k近邻算法-6.更多思考
k近邻算法的思考
k近邻的缺点
1.效率低下
如果训练集有m个样本,n个特征,预测一个新的数据,需要O(m*n)
优化:使用数结构,KD-Tree,Ball-Tree
2.高度数据相关
对outline更敏感,如果使用三近邻算法,在预测的样本中间如果有两个错误,则足够影响结果的准确性,尽管空间中有大量正确的样本。
3.预测结果不具有可解释性
只找到了和预测的这些样本比较近的样本,我们就说要预测的样本属于这个类别,但为什么属于这个样本我们无从得知,更多时候,我们只拿到结果是远远不够的。
4.维数灾难
随着维度的增加,看似相近的两个点之间的距离变的越来越大
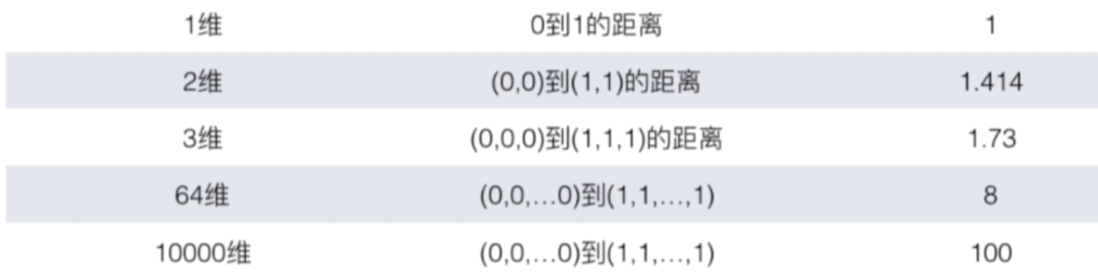
解决办法:降维
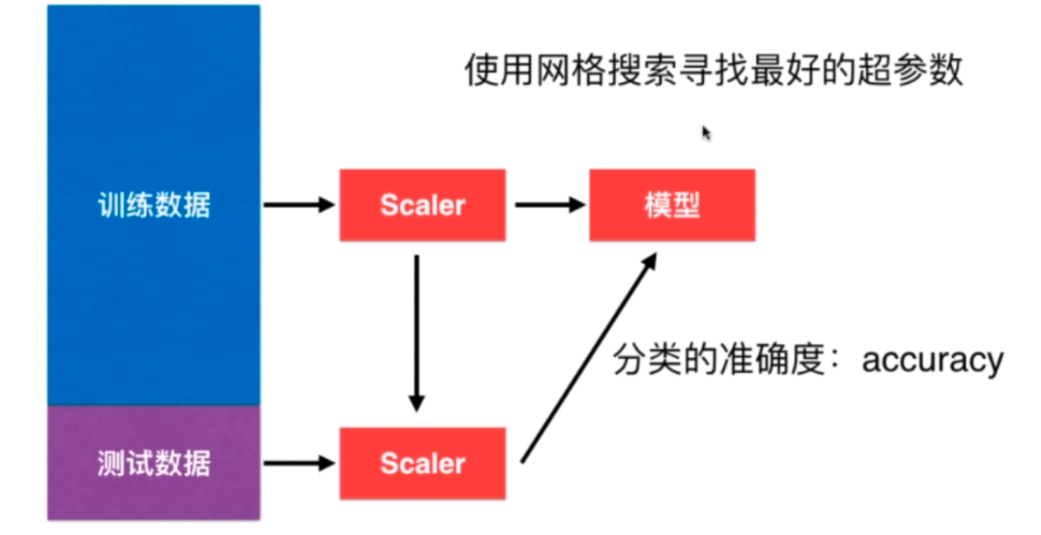
机器学习的一般流程: