业务数据分析最佳案例!旅游业数据分析!⛵
 本文使用『城市酒店和度假酒店的预订信息』,对旅游业的发展现状进行数据分析,包含了完整的数据分析流程:数据读取、数据初览、数据预处理、描述性统计、探索性数据分析、关联分析、相关性分析。
本文使用『城市酒店和度假酒店的预订信息』,对旅游业的发展现状进行数据分析,包含了完整的数据分析流程:数据读取、数据初览、数据预处理、描述性统计、探索性数据分析、关联分析、相关性分析。

💡 作者:韩信子@ShowMeAI
📘 数据分析实战系列:https://www.showmeai.tech/tutorials/40
📘 本文地址:https://www.showmeai.tech/article-detail/388
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏ShowMeAI查看更多精彩内容

在本篇内容中,ShowMeAI将带大家对旅游业,主要是酒店预订需求进行分析,我们使用到的数据集包含城市酒店和度假酒店的预订信息,包括预订时间、住宿时长、客人入住的周末或工作日晚数以及可用停车位数量等信息。

我们本次用到的是 🏆酒店预订数据集,包含 119390 位客人,有 32 个特征字段,大家可以通过 ShowMeAI 的百度网盘地址下载。
🏆 实战数据集下载(百度网盘):公✦众✦号『ShowMeAI研究中心』回复『实战』,或者点击 这里 获取本文 [59]旅游业大数据多维度业务分析案例 『酒店预订数据集』
⭐ ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub
本文数据分析部分涉及的工具库,大家可以参考ShowMeAI制作的工具库速查表和教程进行学习和快速使用。
💡 导入工具库
# 数据处理&科学计算
import pandas as pd
import numpy as np
# 数据分析&绘图
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import plotly.graph_objects as go
import plotly.figure_factory as ff
import warnings
warnings.filterwarnings("ignore")
# 科学计算
from scipy.stats import skew,kurtosis
import pylab as py
# 时间
import time
import datetime
from datetime import datetime
from datetime import date
💡 读取数据
df = pd.read_csv("hotel_bookings.csv")
df.head()
💡 数据信息初览
df.info()

💡 数据预处理
💦 清洗&缺失值处理
首先统计字段缺失值比例
df.isnull().sum().sort_values(ascending = False) / len(df)

我们对有缺失的字段做一些缺失值填充工作
# 填充"agent" 和 "company" 字段中的缺失值
df["agent"].fillna(0, inplace = True)
df["company"].fillna(0, inplace = True)
# 使用众数填充"country"字段缺失值
df["country"].fillna(df["country"].mode()[0], inplace = True)
# 删除包含"children"缺失值的数据记录
df.dropna(subset = ["children"], axis = 0, inplace = True)
💦 字段数据处理
# 将“distribution_channel”列中的“Undefined”转换为“TA/TO”
df["distribution_channel"].replace("Undefined", "TA/TO", inplace = True)
# meal字段映射处理
df["meal"].replace(["Undefined", "BB", "FB", "HB", "SC" ], ["No Meal", "Breakfast", "Full Board", "Half Board", "No Meal"], inplace = True)
# 将“is_canceled”列的值从 0 和 1 转换为“Cancelled”和“Not Cancelled”
df["is_canceled"].replace([0, 1], ["Cancelled", "Not Cancelled"], inplace = True)
💦 调整数据类型
- 将
children、agent和company列的数据类型转换为整型 - 将
reservation_status_date列的数据类型从对象转换为日期类型
# 转整型
df["children"].astype(int)
df["agent"].astype(int)
df["company"].astype(int)
# 时间型
pd.to_datetime(df["reservation_status_date"])
💦 重复数据处理
df.drop_duplicates(inplace = True)
💦 构建汇总字段
我们对顾客总体的居住晚数进行统计
df["total_nights"] = df["stays_in_weekend_nights"] + df["stays_in_week_nights"]
💡 描述性统计
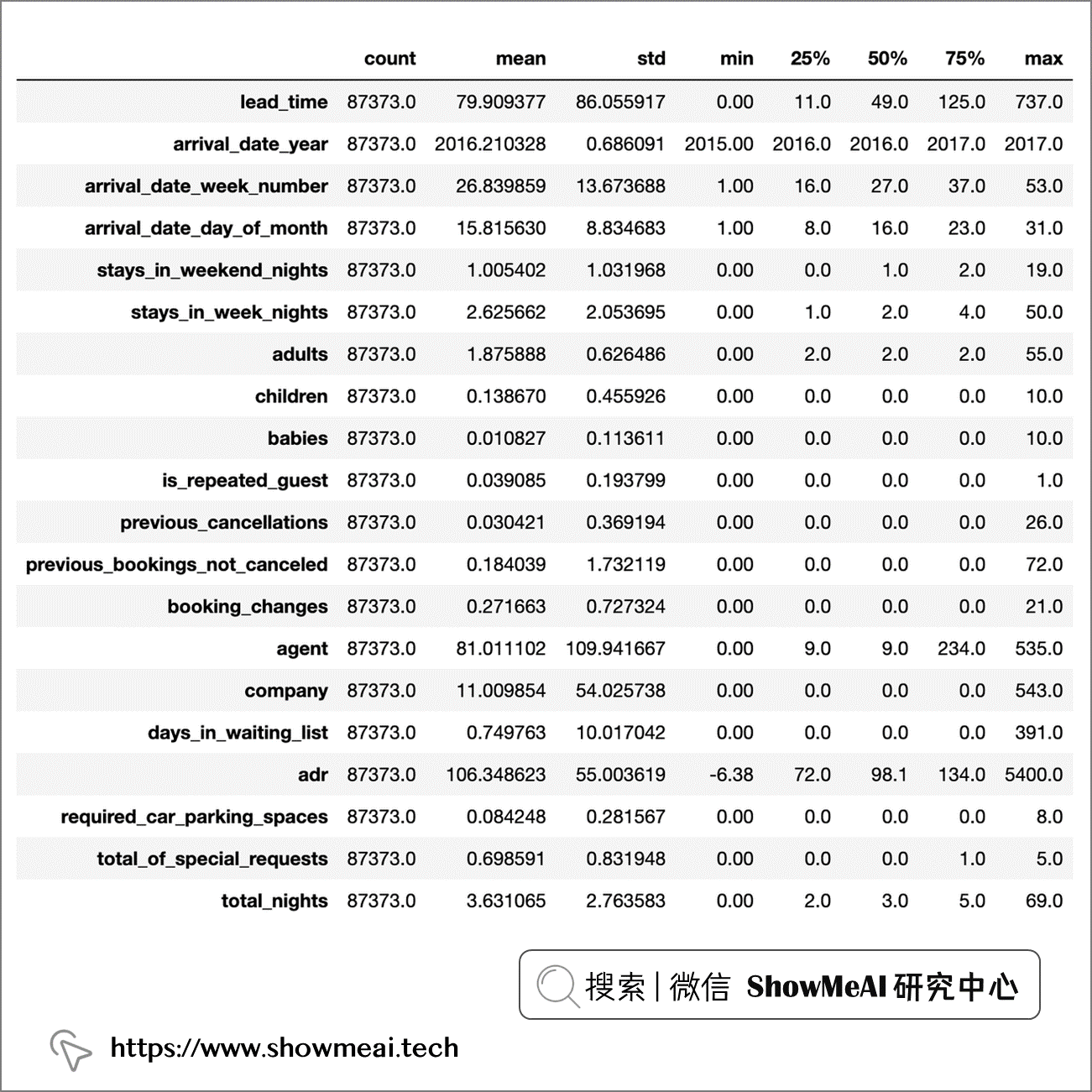
我们基于pandas的简单功能,对数据的统计分布做一个处理了解
df.describe().T
💡 探索性数据分析
💦 酒店维度分析
# 我们对 城市酒店 和 度假酒店 进行统计分析
labels = ['City Hotel', 'Resort Hotel']
colors = ["#538B8B", "#7AC5CD"]
order = df['hotel'].value_counts().index
plt.figure(figsize = (19, 9))
plt.suptitle('Bookings By Hotels', fontweight = 'heavy', fontsize = '16',
fontfamily = 'sans-serif', color = "black")
# Pie Chart
plt.subplot(1, 2, 1)
plt.title('Pie Chart', fontweight = 'bold', fontfamily = "sans-serif", color = 'black')
plt.pie(df["hotel"].value_counts(), pctdistance = 0.7, autopct = '%.2f%%', labels = labels,
wedgeprops = dict(alpha = 0.8, edgecolor = "black"), textprops = {'fontsize': 12}, colors = colors)
centre = plt.Circle((0,0), 0.45, fc = "white", edgecolor = "black")
plt.gcf().gca().add_artist(centre)
# Histogram
countplt = plt.subplot(1, 2, 2)
plt.title("Histogram", fontweight = "bold", fontsize = 14,
