
k近邻算法-2.模型评估与选择
模型评估与选择
如何评价一个算法的性能?
将所有样本数据作为训练数据集参与模型的创建,得到的模型如果很差,在真实环境中会造成损失,而真实环境难以拿到真实的归类。此时我们需要将所有的样本数据分类,一部分作为训练数据集,一部分作为测试数据集,这样可以检测模型的泛化能力从而对算法做出改进。
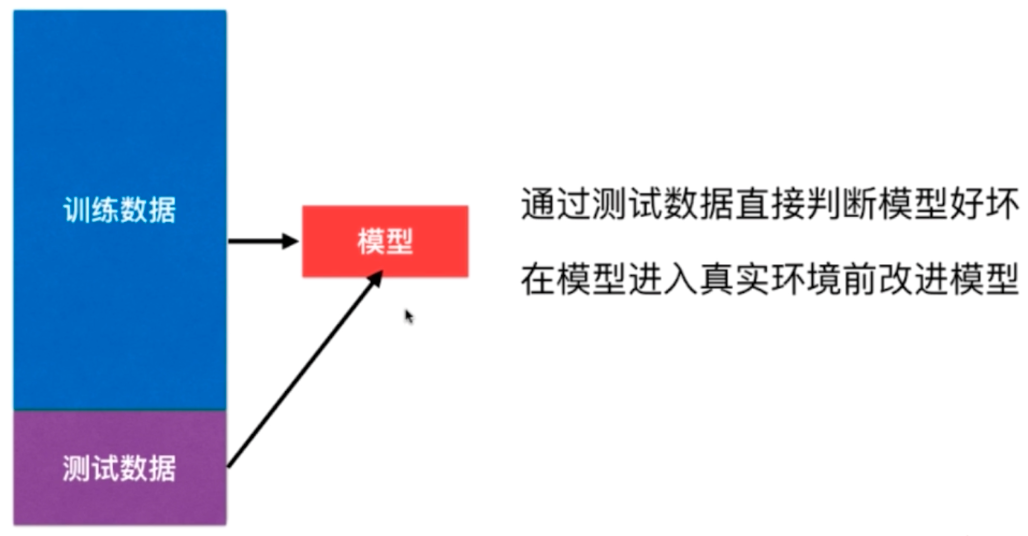
train_test_split
将数据集分割,一部分作为训练数据集,一部分作为测试数据集。此方法为留出法。
从机器学习库中加载数据集(鸢尾花数据集)
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
iris = datasets.load_iris()
x = iris.data
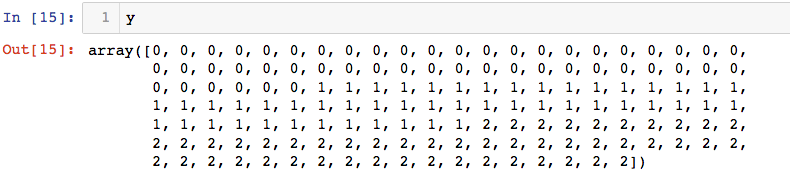
y = iris.target

鸢尾花数据集共有150个样本,每个样本有四个特征,为鸢尾花的叶片和花瓣特征,对应三种不同的鸢尾花类别,其数据集描述如下:
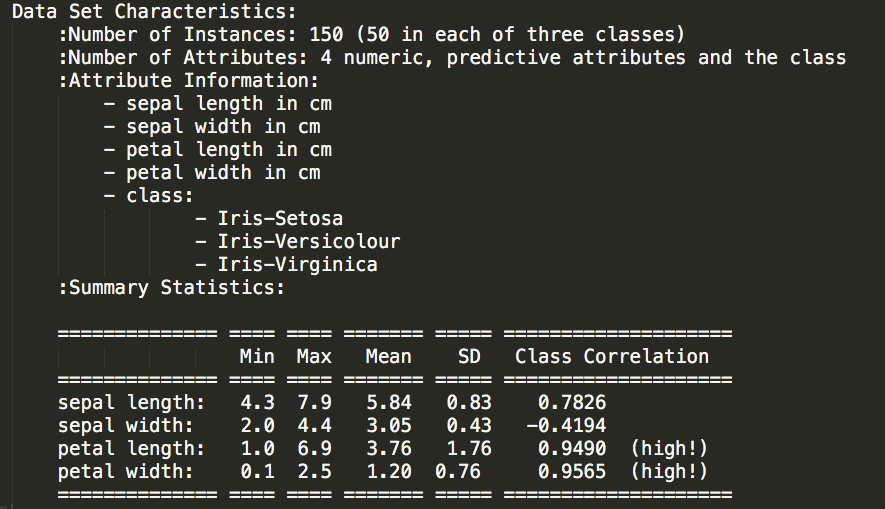
每个数据样本对应的花类别结果:
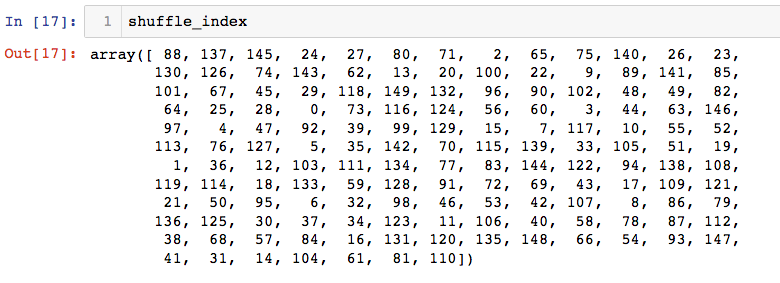
怎么分割?此鸢尾花数据是按花种类顺序排列的,如果取前一部分或者后一部分的一部分样本作为训练集,训练模型泛化能力会很差,所以此处需要将数据索引随机打乱
#用random中的permutation 对数据索引进行打乱
shuffle_index = np.random.permutation(len(x))
训练数据和测试数据分类,取20%的数据作为测试数据集
# 规定测试数据和训练数据的分配比例
test_ratio = 0.2
test_size = int(len(x) * test_ratio)
test_index = shuffle_index[:test_size]
train_index = shuffle_index[test_size:]
x_train = x[train_index]
x_test = x[test_index]
y_train = y[train_index]
y_test = y[test_index]
scikit-learn中的train_test_split
# 从sklearn中的model_selection导入 训练_测试_数据集分离
from sklearn.model_selection import train_test_split
# 返回训练的样本,和测试的样本
x_train,x_test,y_train,y_test = train_test_split(x, y, test_size=0.2, random_state=600)
#random_state 指定随机数种子,结果可重复
注:mac系统python相关路径操作
# 编辑.bash_profile文件,增加环境变量PYTHONPATH,--->python包的路径,用冒号分割
# vim ~/.bash_profile
# PYTHONPATH="${PYTHONPATH}:/Users/yuxiaolong/人工智能/packets"
# export PYTHONPATH
# Setting PATH for Python 3.7 ---->python程序的执行路径
# The original version is saved in .bash_profile.pysave
#PATH="/Library/Frameworks/Python.framework/Versions/3.7/bin:${PATH}"
#export PATH

