HBase 与 Phoenix 基础
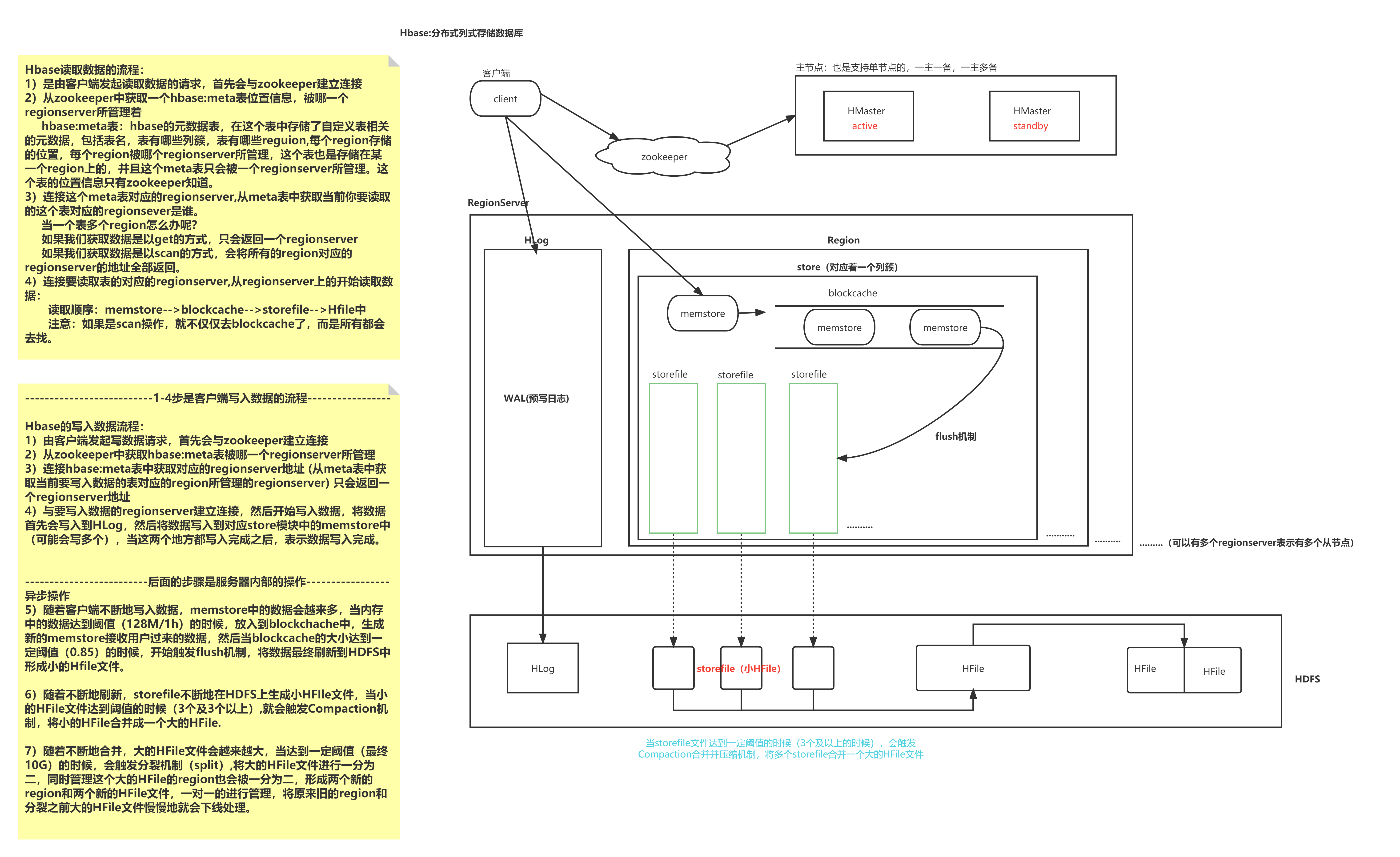
HBase 架构与读取流程
HBase RowKey 设计
HBase 是三维有序存储的,通过rowkey,column key(column family qulifier) 和TimeStamp 这三个维度确定唯一的cell 数据。
HBase中rowkey可标识一行记录,在HBase中共有2种方式提供查询:
- 通过get方式,指定rowkey获取唯一一条记录
- 通过scan方式,是指startRow和stopRow参数进行范围匹配
全表扫描,直接扫描整张表中所有行记录
rowkey长度原则
rowkey是一个二进制码流,可以是任意字符串,最大长度64kb,一般设计成定长,不超过16个字节。
数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,比如超过100字节,1000w行数据,光rowkey就要占用100*1000w=10亿个字节,将近1G数据,这样会极大影响HFile的存储效率;
MemStore将缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。
目前操作系统都是64位系统,内存8字节对齐,控制在16个字节,8字节的整数倍利用了操作系统的最佳特性。
rowkey唯一原则
必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
rowkey热点数据
HBase中的行是按照rowkey的字典顺序排序的,这种设计优化了scan操作,可以将相关的行以及会被一起读取的行存取在临近位置,便于scan。然而糟糕的rowkey设计是热点的源头。 热点发生在大量的client直接访问集群的一个或极少数个节点(访问可能是读,写或者其他操作)。大量访问会使热点region所在的单个机器超出自身承受能力,引起性能下降甚至region不可用,这也会影响同一个RegionServer上的其他region,由于主机无法服务其他region的请求。 设计良好的数据访问模式以使集群被充分,均衡的利用。
为了避免写热点,设计rowkey使得不同行在同一个region,但是在更多数据情况下,数据应该被写入集群的多个region,而不是一个。
热点数据解决方案
加盐
这里所说的加盐不是密码学中的加盐,而是在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同。分配的前缀种类数量应该和你想使用数据分散到不同的region的数量一致。加盐之后的rowkey就会根据随机生成的前缀分散到各个region上,以避免热点。
哈希
哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据
反转
第三种防止热点的方法时反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。
反转rowkey的例子以手机号为rowkey,可以将手机号反转后的字符串作为rowkey,这样的就避免了以手机号那样比较固定开头导致热点问题
时间戳反转
一个常见的数据处理问题是快速获取数据的最近版本,使用反转的时间戳作为rowkey的一部分对这个问题十分有用,可以用 Long.Max_Value - timestamp 追加到key的末尾,例如 [key]reverse_timestamp , [key] 的最新值可以通过scan [key]获得[key]的第一条记录,因为HBase中rowkey是有序的,第一条记录是最后录入的数据。
比如需要保存一个用户的操作记录,按照操作时间倒序排序,在设计rowkey的时候,可以这样设计
[userId反转]Long.Max_Value - timestamp,在查询用户的所有操作记录数据的时候,直接指定反转后的userId,startRow是[userId反转]000000000000,stopRow是[userId反转]Long.Max_Value - timestamp