fontfamily = "sans-serif", color = 'black')
ax = sns.countplot(x = "hotel", data = df, order = order, edgecolor = "black", palette = colors)
for rect in ax.patches:
ax.text(rect.get_x() + rect.get_width()/2, rect.get_height() + 4.25, rect.get_height(),
horizontalalignment="center", fontsize = 10, bbox = dict(facecolor = "none", edgecolor = "black",
linewidth = 0.25, boxstyle = "round"))
plt.xlabel("Hotel", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.ylabel("Number Of Bookings", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.xticks([0, 1], labels)
plt.grid(axis = "y", alpha = 0.4)
df['hotel'].value_counts()
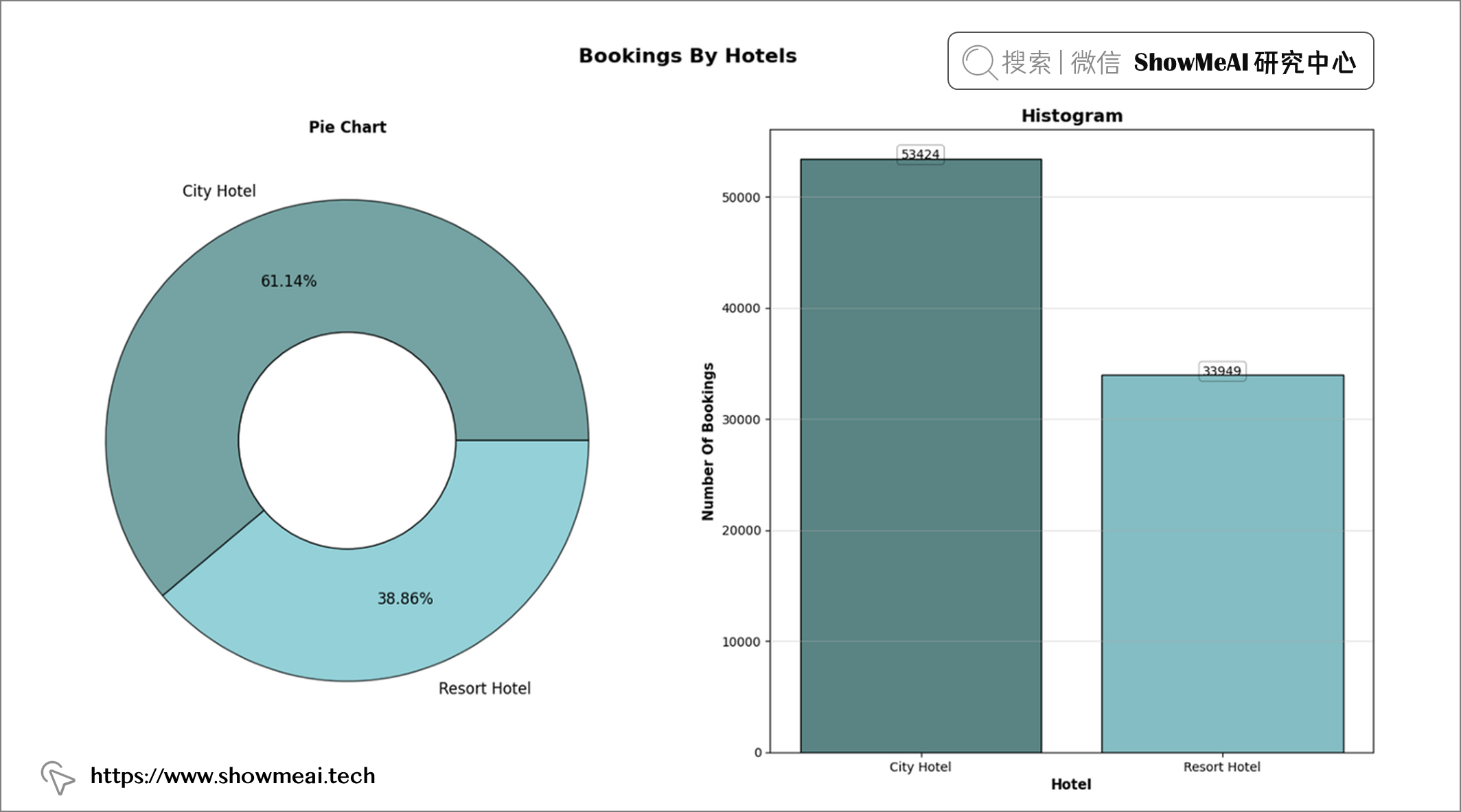
📢 结论:超过 60% 的预订酒店是城市酒店
💦 细分市场分析
labels = ["Online TA", "Offline TA/TO", "Direct", "Groups", "Corporate", "Complementary", "Aviation"]
order = df['market_segment'].value_counts().index
plt.figure(figsize = (22, 9))
plt.suptitle('Bookings By Market Segment', fontweight = 'heavy', fontsize = '16',
fontfamily = 'sans-serif', color = "black")
# Pie Chart
plt.subplot(1, 2, 1)
plt.title('Pie Chart', fontweight = 'bold', fontfamily = "sans-serif", color = 'black')
plt.pie(df["market_segment"].value_counts(), pctdistance = 0.7, autopct = '%.2f%%', labels = labels,
wedgeprops = dict(alpha = 0.8, edgecolor = "black"), textprops = {'fontsize': 12})
centre = plt.Circle((0,0), 0.45, fc = "white", edgecolor = "black")
plt.gcf().gca().add_artist(centre)
# Histogram
countplt = plt.subplot(1, 2, 2)
plt.title("Histogram", fontweight = "bold", fontsize = 14,
fontfamily = "sans-serif", color = 'black')
ax = sns.countplot(x = "market_segment", data = df, order = order, edgecolor = "black",)
for rect in ax.patches:
ax.text(rect.get_x() + rect.get_width()/2, rect.get_height() + 4.25, rect.get_height(),
horizontalalignment="center", fontsize = 10, bbox = dict(facecolor = "none", edgecolor = "black",
linewidth = 0.25, boxstyle = "round"))
plt.xlabel("Market Segment", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.ylabel("Number Of Bookings", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.grid(axis = "y", alpha = 0.4)
df['market_segment'].value_counts()
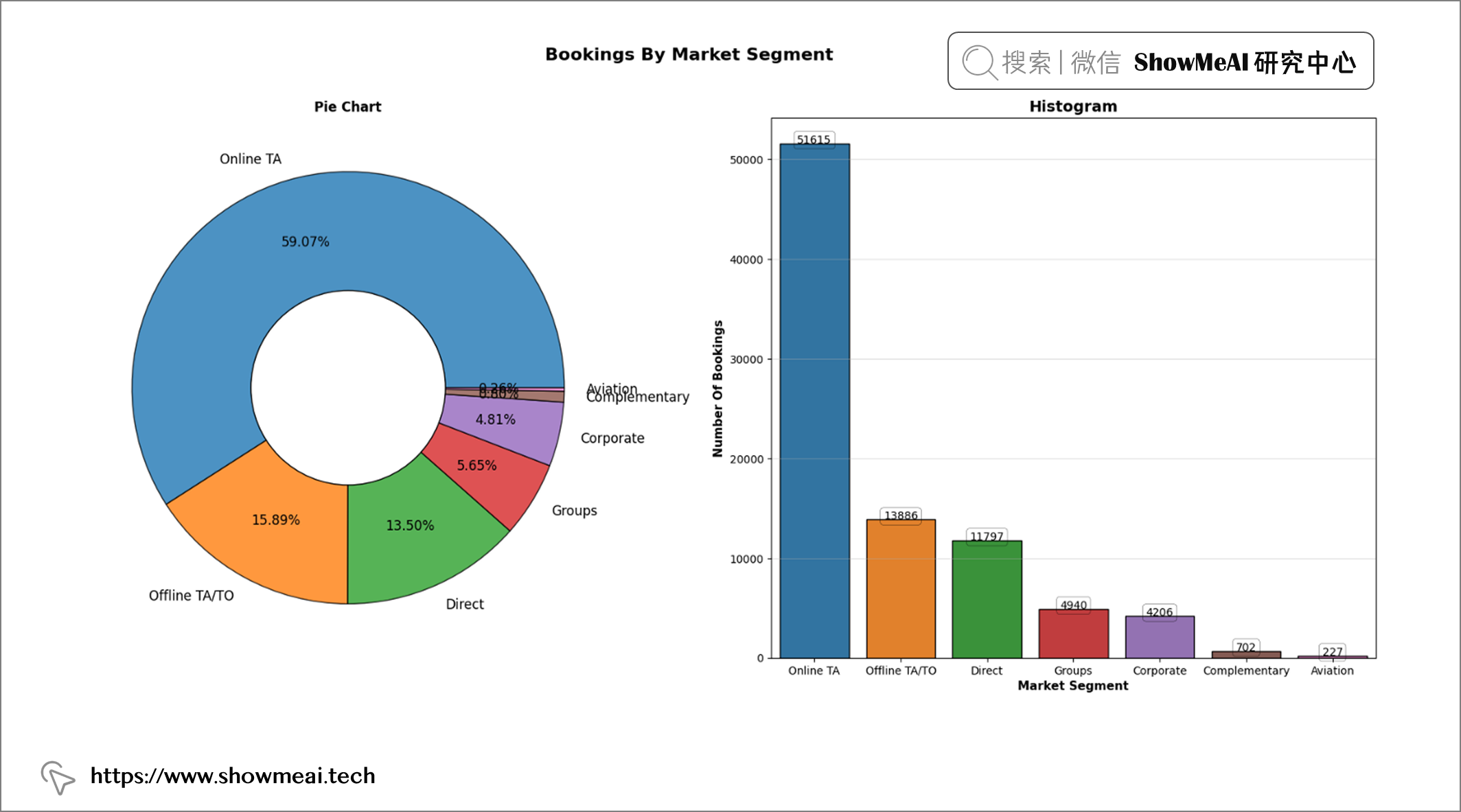
📢 结论:超过 50% 的预订是通过在线旅行社完成的。
💦 分销渠道分析
colors = ["#8B7D6B", "#000000", "#CDB79E", "#FFE4C4"]
labels = ["TA/TO", "Direct", "Corporate", "GDS"]
order = df['distribution_channel'].value_counts().index
plt.figure(figsize = (19, 9))
plt.suptitle('Bookings By Distribution Channel', fontweight = 'heavy', fontsize = '16',
fontfamily = 'sans-serif', color = "black")
# Pie Chart
plt.subplot(1, 2, 1)
plt.title('Pie Chart', fontweight = 'bold', fontfamily = "sans-serif", color = 'black')
plt.pie(df["distribution_channel"].value_counts(), pctdistance = 0.7, autopct = '%.2f%%', labels = labels, colors = colors,
wedgeprops = dict(alpha = 0.8, edgecolor = "black"), textprops = {'fontsize': 12})
centre = plt.Circle((0,0), 0.45, fc = "white", edgecolor = "black")
plt.gcf().gca().add_artist(centre)
# Histogram
countplt = plt.subplot(1, 2, 2)
plt.title("Histogram", fontweight = "bold", fontsize = 14,
fontfamily = "sans-serif", color = 'black')
ax = sns.countplot(x = "distribution_channel", data = df, order = order, edgecolor = "black", palette = colors)
for rect in ax.patches:
ax.text(rect.get_x() + rect.get_width()/2, rect.get_height() + 4.25, rect.get_height(),
