

2022年Python顶级自动化特征工程框架⛵
 特征工程一般是手动完成,不仅依赖于工程师的丰富经验,也非常耗时。因此『自动化特征工程』可以自动生成大量候选特征,帮助数据科学家显著提升了工作效率和模型效果。
特征工程一般是手动完成,不仅依赖于工程师的丰富经验,也非常耗时。因此『自动化特征工程』可以自动生成大量候选特征,帮助数据科学家显著提升了工作效率和模型效果。

💡 作者:韩信子@ShowMeAI
📘 机器学习实战系列:https://www.showmeai.tech/tutorials/41
📘 本文地址:https://www.showmeai.tech/article-detail/328
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏ShowMeAI查看更多精彩内容

特征工程(feature engineering)指的是:利用领域知识和现有数据,创造出新的特征,用于机器学习算法。
- 特征:数据中抽取出来的对结果预测有用的信息。
- 特征工程:使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
在业界有一个很流行的说法:数据与特征工程决定了模型的上限,改进算法只不过是逼近这个上限而已。
特征工程的目的是提高机器学习模型的整体性能,以及生成最适合用于机器学习的算法的输入数据集。
关于特征工程的各种方法详解,欢迎大家阅读 ShowMeAI 整理的特征工程解读教程。
💡 自动化特征工程
在很多生产项目中,特征工程都是手动完成的,而且它依赖于先验领域知识、直观判断和数据操作。整个过程是非常耗时的,并且场景或数据变换后又需要重新完成整个过程。而『自动化特征工程』希望对数据集处理自动生成大量候选特征来帮助数据科学家和工程师们,可以选择这些特征中最有用的进行进一步加工和训练。
自动化特征工程是很有意义的一项技术,它能使数据科学家将更多时间花在机器学习的其他环节上,从而提高工作效率和效果。

在本篇内容中,ShowMeAI将总结数据科学家在 2022 年必须了解的 Python 中最流行的自动化特征工程框架。
- Feature Tools
- TSFresh
- Featurewiz
- PyCaret
💡 Feature Tools
📌 简介
📘Featuretools是一个用于执行自动化特征工程的开源库。 ShowMeAI在文章 机器学习实战 | 自动化特征工程工具Featuretools应用 中也对它做了介绍。

要了解 Featuretools,我们需要了解以下三个主要部分:
- Entities
- Deep Feature Synthesis (DFS)
- Feature primitives
在 Featuretools 中,我们用 Entity 来囊括原本 Pandas DataFrame 的内容,而 EntitySet 由不同的 Entity 组合而成。
Featuretools 的核心是 Deep Feature Synthesis(DFS) ,它实际上是一种特征工程方法,它能从单个或多个 DataFrame中构建新的特征。
