
2022!影响百万用户金融信用评分,Equifax被告上法庭,罪魁祸首——『数据漂移』!⛵
 数据随着时间变化,会导致已有模型的准确度大打折扣,这就是数据漂移问题。本文讲解数据漂移问题的诸多实际案例、检测方法、基于evidently库的代码实现。
数据随着时间变化,会导致已有模型的准确度大打折扣,这就是数据漂移问题。本文讲解数据漂移问题的诸多实际案例、检测方法、基于evidently库的代码实现。

💡 作者:韩信子@ShowMeAI
📘 数据分析实战系列:https://www.showmeai.tech/tutorials/40
📘 机器学习实战系列:https://www.showmeai.tech/tutorials/41
📘 本文地址:https://www.showmeai.tech/article-detail/331
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏ShowMeAI查看更多精彩内容
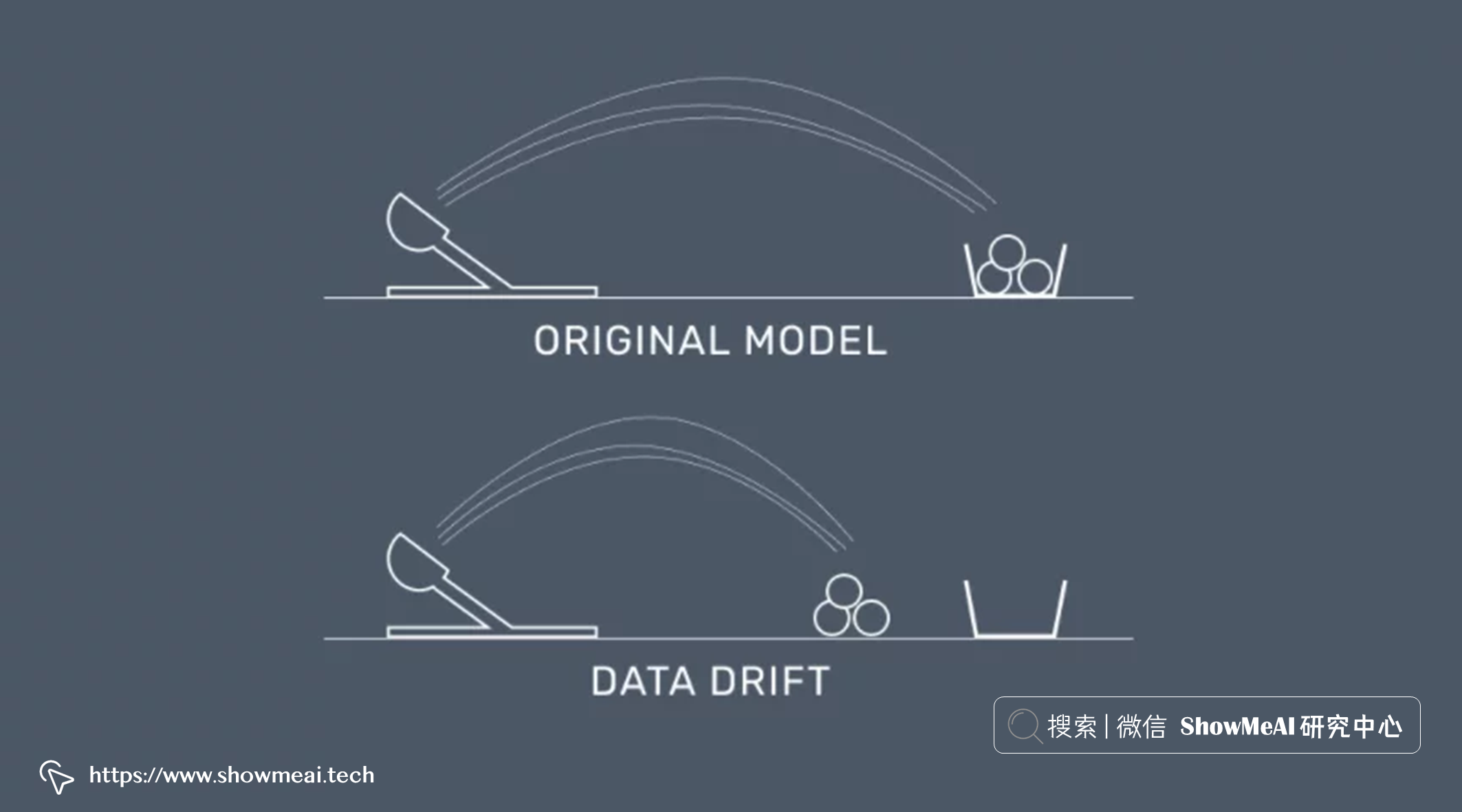
💦 数据漂移
The Only Constant in Life Is Change. 世界上唯一不变的就是变化本身。
