
数据驱动!精细化运营!用机器学习做客户生命周期与价值预估!⛵
 如何预测客户价值,计算特定时间段内能带来的价值,是互联网公司在面临海量用户时急需解决的运营命题。本文就来讲解『机器学习+RFM模型』的精细化运营解决方案。
如何预测客户价值,计算特定时间段内能带来的价值,是互联网公司在面临海量用户时急需解决的运营命题。本文就来讲解『机器学习+RFM模型』的精细化运营解决方案。

💡 作者:韩信子@ShowMeAI
📘 机器学习实战系列:https://www.showmeai.tech/tutorials/41
📘 本文地址:https://www.showmeai.tech/article-detail/330
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏ShowMeAI查看更多精彩内容

现在的互联网平台都有着海量的客户,但客户和客户之间有很大的差异,了解客户的行为方式对于充分理解用户与优化服务增强业务至关重要。而借助机器学习,我们可以实现更精细化地运营,具体来说,我们可以预测客户价值,即在特定时间段内将为公司带来多少价值。
本篇内容中使用的 🏆scanner在线交易数据集,可以直接在 ShowMeAI的百度网盘中下载获取。
🏆 实战数据集下载(百度网盘):公✦众✦号『ShowMeAI研究中心』回复『实战』,或者点击 这里 获取本文 [26] 基于机器学习的客户价值预估 『scanner在线交易数据集』
⭐ ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub

本篇内容中我们的实现步骤包括:
- 整合&处理数据
- 基于递归 RFM 技术从数据构建有效特征
- 基于数据建模与预估
💡 整合&处理数据
💦 数据说明
ShowMeAI本篇使用到的数据集,是通过零售店『扫描』商品条形码而获得的流水销售的详细数据。数据集覆盖一年时间,涵盖 22625 个顾客、5242 个商品、64682 次交易。数据字段说明如下:
| 字段 | 含义 |
|---|---|
| Date | 销售交易的日期 |
| Customer_ID | 客户ID |
| Transaction_ID | 交易ID |
| SKU_Category_ID | 商品类别ID |
| SKU_ID | 商品ID |
| Quantity | 销售数量 |
| Sales_Amount | 销售金额(单价乘以数量) |
