精准营销!用机器学习完成客户分群!⛵
 客户分群对于精准营销的意义重大,而机器学习可以优化这一过程。本文会详细拆解实现过程:数据收集、创建RFM表、探索数据&数据变换、应用聚类做用户分群、解释结果。
客户分群对于精准营销的意义重大,而机器学习可以优化这一过程。本文会详细拆解实现过程:数据收集、创建RFM表、探索数据&数据变换、应用聚类做用户分群、解释结果。

💡 作者:韩信子@ShowMeAI
📘 数据分析实战系列:https://www.showmeai.tech/tutorials/40
📘 机器学习实战系列:https://www.showmeai.tech/tutorials/41
📘 本文地址:https://www.showmeai.tech/article-detail/325
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏ShowMeAI查看更多精彩内容

我们总会听到很多公司的技术人员在做用户画像的工作,细分客户/客户分群是一个很有意义的工作,可以确保企业构建更个性化的消费者针对策略,同时优化产品和服务。
在机器学习的角度看,客户分群通常会采用无监督学习的算法完成。应用这些方法,我们会先收集整理客户的基本信息,例如地区、性别、年龄、偏好 等,再对其进行分群。
在本篇内容中,ShowMeAI将用一个案例讲解基于客户信息做用户分群的方法实现。
💡 核心步骤

整个客户分群的过程包含一些核心的步骤:
- 数据收集
- 创建RFM表
- 探索数据&数据变换
- 应用聚类做用户分群
- 解释结果
💡 数据收集

下列数据操作处理与分析涉及的工具和技能,欢迎大家查阅ShowMeAI对应的教程和工具速查表,快学快用。
我们需要先结合业务场景收集数据,我们在本案例中使用的是 🏆Online_Retail在线零售数据集,大家可以在ShowMeAI的百度网盘中下载获取数据。

本份数据对应的是在线零售业务的交易数据,包含英国在线零售从 2010 年 12 月 1 日到 2011 年 12 月 9 日的交易。核心字段包括产品名称、数量、价格和其他表示 ID 的列。数据集包含 541909 条数据记录。
🏆 实战数据集下载(百度网盘):公众号『ShowMeAI研究中心』回复『实战』,或者点击 这里 获取本文 [24]基于机器学习的用户价值数据挖掘与客户分群 『Online_Retail 在线零售数据集』
⭐ ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub
为了快速演示客户分群过程,我们不使用全部数据,我们从数据中采样出 10000 条演示整个过程,对应的数据读取与采样代码如下:
# 导入工具库
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 读取数据
df = pd.read_excel('Online_Retail.xlsx')
df = df[df['CustomerID'].notna()]
# 数据采样
df_fix = df.sample(10000, random_state = 42)
采样出来的数据如下
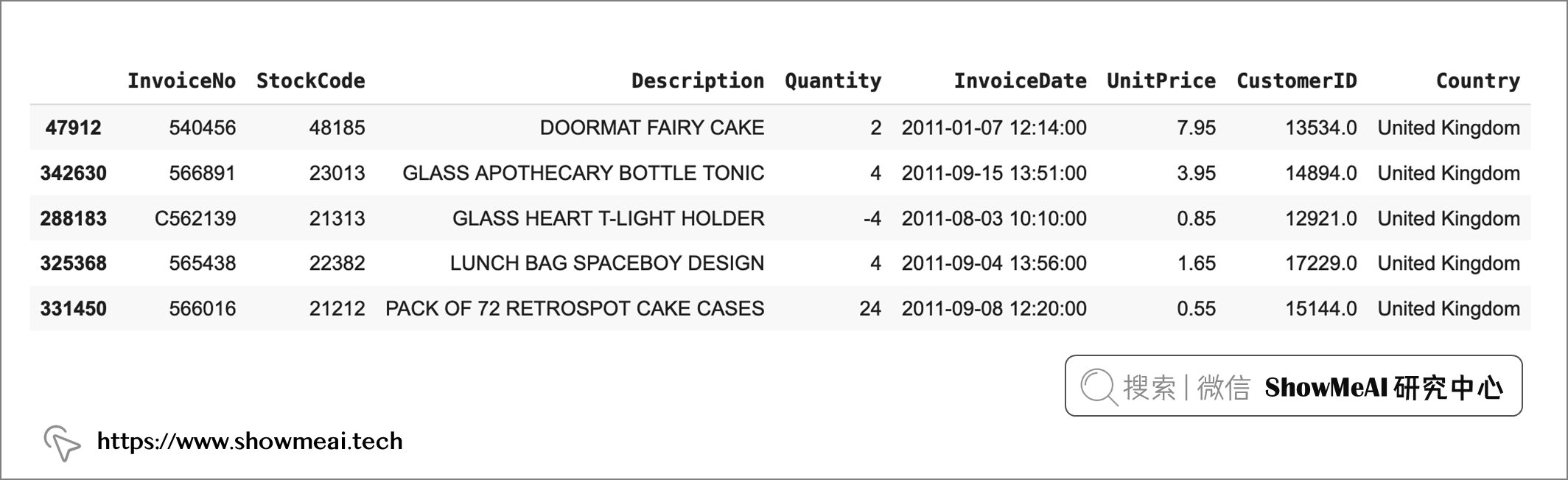
💡 创建 RFM 表
数据准备好之后,为了细分客户,我们会对数据做处理,拿到一些核心指标,比如客户上次购买产品的时间,客户购买产品的频率以及客户为产品支付的费用。

也就是我们说的制作 RFM 表的过程,我们创建对应的字段,包括 Recency(最近一次消费)、Frequency(消费频率)和 Monetary Value(消费金额列),它们的构建方式分别如下:
- 可以用事务发生的日期减去快照日期,来代表最近消费时间点。
- 可以计算每个客户的交易量,作为频度信息。
- 可以汇总每个客户的所有交易金额,作为消费金额列。
处理过程的代码如下:
# 只保留日期
from datetime import datetime
df_fix["InvoiceDate"] = df_fix["InvoiceDate"].dt.date
# 总金额
df_fix["TotalSum"] = df_fix["Quantity"] * df_fix["UnitPrice"]
# 最近消费时间点快照
import datetime
snapshot_date = max(df_fix.InvoiceDate) + datetime.timedelta(days=1)
# 统计聚合
customers = df_fix.groupby(['CustomerID']).agg({
'InvoiceDate': lambda x: (snapshot_date - x.max()).days,
'InvoiceNo': 'count',
'TotalSum': 'sum'})
# 重命名字段
customers.rename(columns = {'InvoiceDate': 'Recency',
'InvoiceNo': 'Frequency',
'TotalSum': 'MonetaryValue'}, inplace=True)
得到结果如下
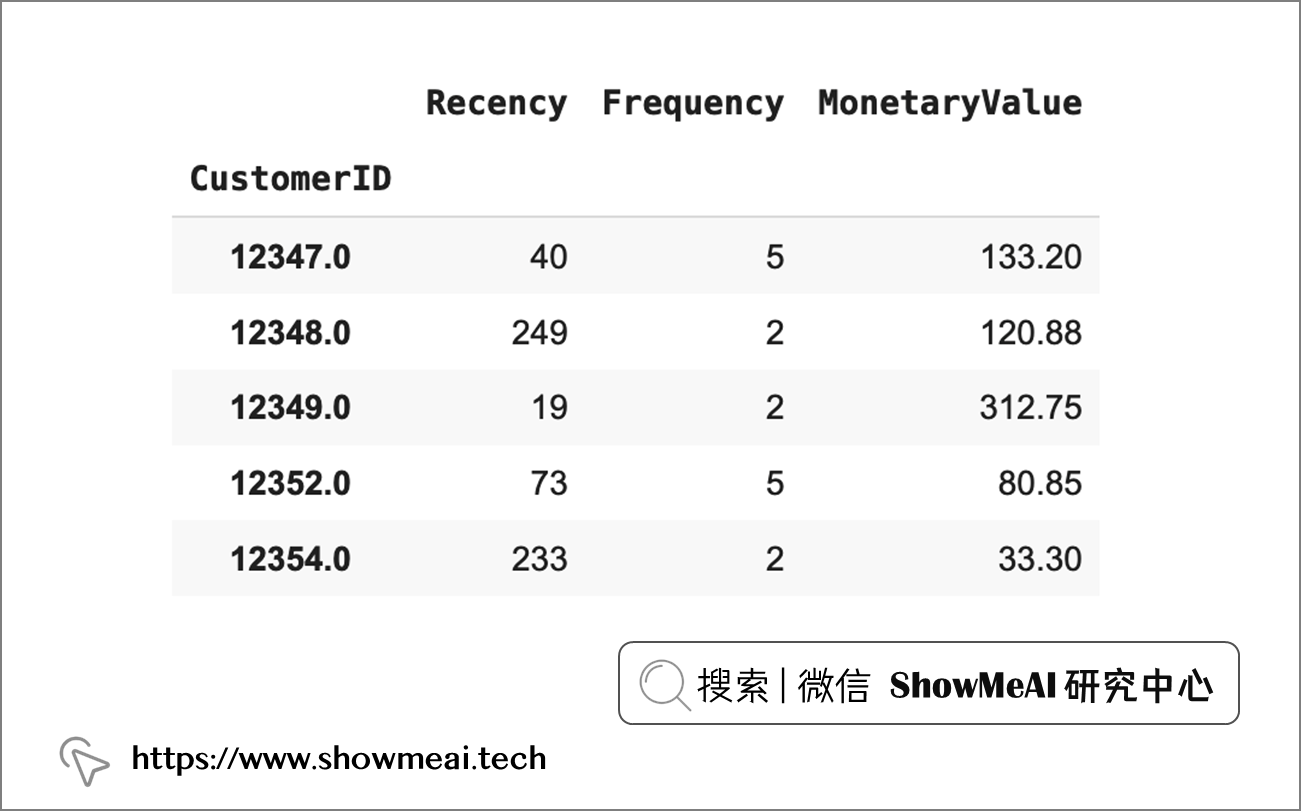
💡 探索数据&数据变换
下列数据预处理涉及的知识,欢迎大家查阅ShowMeAI对应的知识详解文章。
我们的很多典型的模型算法,对于数据分布都有一些前提假设,比如我们会认为连续值字段是基本符合正态分布的,我们对不同的字段进行可视化处理,以查看其分布:
fig, ax = plt.subplots(1, 3, figsize=(15,3))
sns.distplot(customers['Recency'], ax=ax[0])
sns.distplot(customers['Frequency'], ax=ax[1])
sns.distplot(customers['MonetaryValue'], ax=ax[2])
plt.tight_layout()
plt.show()
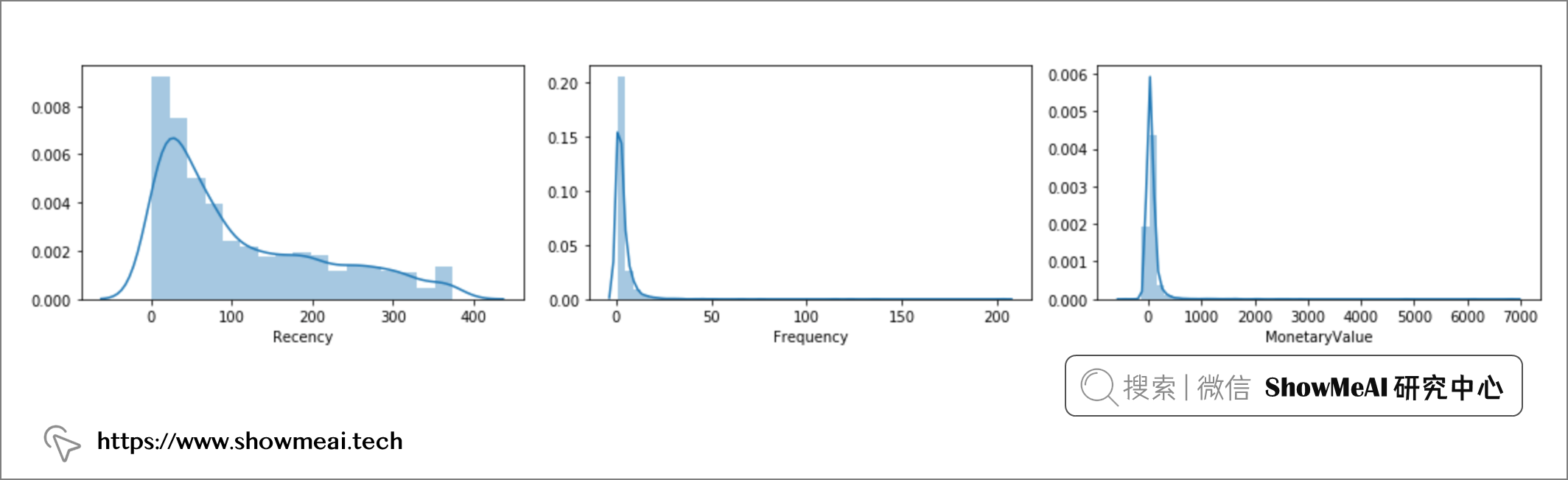
我们会发现,数据并不是完全正态分布的,准确地说,它们都是有偏的,我们通常会通过一些数据变换手段来对数据做一些梳理,常见的数据变换方式包括:
- 对数转换
- 平方根变换
- box-cox 变换
我们可以对原始数据,分别使用『对数变换』、『平方根变换』和『box-cox 变换处理』,把分布绘制如下:
from scipy import stats
def analyze_skewness(x):
fig, ax = plt.subplots(2, 2, figsize=(5,5))
sns.distplot(customers[x], ax=ax[0,0])
sns.distplot(np.log(customers[x]), ax=ax[0,1])
sns.distplot(np.sqrt(customers[x]), ax=ax[1,0])
sns.distplot(stats.boxcox(customers[x])[0], ax=ax[1,1])
plt.tight_layout()
plt.show()
print(customers[x].skew().round(2))
print(np.log(customers[x]).skew().round(2))
print(np.sqrt(customers[x]).skew().round(2))
print(pd.Series(stats.boxcox(customers[x])[0]).skew().round(2))
analyze_skewness('Recency')
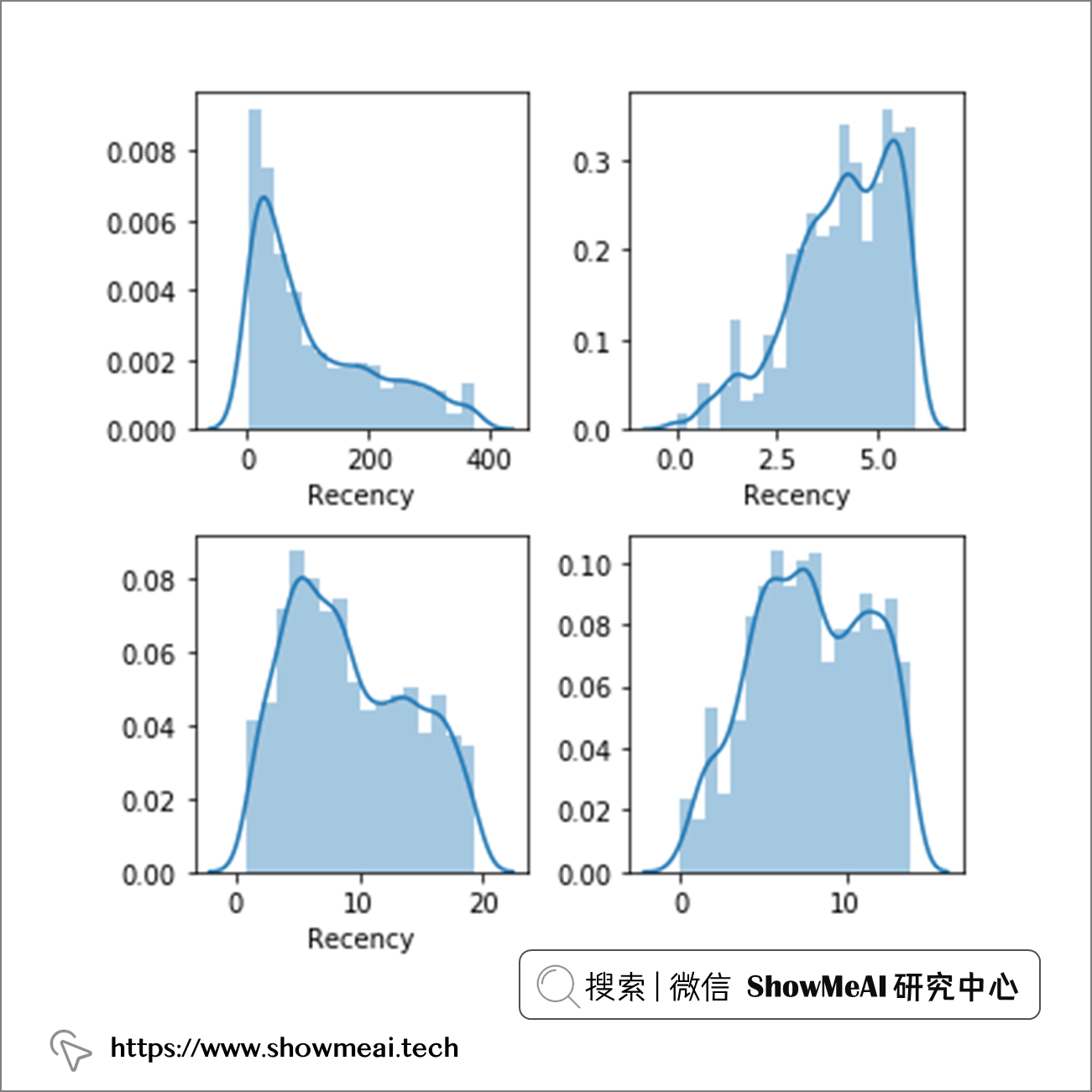
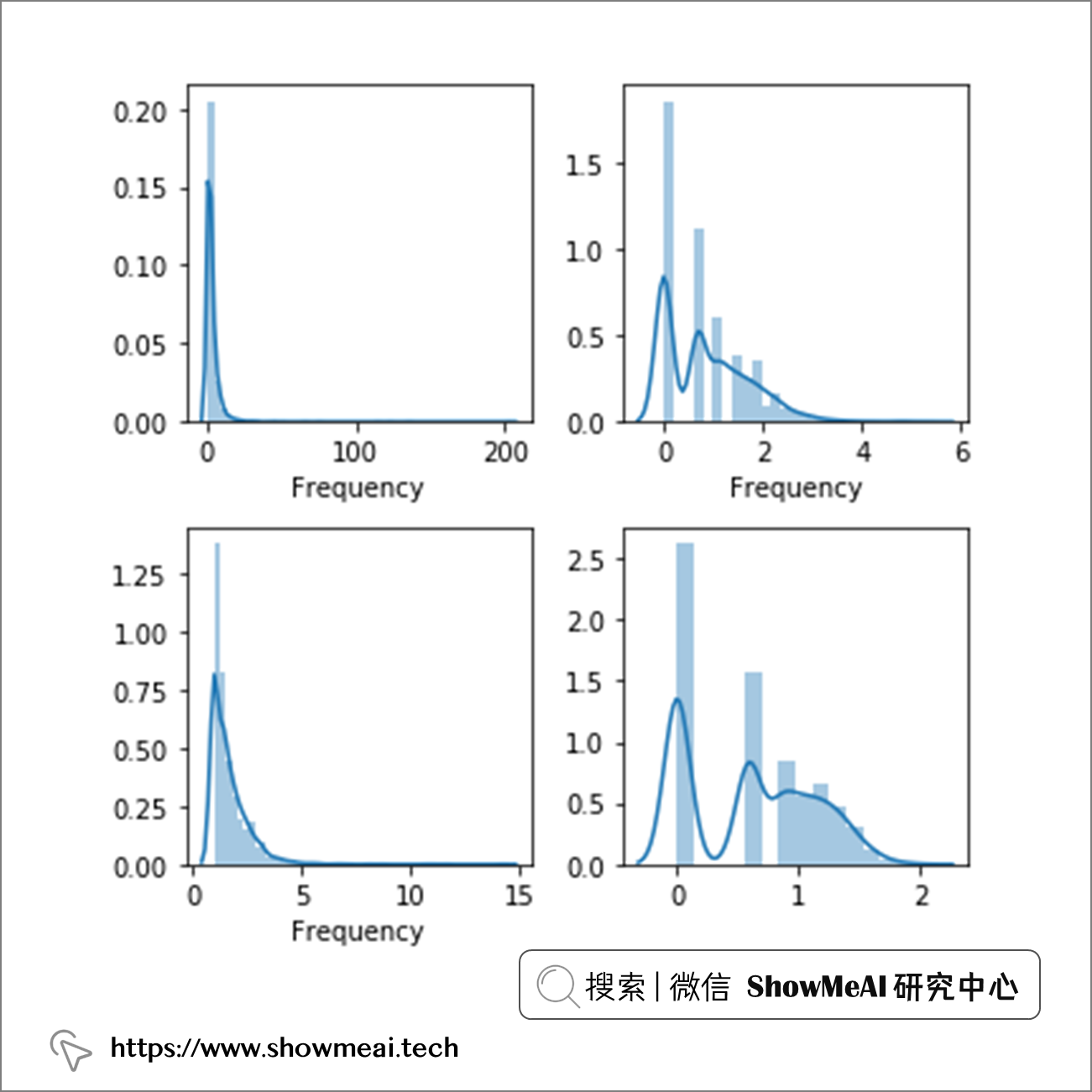
analyze_skewness('Frequency')
fig, ax = plt.subplots(1, 2, figsize=(10,3))
sns.distplot(customers['MonetaryValue'], ax=ax[0])
sns.distplot(np.cbrt(customers['MonetaryValue']), ax=ax[1])
plt.show()
print(customers['MonetaryValue'].skew().round(2))
print(np.cbrt(customers['MonetaryValue']).skew().round(2))
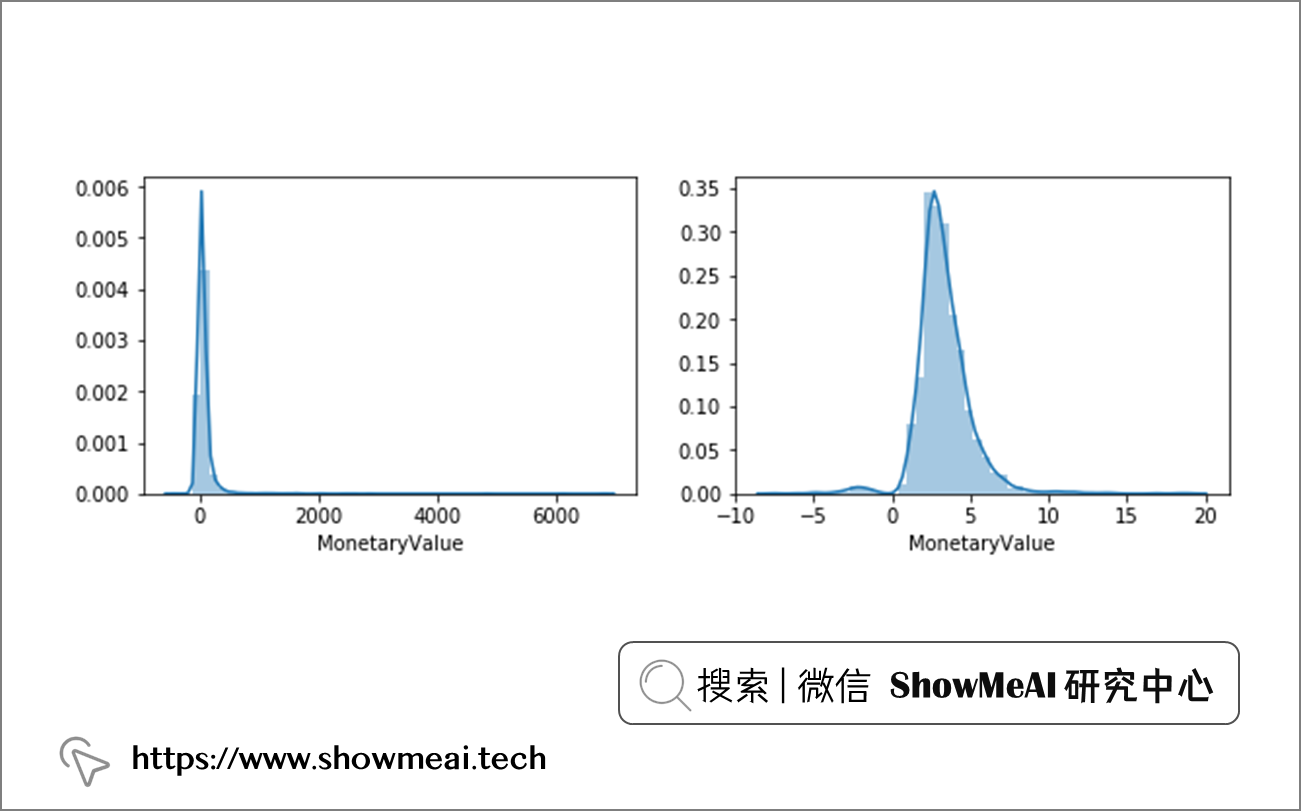
根据图像可视化,我们分别对Recency、Frequency、MonetaryValue选择box-cox变换,box-cox变换和三次方根(cbrt)变换。
from scipy import stats
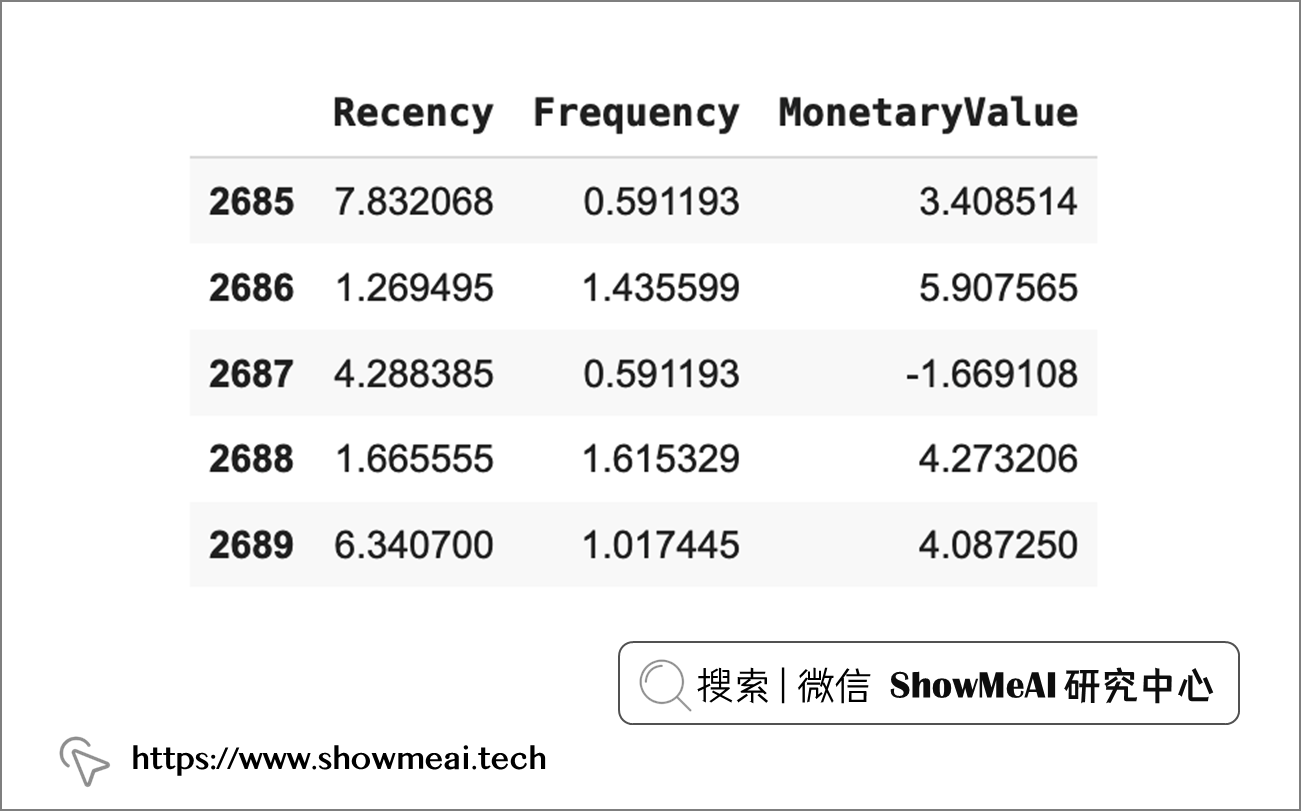
customers_fix = pd.DataFrame()
customers_fix["Recency"] = stats.boxcox(customers['Recency'])[0]
customers_fix["Frequency"] = stats.boxcox(customers['Frequency'])[0]
customers_fix["MonetaryValue"] = pd.Series(np.cbrt(customers['MonetaryValue'])).values
customers_fix.tail()
处理过后的数据是这样的
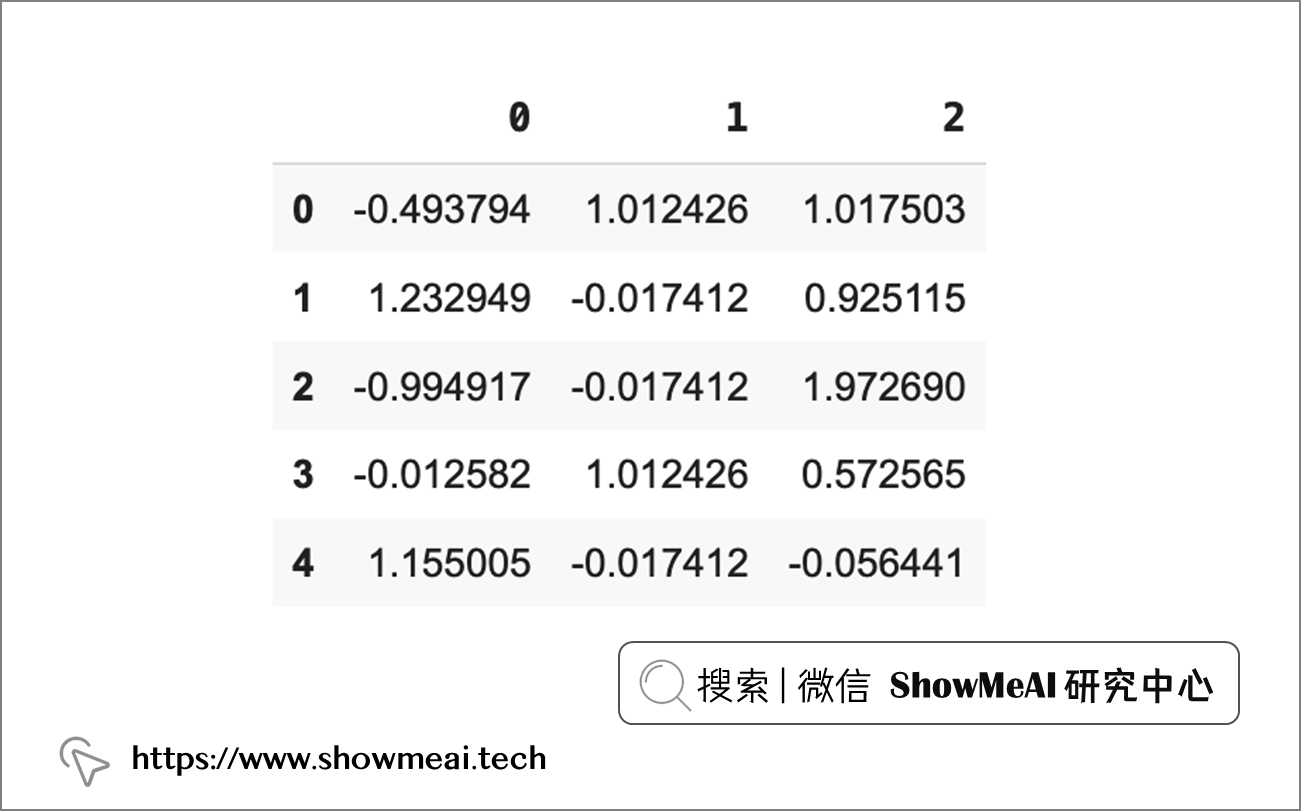
我们一会儿使用到的模型算法(K-Means 聚类),对于不同字段的幅度大小是敏感的,我们会再做进一步的数据处理,把数据幅度规范化,这里我们可以直接使用 Scikit-Learn 的
# 导入库
from sklearn.preprocessing import StandardScaler
# 初始化对象
scaler = StandardScaler()
# 拟合和转换数据
scaler.fit(customers_fix)
customers_normalized = scaler.transform(customers_fix)
# 均值为 0,方差为 1
print(customers_normalized.mean(axis = 0).round(2)) # [0. -0。 0.]
print(customers_normalized.std(axis = 0).round(2)) # [1. 1. 1.]
