
异常值检测!最佳统计方法实践(代码实现)!⛵
 数据集中的异常值,对于数据分布、建模等都有影响。本文讲解两大类异常值的检测方法及其Python实现:可视化方法(箱线图&直方图)、统计方法(z分数&四分位距)。
数据集中的异常值,对于数据分布、建模等都有影响。本文讲解两大类异常值的检测方法及其Python实现:可视化方法(箱线图&直方图)、统计方法(z分数&四分位距)。

💡 作者:韩信子@ShowMeAI
📘 Python3◉技能提升系列:https://www.showmeai.tech/tutorials/56
📘 数据分析实战系列:https://www.showmeai.tech/tutorials/40
📘 本文地址:https://www.showmeai.tech/article-detail/336
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏ShowMeAI查看更多精彩内容

💡 异常值 Q&A
异常值是距离其他数据值太远的数据点,也被称为离群点。它可能是自然发生的,也可能是由于测量不准确、拼写错误或系统故障造成的。异常值也可能出现在倾斜数据中,这些类型的异常值被认为是自然异常值。

了解异常值检测与分析的基础知识,请查看 ShowMeAI](https://www.showmeai.tech/) 这篇文章:
💦 异常值对分布有什么影响?
异常值会影响数据的均值、标准差和四分位数值。如果我们在去除异常值之前和之后计算这些统计数据,可能会有比较大的差异。
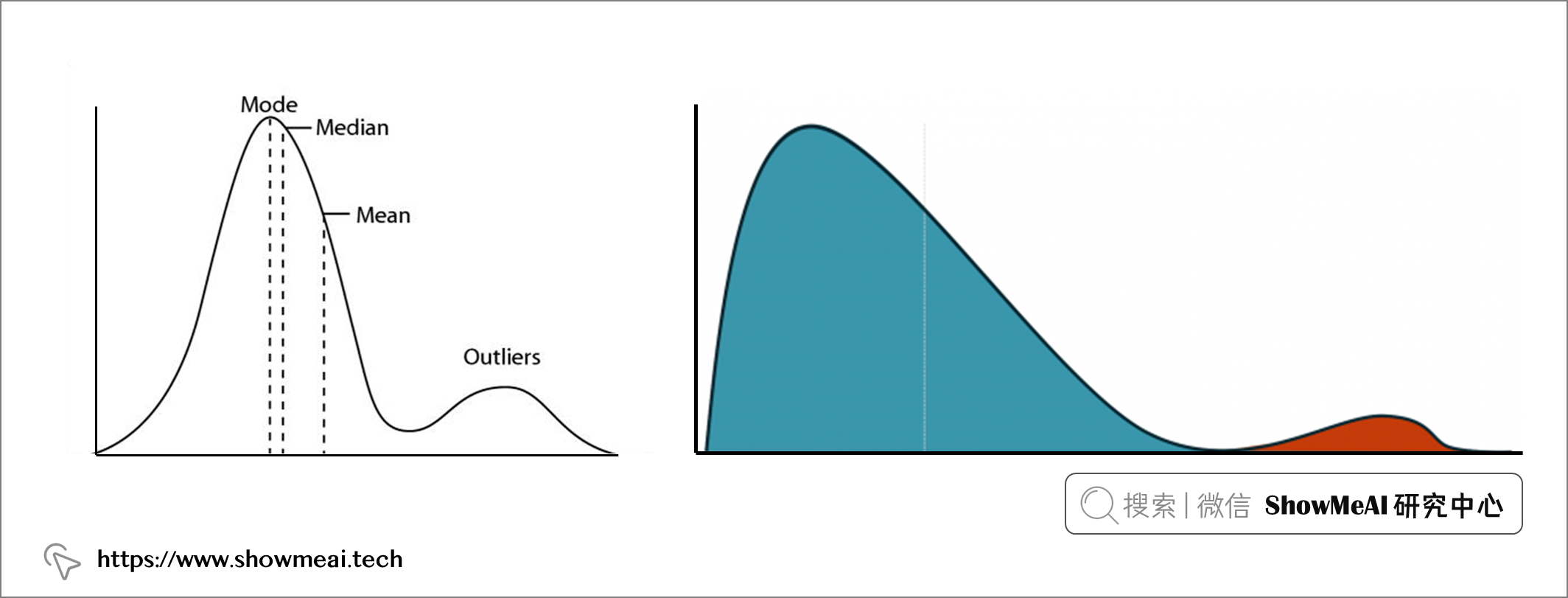
💦 异常值对机器学习模型有什么影响?