horizontalalignment="center", fontsize = 10, bbox = dict(facecolor = "none", edgecolor = "black",
linewidth = 0.25, boxstyle = "round"))
plt.xlabel("Distribution Channel", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.ylabel("Number Of Bookings", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.grid(axis = "y", alpha = 0.4)
df['distribution_channel'].value_counts()
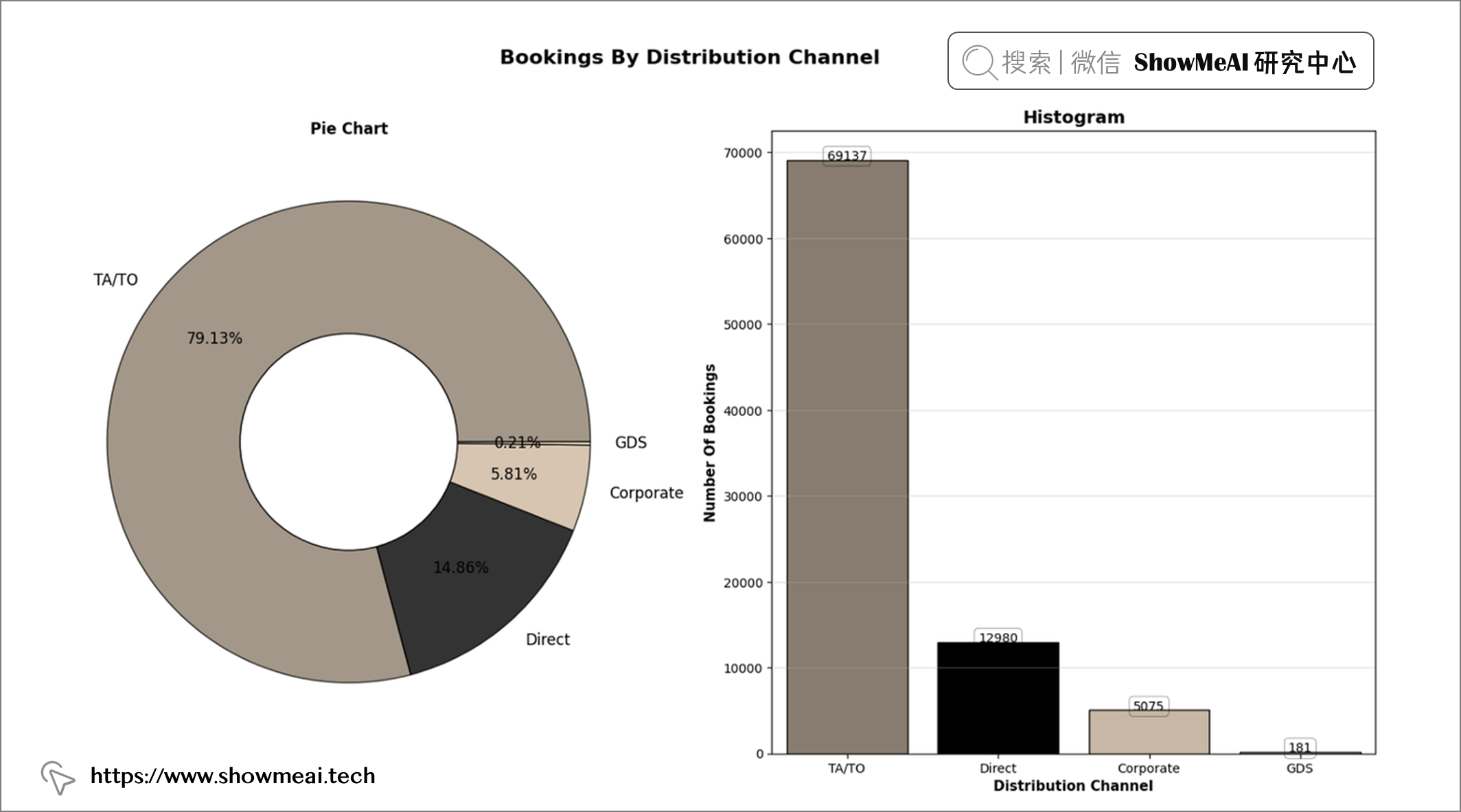
📢 结论:超过 80% 的预订是通过旅行社/运营商完成的。
💦 餐食分析
colors = ["#6495ED", "#1874CD", "#009ACD", "#00688B"]
labels = ["Breakfast", "No Meal", "Half Board", "Full Board"]
order = df['meal'].value_counts().index
plt.figure(figsize = (19, 9))
plt.suptitle('Bookings By Meals', fontweight = 'heavy', fontsize = '16',
fontfamily = 'sans-serif', color = "black")
# Pie Chart
plt.subplot(1, 2, 1)
plt.title('Pie Chart', fontweight = 'bold', fontfamily = "sans-serif", color = 'black')
plt.pie(df["meal"].value_counts(), pctdistance = 0.7, autopct = '%.2f%%', labels = labels, colors = colors,
wedgeprops = dict(alpha = 0.8, edgecolor = "black"), textprops = {'fontsize': 12})
centre = plt.Circle((0,0), 0.45, fc = "white", edgecolor = "black")
plt.gcf().gca().add_artist(centre)
# Histogram
countplt = plt.subplot(1, 2, 2)
plt.title("Histogram", fontweight = "bold", fontsize = 14,
fontfamily = "sans-serif", color = 'black')
ax = sns.countplot(x = "meal", data = df, order = order, edgecolor = "black", palette = colors)
for rect in ax.patches:
ax.text(rect.get_x() + rect.get_width()/2, rect.get_height() + 4.25, rect.get_height(),
horizontalalignment="center", fontsize = 10, bbox = dict(facecolor = "none", edgecolor = "black",
linewidth = 0.25, boxstyle = "round"))
plt.xlabel("Meal", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.ylabel("Number Of Bookings", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.grid(axis = "y", alpha = 0.4)
df['meal'].value_counts()
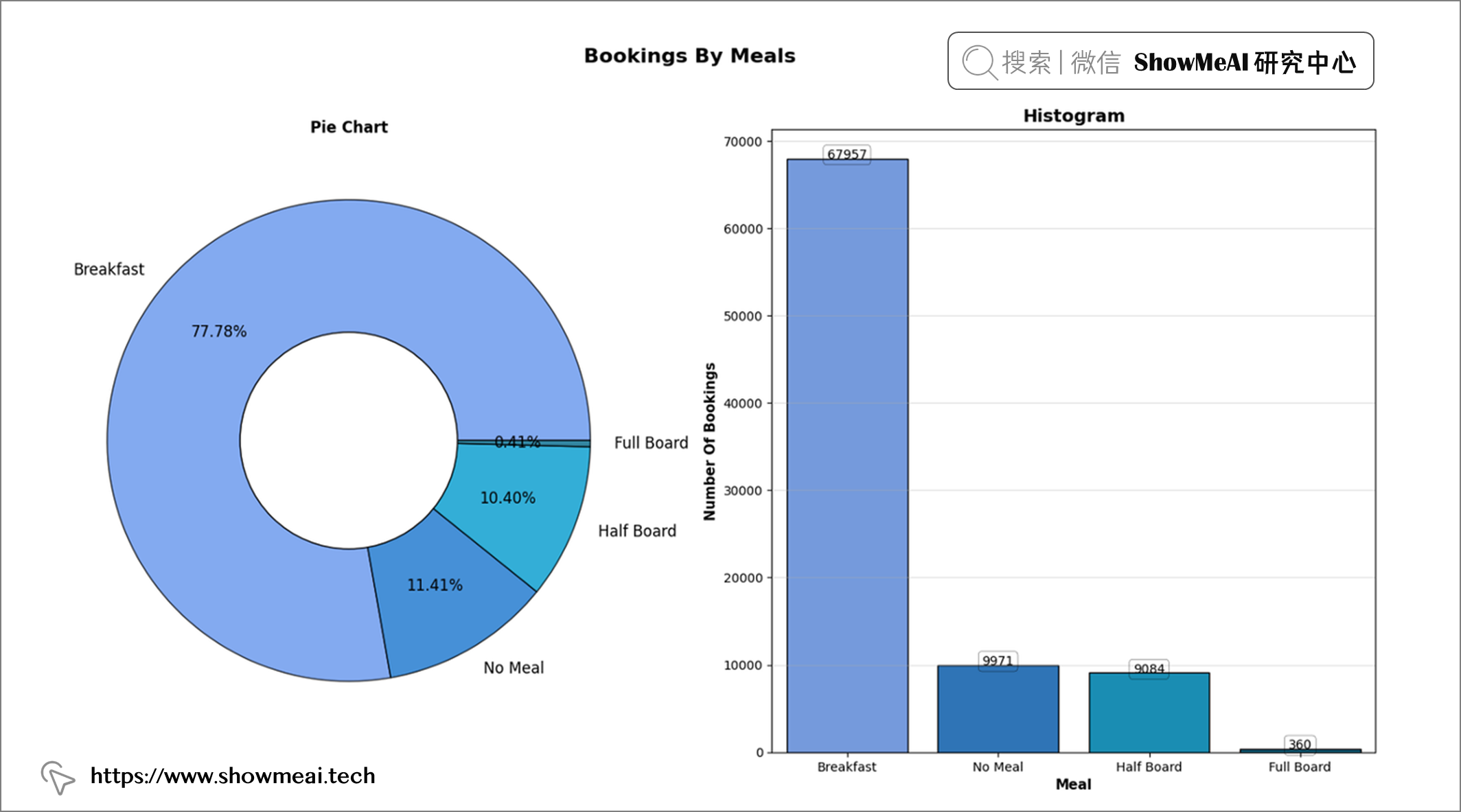
📢 结论:超过 70% 的客人预订早餐,近 90% 的客人预订餐点。
💦 顾客类型分析
labels = ["Transient", "Transient-Party", "Contract", "Group"]
order = df['customer_type'].value_counts().index
plt.figure(figsize = (19, 9))
plt.suptitle('Bookings By Customer Type', fontweight = 'heavy', fontsize = '16',
fontfamily = 'sans-serif', color = "black")
# Pie Chart
plt.subplot(1, 2, 1)
plt.title('Pie Chart', fontweight = 'bold', fontfamily = "sans-serif", color = 'black')
plt.pie(df["customer_type"].value_counts(), pctdistance = 0.7, autopct = '%.2f%%', labels = labels,
wedgeprops = dict(alpha = 0.8, edgecolor = "black"), textprops = {'fontsize': 12})
centre = plt.Circle((0,0), 0.45, fc = "white", edgecolor = "black")
plt.gcf().gca().add_artist(centre)
# Histogram
countplt = plt.subplot(1, 2, 2)
plt.title("Histogram", fontweight = "bold", fontsize = 14,
fontfamily = "sans-serif", color = 'black')
ax = sns.countplot(x = "customer_type", data = df, order = order, edgecolor = "black")
for rect in ax.patches:
ax.text(rect.get_x() + rect.get_width()/2, rect.get_height() + 4.25, rect.get_height(),
horizontalalignment="center", fontsize = 10, bbox = dict(facecolor = "none", edgecolor = "black",
linewidth = 0.25, boxstyle = "round"))
plt.xlabel("Customer Type", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.ylabel("Number Of Bookings", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.grid(axis = "y", alpha = 0.4)