💦 数据读取 & 处理
本文数据处理部分涉及的工具库,大家可以参考ShowMeAI制作的工具库速查表和教程进行学习和快速使用。
上述信息中最重要的3列是:客户ID、销售交易的日期、销售金额,当然大家也可以在后续建模中囊括更多的丰富信息(如商品类别等)。这里我们先读取数据并针对时间字段做一点格式转换。
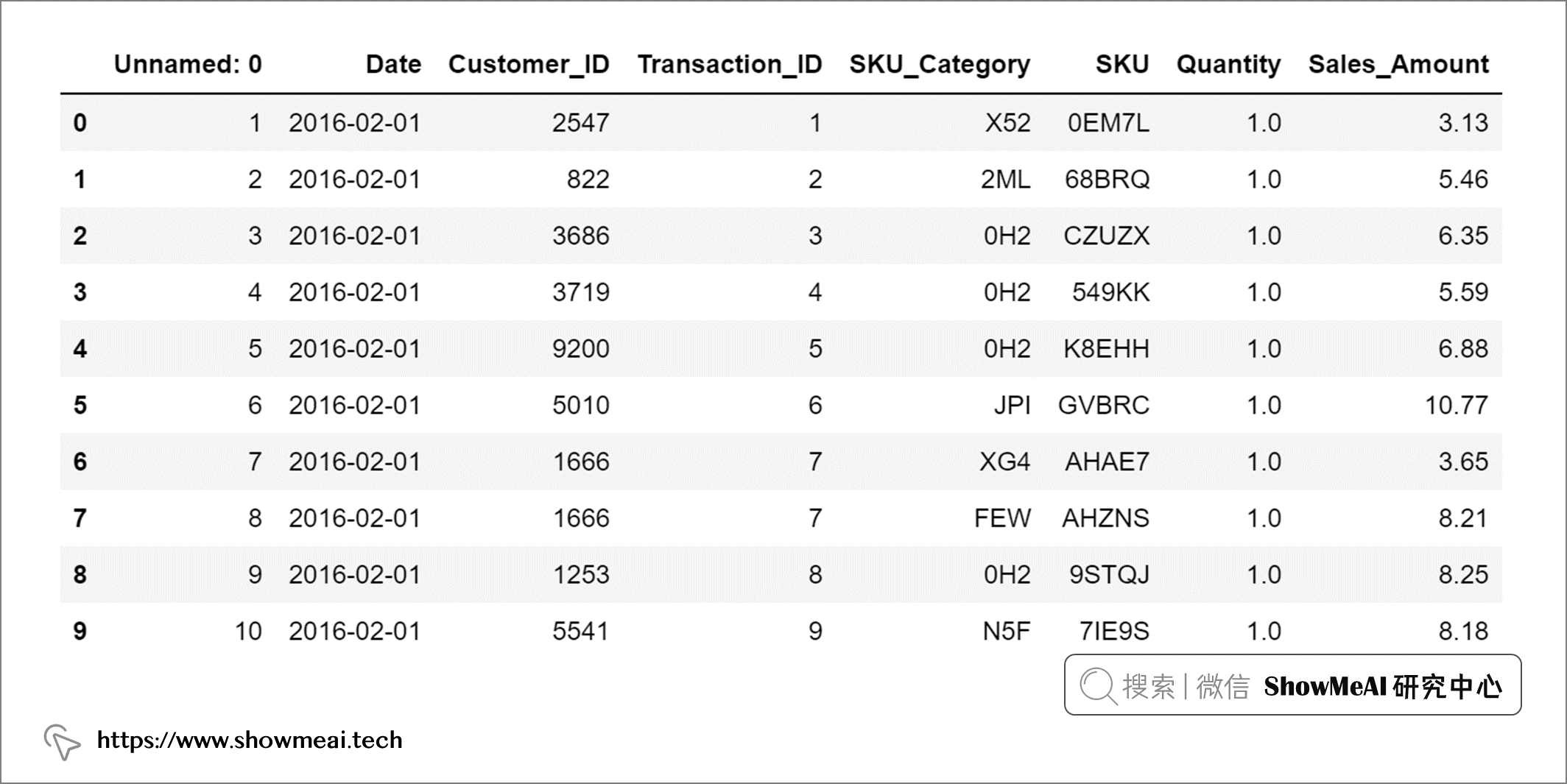
import pandas as pd # 读取CSV格式交易数据 df = pd.read_csv(data_path) # 数据路径 # 日期型数据转换 df.Date = pd.to_datetime(df.Date) df.head(10)
💡 RFM & 特征工程
关于机器学习特征工程,大家可以参考 ShowMeAI 整理的特征工程最全解读教程。
💦 RFM介绍
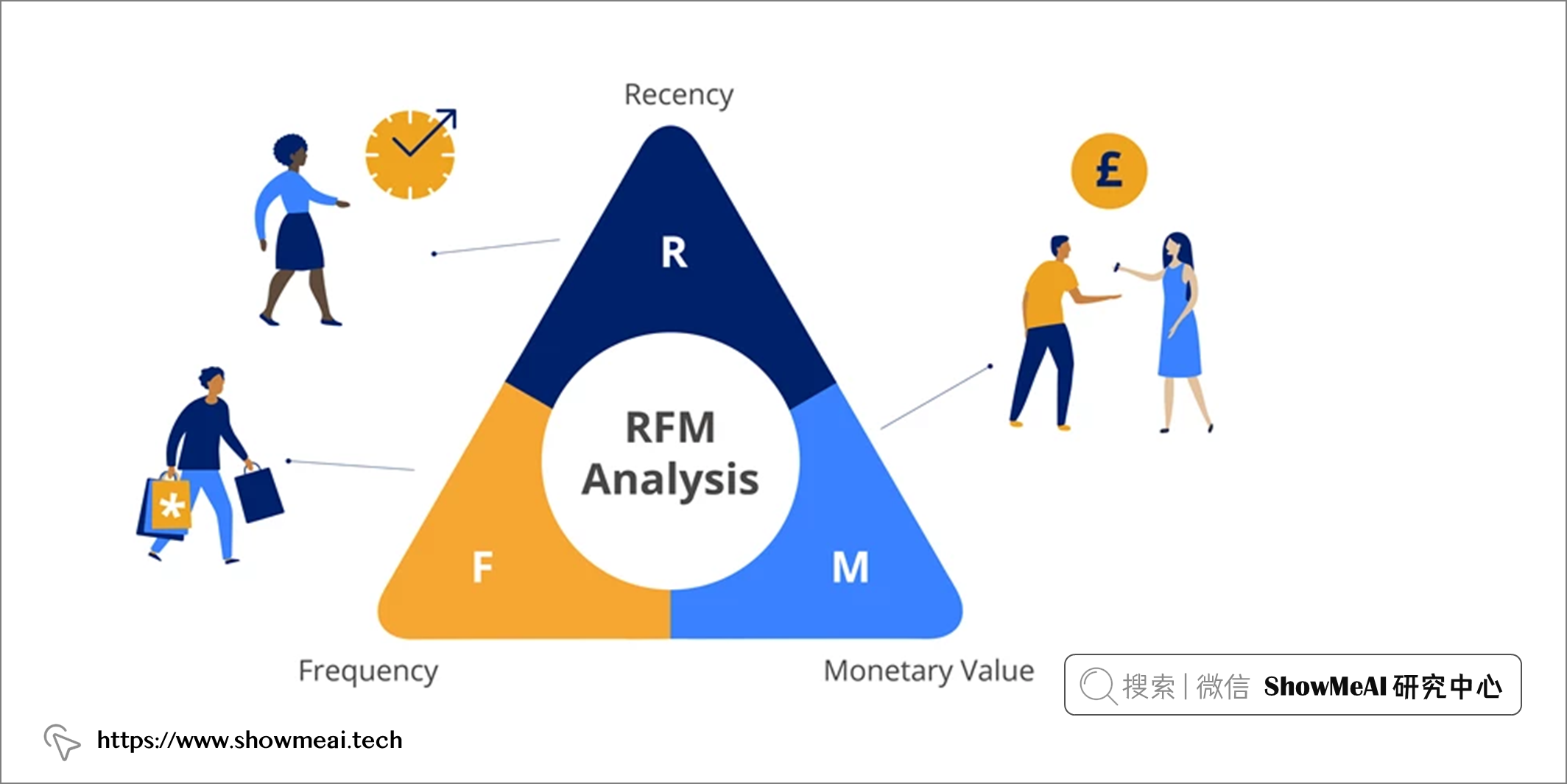
📘RFM 是一种量化客户价值的方法,英文全称为『Recency, Frequency and Monetary value』。RFM 模型的三个参数分别是 R(最近一次消费的时间间隔)、F(消费的频率)和 M(消费金额)。
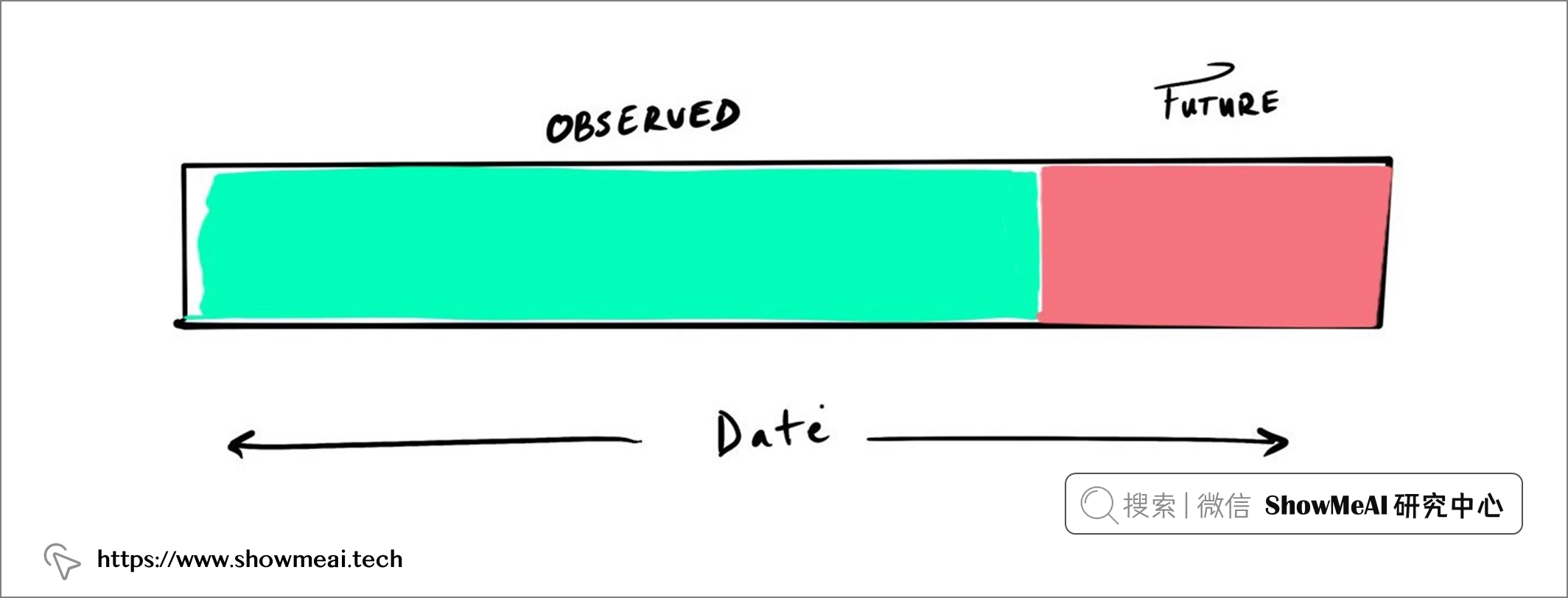
RFM的使用方法是,将训练数据分成观察期 Observed 和未来期 Future。 如果我们要预测客户一年内会花费多少,就将未来期 Future的长度设置为一年。如下图所示:
基于观察期的数据特征建模,并预测未来期的情况,下述代码我们基于日期进行截断:
# 截断日期前的数据 observed = df[df[date_col] < cut_off # 截断日期后的数据 future = df [(df[date_col] > cut_off) & (df[date_col] < cut_off + pd.Timedelta(label_period_days, unit='D'))]
下面我们来看看 RFM 的3要素,并通过代码进行实现:
💦 Recency / 时间间隔
它代表自最近一次交易以来的时间(小时/天/周)。 我们需要设置一个基准时间点来计算 Recency。 我们会计算客户在基准时间点后多少天进行了交易。