这是一句来自希腊的哲学家赫拉克利特写的话,它很简单但却道出了世界的真理之一。在数据科学与机器学习领域,这句话同样是非常有意义的,在生产中部署机器学习模型的许多实际应用中,数据通常会随着时间的推移而变化,因此之前构建的模型会随着时间的推移而变得不准确,效果大打折扣,这就是典型的数据漂移问题。
💦 真实案例
2022年3月17日至4月6日,信用报告机构 Equifax 的系统出现问题,导致 📘信用评分不正确,影响到百万级别的消费者,并导致了针对公司的法律索赔和集体诉讼,业内专家称,这个问题的根源就是数据漂移。

💡 数据漂移
💦 何为数据漂移
当我们在使用数据科学方法解决场景问题时,得到方案之后,在实际生产环境中,如果我们拿到的实时预测数据,分布与用于训练模型的训练数据分布有差异时,就发生了『数据漂移』,而它的后果就是预估不再准确,效果下降甚至直接影响公司的收益。
简单的例子,例如用『口罩政策』之前的互联网数据建模,对『口罩政策』实施时的用户行为预估,那一定会有偏差;又如我们用日常数据建模,构建电商推荐系统,在 618 和双11当天预测,可能也会有偏差,模型效果下降。
训练数据和生产数据之间的差异可能是由多种因素造成的。可能本来使用的训练数据就不合适。

例如,如果使用美国道路数据集训练和检测道路状况,应用在中国的道路上,效果就会差非常多,这也是明显的数据漂移。