df['customer_type'].value_counts()
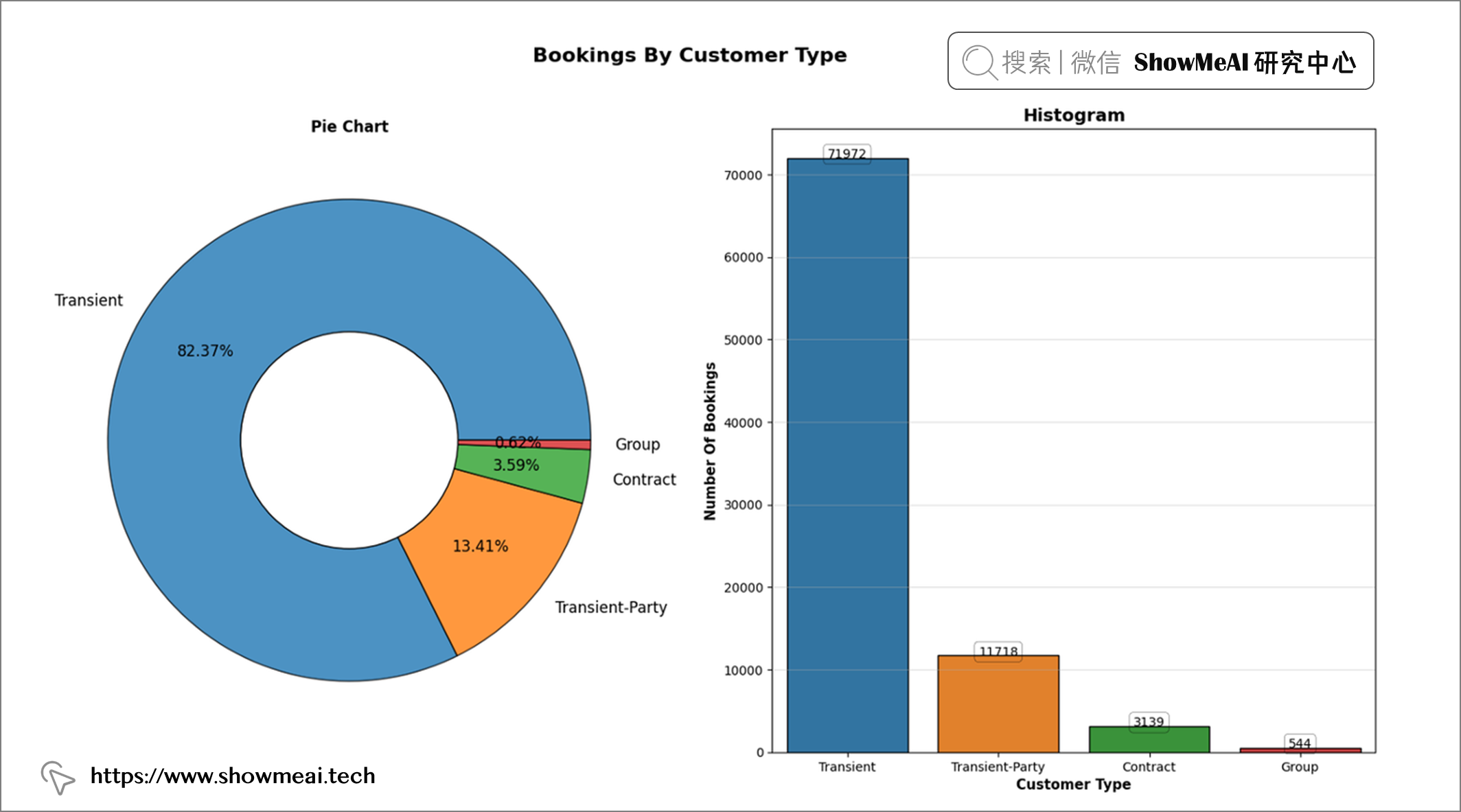
📢 结论:大多数人没有选择跟团旅游。
💦 押金情况分析
plt.figure(figsize = (19, 12))
order = sorted(df["deposit_type"].unique())
plt.title("Bookings By Deposit Types", fontweight = "bold", fontsize = 14,
fontfamily = "sans-serif", color = 'black')
ax = sns.countplot(x = "deposit_type", data = df, hue = "hotel", edgecolor = "black", palette = "bone", order = order)
plt.xlabel("Deposit Type", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.ylabel("Number Of Bookings", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.grid(axis = "y", alpha = 0.4)
df["deposit_type"].value_counts()
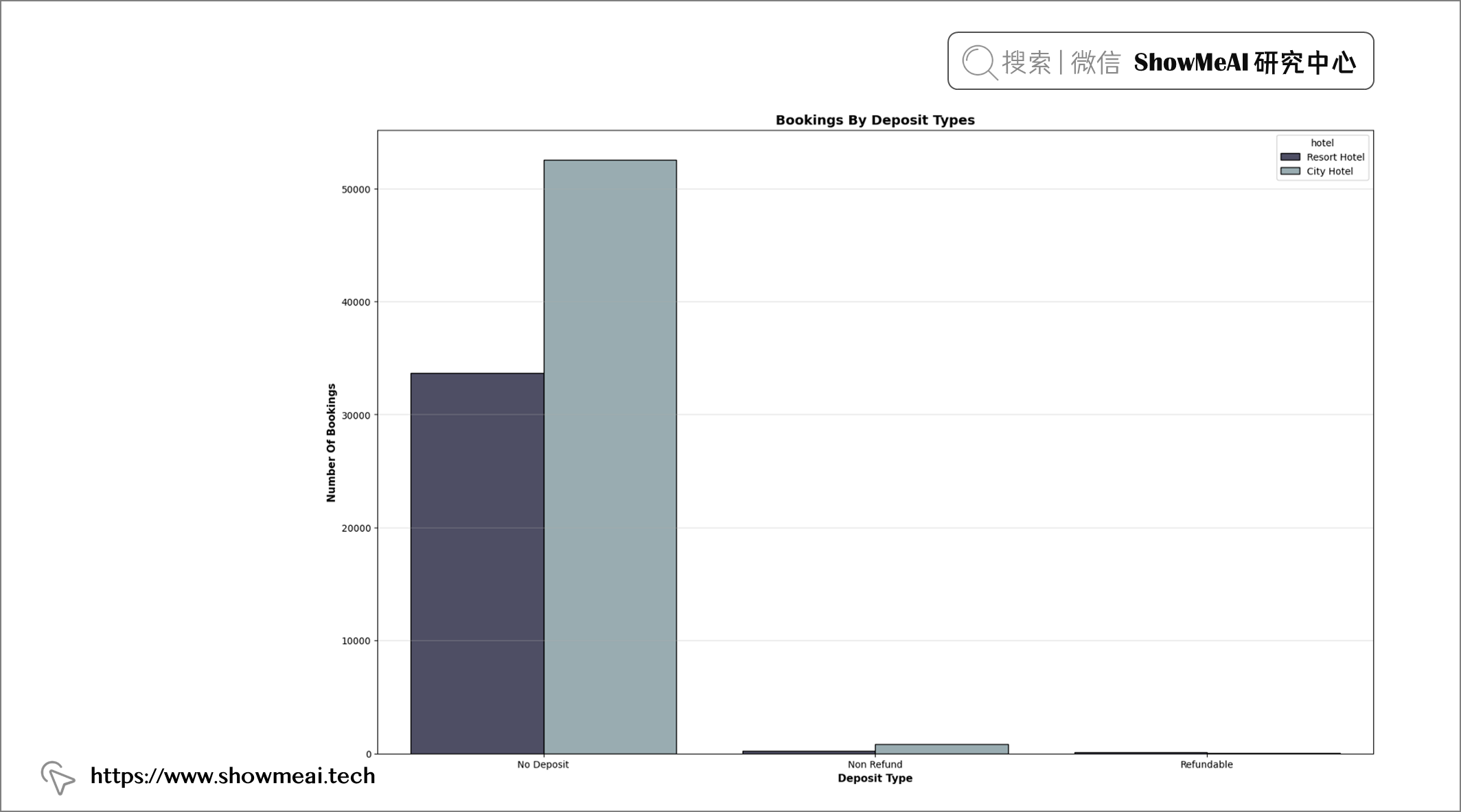
📢 结论:大部分客人没有交押金。
💦 客人类型分析
labels = ['New Guest', 'Repeated Guest']
colors = ["#00008B", "#C1CDCD"]
order = df['is_repeated_guest'].value_counts().index
plt.figure(figsize = (19, 9))
plt.suptitle('Bookings By Type Of Guest', fontweight = 'heavy', fontsize = '16',
fontfamily = 'sans-serif', color = "black")
# Pie Chart
plt.subplot(1, 2, 1)
plt.title('Pie Chart', fontweight = 'bold', fontfamily = "sans-serif", color = 'black')
plt.pie(df["is_repeated_guest"].value_counts(), pctdistance = 0.7, autopct = '%.2f%%', labels = labels,
wedgeprops = dict(alpha = 0.8, edgecolor = "black"), textprops = {'fontsize': 12}, colors = colors)
centre = plt.Circle((0,0), 0.45, fc = "white", edgecolor = "black")
plt.gcf().gca().add_artist(centre)
# Histogram
countplt = plt.subplot(1, 2, 2)
plt.title("Histogram", fontweight = "bold", fontsize = 14, fontfamily = "sans-serif", color = 'black')
ax = sns.countplot(x = "is_repeated_guest", data = df, order = order, edgecolor = "black", palette = colors)
for rect in ax.patches:
ax.text(rect.get_x() + rect.get_width()/2, rect.get_height() + 4.25, rect.get_height(),
horizontalalignment="center", fontsize = 10, bbox = dict(facecolor = "none", edgecolor = "black",
linewidth = 0.25, boxstyle = "round"))
plt.xlabel("Type Of Guest", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.ylabel("Total", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.xticks([0, 1], labels)
plt.grid(axis = "y", alpha = 0.4)
df['is_repeated_guest'].value_counts()
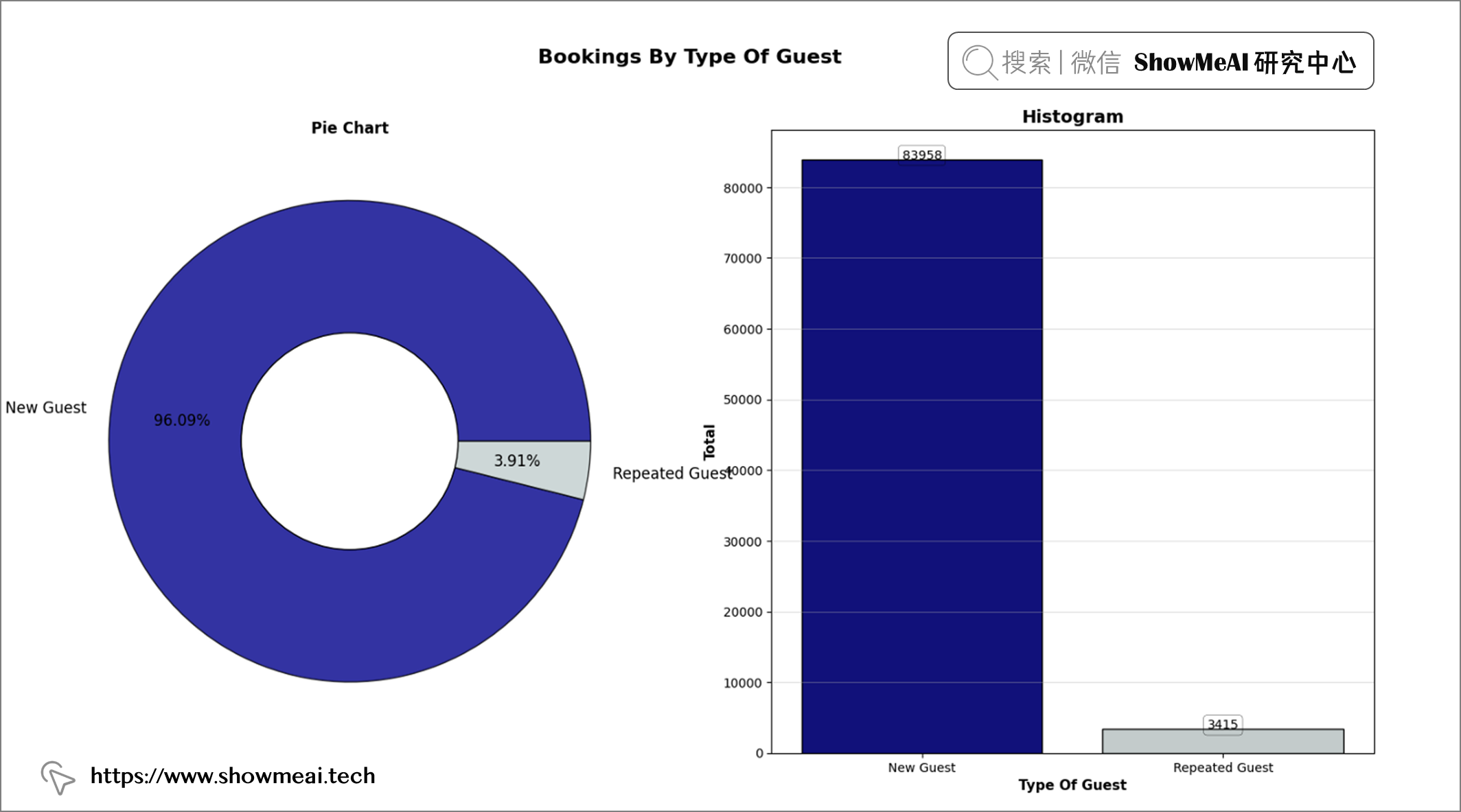
📢 结论:几乎所有的客人都是新客人。
💦 预订房间类型分析
plt.figure(figsize = (19, 12))
order = sorted(df["reserved_room_type"].unique())
plt.title("Bookings By Reserved Room Types", fontweight = "bold", fontsize = 14,
fontfamily = "sans-serif", color = 'black')
ax = sns.countplot(x = "reserved_room_type", data = df, hue = "hotel", edgecolor = "black", palette = "bone", order = order)
plt.xlabel("Reserved Room Type", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.ylabel("Number Of Bookings", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.grid(axis = "y", alpha = 0.4)
df["reserved_room_type"].value_counts()
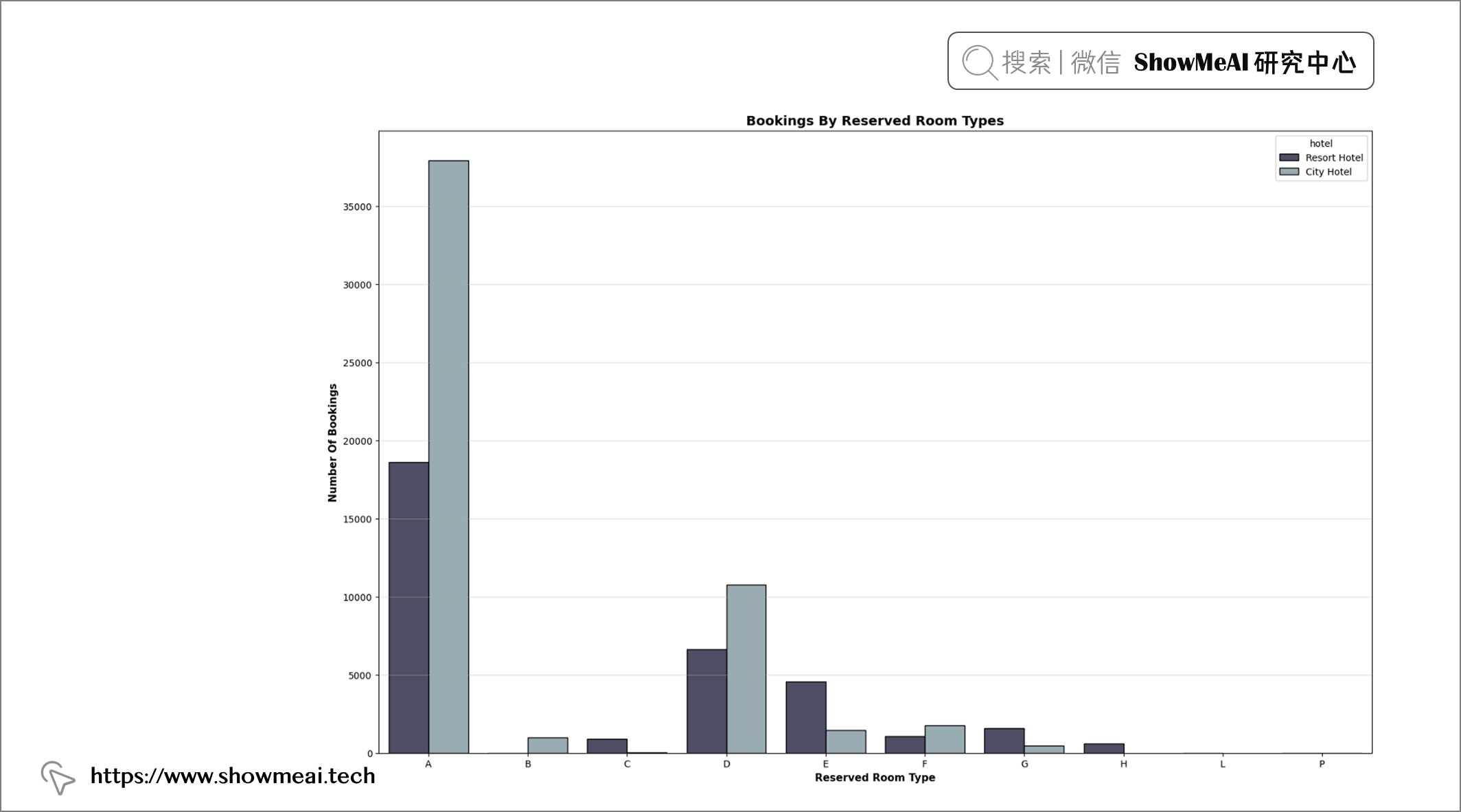
📢 结论:大多数客人预订了房间A,少数预订了房间D和E,其余的需求很少。
💦 分配的房间类型分析
plt.figure(figsize = (19, 12))
order = sorted(df["assigned_room_type"].unique())
plt.title("Bookings By Assigned Room Types", fontweight = "bold", fontsize = 14,
fontfamily = "sans-serif", color = 'black')
ax = sns.countplot(x = "assigned_room_type", data = df, hue = "hotel", edgecolor = "black", palette = "bone", order = order)