def customer_recency(data, cut_off, date_column, customer_id_column): # 截断前的数据 recency = data[data[date_column] < cut_off].copy() recency[date_column] = pd.to_datetime(recency[date_column]) # 按最新交易对客户进行分组 recency = recency.groupby(customer_id_column)[date_column].max() return ((pd.to_datetime(cut_off) - recency).dt.days).reset_index().rename( columns={date_column : 'recency'} )
💦 Frequency / 频率
它代表客户进行交易的不同时间段的数量。 这将使我们能够跟踪客户进行了多少交易以及交易发生的时间。 我们还可以保留从截止日期开始计算这些指标的做法,因为以后会很方便。
def customer_frequency(data, cut_off, date_column, customer_id_column, value_column, freq='M'): # 截断前的数据 frequency = data[data[date_column] < cut_off].copy() # 设置日期列为索引 frequency.set_index(date_column, inplace=True) frequency.index = pd.DatetimeIndex(frequency.index) # 按客户键和不同时期对交易进行分组 # 并统计每个时期的交易 frequency = frequency.groupby([ customer_id_column, pd.Grouper(freq=freq, level=date_column) ]).count() frequency[value_column] = 1 # 存储所有不同的交易 # 统计汇总所有交易 return frequency.groupby(customer_id_column).sum().reset_index().rename( columns={value_column : 'frequency'} )
💦 Monetary value / 消费金额
它代表平均销售额。 在这里我们可以简单计算每个客户所有交易的平均销售额。 (当然,我们后续也会用到)