- 如果认为异常值是自然的,不是由于测量错误产生的 → 应该将其保留在数据集中,并用『标准化』等数据预处理方式处理。
- 如果有一个包含少量异常值的大型数据集 → 应该将其保留,不会显著影响结果。
- 如果确定异常值是由测量误差造成的 → 应该将它们从数据集中删除。
去除异常值会带来数据集规模的减小,而且模型的适用性也会限制在输入值的度量范围内,丢弃自然异常值也可能导致模型不准确。
💡 基于可视化的异常值检测
异常值不容易被『肉眼』检测到,但我们有一些可视化工具可以帮助完成这项任务。最常见的是箱线图和直方图。我们这里用 🏆保险数据来做一个讲解:
🏆 实战数据集下载(百度网盘):公✦众✦号『ShowMeAI研究中心』回复『实战』,或者点击 这里 获取本文 [29]基于统计方法的异常值检测代码实战 『insurance数据集』
⭐ ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub
我们首先导入必要的库并加载数据集。
import numpy as np import pandas as pd import seaborn as sns import statistics#Load dataset: df = pd.read_csv('insurance.csv') df
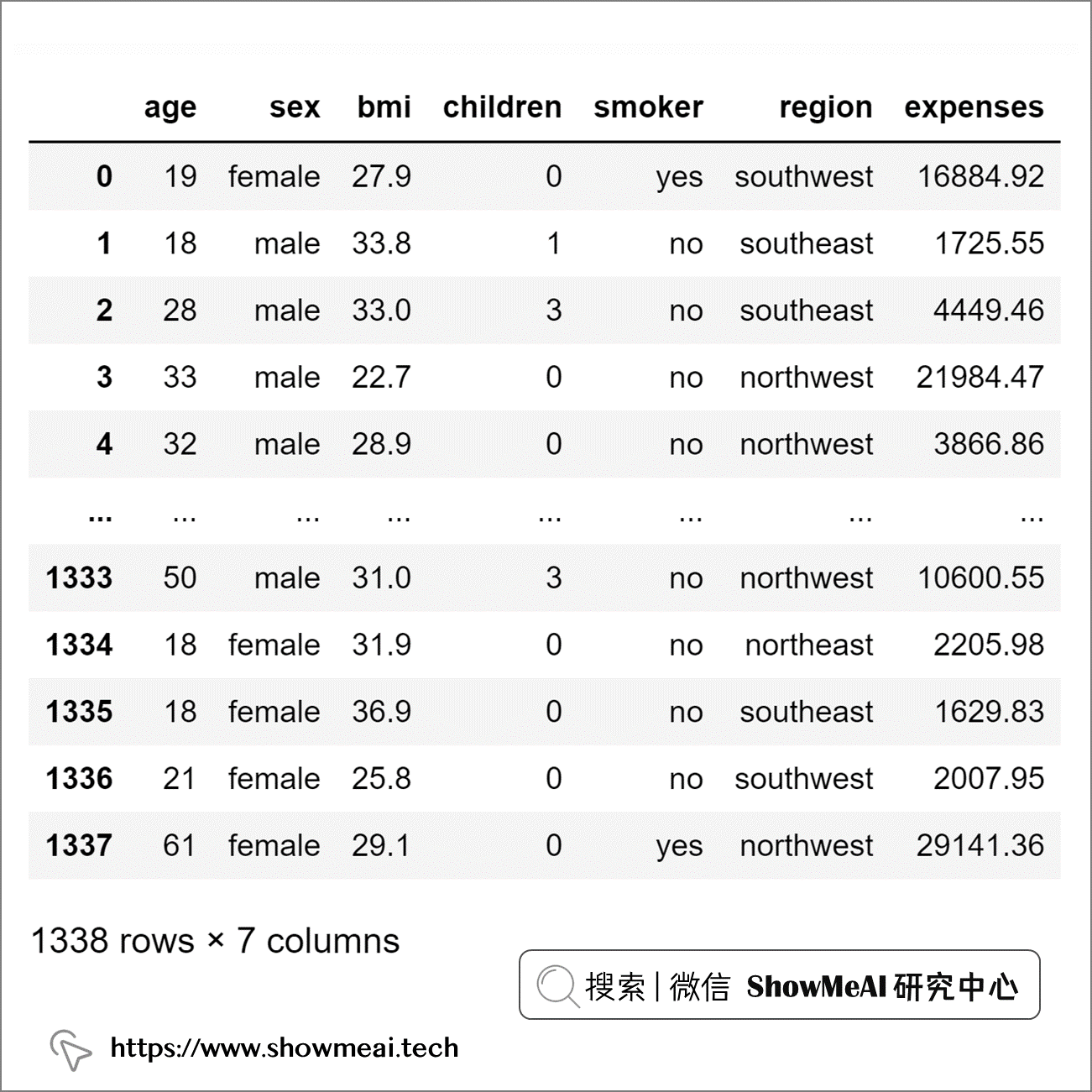
我们对变量『年龄』、『体重指数』和『费用』进行异常值检测分析。
第一种方法是使用箱线图 / Box-Plots 来绘制数据分布:
# age, bmi 和 expenses的箱线图绘图 sns.boxplot(y="age", data=df) sns.boxplot(y="bmi", data=df) sns.boxplot(y="expenses", data=df)
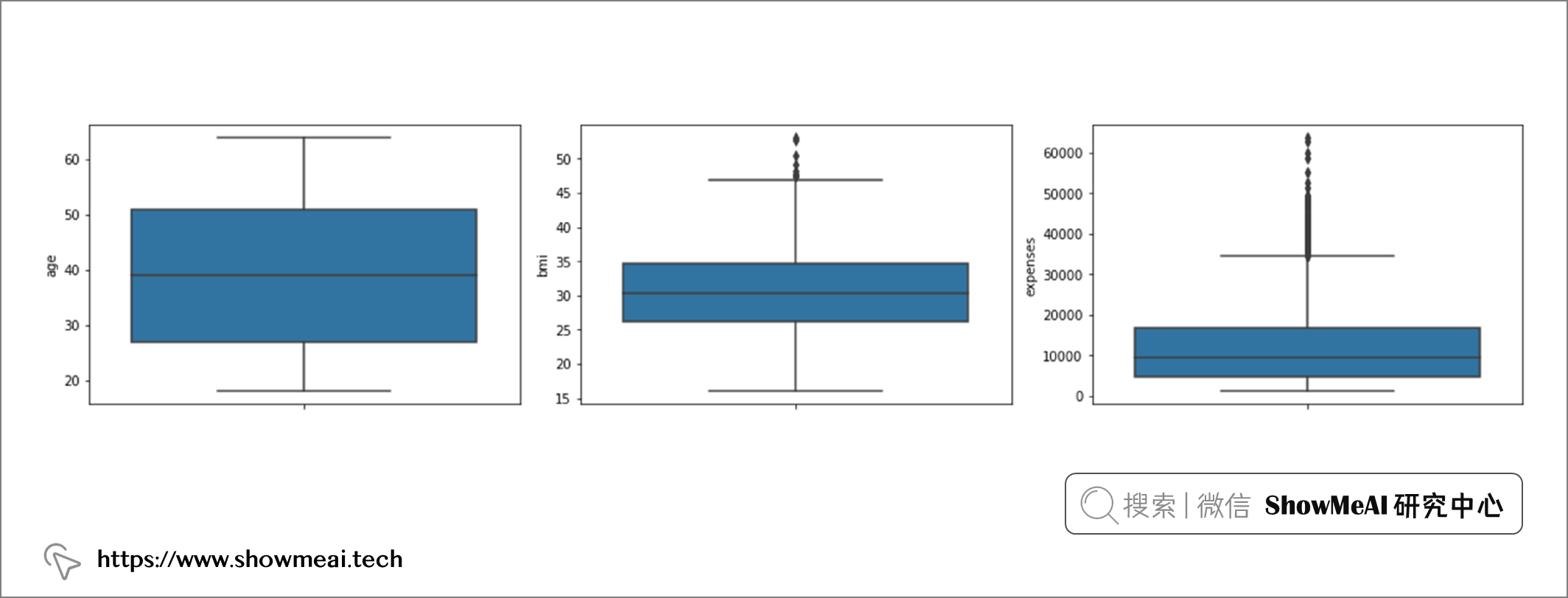
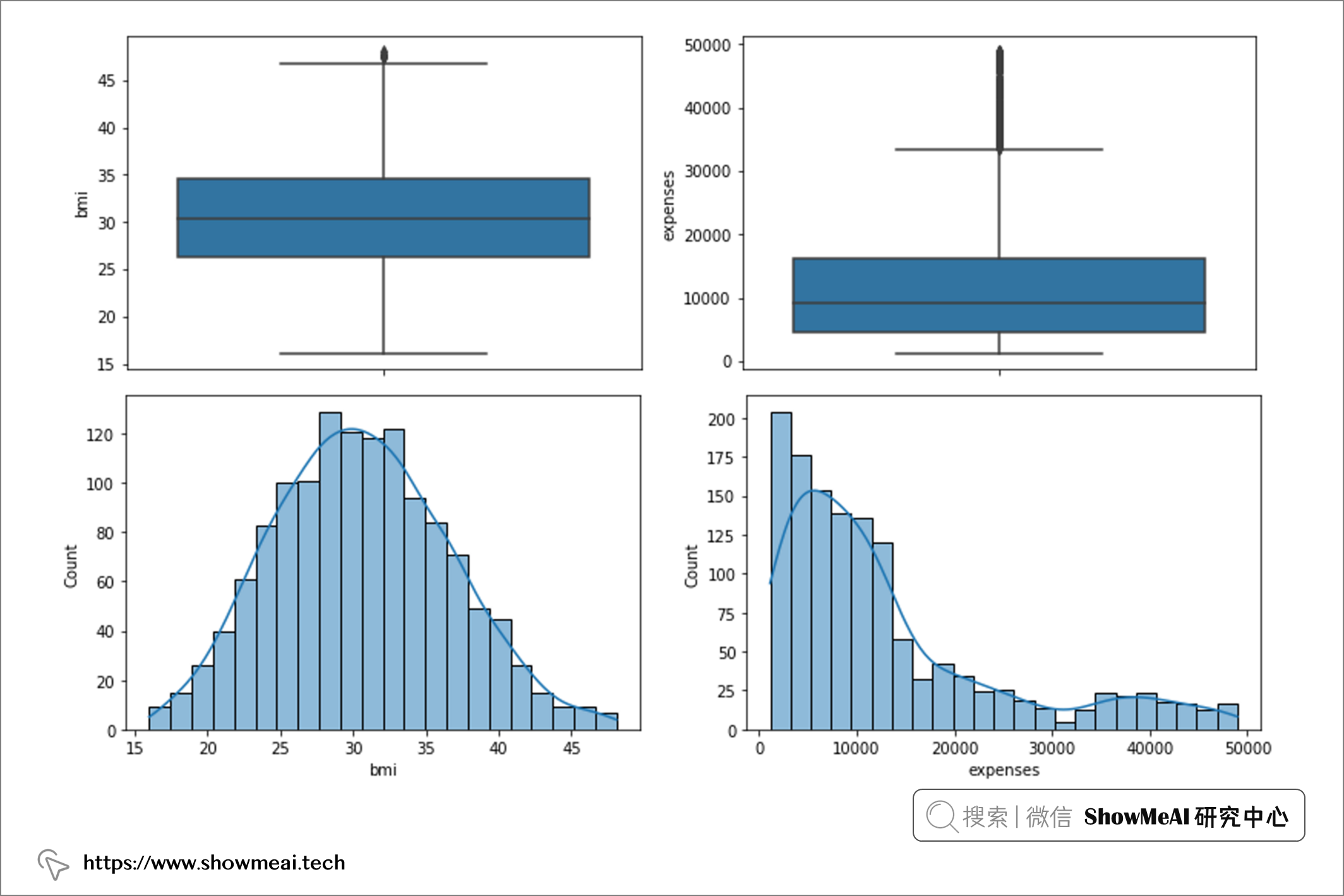
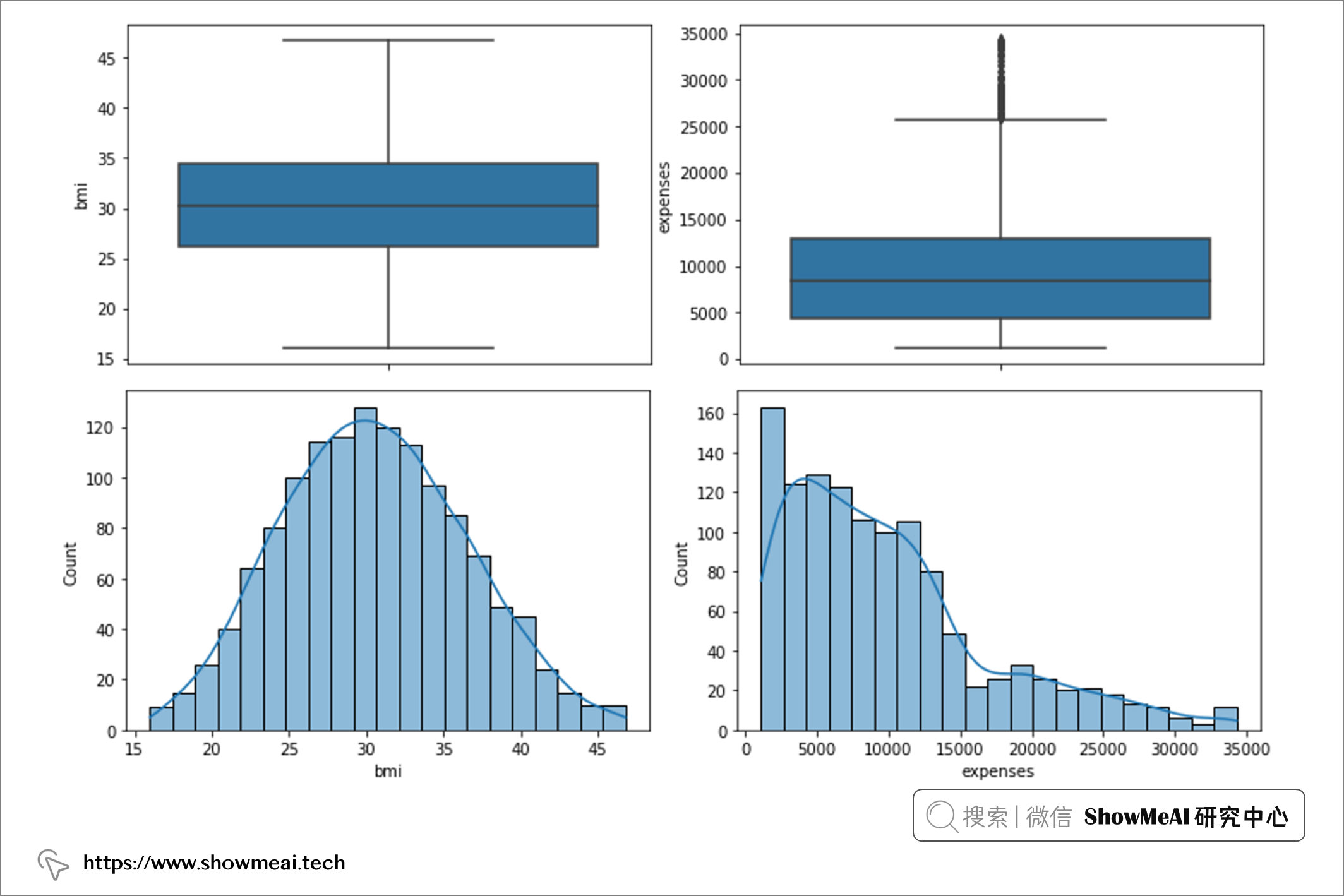
通过查看箱线图,我们可以看到变量 age 没有异常值,变量 bmi 在上限中有一些异常值,而变量 expense 在上限中有一系列异常值(表明存在偏态分布)。
为了检查偏态分布,我们再使用直方图绘图:
# age, bmi 和 expenses的直方图 sns.histplot(df, x="age", kde=True) sns.histplot(df, x="bmi", kde=True) sns.histplot(df, x="expenses", kde=True)
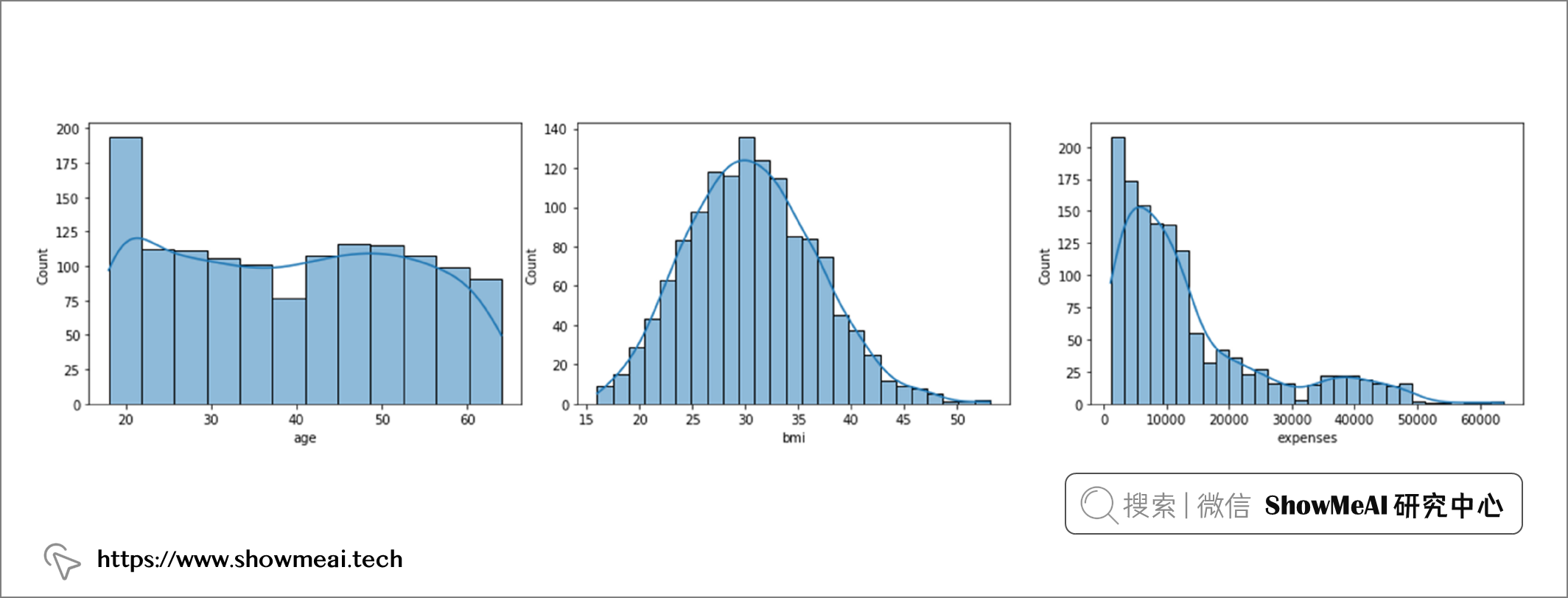
通过直方图,我们可以看到变量『age』是近似均匀分布,『bmi』接近正态分布,而『expense/费用』则呈偏态分布。
对于年龄,我们无需做异常值剔除;对于 bmi,我们将剔除高于 47 的值;对于费用,我们将剔除高于 50000 的值。