plt.xlabel("Assigned Room Type", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.ylabel("Number Of Bookings", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.grid(axis = "y", alpha = 0.4)
df["assigned_room_type"].value_counts()
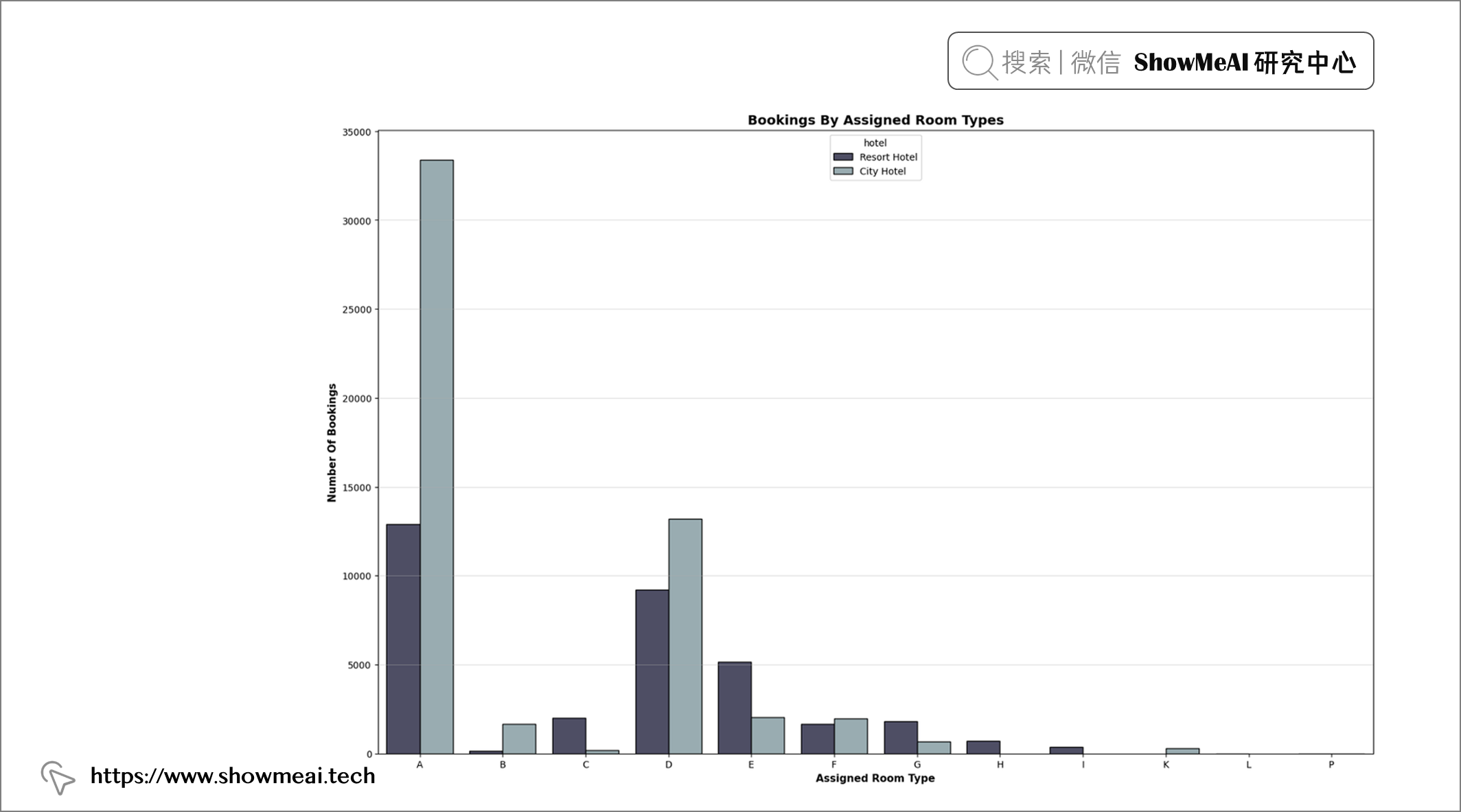
📢 结论:大多数客人被分配到 A 室,少数被分配到 D 和 E 室,其余的很少。
💦 预订状态分析
plt.figure(figsize = (19, 12))
order = sorted(df["reservation_status"].unique())
plt.title("Bookings By Reservation Status", fontweight = "bold", fontsize = 14,
fontfamily = "sans-serif", color = 'black')
ax = sns.countplot(x = "reservation_status", data = df, hue = "hotel", edgecolor = "black", palette = "ocean", order = order)
plt.xlabel("Reservation Status", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.ylabel("Number Of Bookings", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.grid(axis = "y", alpha = 0.4)
df["reservation_status"].value_counts()
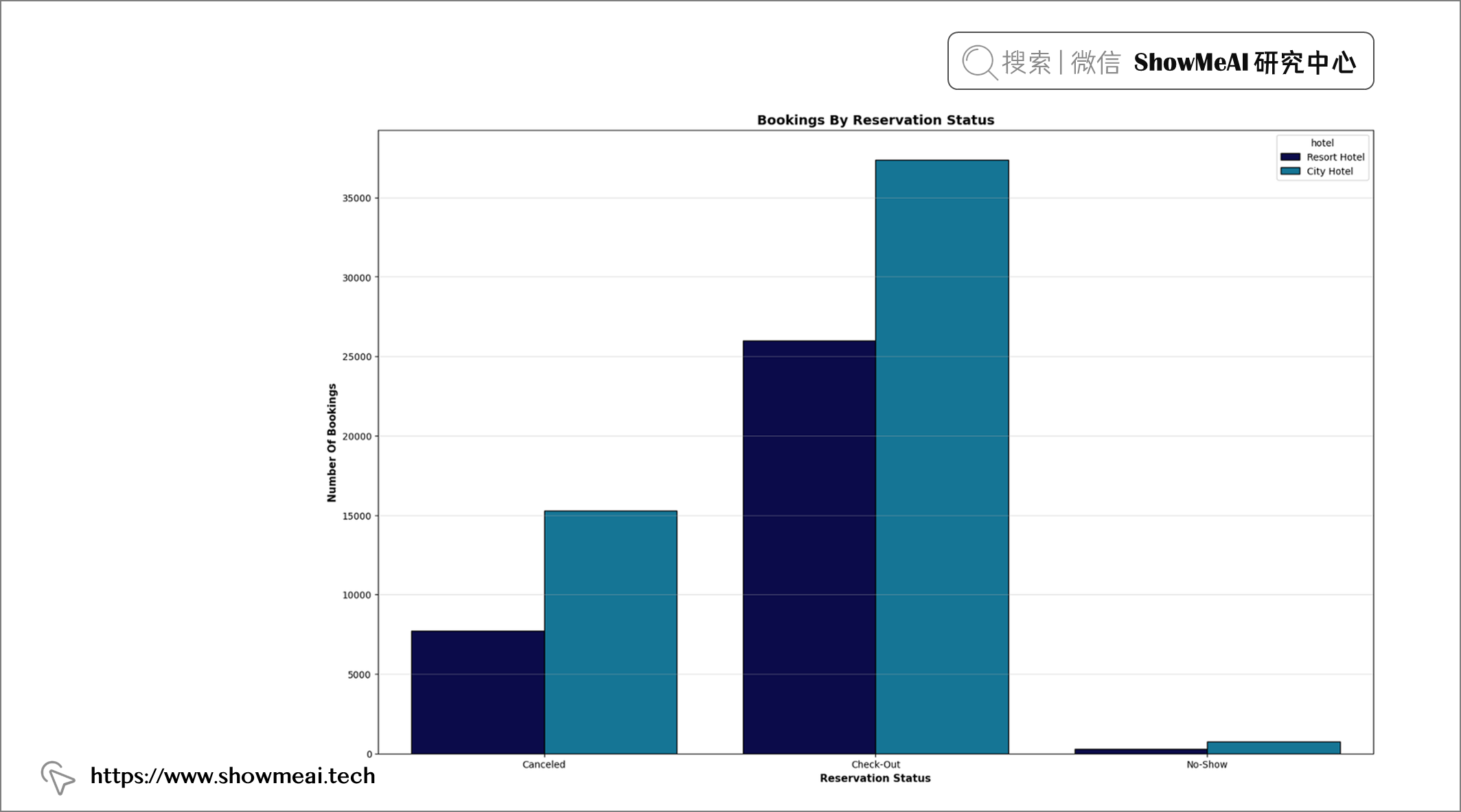
📢 结论:大多数客人登记入住并已经离开。
💦 总住宿夜数分布
plt.figure(figsize = (19, 9))
df2 = df.groupby("total_nights")["total_nights"].count()
df2.sort_values(ascending = False)[: 10].plot(kind = 'bar')
plt.title("Bookings By Total Nights Stayed By Guests", fontweight = "bold", fontsize = 14, fontfamily = "sans-serif",
color = 'black')
plt.xticks(rotation = 30)
plt.xlabel("Number Of Nights", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.ylabel("Number Of Bookings", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.grid(axis = "y", alpha = 0.4)
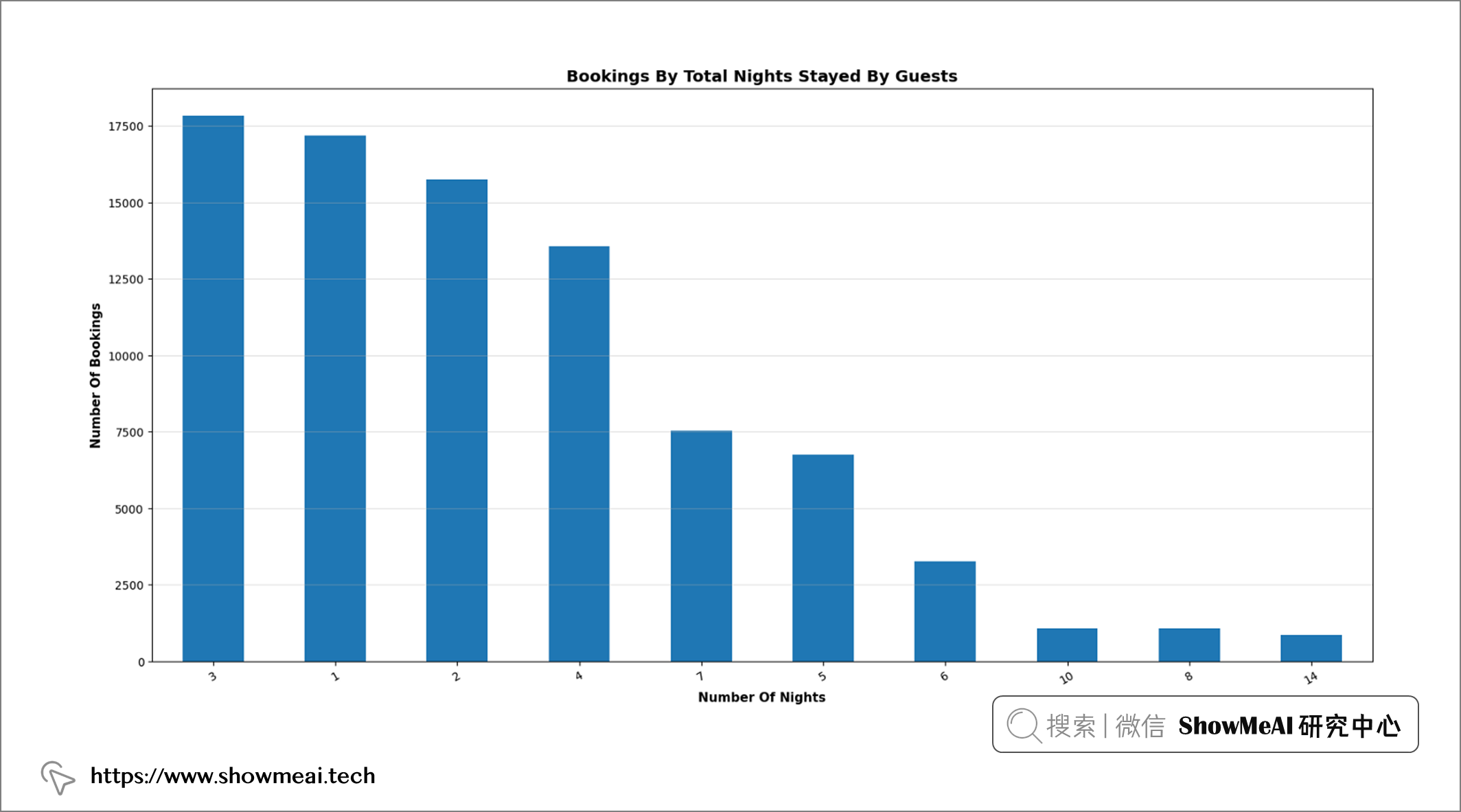
📢 结论:最受欢迎的酒店住宿时间是三晚。
💦 酒店&总住宿夜数
plt.figure(figsize = (19, 12))
order = df.total_nights.value_counts().iloc[:10].index
plt.title("Total Nights Stayed By Guests In Hotel", fontweight = "bold", fontsize = 14,
fontfamily = "sans-serif", color = 'black')
ax = sns.countplot(x = "total_nights", data = df, hue = "hotel", edgecolor = "black", palette = "ocean", order = order)
plt.xlabel("Total Nights", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.ylabel("Number Of Bookings", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.grid(axis = "y", alpha = 0.4)
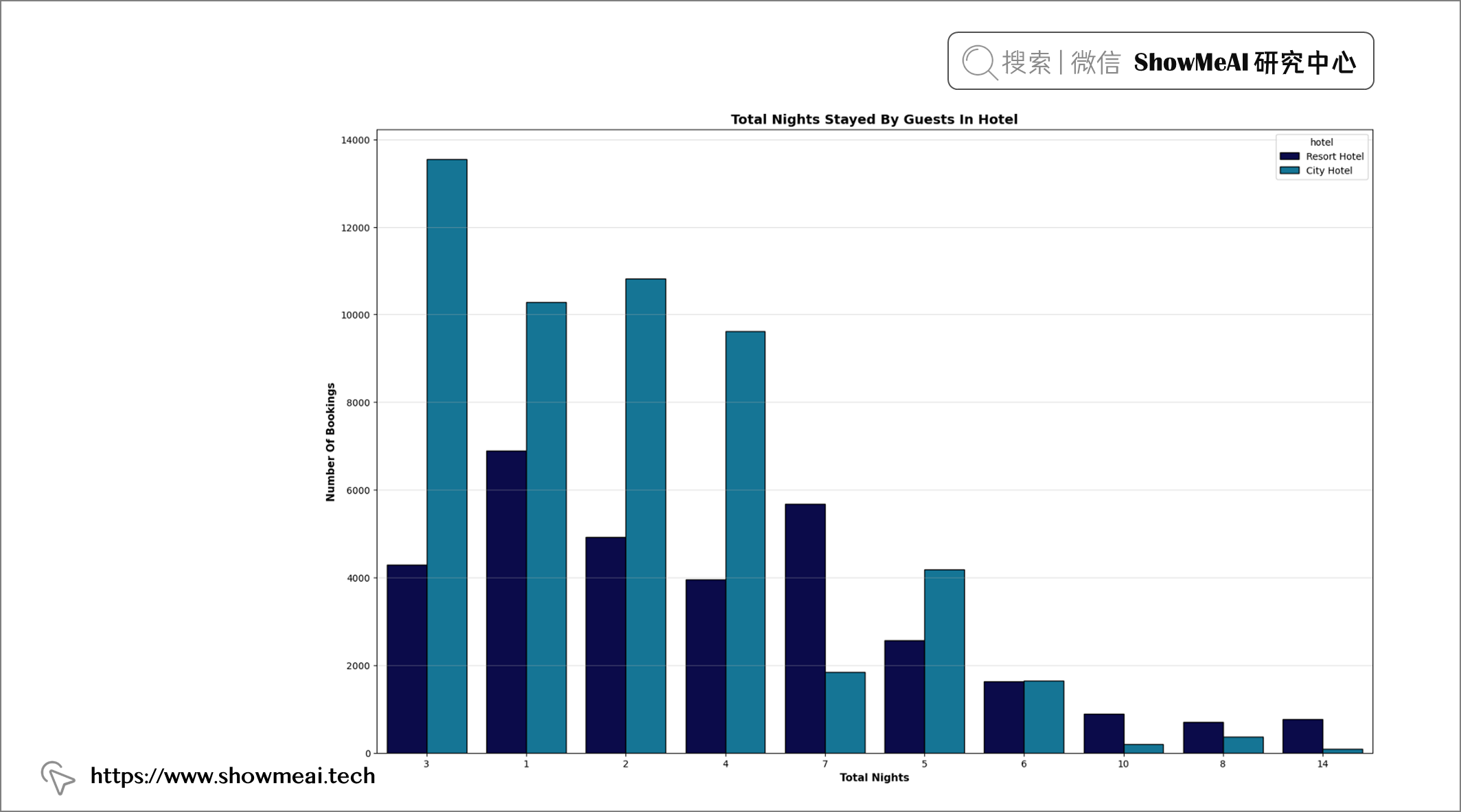
📢 结论:度假酒店最受欢迎的住宿时间是一晚、七晚、两晚、三晚和四晚。城市酒店最受欢迎的住宿时间是三晚、两晚、一晚和四晚。
💦 热门国家分布
plt.figure(figsize = (19, 9))
df2 = df.groupby("country")["country"].count()
df2.sort_values(ascending = False)[: 20].plot(kind = 'bar')
plt.title("Bookings By Top 20 Countries", fontweight = "bold", fontsize = 14, fontfamily = "sans-serif", color = 'black')
plt.xticks(rotation = 30)
plt.xlabel("Country", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.ylabel("Number Of Bookings", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.grid(axis = "y", alpha = 0.4)
df["country"].value_counts()
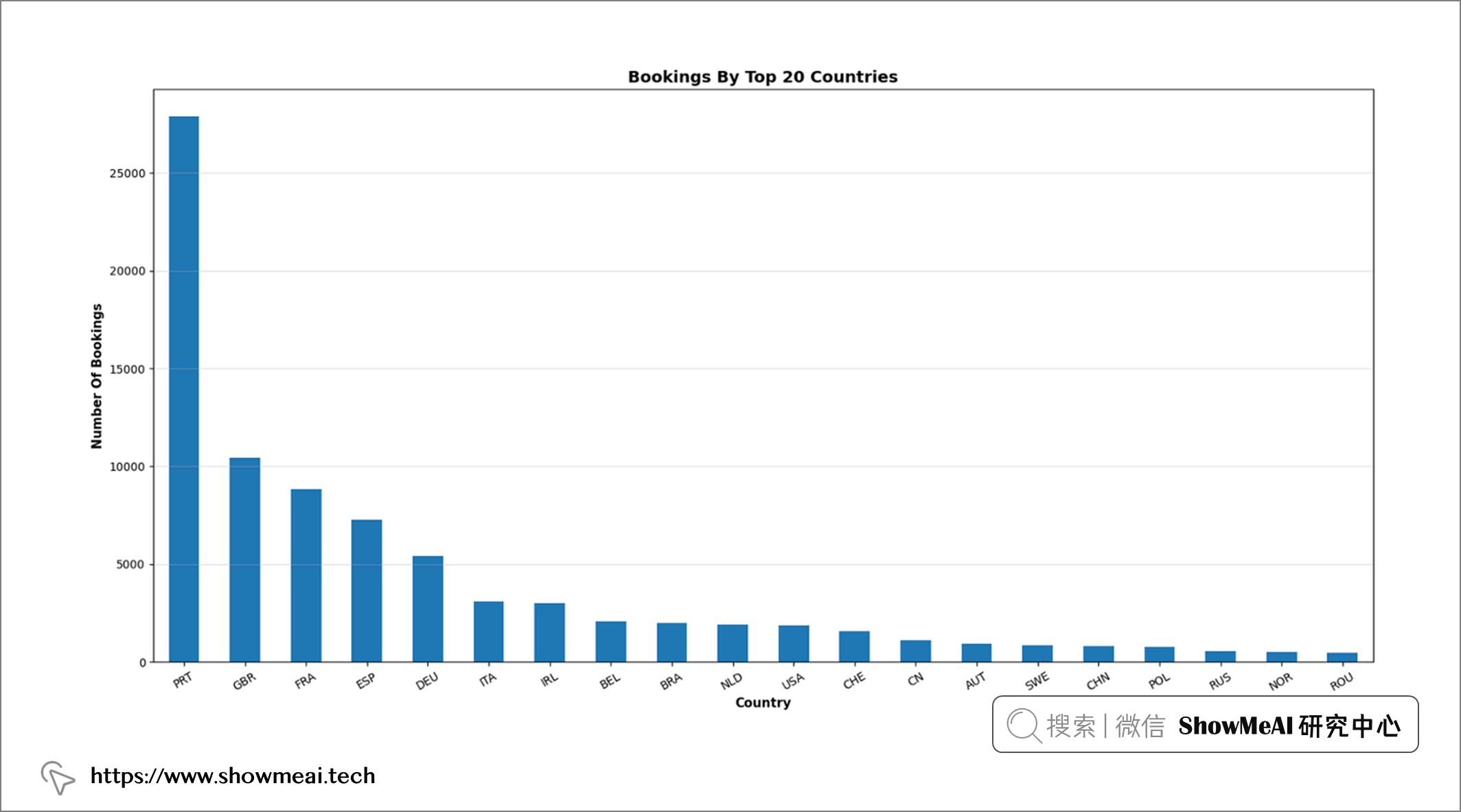
📢 结论:在这份数据中,葡萄牙的预订量比其他任何国家都多。
💦 预定下单时间
plt.figure(figsize = (16, 6))
plt.title("Bookings By Lead Time", fontweight = "bold", fontsize = 14, fontfamily = 'sans-serif', color = 'black')
sns.histplot(data = df, x = 'lead_time', hue = "hotel", kde = True, color = "#104E8B")
plt.xlabel('Lead Time', fontweight = 'normal', fontsize = 11, fontfamily = 'sans-serif', color = "black")
plt.ylabel('Number Of Bookings', fontweight = 'regular', fontsize = 11, fontfamily = "sans-serif", color = "black")
df["lead_time"].describe().T
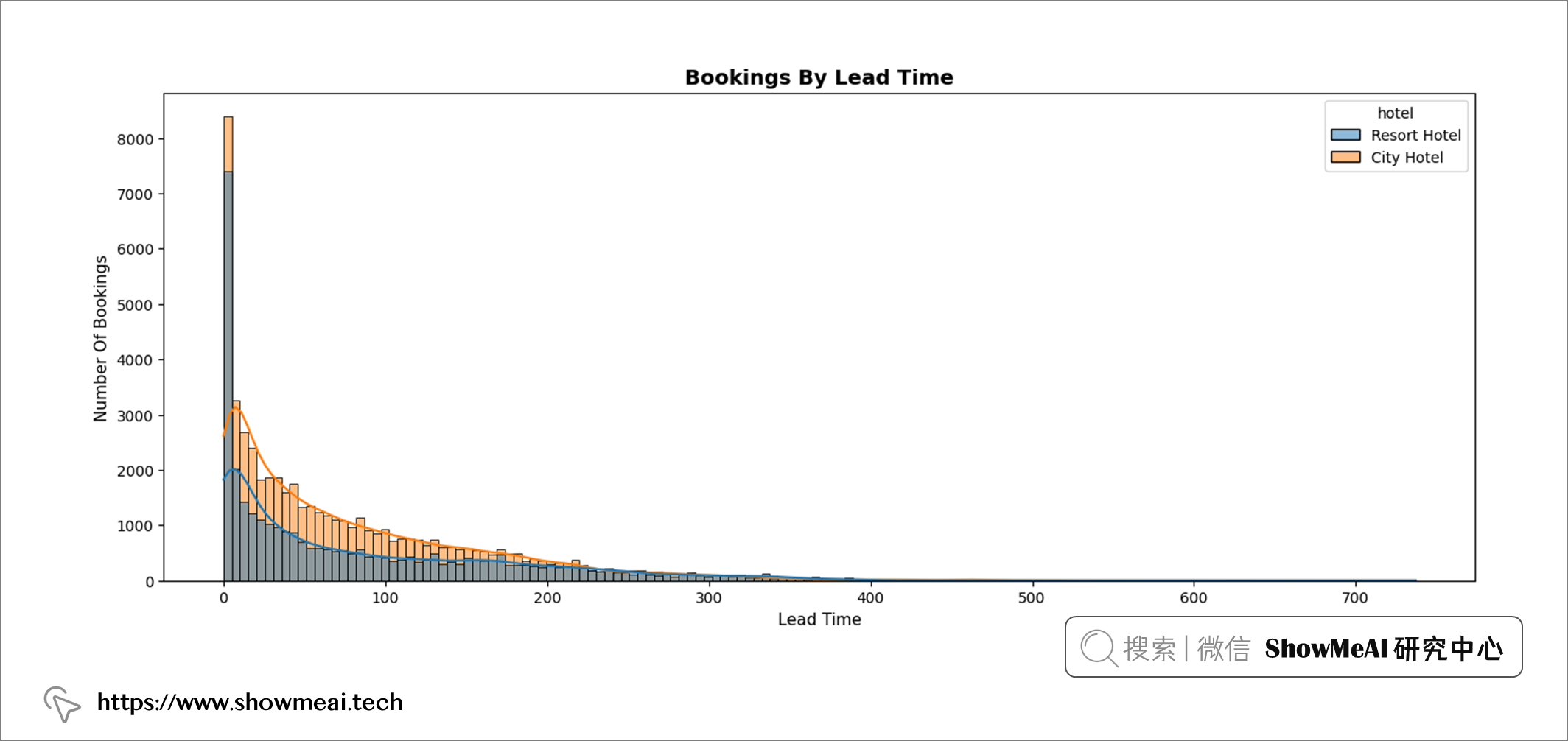
📢 结论:大多数预订是在入住酒店前 100 天内完成的。
💡 关联分析
💦 预订取消&酒店类型
plt.figure(figsize = (19, 12))
