Flink如何保证数据的一致性
 flink一致性详解
flink一致性详解
当在分布式系统中引入状态时,自然也引入了一致性问题。一致性实际上是"正确性级别"的另一种说法,也就是说在成功处理故障并恢复之后得到的结果,与没有发生任何故障时得到的结果相比,前者到底有多正确?举例来说,假设要对最近一小时登录的用户计数。在系统经历故障之后,计数结果是多少?如果有偏差,是有漏掉的计数还是重复计数?
一致性级别
在流处理中,一致性可以分为3个级别:
- at-most-once: 这其实是没有正确性保障的委婉说法——故障发生之后,计数结果可能丢失。同样的还有udp。
- at-least-once: 这表示计数结果可能大于正确值,但绝不会小于正确值。也就是说,计数程序在发生故障后可能多算,但是绝不会少算。
- exactly-once: 这指的是系统保证在发生故障后得到的计数结果与正确值一致。
Flink的一个重大价值在于,它既保证了exactly-once,也具有低延迟和高吞吐的处理能力。
端到端(end-to-end)状态一致性
目前我们看到的一致性保证都是由流处理器实现的,也就是说都是在 Flink 流处理器内部保证的;而在真实应用中,流处理应用除了流处理器以外还包含了数据源(例如 Kafka)和输出到持久化系统。
端到端的一致性保证,意味着结果的正确性贯穿了整个流处理应用的始终;每一个组件都保证了它自己的一致性,整个端到端的一致性级别取决于所有组件中一致性最弱的组件。具体可以划分如下:
- 内部保证 —— 依赖checkpoint
- source 端 —— 需要外部源可重设数据的读取位置
- sink 端 —— 需要保证从故障恢复时,数据不会重复写入外部系统
而对于sink端,又有两种具体的实现方式:幂等(Idempotent)写入和事务性(Transactional)写入。
- 幂等写入
所谓幂等操作,是说一个操作,可以重复执行很多次,但只导致一次结果更改,也就是说,后面再重复执行就不起作用了。 - 事务写入
需要构建事务来写入外部系统,构建的事务对应着 checkpoint,等到 checkpoint 真正完成的时候,才把所有对应的结果写入 sink 系统中。
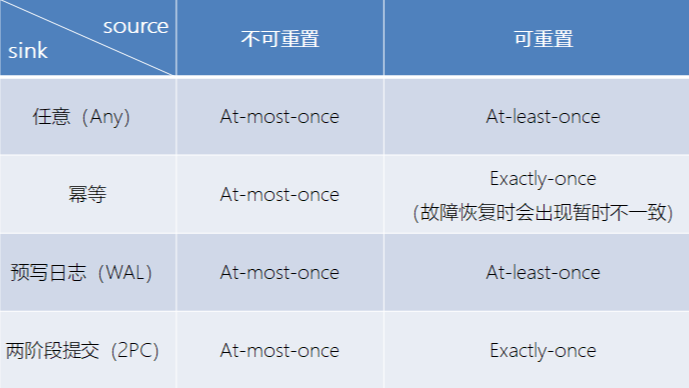
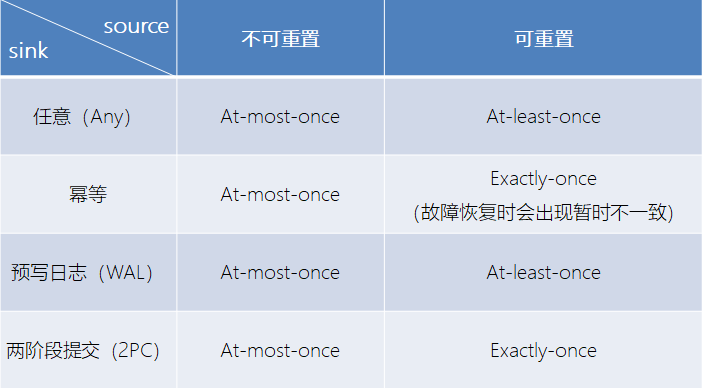
不同Source和Sink的一致性保证可用下表说明:
检查点
检查点的代码实践
public class CheckpointApp {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 开启checkpoint
/**
* 不开启checkpoint: 不重启
* 配置了重启策略: 使用配置的重启策略
* 1. 使用默认的重启策略: Integer.MAX_VALUE
* 2. 配置了重启策略, 使用配置的重启策略覆盖默认的
*
* 重启策略的配置:
* 1. code
* 2. yaml
*/
env.enableCheckpointing(5000);
// env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
// 作业完成后是否保留
CheckpointConfig config = env.getCheckpointConfig();
config.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 设置状态后端
config.setCheckpointStorage("file:////Users/carves/workspace/imook-flink");
// 自定义设置我们需要的重启策略
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // number of restart attempts, 正常运行之后,进入错误再运行的次数
Time.of(10, TimeUnit.SECONDS) // delay
));
DataStreamSource<String> source = env.socketTextStream("localhost", 9527);
source.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
if (value.contains("pk")) {
throw new RuntimeException("PK pk test!");
} else {
return value.toLowerCase();
}
}
}).flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] splits = value.split(",");
