
k近邻算法-5.数据归一化
数据归一化(Feature Scaling)
多个特征值时,其中某个特征数量级比较大,其他特征较小时,分类结果会被特征值所主导,而弱化了其他特征的影响,这是各个特征值的量纲不同所致,需要将数据归一化处理

如上图所示,样本间的距离,被发现时间所主导
解决办法:将所有的数据映射到同一尺度
方法一:最值归一化
把所有的数据映射到0-1之间,适用于有明显的边界,受outlier极值影响较大,比如收入的分布
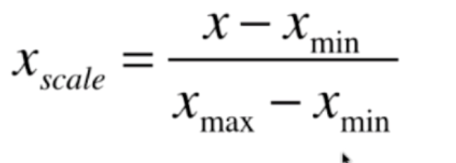
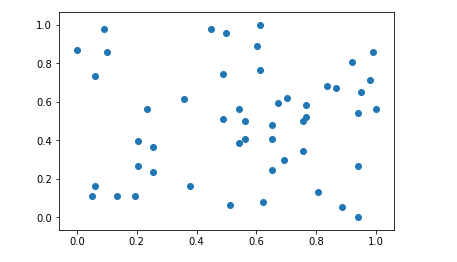
import numpy
import matplotlib.pyplot as plt
x = numpy.random.randint(0,100,(50,4))
x = np.array(x,dtype=float)
for i in range(x.shape[1]):
x[:,i] = (x[:,i] - np.min(x[:,i])) / (np.max(x[:,i]) - np.min(x[:,i]))
plt.scatter(x[:,0],x[:,1])
plt.show()
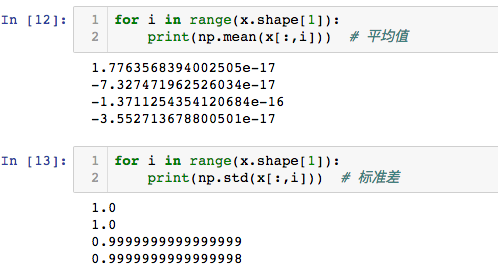
归一化后的平均值和方差:

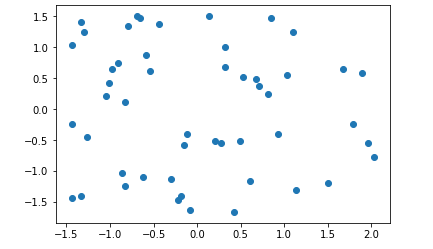
方法二:均值方差归一化
把所有数据归一化到均值为0,方差为1的分布中,适用于数据分布没有明显的边界,存在极端数据值的数据集

import numpy
import matplotlib.pyplot as plt
x = numpy.random.randint(0,100,(50,4))
x = numpy.array(x,dtype=float)
for i in range(x.shape[1]):
x[:,i] = (x[:,i] - numpy.mean(x[:,i])) / numpy.std(x[:,i])
plt.scatter(x[:,0],x[:,1])
plt.show()
归一化后的平均值和方差:
scikit-learn 中的 StandardScaler
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
x = iris.data
y = iris.target
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2)
从预处理模块导入标准 标量器
from sklearn.preprocessing import StandardScaler
standardScaler = StandardScaler()
standardScaler.fit(x_train)
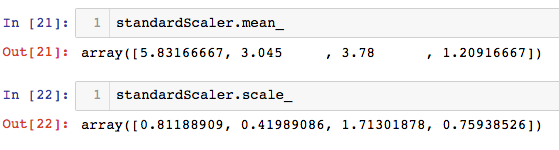
x_train = standardScaler.transform(x_train)
x_test = standardScaler.transform(x_test)
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(x_train,y_train)
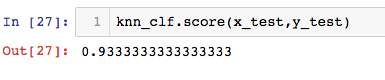
knn_clf.score(x_test,y_test)
自己封装的StandardScaler
预处理文件
import numpy as np
class StandardScaler:
def __init__(self):
self.mean_ = None
self.scale_ = None
#求出传入的x数据集的每一列的均值和标准差
def fit(self, x):
assert x.ndim == 2, "the dimension of x must be 2"
self.mean_ = np.array([np.mean(x[:,i]) for i in range(x.shape[1])])
self.scale_ = np.array([np.std(x[:,i]) for i in range(x.shape[1])])
return self
#对x进行数据归一化
def transform(self, x):
assert x.ndim == 2, "the dimension of x must be 2"
assert self.mean_ is not None and self.scale_ is not None,\
"must fit before transform!"
assert x.shape[1] == len(self.mean_), \
"the feature number os x must be equal to mean_ and std_"
res_x = np.empty(shape=x.shape, dtype=float)
for col in range(x.shape[1]):
res_x[:,col] = (x[:,col] - self.mean_[col]) / self.scale_[col]
return res_x
调用封装的预处理库
from mylib import preprocessing
standScaler = preprocessing.StandardScaler() #创建一个均值方差归一化的类
standScaler.fit(x_train) #找出样本的均值和标准差
x_train = standScaler.transform(x_train) #根据均值,标准差,求出归一化的值
x_test = standScaler.transform(x_test) #针对测试数据,也是一样用训练集的均值,标准差
knn = KNeighborsClassifier(n_neighbors=3) #knn算法分类器
knn.fit(x_train,y_train)
knn.score(x_test,y_test)