plt.title("Number Of Bookings Cancelled By Guests", fontweight = "bold", fontsize = 14,
fontfamily = "sans-serif", color = 'black')
ax = sns.countplot(x = "hotel", data = df, hue = "is_canceled", edgecolor = "black", palette = "bone")
for rect in ax.patches:
ax.text(rect.get_x() + rect.get_width()/2, rect.get_height() + 4.25, rect.get_height(),
horizontalalignment="center", fontsize = 10, bbox = dict(facecolor = "none", edgecolor = "black",
linewidth = 0.25, boxstyle = "round"))
plt.xlabel("Hotel", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.ylabel("Number Of Bookings", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.grid(axis = "y", alpha = 0.4)
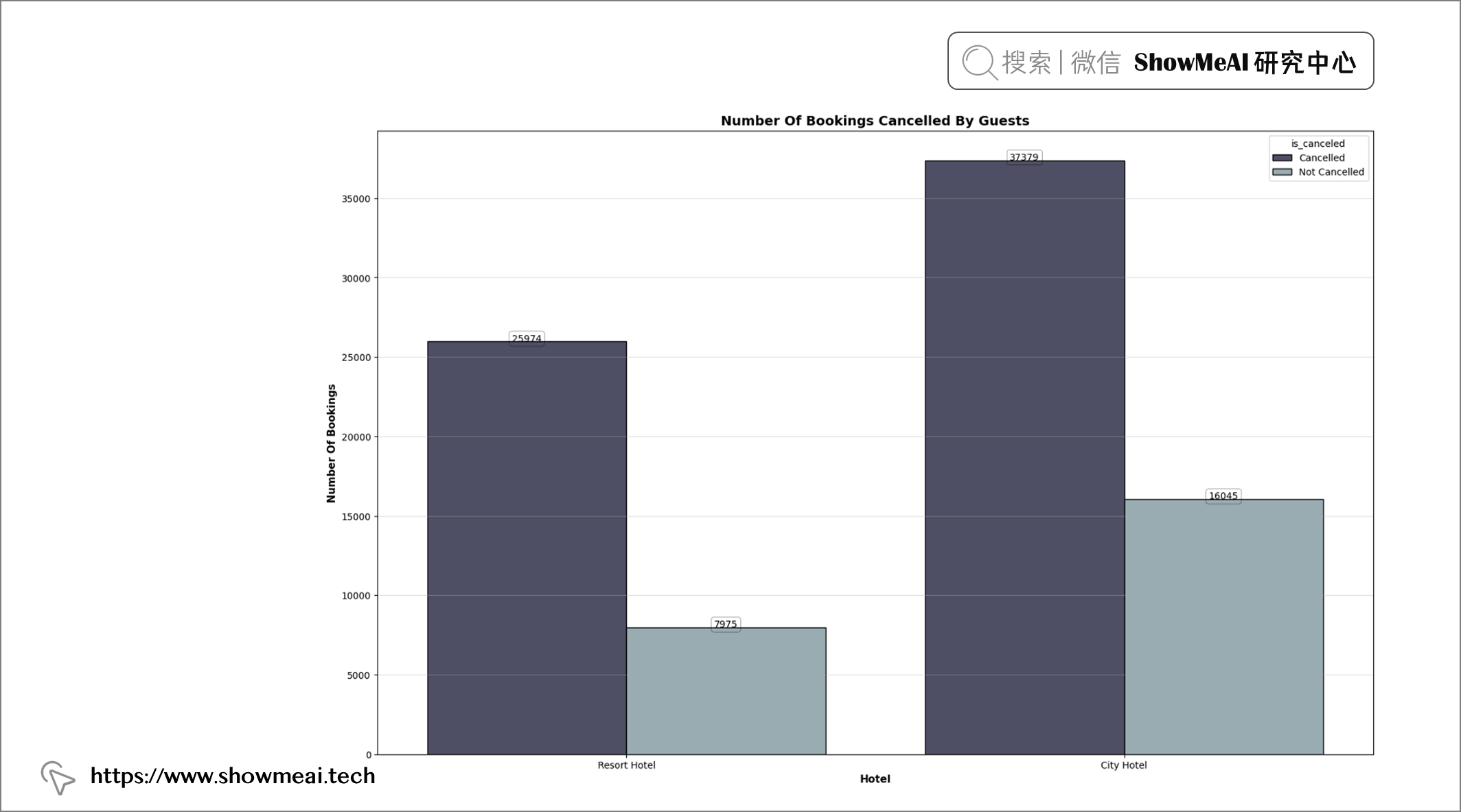
📢 结论:度假村酒店的客人取消预订的频率低于城市酒店的客人。
💦 预约取消&新老客
plt.figure(figsize = (19, 12))
plt.title("Number Of Bookings Cancelled By Type Of Guests", fontweight = "bold", fontsize = 14,
fontfamily = "sans-serif", color = 'black')
ax = sns.countplot(x = "is_canceled", data = df, hue = "is_repeated_guest", edgecolor = "black", palette = "bone")
for rect in ax.patches:
ax.text(rect.get_x() + rect.get_width()/2, rect.get_height() + 4.25, rect.get_height(),
horizontalalignment="center", fontsize = 10, bbox = dict(facecolor = "none", edgecolor = "black",
linewidth = 0.25, boxstyle = "round"))
plt.xlabel("Cancellation", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.ylabel("Number Of Bookings", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.legend(['New Guest', 'Repeated Guest'])
plt.grid(axis = "y", alpha = 0.4)
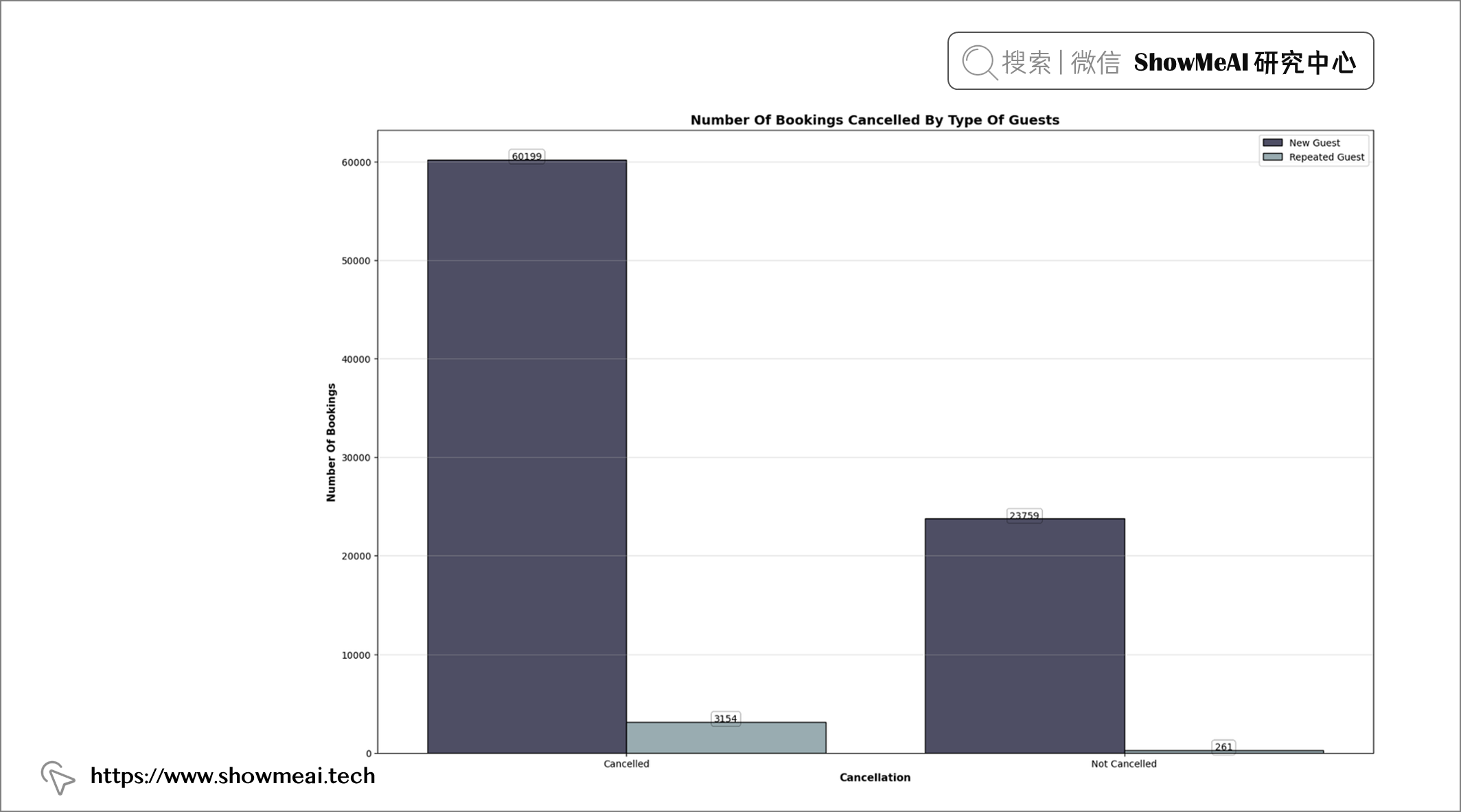
📢 结论:老客取消预订的次数少于新客。
💦 预约取消&细分市场
plt.figure(figsize = (19, 12))
plt.title("Number Of Bookings Cancelled By Market Segments", fontweight = "bold", fontsize = 14,
fontfamily = "sans-serif", color = 'black')
ax = sns.countplot(x = "market_segment", data = df, hue = "is_canceled", edgecolor = "black", palette = "bone")
for rect in ax.patches:
ax.text(rect.get_x() + rect.get_width()/2, rect.get_height() + 4.25, rect.get_height(),
horizontalalignment="center", fontsize = 10, bbox = dict(facecolor = "none", edgecolor = "black",
linewidth = 0.25, boxstyle = "round"))
plt.xlabel("Market Segment", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.ylabel("Number Of Bookings", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.grid(axis = "y", alpha = 0.4)
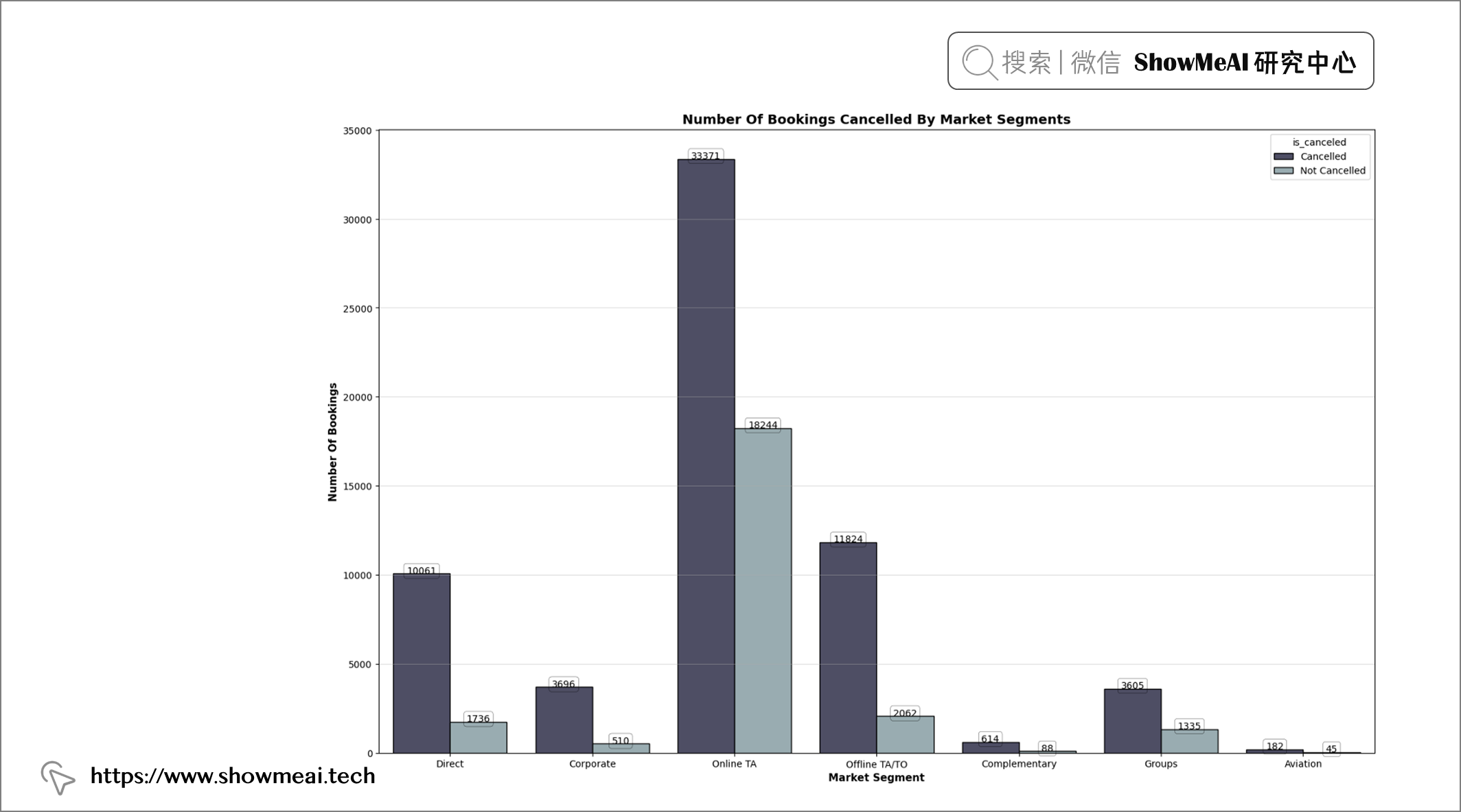
📢 结论:在线旅行社、线下旅行社/运营商和直销部分的取消率高于其他部分。
💦 预订数量&年份
plt.figure(figsize = (19, 12))
plt.title("Number Of Bookings Per Year", fontweight = "bold", fontsize = 14,
fontfamily = "sans-serif", color = 'black')
ax = sns.countplot(x = "arrival_date_year", data = df, hue = "hotel", edgecolor = "black", palette = "cool")
for rect in ax.patches:
ax.text(rect.get_x() + rect.get_width()/2, rect.get_height() + 4.25, rect.get_height(),
horizontalalignment="center", fontsize = 10, bbox = dict(facecolor = "none", edgecolor = "black",
linewidth = 0.25, boxstyle = "round"))
plt.xlabel("Year", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.ylabel("Number Of Bookings", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.grid(axis = "y", alpha = 0.4)
df["arrival_date_year"].value_counts()
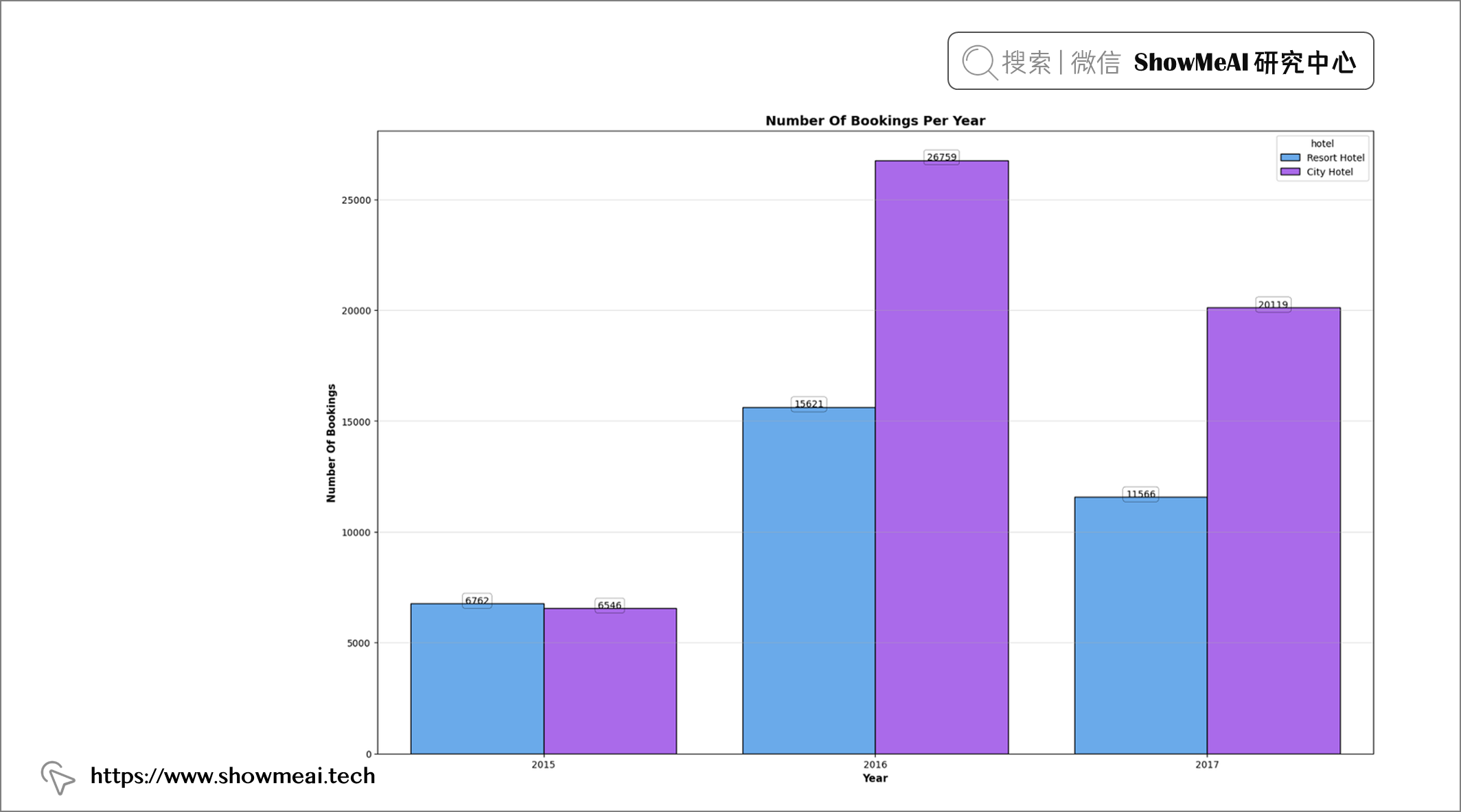
📢 结论:度假村和城市酒店在 2016 年的预订量均最高。与度假村酒店相比,城市酒店在 2017 年的预订量更高。两者在 2015 年的预订量几乎相同。
💦 预订数量&月份
plt.figure(figsize = (16, 10))
plt.title("Number Of Bookings Per Customer Type", fontweight = "bold", fontsize = 14,
