

Python之爬虫从入门到放弃(十三) Scrapy框架整体的了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解
该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider/tree/master/jobboleSpider
注:这个文章并不会对详细的用法进行讲解,是为了让对scrapy各个功能有个了解,建立整体的印象。
在学习Scrapy框架之前,我们先通过一个实际的爬虫例子来理解,后面我们会对每个功能进行详细的理解。
这里的例子是爬取http://blog.jobbole.com/all-posts/ 伯乐在线的全部文章数据
分析要爬去的目标站信息
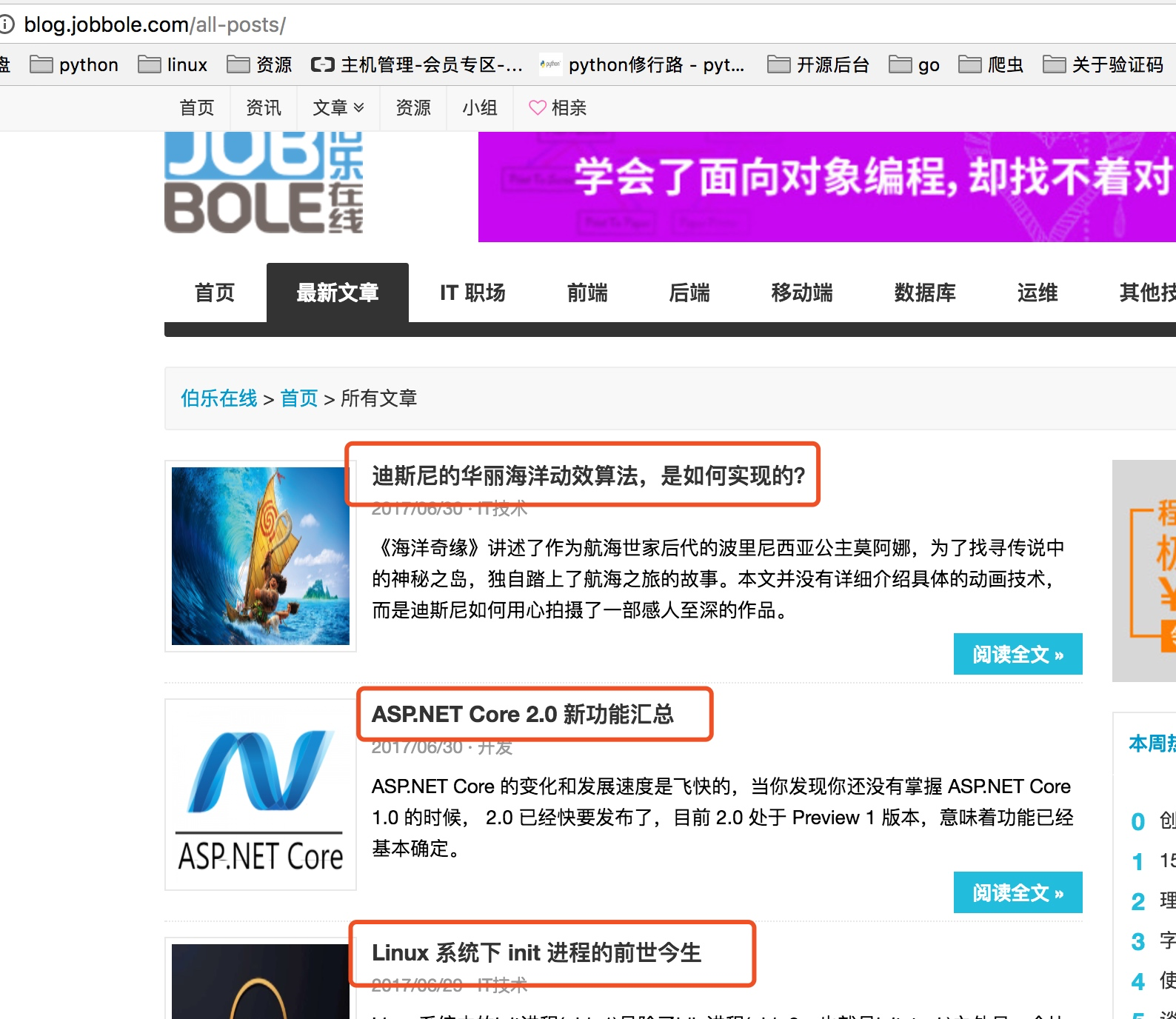
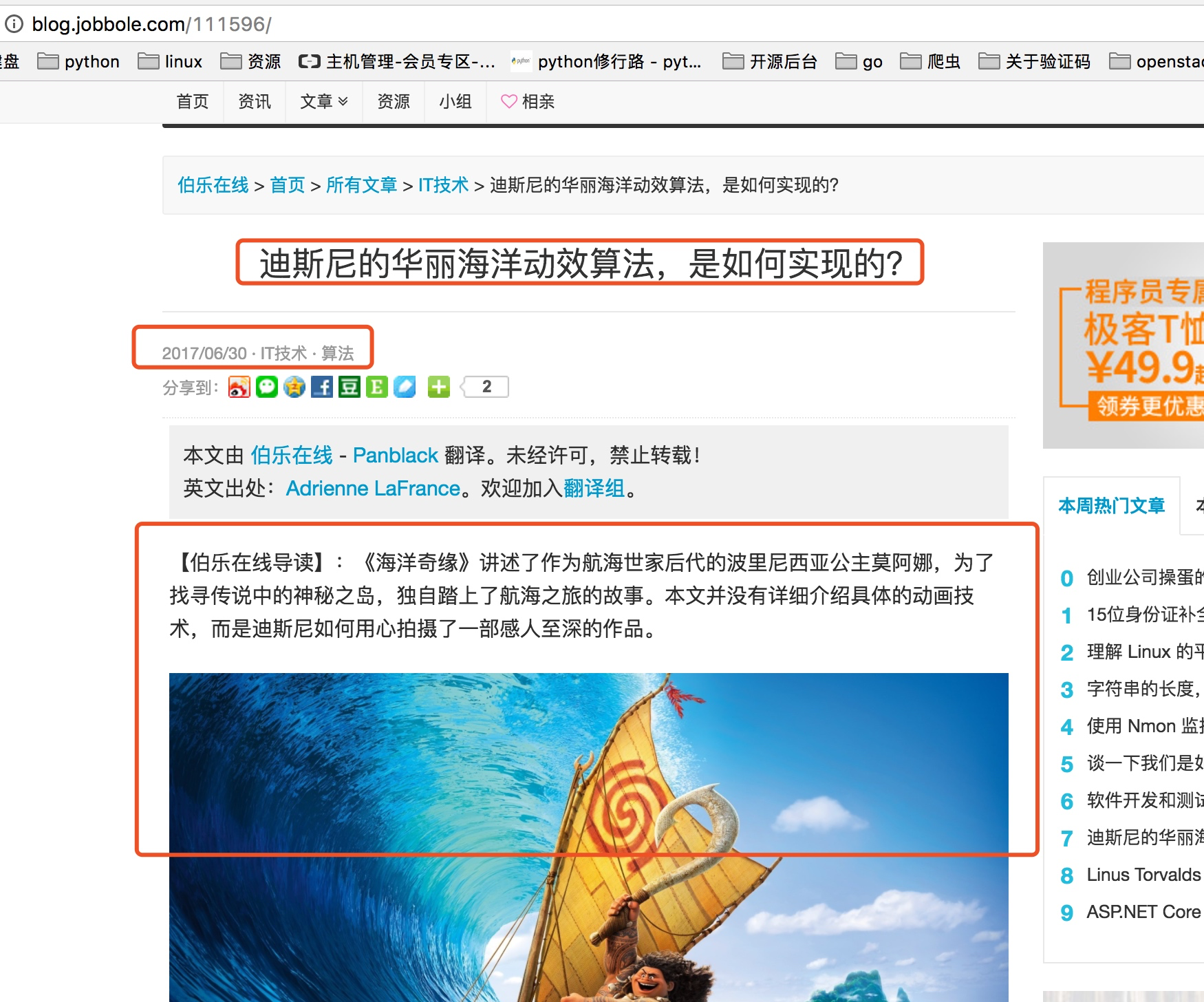
先看如下图,首先我们要获取下图中所有文章的连接,然后是进入每个文章连接爬取每个文章的详细内容。
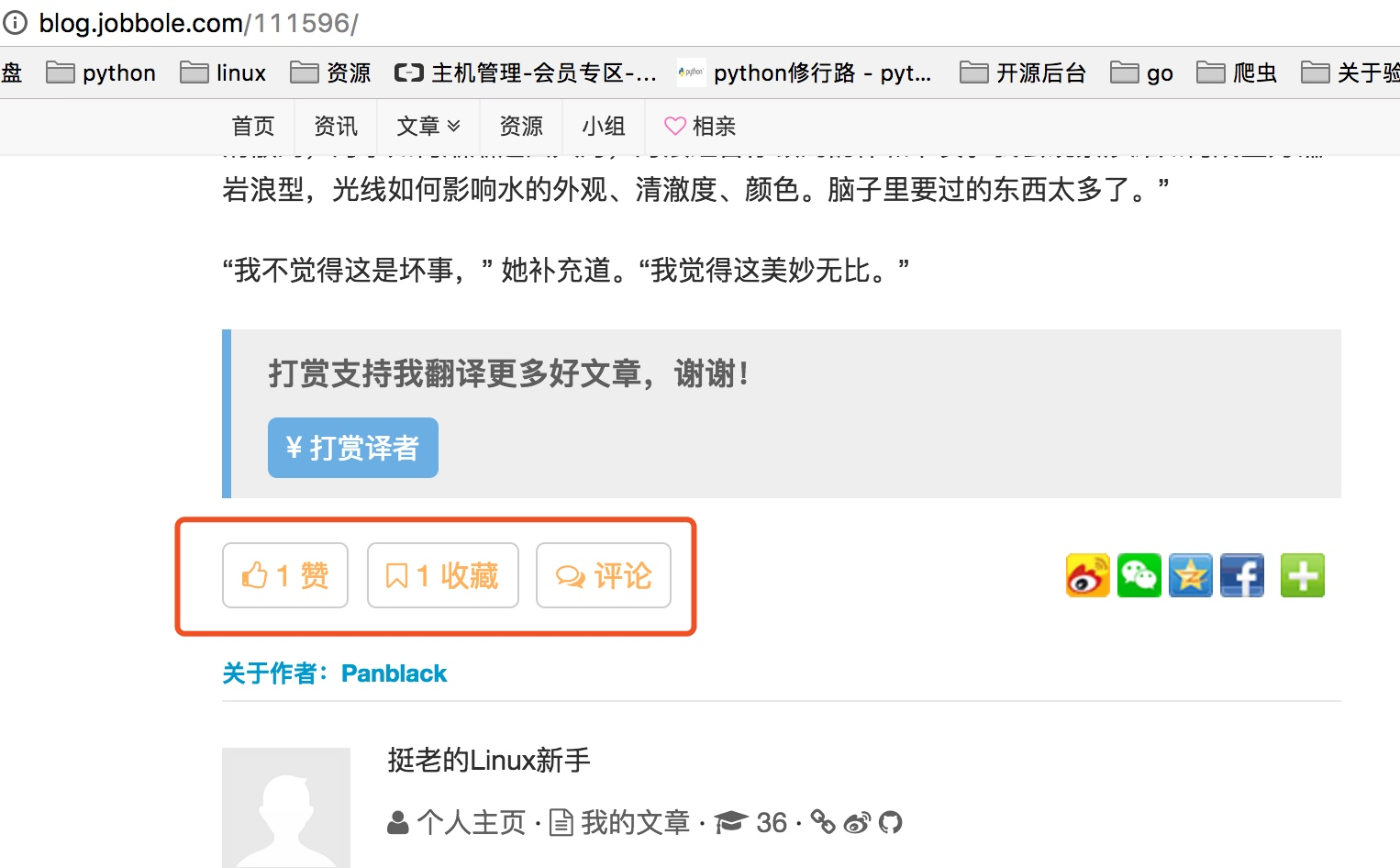
每个文章中需要爬取文章标题,发表日期,以及标签,赞赏收藏,评论数,文章内容。
对于该爬虫的一个整体思路
我们对这个爬虫进行一个思路整理,通过如下图表示:
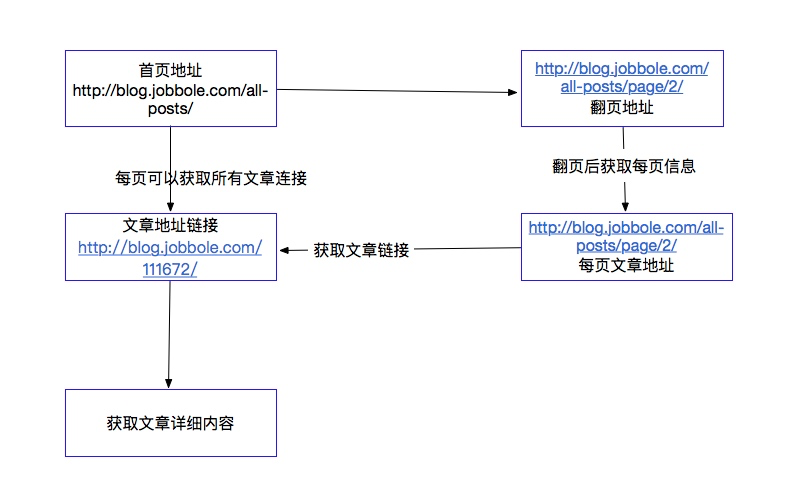
以上是我们对这个爬虫需求了解,下面我们通过scrapy爬取我们想要爬取的数据,下面我们先对scrapy进行一个简单的了解
Scrapy的初步认识
Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码。对于会阻塞线程的操作包含访问文件、数据库或者Web、产生新的进程并需要处理新进程的输出(如运行shell命令)、执行系统层次操作的代码(如等待系统队列),Twisted提供了允许执行上面的操作但不会阻塞代码执行的方法。
scrapy的项目结构:
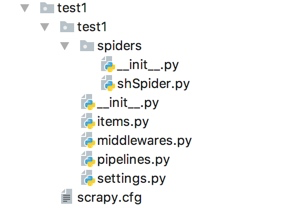
items.py 负责数据模型的建立,类似于实体类。
middlewares.py 自己定义的中间件。
pipelines.py 负责对spider返回数据的处理。
settings.py 负责对整个爬虫的配置。
spiders目录 负责存放继承自scrapy的爬虫类。
scrapy.cfg scrapy基础配置
那么如何创建上述的目录,通过下面命令:
zhaofandeMBP:python_project zhaofan$ scrapy startproject test1
New Scrapy project 'test1', using template directory '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/scrapy/templates/project', created in:
/Users/zhaofan/Documents/python_project/test1
