摘要:
新开分类,增加职业规划随想,用于记录自己对于以后的职业畅想。 畅想自己在2019-2023年这4年期间,自己从基础的平台开发运营, 到各种开源组件的学习应用,再到一个CRUD的大数据工程师。自己一路走来,更多是像一名技师,孰能生巧,唯手熟尔。 如今开一博客,记录日常解决问题,新技术探索学习。 也探讨 阅读全文
posted @ 2023-07-30 23:34
stone_la
阅读(142)
评论(0)
推荐(0)
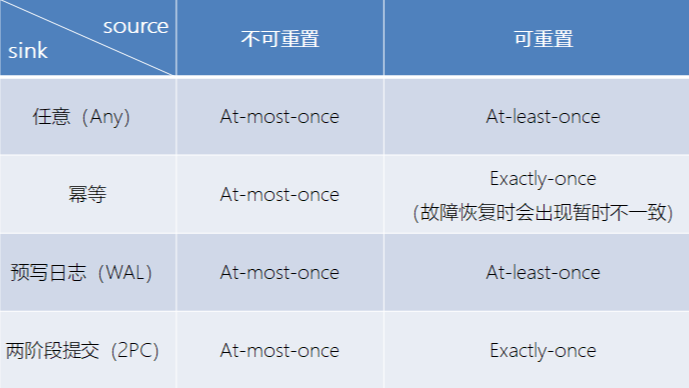 flink一致性详解 阅读全文
flink一致性详解 阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号