fontfamily = "sans-serif", color = 'black')
ax = sns.countplot(x = "customer_type", data = df, hue = "hotel", edgecolor = "black", palette = "pink")
for rect in ax.patches:
ax.text(rect.get_x() + rect.get_width()/2, rect.get_height() + 4.25, rect.get_height(),
horizontalalignment="center", fontsize = 10, bbox = dict(facecolor = "none", edgecolor = "black",
linewidth = 0.25, boxstyle = "round"))
plt.xlabel("Customer Type", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.ylabel("Number Of Bookings", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.grid(axis = "y", alpha = 0.4)
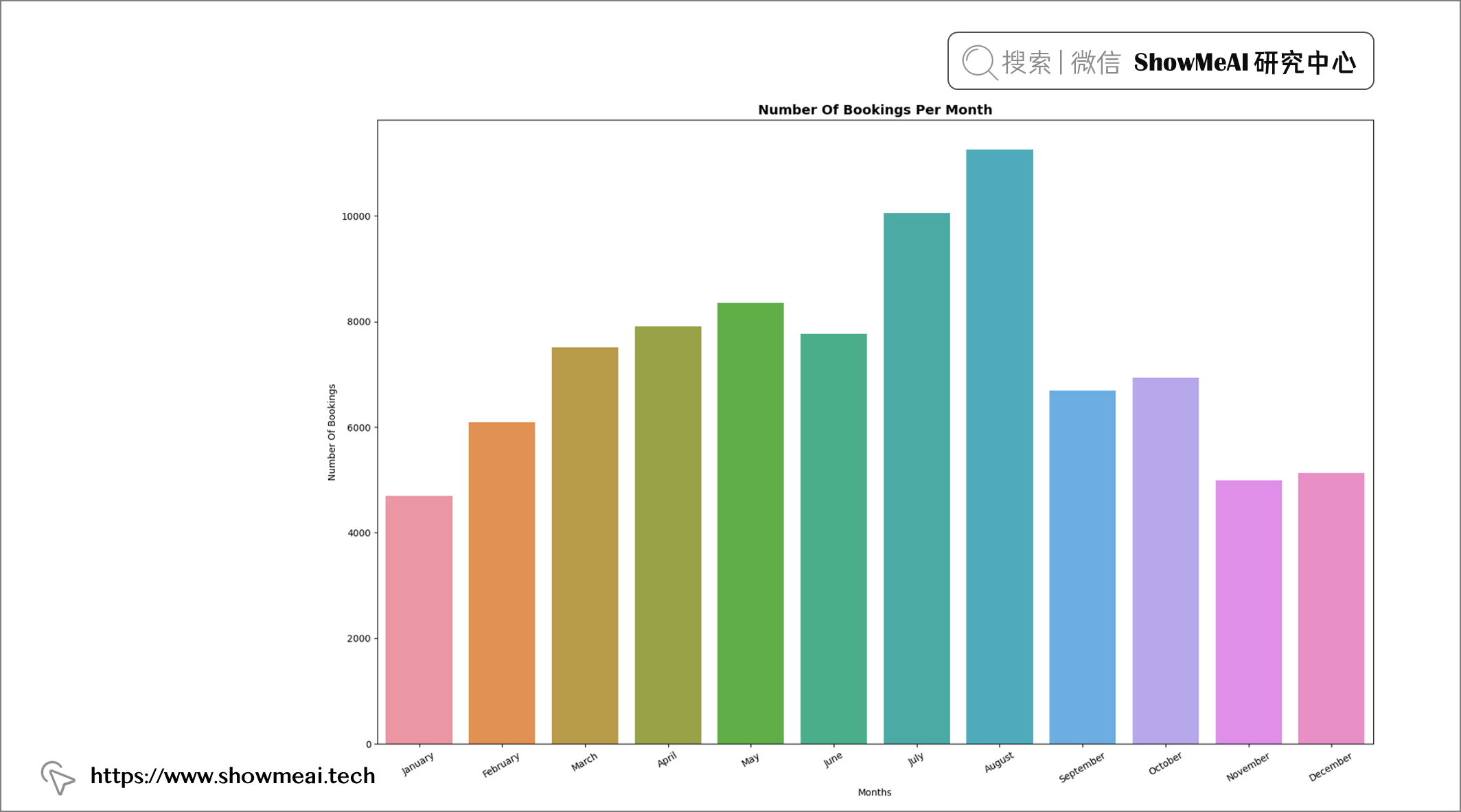
📢 结论:十一月、十二月、一月和二月是预定最少的月份,7 月和 8 月是预订高峰月份。
💦 预订数量&客户类型
months = ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October",
"November", "December"]
plt.figure(figsize = (19, 12))
plt.title("Number Of Bookings Per Month", fontweight = "bold", fontsize = 14,
fontfamily = "sans-serif", color = 'black')
d = df.groupby("arrival_date_month")["arrival_date_month"].count()
sns.barplot(x = d.index, y = d, order = months)
plt.xticks(rotation = 30)
plt.xlabel("Months")
plt.ylabel("Number Of Bookings")
df["arrival_date_month"].value_counts()
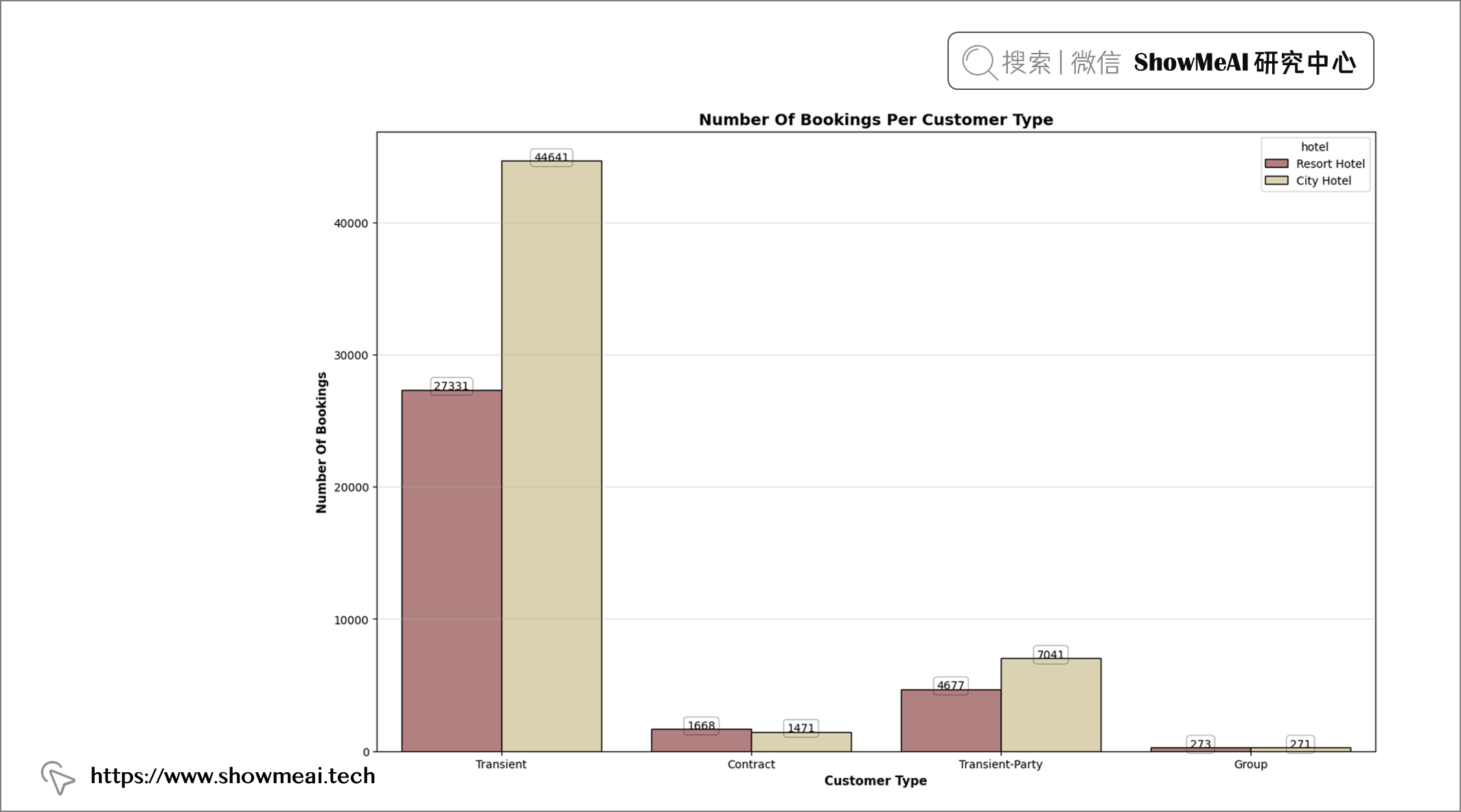
📢 结论:临时和临时派对客人大多预订城市酒店,而跟团客人在度假村和城市酒店的预订数量几乎相同。
💦 车位&预订
plt.figure(figsize = (19, 12))
plt.title("Number Of Bookings Per Required Car Parking Space", fontweight = "bold", fontsize = 14,
fontfamily = "sans-serif", color = 'black')
ax = sns.countplot(x = "required_car_parking_spaces", data = df, hue = "hotel", edgecolor = "black", palette = "cool")
plt.xlabel("Required Car Parking Space", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.ylabel("Number Of Bookings", fontweight = "bold", fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.grid(axis = "y", alpha = 0.4)
df["required_car_parking_spaces"].value_counts()
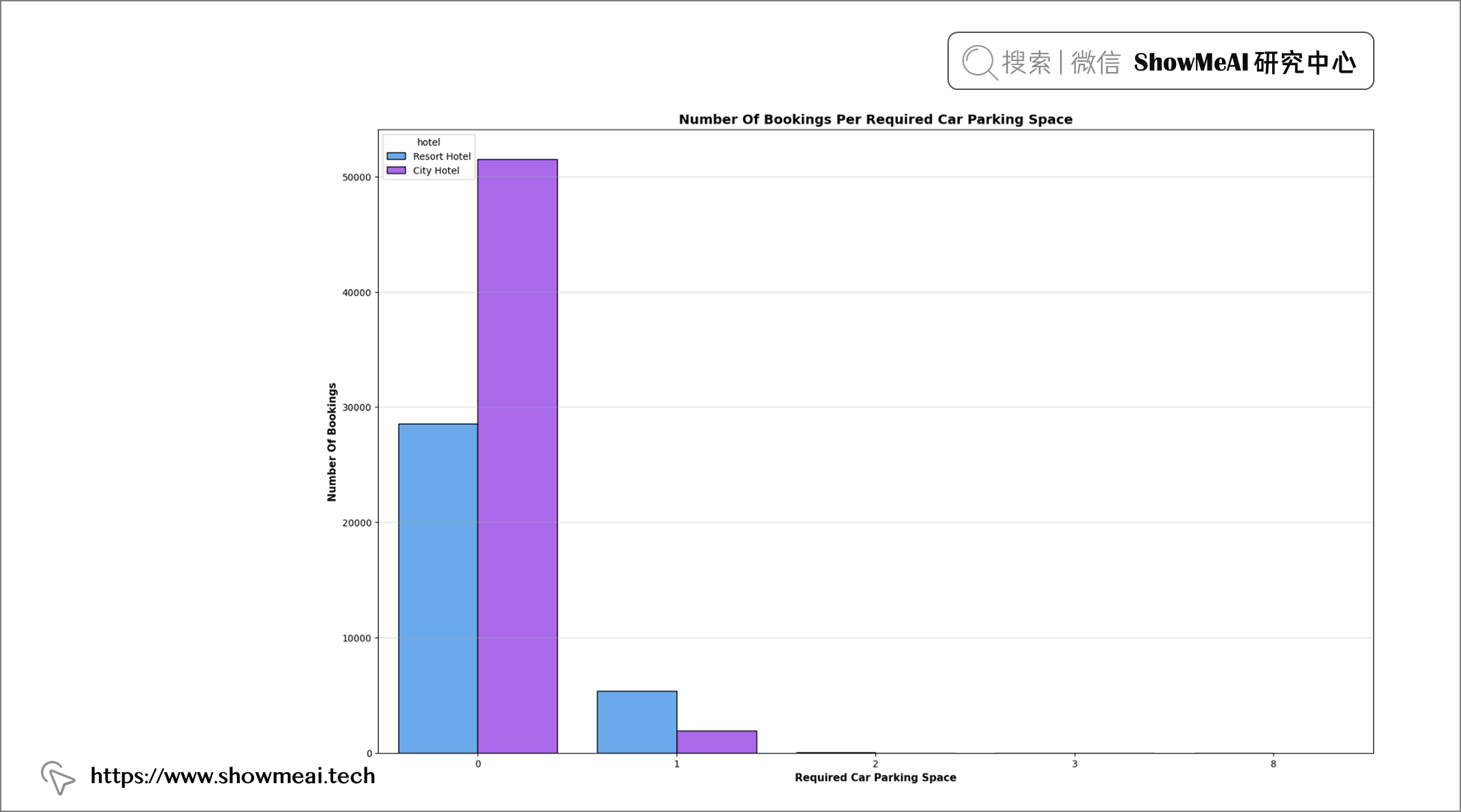
📢 结论:大多数客人不需要停车位,而少数客人需要停车位。
💦 国家/地区&特殊要求数量
df2 = df.groupby("country")["total_of_special_requests"].mean().sort_values(ascending = False)[: 20]
plt.figure(figsize = (18, 8))
sns.barplot(x = df2.index, y = df2)
plt.xticks(rotation = 30)
plt.xlabel("Country")
plt.ylabel("Average Number Of Special Requests")
plt.title("Average Number Of Special Requests Made By Top 20 Countries ", fontweight = "bold", fontsize = 14,fontfamily = "sans-serif", color = 'black')
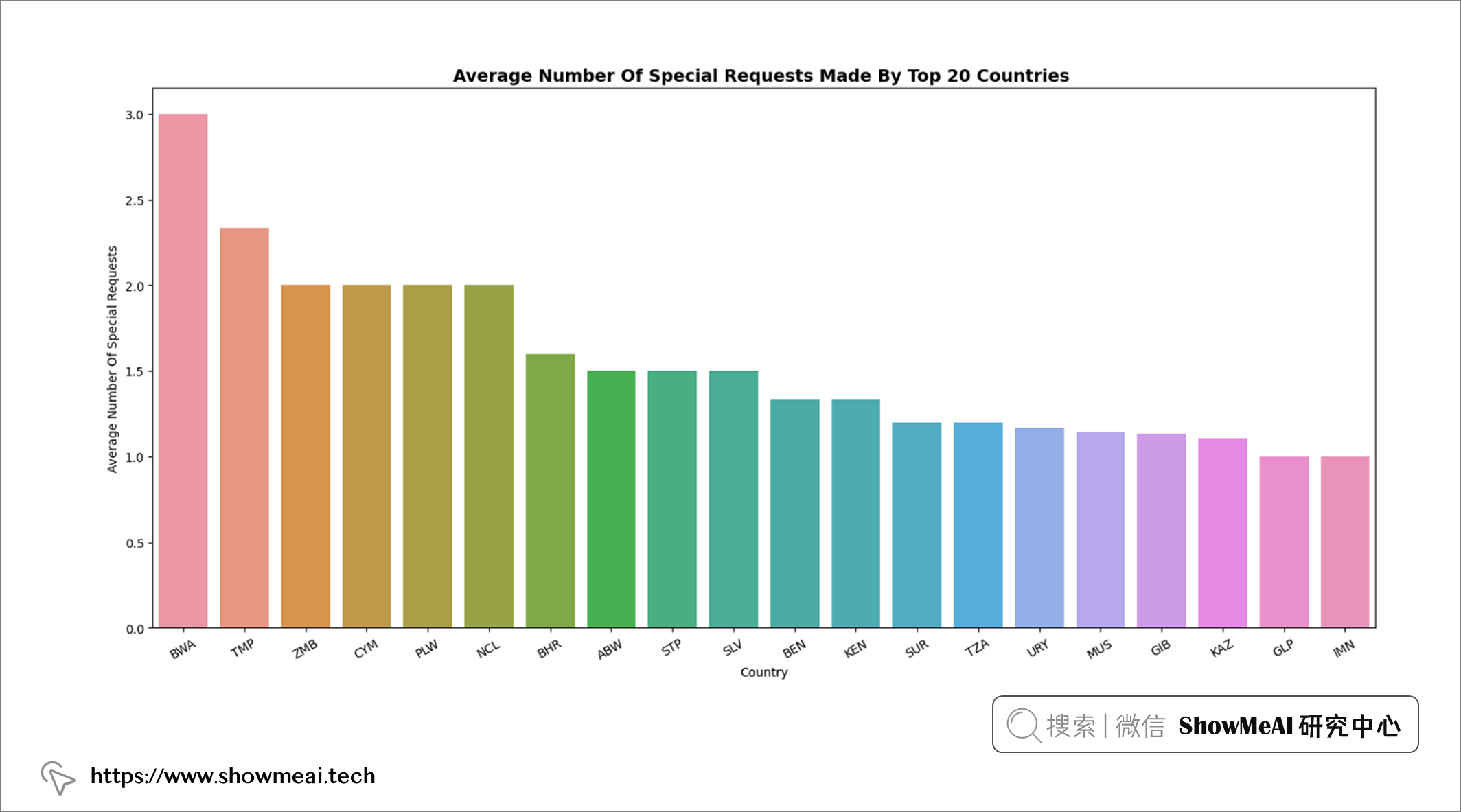
📢 结论:在这些国家中,博茨瓦纳的特殊要求数量最多。
💦 客户类型&特殊要求数量
df2 = df.groupby("customer_type")["total_of_special_requests"].mean().sort_values(ascending = False)[: 20]
plt.figure(figsize = (18, 8))
sns.barplot(x = df2.index, y = df2)
plt.xticks(rotation = 30)
plt.xlabel("Customer Type")
plt.ylabel("Average Number Of Special Requests")
plt.title("Average Number Of Special Requests By Customer Type", fontweight = "bold", fontsize = 14, fontfamily = "sans-serif", color = 'black')
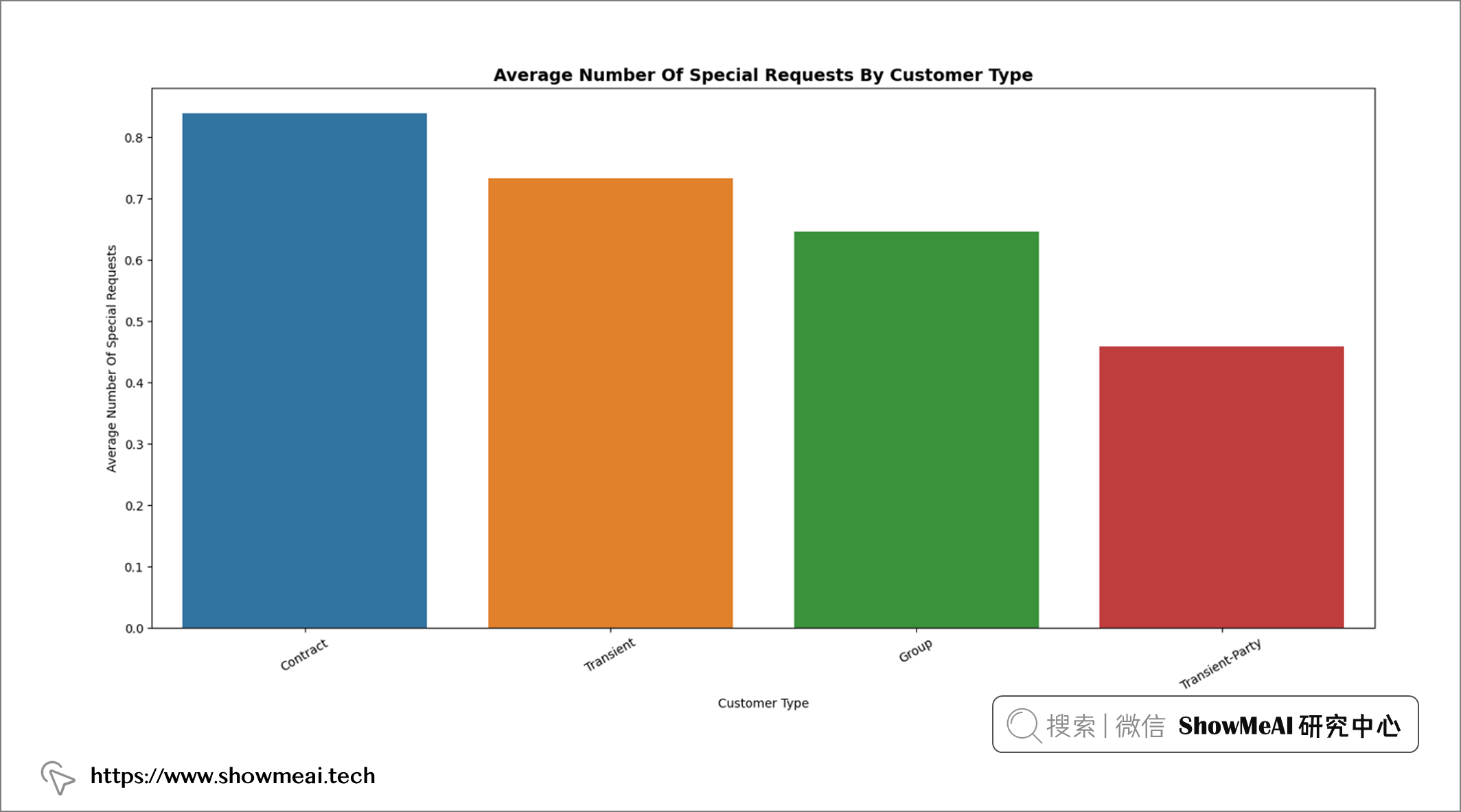
📢 结论:跟团客人的特殊要求数量最多,而临时派对客人的特殊要求数量最少。
💦 月份&特殊要求数量
months = ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October",
"November", "December"]
df2 = df.groupby("arrival_date_month")["total_of_special_requests"].mean().sort_values(ascending = False)[: 20]
plt.figure(figsize = (18, 8))
sns.barplot(x = df2.index, y = df2, order = months)
plt.xticks(rotation = 30)
plt.xlabel("Months")