现代互联网时代,没分每秒都迅速产生海量大数据,我们的数据源呈现爆炸式增长也更容易会有变化。我们并不能每次都提前预判到『数据漂移』问题,甚至有时候我们会遇到特殊的网络攻击,基于『数据漂移』的知识进行调整和切换攻击方式。

例如,我们基于历史数据构建了效果非常良好的垃圾邮件检测功能,但攻击者可能在某个时候改变发送垃圾邮件的行为,因为送入模型的数据发生了变化,我们原本构建的模型可能真的会被『欺骗』。
因此,很重要的是,我们需要有一套比对和检测的机制,可以及时发现『数据漂移』,并对其进行处理。
💦 检测方法概述
有很多数据漂移的检测方法,最简单的方式是基于统计方法来比较『训练数据』(称为基线或参考)和『实时数据』(生产数据)的分布,如果两个分布之间有着显着差异,我们就判断为发生数据漂移。
最流行的统计检验方法包括 📘Kolmogorov-Smirnov 检验、📘卡方检验、 📘Jensen-Shannon 散度、 📘Wasserstein 距离。 另一类方法是使用机器学习模型来监控数据质量。 我们也可以把两类方法混合使用。
实际生产环境中,统计的方法使用得很多,它们简单且有很不错的效果。下面 ShowMeAI 就基于代码告诉大家如何进行『数据漂移』检测。
💡 代码实现
💦 数据漂移检测