def customer_value(data, cut_off, date_column, customer_id_column, value_column): value = data[data[date_column] < cut_off] # 设置日期列为索引 value.set_index(date_column, inplace=True) value.index = pd.DatetimeIndex(value.index) # 获取每个客户的平均或总销售额 return value.groupby(customer_id_column)[value_column].mean().reset_index().rename( columns={value_column : 'value'} )
💦 附加信息
用户龄: 自第一次交易以来的时间。我们把每个客户首次交易以来的天数也加到信息中。
def customer_age(data, cut_off, date_column, customer_id_column): age = data[data[date_column] < cut_off] # 获取第一笔交易的日期 first_purchase = age.groupby(customer_id_column)[date_column].min().reset_index() # 获取截止到第一次交易之间的天数 first_purchase['age'] = (cut_off - first_purchase[date_column]).dt.days return first_purchase[[customer_id_column, 'age']]
最后我们定义一个函数把 RFM 涉及到的信息囊括进去:
def customer_rfm(data, cut_off, date_column, customer_id_column, value_column, freq='M'): cut_off = pd.to_datetime(cut_off) # 计算 recency = customer_recency(data, cut_off, date_column, customer_id_column) # 计算频率 frequency = customer_frequency(data, cut_off, date_column, customer_id_column, value_column, freq=freq) # 