plt.ylabel("Average Number Of Special Requests")
plt.title("Average Number Of Special Requests By Guests Per Months ", fontweight = "bold", fontsize = 14, fontfamily = "sans-serif", color = 'black')
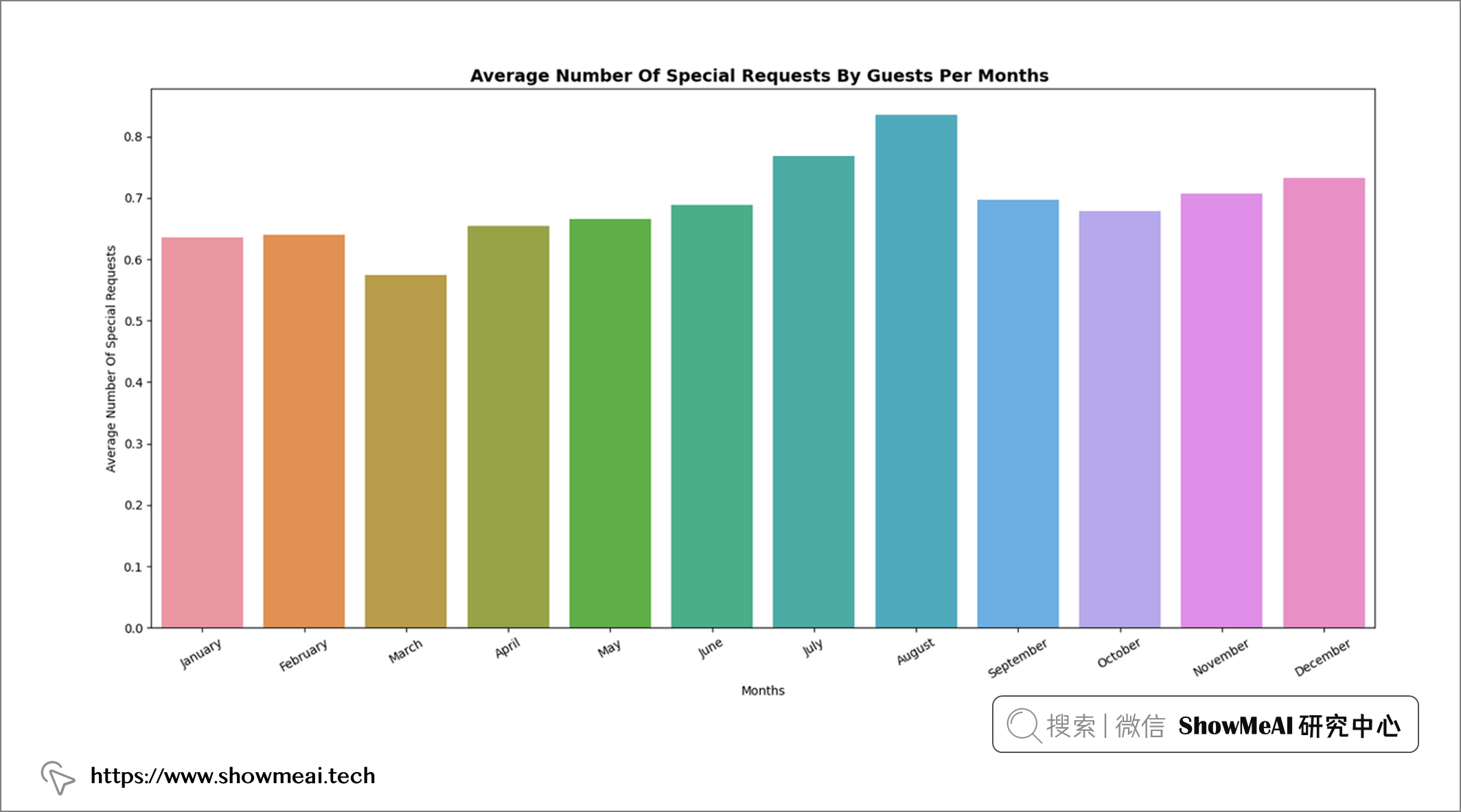
📢 结论:客人在几个月内提出了几乎相似数量的特殊要求,但在 8 月、7 月和 12 月提出的特殊要求略多一些。
💦 酒店类型&价格
# Histogram
fig = plt.figure(figsize = (16, 10))
df.drop(df[df["adr"] == 5400].index, axis = 0, inplace = True)
plt.suptitle("Average Daily Rate Per Hotel", fontweight = "bold", fontsize = 14,
fontfamily = "sans-serif", color = 'black')
plot1 = fig.add_subplot(1, 2, 2)
plt.title("Histogram Plot", fontweight = "bold", fontsize = 14, fontfamily = 'sans-serif', color = 'black')
sns.histplot(data = df, x = 'adr', hue = "hotel", kde = True, color = "#104E8B")
plt.xlabel('Average Daily Rate', fontweight = 'normal', fontsize = 11, fontfamily = 'sans-serif', color = "black")
plt.ylabel('Count', fontweight = 'regular', fontsize = 11, fontfamily = "sans-serif", color = "black")
# Box Plot
plot2 = fig.add_subplot(1, 2, 1)
plt.title("Box Plot", fontweight = "bold", fontsize = 14, fontfamily = 'sans-serif', color = 'black')
sns.boxplot(data = df, x = "hotel", y = 'adr', color = "#104E8B")
plt.ylabel('Average Daily Rate', fontweight = 'regular', fontsize = 11, fontfamily = 'sans-serif', color = "black")
plt.show()
df["adr"].describe()
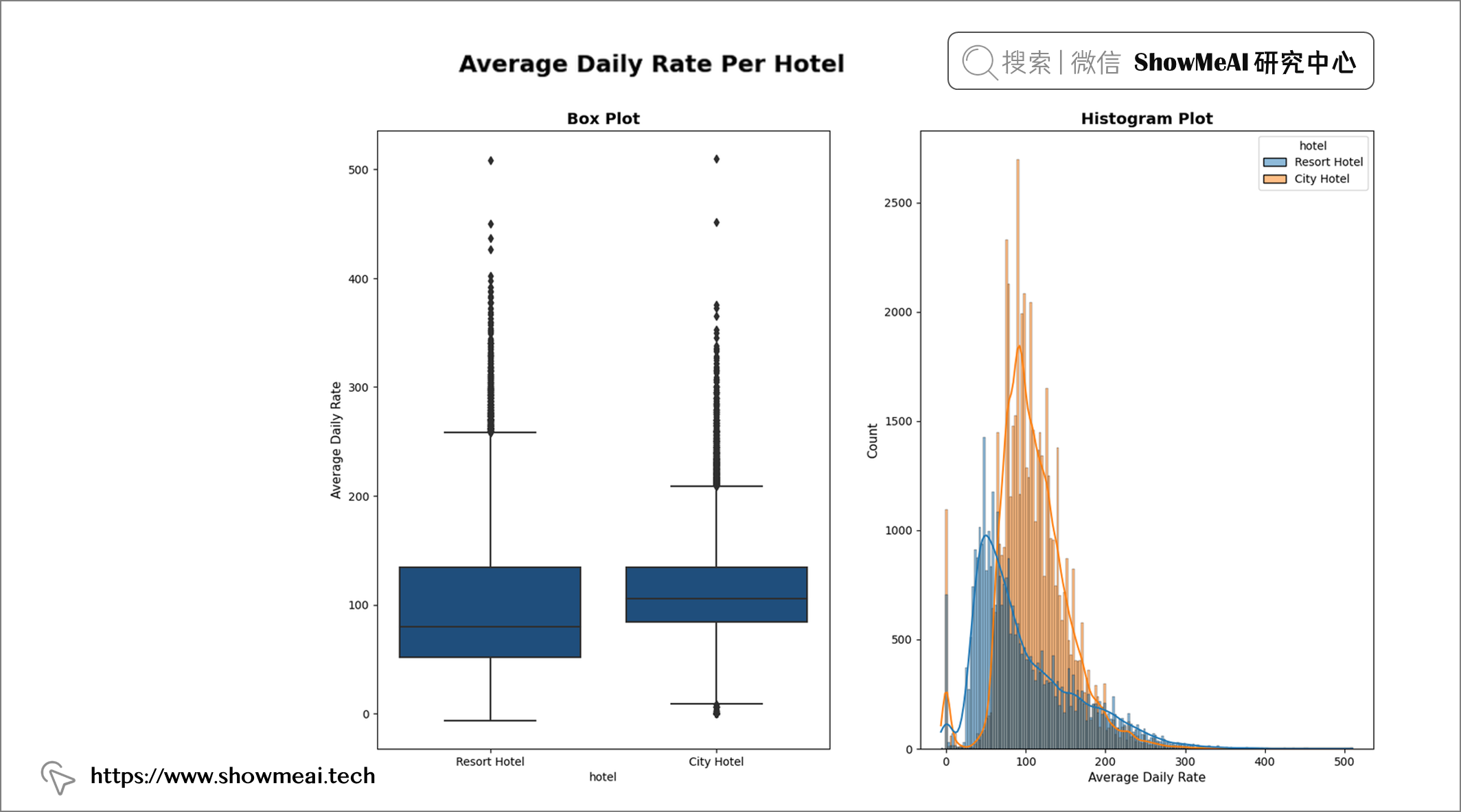
📢 结论:度假村酒店的平均每日价格比城市酒店更分散。
💦 月份&费率
months = ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October",
"November", "December"]
df.drop(df[df["adr"] == 5400].index, axis = 0, inplace = True)
d = df.groupby(["hotel", "arrival_date_month"])["adr"].mean().reset_index()
d["arrival_date_month"] = pd.Categorical(d["arrival_date_month"], categories = months, ordered = True)
d.sort_values("arrival_date_month", inplace = True)
fig = plt.figure(figsize = (16, 10))
plt.suptitle("Average Daily Rate Per Month", fontweight = "bold", fontsize = 14,
fontfamily = "sans-serif", color = 'black')
sns.lineplot(data = d, y = 'adr', x = "arrival_date_month", hue = "hotel")
plt.ylabel('Average Daily Rate', fontweight = 'normal', fontsize = 11, fontfamily = 'sans-serif', color = "black")
plt.xlabel('Months', fontweight = 'regular', fontsize = 11, fontfamily = "sans-serif", color = "black")
plt.xticks(rotation = 30)
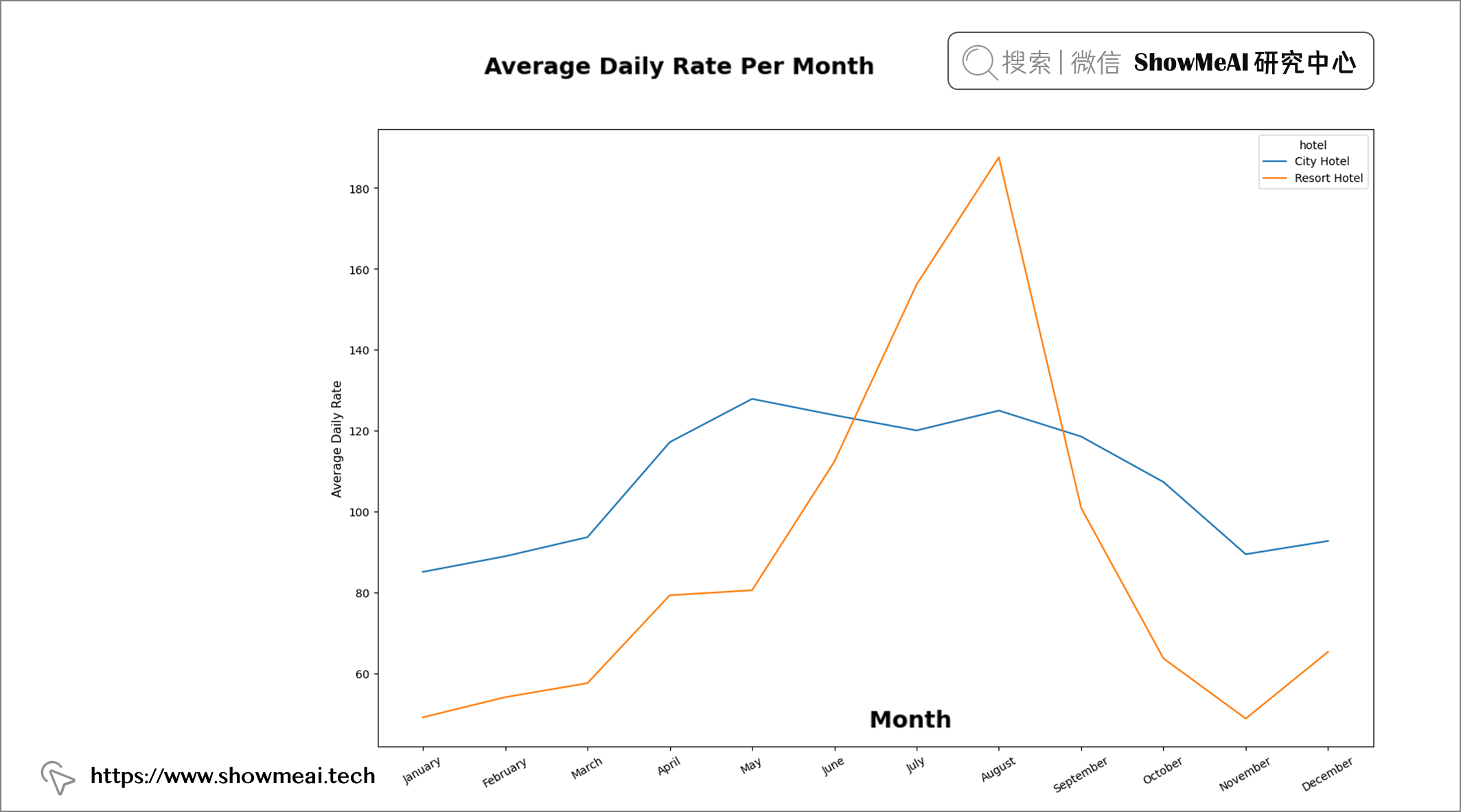
📢 结论:两类酒店的平均每日房价在年中均较高。与度假村酒店相比,城市酒店在年初和年末的每日房价较高。
💡 相关性分析
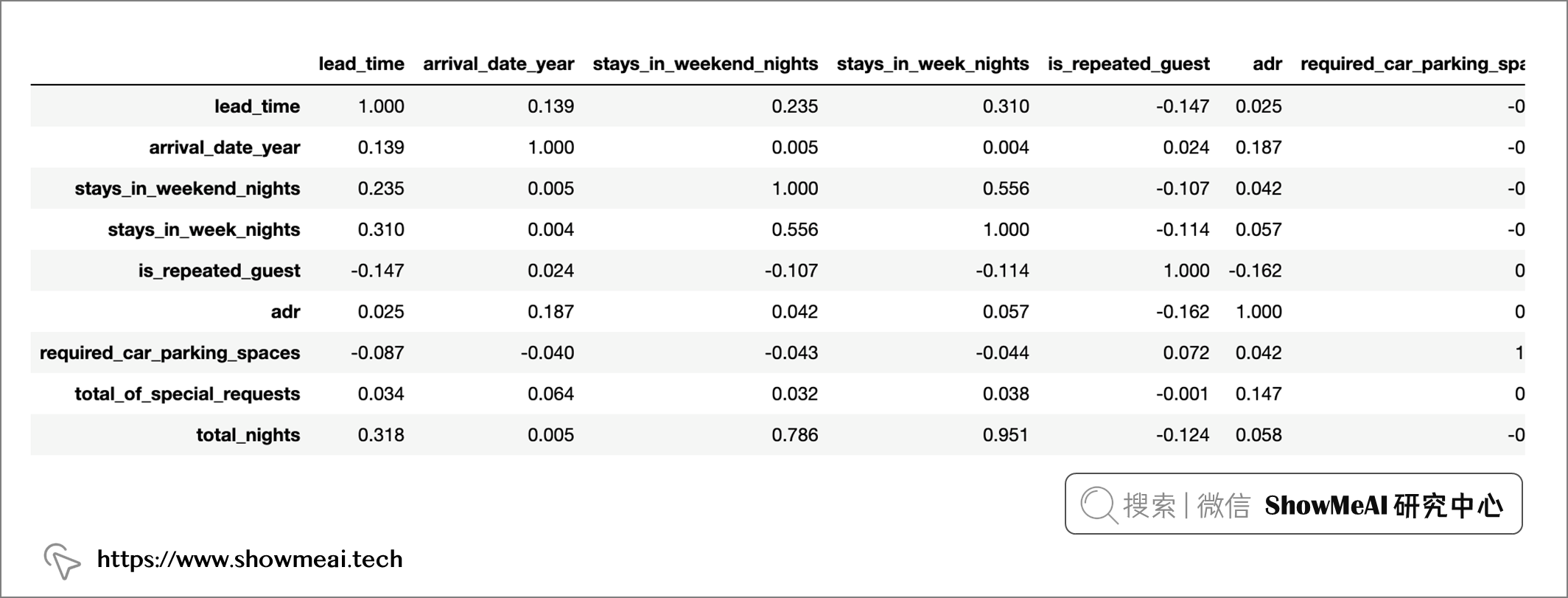
💦 相关矩阵
我们计算一下相关矩阵,看看字段间的相关性如何
# 剔除一些不参与相关分析的字段
df_sub = df.drop(['arrival_date_week_number', 'arrival_date_day_of_month', 'previous_cancellations','previous_bookings_not_canceled', 'booking_changes', 'reservation_status_date', 'agent', 'company', 'days_in_waiting_list', 'adults', 'babies', 'children'], axis = 1)
# 相关矩阵
corr_matrix = round(df_sub.corr(), 3)
"Correlation Matrix: "
corr_matrix
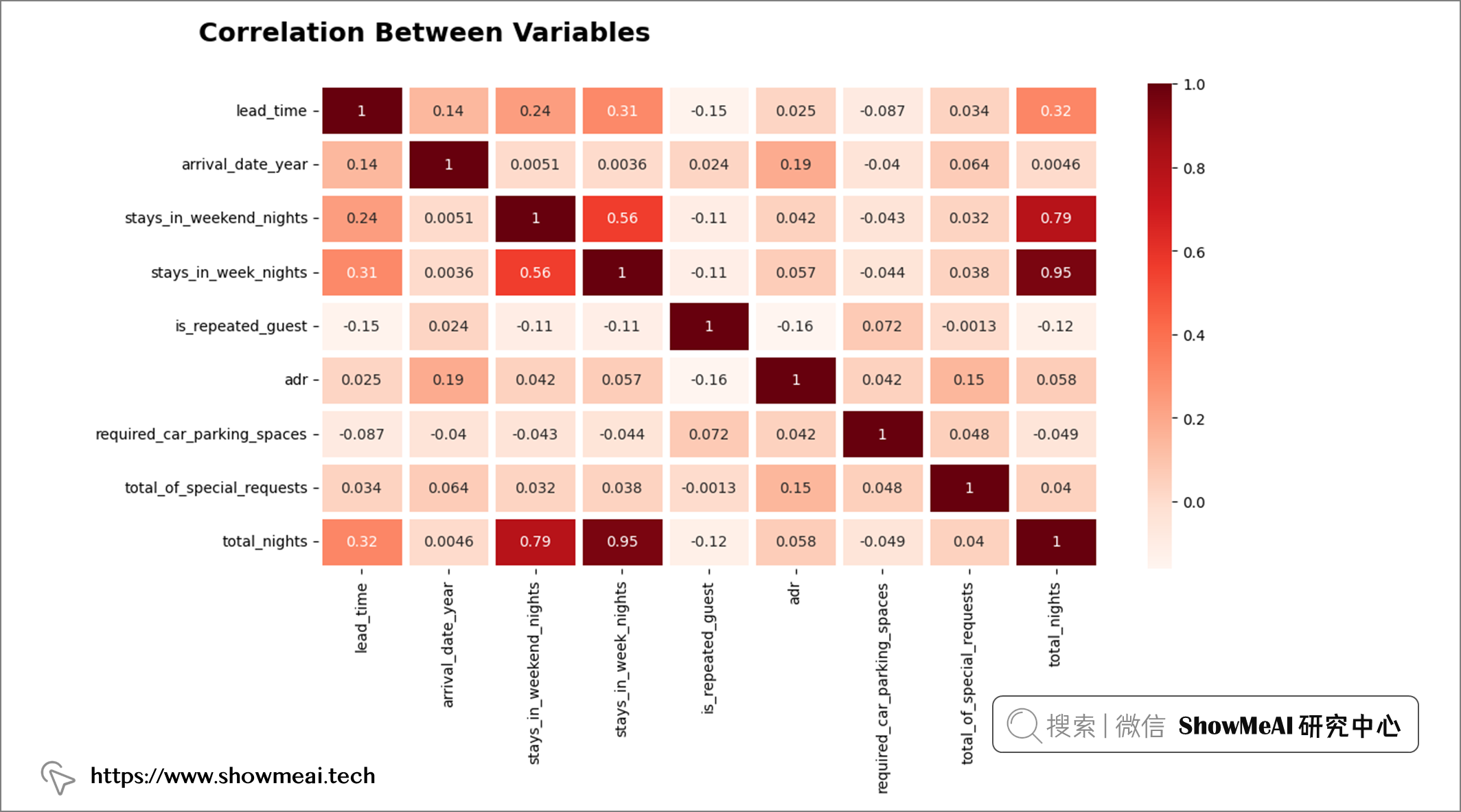
💦 热力图
我们做一个热力图的绘制,以便更清晰看到字段间相关性。
plt.rcParams['figure.figsize'] =(12, 6)
sns.heatmap(df_sub.corr(), annot=True, cmap='Reds', linewidths=5)
plt.suptitle('Correlation Between Variables', fontweight='heavy', x=0.03, y=0.98, ha = "left", fontsize='18', fontfamily='sans-serif', color= "black")
参考资料
- 📘 数据科学工具库速查表 | Pandas 速查表:https://www.showmeai.tech/article-detail/101
- 📘 图解数据分析:从入门到精通系列教程:https://www.showmeai.tech/tutorials/33

 浙公网安备 33010602011771号
浙公网安备 33010602011771号