得到结果如下:
💡 建模与分群
数据处理完成,我们可以进一步使用算法模型完成客户分群了,这里我们使用聚类算法 K-Means 来对数据分组。
K-Means 算法是一种无监督学习算法,它通过迭代和聚合来根据数据分布确定数据属于哪个簇。关于 K-Means 的详细知识欢迎大家查看ShowMeAI的教程文章:
实际应用 K-Means 算法是很简单的,我们直接使用 Scikit-Learn 来实现。但是 K-Means 算法中有一个很重要的超参数『簇数k』。下面我们使用『肘点法』来定位最好的超参数:
from sklearn.cluster import KMeans
sse = {}
for k in range(1, 11):
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(customers_normalized)
sse[k] = kmeans.inertia_
plt.title('The Elbow Method')plt.xlabel('k')
plt.ylabel('SSE')
sns.pointplot(x=list(sse.keys()), y=list(sse.values()))
plt.show()
这是结果,
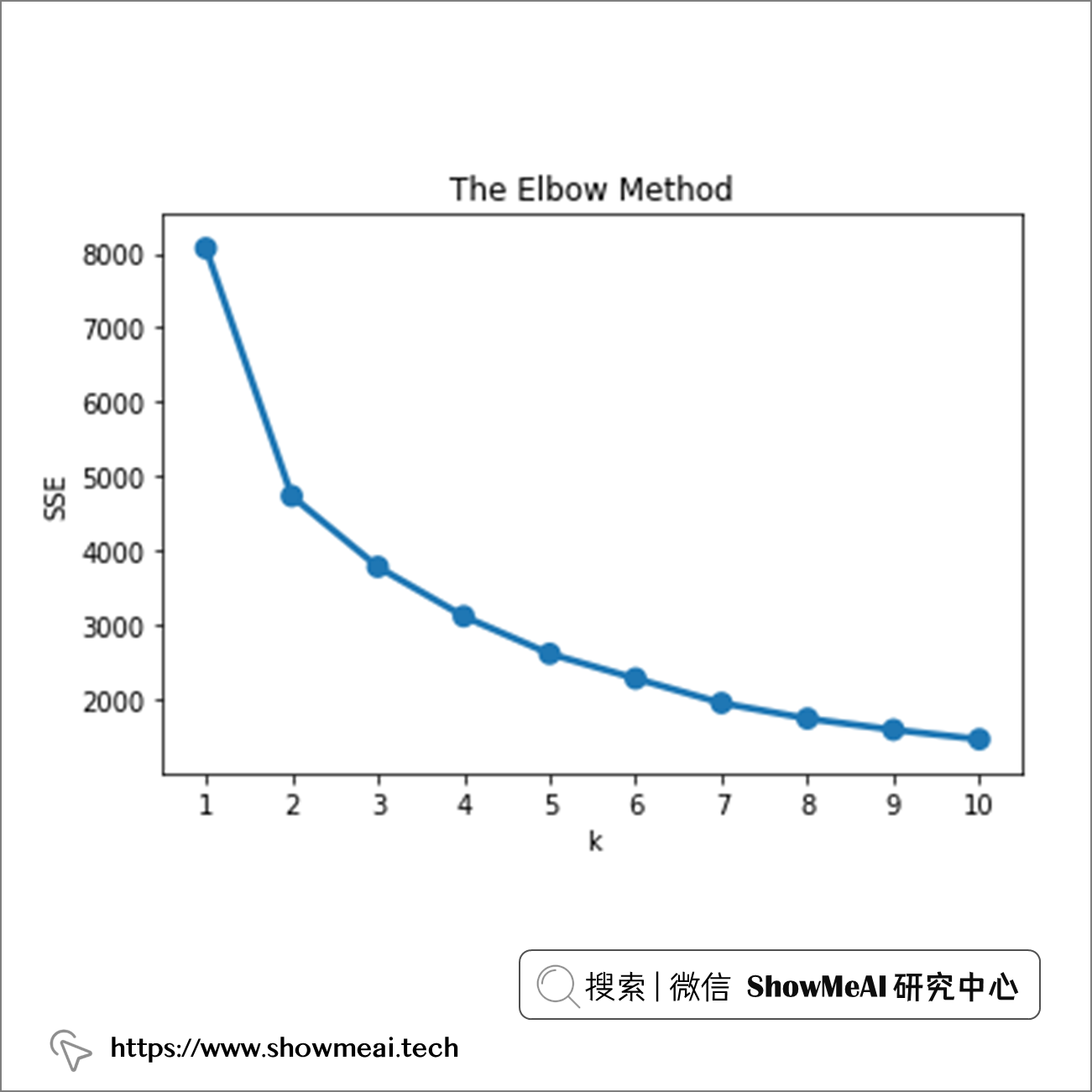
根据上图的结果,我们选定 k 取值为 3(因为大于3的k取值下,SSE的结果并不再急剧下降,而是呈现近线性)。我们设定n_clusters为3,再重新聚类:
model = KMeans(n_clusters=3, random_state=42)
model.fit(customers_normalized)
model.labels_.shape
💡 模型解释&业务理解
我们基于聚类结果来对用户群做一些解读和业务理解,这里我们将聚类得到的 3 个 cluster 的聚类中心信息输出,代码如下:
customers["Cluster"] = model.labels_
customers.groupby('Cluster').agg({
'Recency':'mean',
'Frequency':'mean',
'MonetaryValue':['mean', 'count']}).round(2)
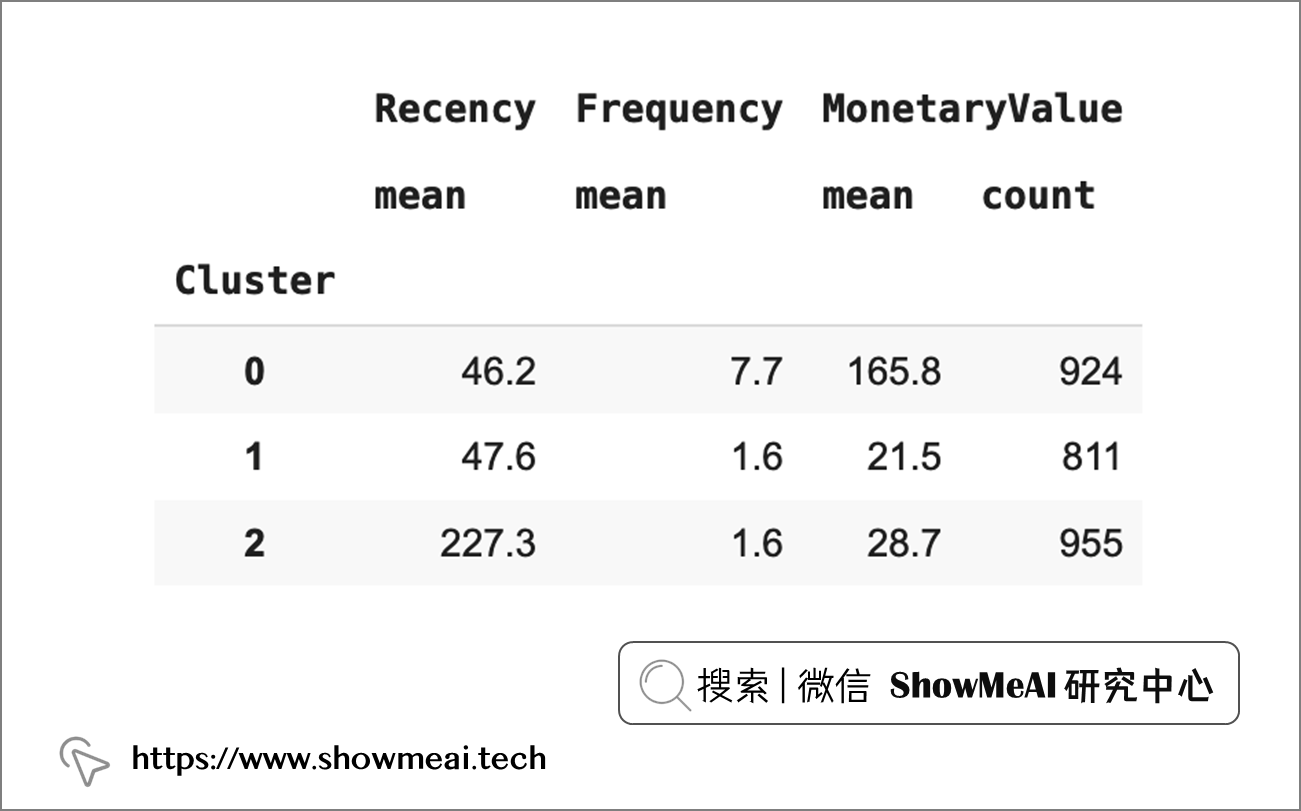