#bmi 和 expenses 的异常值处理 df.drop(df[df['bmi'] >= 47].index, inplace = True) df.drop(df[df['expenses'] >= 50000].index, inplace = True)
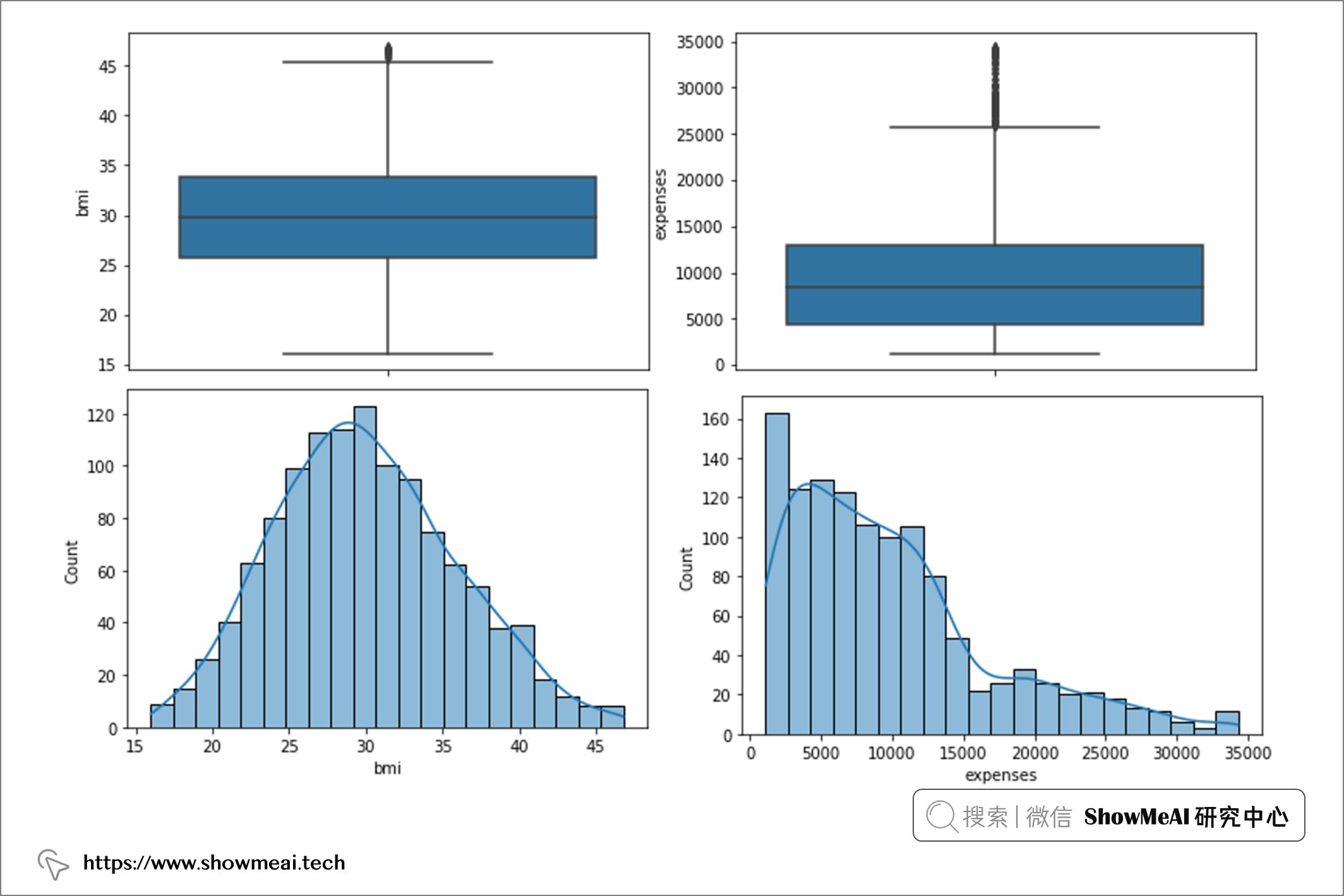
现在,如果我们再次检查箱线图和直方图:
💡 基于统计方法的异常值检测
检测异常值有两种主要的统计方法:使用 z 分数和使用四分位距。
💦 使用 z 分数检测异常值
Z 分数是一种数学变换,它根据每个观测值与平均值的距离对其进行分类。z-score 的计算公示为:

我们定义异常检测标准:如果 z-score 小于 -3或 z-score 大于 3。
我们将重新加载数据集,因为我们在前面的示例中对其进行了更改,加载后的数据上我们会把变量转换为 z 分数:
# 重新加载数据 df = pd.read_csv('insurance.csv') # 为age计算均值和标准差 mean_age = statistics.mean(df['age']) stdev_age = statistics.stdev(df['age']) # 计算z值 age_z_score = (df['age']-mean_age)/stdev_age # 添加z结果到原dataframe df['age_z_score'] = age_z_score.tolist()
现在我们将检查高于 3SD 或低于 -3SD 的值:
# 检测小于-3SD的值: df.sort_values(by=['age_z_score'], ascending=True)
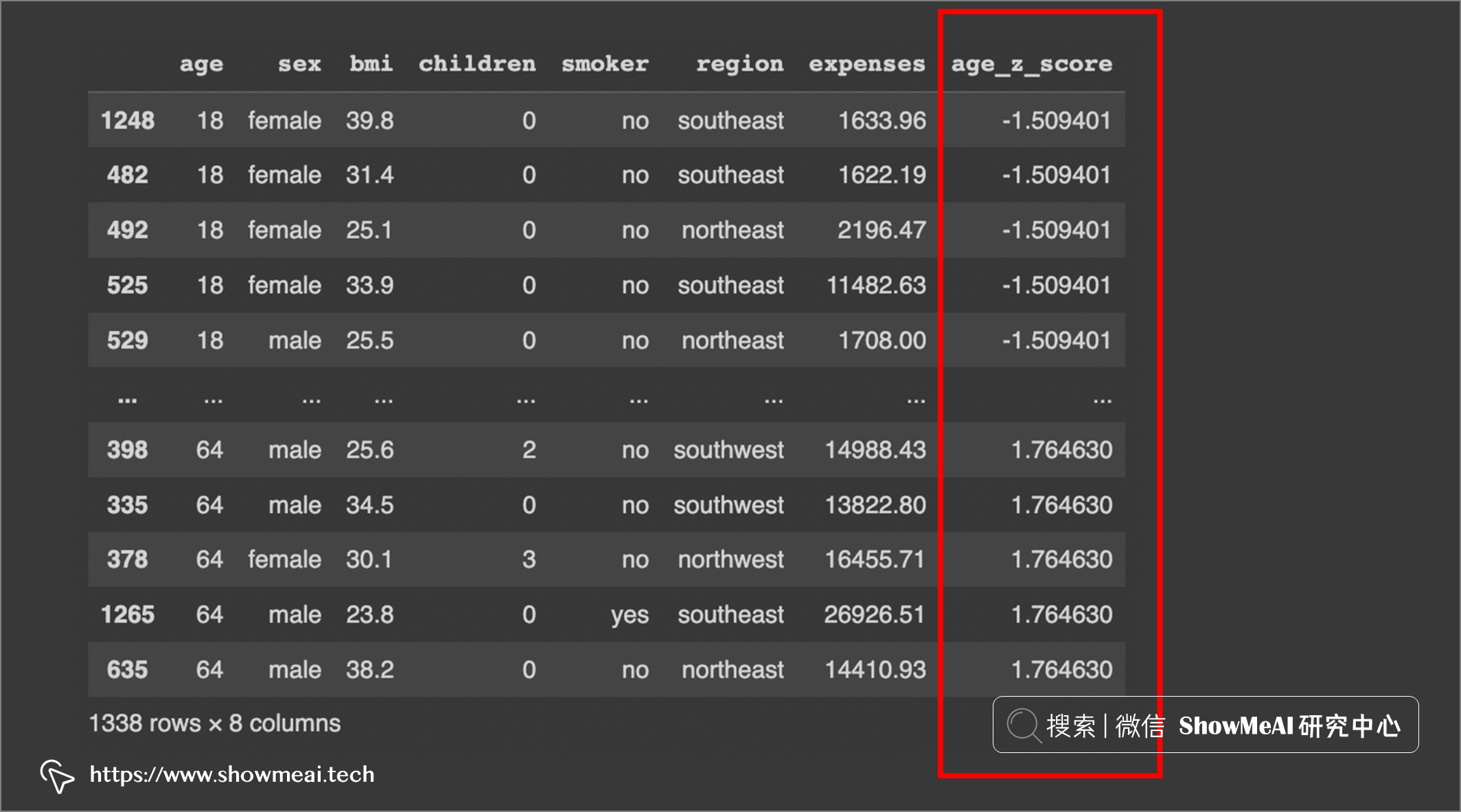
我们可以看到 -3SD 以下没有值。我们现在将检查 3SD 以上的值:
# 检测+3SD以上的值: df.sort_values(by=['age_z_score'], ascending=False)
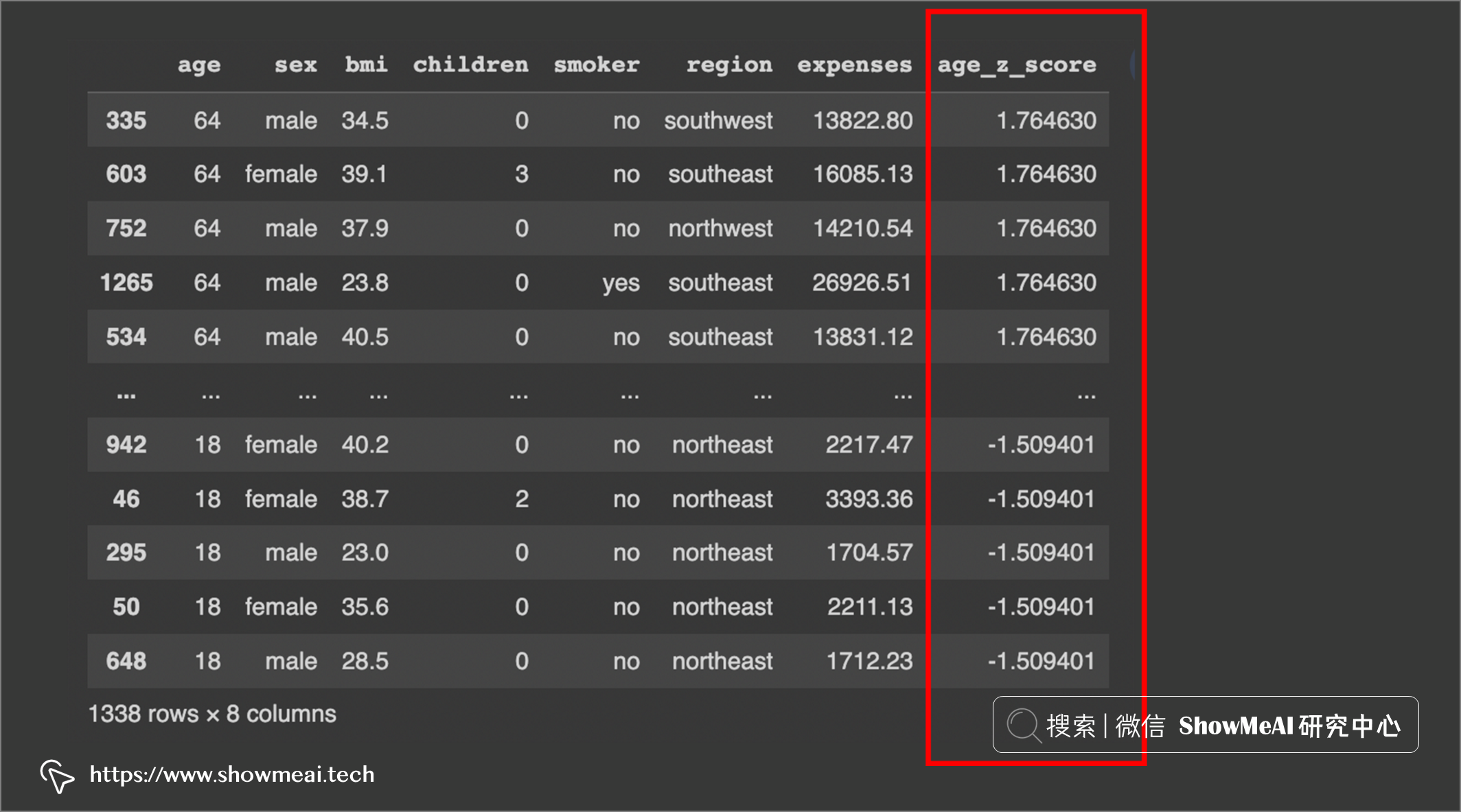
我们可以看到没有高于 3SD 的值。变量年龄没有异常值。
现在我们将对变量 bmi 执行相同的操作:
# 为bmi计算均值和标准差 mean_bmi = statistics.mean(df['bmi']) stdev_bmi = statistics.stdev(df['bmi']) # 为bmi计算z-score bmi_z_score = (df['bmi']-mean_bmi)/stdev_bmi # 添加到原始dataframe df['bmi_z_score'] = bmi_z_score.tolist() # 检查低于-3SD的值 df.sort_values(by=['bmi_z_score'], ascending=True) # 检查大于3SD的值 df.sort_values(by=['bmi_z_score'], ascending=False)
这次我们会发现一些高于 3SD 的值:
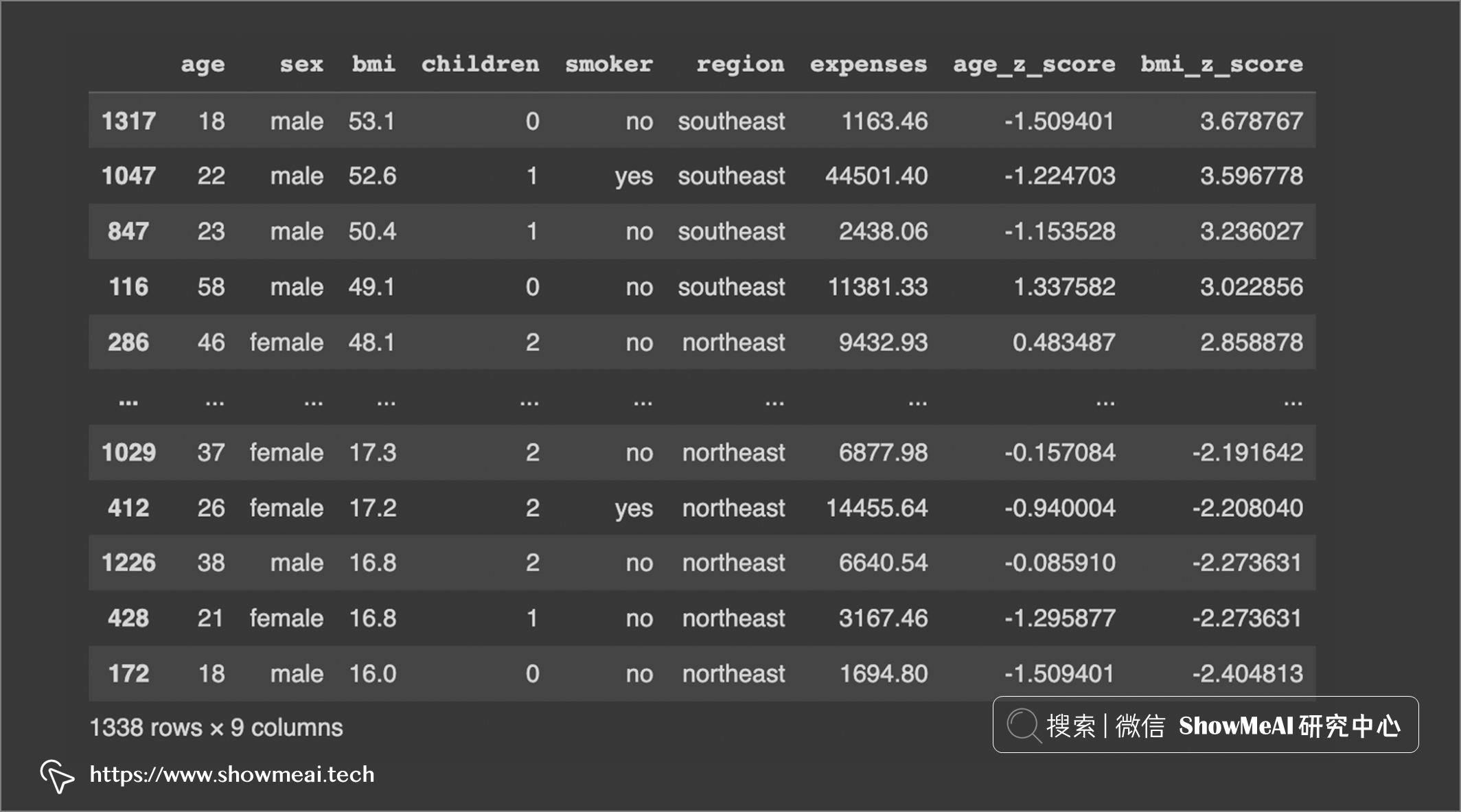