计算平均值 value = customer_value(data, cut_off, date_column, customer_id_column, value_column) # 计算年龄 age = customer_age(data, cut_off, date_column, customer_id_column) # 合并所有列 return recency.merge(frequency, on=customer_id_column).merge(on=customer_id_column).merge(age,on=customer_id_column)
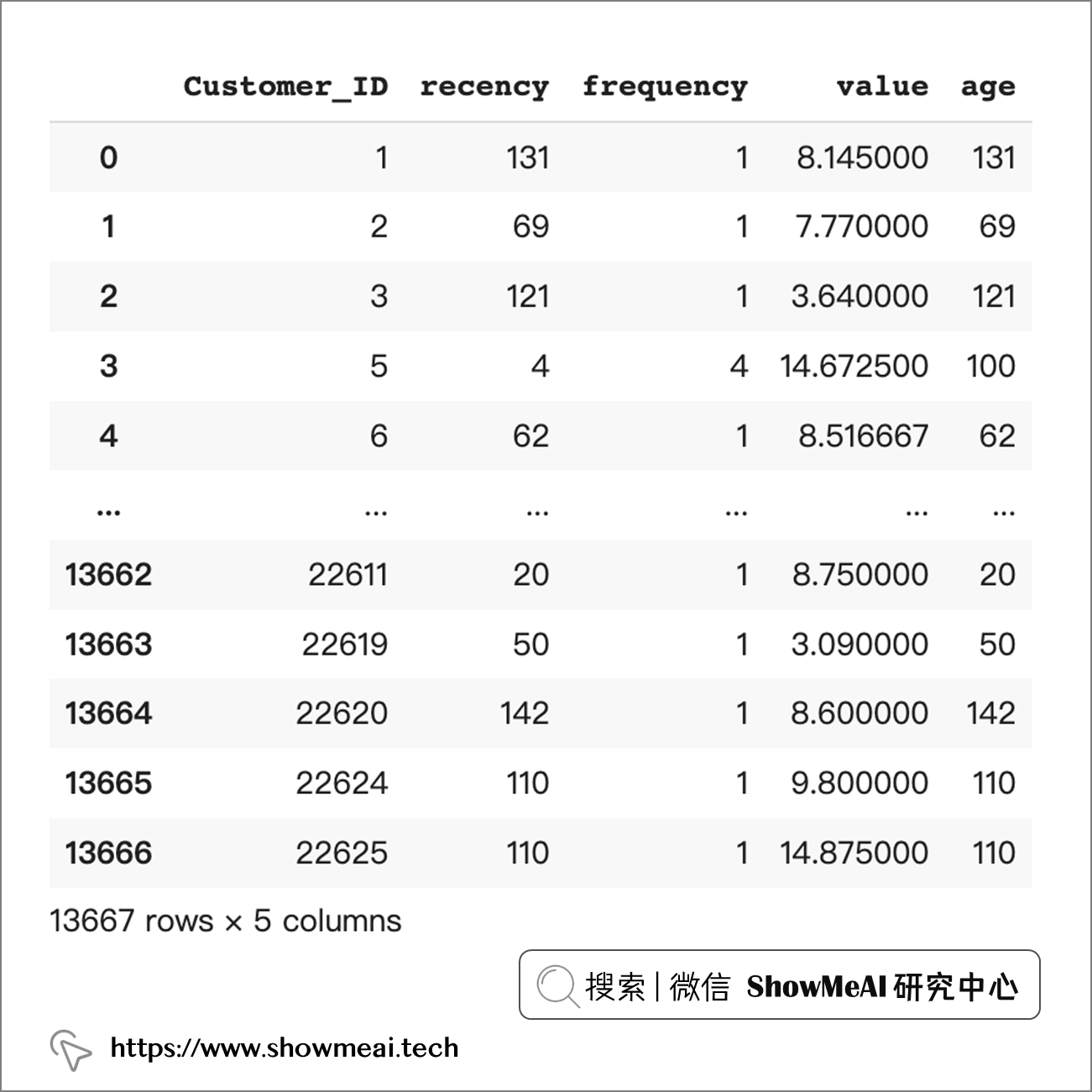
理想情况下,这可以捕获特定时间段内的信息,看起来像下面这样:
我们把每个客户未来期间花费的金额作为标签(即我们截断数据的后面一部分,即future)。
labels = future.groupby(id_col)[value_col].sum()
💡 建模思路 & 实现
通过上面的方式我们就构建出了数据样本,但每个用户只有1个样本,如果我们希望有更多的数据样本,以及在样本中囊括不同的情况(例如时间段覆盖节假日和 618 和 11.11 等特殊促销活动),我们需要使用到『递归RFM』方法。
💦 递归 RFM
所谓的递归 RFM 相当于以滑动窗口的方式来把未来不同的时间段构建为 future 标签,如下图所示。假设数据从年初(最左侧)开始,我们选择一个频率(例如,一个月)遍历数据集构建未来 (f) 标签,也即下图的红色 f 块。
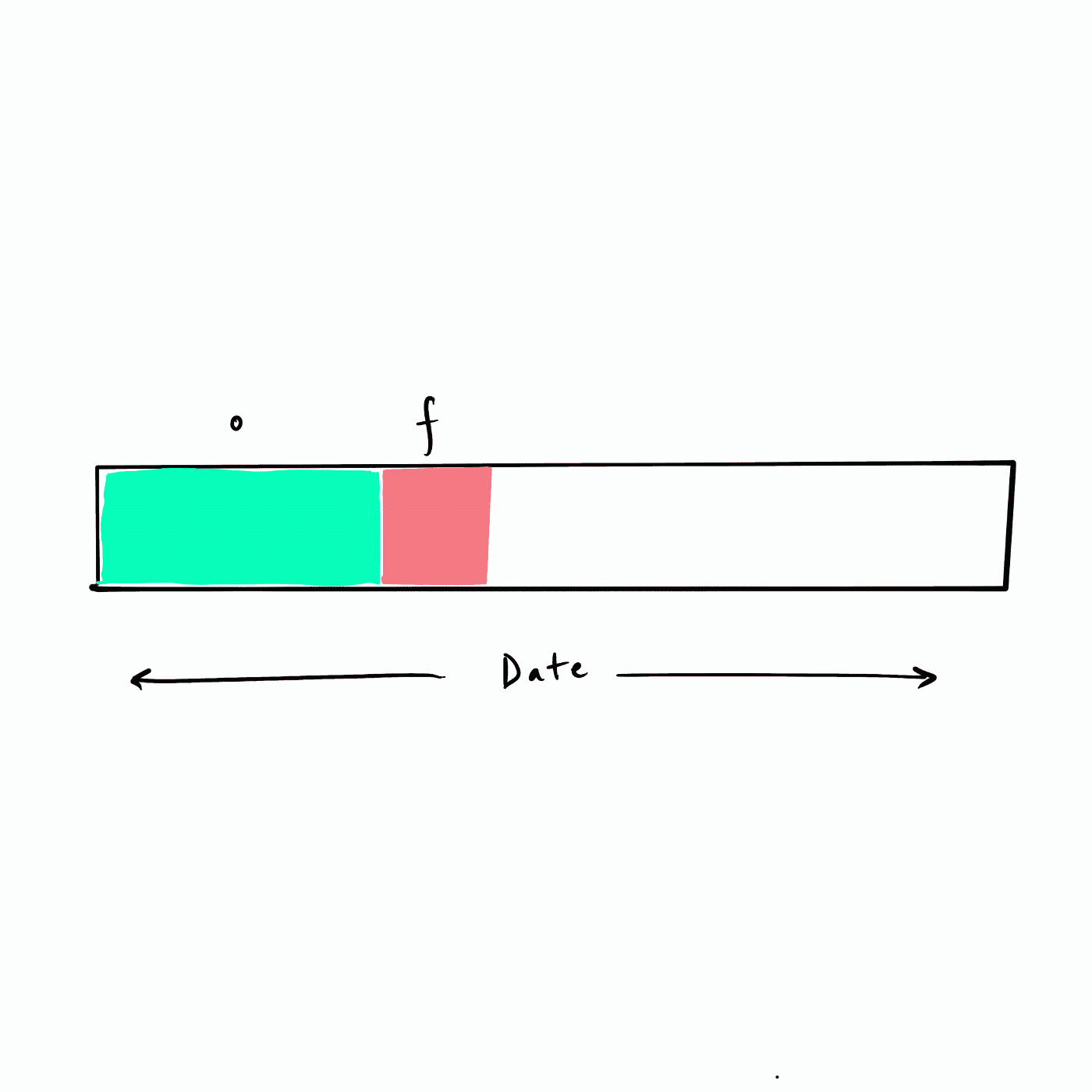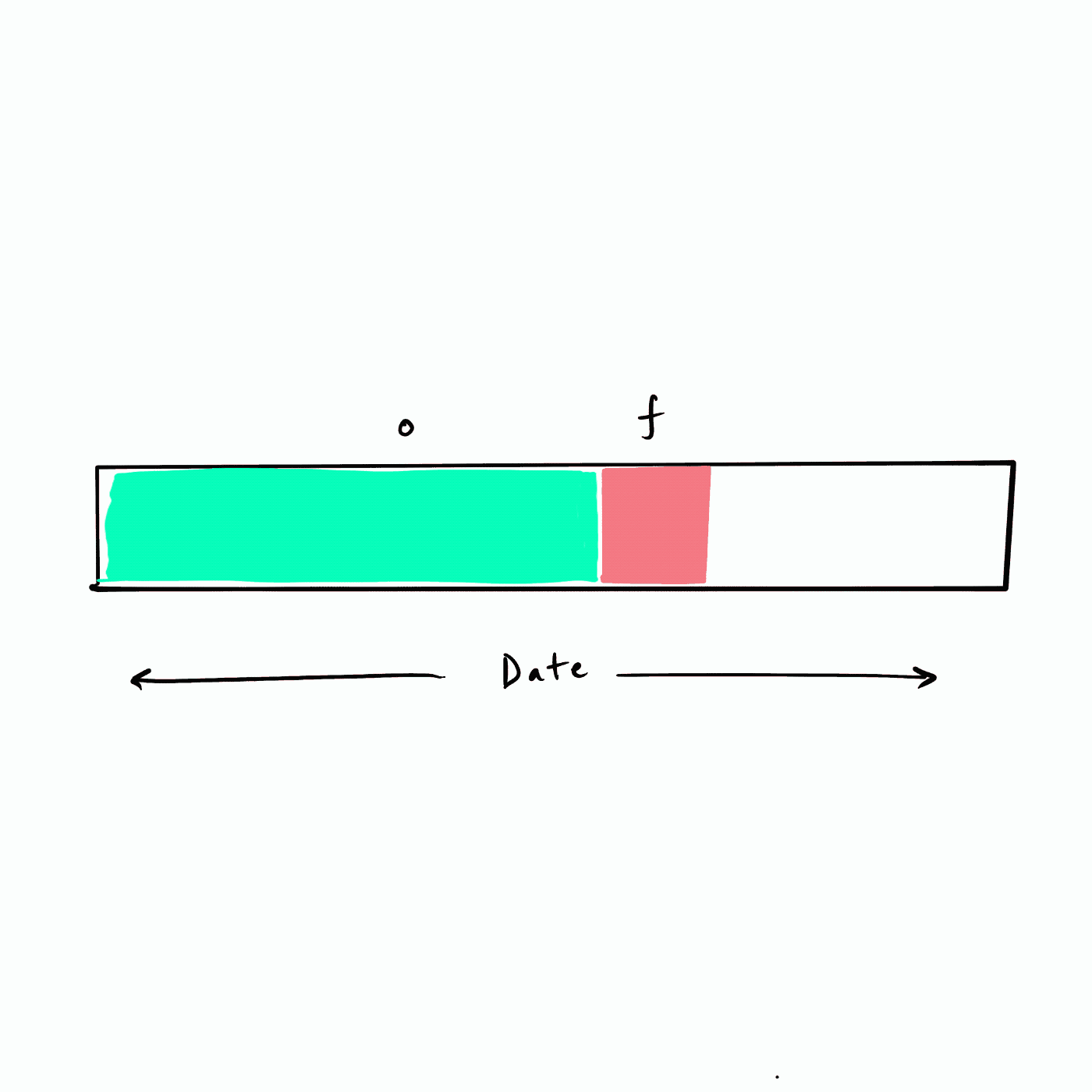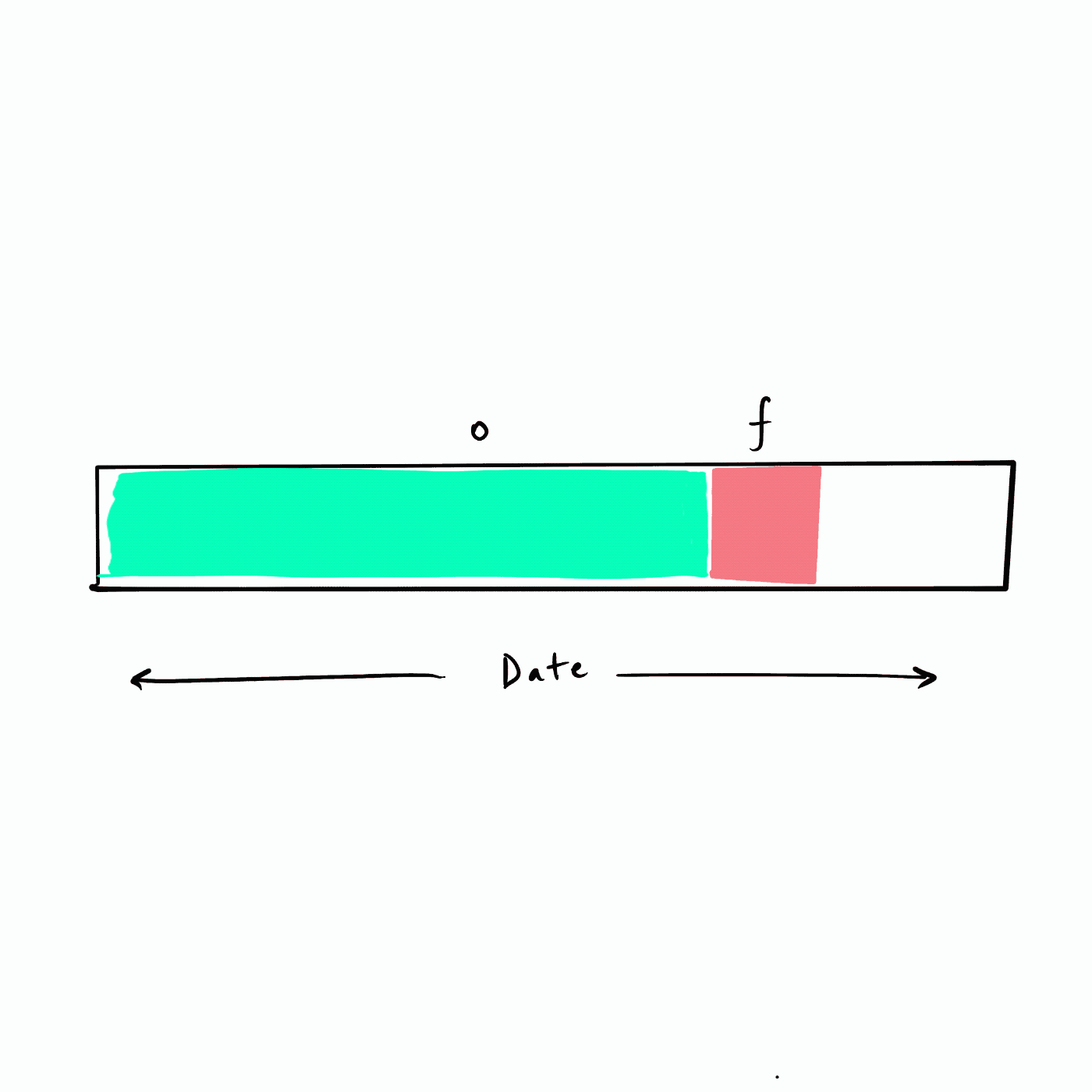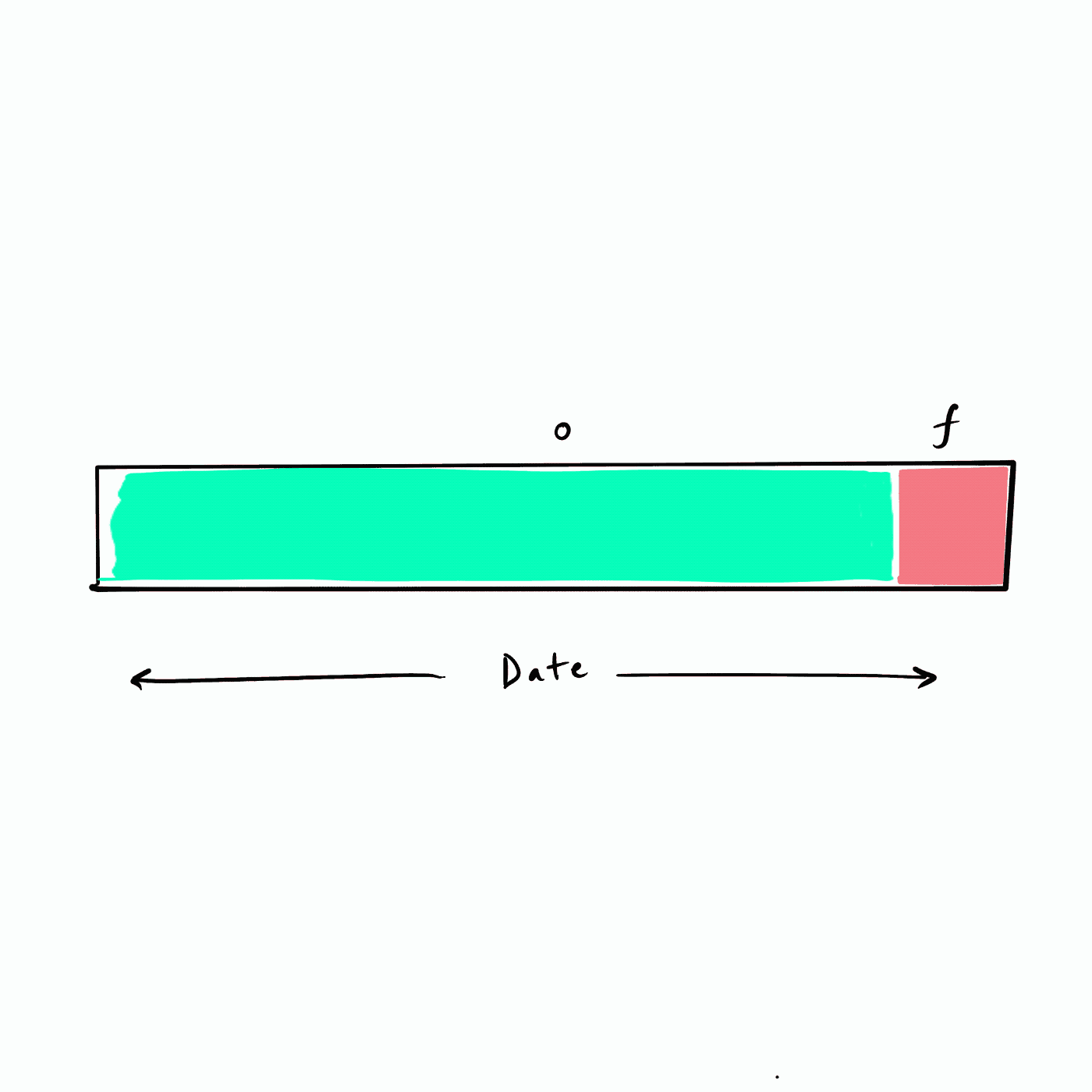 |
具体的实现代码如下:
def recursive_rfm(data, date_col, id_col, value_col, freq='M', start_length=30, label_period_days=30): dset_list = [] # 获取数据集的起始时间 start_date = data[date_col].min() + pd.Timedelta(start_length, unit="D") end_date = data[date_col].max() - pd.Timedelta(label_period_days, unit="D") # 获取时间段 dates = pd.date_range(start=start_date, end=end_date, freq=freq) data[date_col] = pd.to_datetime(data[date_col]) for cut_off in dates: # 切分 observed = data[data[date_col] < cut_off] future = data[ (data[date_col] > cut_off) & (data[date_col] < cut_off + pd.Timedelta(label_period_days, unit='D')) ] rfm_columns = [date_col, id_col, value_col] print(f"computing rfm features for {cut_off} to {future[date_col].max()}:") _observed = observed[rfm_columns] # 计算训练数据特征部分(即observed部分) rfm_features = customer_rfm(_observed, cut_off, date_col, id_col, value_col) # 计算标签(即future的总消费) labels = future.groupby(id_col)[value_col].sum() # 合并数据 dset = rfm_features.merge(labels, on=id_col, how='outer').fillna(0) dset_list.append(dset) # 完整数据 full_dataset = pd.concat(dset_list, axis=0) res = full_dataset[full_dataset.recency != 0].dropna(axis=1, how='any') return res rec_df = recursive_rfm(data_for_rfm, 'Date', 'Customer_ID', 'Sales_Amount')