如果需要查询某段时间的操作记录,startRow是[user反转]Long.Max_Value - 起始时间,stopRow是[userId反转]Long.Max_Value - 结束时间
二级索引种类
1、创建单列索引
2、同时创建多个单列索引
3、创建联合索引(最多同时支持3个列)
4、只根据rowkey创建索引
Phoenix 二级索引
全局索引
全局索引适合读多写少的场景。如果使用全局索引,读数据基本不损耗性能,所有的性能损耗都来源于写数据。数据表的添加、删除和修改都会更新相关的索引表(数据删除了,索引表中的数据也会删除;数据增加了,索引表的数据也会增加)
注意: 对于全局索引在默认情况下,在查询语句中检索的列如果不在索引表中,Phoenix不会使用索引表将,除非使用hint。
示例
# 创建DIANXIN.sql
CREATE TABLE IF NOT EXISTS DIANXIN (
mdn VARCHAR ,
start_date VARCHAR ,
end_date VARCHAR ,
county VARCHAR,
x DOUBLE ,
y DOUBLE,
bsid VARCHAR,
grid_id VARCHAR,
biz_type VARCHAR,
event_type VARCHAR ,
data_source VARCHAR ,
CONSTRAINT PK PRIMARY KEY (mdn,start_date)
) column_encoded_bytes=0;
# 上传数据DIANXIN.csv
# 导入数据
psql.py master,node1,node2 DIANXIN.sql DIANXIN.csv
-- 创建全局索引
CREATE INDEX DIANXIN_INDEX ON DIANXIN ( end_date );
-- 查询数据 ( 索引未生效)
select * from DIANXIN where end_date = '20180503154014';
-- 强制使用索引 (索引生效) hint
select /*+ INDEX(DIANXIN DIANXIN_INDEX) */ * from DIANXIN where end_date = '20180503154014';
select /*+ INDEX(DIANXIN DIANXIN_INDEX) */ * from DIANXIN where end_date = '20180503154014' and start_date = '20180503154614';
-- 取索引列,(索引生效)
select end_date from DIANXIN where end_date = '20180503154014';
-- 创建多列索引
CREATE INDEX DIANXIN_INDEX1 ON DIANXIN ( end_date,COUNTY );
-- 多条件查询 (索引生效)
select end_date,MDN,COUNTY from DIANXIN where end_date = '20180503154014' and COUNTY = '8340104';
-- 查询所有列 (索引未生效)
select * from DIANXIN where end_date = '20180503154014' and COUNTY = '8340104';
-- 查询所有列 (索引生效)
select /*+ INDEX(DIANXIN DIANXIN_INDEX1) */ * from DIANXIN where end_date = '20180503154014' and COUNTY = '8340104';
-- 单条件 (索引未生效)
select end_date from DIANXIN where COUNTY = '8340103';
-- 单条件 (索引生效) end_date 在前
select COUNTY from DIANXIN where end_date = '20180503154014';
-- 删除索引
drop index DIANXIN_INDEX on DIANXIN;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号