我们在这里会使用到 evidently 这个非常简单易用的工具库,它是一个专门针对『数据漂移』问题构建的工具库,可以对数据 / 标签 / 模型表现等进行检测,不仅可以输出报告,还可以启动实时看板监控。
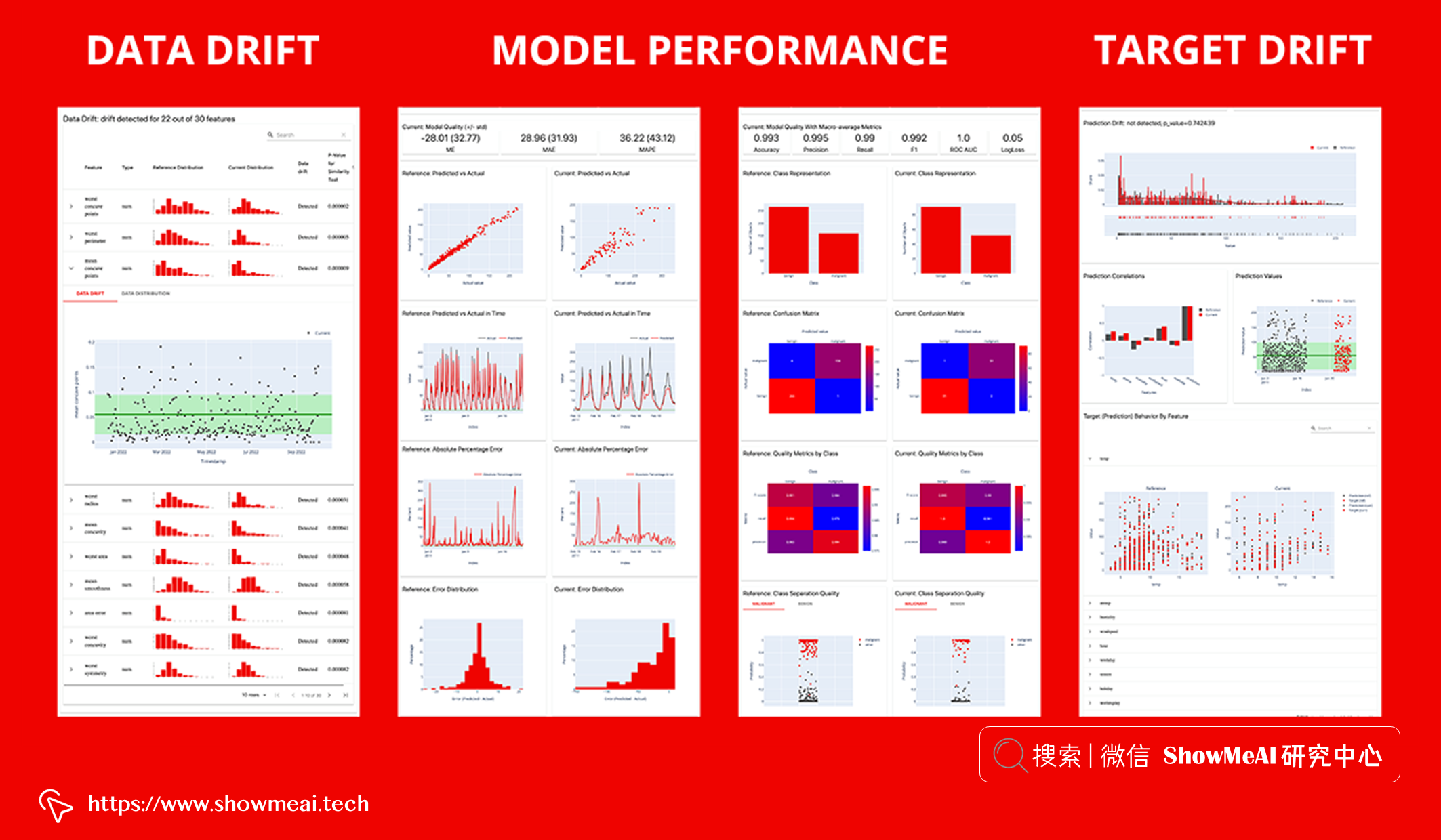
下面导入工具库
import pandas as pd from sklearn import datasets from evidently.dashboard import Dashboard from evidently.dashboard.tabs import DataDriftTab, CatTargetDriftTab
evidently的使用步骤如下,我们会先加载数据,然后做漂移分析和检测,最后可以构建看板进行分析结果的呈现。
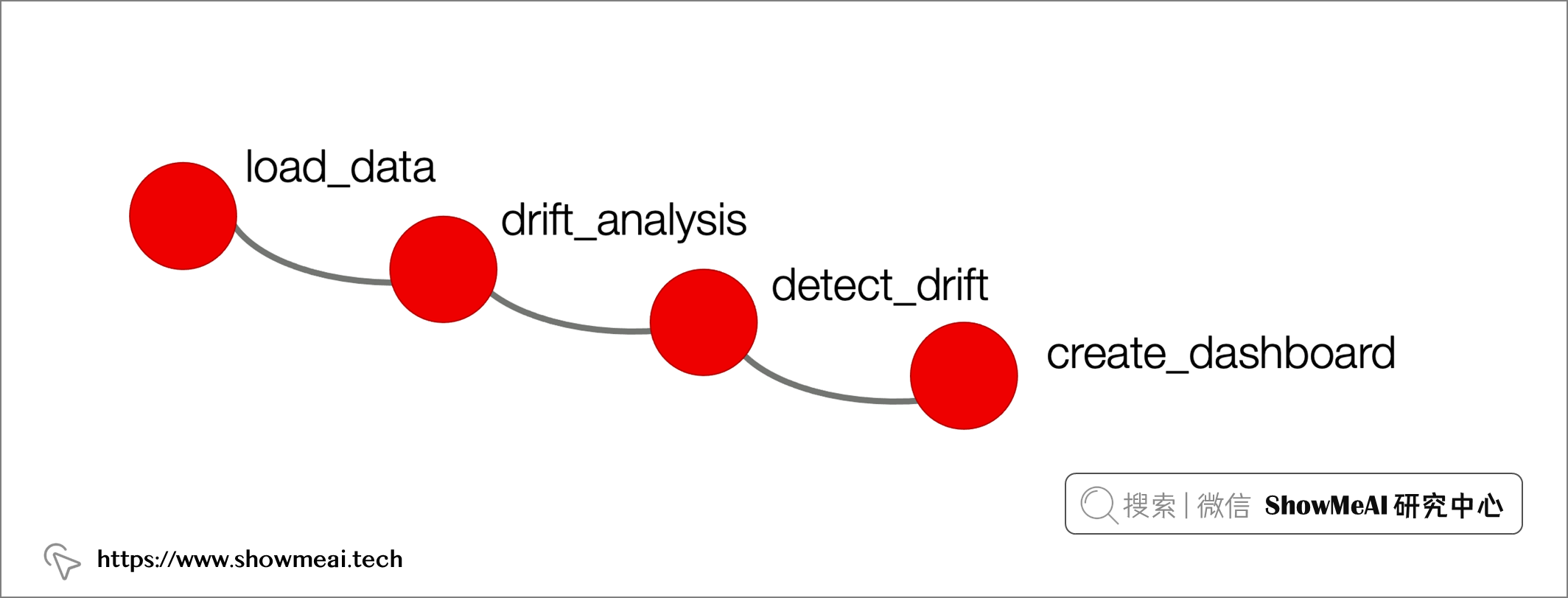
我们使用sklearn自带的 iris 数据集作为示例来给大家讲解,我们把对应的数据和标签读取出来。
iris = datasets.load_iris() iris_frame = pd.DataFrame(iris.data, columns = iris.feature_names) iris_frame['target'] = iris.target