接下来我们进行数据切分,以便更好地进行建模和评估,这里依旧把数据切分为 80% 用于训练,20% 用于测试。
from sklearn.model_selection import train_test_split # 数据采样,如果大家本地计算资源少,可以设置百分比进行采样 rec_df = rec_df.sample(frac=1) # 确定特征与标签 X = rec_df[['recency', 'frequency', 'value', 'age']] y = rec_df[['Sales_Amount']].values.reshape(-1) # 数据集切分 test_size = 0.2 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=42, shuffle=True)
💦 机器学习建模
关于机器学习建模部分,大家可以参考 ShowMeAI 的机器学习系列教程与模型评估基础知识文章。
有很多机器学习模型都可以进行建模,在本例中我们使用最常用且效果良好的随机森林进行建模,因为是回归任务,我们直接使用 scikit-learn 中的随机森林回归器,代码如下。
from sklearn.ensemble import RandomForestRegressor # 在训练数据集上初始化和拟合模型 rf = RandomForestRegressor().fit(X_train, y_train)
拟合后,我们可以在数据框中查看我们对测试集的预测。
from sklearn.metrics import mean_squared_error # 训练集:标准答案与预估值 predictions = pd.DataFrame() predictions['true'] = y_train predictions['preds'] = rf.predict(X_train) # 测试集:标准答案与预估值 predictions_test = pd.DataFrame() predictions_test['true'] = y_test predictions_test['preds'] = rf.predict(X_test) # 模型评估 train_rmse = mean_squared_error(predictions.true, predictions.preds)**0.5 test_rmse = mean_squared_error(predictions_test.true, predictions_test.preds)**0.5 print(f"Train RMSE: {train_rmse}, Test RMSE: {test_rmse}")
