Hdfs的写入机制
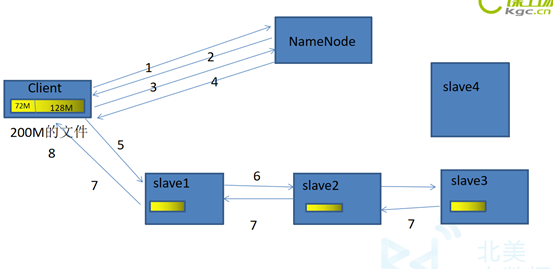
首先我要将一个200M文件存到HDFS集群中。
- 客户端通过RPC(远程服务)访问NameNode,请求写入一个文件。
- NameNode检查客户端是否有权限写入,如果有权限返回一个响应。如果没有客户端就会抛出一个异常。
- 客户端会将文件按BlckSize大小(默认128M)将文件切分成一个一个Block块,然后请求写入第一个Block块。
- NameNode会根据它的负载均衡机制,给客户端返回满足其副本数量(默认是3)的列表(BlockId:主机,端口号,存放的目录)。
- 客户端根据返回的列表,开始建立管道(pipeline)。客户端->第一个节点->第二个节点->第三个节点。
- 开始传输数据,Block按照Packet一次传输,当一个Packet成功传输到第一个DataNode上以后,第一个DodaNode就把这个Packet开始进行复制,并将这个Packet通过管道传输到下一个DataNode上,下一个DataNode接收到Packet后,继续进行复制,再传输到下一个DataNode上。
- 当一个Block块成功传输完以后,从最后一个DataNode开始,依次从管道返回ACK队列,到客户端。
- 客户端会在自己内部维护着一个ACK队列,跟返回来的ACK队列进行匹配,只要有一台DataNode写成功,就认为这次写操作是完成的。
- 开始进行下一个Block块的写入。重复3-8。
如果在传输的时候,有的DataNode宕机了,这个DataNode就会从这个管道中退出。剩下的DataNode继续传输。然后,等传输完成以后,NameNode会再分发出一个节点,去写成功的DataNode上复制出一份Block块,写到新的DataNode上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号