结合上述结果,对3类聚类得到的用户群解读如下:
- 用户群0:频繁消费,消费数额大,且最近有购买行为。可以视作『忠实客户群』。
- 用户群1: 消费频率较低,消费数额小,但最近有购买行为。可以视作『新客户群』。
- 用户群2:消费频率较低,消费数额小,上一次购买的时间较早。可以视作『流失客户群』。

参考资料
- 📚 Daqing C., Sai L.S, and Kun G. Data mining for the online retail industry: A case study of RFM model-based customer segmentation using data mining (2012), Journal of Database Marketing and Customer Strategy Management.
- 📚 Millman K. J, Aivazis M. Python for Scientists and Engineers (2011), Computing in Science & Engineering.
- 📚 Radečić D. Top 3 Methods for Handling Skewed Data (2020), Towards Data Science.
- 📚 Elbow Method for optimal value of k in KMeans, Geeks For Geeks.
- 📘 图解数据分析:从入门到精通系列教程:https://www.showmeai.tech/tutorials/33
- 📘 数据科学工具库速查表 | Pandas 速查表:https://www.showmeai.tech/article-detail/101
- 📘 数据科学工具库速查表 | Seaborn 速查表:https://www.showmeai.tech/article-detail/105
- 📘 机器学习实战 | 机器学习特征工程最全解读:https://www.showmeai.tech/article-detail/208
- 📘 图解机器学习 | 聚类算法详解:https://www.showmeai.tech/article-detail/197

 浙公网安备 33010602011771号
浙公网安备 33010602011771号