输出:
Train RMSE :10.608368028113563, Test RMSE :28.366171873961612
这里我们使用的均方根误差 (RMSE) 作为评估准则,它计算的是训练数据和测试数据上『标准答案』和『预估值』的偏差平方和与样本数 N 比值的平方根。 即如下公式:

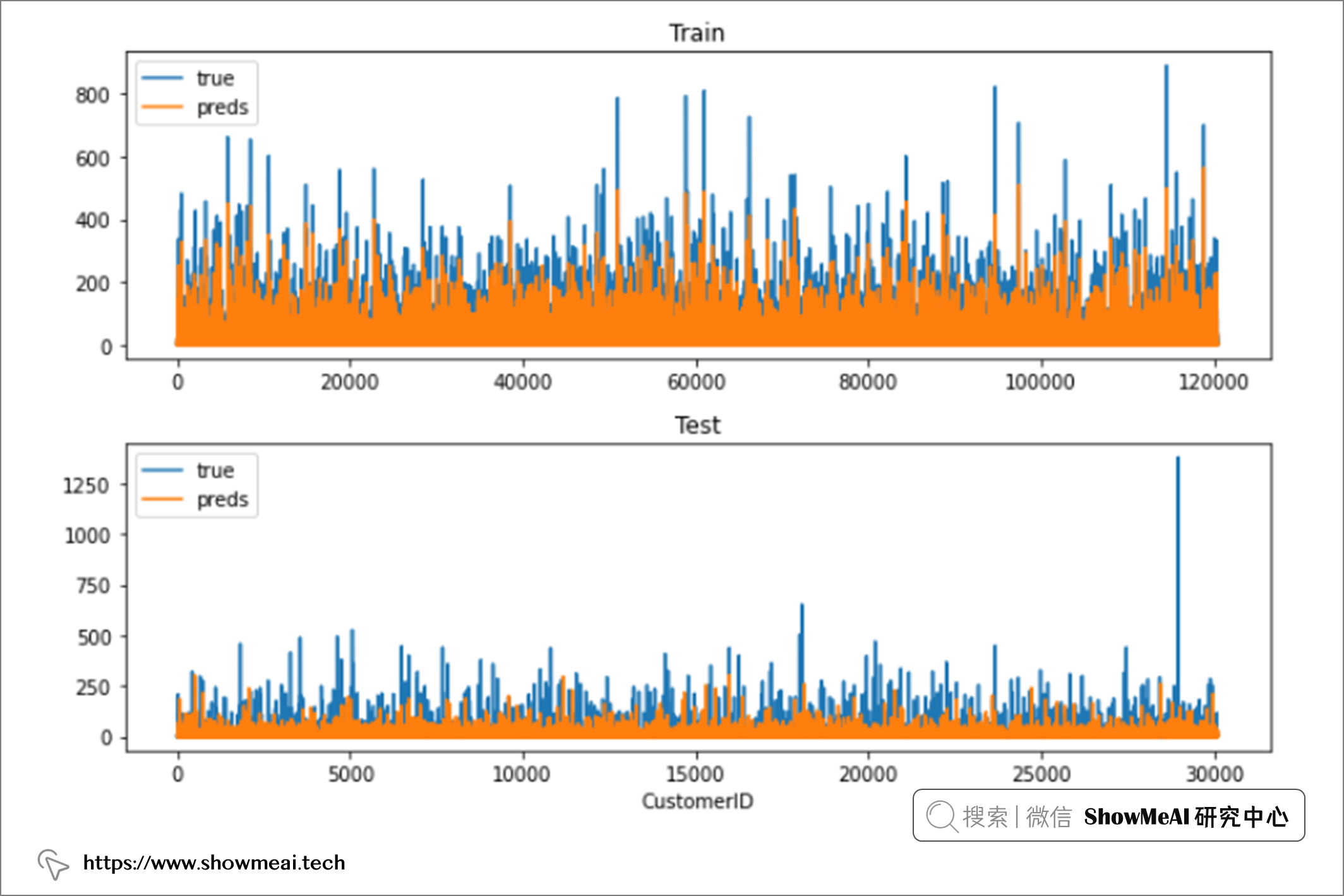
机器学中的过拟合问题,可以通过对模型的调参进行优化,比如在随机森林模型中,可能是因为树深太深,叶子节点样本数设置较小等原因导致,大家可以通过调参方法(如网格搜索、随机搜索、贝叶斯优化)等进行优化。可以在 ShowMeAI的过往机器学习实战文章中找到调参模板:
参考资料
- 📘 数据科学工具库速查表 | Pandas 速查表:https://www.showmeai.tech/article-detail/101
- 📘 图解数据分析:从入门到精通系列教程:https://www.showmeai.tech/tutorials/33
- 📘 图解机器学习算法:从入门到精通系列教程:https://www.showmeai.tech/tutorials/34
- 📘 图解机器学习算法| 模型评估方法与准则:https://www.showmeai.tech/article-detail/186
- 📘 图解机器学习算法 | 随机森林模型详解:https://www.showmeai.tech/article-detail/191
- 📘 机器学习实战 | 机器学习特征工程最全解读:https://www.showmeai.tech/article-detail/208
- 📘 人力资源流失场景机器学习建模与调优:https://www.showmeai.tech/article-detail/308
- 📘 基于Airbnb数据的民宿房价预测模型:https://www.showmeai.tech/article-detail/316


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人