You can start your first spider with:
cd test1
scrapy genspider example example.com
zhaofandeMBP:python_project zhaofan$
zhaofandeMBP:test1 zhaofan$ scrapy genspider shSpider hshfy.sh.cn
Created spider 'shSpider' using template 'basic' in module:
test1.spiders.shSpider
相信上面这段话你肯定会觉得很无聊,所以直接分析爬虫代码。
代码的项目结构

items.py代码分析
items.py里存放的是我们要爬取数据的字段信息,代码如下:
我们分别要爬取的信息包括:文章标题,文件发布时间,文章url地址,url_object_id是我们会对地址进行md5加密,front_image_url 是文章下图片的url地址,front_image_path图片的存放路径
class JoBoleArticleItem(scrapy.Item):
title = scrapy.Field()
create_date = scrapy.Field()
url = scrapy.Field()
url_object_id = scrapy.Field()
front_image_url = scrapy.Field()
front_image_path = scrapy.Field()
praise_nums = scrapy.Field()
fav_nums = scrapy.Field()
comment_nums = scrapy.Field()
tag = scrapy.Field()
content = scrapy.Field()
spiders/Article.py代码分析
spiders目录下的Article.py为主要的爬虫代码,包括了对页面的请求以及页面的处理,这里有几个知识点需要注意:
这些知识点我会在后面详细写一个文章整理,这里先有一个初步的印象。
1. 我们爬取的页面时http://blog.jobbole.com/all-posts/,所以parse的response,返回的是这个页面的信息,但是我们这个时候需要的是获取每个文章的地址继续访问,这里就用到了yield Request()这种用法,可以把获取到文章的url地址继续传递进来再次进行请求。
2. scrapy提供了response.css这种的css选择器以及response.xpath的xpath选择器方法,我们可以根据自己的需求获取我们想要的字段信息