我们把完整的数据集切分为训练集和测试集,对其进行对比和数据漂移分析,最后构建仪表盘看板:
iris_data_drift_report = Dashboard(tabs=[DataDriftTab(verbose_level=verbose), CatTargetDriftTab(verbose_level=verbose)]) iris_data_drift_report.calculate(iris_frame[:75], iris_frame[-new_samples:], column_mapping = None) iris_data_drift_report.show(mode="inline")
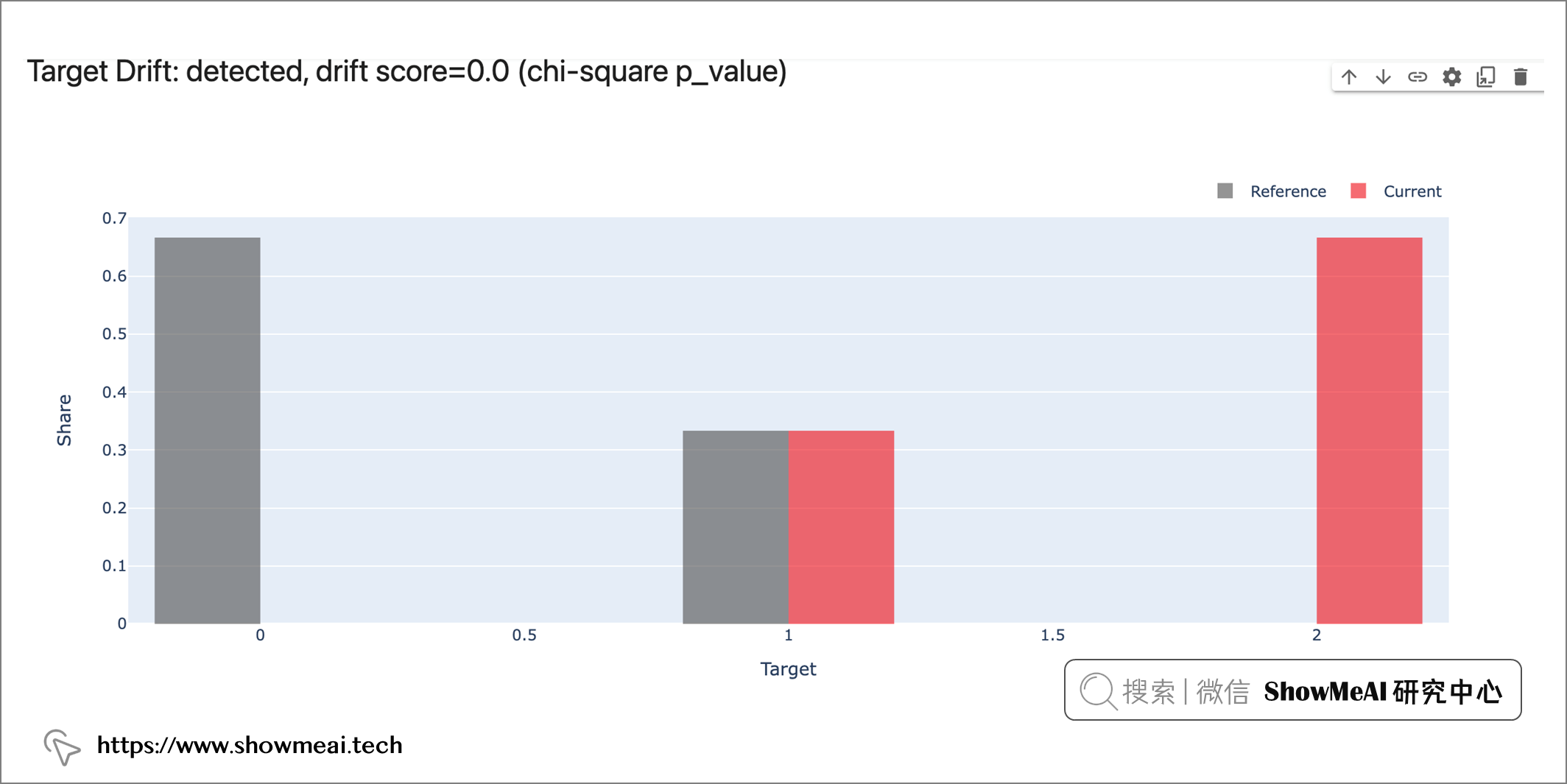
注意到参数verbose,它是布尔值,用于控制显示仪表板的详细程度。 上述代码中我们设置为 False,会得到一个报告如下,里面详细分析了训练集和测试集的『特征字段』和『标签』的分布差异情况:
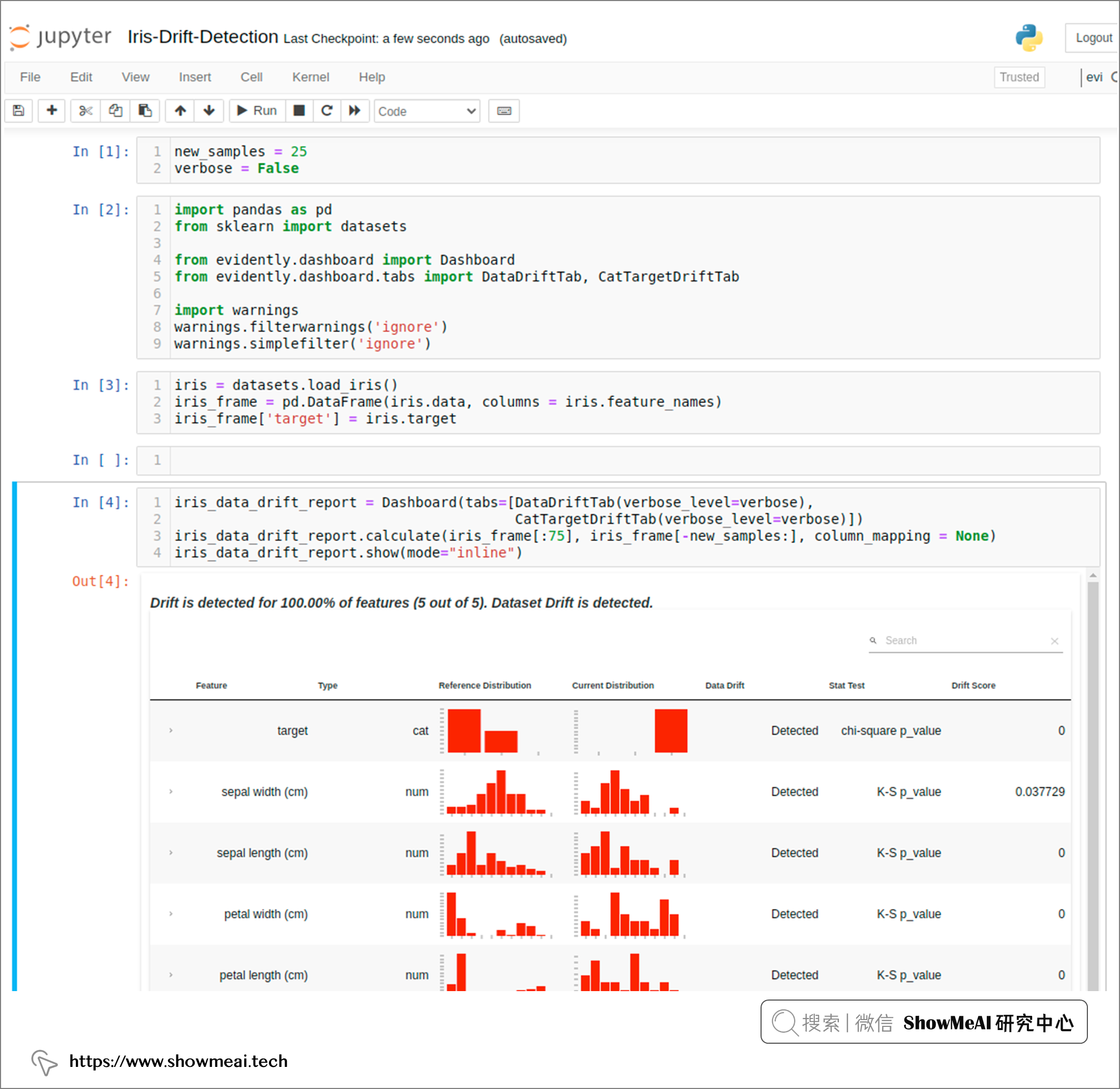
我们也可以通过下列代码去打开看板和存储html报告。
iris_target_drift_dashboard.show() iris_target_drift_dashboard.save('iris_target_drift.html')
参考资料
- 📘 Equifax issued wrong credit scores for millions of consumers:https://www.cnn.com/2022/08/03/business/equifax-wrong-credit-scores/index.html
- 📘 Kolmogorov-Smirnov 检验:https://en.wikipedia.org/wiki/Kolmogorov%E2%80%93Smirnov_test
- 📘 卡方检验:https://en.wikipedia.org/wiki/Chi-squared_test
- 📘 Jensen-Shannon 散度:https://en.wikipedia.org/wiki/Jensen%E2%80%93Shannon_divergence
- 📘 Wasserstein 距离:https://en.wikipedia.org/wiki/Wasserstein_metric


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人