DFS 通过 EntitySet 上指定的 Feature primitives 创建特征。例如,primitives中的mean函数将对变量在聚合时进行均值计算。
📌 使用示例
💦 ① 数据与预处理
以下示例转载自 📘官方快速入门。
# 安装 # pip install featuretools import featuretools as ft data = ft.demo.load_mock_customer() # 载入数据集 customers_df = data["customers"] customers_df
sessions_df = data["sessions"] sessions_df.sample(5)
transactions_df = data["transactions"] transactions_df.sample(5)
下面我们指定一个包含数据集中每个 DataFrame 的字典,如果数据集有索引index列,我们会和 DataFrames 一起传递,如下图所示。
dataframes = { "customers": (customers_df, "customer_id"), "sessions": (sessions_df, "session_id", "session_start"), "transactions": (transactions_df, "transaction_id", "transaction_time"), }
接下来我们定义 DataFrame 之间的连接。在这个例子中,我们有两个关系:
relationships = [ ("sessions", "session_id", "transactions", "session_id"), ("customers", "customer_id", "sessions", "customer_id"), ]
💦 ② 深度特征合成
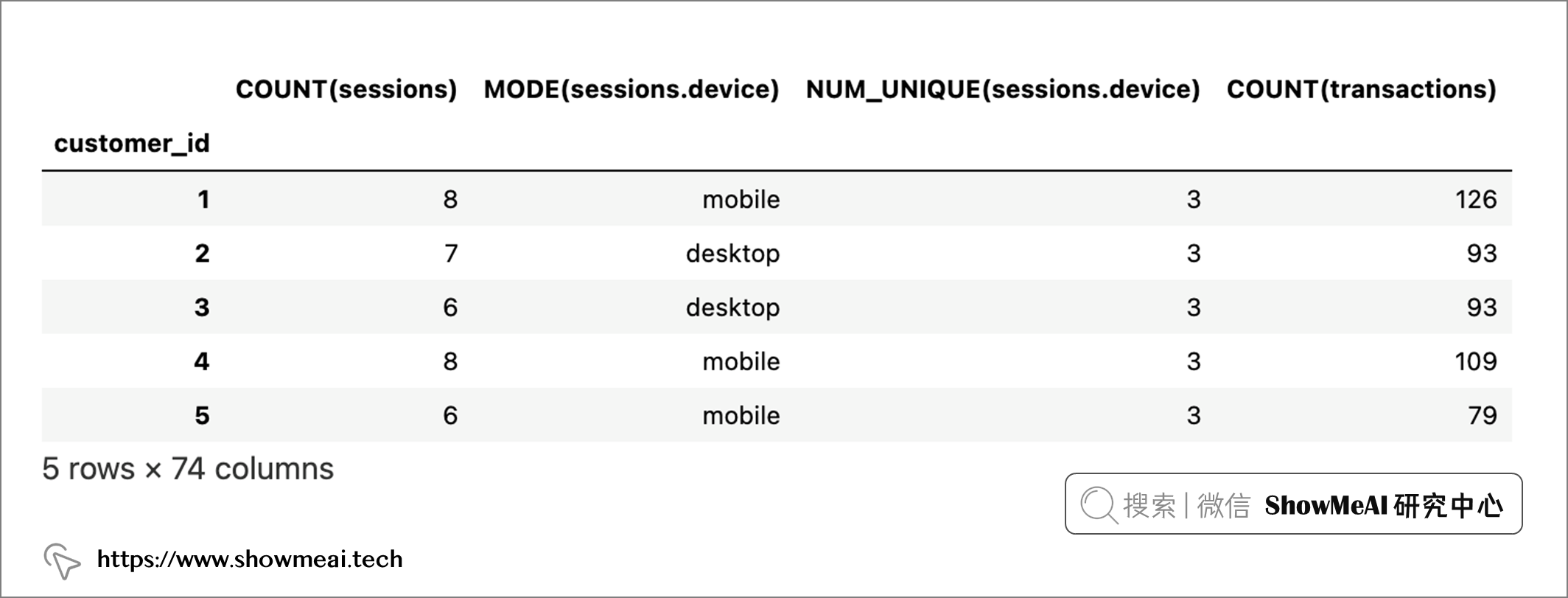
接下来我们可以通过DFS生成特征了,它需要『DataFrame 的字典』、『Dataframe关系列表』和『目标 DataFrame 名称』3个基本输入。
feature_matrix_customers, features_defs = ft.dfs( dataframes=dataframes, relationships=relationships, target_dataframe_name="customers", ) feature_matrix_customers
比如我们也可以以sessions为目标dataframe构建新特征。
feature_matrix_sessions, features_defs = ft.dfs( dataframes=dataframes, relationships=relationships, target_dataframe_name="sessions" ) feature_matrix_sessions.head(5)