我们对它进行剔除:
# 异常值处理 df.drop(df[df[‘bmi_z_score’] >= 3].index, inplace = True)
我们将对『expense/费用』应用相同的技术:
# 为expenses计算均值和标准差 mean_expenses = statistics.mean(df['expenses']) stdev_expenses = statistics.stdev(df['expenses']) # 计算z-score expenses_z_score = (df['expenses']-mean_expenses)/stdev_expenses # 添加到原始dataframe df['expenses_z_score'] = expenses_z_score.tolist() # 检查低于-3SD的值 df.sort_values(by=['expenses_z_score'], ascending=True) # 检查高于3SD的值 df.sort_values(by=['expenses_z_score'], ascending=False) # 异常值处理 df.drop(df[df[‘expenses_z_score’] >= 3].index, inplace = True)
如果我们再次检查箱线图和直方图,我们将获得:
💦 使用四分位距检测异常值
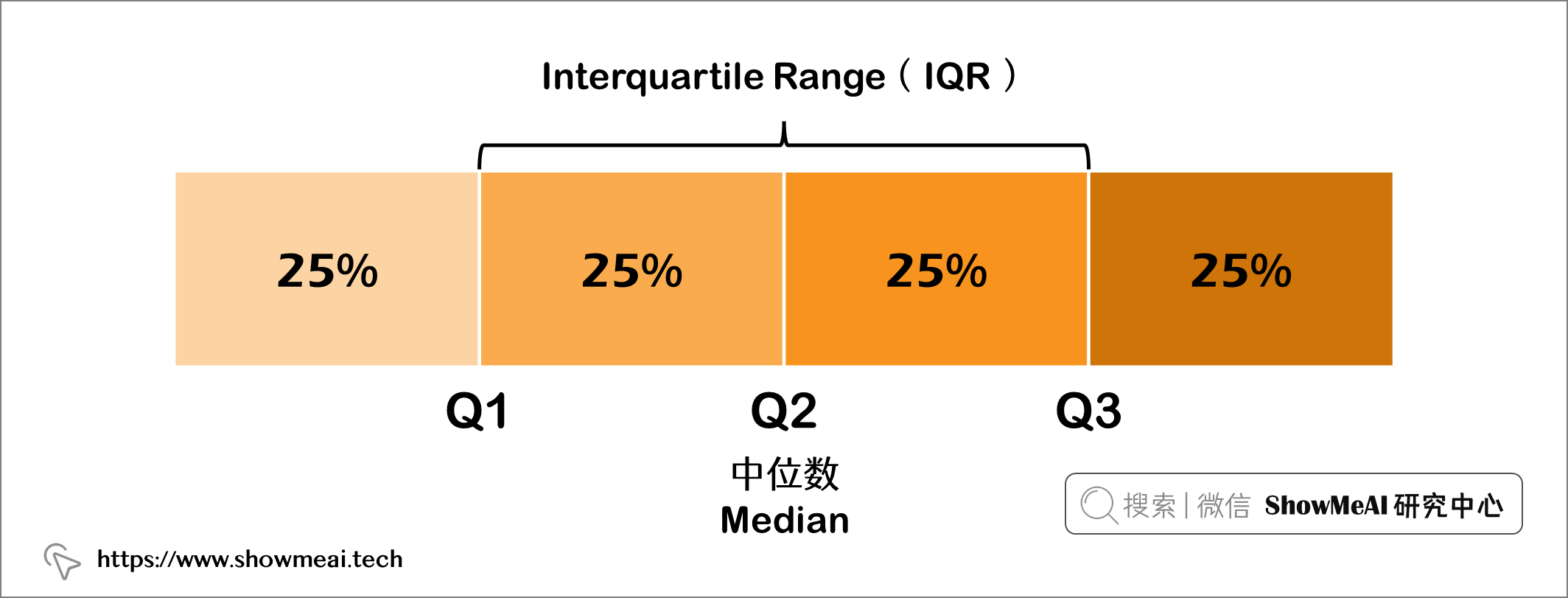