for (String split:
splits) {
out.collect(split);
}
}
}).map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
return Tuple2.of(value, 1);
}
}).keyBy(value -> value.f0)
.sum(1)
.print();
env.execute("CheckpointApp");
}
}
检查点算法:
Flink检查点算法的正式名称是异步分界线快照(asynchronous barrier snapshotting)。该算法大致基于Chandy-Lamport分布式快照算法。
检查点是Flink最有价值的创新之一,因为它使Flink可以保证exactly-once,并且不需要牺牲性能。
Flink + Kafka 实现exactly once 语义
我们知道,端到端的状态一致性的实现,需要每一个组件都实现,对于Flink + Kafka的数据管道系统(Kafka进、Kafka出)而言,各组件怎样保证exactly-once语义呢?利用checkpoint机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性
- source —— kafka consumer作为source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性
- sink —— kafka producer作为sink,采用两阶段提交 sink,需要实现一个 TwoPhaseCommitSinkFunction
内部的checkpoint机制我们已经有了了解,那source和sink具体又是怎样运行的呢?接下来我们逐步做一个分析。
我们知道Flink由JobManager协调各个TaskManager进行checkpoint存储,checkpoint保存在 StateBackend中,默认StateBackend是内存级的,也可以改为文件级的进行持久化保存。
2阶段提交
执行过程实际上是一个两段式提交,每个算子执行完成,会进行“预提交”,直到执行完sink操作,会发起“确认提交”,如果执行失败,预提交会放弃掉。
当 checkpoint 启动时,JobManager 会将检查点分界线(barrier)注入数据流;barrier会在算子间传递下去。
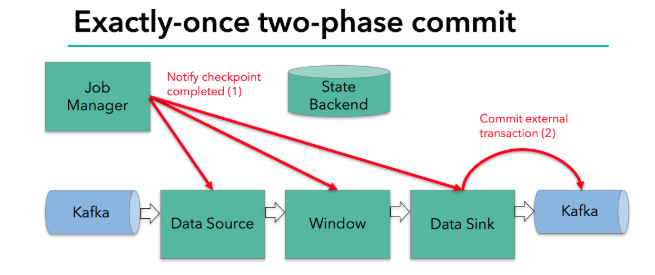
每个算子会对当前的状态做个快照,保存到状态后端。对于source任务而言,就会把当前的offset作为状态保存起来。下次从checkpoint恢复时,source任务可以重新提交偏移量,从上次保存的位置开始重新消费数据。
具体的两阶段提交步骤总结如下:第一条数据来了之后,开启一个 kafka 的事务(transaction),正常写入 kafka 分区日志但标记为未提交,这就是“预提交”。jobmanager 触发 checkpoint 操作,barrier 从 source 开始向下传递,遇到 barrier 的算子将状态存入状态后端,并通知 jobmanager。sink 连接器收到 barrier,保存当前状态,存入 checkpoint,通知 jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据。jobmanager 收到所有任务的通知,发出确认信息,表示 checkpoint 完成。sink 任务收到 jobmanager 的确认信息,正式提交这段时间的数据。外部kafka关闭事务,提交的数据可以正常消费了。
2阶段提交步骤
- 第一条数据来了之后,开启一个 kafka 的事务(transaction),正常写入 kafka 分区日志但标记为未提交,这就是“预提交”jobmanager 触发 checkpoint 操作,barrier 从 source 开始向下传递,遇到 barrier 的算子将状态存入状态后端,并通知 jobmanager
- sink 连接器收到 barrier,保存当前状态,存入 checkpoint,通知 jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据
- jobmanager 收到所有任务的通知,发出确认信息,表示 checkpoint 完成
- sink 任务收到 jobmanager 的确认信息,正式提交这段时间的数据
- 外部kafka关闭事务,提交的数据可以正常消费了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号