class ArticleSpider(scrapy.Spider): name = "Article" allowed_domains = ["blog.jobbole.com"] start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response): ''' 1.获取文章列表也中具体文章url,并交给scrapy进行下载后并进行解析 2.获取下一页的url并交给scrapy进行下载,下载完成后,交给parse :param response: :return: ''' #解析列表页中所有文章的url,并交给scrapy下载后进行解析 post_nodes = response.css("#archive .floated-thumb .post-thumb a") for post_node in post_nodes: #image_url是图片的地址 image_url = post_node.css("img::attr(src)").extract_first("") post_url = post_node.css("::attr(href)").extract_first("") #这里通过meta参数将图片的url传递进来,这里用parse.urljoin的好处是如果有域名我前面的response.url不生效 # 如果没有就会把response.url和post_url做拼接 yield Request(url=parse.urljoin(response.url,post_url),meta={"front_image_url":parse.urljoin(response.url,image_url)},callback=self.parse_detail) #提取下一页并交给scrapy下载 next_url = response.css(".next.page-numbers::attr(href)").extract_first("") if next_url: yield Request(url=next_url,callback=self.parse) def parse_detail(self,response): ''' 获取文章的详细内容 :param response: :return: ''' article_item = JoBoleArticleItem() front_image_url = response.meta.get("front_image_url","") #文章封面图地址 title = response.xpath('//div[@class="entry-header"]/h1/text()').extract_first() create_date = response.xpath('//p[@class="entry-meta-hide-on-mobile"]/text()').extract()[0].strip().split()[0] tag_list = response.xpath('//p[@class="entry-meta-hide-on-mobile"]/a/text()').extract() tag_list = [element for element in tag_list if not element.strip().endswith("评论")] tag =",".join(tag_list) praise_nums = response.xpath('//span[contains(@class,"vote-post-up")]/h10/text()').extract() if len(praise_nums) == 0: praise_nums = 0 else: praise_nums = int(praise_nums[0]) fav_nums = response.xpath('//span[contains(@class,"bookmark-btn")]/text()').extract()[0] match_re = re.match(".*(\d+).*",fav_nums) if match_re: fav_nums = int(match_re.group(1)) else: fav_nums = 0 comment_nums =response.xpath("//a[@href='#article-comment']/span/text()").extract()[0] match_com = re.match(".*(\d+).*",comment_nums) if match_com: comment_nums = int(match_com.group(1)) else: comment_nums=0 content = response.xpath('//div[@class="entry"]').extract()[0] article_item["url_object_id"] = get_md5(response.url) #这里对地址进行了md5变成定长 article_item["title"] = title article_item["url"] = response.url try: create_date = datetime.datetime.strptime(create_date,'%Y/%m/%d').date() except Exception as e: create_date = datetime.datetime.now().date() article_item["create_date"] = create_date article_item["front_image_url"] = [front_image_url] article_item["praise_nums"] = int(praise_nums) article_item["fav_nums"] = fav_nums article_item["comment_nums"] = comment_nums article_item["tag"] = tag article_item['content'] = content yield article_item
pipeline中代码的分析
pipeline主要是对spiders中爬虫的返回的数据的处理,这里我们可以让写入到数据库,也可以让写入到文件等等。
下面代码中主要包括的写入到json文件以及写入到数据库,包括异步插入到数据库,还有图片的处理,这里我们可以定义各种我们需要的pipeline,当然这里我们不同的pipeline是有一定的顺序的,需要的设置是在settings配置文件中,如下,后面的数字表示的是优先级,数字越小优先级越高。