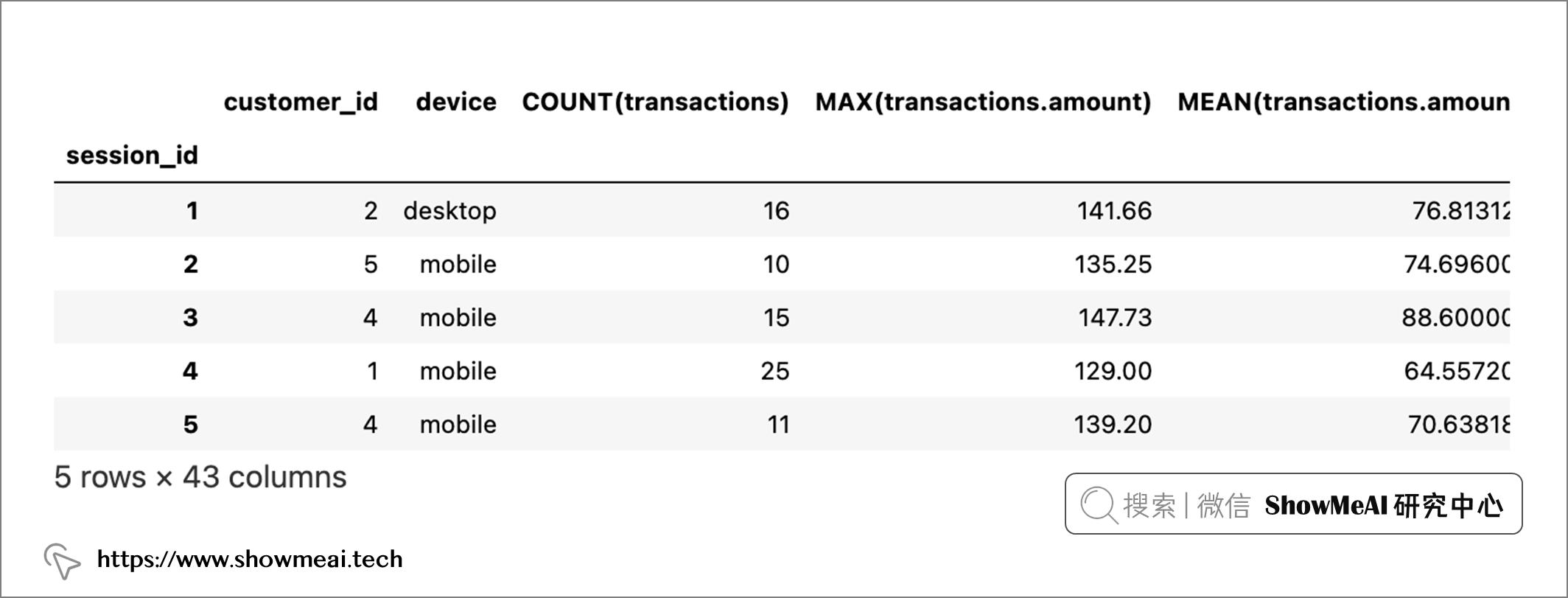
💦 ③ 特征输出
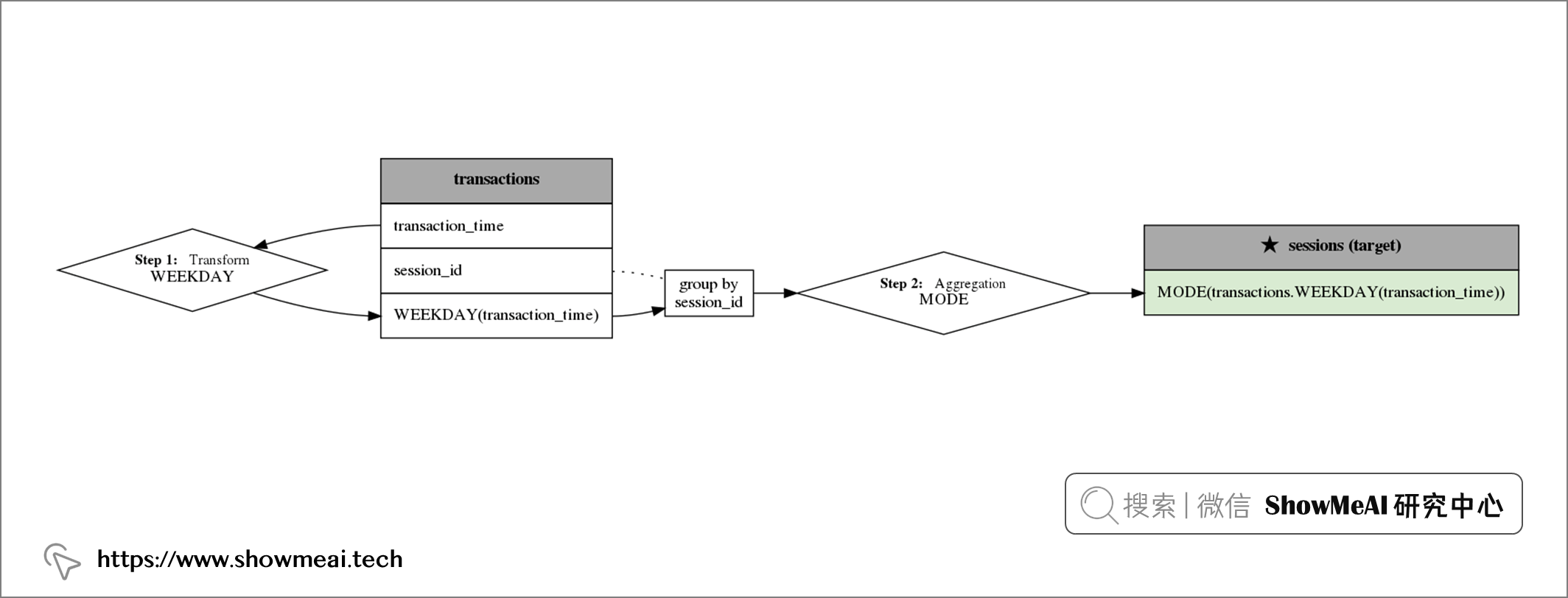
Featuretools不仅可以完成自动化特征生成,它还可以对生成的特征可视化,并说明Featuretools 生成它的方法。
feature = features_defs[18] feature
💡 TSFresh
📌 简介
📘TSFresh 是一个开源 Python 工具库,有着强大的时间序列数据特征抽取功能,它应用统计学、时间序列分析、信号处理和非线性动力学的典型算法与可靠的特征选择方法,完成时间序列特征提取。

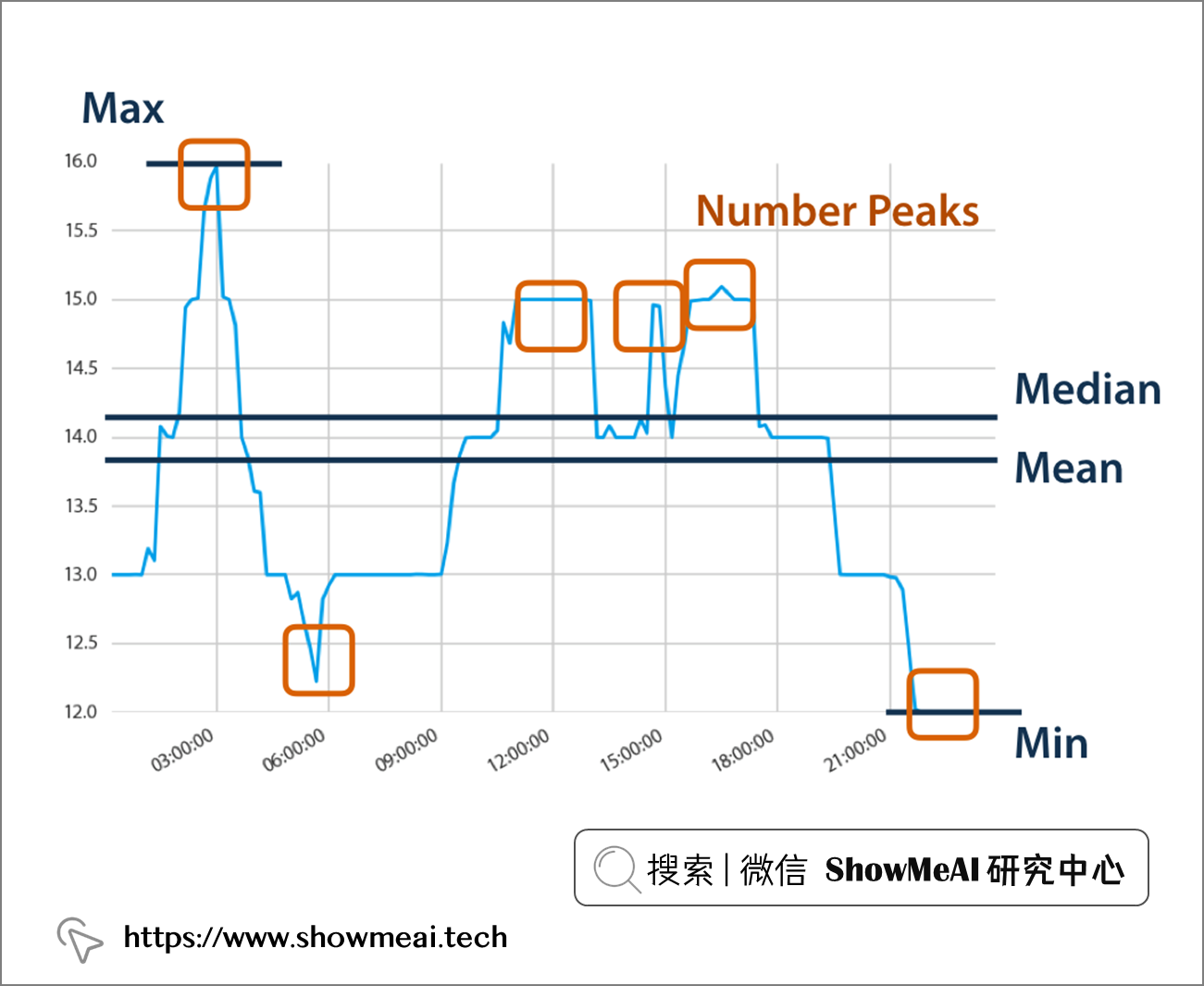
TSFresh 自动从时间序列中提取 100 个特征。 这些特征描述了时间序列的基本特征,例如峰值数量、平均值或最大值或更复杂的特征,例如时间反转对称统计量。
📌 使用示例
# 安装 # pip install tsfresh # 数据下载 from tsfresh.examples.robot_execution_failures import download_robot_execution_failures, load_robot_execution_failures download_robot_execution_failures() timeseries, y = load_robot_execution_failures() # 特征抽取 from tsfresh import extract_features extracted_features = extract_features(timeseries, column_id="id", column_sort="time")
💡 Featurewiz
📌 简介
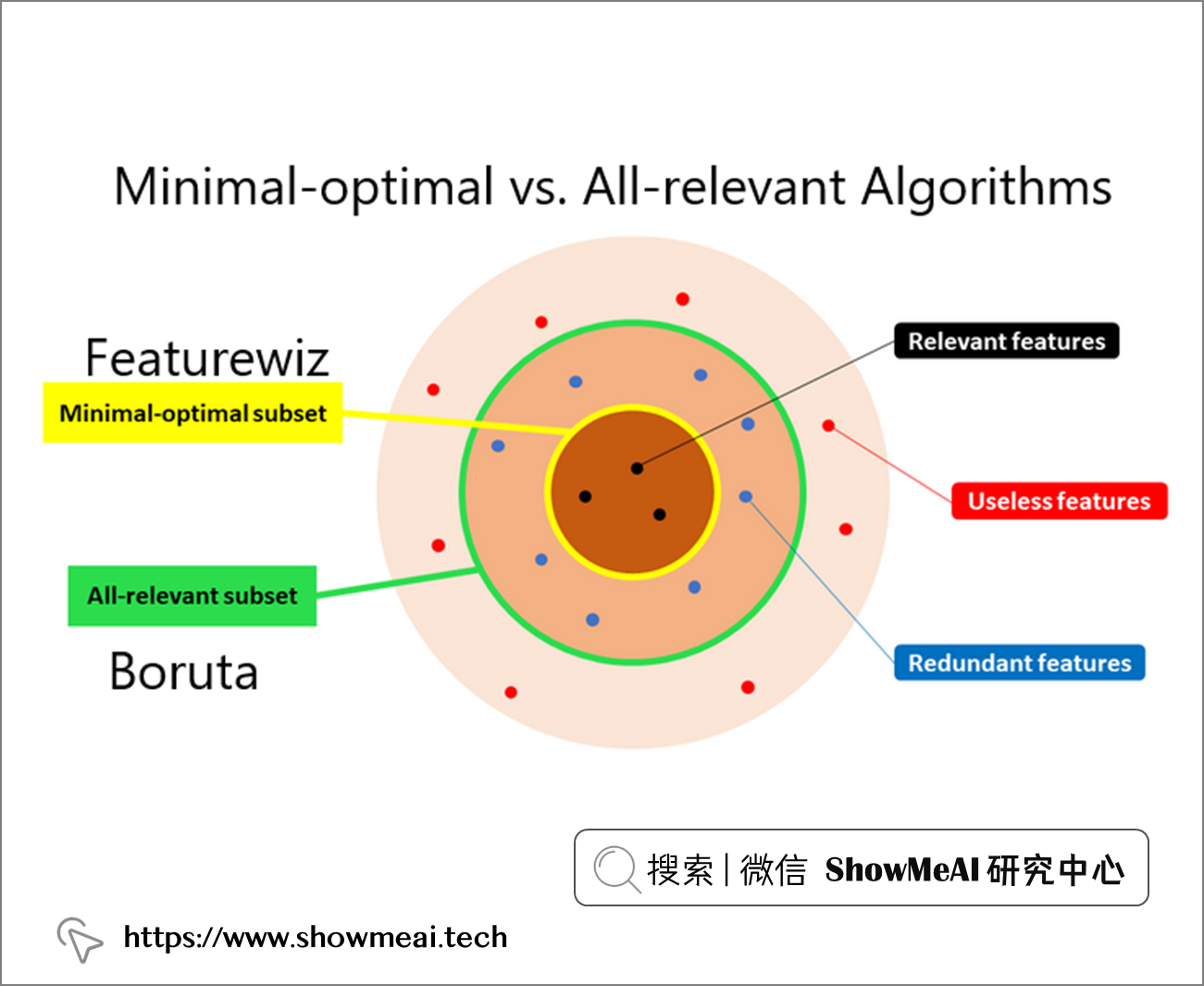
Featurewiz 是另外一个非常强大的自动化特征工程工具库,它结合两种不同的技术,共同帮助找出最佳特性:

💦 ① SULOV
Searching for the uncorrelated list of variables:这个方法会搜索不相关的变量列表来识别有效的变量对,它考虑具有最低相关性和最大 MIS(互信息分数)评级的变量对并进一步处理。
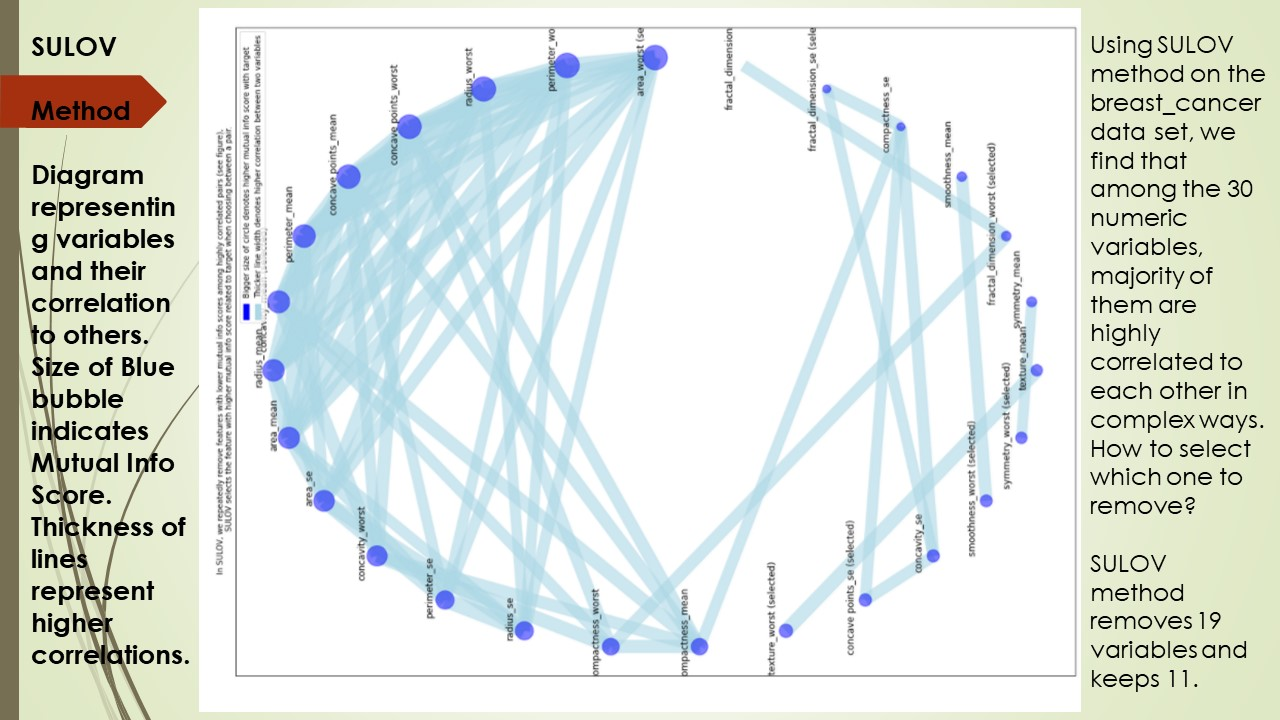
💦 ② 递归 XGBoost
上一步SULOV中识别的变量递归地传递给 XGBoost,通过xgboost选择和目标列最相关的特征,并组合它们,作为新的特征加入,不断迭代这个过程,直到生成所有有效特征。

📌 使用示例
简单的使用方法示例代码如下:
from featurewiz import FeatureWiz features = FeatureWiz(corr_limit=0.70, feature_engg='', category_encoders='', dask_xgboost_flag=False, nrows=None, verbose=2) X_train_selected = features.fit_transform(X_train, y_train) X_test_selected = features.transform(X_test) features.features # 选出的特征列表 # # 自动化特征工程构建特征 import featurewiz as FW outputs = FW.featurewiz(dataname=train, target=target, corr_limit=0.70, verbose=2, sep=',', header=0, test_data='',feature_engg='', category_encoders='', dask_xgboost_flag=False, nrows=None)
💡 PyCaret
📌 简介
📘PyCaret是 Python 中的一个开源、低代码机器学习库,可自动执行机器学习工作流。它是一个端到端的机器学习和模型管理工具,可加快实验周期并提高工作效率。

与本文中的其他框架不同,PyCaret 不是一个专用的自动化特征工程库,但它包含自动生成特征的功能。
📌 使用示例
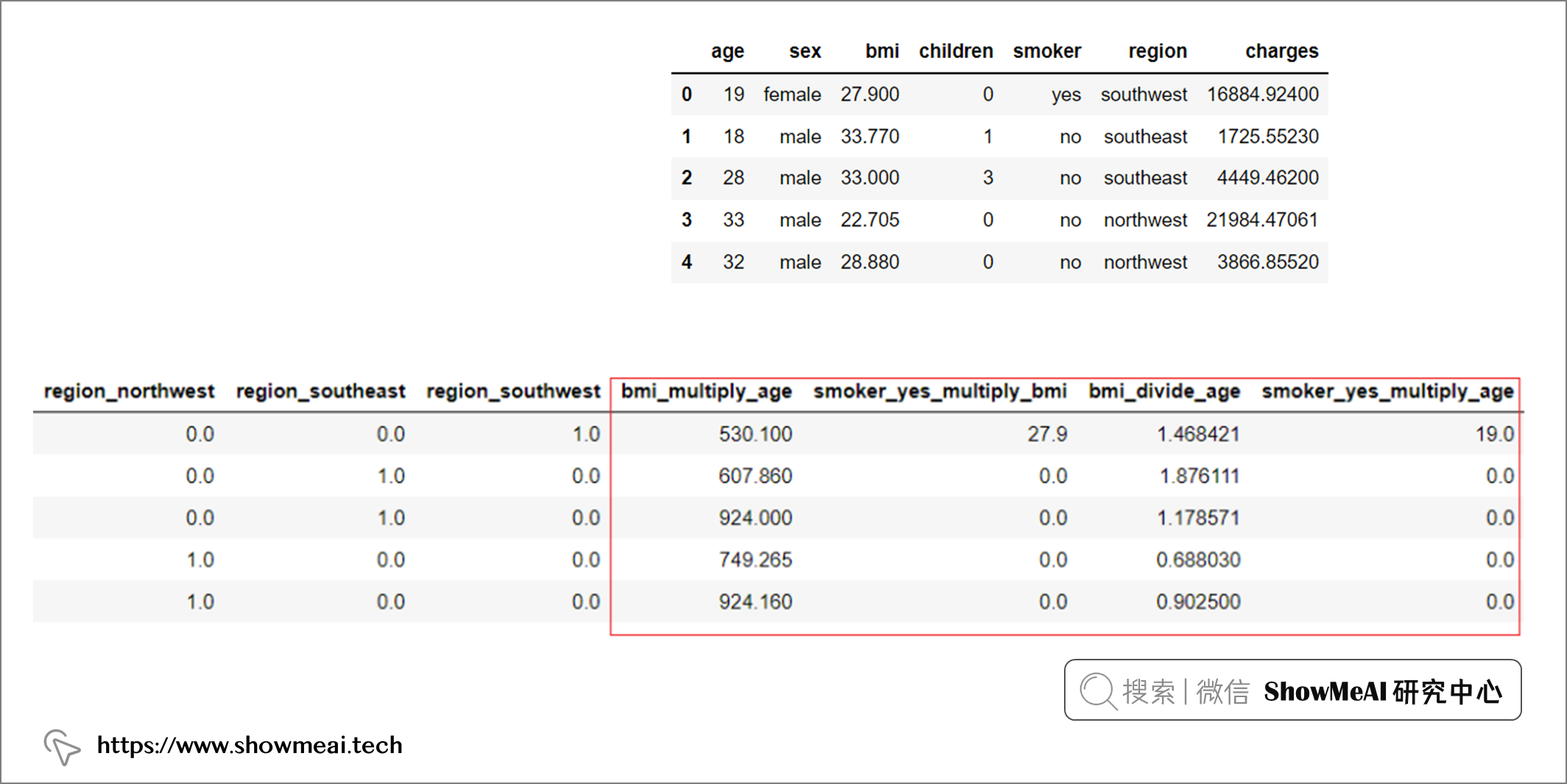
# 安装 # pip install pycaret # 加载数据 from pycaret.datasets import get_data insurance = get_data('insurance') # 初始化设置 from pycaret.regression import * reg1 = setup(data = insurance, target = 'charges', feature_interaction = True, feature_ratio = True)
参考资料
- 📘 机器学习实战 | 机器学习特征工程全面解读:https://www.showmeai.tech/article-detail/208
- 📘 Featuretools:https://featuretools.alteryx.com/en/stable/
- 📘 机器学习实战 | 自动化特征工程工具Featuretools应用:https://www.showmeai.tech/article-detail/209
- 📘 官方快速入门:https://featuretools.alteryx.com/en/stable/
- 📘 TSFresh:https://github.com/blue-yonder/tsfresh
- 📘 Featurewiz:https://github.com/AutoViML/featurewiz
- 📘 PyCaret:http://pycaret.org


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具