.spark.streaming.StateSpec$$anonfun$1.apply(StateSpec.scala:179)
at org.apache.spark.streaming.rdd.MapWithStateRDDRecord$$anonfun$updateRecordWithData$2.apply(MapWithStateRDD.scala:72)
at org.apache.spark.streaming.rdd.MapWithStateRDDRecord$$anonfun$updateRecordWithData$2.apply(MapWithStateRDD.scala:70)
at scala.collection.Iterator$class.foreach(Iterator.scala:727)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1157)
at org.apache.spark.streaming.rdd.MapWithStateRDDRecord$.updateRecordWithData(MapWithStateRDD.scala:70)
at org.apache.spark.streaming.rdd.MapWithStateRDD.compute(MapWithStateRDD.scala:155)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:306)
at org.apache.spark.CacheManager.getOrCompute(CacheManager.scala:69)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:268)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:306)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:270)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:306)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:270)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:66)
at org.apache.spark.scheduler.Task.run(Task.scala:89)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:242)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