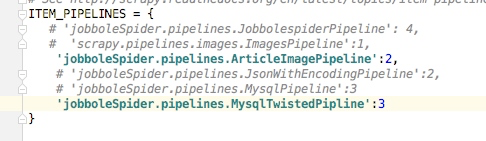
class JobbolespiderPipeline(object): def process_item(self, item, spider): return item class JsonWithEncodingPipeline(object): ''' 返回json数据到文件 ''' def __init__(self): self.file = codecs.open("article.json",'w',encoding="utf-8") def process_item(self, item, spider): lines = json.dumps(dict(item),ensure_ascii=False) + "\n" self.file.write(lines) return item def spider_closed(self,spider): self.file.close() class MysqlPipeline(object): ''' 插入mysql数据库 ''' def __init__(self): self.conn =pymysql.connect(host='192.168.1.19',port=3306,user='root',passwd='123456',db='article_spider',use_unicode=True, charset="utf8") self.cursor = self.conn.cursor() def process_item(self,item,spider): insert_sql = ''' insert into jobbole_article(title,create_date,url,url_object_id,front_image_url,front_image_path,comment_nums,fav_nums,praise_nums,tag,content) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s) ''' self.cursor.execute(insert_sql,(item["title"],item["create_date"],item["url"],item["url_object_id"],item["front_image_url"],item["front_image_path"],item["comment_nums"],item["fav_nums"],item["praise_nums"],item["tag"],item["content"])) self.conn.commit() class MysqlTwistedPipline(object): ''' 采用异步的方式插入数据 ''' def __init__(self,dbpool): self.dbpool = dbpool @classmethod def from_settings(cls,settings): dbparms = dict( host = settings["MYSQL_HOST"], port = settings["MYSQL_PORT"], user = settings["MYSQL_USER"], passwd = settings["MYSQL_PASSWD"], db = settings["MYSQL_DB"], use_unicode = True, charset="utf8", ) dbpool = adbapi.ConnectionPool("pymysql",**dbparms) return cls(dbpool) def process_item(self,item,spider): ''' 使用twisted将mysql插入变成异步 :param item: :param spider: :return: ''' query = self.dbpool.runInteraction(self.do_insert,item) query.addErrback(self.handle_error) def handle_error(self,failure): #处理异步插入的异常 print(failure) def do_insert(self,cursor,item): #具体插入数据 insert_sql = ''' insert into jobbole_article(title,create_date,url,url_object_id,front_image_url,front_image_path,comment_nums,fav_nums,praise_nums,tag,content) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s) ''' cursor.execute(insert_sql,(item["title"],item["create_date"],item["url"],item["url_object_id"],item["front_image_url"],item["front_image_path"],item["comment_nums"],item["fav_nums"],item["praise_nums"],item["tag"],item["content"])) class ArticleImagePipeline(ImagesPipeline): ''' 对图片的处理 ''' def item_completed(self, results, item, info): for ok ,value in results: if ok: image_file_path = value["path"] item['front_image_path'] = image_file_path else: item['front_image_path'] = "" return item
