大数据~面试~Flink
Index
Flink面试题
1. Flink 与Spark区别?
2. Flink组件栈
3. Flink架构中的角色
4. Flink程序执行流程图
5. Flink几个双流join算子
6. Flink分区
7. Flink窗口函数种类
8. 对于滚动窗口的超时数据,如何处理
9. Flink如何实现exactly-once
10. Flink内存管理
11. Flink序列化如何实现
12. Flink的RPC
13. Flink使用window 出现数据倾斜
14. Flink的反压
15. operator chain 及Flink优化执行task
16. subtask
17. subtask在slot中执行
18. 使用bloom filter 统计UV
19. Flink集群优化
Flink面试题[Top]
1. Flink 与Spark区别?[Top]
架构模型上:Spark Streaming 的task运行依赖driver 和 executor和worker,当然driver和excutor还依赖于集群管理器Standalone或者yarn等。而Flink运行时主要是JobManager、TaskManage和TaskSlot。
数据模型上:Spark Streaming 是微批处理,运行的时候需要指定批处理的时间,每次运行 job 时处理一个批次的数据;Flink 是基于事件驱动的,事件可以理解为消息。
时间机制上:flink 支持三种时间机制事件时间,注入时间,处理时间,同时支持 watermark 机制处理滞后数据。Spark Streaming 只支持处理时间,Structured streaming则支持了事件时间和watermark机制。
容错机制上:二者保证exactly-once的方式不同。spark streaming 通过保存offset和事务的方式;Flink 则使用两阶段提交协议来解决这个问题。
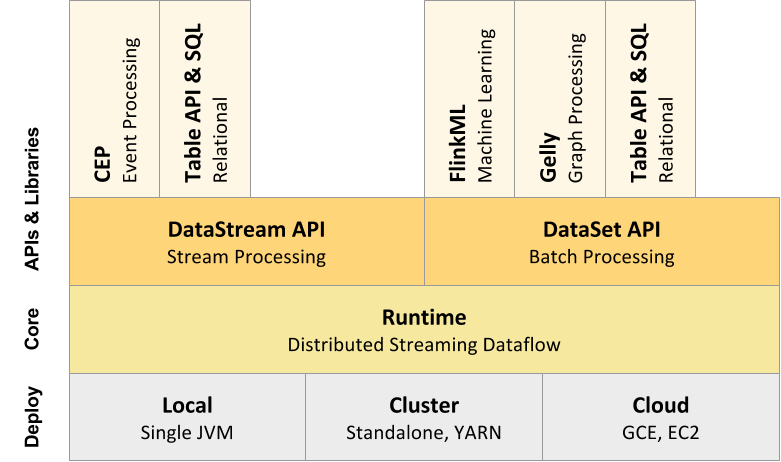
2. Flink组件栈[Top]
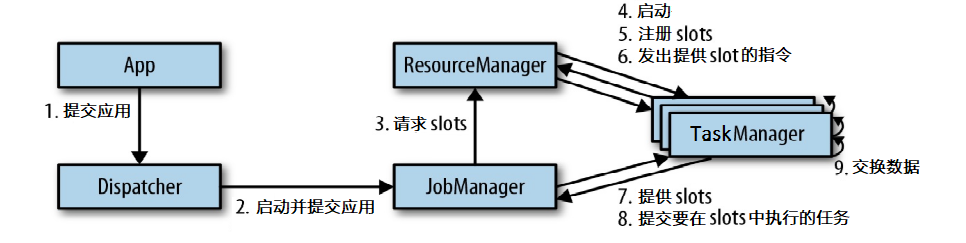
3. Flink架构中的角色[Top]
client,Jobmanager,taskmanager
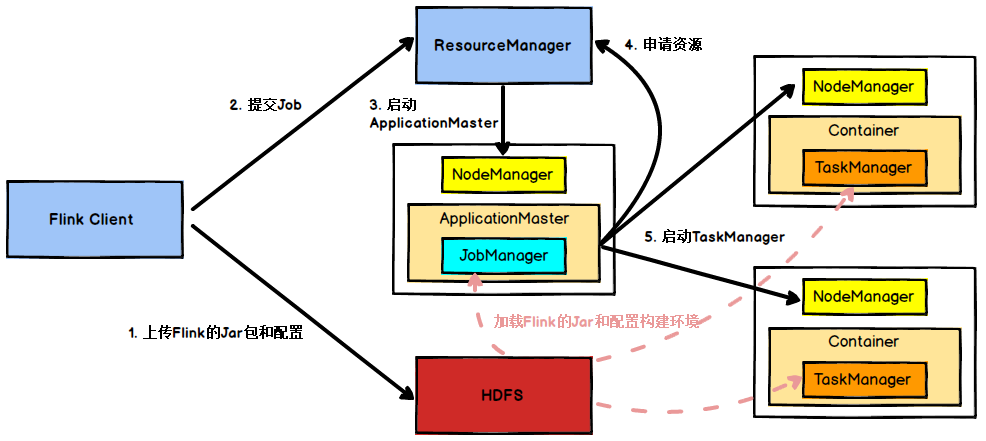
4. Flink程序执行流程图[Top]
具体的,将任务提交到yarn上,则有:
5. Flink几个双流join算子[Top]
join: 双流内连接,在时间维度join
coGroup: 侧外,相当于left join和right join,侧重于group,只能用于window
connect: 双流连接,返回connectStreams, 只能2流一起connect,没有匹配条件
union: 可多流合并,合并DataStream或Dataset,不去重,2个源数据保存
6. Flink分区[Top]
GlobalPartitioner: DataStream => DataStream
GlobalPartitioner,GLOBAL分区。将记录输出到下游Operator的第一个实例。
ShufflePartitioner: DataStream => DataStream
ShufflePartitioner,SHUFFLE分区。将记录随机输出到下游Operator的每个实例。
RebalancePartitioner: DataStream => DataStream