四分位间距将数据分为四个部分,从低到高排序,如下图所示,每个部分包含相同数量的样本。第一个四分位数(Q1)是边界中数据点的值。这同样适用于 Q2 和 Q3。 四分位距(IQR)是两个中间部分的数据点(代表 50% 的数据)。四分位距包含高于 Q1 和低于 Q3 的所有数据点。如果该点高于 Q3 + (1.5 x IQR),则存在较高的异常值,如果 Q1 - (1.5 x IQR),则存在较低的异常值。
代码实现如下:
# 重新加载数据 df = pd.read_csv('insurance.csv') # 计算上下四分位数位置 q75_age, q25_age = np.percentile(df['age'], [75 ,25]) iqr_age = q75_age - q25_age iqr_age # 计算上下边界以用于异常检测 age_h_bound = q75_age+(1.5*iqr_age) age_l_bound = q25_age-(1.5*iqr_age) print(age_h_bound) print(age_l_bound)
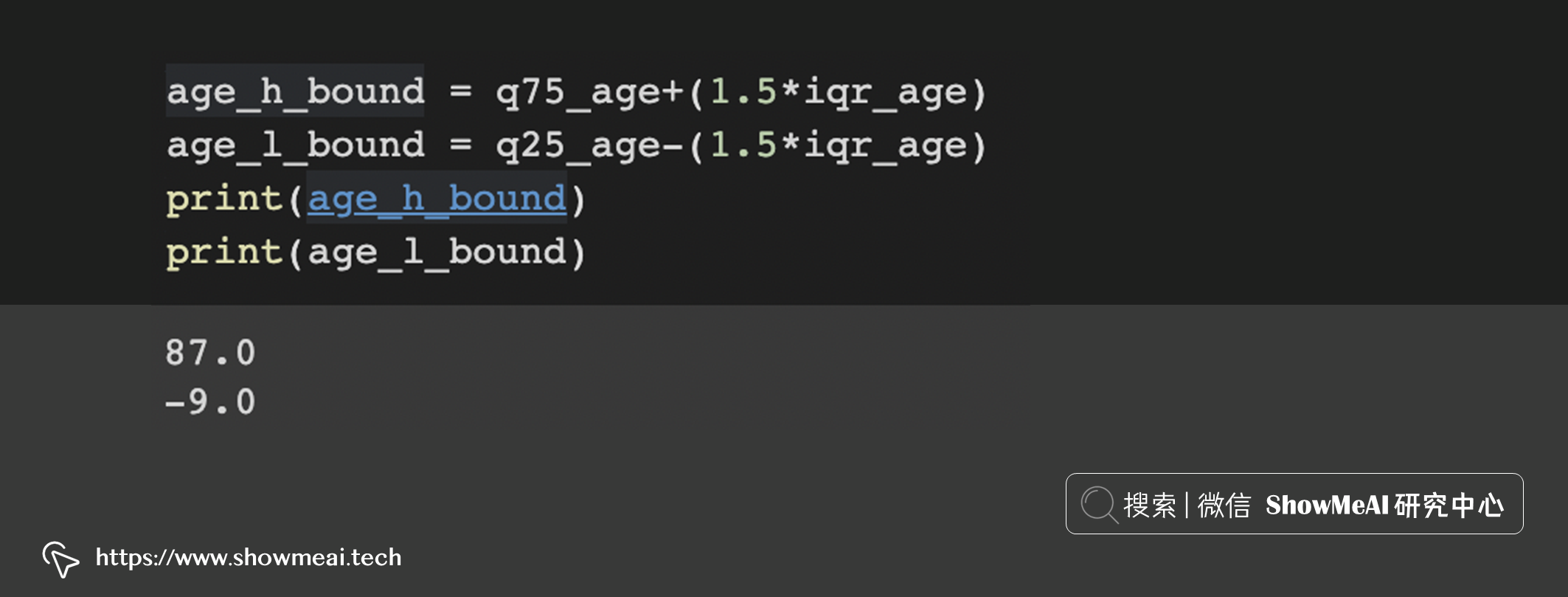
我们计算得到上边界 87 和下边界 -9:
# 排序 df.sort_values(by=['age'], ascending=True)
# 排序 df.sort_values(by=['age'], ascending=False)
我们看到没有异常值。
我们对变量 bmi 执行相同的操作:
# 计算上下四分位数位置 q75_bmi, q25_bmi = np.percentile(df['bmi'], [75 ,25]) iqr_bmi = q75_bmi - q25_bmi iqr_bmi # 计算上下边界以用于异常检测 bmi_h_bound = q75_bmi+(1.5*iqr_bmi) bmi_l_bound = q25_bmi-(1.5*iqr_bmi) print(bmi_h_bound) print(bmi_l_bound) # 排序 df.sort_values(by=['bmi'], ascending=True) df.sort_values(by=['bmi'], ascending=False) # 剔除异常值 df.drop(df[df['bmi'] >= 47.3].index, inplace = True) df.drop(df[df['bmi'] <= 13.7].index, inplace = True)
我们只需要对可变费用做同样的事情,我们将获得以下箱线图和直方图:
参考资料
- 📘 图解数据分析 | 数据清洗与预处理:https://www.showmeai.tech/article-detail/138


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2021-11-23 大厂技术实现 | 爱奇艺短视频推荐业务中的多目标优化实践 @推荐与计算广告系列
2021-11-23 大厂技术实现 | 多目标优化及应用(含代码实现)@推荐与计算广告系列