RebalancePartitioner,REBALANCE分区。将记录以循环的方式输出到下游Operator的每个实例。
RescalePartitioner: DataStream => DataStream
RescalePartitioner,RESCALE分区。基于上下游Operator的并行度,将记录以循环的方式输出到下游Operator的每个实例。举例: 上游并行度是2,下游是4,则上游一个并行度以循环的方式将记录输出到下游的两个并行度上;上游另一个并行度以循环的方式将记录输出到下游另两个并行度上。若上游并行度是4,下游并行度是2,则上游两个并行度将记录输出到下游一个并行度上;上游另两个并行度将记录输出到下游另一个并行度上。
BroadcastPartitioner: DataStream => DataStream
BroadcastPartitioner,BROADCAST分区。广播分区将上游数据集输出到下游Operator的每个实例中。适合于大数据集Join小数据集的场景。
ForwardPartitioner
ForwardPartitioner,FORWARD分区。将记录输出到下游本地的operator实例。ForwardPartitioner分区器要求上下游算子并行度一样。上下游Operator同属一个SubTasks。
KeyGroupStreamPartitioner(HASH方式):
KeyGroupStreamPartitioner,HASH分区。将记录按Key的Hash值输出到下游Operator实例。
CustomPartitionerWrapper
CustomPartitionerWrapper,CUSTOM分区。通过Partitioner实例的partition方法(自定义的)将记录输出到下游。
7. Flink窗口函数种类[Top]
Tumbling window: 将数据依据固定窗口长度对数据切片。
Sliding window: 滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成。
Session window: 由一系列事件组合一个指定时间长度的timeout间隙组成,类似于web应用的session,也就是一段时间没有接收到新数据就会生成新的窗口。
CountWindow:按照指定的数据条数生成一个Window,与时间无关。
8. 对于滚动窗口的超时数据,如何处理[Top]
采用业界的标准方式,使用侧流输出延迟的流数据,然后通过更新原窗口的数据,进行整体数据的更新,从而达到数据的延迟加载。
如果窗口不能直接更新,可以将侧流的延时数据写入到MySQL,然后再根据业务需要进行操作。
9. Flink如何实现exactly-once[Top]
见 Flink如何保证数据的一致性
10. Flink内存管理[Top]
Flink将对象都序列化到一个预分配的内存块上,此内存块叫memorySegment(默认32kb),代表固定长度的内存,是Flink中最小内存分配单元,每天记录会以序列化形式存储在一个或多个memorySegment中。
11. Flink序列化如何实现[Top]
Flink数据流通常是一种类型,只保存一份对象schema信息,节省存储空间。Flink支持任意Java或Scala类型,类型信息由TypeInfomation类表示。
Flink实现了自己的序列化框架,Flink处理的数据流通常是一种类型,所以可以只保存一份对象Schema信息,节省存储空间。又因为对象类型固定,所以可以通过偏移量存取。
Java支持任意Java或Scala类型,类型信息由TypeInformation类表示,TypeInformation支持以下几种类型:
BasicTypeInfo:任意Java 基本类型或String类型。
BasicArrayTypeInfo:任意Java基本类型数组或String数组。
WritableTypeInfo:任意Hadoop Writable接口的实现类。
TupleTypeInfo:任意的Flink Tuple类型(支持Tuple1 to Tuple25)。Flink tuples 是固定长度固定类型的Java Tuple实现。
CaseClassTypeInfo: 任意的 Scala CaseClass(包括 Scala tuples)。
PojoTypeInfo: 任意的 POJO (Java or Scala),例如,Java对象的所有成员变量,要么是 public 修饰符定义,要么有 getter/setter 方法。
GenericTypeInfo: 任意无法匹配之前几种类型的类。
针对前六种类型数据集,Flink皆可以自动生成对应的TypeSerializer,能非常高效地对数据集进行序列化和反序列化。对于最后一种数据类型,Flink会使用Kryo进行序列化和反序列化。
12. Flink的RPC[Top]
底层基于Akka实现
13. Flink使用window 出现数据倾斜[Top]
注:指不同窗口内积攒的数据量不同,主要由源头数据产生速度导致差异
核心思路:
- 重新设计key,基于热点省份 + 区
- 窗口计算前做预聚合
14. Flink的反压[Top]
Flink运行时主要由operator和stream构成,每个operator会消费中间态的流,并在流上进行转换,生成新的流。Flink会将逻辑流放入阻塞队列中,而队列通过缓冲池来表现。缓冲池管理着一组缓冲,用来实现Flink的反压。
Flink使用了一个小trick来实现反压的监控。如果一个Task反压降速,则会卡在LocalBufferPool申请内存块上,不断采样task的stack trace可实现反压监控。
故在Flink的实现中,仅当web页面切换到Job的Backpressure页面,才会触发反压检测。
15. operator chain 及Flink优化执行task[Top]
在执行操作时,Flink可将链接的操作operator链接到一起,称为一个task。但不是所有operator都可以被链接,keyBy等操作会导致shuffle和重分区,一个Task是可以链接最小操作链(operator chains)
16. subtask[Top]
A subtask is one parallel slice of a task, 即一个task可按照并行度拆分为多个subTask
17. subtask在slot中执行[Top]
由于每个操作所需资源不同, 故Flink允许多个subtasks 共享slots,只需要来自同一个Tob就行。
18. 使用bloom filter 统计UV[Top]
- Flink直接统计userId,使用timeWindowAll以及apply算子
- 优化使用bloom filter进行UV统计
补充:布隆过滤器是一种数据结构,特点是高效地插入与查询,可描述"某样东西一定不存在或者可能存在"。布隆过滤器本身是一个很长的二进制向量。优点是高效,占用空间少,缺点是返回结果是概率性的。
19. Flink集群优化[Top]
taskmanager.heap.mb 调优,默认1024,可以提升为2048。 并且调整执行task的并行度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号